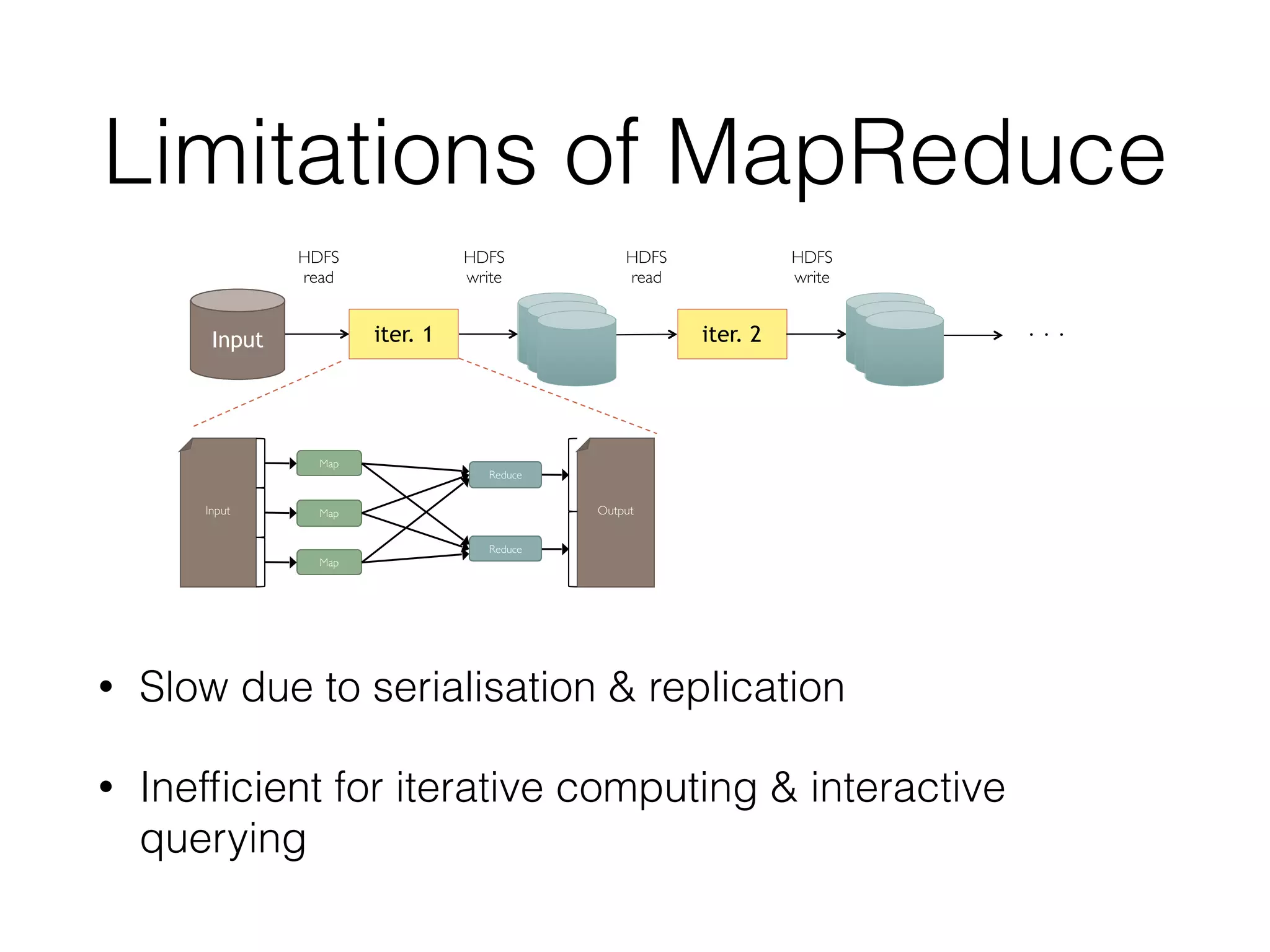
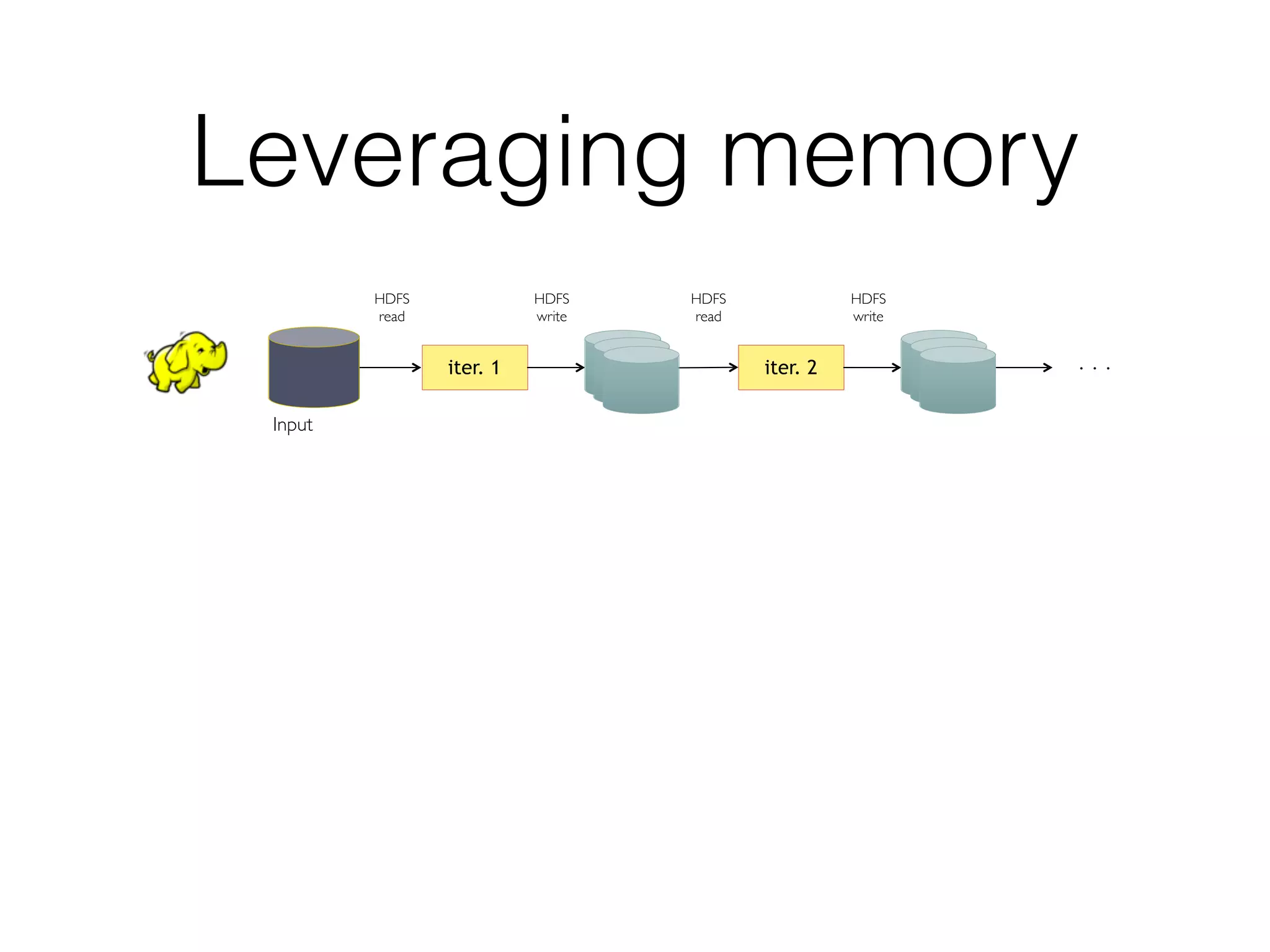
