The document discusses various models of parallel and distributed computing including symmetric multiprocessing (SMP), cluster computing, distributed computing, grid computing, and cloud computing. It provides definitions and examples of each model. It also covers parallel processing techniques like vector processing and pipelined processing, and differences between shared memory and distributed memory MIMD (multiple instruction multiple data) architectures.
Parallel Computing Itis a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently in parallel.
Distributed Computing Wikipedia: It deals with hardware and software systems containing more than one processing element or storage element, concurrent processes, or multiple programs, running under a loosely or tightly controlled regime
23.
Grid Computing Wikipedia: A form of distributed computing whereby a super and virtual computer is composed of a cluster of networked, loosely-coupled computers, acting in concert to perform large tasks.
24.
pcwebopedia.com : Unlikeconventional networks that focus on communication among devices, grid computing harnesses unused processing cycles of all computers in a network for solving problems too intensive for any stand-alone machine.
25.
IBM: Gridcomputing enables the virtualization of distributed computing and data resources such as processing, network bandwidth and storage capacity to create a single system image, granting users and applications seamless access to vast IT capabilities. Just as an Internet user views a unified instance of content via the Web, a grid user essentially sees a single, large virtual computer.
26.
Sun: GridComputing is a computing infrastructure that provides dependable, consistent, pervasive and inexpensive access to computational capabilities.
27.
Cloud Computing Wikipedia: It is a style of computing in which dynamically stable and often virtualised resources are provided as a service over the Internet.
Hardware: IBM p690Regatta 32 POWER4 CPUs (1.1 GHz) 32 GB RAM 218 GB internal disk OS: AIX 5.1 Peak speed: 140.8 GFLOP/s * Programming model: shared memory multithreading (OpenMP) (also supports MPI) * GFLOP/s: billion floating point operations per second
34.
270 Pentium4 XeonDPCPUs 270 GB RAM 8,700 GB disk OS: Red Hat Linux Enterprise 3 Peak speed: 1.08 TFLOP/s * Programming model: distributed multiprocessing (MPI) * TFLOP/s: trillion floating point operations per second Hardware: Pentium4 Xeon Cluster
35.
56 Itanium2 1.0GHz CPUs 112 GB RAM 5,774 GB disk OS: Red Hat Linux Enterprise 3 Peak speed: 224 GFLOP/s * Programming model: distributed multiprocessing (MPI) * GFLOP/s: billion floating point operations per second Hardware: Itanium2 Cluster schooner.oscer.ou.edu New arrival!
36.
Vector Processing Itis based on array processors where the instruction set includes operations that can perform mathematical operations on data elements simultaneously
Pipelined Processing Thefundamental idea is to split the processing of a computer instruction into a series of independent steps, with storage at the end of each step.
42.
This allows thecomputer's control circuitry to issue instructions at the processing rate of the slowest step, which is much faster than the time needed to perform all steps at once.
43.
A non-pipeline architectureis inefficient because some CPU components (modules) are idle while another module is active during the instruction cycle
44.
Processors with pipeliningare organized inside into stages which can semi-independently work on separate jobs
45.
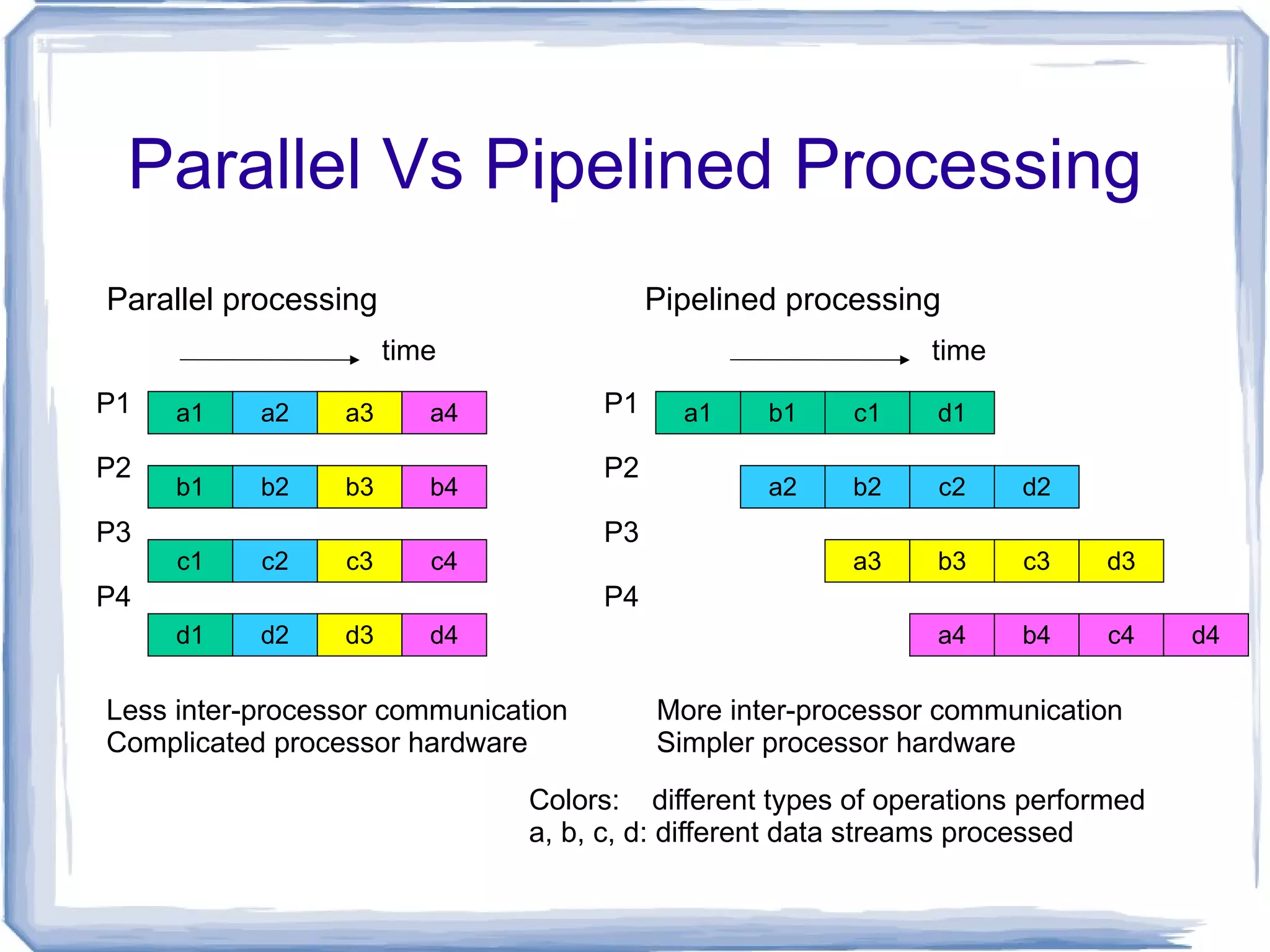
Parallel Vs PipelinedProcessing Parallel processing Pipelined processing a1 a2 a3 a4 b1 b2 b3 b4 c1 c2 c3 c4 d1 d2 d3 d4 a1 b1 c1 d1 a2 b2 c2 d2 a3 b3 c3 d3 a4 b4 c4 d4 P1 P2 P3 P4 P1 P2 P3 P4 time Colors: different types of operations performed a, b, c, d: different data streams processed Less inter-processor communication Complicated processor hardware time More inter-processor communication Simpler processor hardware
46.
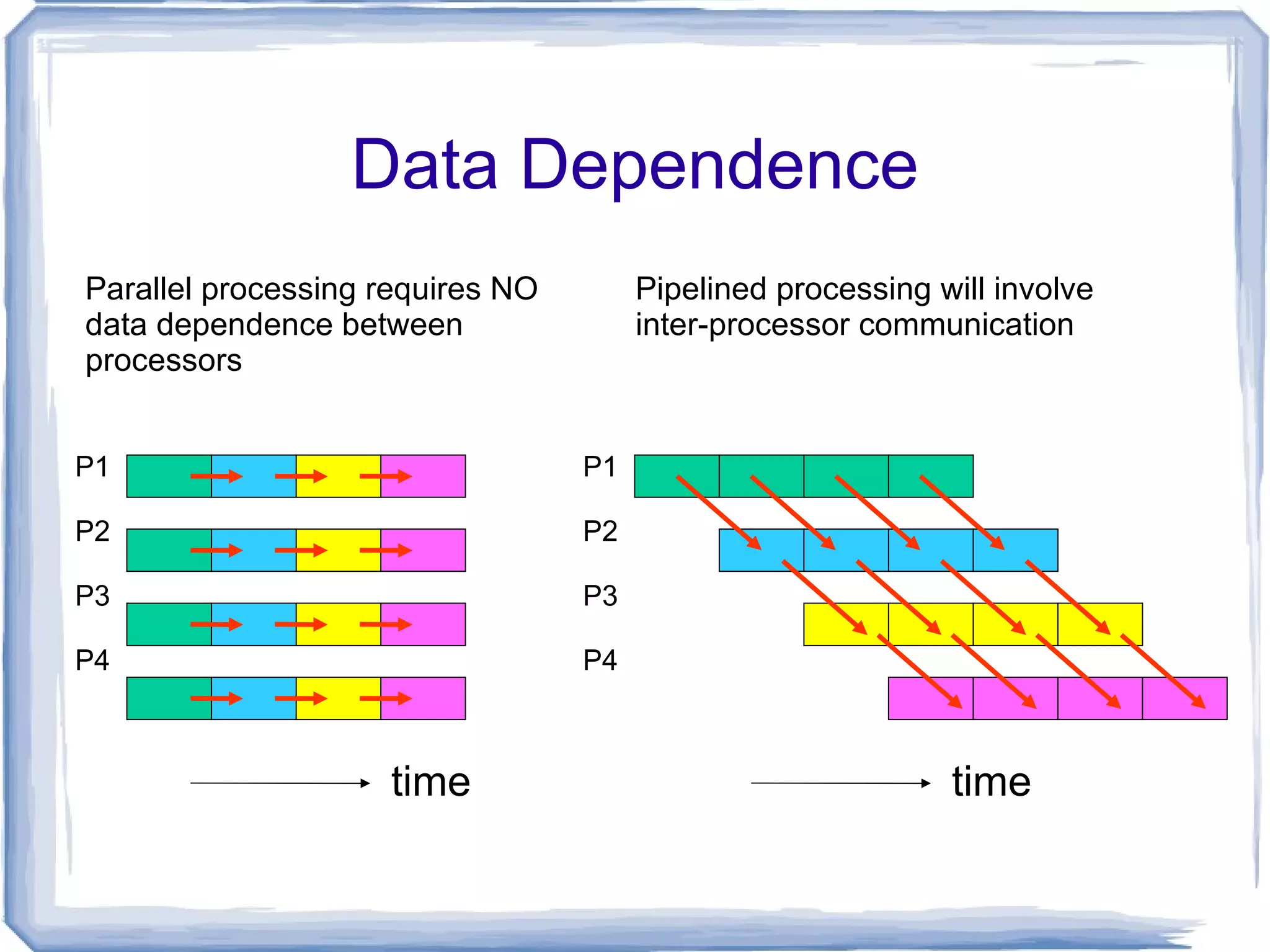
Data Dependence Parallelprocessing requires NO data dependence between processors Pipelined processing will involve inter-processor communication P1 P2 P3 P4 P1 P2 P3 P4 time time
47.
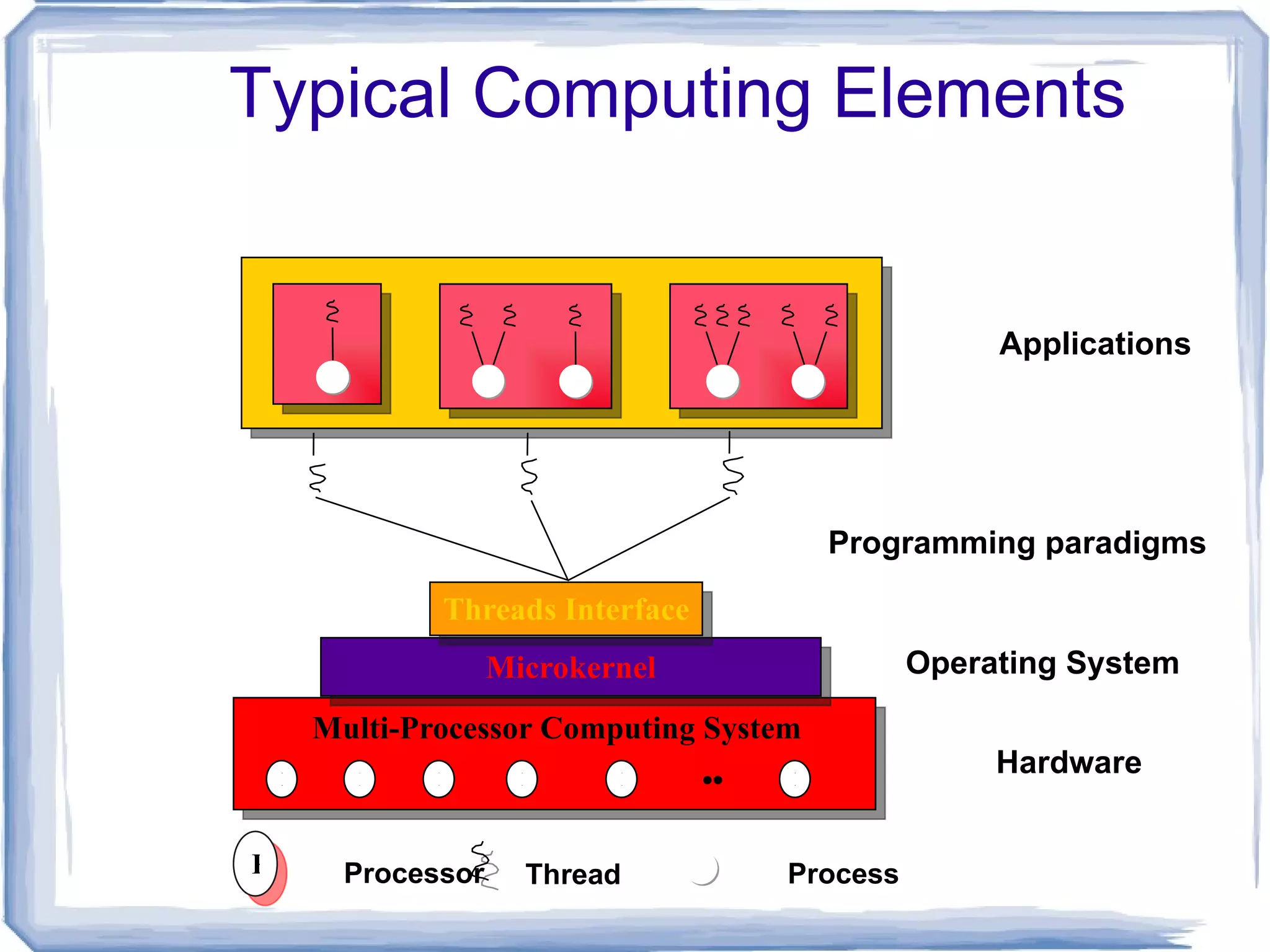
Typical Computing ElementsHardware Operating System Applications Programming paradigms P P P P P P Microkernel Multi-Processor Computing System Threads Interface Process Processor Thread P
48.
