













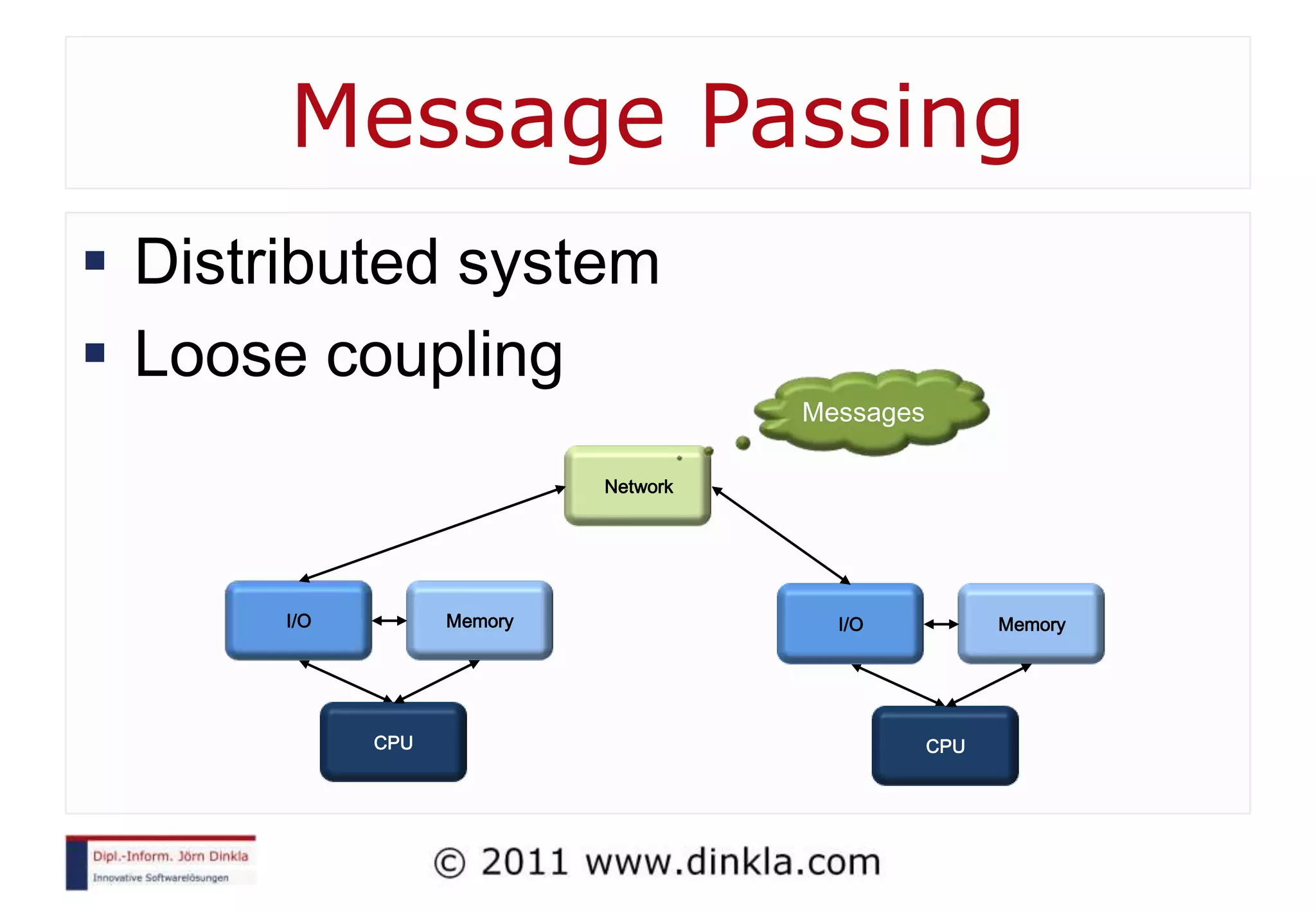

![Sequential Algorithms Random Access Machine (RAM) Step by step, deterministic Addr Value 0 3 PC int sum = 0 1 2 7 5 for i=0 to 4 3 1 4 2 sum += mem[i] 5 18 mem[5]= sum](https://image.slidesharecdn.com/introductiontoparallelcomputing-111212063757-phpapp02/75/Introduction-To-Parallel-Computing-23-2048.jpg)
