Downloaded 26 times










![MPI Programming (2) #include “mpi.h” int main (int argc, char *argv[]) { … MPI_Init(&argc, &argv); … MPI_Finalize(); return …; }](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-11-2048.jpg)






![Example ‘Hello World!’ #include <stdio.h> #include "mpi.h" int main (int argc, char *argv[]) { int size, rank; MPI_Init (&argc, &argv); MPI_Comm_size (MPI_COMM_WORLD, &size); MPI_Comm_rank (MPI_COMM_WORLD, &rank); printf ("Hello world! from processor (%d/%d)n", rank+1, size); MPI_Finalize(); return 0; }](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-18-2048.jpg)




![Example send / receive #include <stdio.h> #include "mpi.h" int main (int argc, char *argv[]) { MPI_Status s; int size, rank, i, j; MPI_Init (&argc, &argv); MPI_Comm_size (MPI_COMM_WORLD, &size); MPI_Comm_rank (MPI_COMM_WORLD, &rank); if (rank == 0) // Master process { printf ("Receiving data . . .n"); for (i = 1; i < size; i++) { MPI_Recv ((void *)&j, 1, MPI_INT, i, 0xACE5, MPI_COMM_WORLD, &s); printf ("[%d] sent %dn", i, j); } } else { j = rank * rank; MPI_Send ((void *)&j, 1, MPI_INT, 0, 0xACE5, MPI_COMM_WORLD); } MPI_Finalize(); return 0; }](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-23-2048.jpg)
![Running send / receive $ mpicc -o sendrecv sendrecv.c $ mpirun -np 4 sendrecv Receiving data . . . [1] sent 1 [2] sent 4 [3] sent 9 $ _](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-24-2048.jpg)


![Example broadcast / barrier int main (int argc, char *argv[]) { int rank, i; MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &rank); if (rank == 0) i = 27; MPI_Bcast ((void *)&i, 1, MPI_INT, 0, MPI_COMM_WORLD); printf ("[%d] i = %dn", rank, i); // Wait for every process to reach this code MPI_Barrier (MPI_COMM_WORLD); MPI_Finalize(); return 0; }](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-27-2048.jpg)
![Running broadcast / barrier $ mpicc -o broadcast broadcast.c $ mpirun -np 3 broadcast [0] i = 27 [1] i = 27 [2] i = 27 $ _](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-28-2048.jpg)


![Example scatter / reduce int main (int argc, char *argv[]) { int data[] = {1, 2, 3, 4, 5, 6, 7}; // Size must be >= #processors int rank, i = -1, j = -1; MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &rank); MPI_Scatter ((void *)data, 1, MPI_INT, (void *)&i , 1, MPI_INT, 0, MPI_COMM_WORLD); printf ("[%d] Received i = %dn", rank, i); MPI_Reduce ((void *)&i, (void *)&j, 1, MPI_INT, MPI_PROD, 0, MPI_COMM_WORLD); printf ("[%d] j = %dn", rank, j); MPI_Finalize(); return 0; }](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-31-2048.jpg)
![Running scatter / reduce $ mpicc -o scatterreduce scatterreduce.c $ mpirun -np 4 scatterreduce [0] Received i = 1 [0] j = 24 [1] Received i = 2 [1] j = -1 [2] Received i = 3 [2] j = -1 [3] Received i = 4 [3] j = -1 $ _](https://image.slidesharecdn.com/parallelcomputing2-130402030243-phpapp02/75/Parallel-computing-2-32-2048.jpg)