Why Parallel Processing? Computation requirements are ever increasing; for instance -- visualization, distributed databases, simulations, scientific prediction (ex: climate, earthquake), etc.
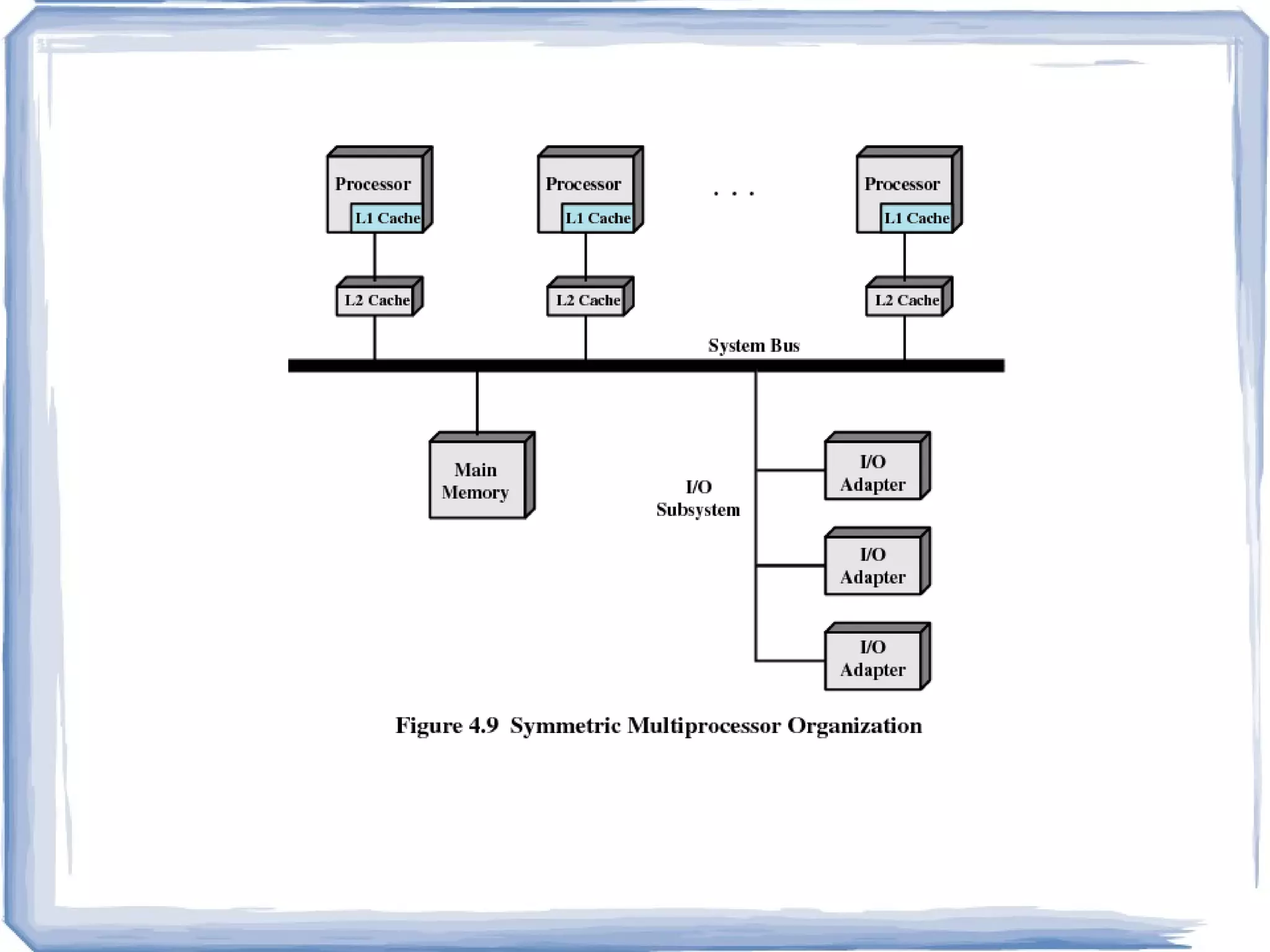
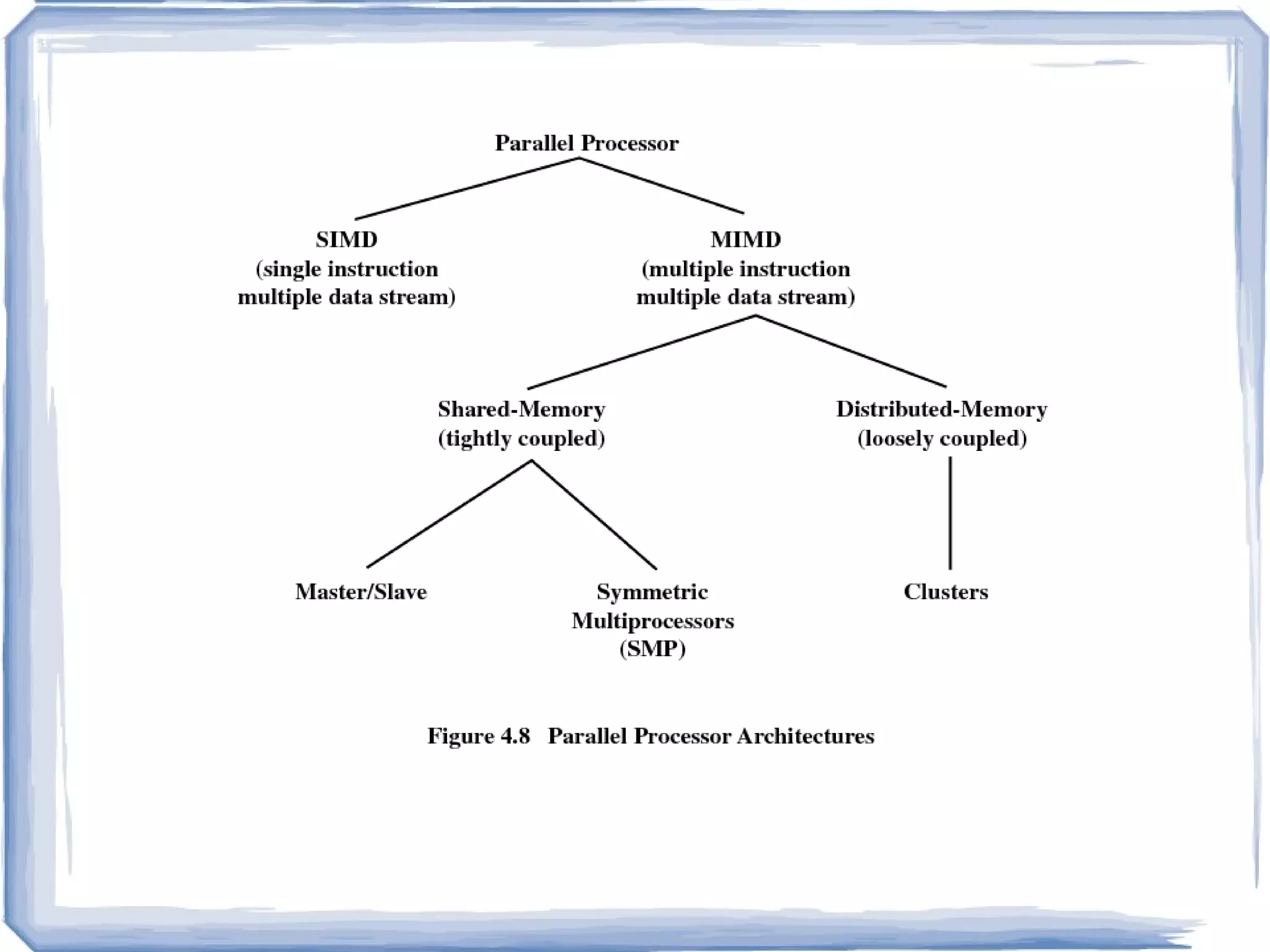
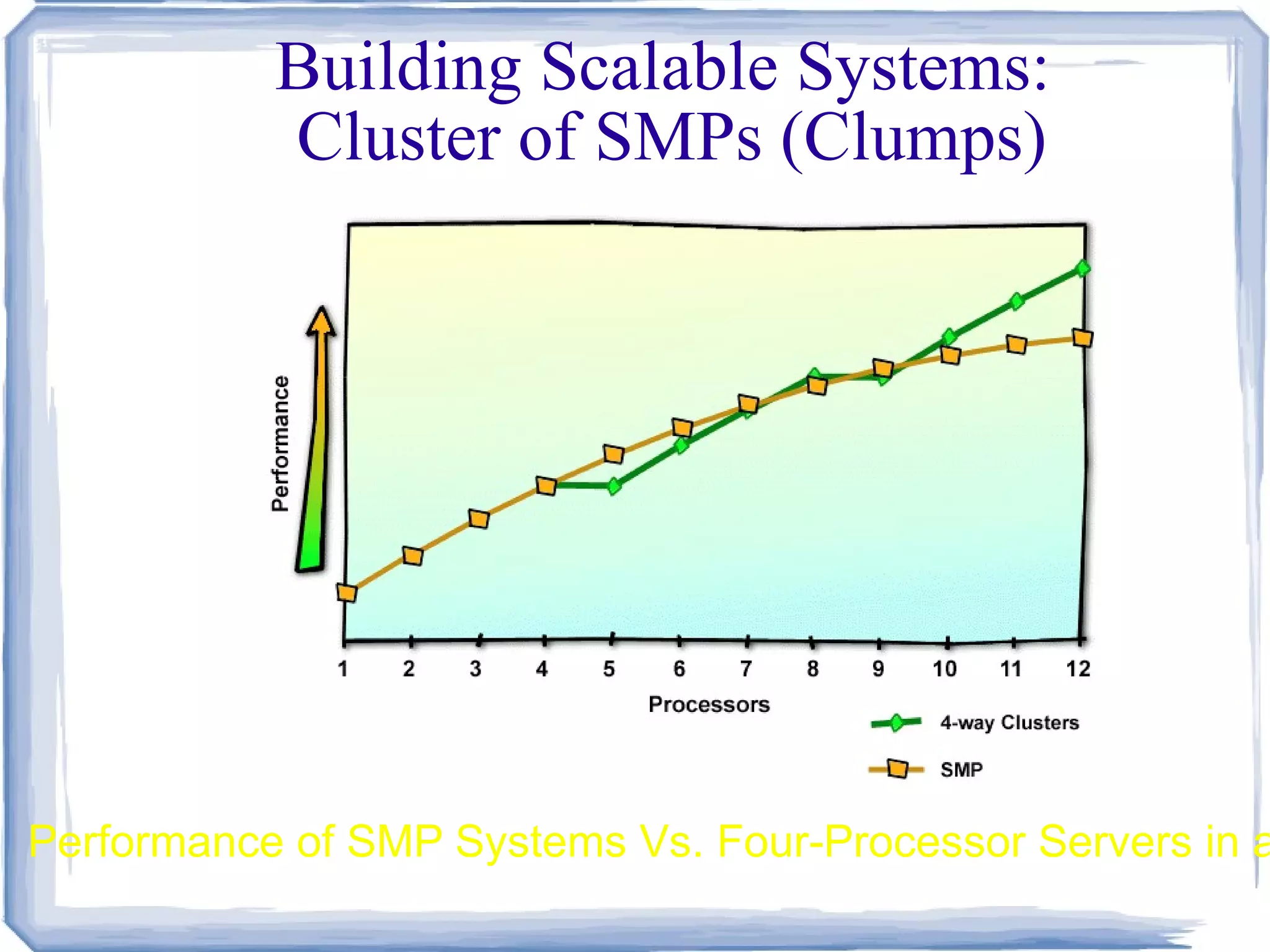
Symmetric Multiprocessing SMPInvolves a multiprocessor computer architecture where two or more identical processors can connect to a single shared main memory
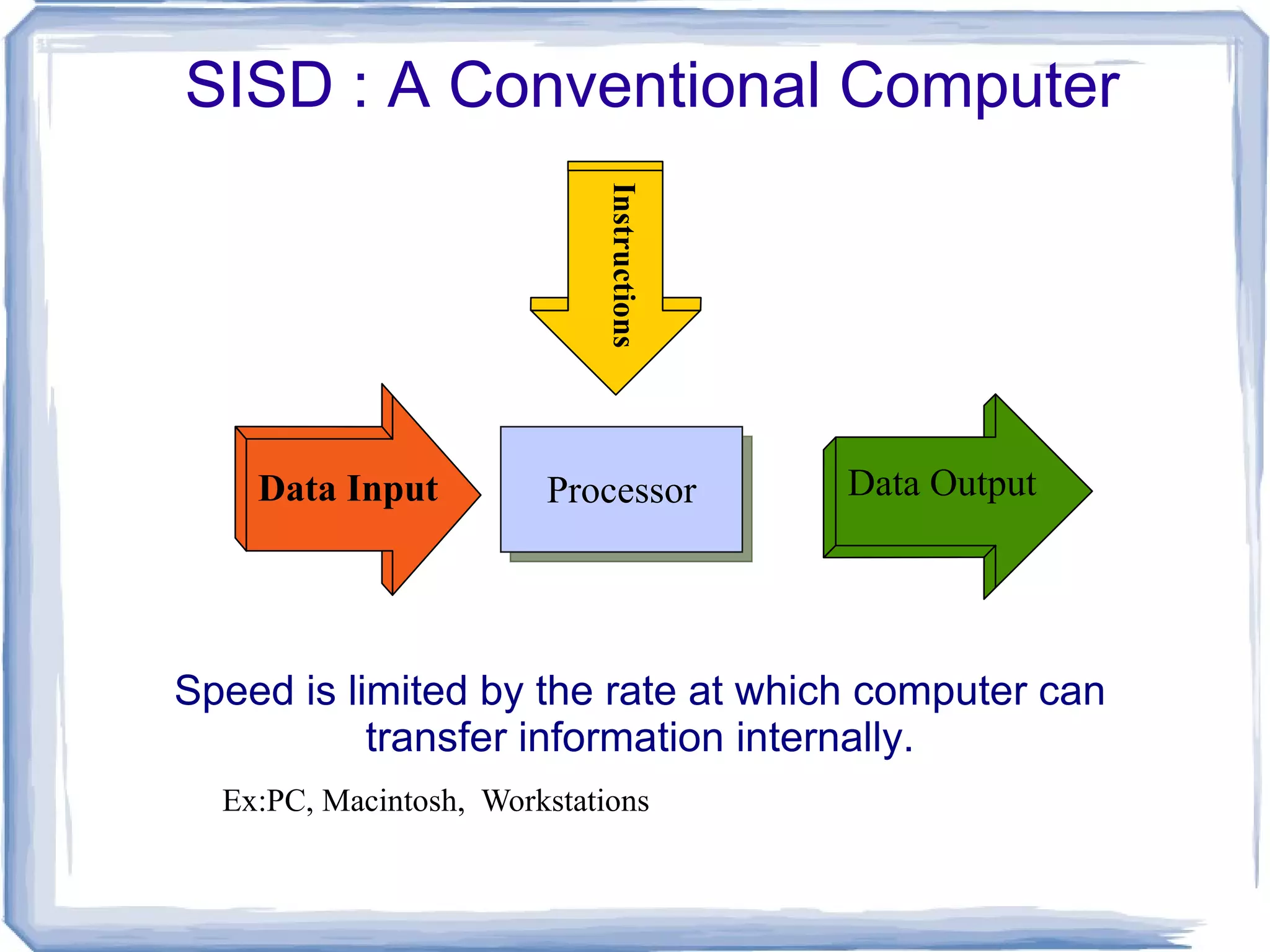
SISD : AConventional Computer Speed is limited by the rate at which computer can transfer information internally. Ex:PC, Macintosh, Workstations Processor Data Input Data Output Instructions
62.