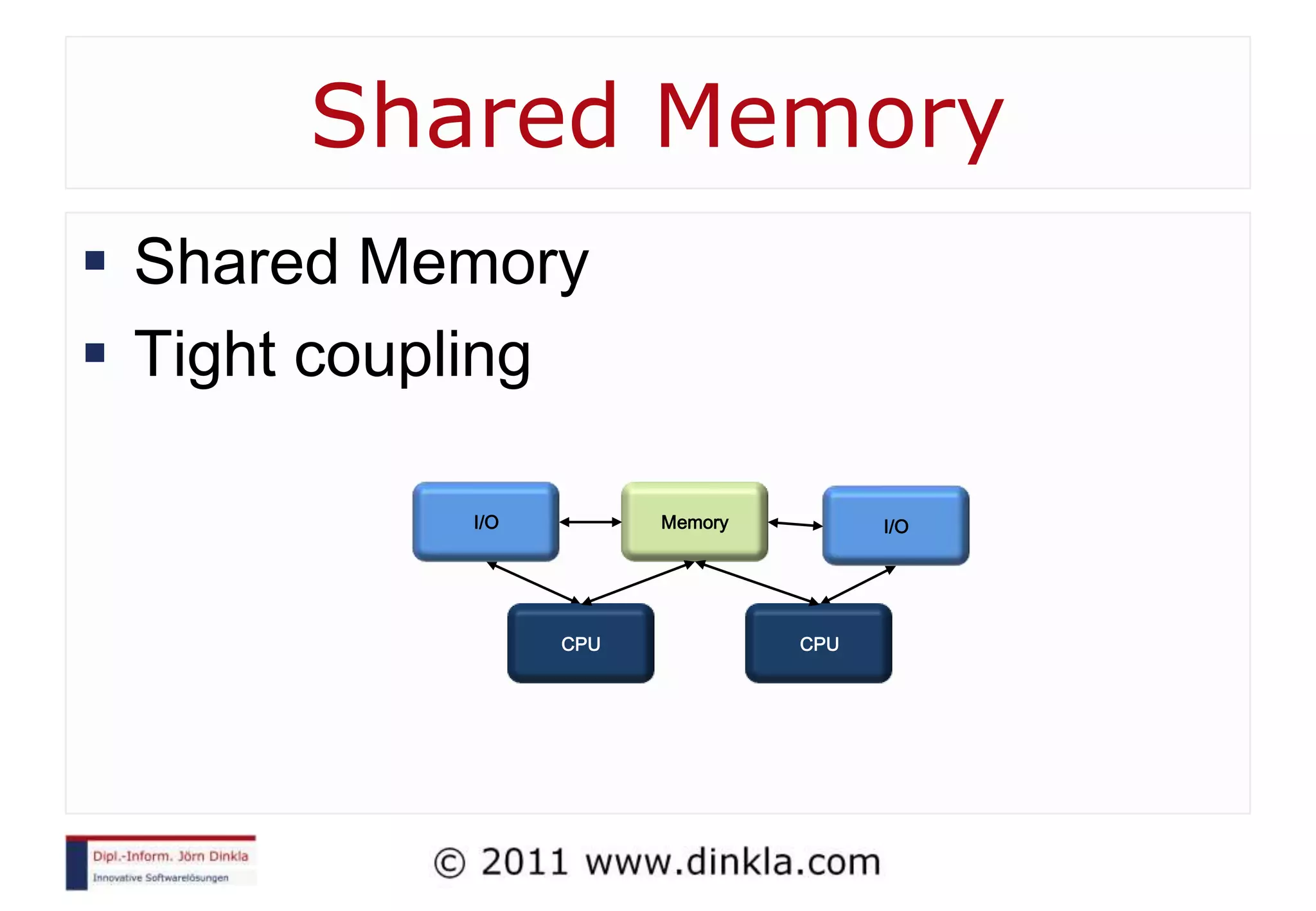
![Sequential Algorithms int sum = 0 for i=0 to 4 sum += mem[i] Addr Value Addr Value Addr Value Addr Value Addr Value Addr Value 0 3 0 3 0 3 0 3 0 3 0 3 1 7 1 7 1 7 1 7 1 7 1 7 2 5 2 5 2 5 2 5 2 5 2 5 3 1 3 1 3 1 3 1 3 1 3 1 4 2 4 2 4 2 4 2 4 2 4 2 5 0 5 3 5 10 5 15 5 