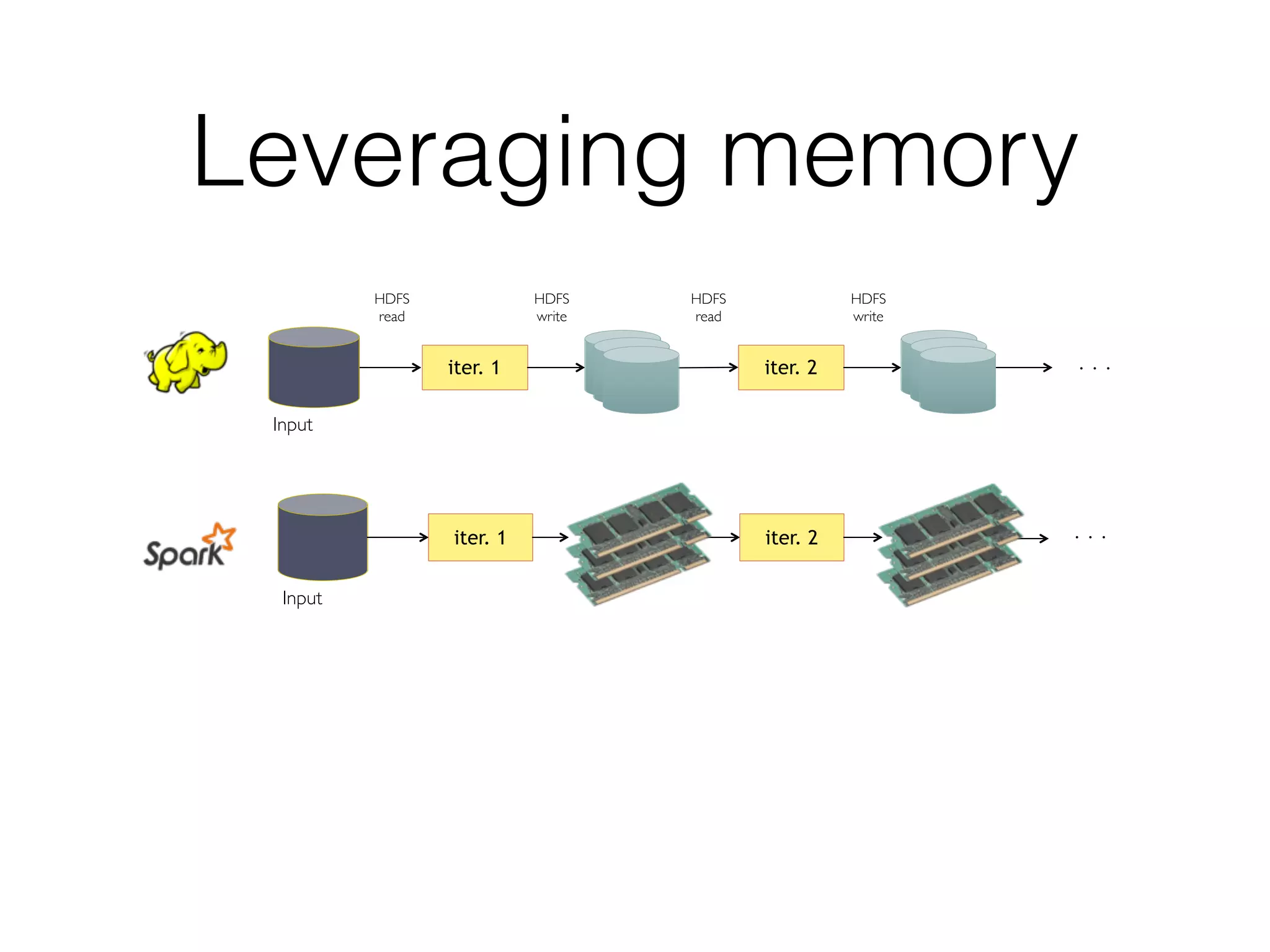
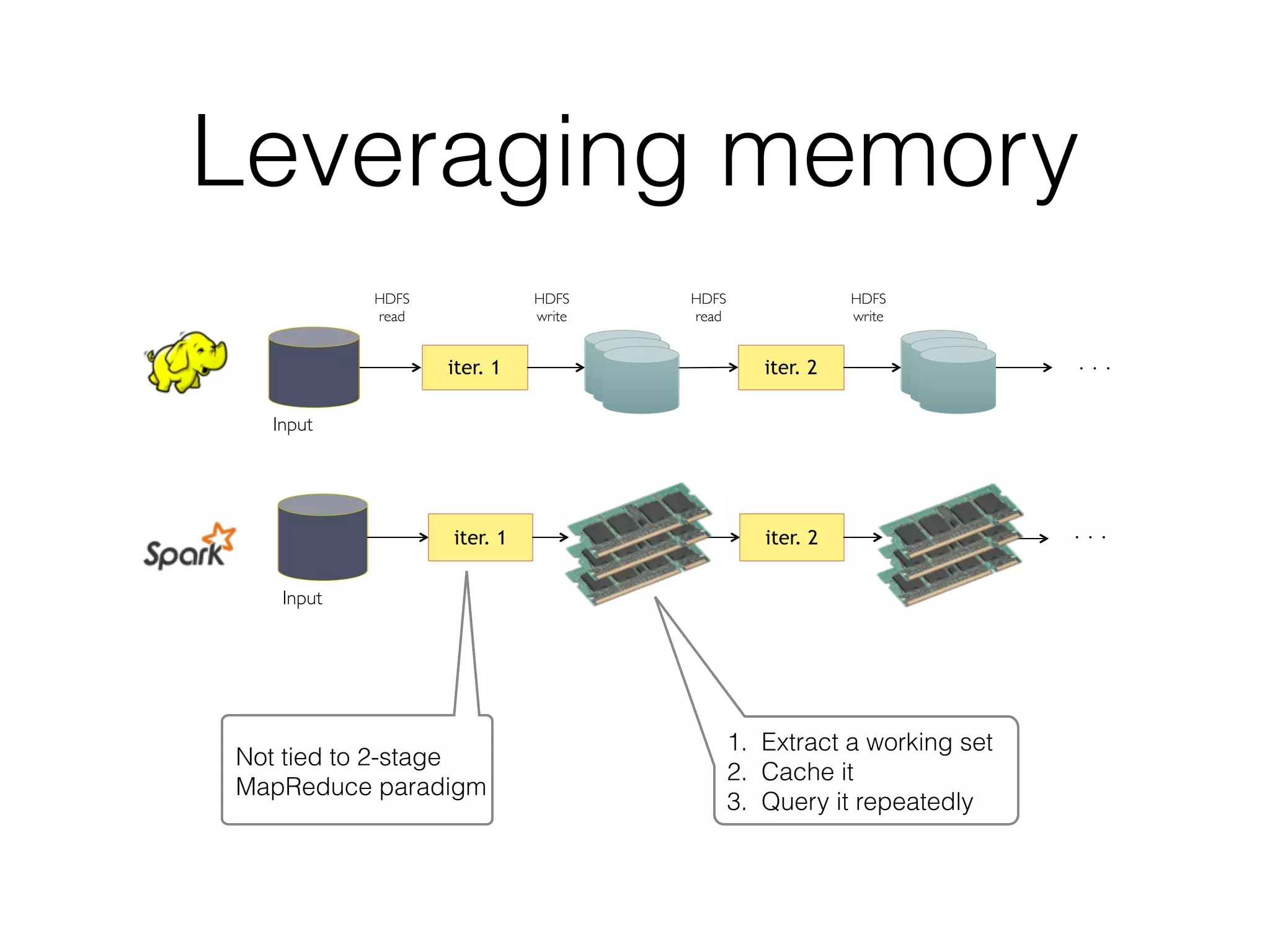
