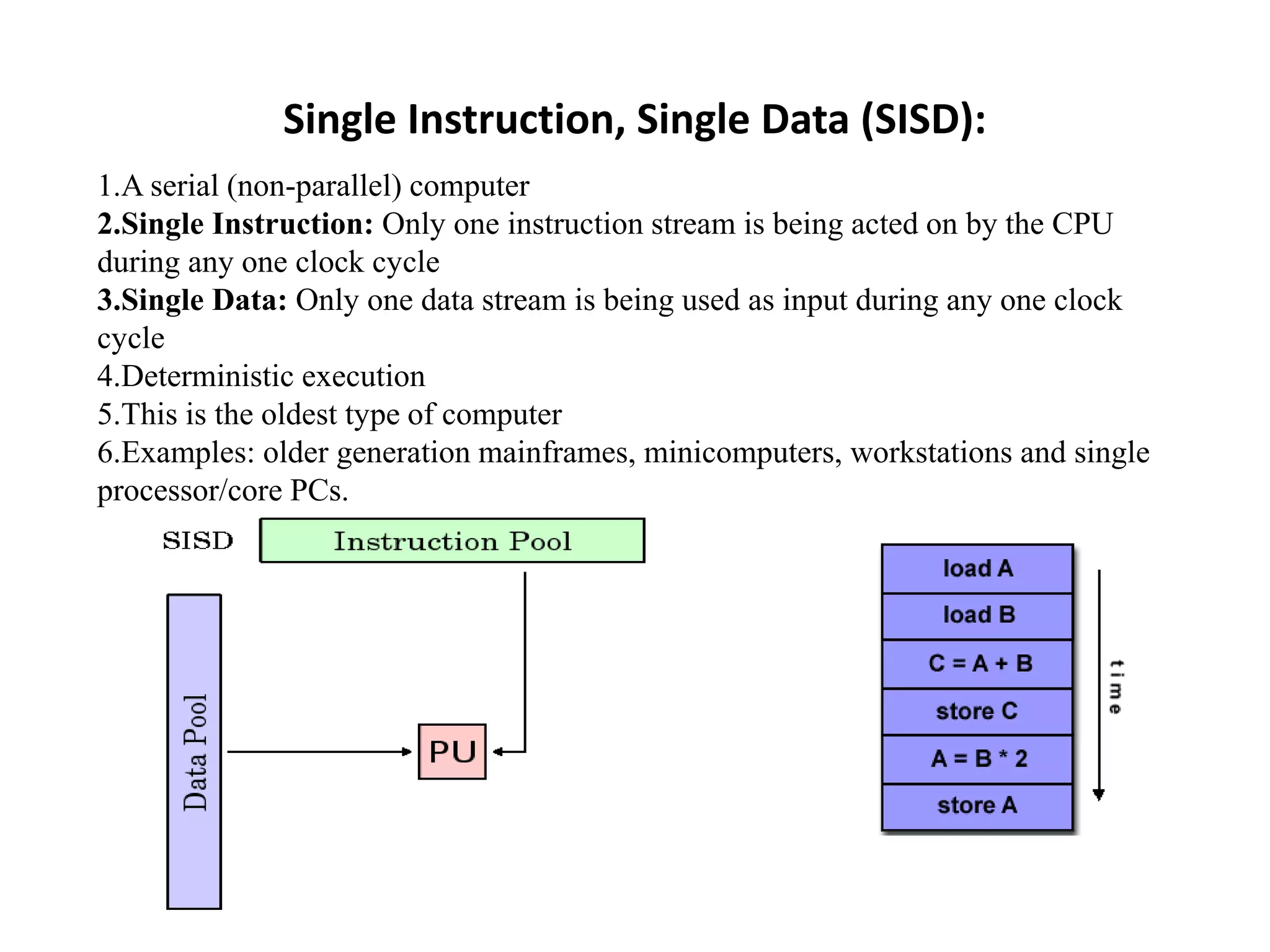
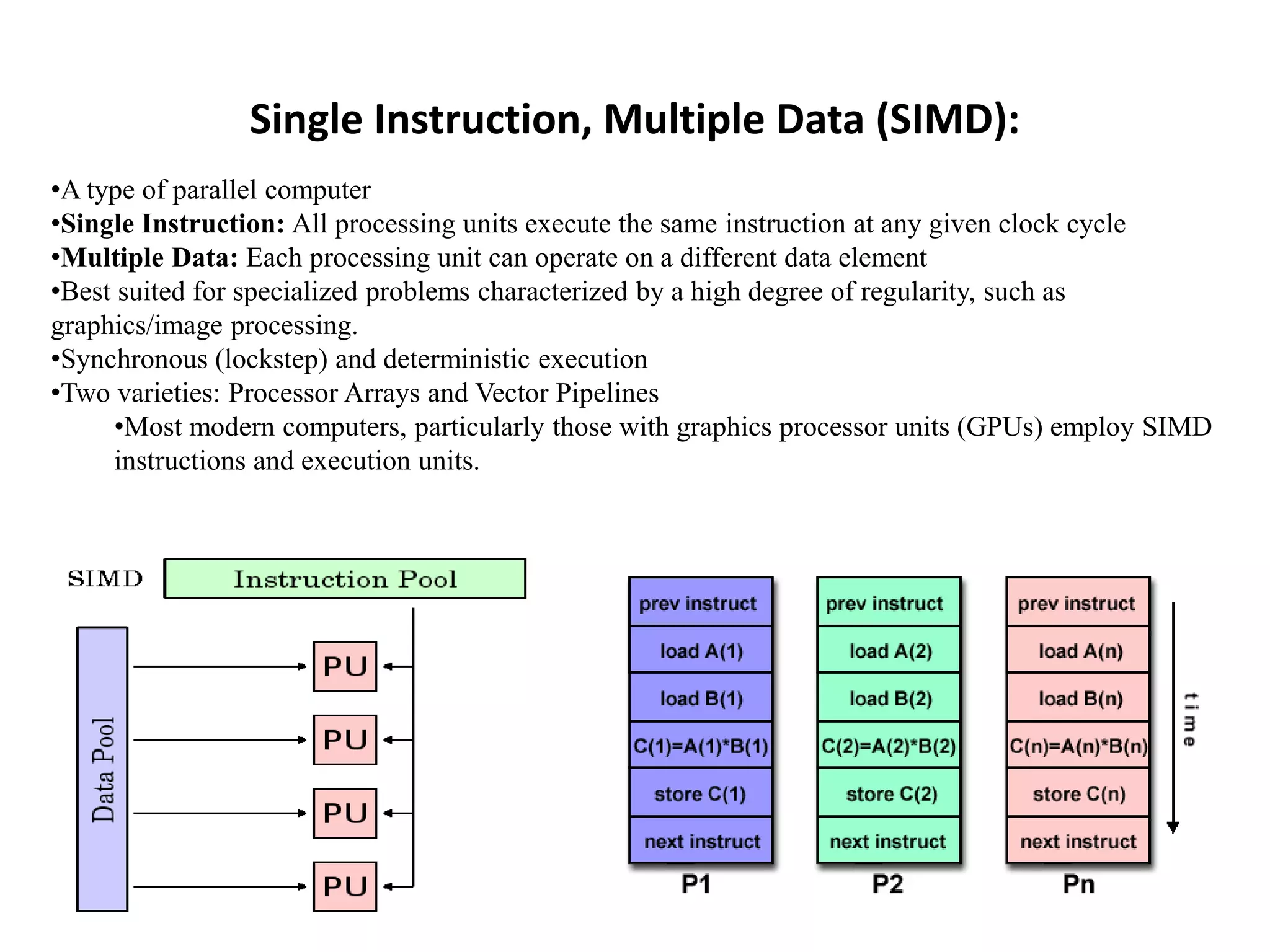
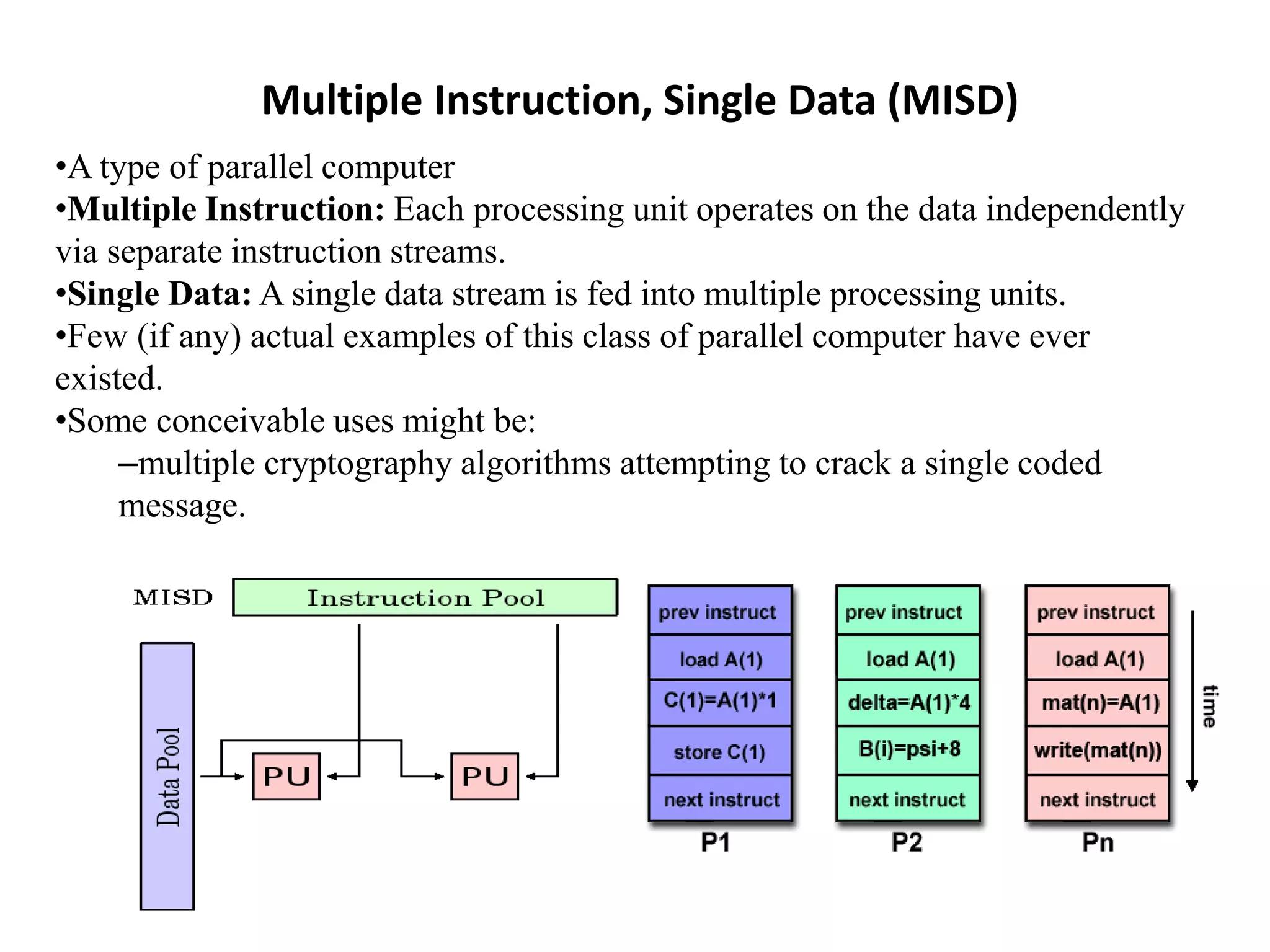
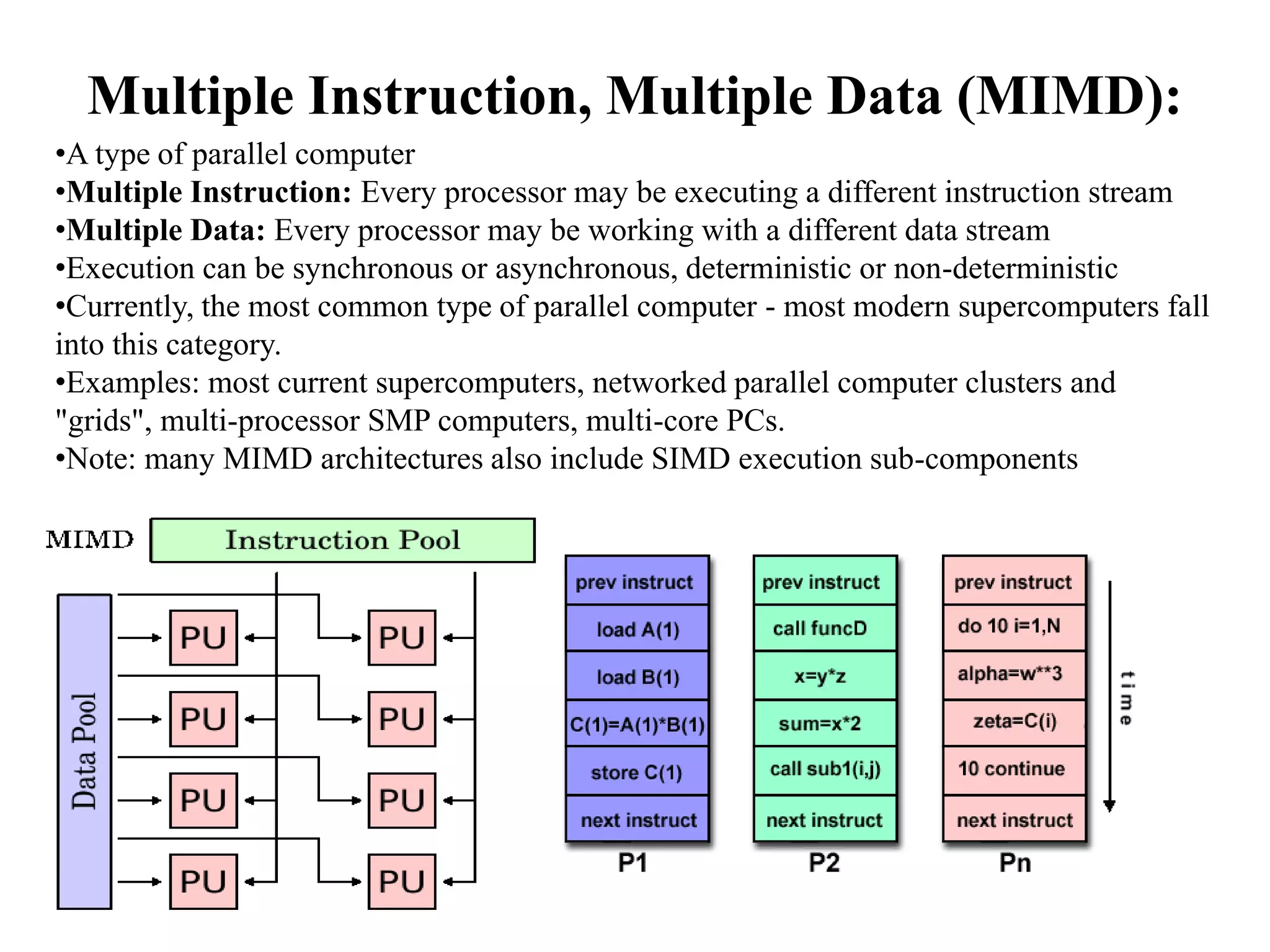
This document discusses parallel computing architectures and concepts. It begins by describing Von Neumann architecture and how parallel computers follow the same basic design but with multiple units. It then covers Flynn's taxonomy which classifies computers based on their instruction and data streams as Single Instruction Single Data (SISD), Single Instruction Multiple Data (SIMD), Multiple Instruction Single Data (MISD), or Multiple Instruction Multiple Data (MIMD). Each classification is defined. The document also discusses parallel terminology, synchronization, scalability, and Amdahl's law on the costs and limits of parallel programming.