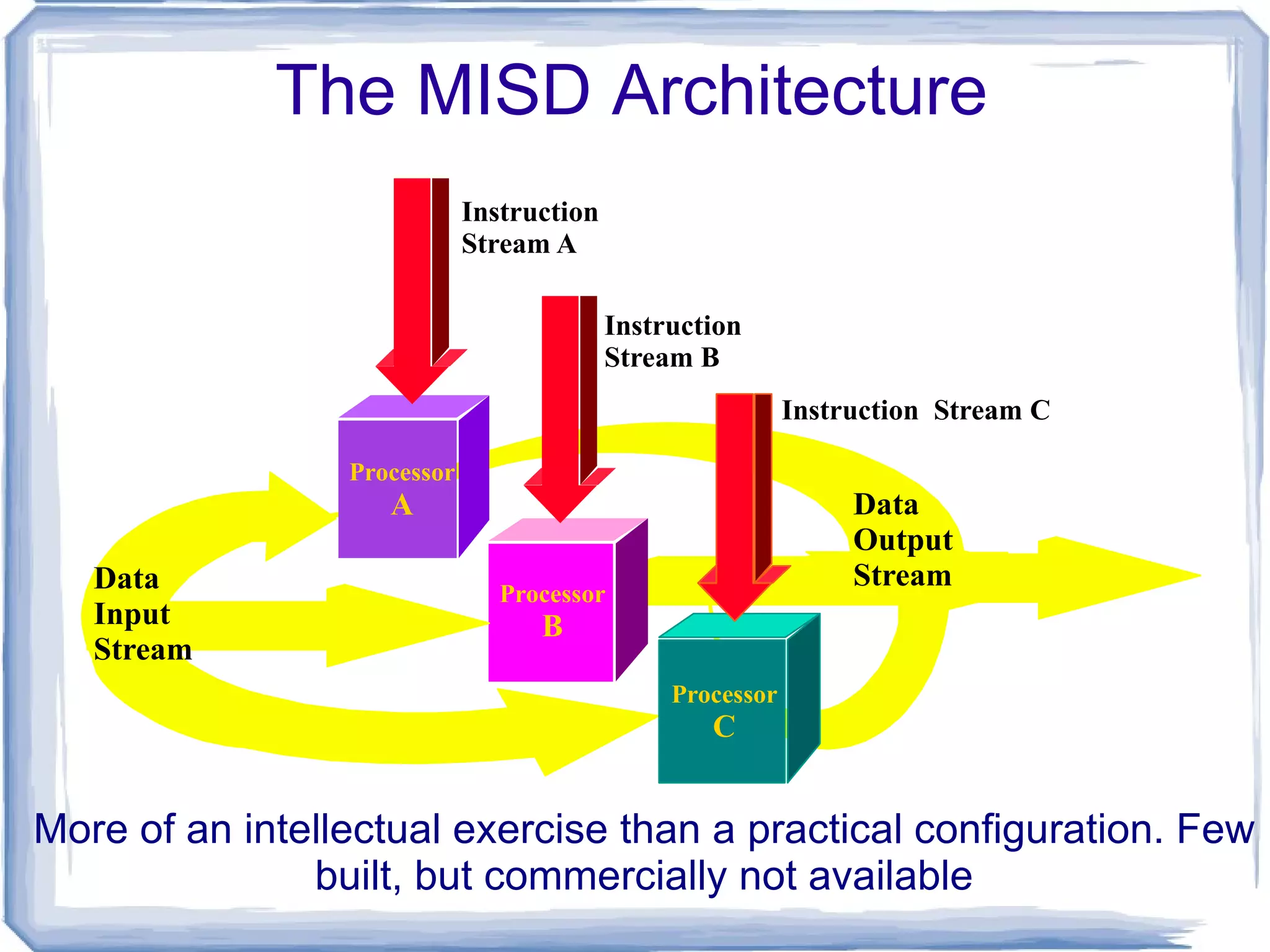
The MISD ArchitectureMore of an intellectual exercise than a practical configuration. Few built, but commercially not available Data Input Stream Data Output Stream Processor A Processor B Processor C Instruction Stream A Instruction Stream B Instruction Stream C
63.
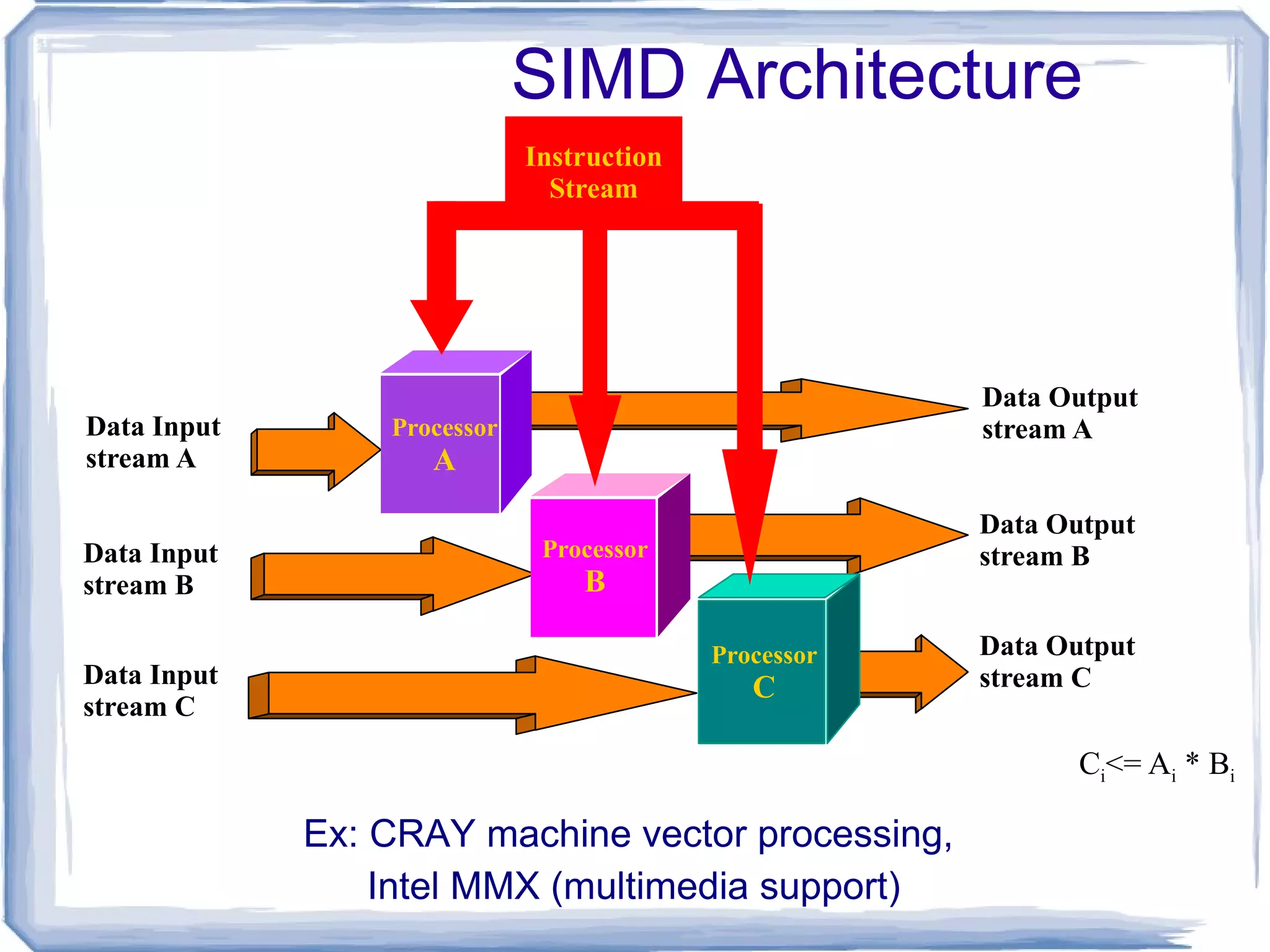
SIMD Architecture Ex:CRAY machine vector processing, Intel MMX (multimedia support) C i <= A i * B i Instruction Stream Processor A Processor B Processor C Data Input stream A Data Input stream B Data Input stream C Data Output stream A Data Output stream B Data Output stream C
64.
