Downloaded 13 times


![#include "mpi.h" #include <stdio.h> int main( int argc, char *argv[] ) { MPI_Init( &argc, &argv ); printf( "Hello, world!n" ); MPI_Finalize(); return 0; } Header File – include "mpi.h" – include 'mpif.h' Initialize MPI Env. – MPI_Init(..) Terminate MPI Env. – MPI_Finalize() General MPI Program Structure](https://image.slidesharecdn.com/introtompi-180121111806/75/Introduction-to-MPI-4-2048.jpg)











![int main(int argc, char *argv[]) { int N; // Number of intervals double w, x; // width and x point int i, myid; double mypi, others_pi; MPI_Init(&argc,&argv); // Initialize // Get # processors MPI_Comm_size(MPI_COMM_WORLD, &num_procs); MPI_Comm_rank(MPI_COMM_WORLD, &myid); N = atoi(argv[1]); w = 1.0/(double) N; mypi = 0.0; //Each MPI Process has its own copy of every variable Compute PI by Numerical Integration C code](https://image.slidesharecdn.com/introtompi-180121111806/75/Introduction-to-MPI-21-2048.jpg)





![MPI_Barrier(MPI_Comm comm) Provides the ability to block the calling process until all processes in the communicator have reached this routine. #include "mpi.h" #include int main(int argc, char *argv[]) { int rank, nprocs; MPI_Init(&argc,&argv); MPI_Comm_size(MPI_COMM_WORLD,&nprocs); MPI_Comm_rank(MPI_COMM_WORLD,&rank); MPI_Barrier(MPI_COMM_WORLD); printf("Hello, world. I am %d of %dn", rank, procs); fflush(stdout); MPI_Finalize(); return 0; } Synchronization](https://image.slidesharecdn.com/introtompi-180121111806/75/Introduction-to-MPI-32-2048.jpg)









The Message Passing Interface (MPI) allows parallel applications to communicate between processes using message passing. MPI programs initialize and finalize a communication environment, and most communication occurs through point-to-point send and receive operations between processes. Collective communication routines like broadcast, scatter, and gather allow all processes to participate in the communication.
Overview of MPI (Message Passing Interface) and its importance in parallel computing.
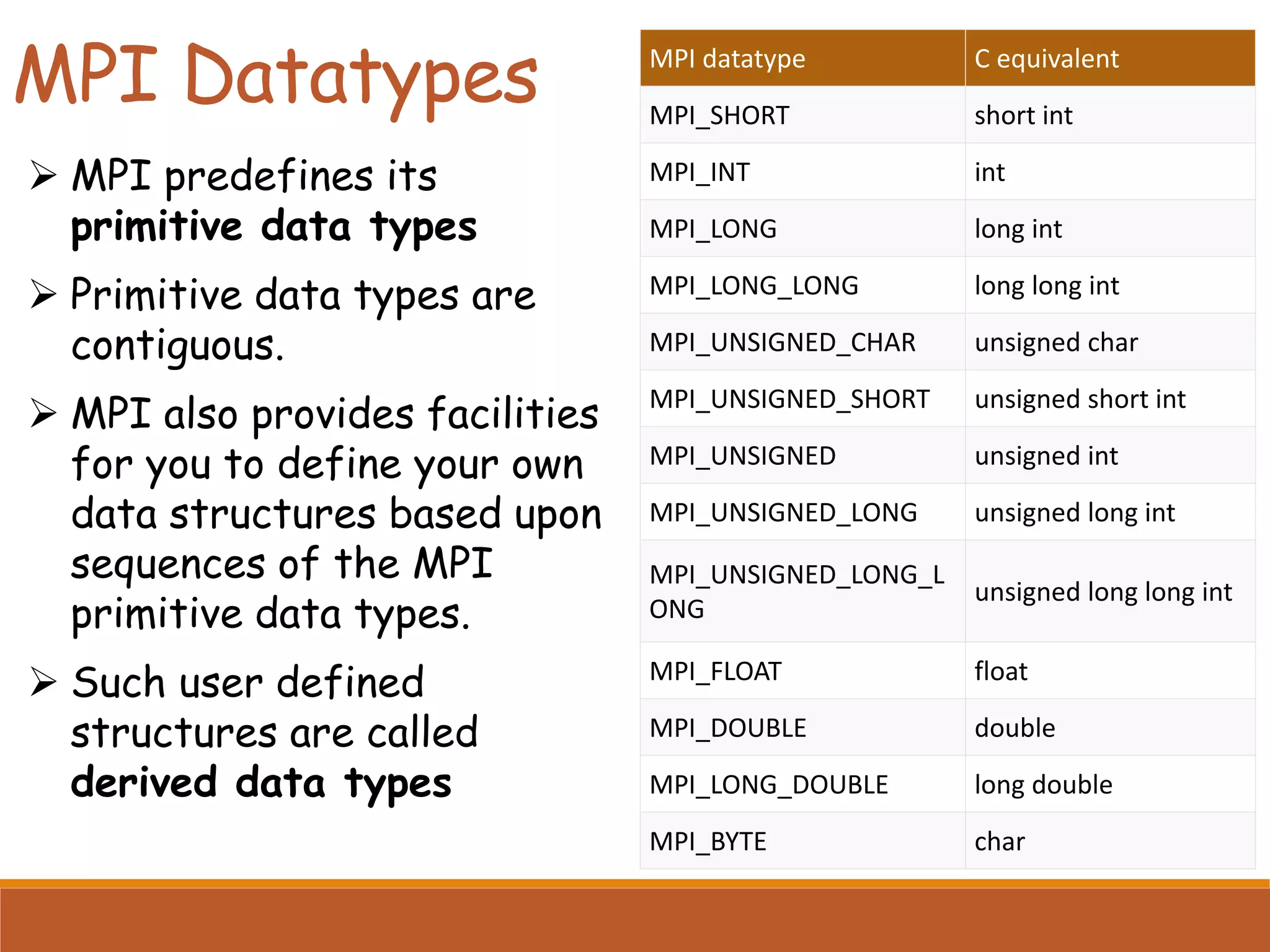
Describes the message passing model and its four primary operation classes: Environment Management, Data Movement, Collective Computation, and Synchronization.