16 5 18](https://image.slidesharecdn.com/introductiontoparallelcomputing-111212063757-phpapp02/75/Introduction-To-Parallel-Computing-24-2048.jpg)

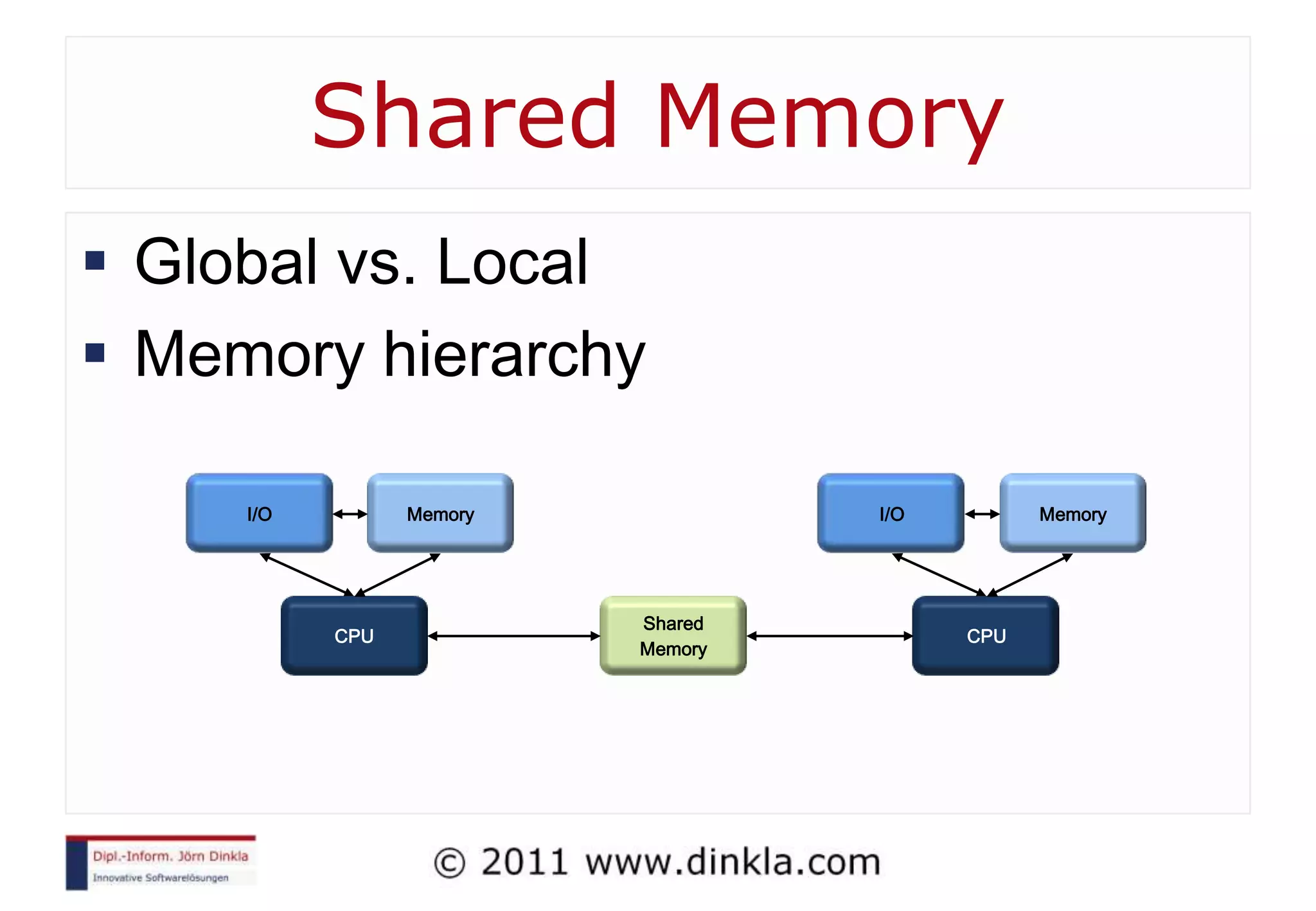
![Two Processors PC 1 int sum = 0 int sum = 0 for i=0 to 2 PC 2 for i=3 to 4 sum += mem[i] sum += mem[i] mem[5]= sum mem[5]= sum Addr Value 0 3 Lockstep 1 2 7 5 Memory Access! 