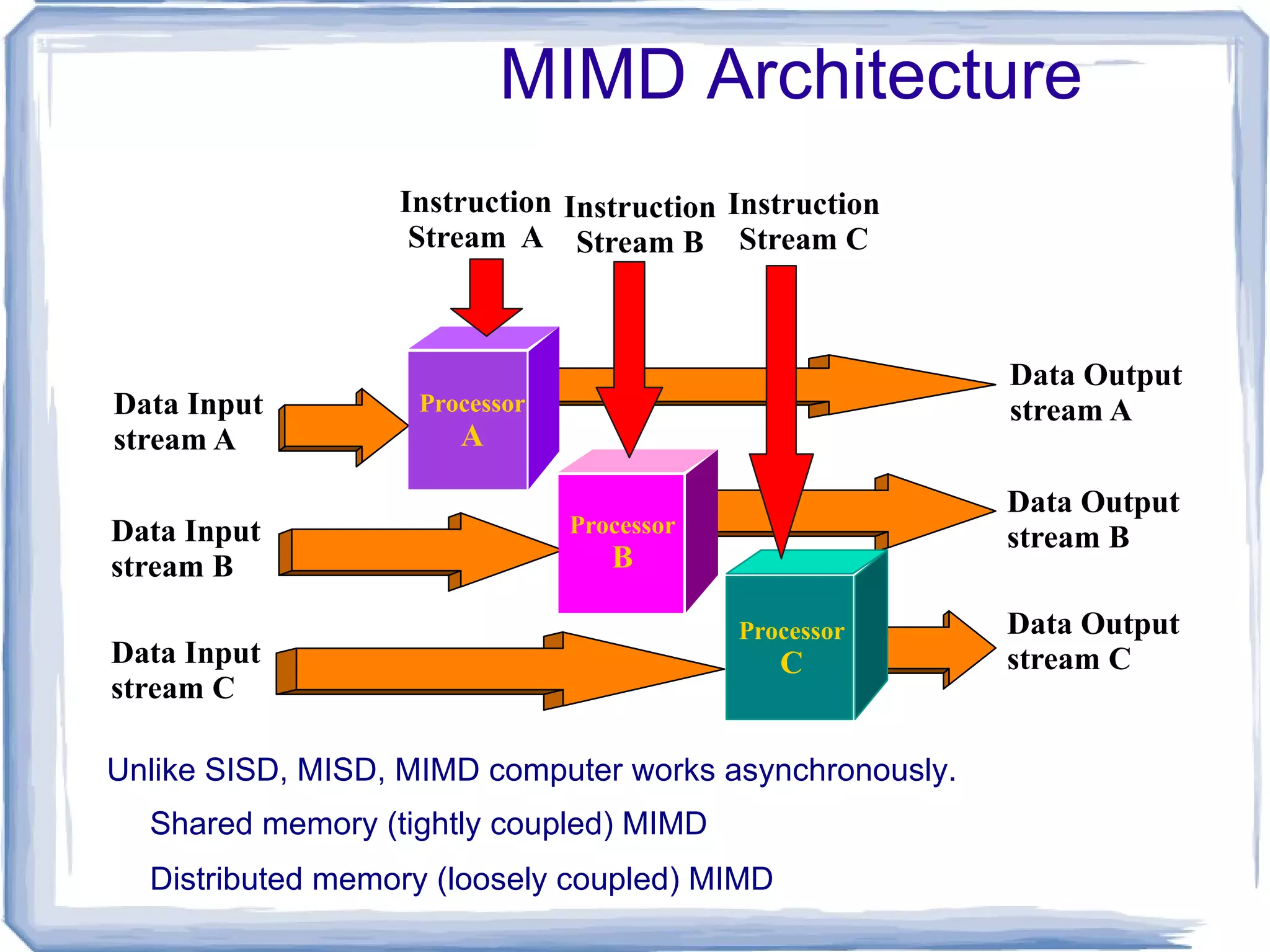
Unlike SISD, MISD,MIMD computer works asynchronously. Shared memory (tightly coupled) MIMD Distributed memory (loosely coupled) MIMD MIMD Architecture Processor A Processor B Processor C Data Input stream A Data Input stream B Data Input stream C Data Output stream A Data Output stream B Data Output stream C Instruction Stream A Instruction Stream B Instruction Stream C
65.
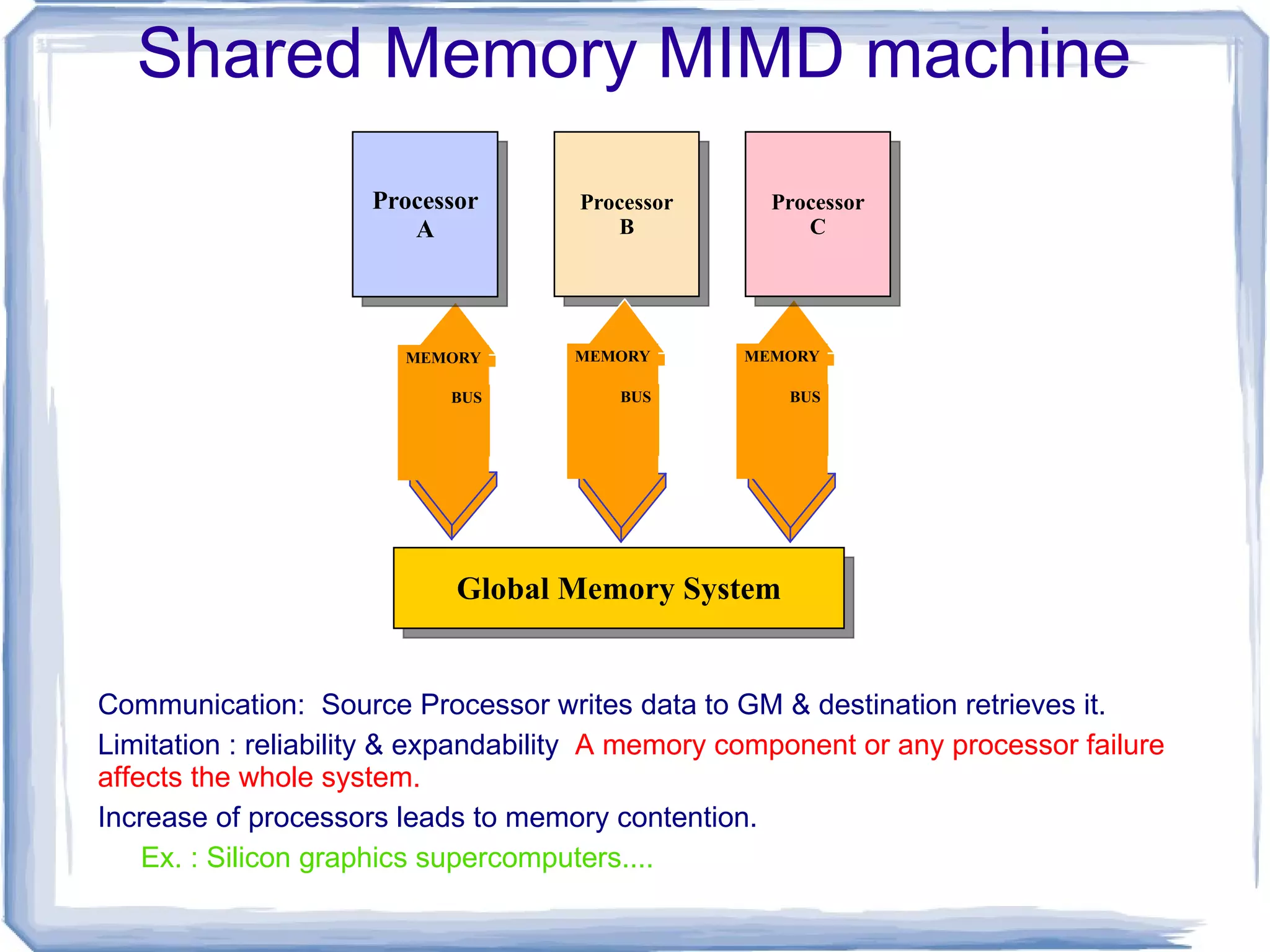
Shared Memory MIMDmachine Communication: Source Processor writes data to GM & destination retrieves it.
66.
Limitation : reliability& expandability A memory component or any processor failure affects the whole system. Increase of processors leads to memory contention. Ex. : Silicon graphics supercomputers.... Global Memory System Processor A Processor B Processor C MEMORY BUS MEMORY BUS MEMORY BUS
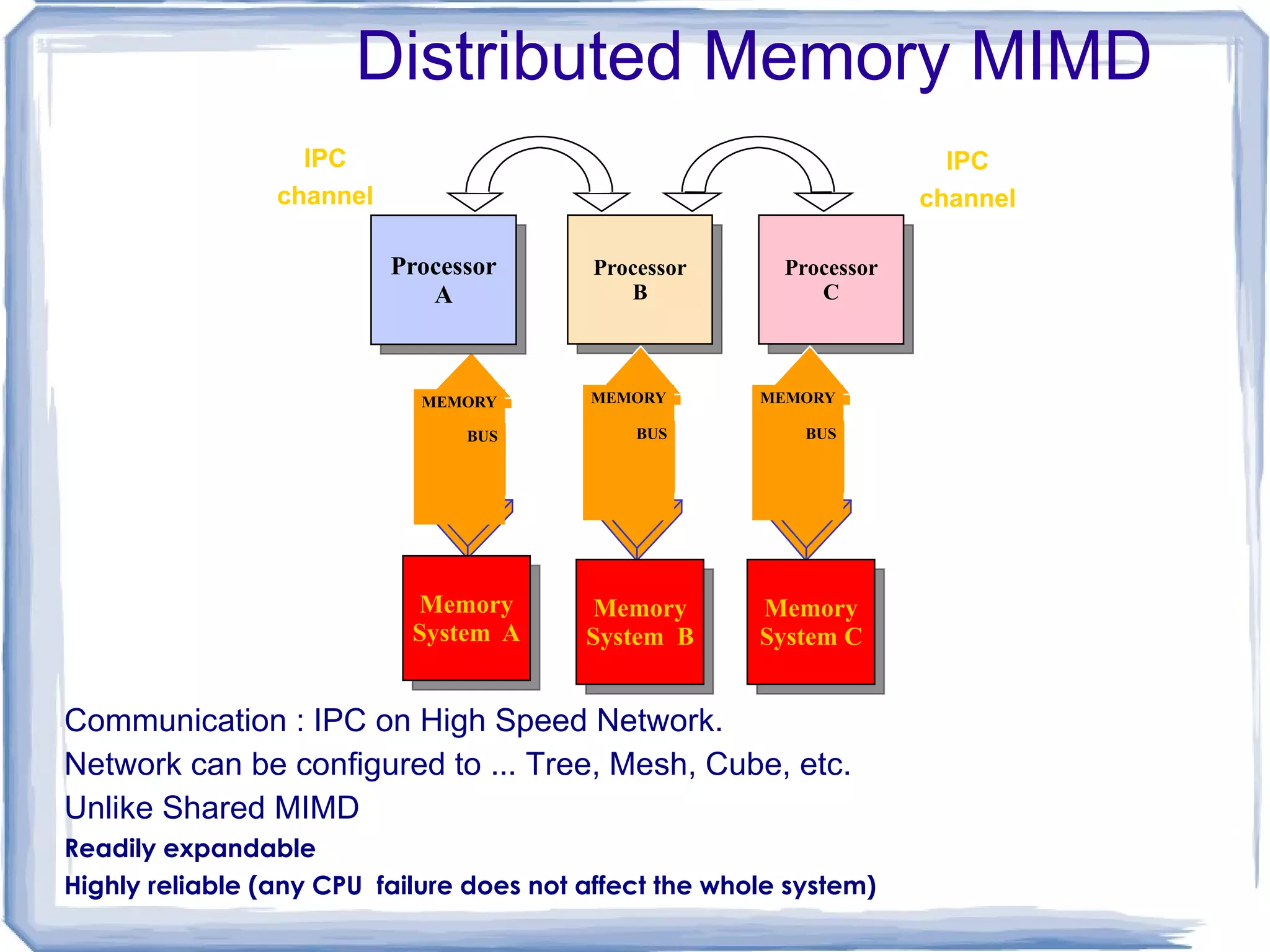
Highly reliable (anyCPU failure does not affect the whole system) Processor A Processor B Processor C IPC channel IPC channel MEMORY BUS MEMORY BUS MEMORY BUS Memory System A Memory System B Memory System C
71.