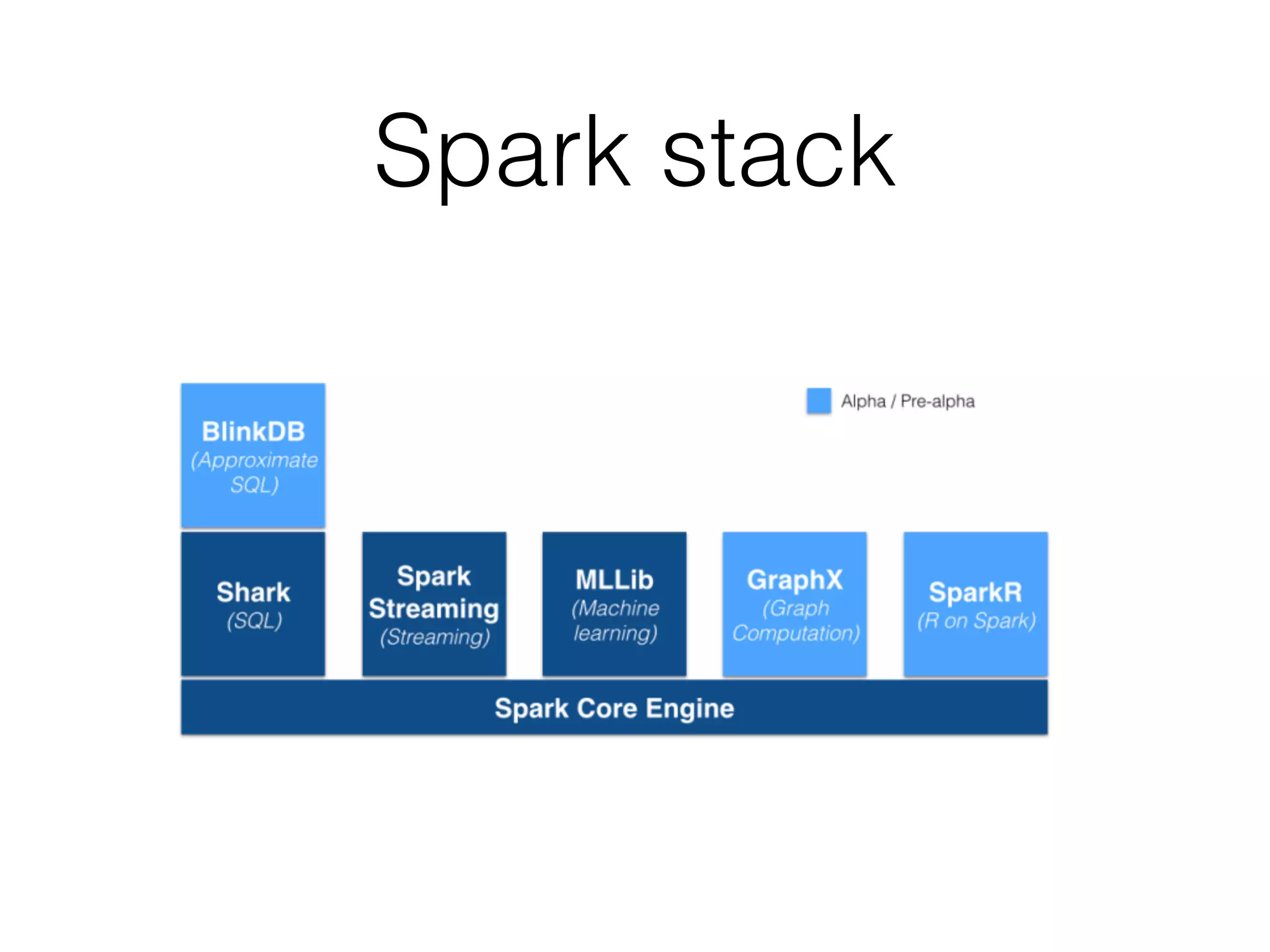
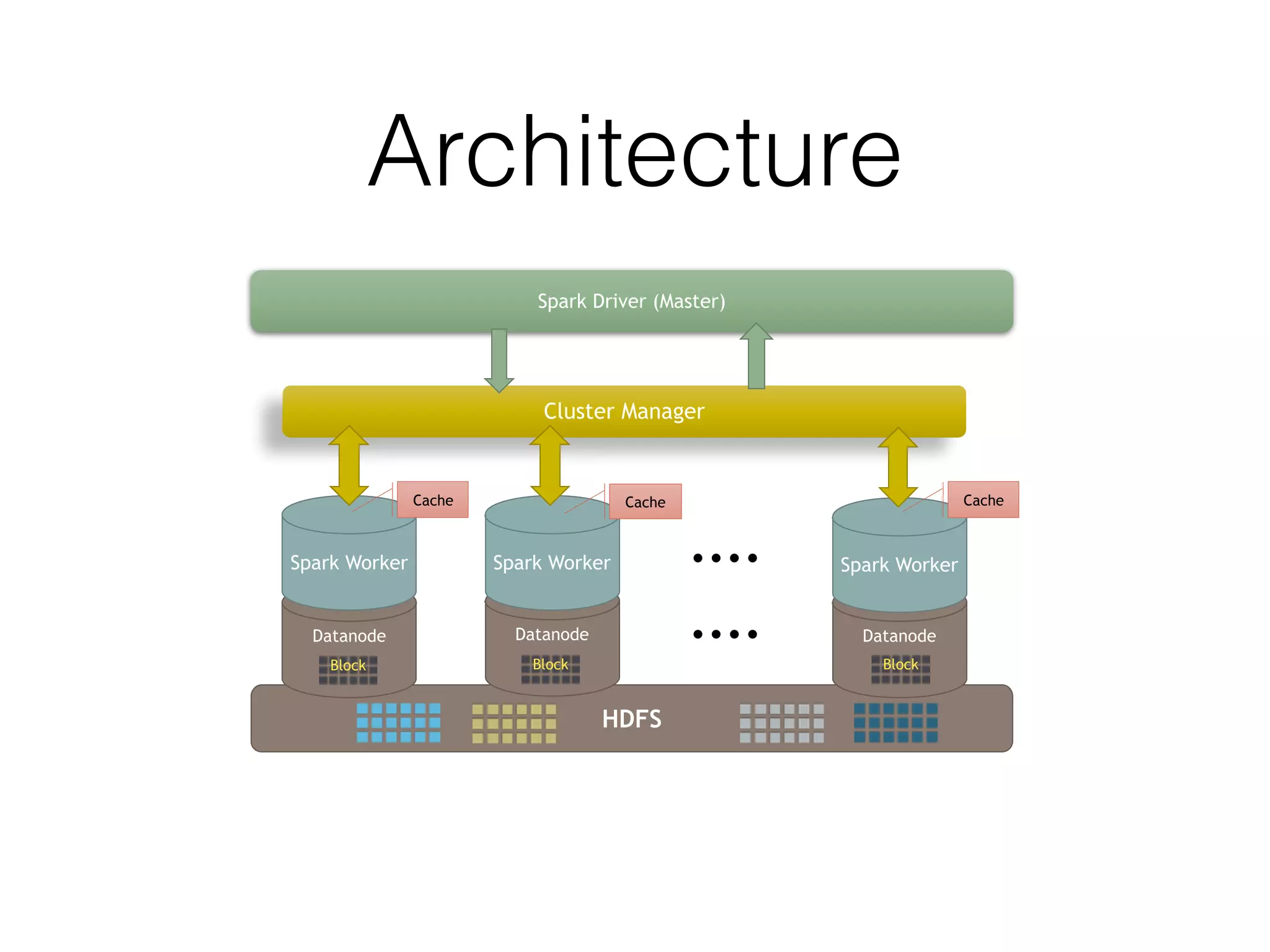
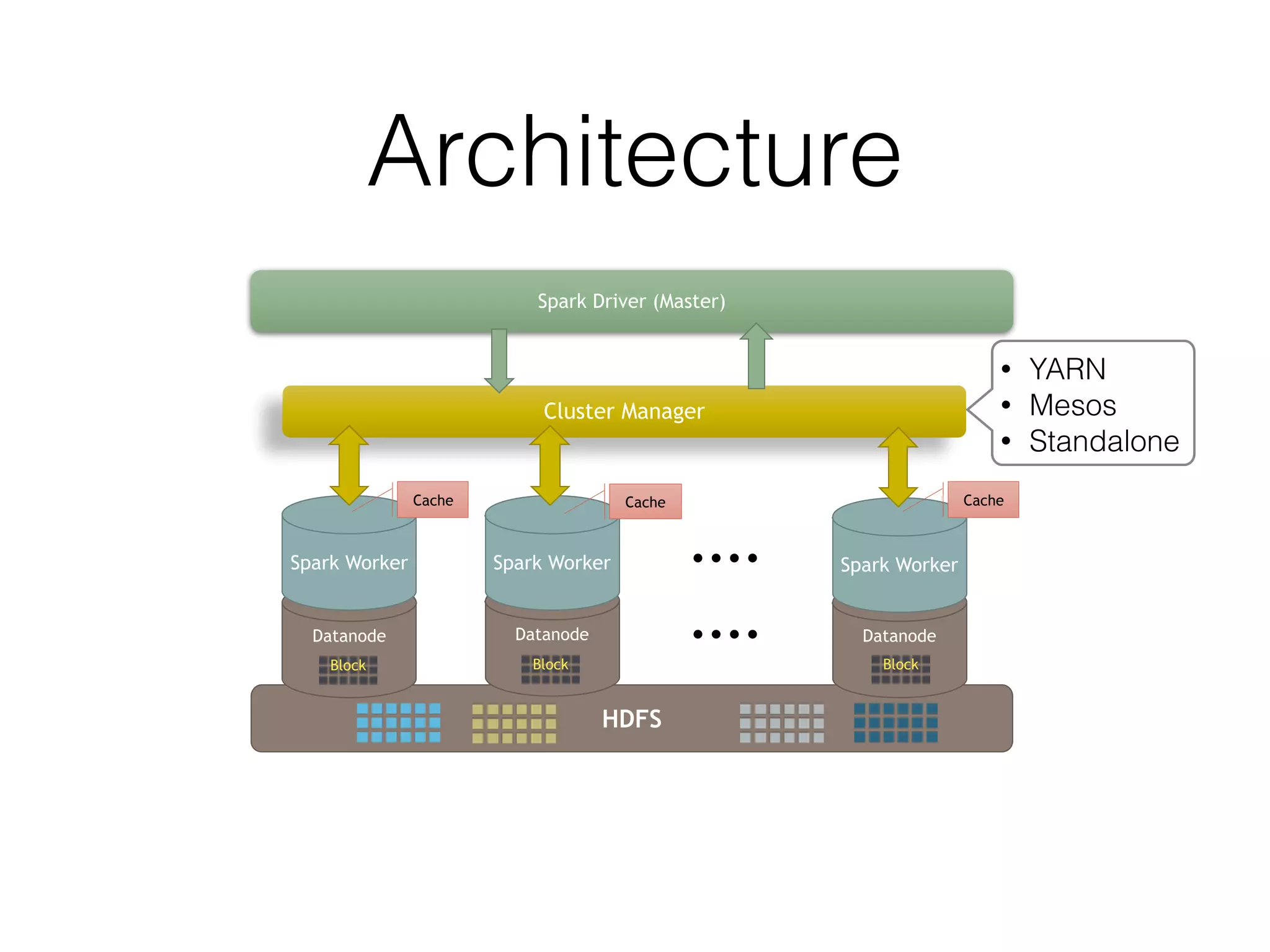