3 4 1 2 5 18](https://image.slidesharecdn.com/introductiontoparallelcomputing-111212063757-phpapp02/75/Introduction-To-Parallel-Computing-26-2048.jpg)














![Problems: Shared Memory PC 1 int sum = 0 int sum = 0 for i=0 to 2 PC 2 for i=3 to 4 sum += mem[i] sum += mem[i] mem[5]= sum mem[5]= sum Addr Value 0 3 Which one first? 1 2 7 5 3 1 4 2 5 18](https://image.slidesharecdn.com/introductiontoparallelcomputing-111212063757-phpapp02/75/Introduction-To-Parallel-Computing-41-2048.jpg)
![Problems: Shared Memory PC 1 int sum = 0 int sum = 0 for i=0 to 2 PC 2 for i=3 to 4 sum += mem[i] sum += mem[i] mem[5]= sum sync() sync() mem[5] += sum Synchronization needed](https://image.slidesharecdn.com/introductiontoparallelcomputing-111212063757-phpapp02/75/Introduction-To-Parallel-Computing-42-2048.jpg)








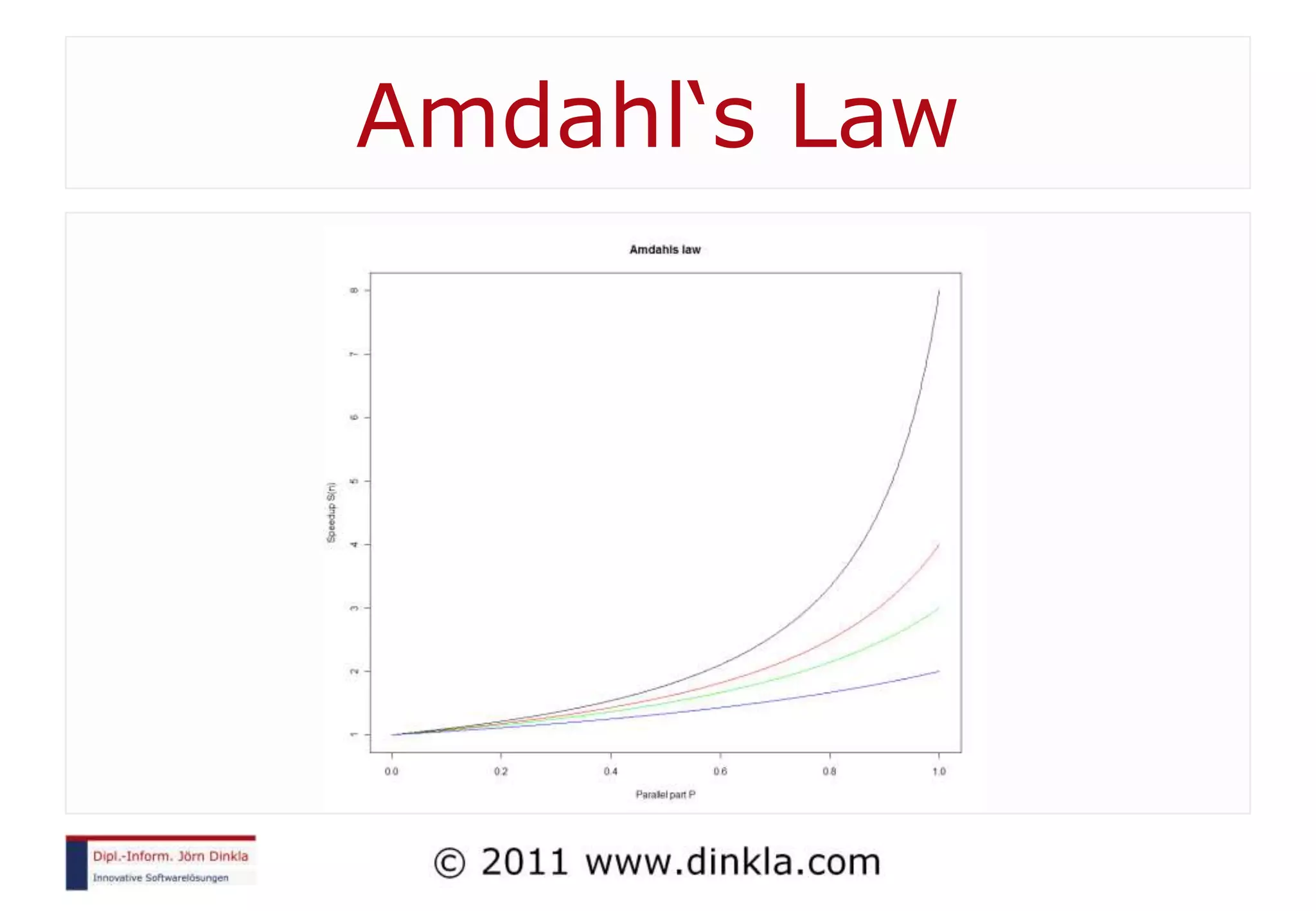








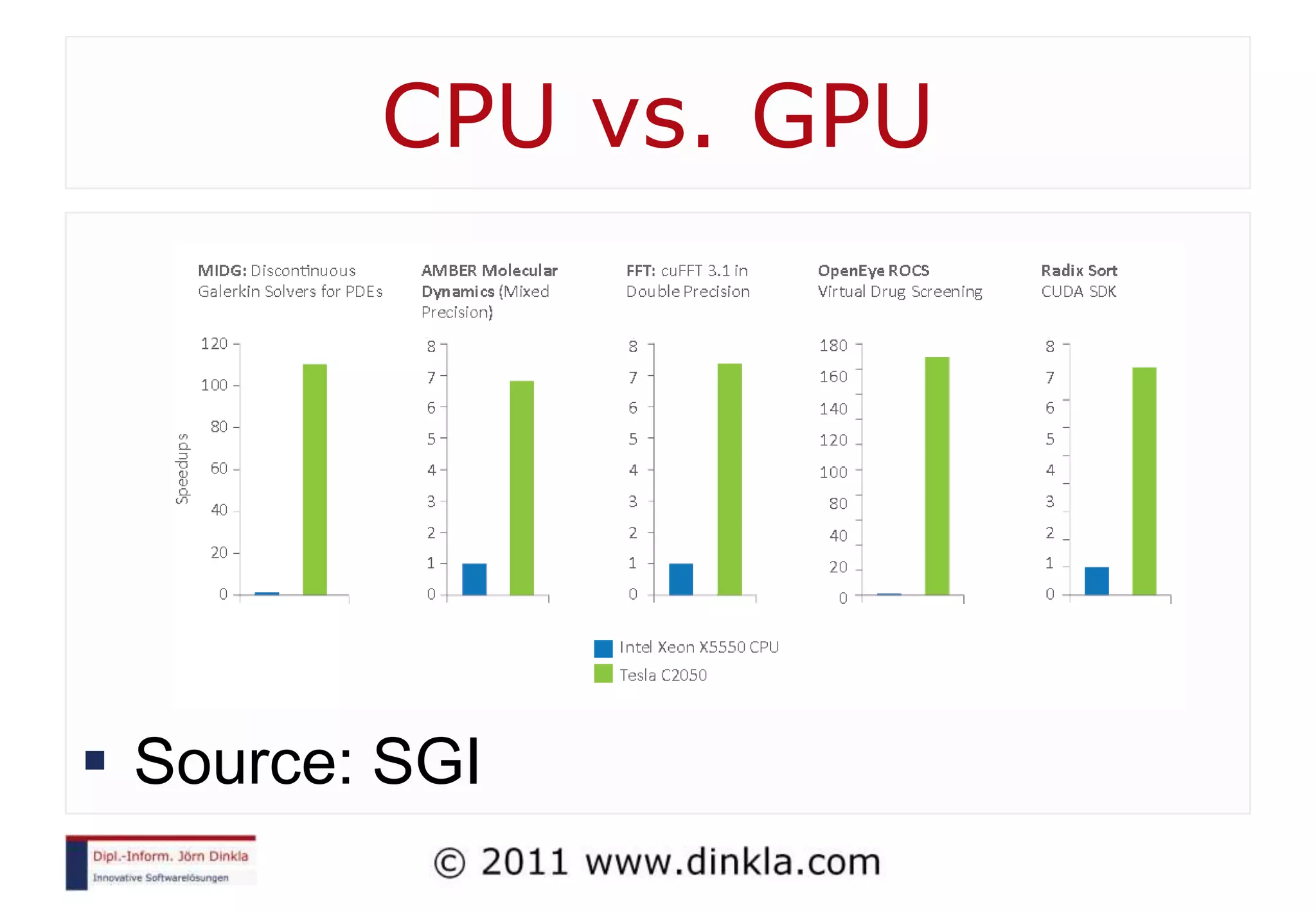

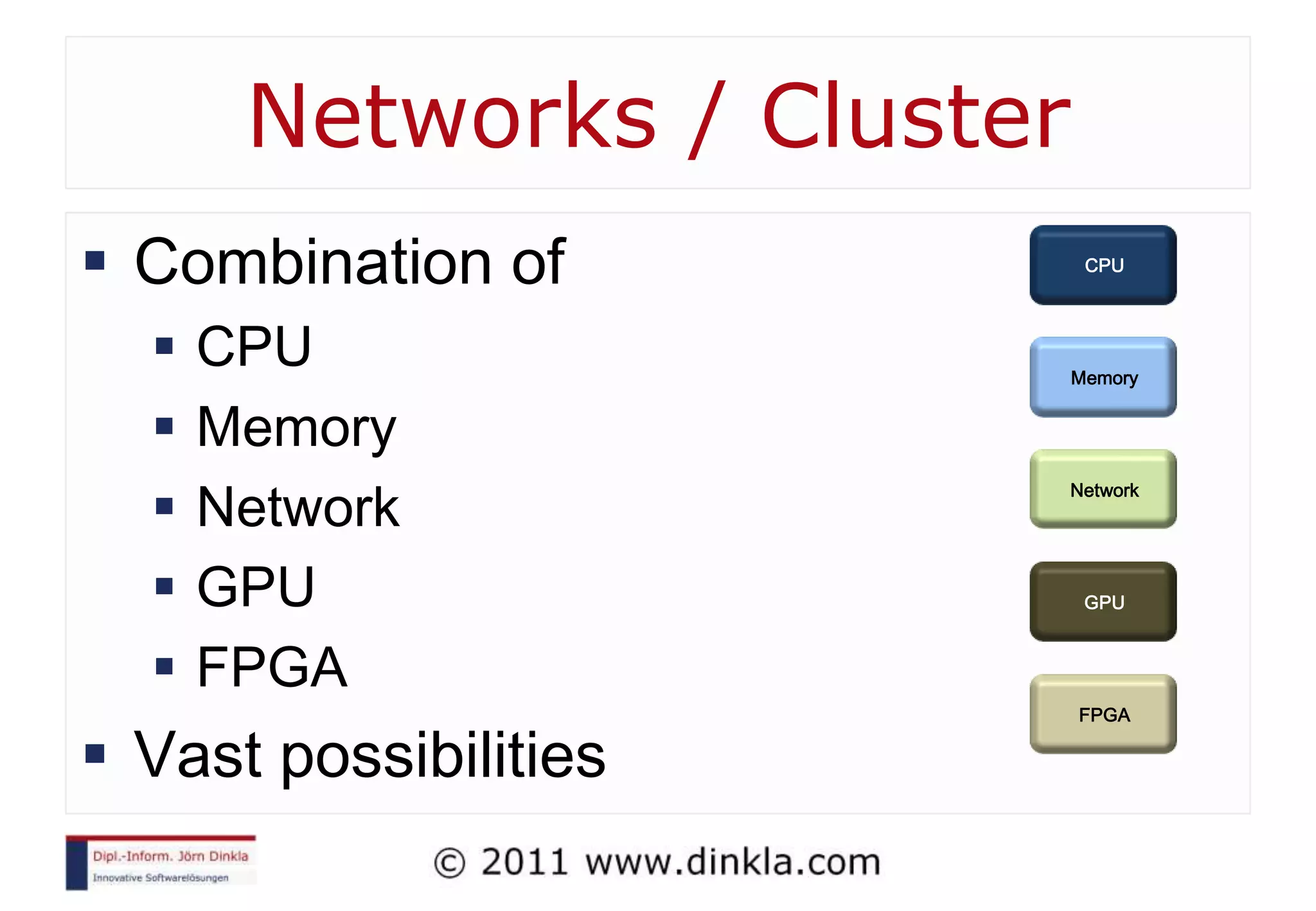
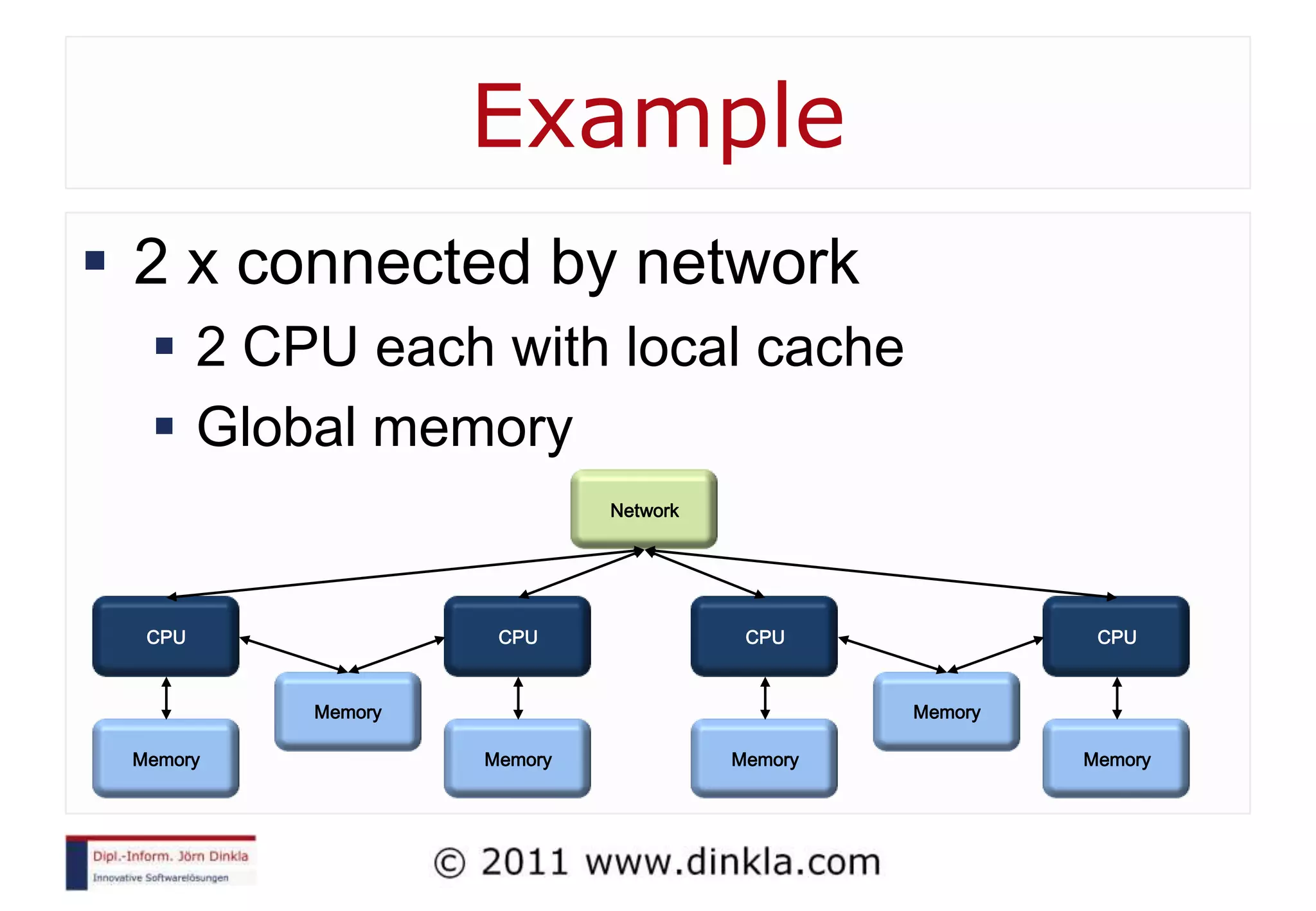