Laws of caution.....Speed of computers is proportional to the square of their cost. i.e. cost = Speed Speedup by a parallel computer increases as the logarithm of the number of processors. Speedup = log 2 (no. of processors) S P logP C S (speed = cost 2 )
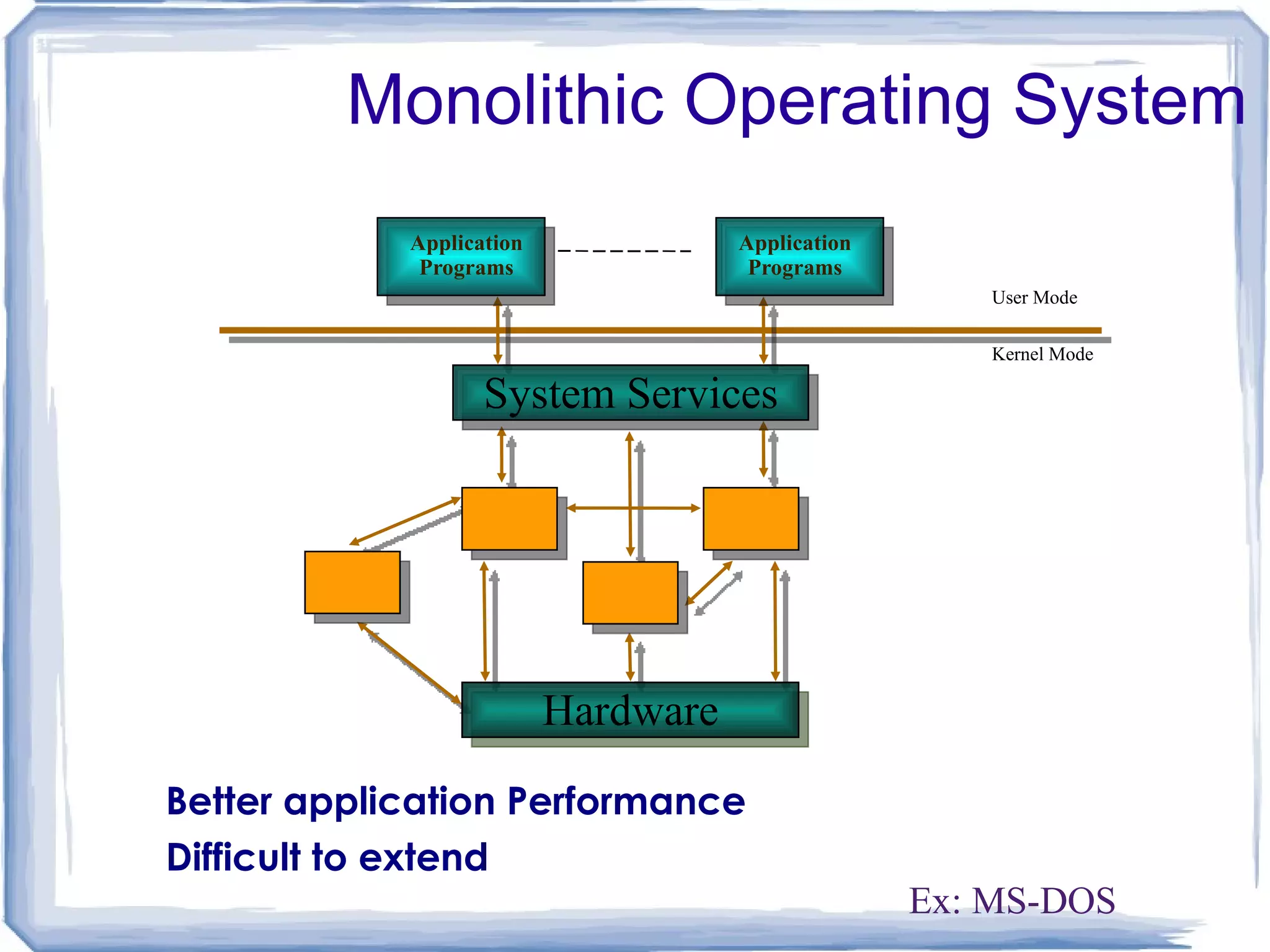
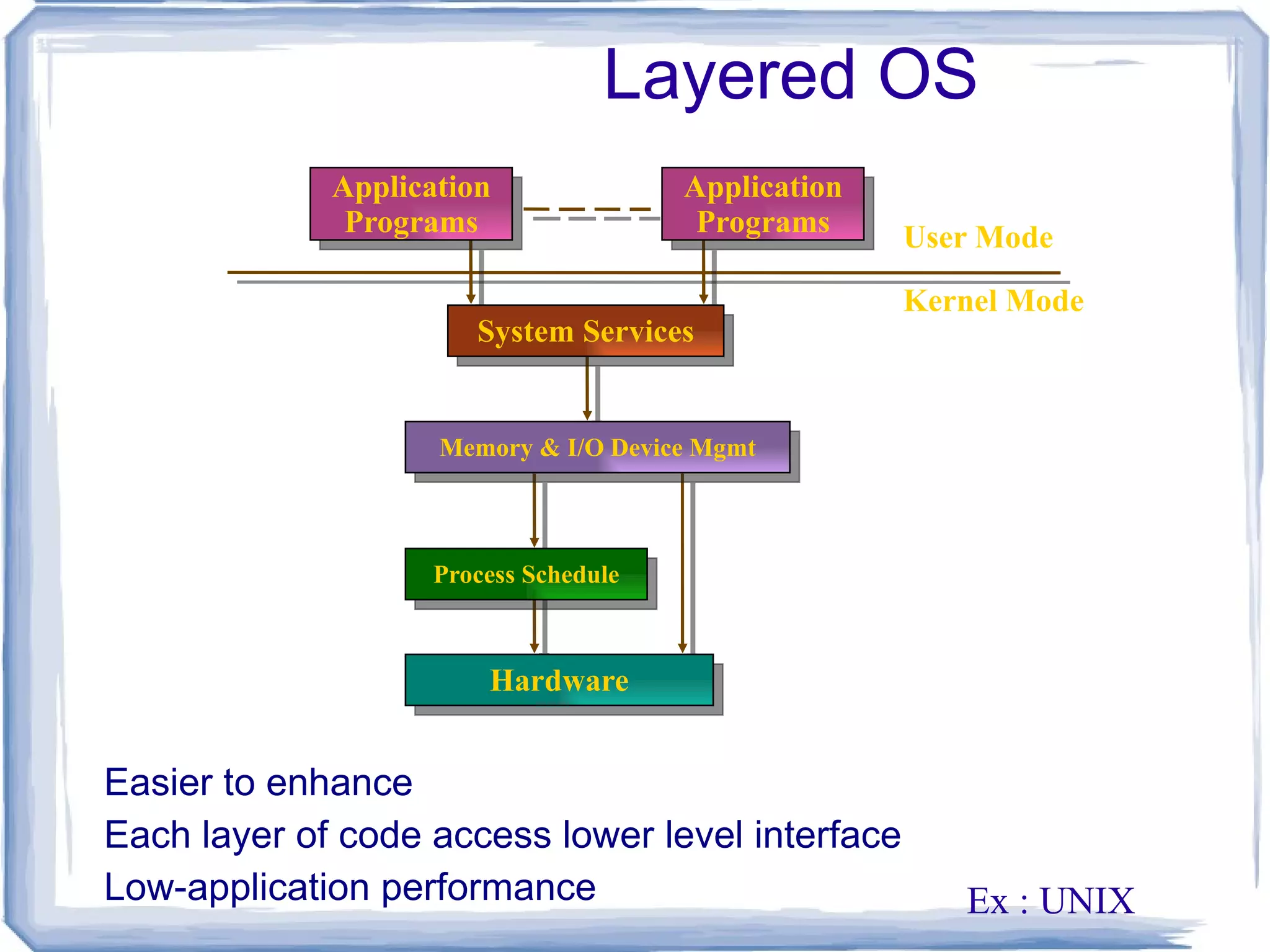
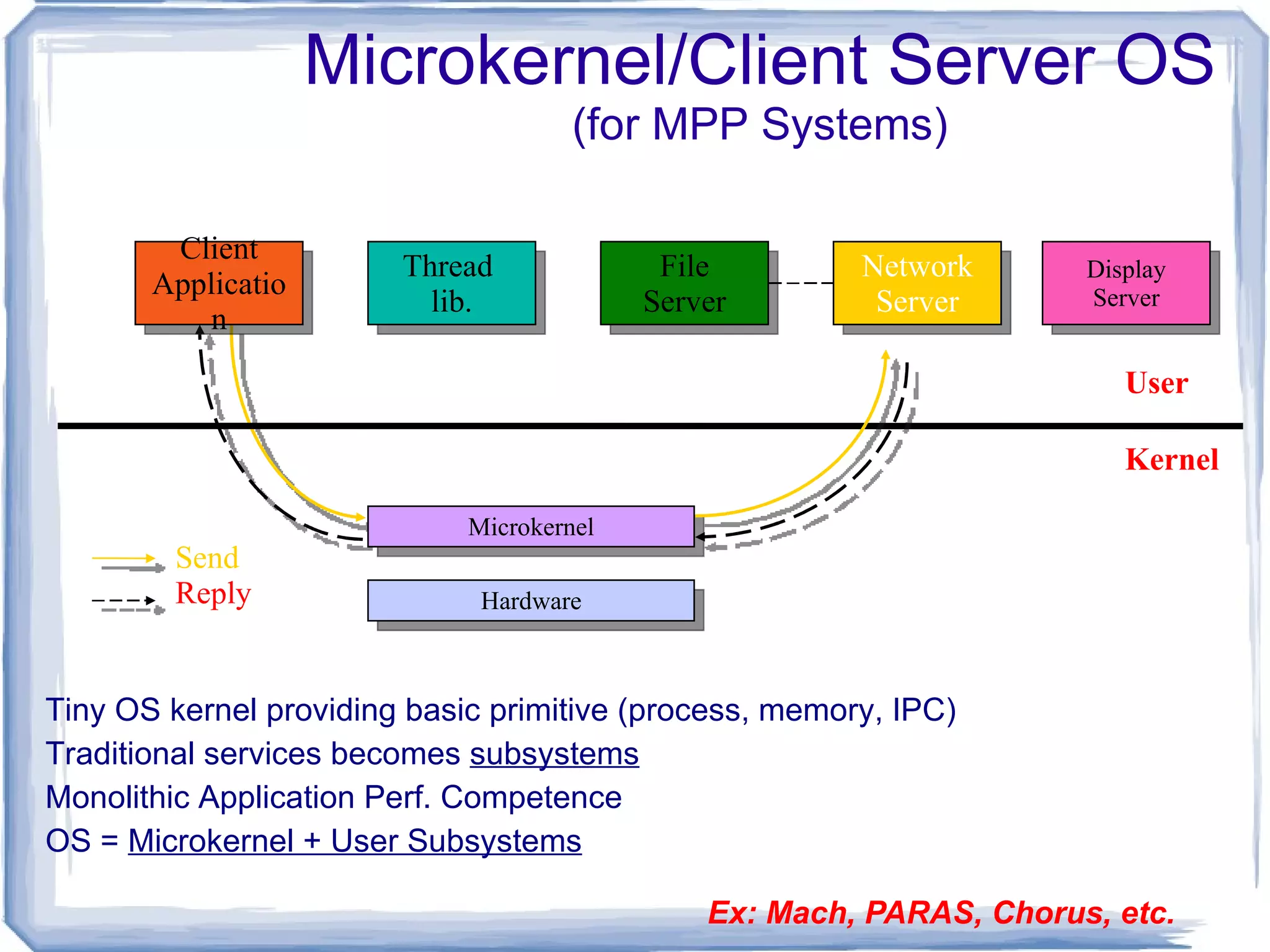
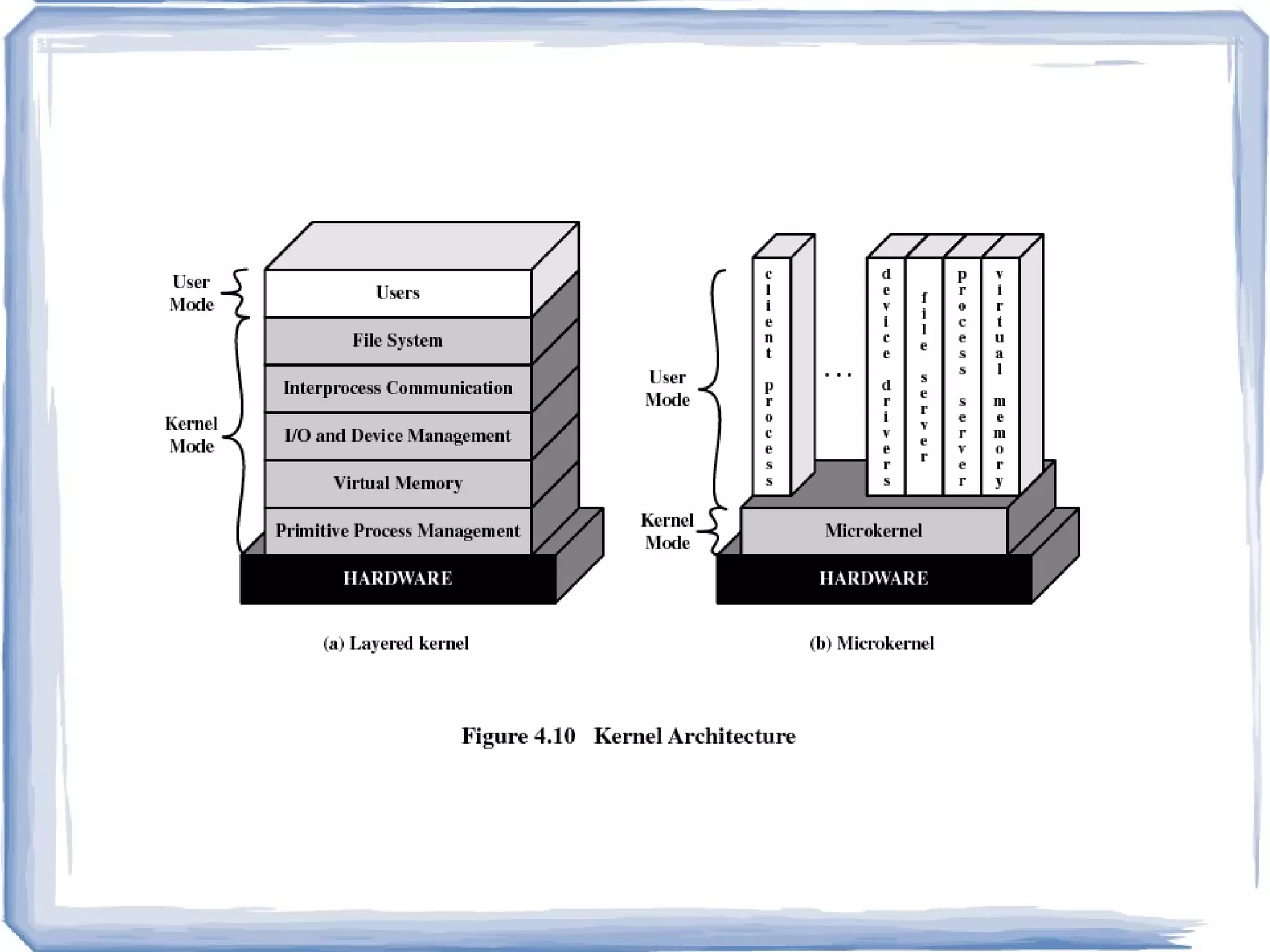
Microkernel based OS Client server OS Suitable for MPP systems Simplicity, flexibility and high performance are crucial for OS. Operating System Models
OS = Microkernel + User Subsystems Client Application Thread lib. File Server Network Server Display Server Microkernel Hardware Send Reply Ex: Mach, PARAS, Chorus, etc. User Kernel
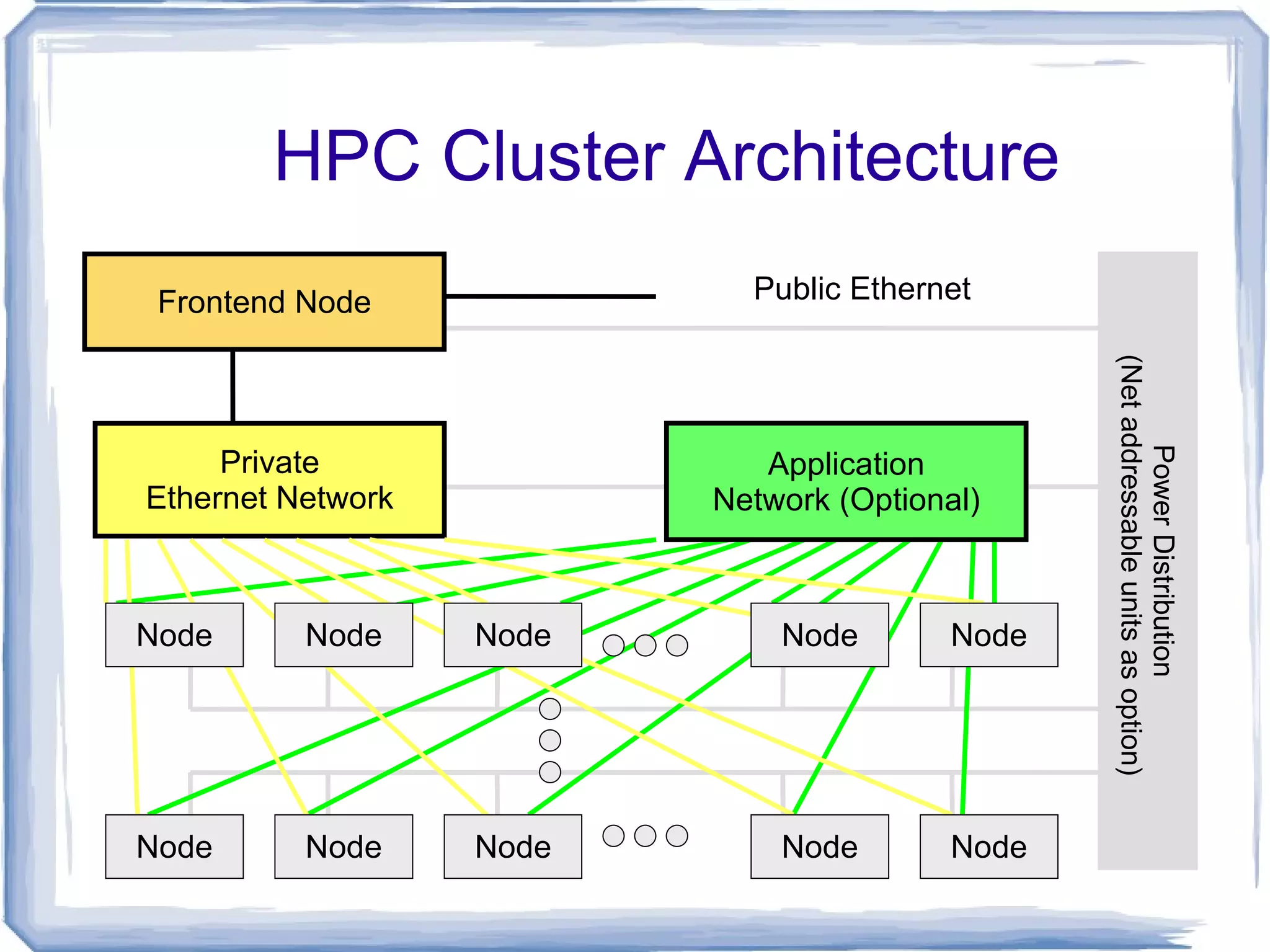
HPC Cluster ArchitectureFrontend Node Public Ethernet Private Ethernet Network Application Network (Optional) Power Distribution (Net addressable units as option) Node Node Node Node Node Node Node Node Node Node
94.