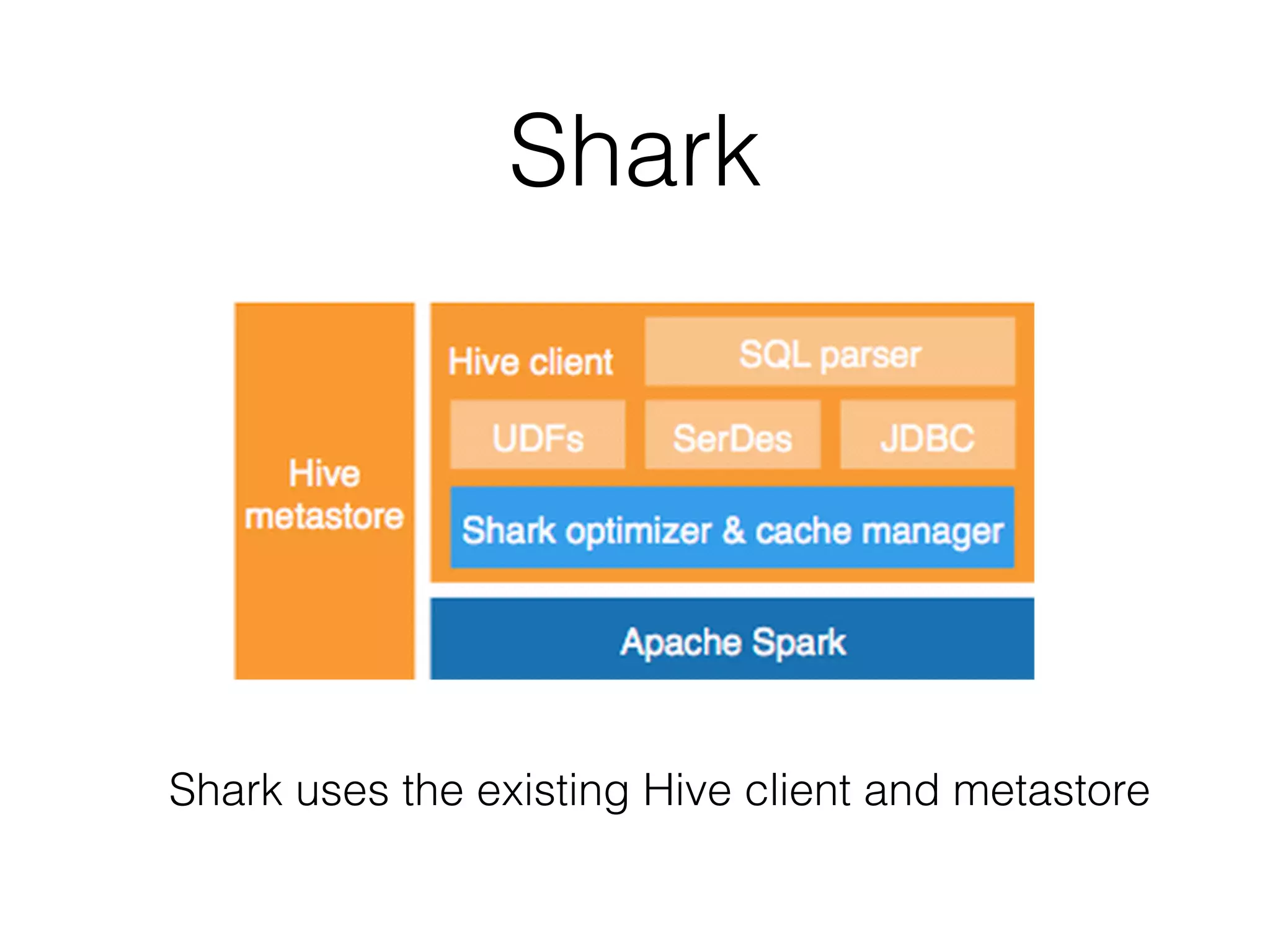
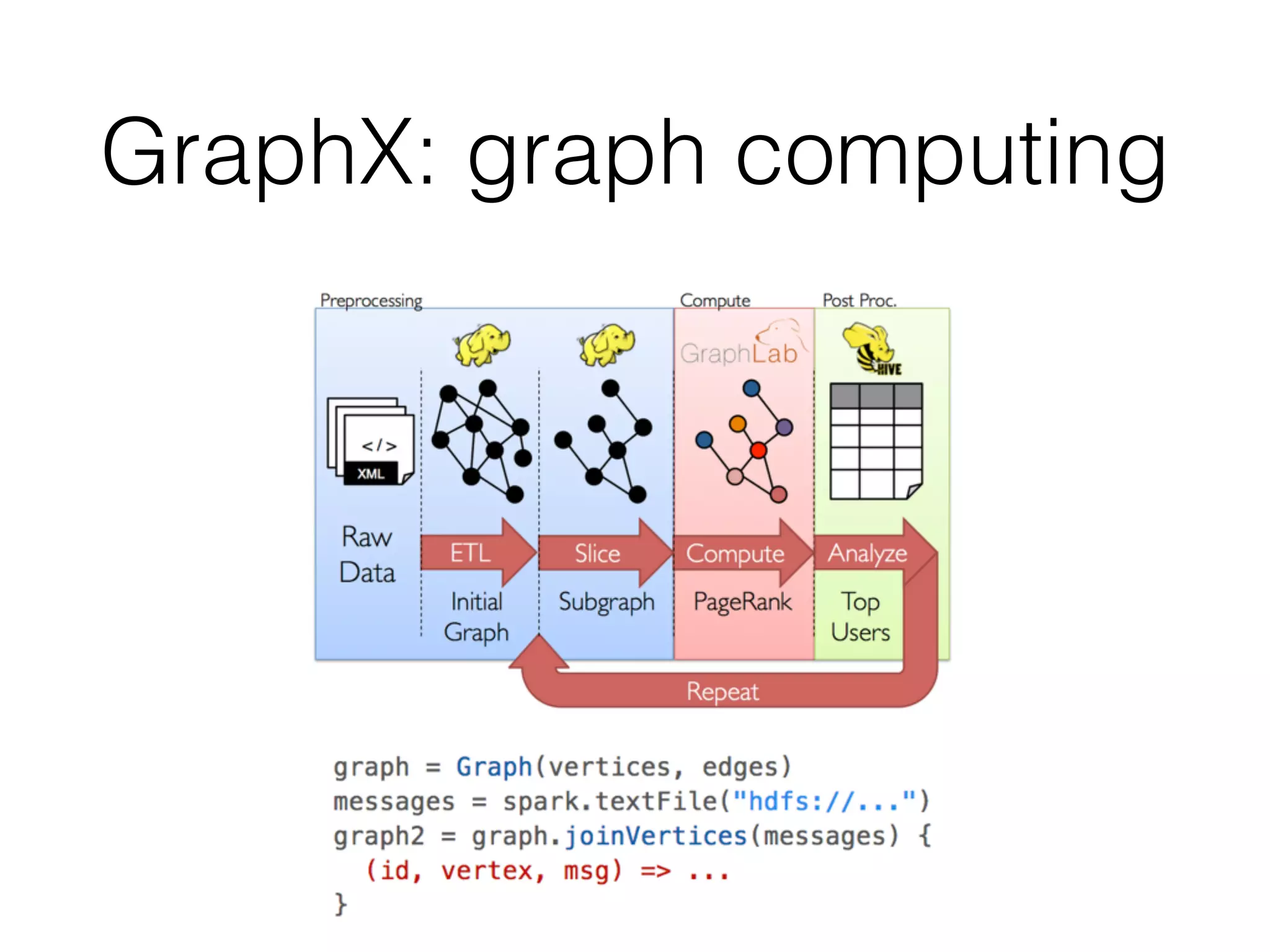
Spark is a general-purpose cluster computing framework that provides high-level APIs and is faster than Hadoop for iterative jobs and interactive queries. It leverages cached data in cluster memory across nodes for faster performance. Spark supports various higher-level tools including SQL, machine learning, graph processing, and streaming.