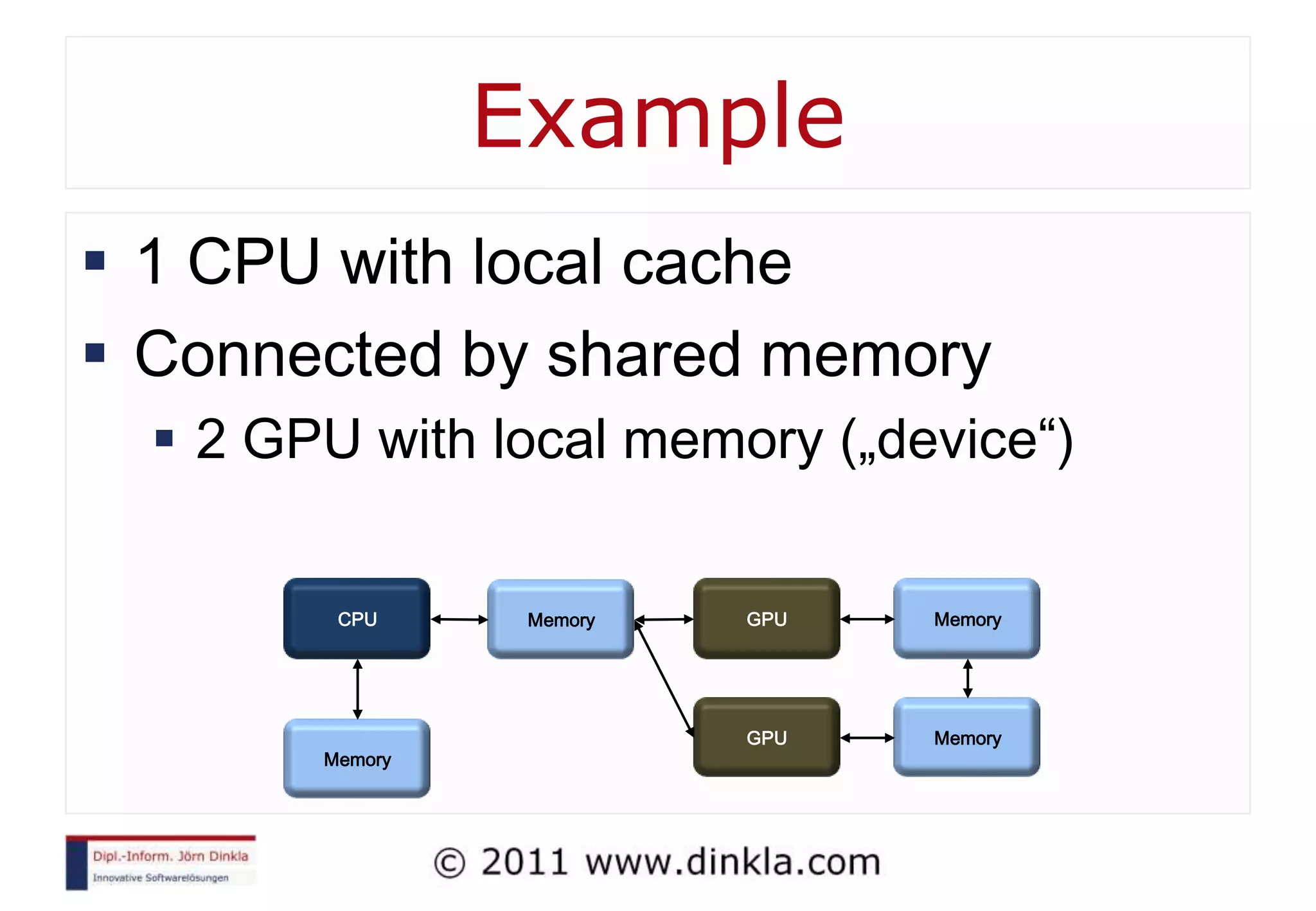
















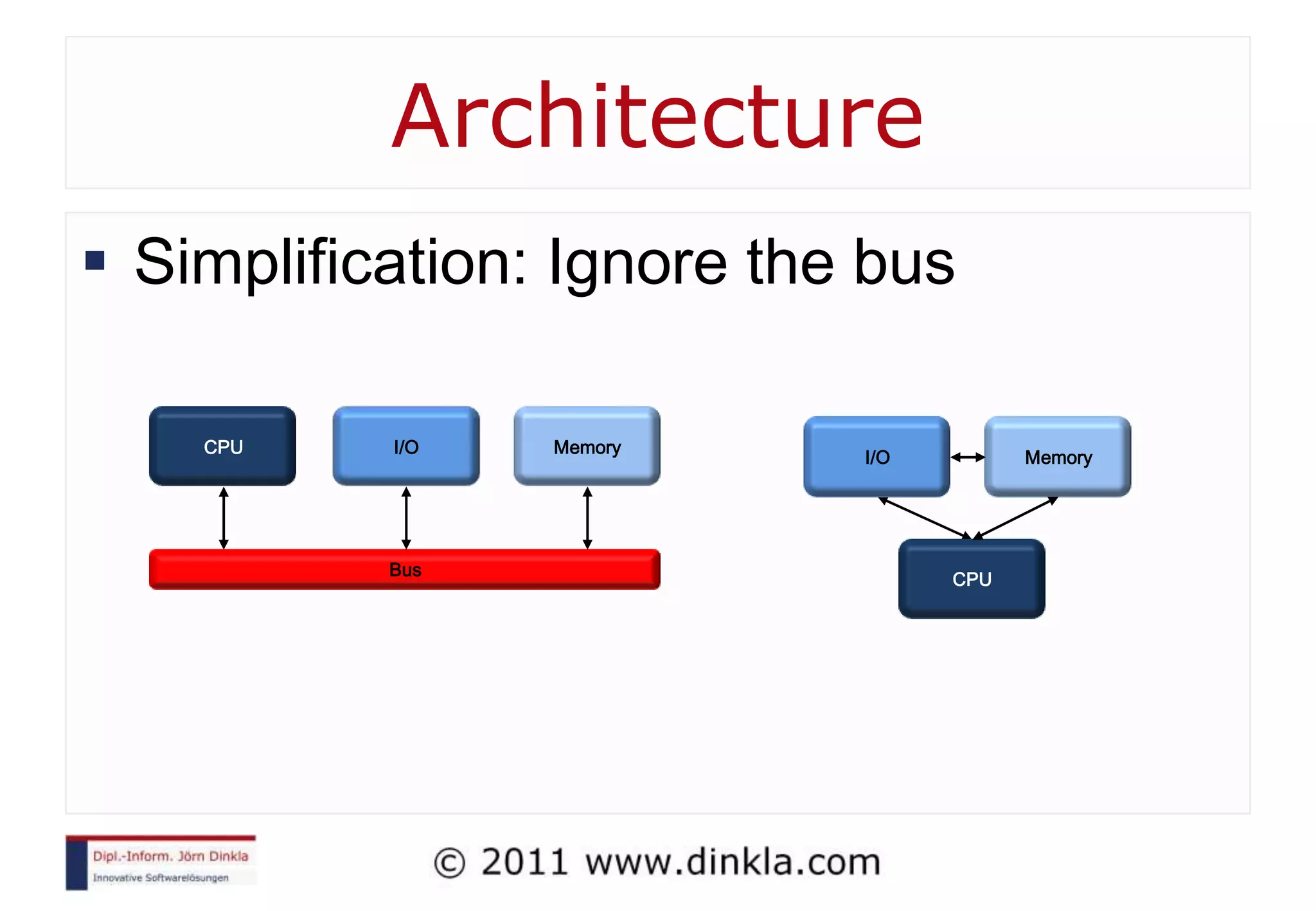
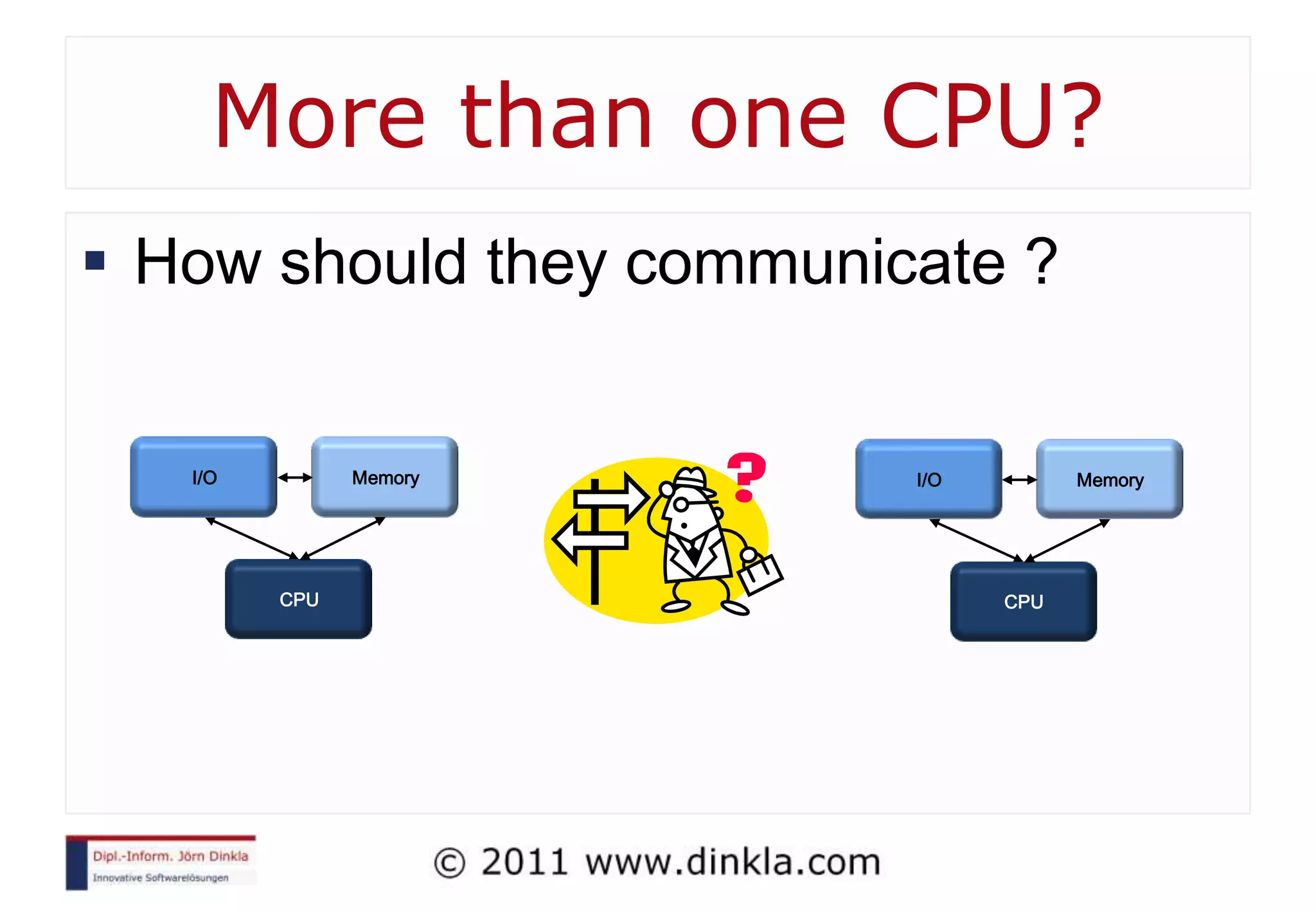
The document provides an extensive overview of parallel computing, covering its evolution, hardware, software advancements, and the challenges of programming in a multi-core environment. It discusses traditional computing architecture, modern algorithm design, issues with synchronization in shared memory, and strategies for optimizing performance on different hardware setups, including GPUs and FPGAs. Additionally, it emphasizes the importance of computational thinking as a key skill for developing efficient parallel algorithms.