Most Critical Problemswith Clusters The largest problem in clusters is software skew When software configuration on some nodes is different than on others
95.
Small differences (minorversion numbers on libraries) can cripple a parallel program The second most important problem is lack of adequate job control of the parallel process Signal propagation
Top 3 Problemswith Software Packages Software installation works only in interactive mode Need a significant work by end-user Often rational default settings are not available Extremely time consuming to provide values
98.
Should be providedby package developers but … Package is required to be installed on a running system Means multi-step operation: install + update
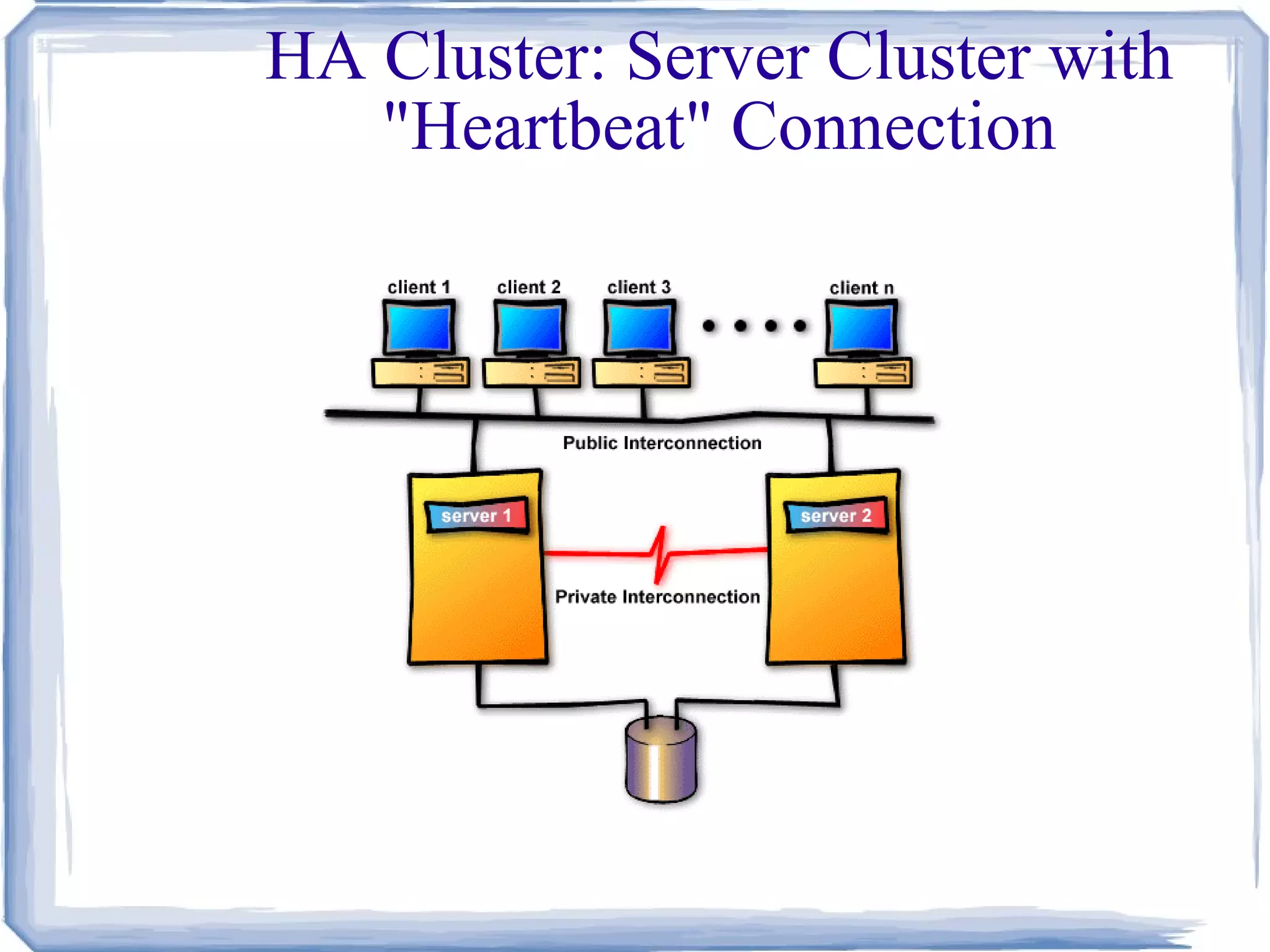
Clusters Classification..1 Basedon Focus (in Market) High Performance (HP) Clusters Grand Challenging Applications High Availability (HA) Clusters Mission Critical applications
Clusters Classification..5 Basedon Processor Arch, Node Type Homogeneous Clusters All nodes will have similar configuration Heterogeneous Clusters Nodes based on different processors and running different Operating Systems
Middleware Design GoalsComplete Transparency Lets the see a single cluster system.. Single entry point, ftp, telnet, software loading... Scalable Performance Easy growth of cluster no change of API & automatic load distribution. Enhanced Availability Automatic Recovery from failures Employ checkpointing & fault tolerant technologies Handle consistency of data when replicated..
125.
What is SingleSystem Image (SSI) ? A single system image is the illusion , created by software or hardware, that a collection of computing elements appear as a single computing resource. SSI makes the cluster appear like a single machine to the user, to applications, and to the network.
A receiver waitsuntil there is a message. Asynchronous Sender never blocks, even if infinitely many messages are waiting to be received
145.
Semi-asynchronous is apractical version of above with large but finite amount of buffering
146.
Message Passing: Pointto Point Q: send(m, P) Send message M to process P P: recv(x, Q) Receive message from process Q, and place it in variable x The message data Type of x must match that of m
Book: RobH. Bisseling, “Parallel Scientific Computation: A Structured Approach using BSP and MPI,” Oxford University Press, 2004, 324 pages, ISBN 0-19-852939-2.
178.
BSP Library Smallnumber of subroutines to implement process creation,
communicates with theExecution Servers (mom's) on the cluster to determine the current state of the nodes.
187.
When all ofthe needed are allocated, passes the .cmd on to the Execution Server on the first node allocated (the "mother superior"). Execution Server will login on the first node as the submitting user and run the .cmd file in the user's home directory.
A two tiertechnology Information gathering and dissemination Support scalable configurations by probabilistic dissemination algorithms
263.
Same overhead for16 nodes or 2056 nodes Pre-emptive process migration that can migrate any process, anywhere, anytime - transparently Supervised by adaptive algorithms that respond to global resource availability
Tier 1: Informationgathering and dissemination In each unit of time (e.g., 1 second) each node gathers information about: CPU(s) speed, load and utilization
Tier 2: Processmigration Load balancing: reduce variance between pairs of nodes to improve the overall performance
270.
Memory ushering: migrateprocesses from a node that nearly exhausted its free memory, to prevent paging
271.
Parallel FileI/O: bring the process to the file-server, direct file I/O from migrated processes
272.
Network transparency Theuser and applications are provided a virtual machine that looks like a single machine.
273.
Example: Disk accessfrom diskless nodes on fileserver is completely transparent to programs
274.
Preemptive process migrationAny user’s process, trasparently and at any time, can/may migrate to any other node.
275.
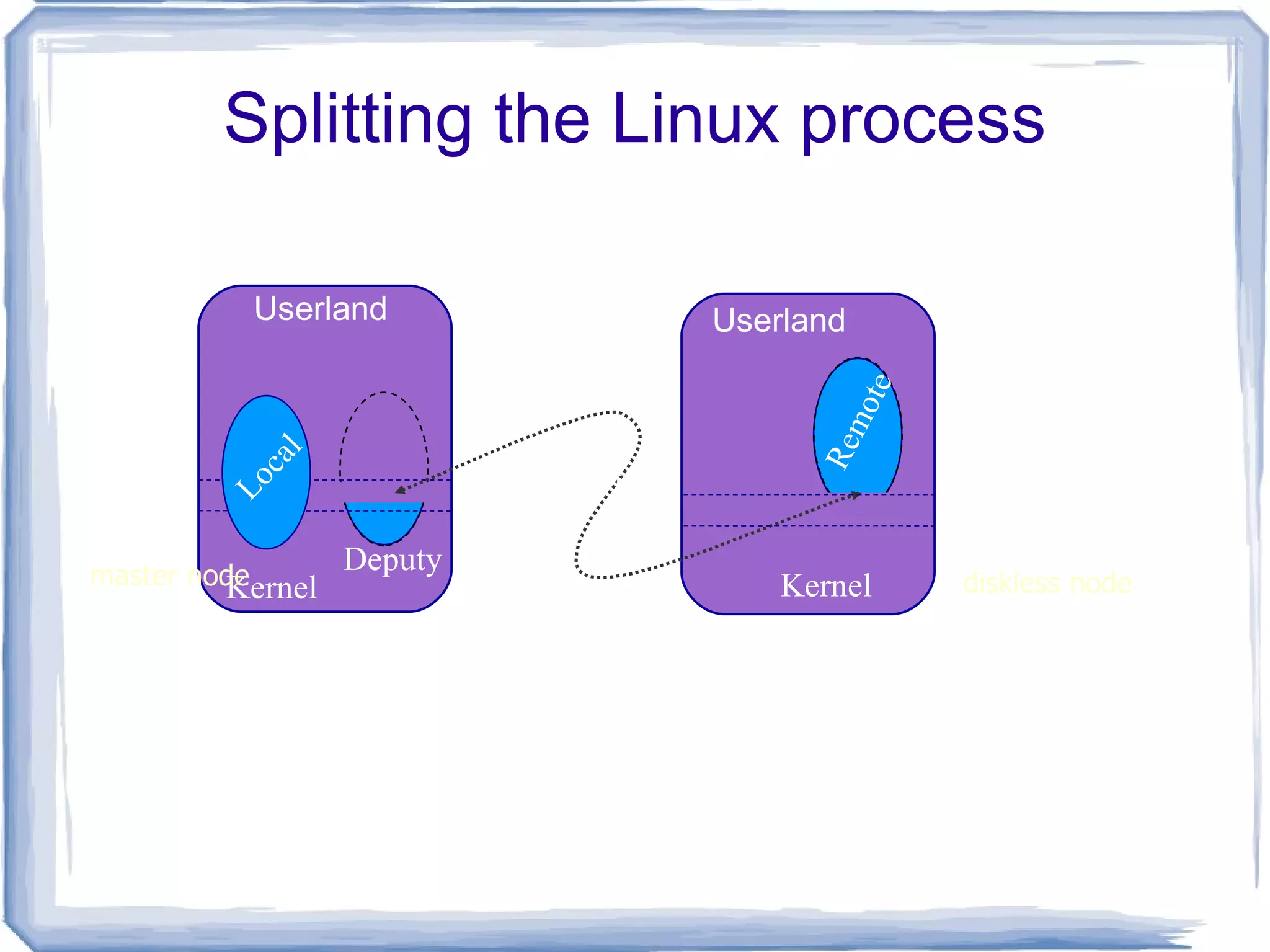
The migrating processis divided into: system context ( deputy ) that may not be migrated from home workstation (UHN);
276.
user context (remote ) that can be migrated on a diskless node;
277.