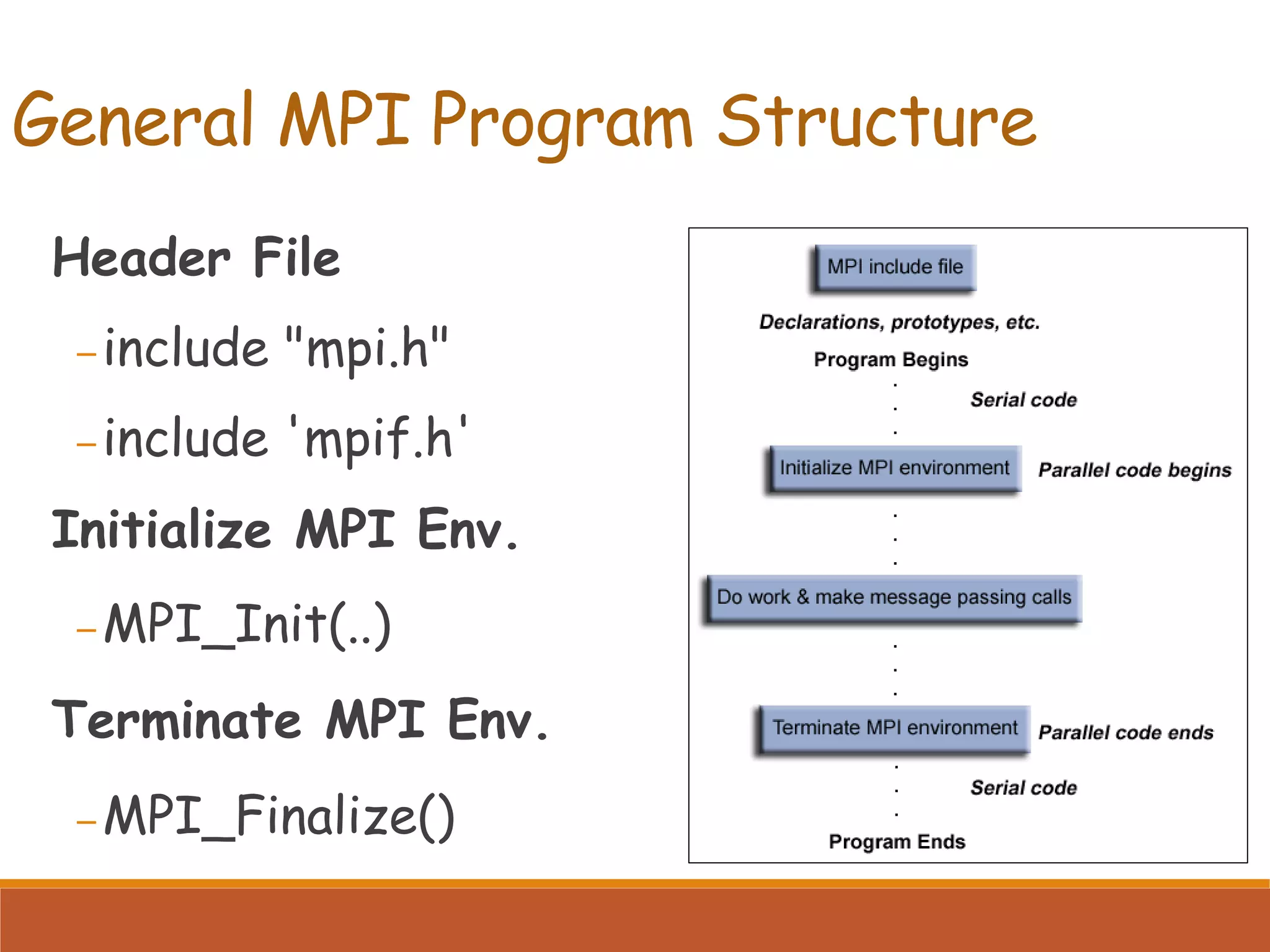
Explains the basic structure of an MPI program including including necessary headers and initializing/terminating the MPI environment.
Details routines for managing the MPI environment, e.g., initializing, finalizing, getting processor name, and timing functions.
Describes communication concepts in MPI, including communicators, ranks, and methods to determine size and rank of MPI processes.
Illustration of a basic HelloWorld MPI program showcasing the use of MPI_Init, MPI_Comm_size, and MPI_Comm_rank.
