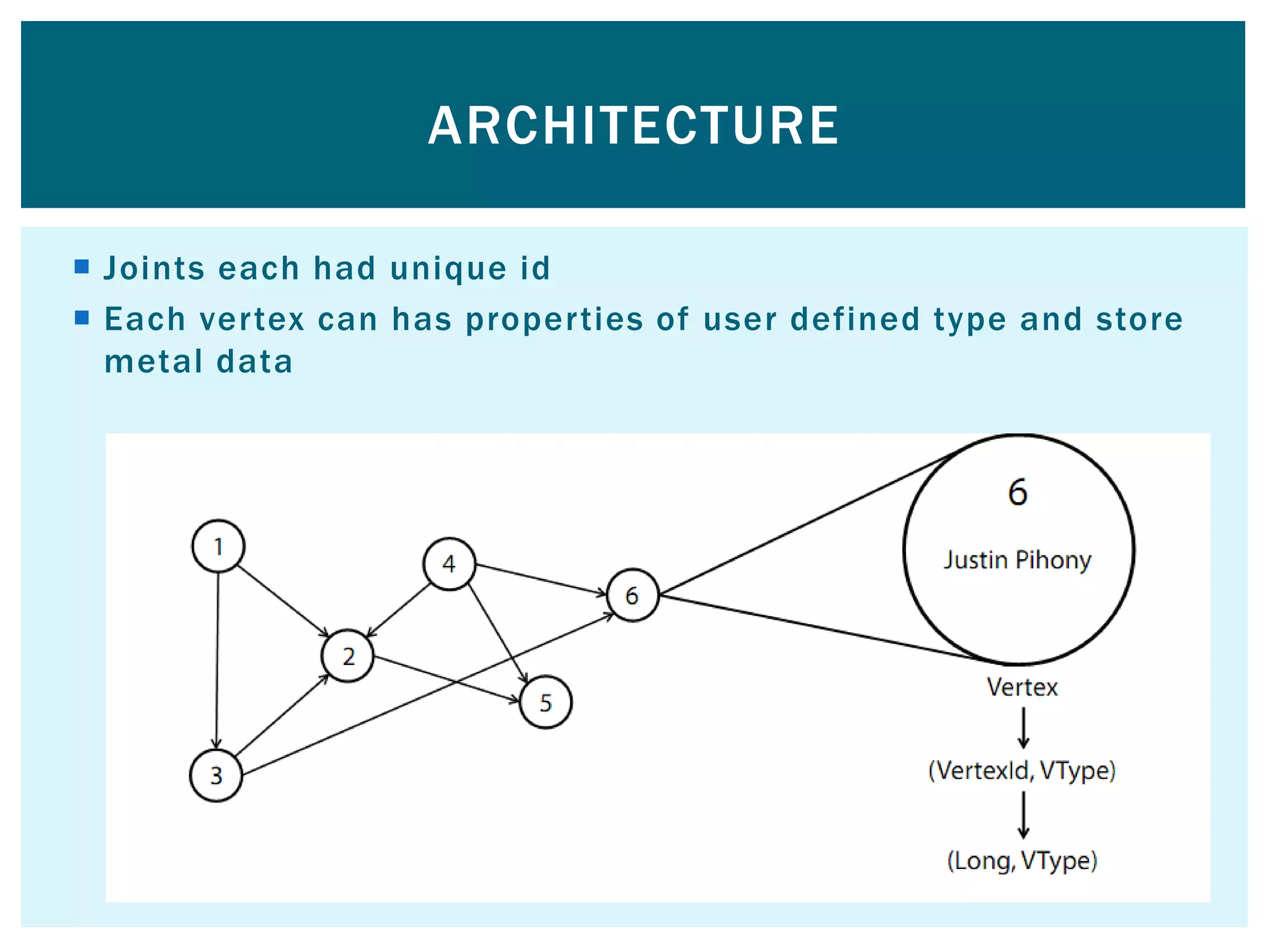
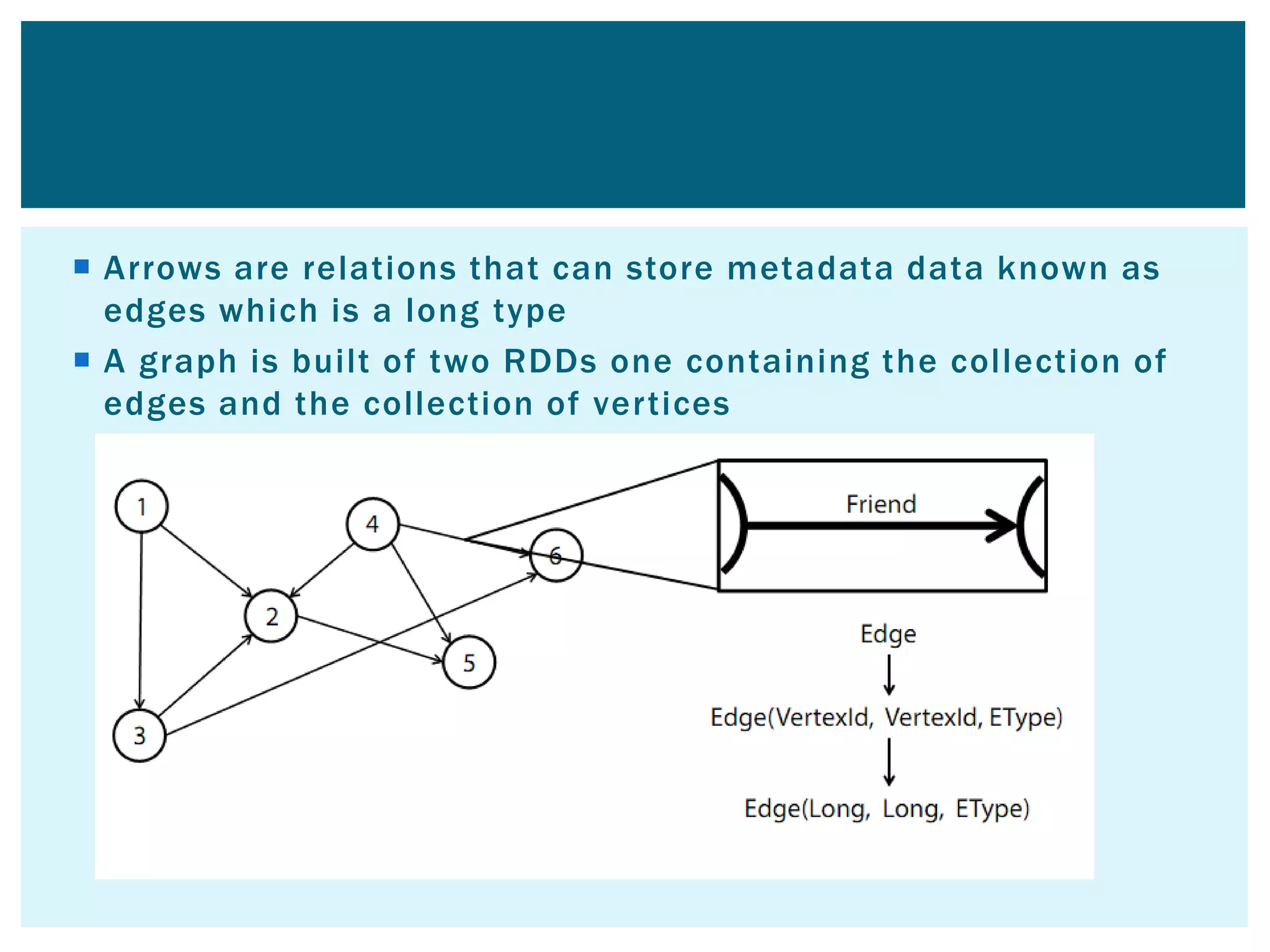
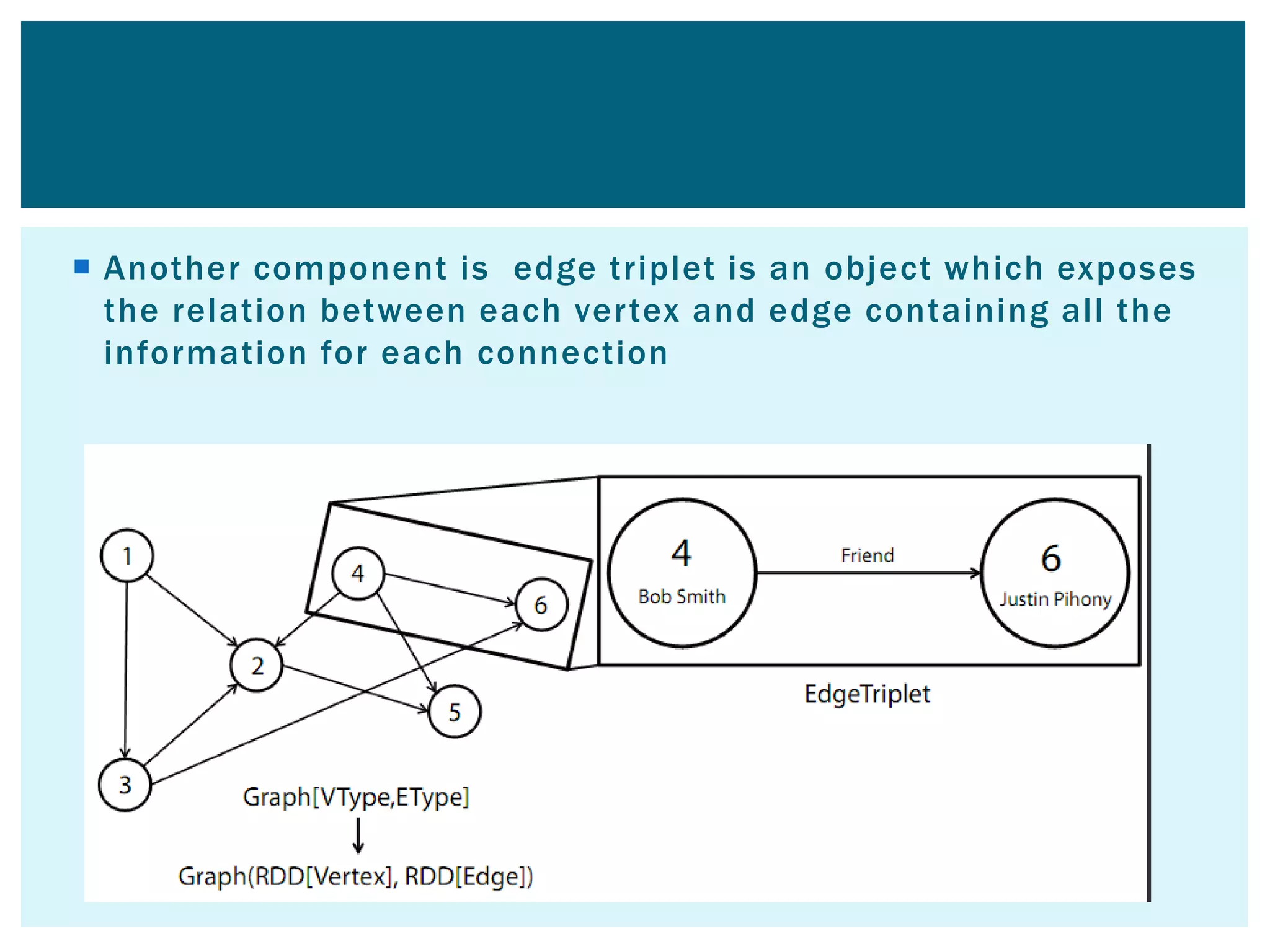
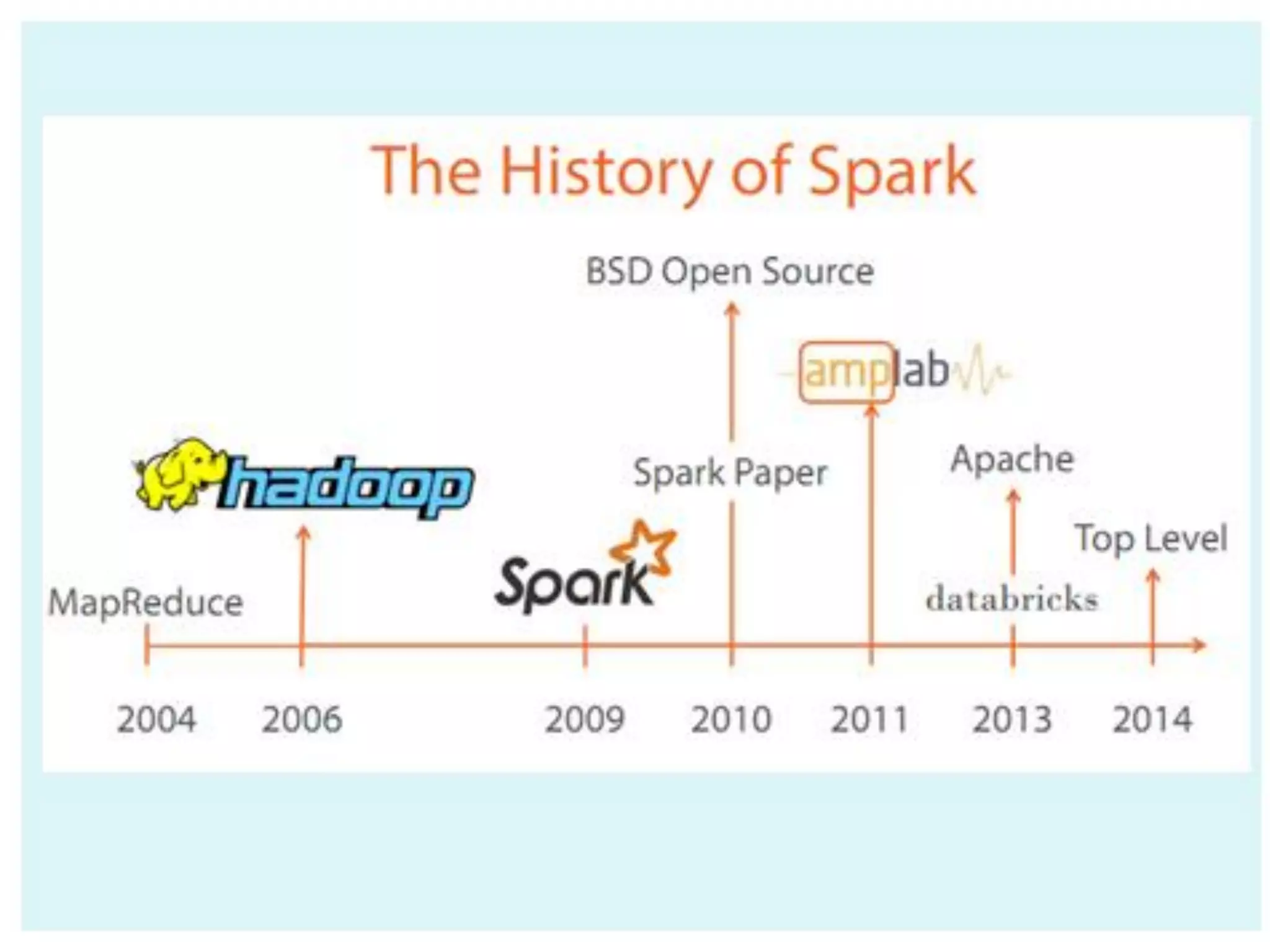