Splitting the Linuxprocess System context (environment) - site dependent- “home” confined
278.
Connected by anexclusive link for both synchronous (system calls) and asynchronous (signals, MOSIX events)
279.
Process context (code,stack, data) - site independent - may migrate Deputy Remote Kernel Kernel Userland Userland openMOSIX Link Local master node diskless node
What Is CORBA?More specifically: “ ( CORBA ) is a standard defined by the Object Management Group (OMG) that enables software components written in multiple computer languages and running on multiple computers to work together ” (1)
Request services fromServant object Invoke a method call Can exist on a different computer from Servant Can also exist on same computer, or even within the same program, as the Servant Implemented by Software Developer
ORB’s and POA’sORB: Object Request Broker The “ORB” in “CORBA” At the heart of CORBA Enables communication
316.
Implemented by ORBVendor An organization that implements the CORBA Specification (a company, a University, etc.) Can be viewed as an API/Framework Set of classes and method Used by Clients and Servers to properly setup communication Client and Server ORB’s communicate over a network
ORB’s and POA’sPOA: Portable Object Adapter A central CORBA goal: Programs using different ORB’s (provided by different ORB Vendors) can still communicate
Can be viewedas an API/Framework Set of classes and method Sits between ORB’s and Servants Glue between Servants and ORBs Job is to: Receive messages from ORB’s
Language independent fromTarget Language Allows Client and Server applications to be written in different (several) languages A “contract” between Clients and Servers Both MUST have the exact same IDL
326.
Specifies messages anddata that can be sent by Clients and received by Servants Written by Software Developer
327.
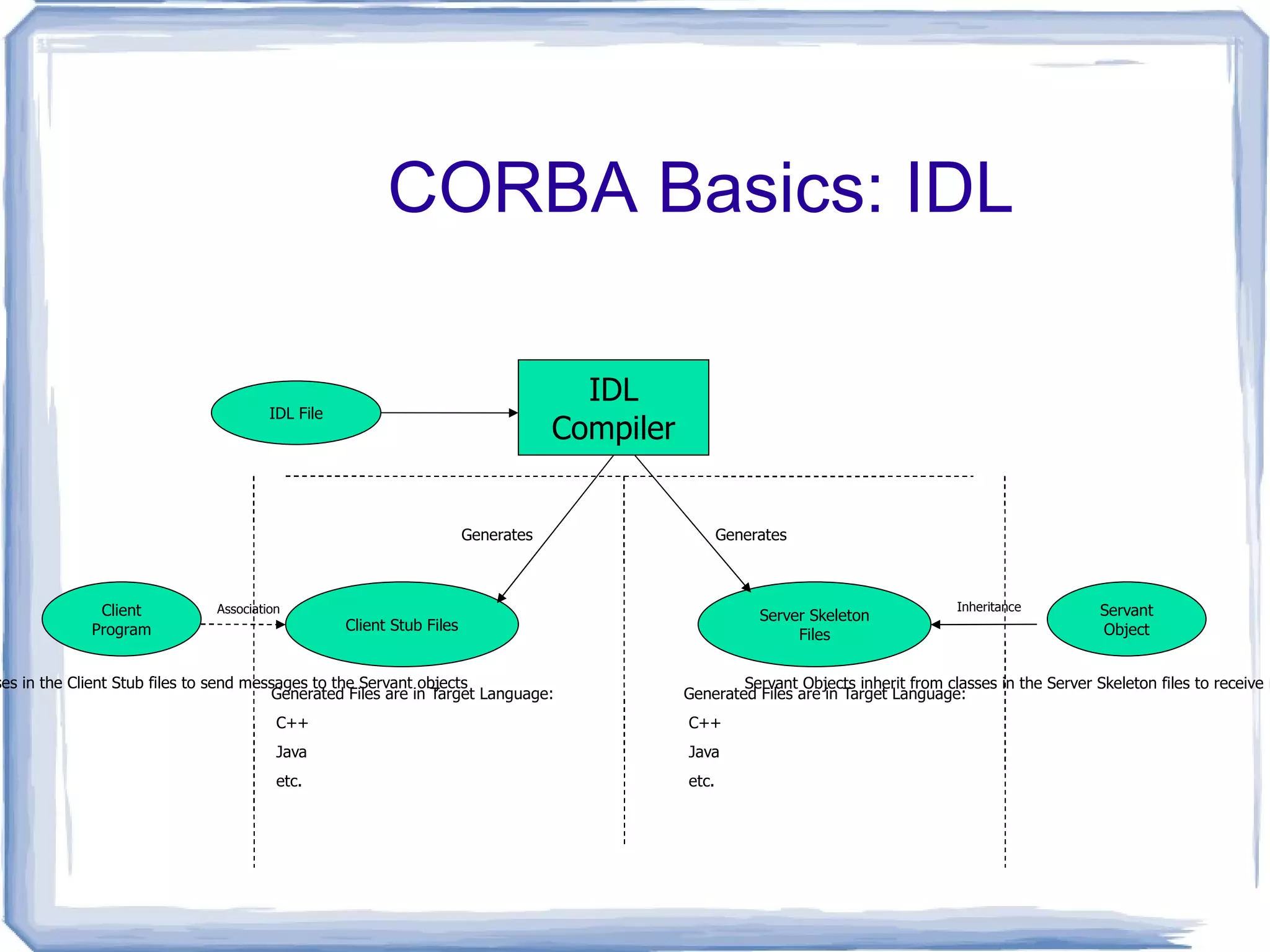
CORBA Basics: IDLUsed to define interfaces (i.e. Servants) Classes and methods that provide services IDL Provides… Primitive Data Types (int, float, boolean, char, string)
CORBA Basics: IDLIDL Compilers Converts IDL files to target language files
332.
Done via LanguageMappings Useful to understand your Language Mapping scheme Target language files contain all the implementation code that facilitates CORBA-based communication More or less “hides” the details from you Creates client “stubs” and Server “skeletons”
etc. Client Programsused the classes in the Client Stub files to send messages to the Servant objects Client Program Servant Object Servant Objects inherit from classes in the Server Skeleton files to receive messages from the Client programs Association Inheritance
339.
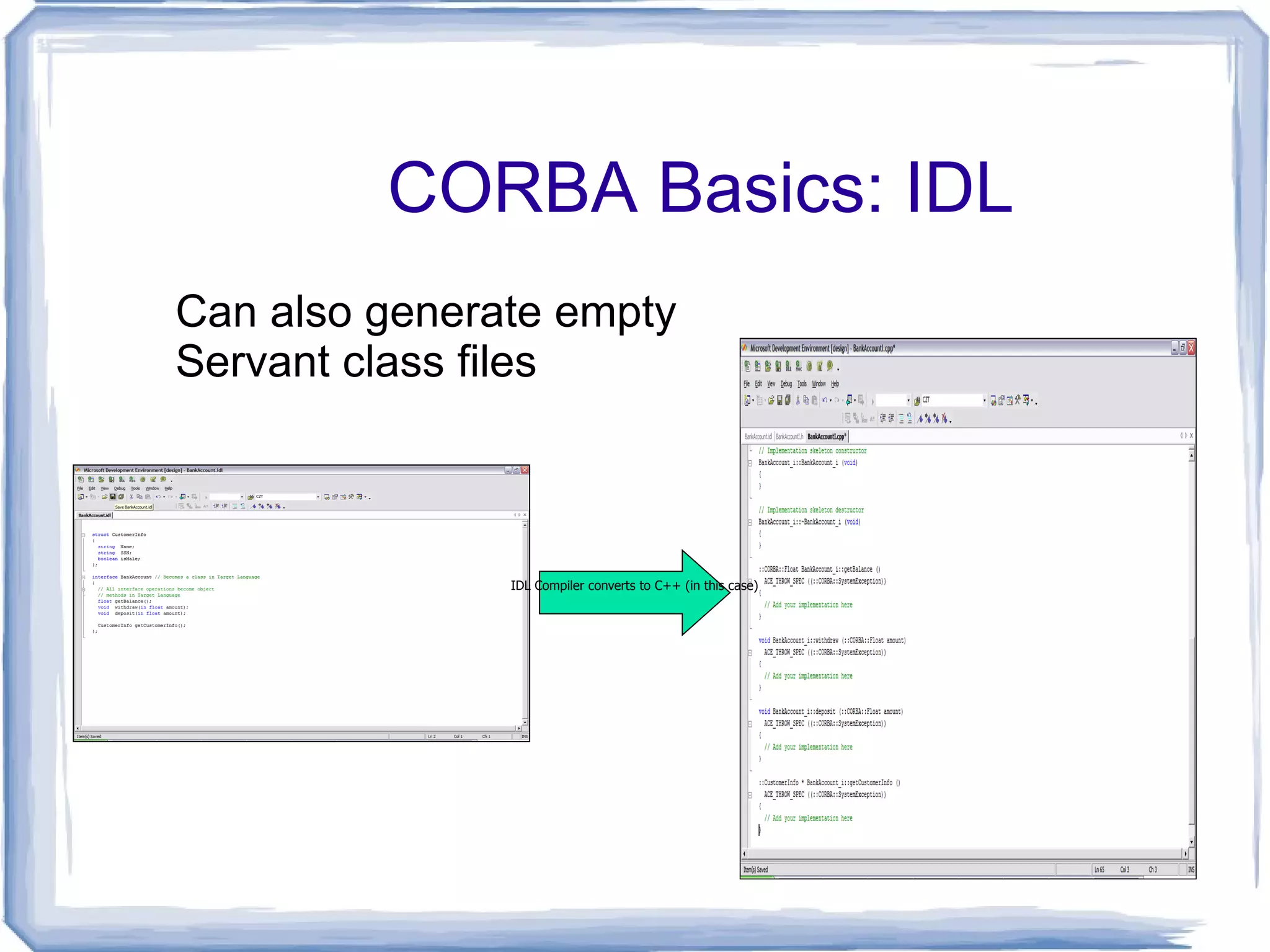
CORBA Basics: IDLCan also generate empty Servant class files IDL Compiler converts to C++ (in this case)
340.
CORBA Basics: IOR’sIOR: Interoperable Object Reference Can be thought of as a “Distributed Pointer”
Used by ORB’sand POA’s to locate Servants For Clients, used to find Servants across networks
343.
For Servers, usedto find proper Servant running within the application Opaque to Client and Server applications Only meaningful to ORB’s and POA’s
344.
Contains information aboutIP Address, Port Numbers, networking protocols used, etc. The difficult part is obtaining them This is the purpose/reasoning behind developing and using CORBA Services
345.