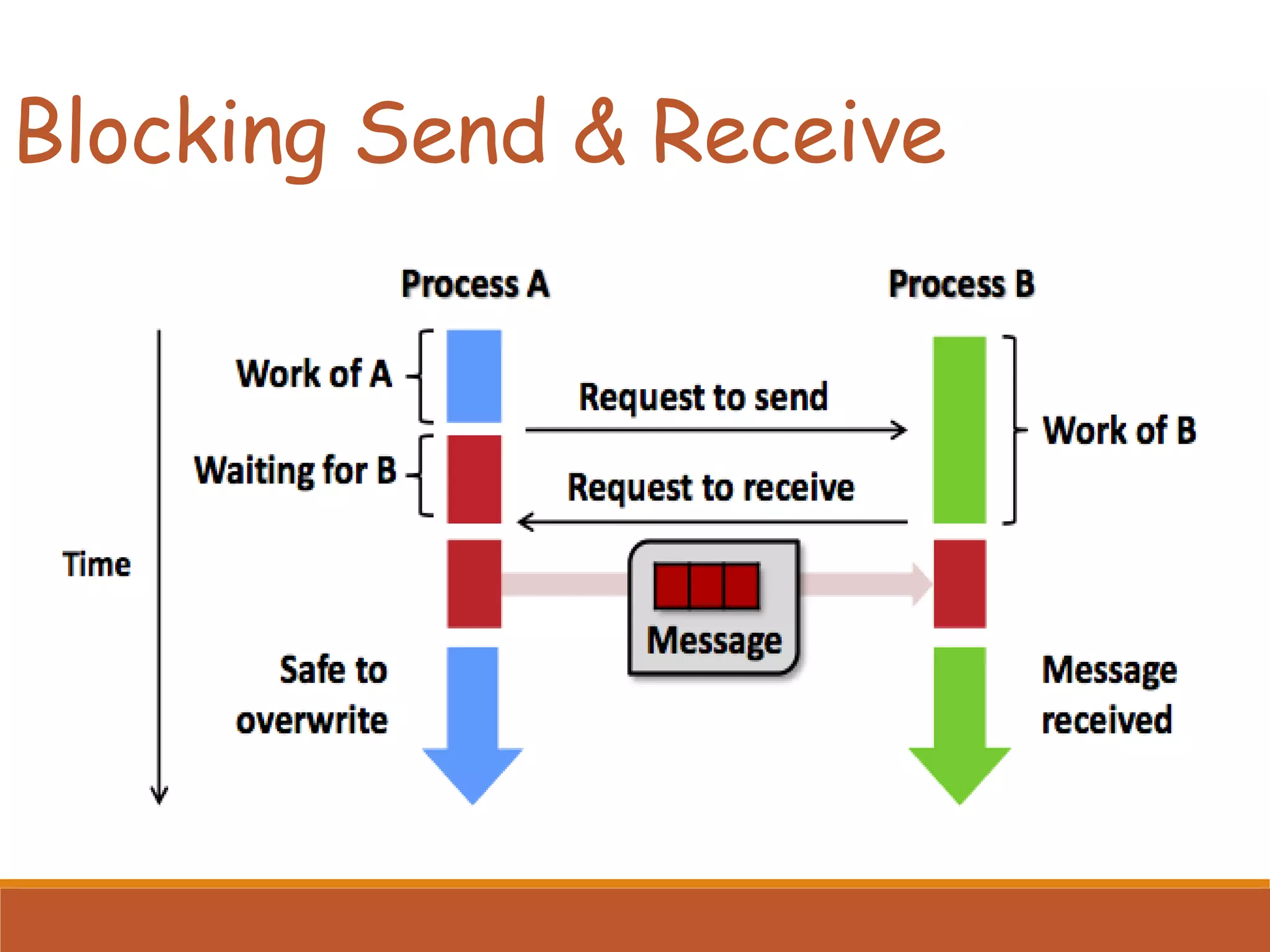
Covers point-to-point communication in MPI, including send/receive operations, message composition, and the importance of message IDs.
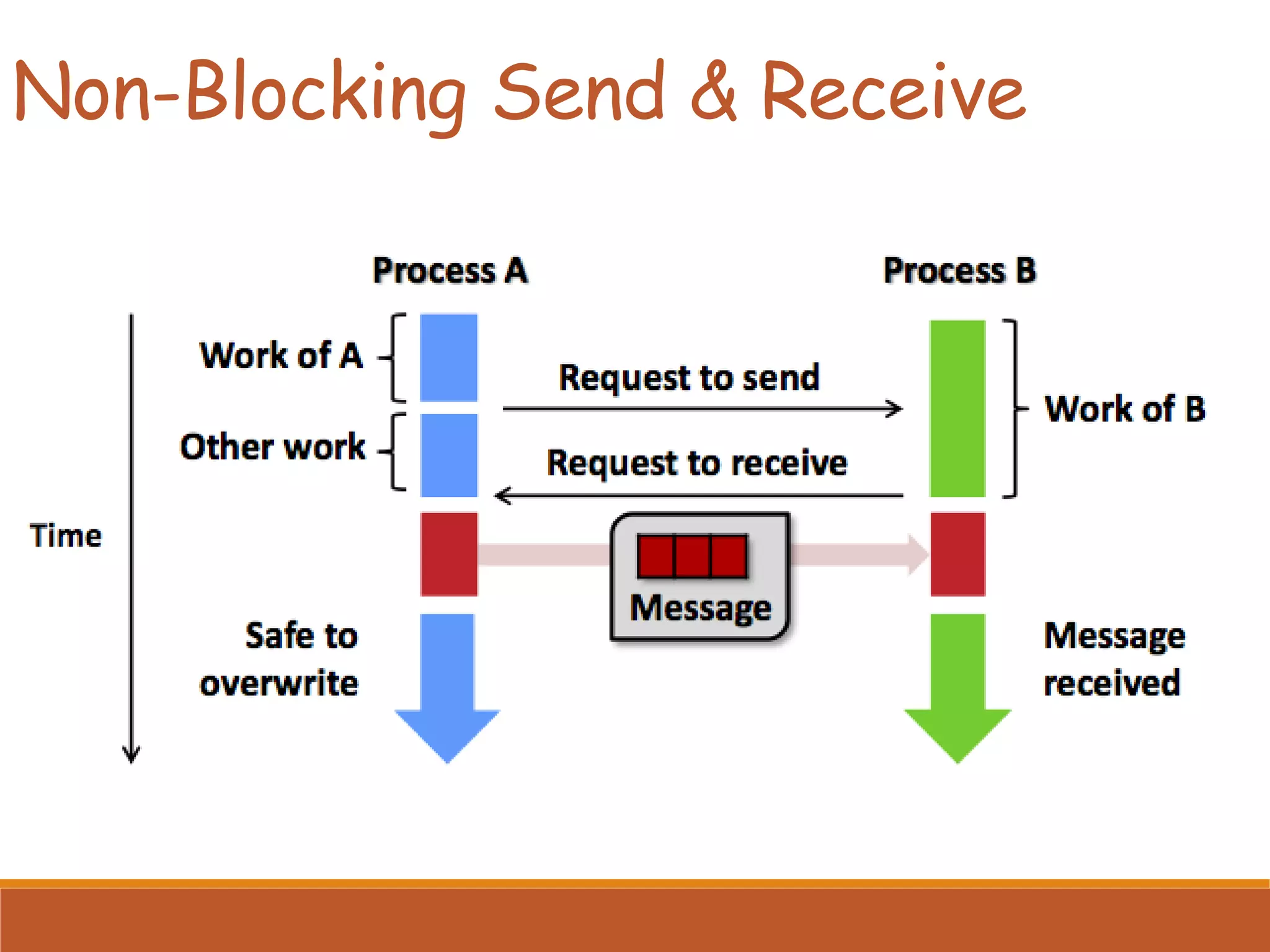
Differences between blocking and non-blocking send/receive operations, emphasizing use cases and handling tasks during communication.