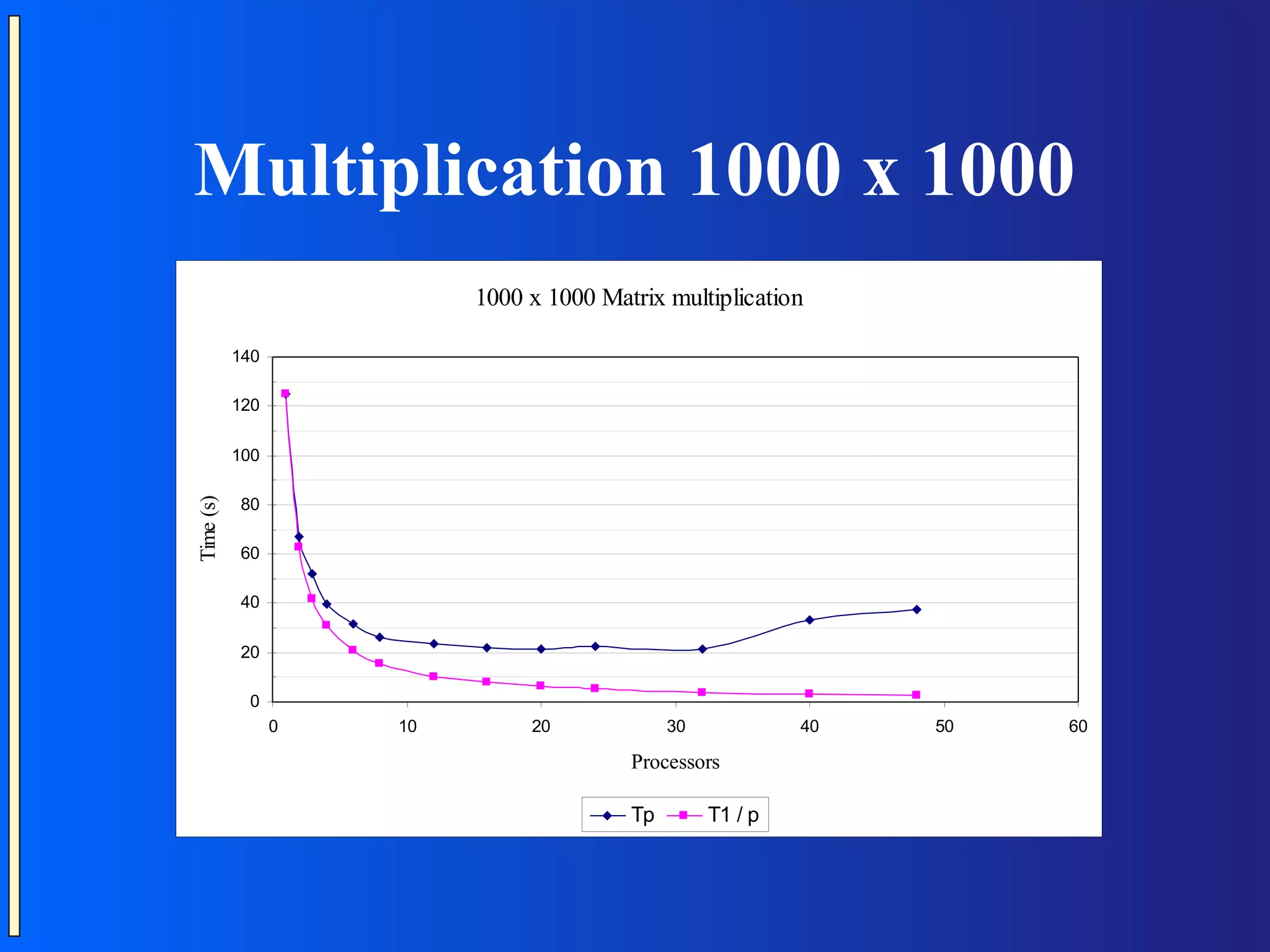
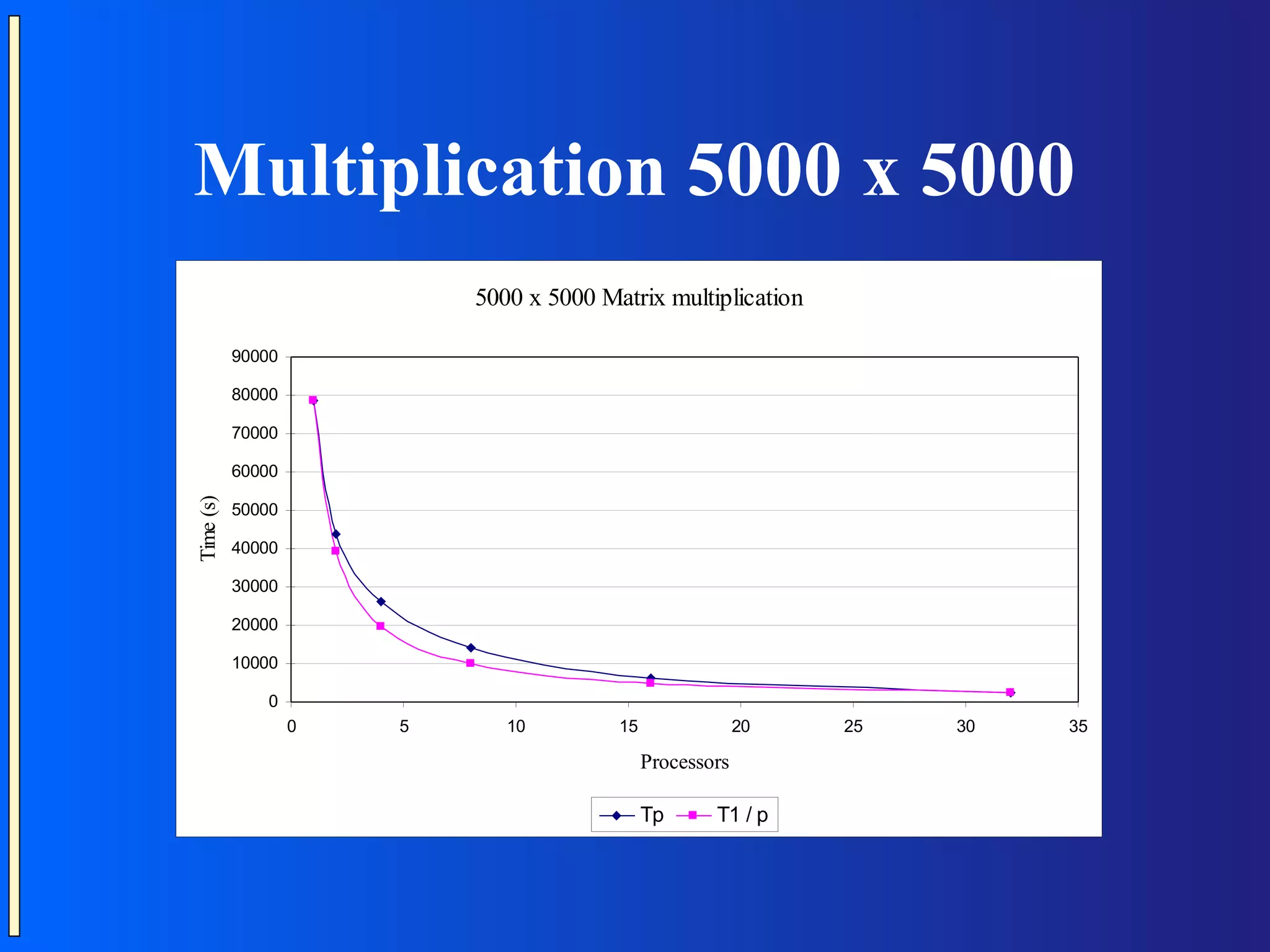








The document provides an introduction to Message Passing Interface (MPI), which is a standard for message passing parallel programming. It discusses key MPI concepts like communicators, data types, point-to-point and collective communication routines. It also presents examples of common parallel programming patterns like broadcast, scatter-gather, and parallel sorting and matrix multiplication. Programming hints are provided, along with references for further reading.