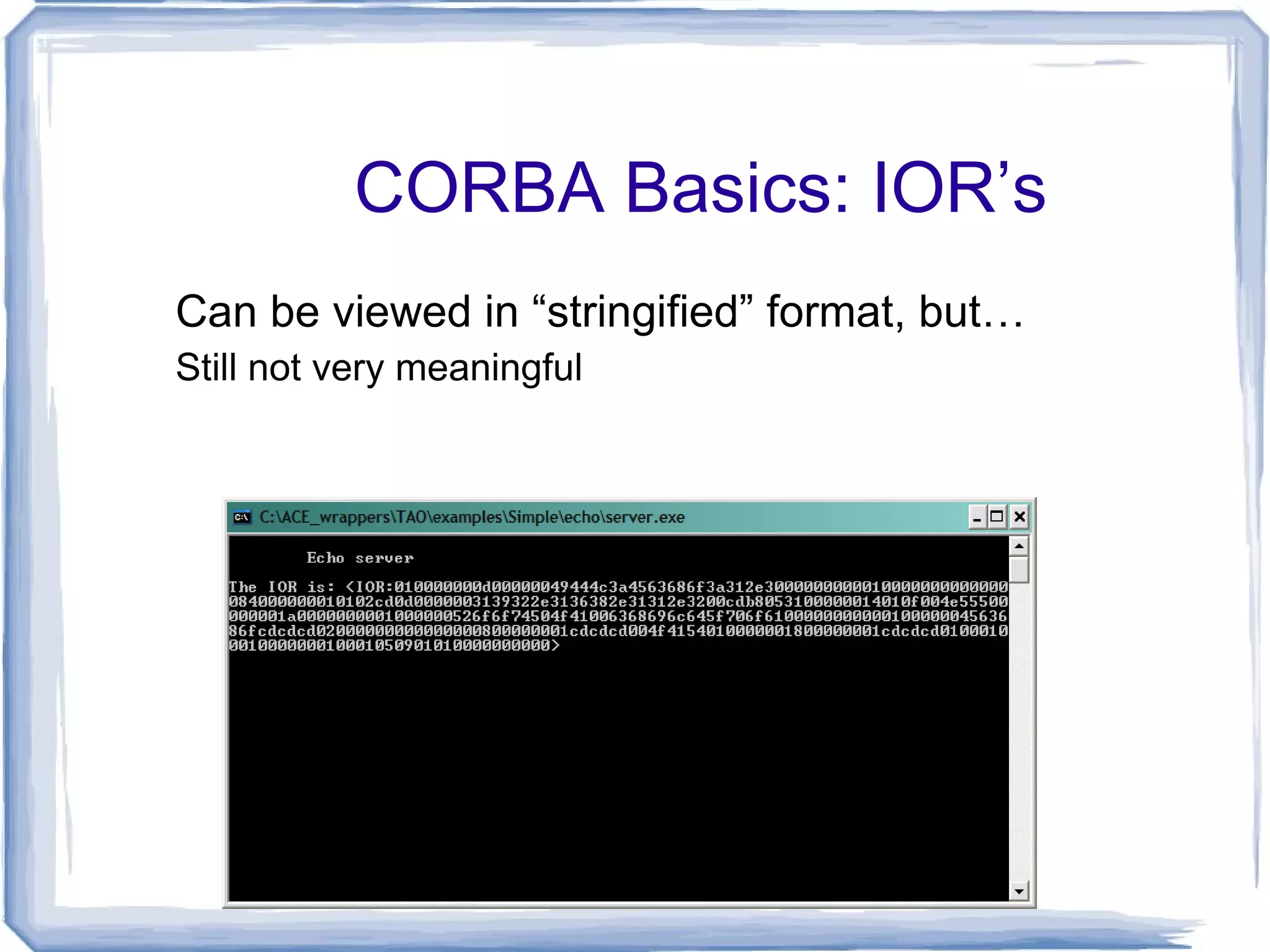
CORBA Basics: IOR’sCan be viewed in “stringified” format, but… Still not very meaningful
346.
CORBA Basics: IOR’sStandardized, to some degree: … … Standardized by the OMG: Used by Client side ORB’s to locate Server side (destination) ORB’s
347.
Contains information neededto make physical connection NOT Standardized by the OMG; proprietary to ORB Vendors Used by Server side ORB’s and POA’s to locate destination Servants
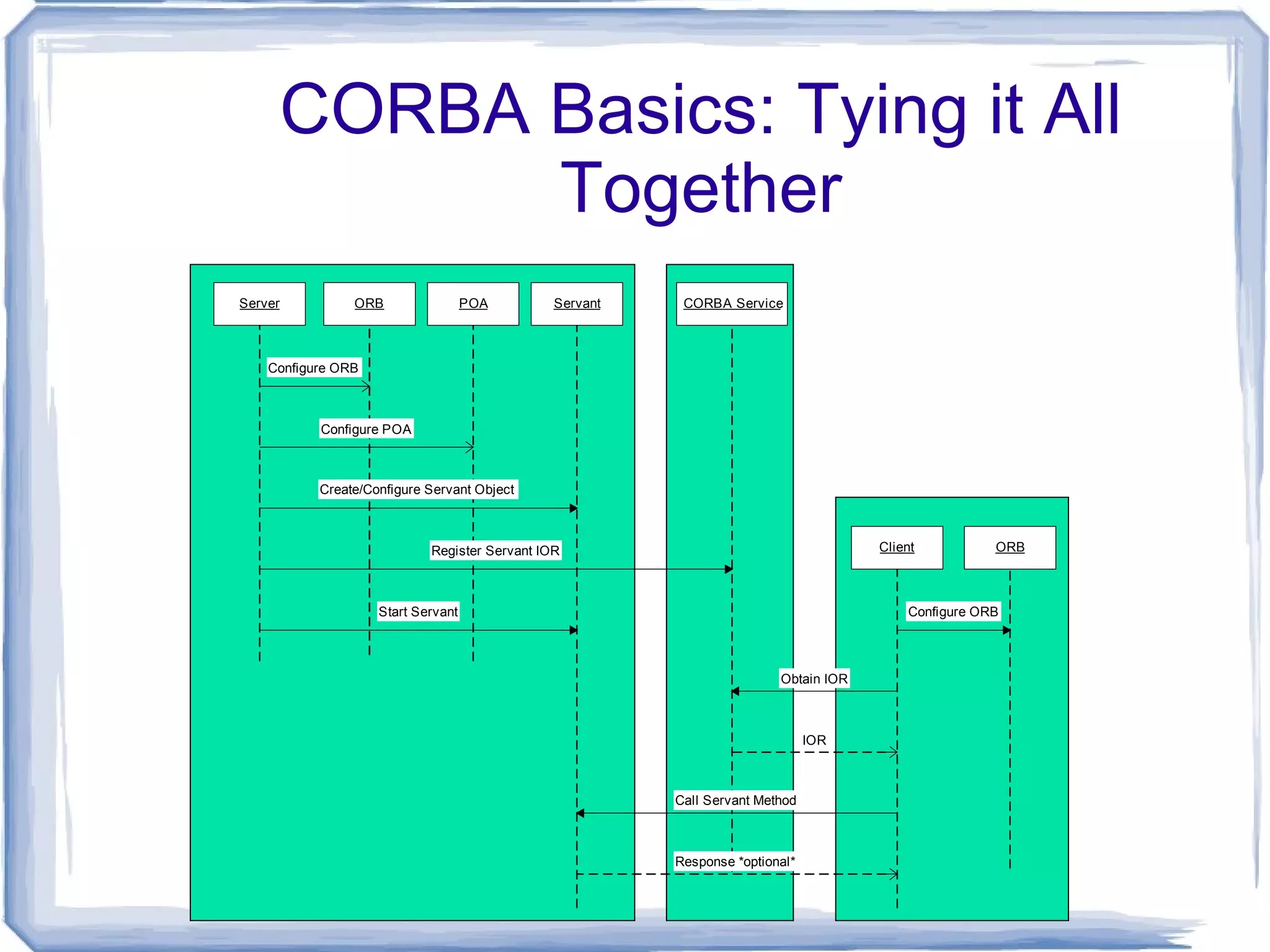
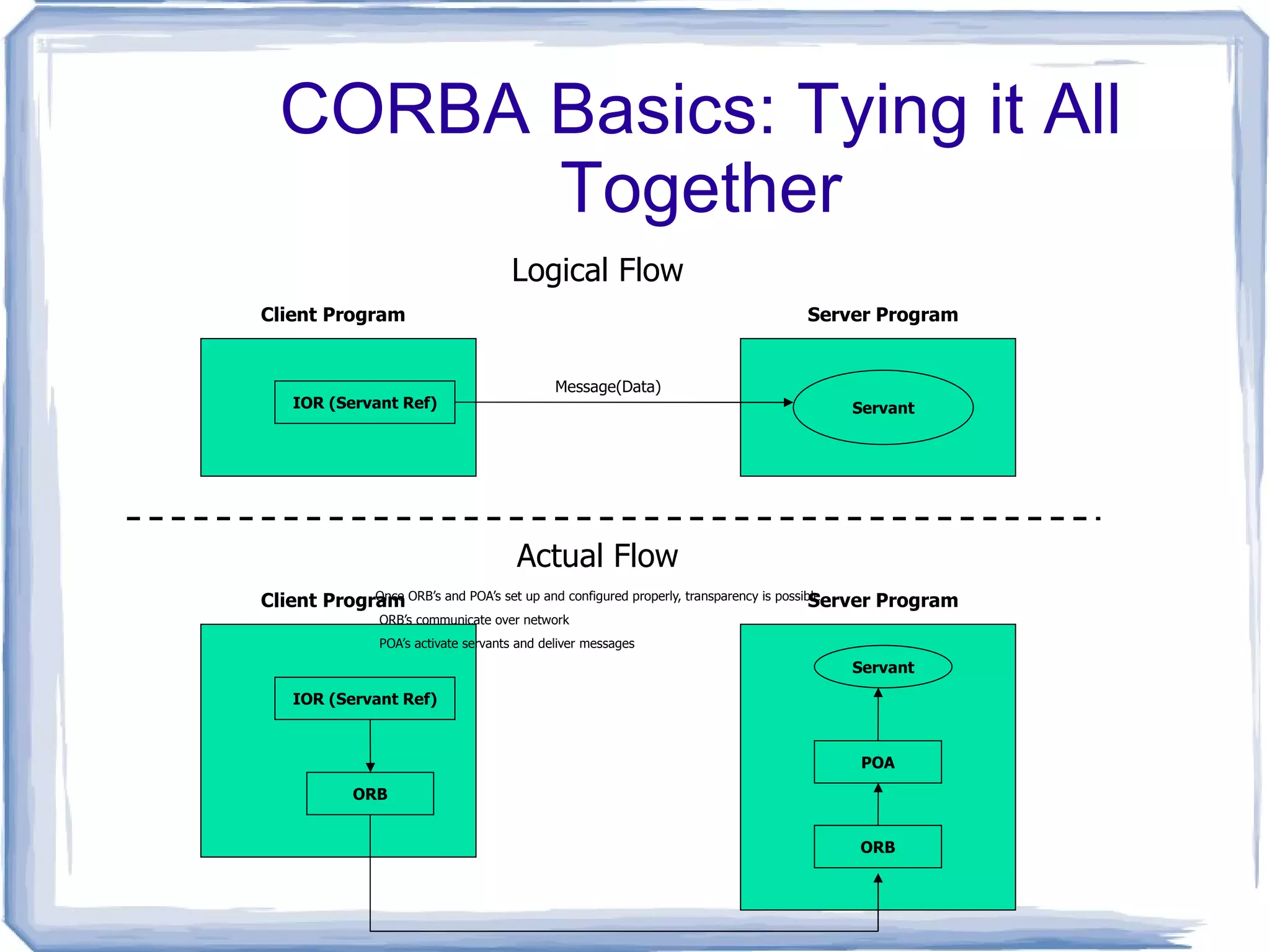
CORBA Basics: Tyingit All Together Client Program IOR (Servant Ref) Server Program Servant Message(Data) Logical Flow Client Program Server Program Servant Actual Flow POA ORB IOR (Servant Ref) ORB Once ORB’s and POA’s set up and configured properly, transparency is possible ORB’s communicate over network
CORBA Services: TheNaming Service The CORBA Naming Service is similar to the White Pages (phone book)
359.
Servants place their“names,” along with their IOR’s, into the Naming Service The Naming Service stores these as pairs Later, Clients obtain IOR’s from the Naming Service by passing the name of the Servant object to it The Naming Service returns the IOR Clients may then use to make requests
360.
CORBA Services: TheTrading Service The CORBA Naming Service is similar to the Yellow Pages (phone book)
361.
Servants place adescription of the services they can provide (i.e. their “Trades”), along with their IOR’s, into the Trading Services The Trading Service stores these Clients obtain IOR’s from the Trading Service by passing the type(s) of Services they require The Trading Service returns an IOR Clients may then use to make requests
Gridware can beviewed as a special type of middleware that enable sharing and manage grid components based on user requirements and resource attributes (e.g., capacity, performance, availability…)
High-Throughput Computing Usesthe grid to schedule large numbers of loosely coupled or independent tasks, with the goal of putting unused processor cycles to work.
390.
On-Demand Computing Usesgrid capabilities to meet short-term requirements for resources that are not locally accessible.
Data-Intensive Computing Thefocus is on synthesizing new information from data that is maintained in geographically distributed repositories, digital libraries, and databases.
Globus A collaborationof Argonne National Laboratory’s Mathematics and Computer Science Division, the University of Southern California’s Information Sciences Institute, and the University of Chicago's Distributed Systems Laboratory.
Globus A projectto develop the underlying technologies needed for the construction of computational grids.
402.
Focuses on executionenvironments for integrating widely-distributed computational platforms, data resources, displays, special instruments and so forth.
403.
The Globus ToolkitThe Globus Resource Allocation Manager (GRAM) Creates, monitors, and manages services.
404.
Maps requests tolocal schedulers and computers. The Grid Security Infrastructure (GSI) Provides authentication services.
405.
The Globus ToolkitThe Monitoring and Discovery Service (MDS) Provides information about system status, including server configurations, network status, and locations of replicated datasets, etc. Nexus and globus_io provides communication services for heterogeneous environments.
406.
What are Clouds?Clouds are “Virtual Clusters” (“Virtual Grids”) of possibly “Virtual Machines” They may cross administrative domains or may “just be a single cluster”; the user cannot and does not want to know Clouds support access (lease of) computer instances Instances accept data and job descriptions (code) and return results that are data and status flags Each Cloud is a “Narrow” (perhaps internally proprietary) Grid
Virtualization and CloudComputing The Virtues of Virtualization Portable environments, enforcement and isolation, fast to deploy, suspend/resume, migration… Cloud computing SaaS: software as a service
Community example: IUhosting environment (quarry) Virtual Workspaces: http//workspace.globus.org
420.
Technical Questions onClouds How is data compute affinity tackled in clouds? Co-locate data and compute clouds?
421.
Lots of opticalfiber i.e. “just” move the data? What happens in clouds when demand for resources exceeds capacity – is there a multi-day job input queue? Are there novel cloud scheduling issues? Do we want to link clouds (or ensembles as atomic clouds); if so how and with what protocols
422.
Is there anintranet cloud e.g. “cloud in a box” software to manage personal (cores on my future 128 core laptop) department or enterprise cloud?
423.
Thanks Much.. 99%of the slides are taken from the Internet from various Authors. Thanks to all of them!