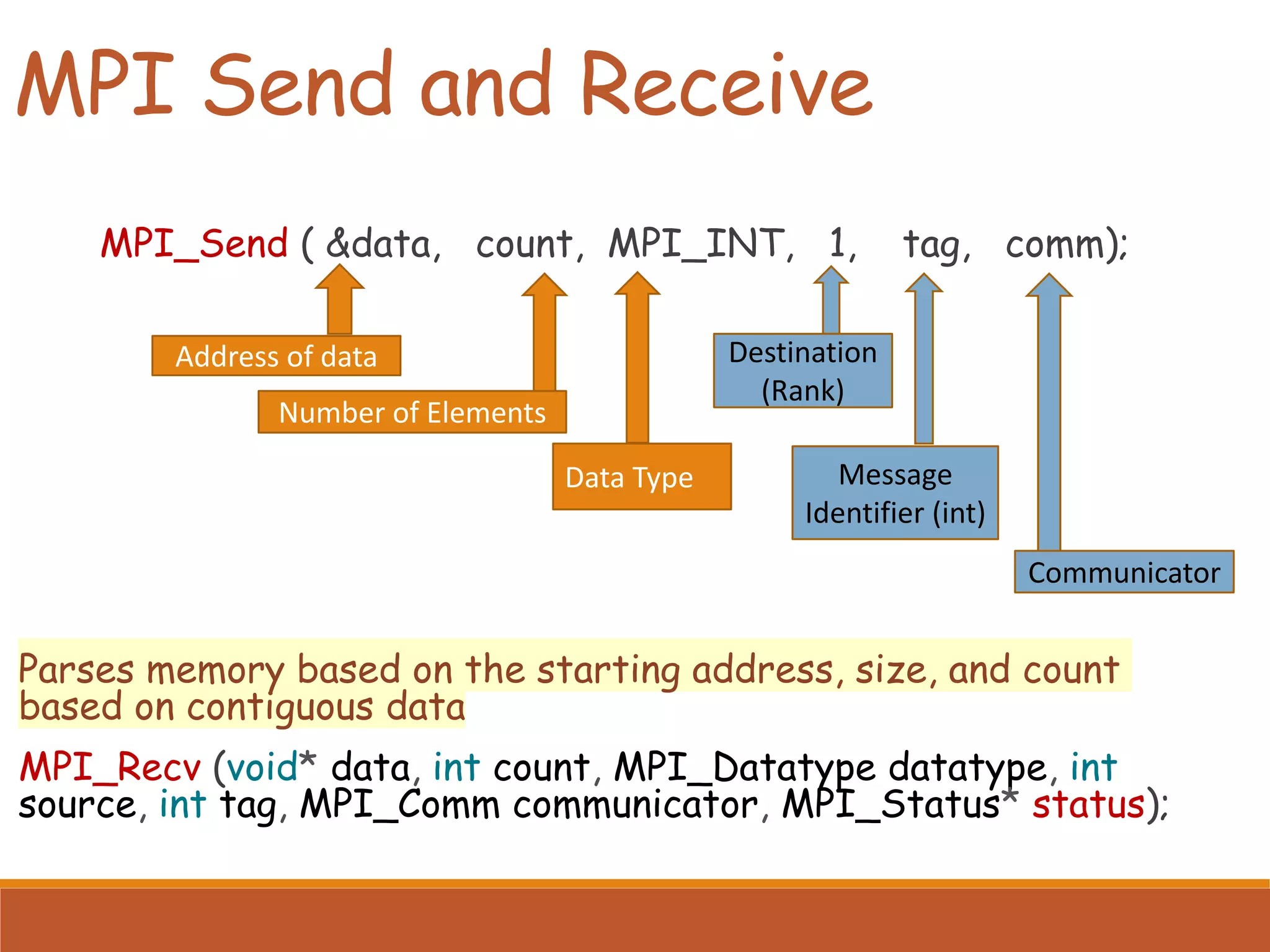
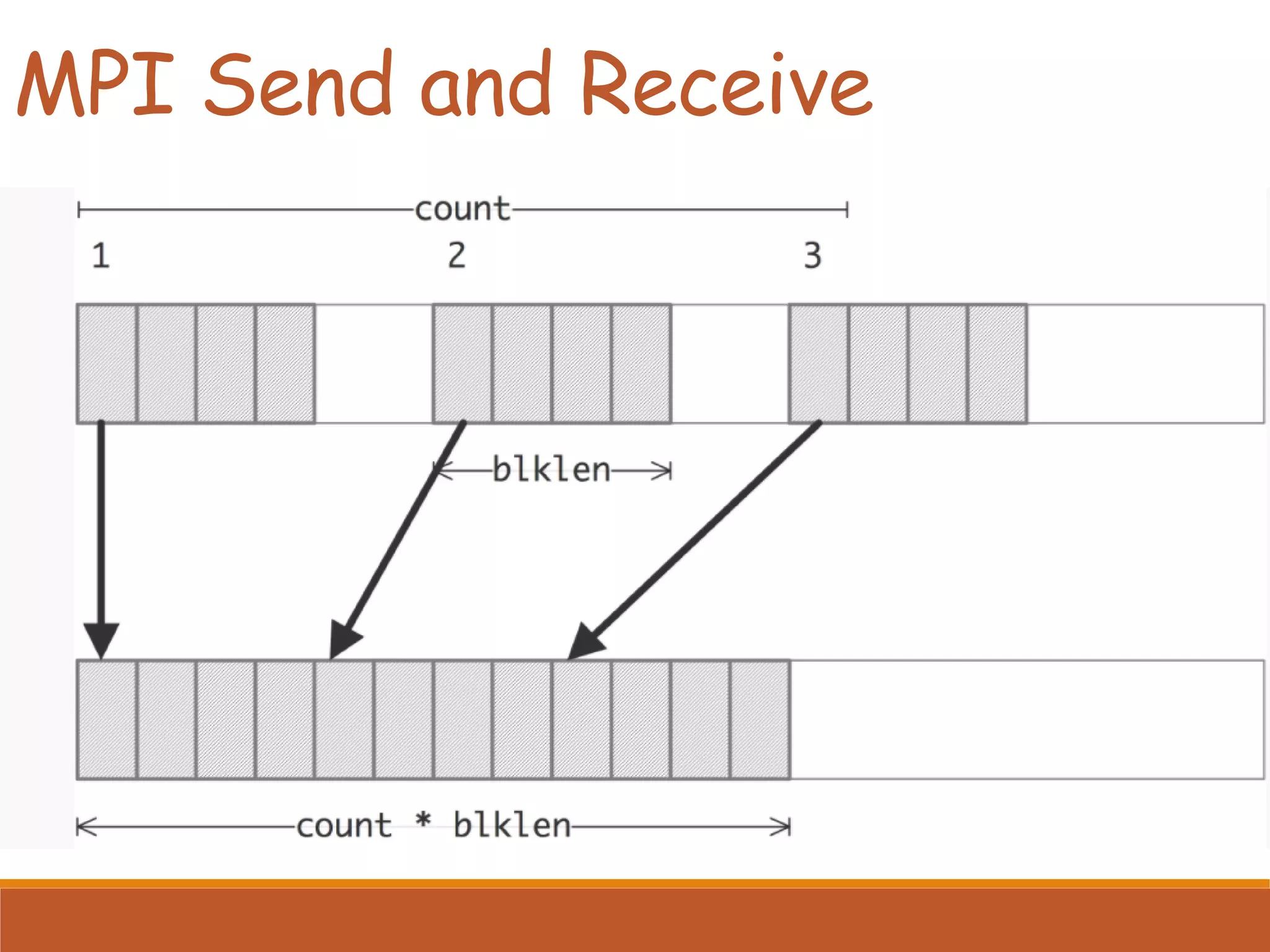
Details about the MPI send and receive functions, including parameters and type compatibility in communication.
Explains how to compute π using numerical integration across multiple processes with MPI, including code structure and communication.
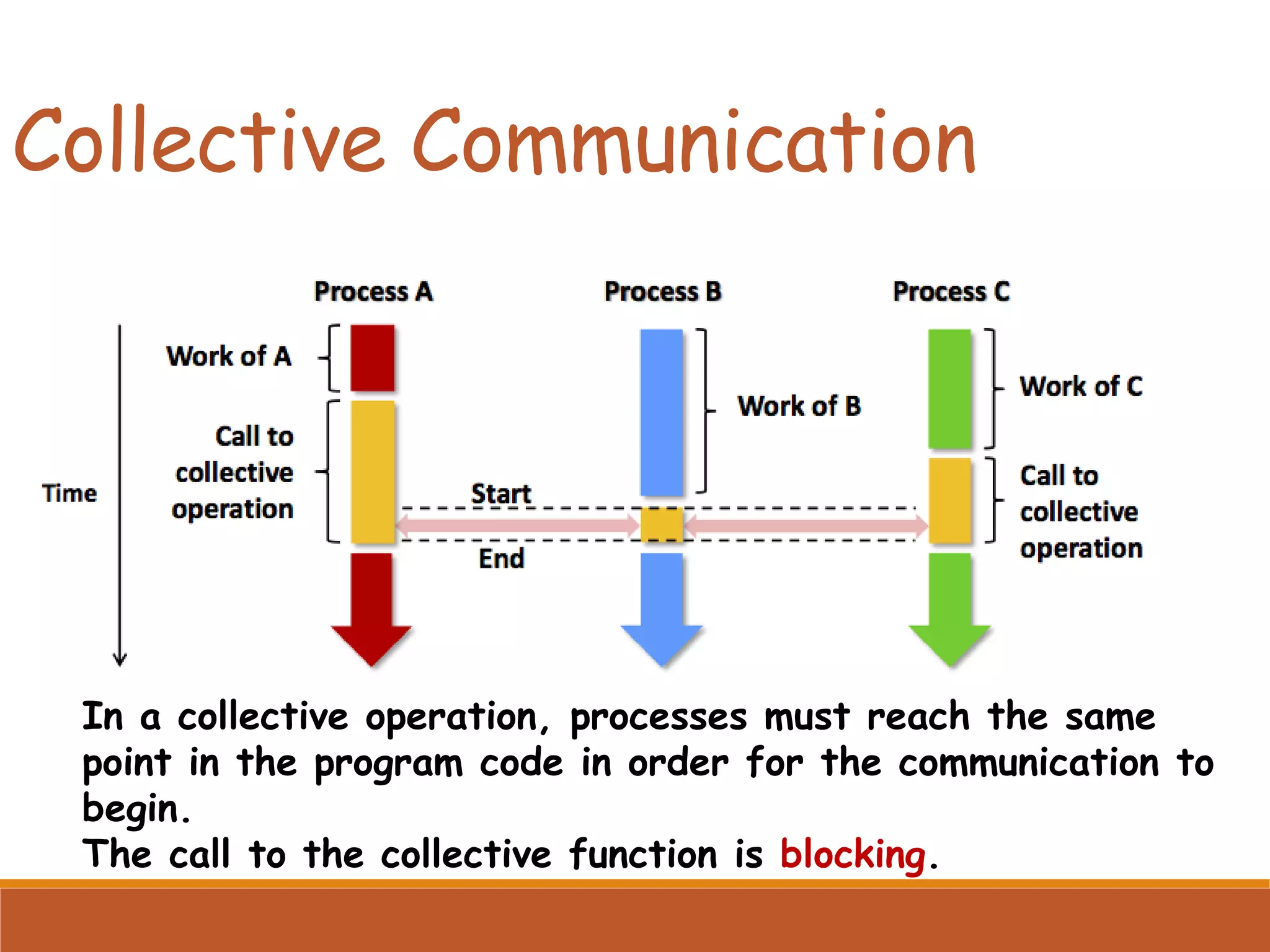
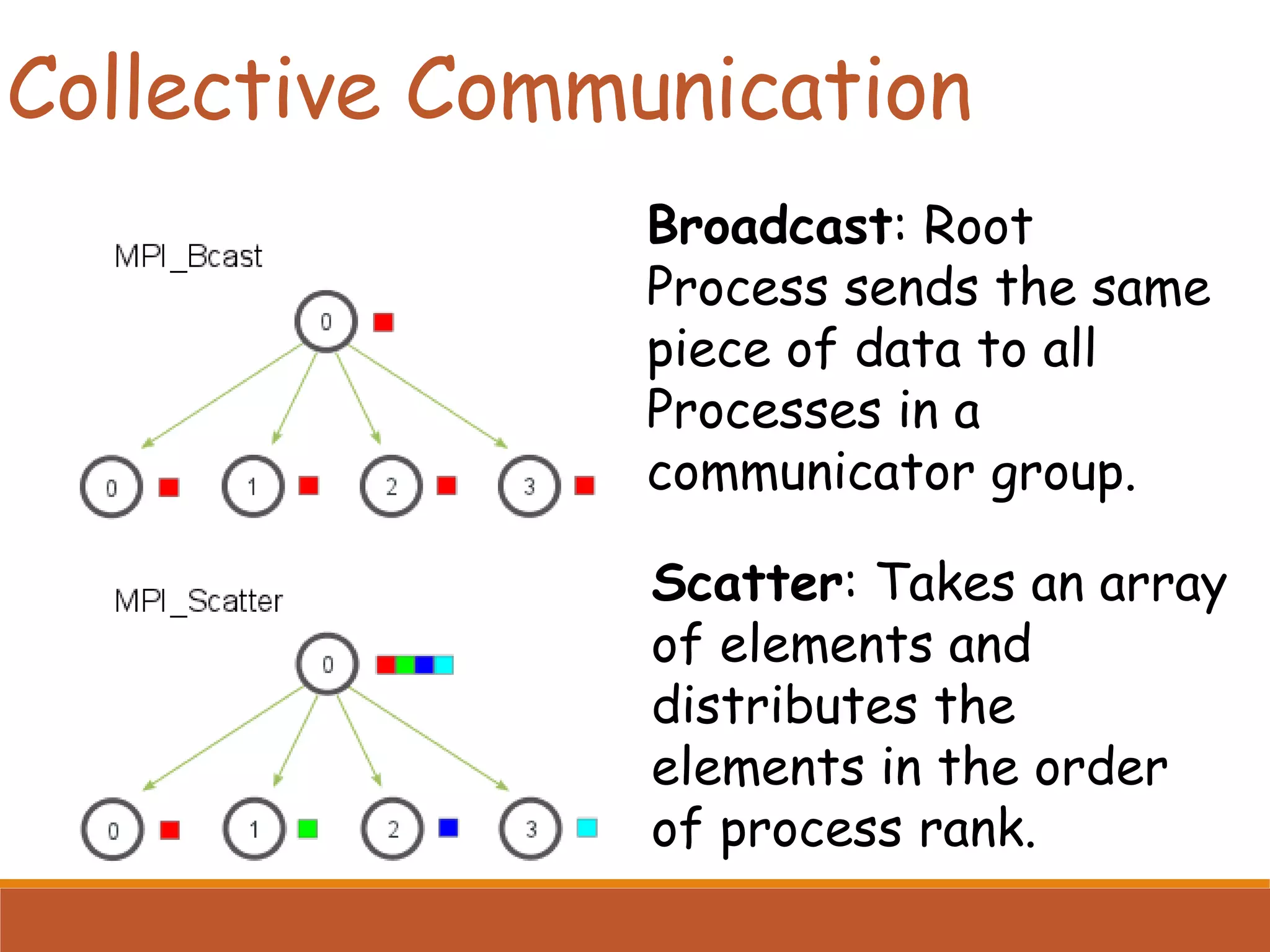
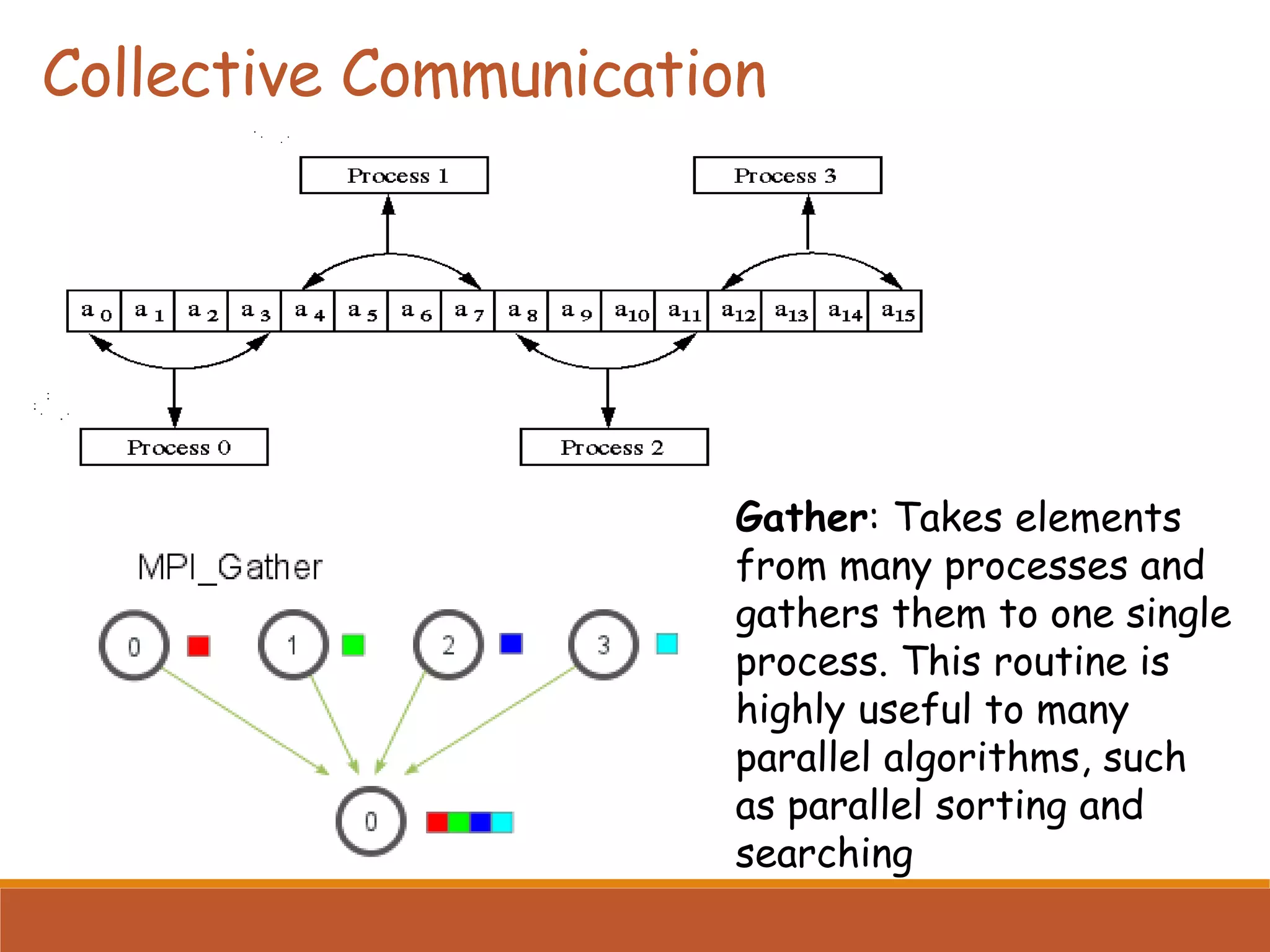
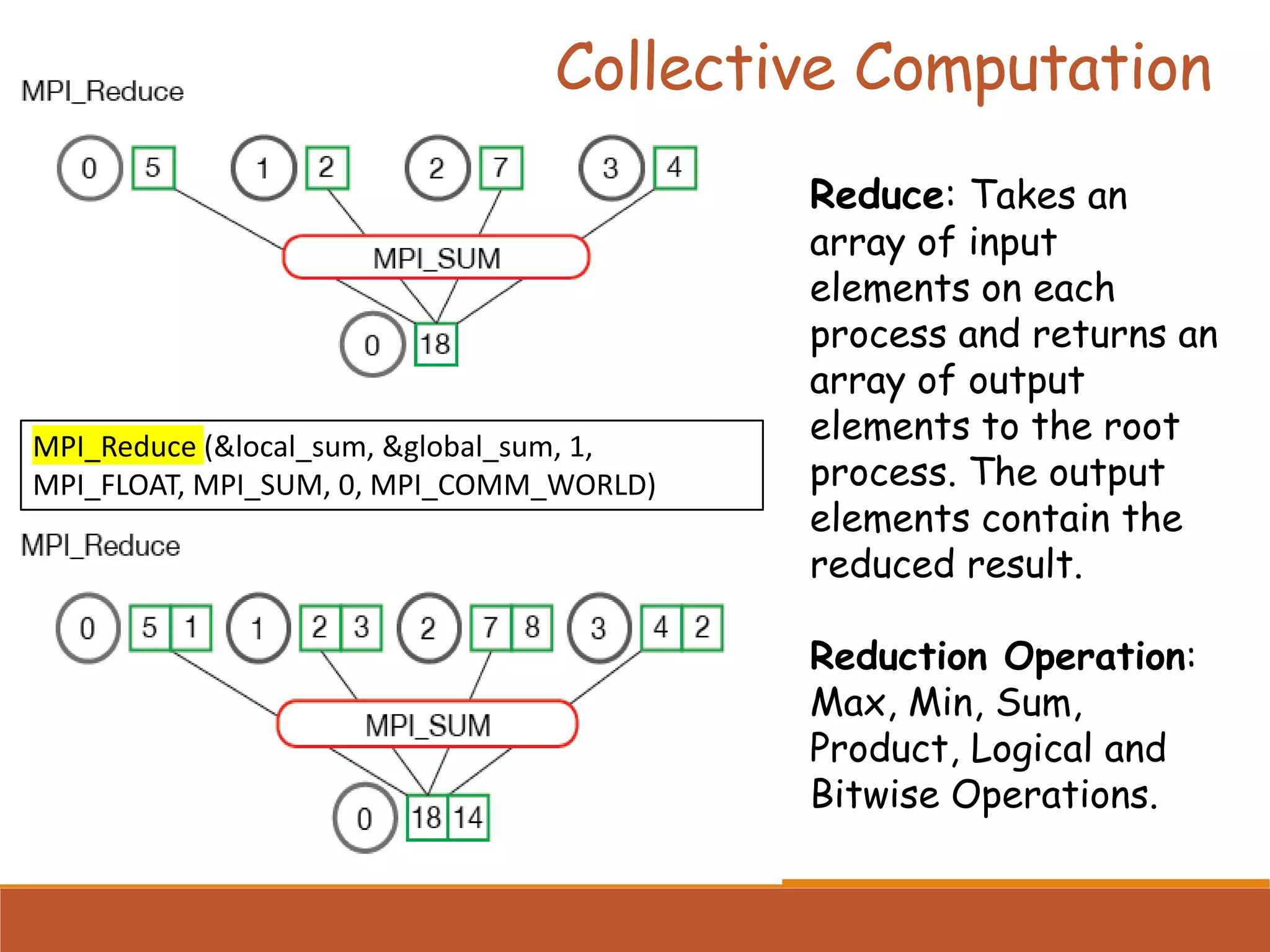
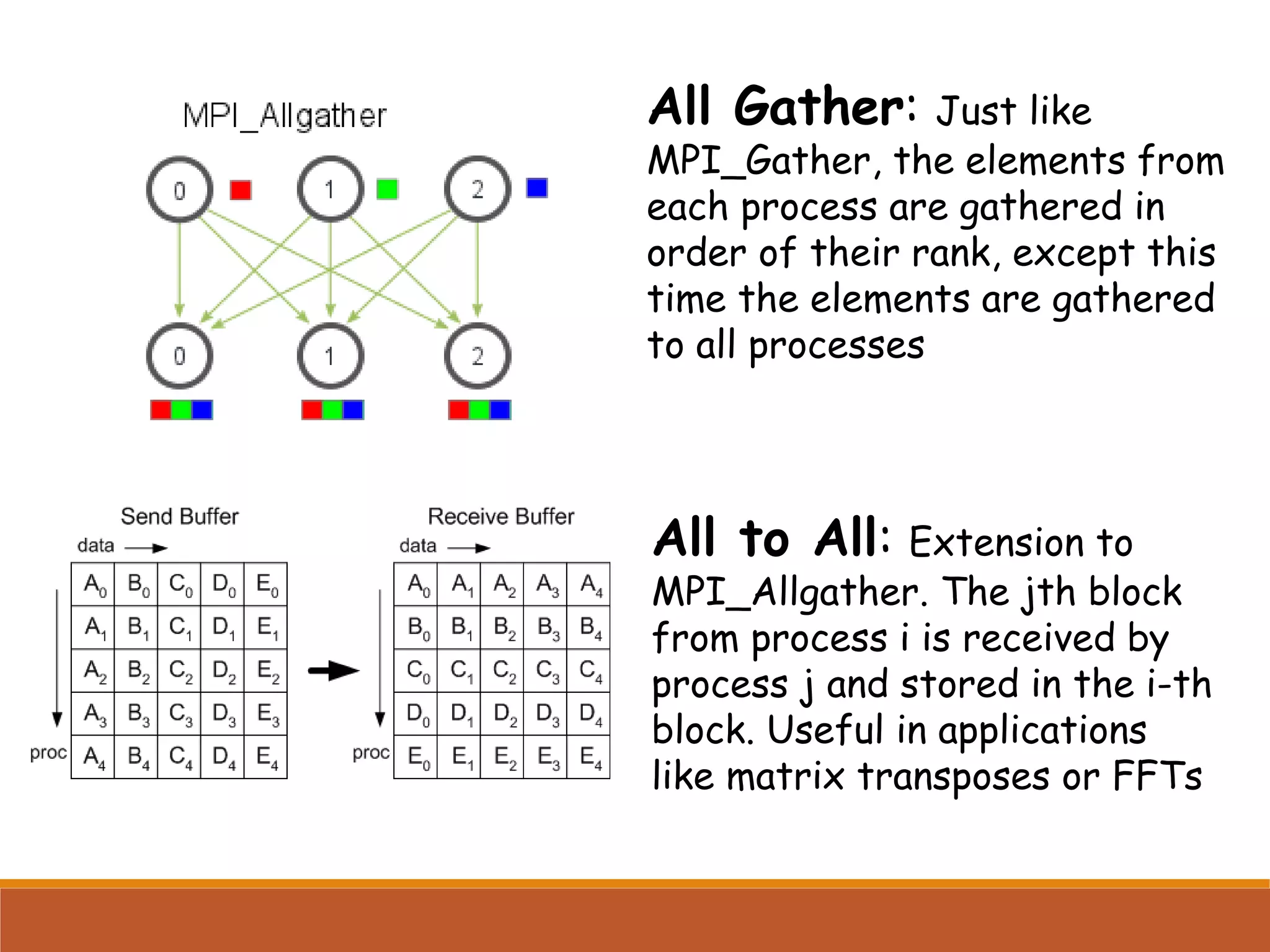
Describes collective communication concepts like broadcast, scatter, gather, and reduction operations among multiple processes.
Usage of collective operations for efficient data distribution at program beginning and results collection at the end.
Explains MPI barrier synchronization, in which a process waits until all processes reach the same point.
Continuation of the PI computation code, detailing summation, reduction, and processing across multiple processors.
Describes the programming environment necessary for MPI, including compilers and software components.
Overview of various MPI implementations and specifics of the Cray MPI-3.0 standard optimized for their hardware.
Instructions on compiling MPI programs with command specifics for C, C++, and Fortran.
Describes the execution modes for MPI programs: interactive and batch mode with scripting examples.
Discusses error handling techniques in MPI, including behavior on errors and possible overrides.
The concluding slide thanking the audience for their attention.