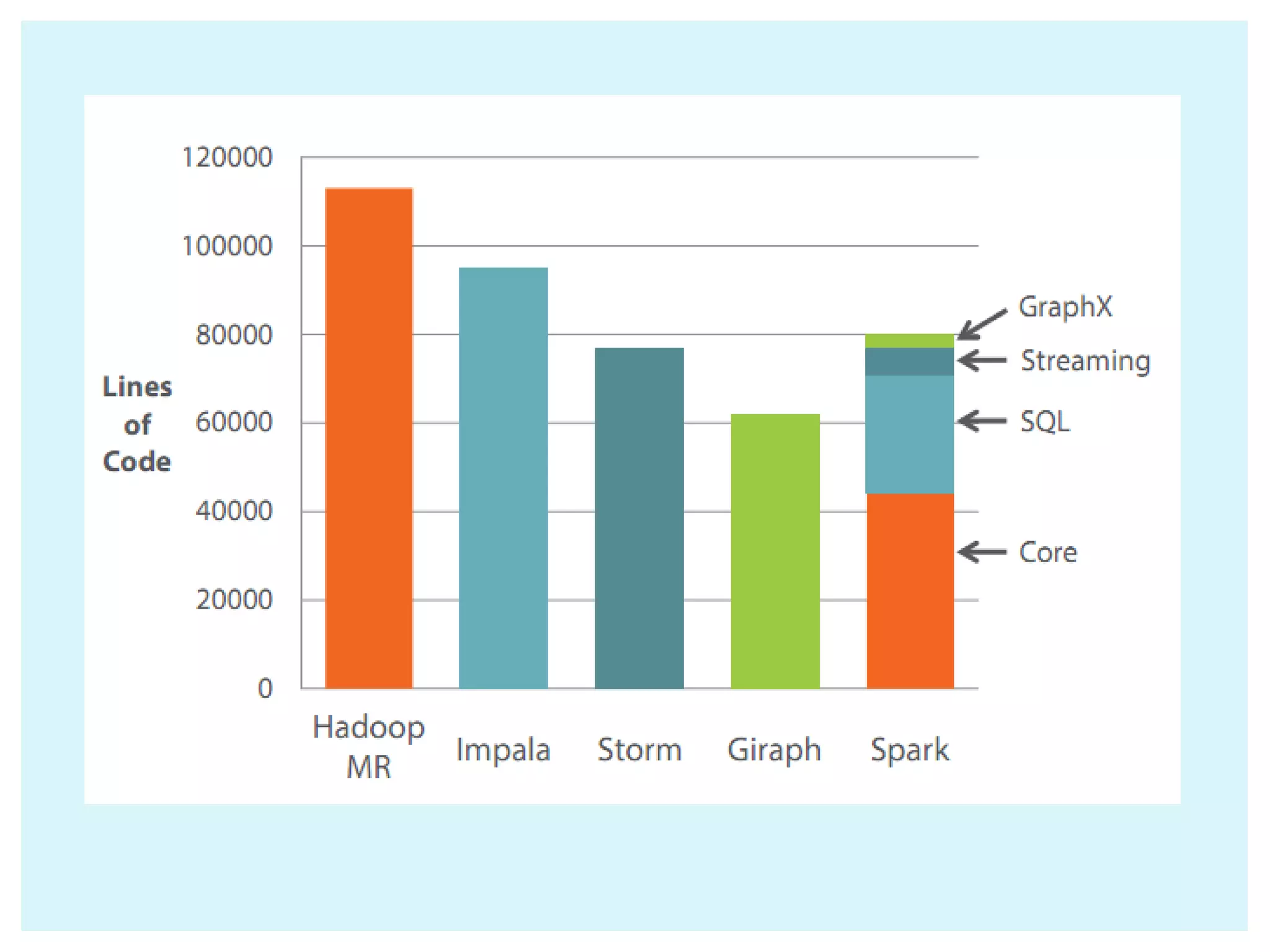
This document provides an overview of Apache Spark, an open-source unified analytics engine for large-scale data processing. It discusses Spark's core APIs including RDDs and transformations/actions. It also covers Spark SQL, Spark Streaming, MLlib, and GraphX. Spark provides a fast and general engine for big data processing, with explicit operations for streaming, SQL, machine learning, and graph processing. The document includes installation instructions and examples of using various Spark components.





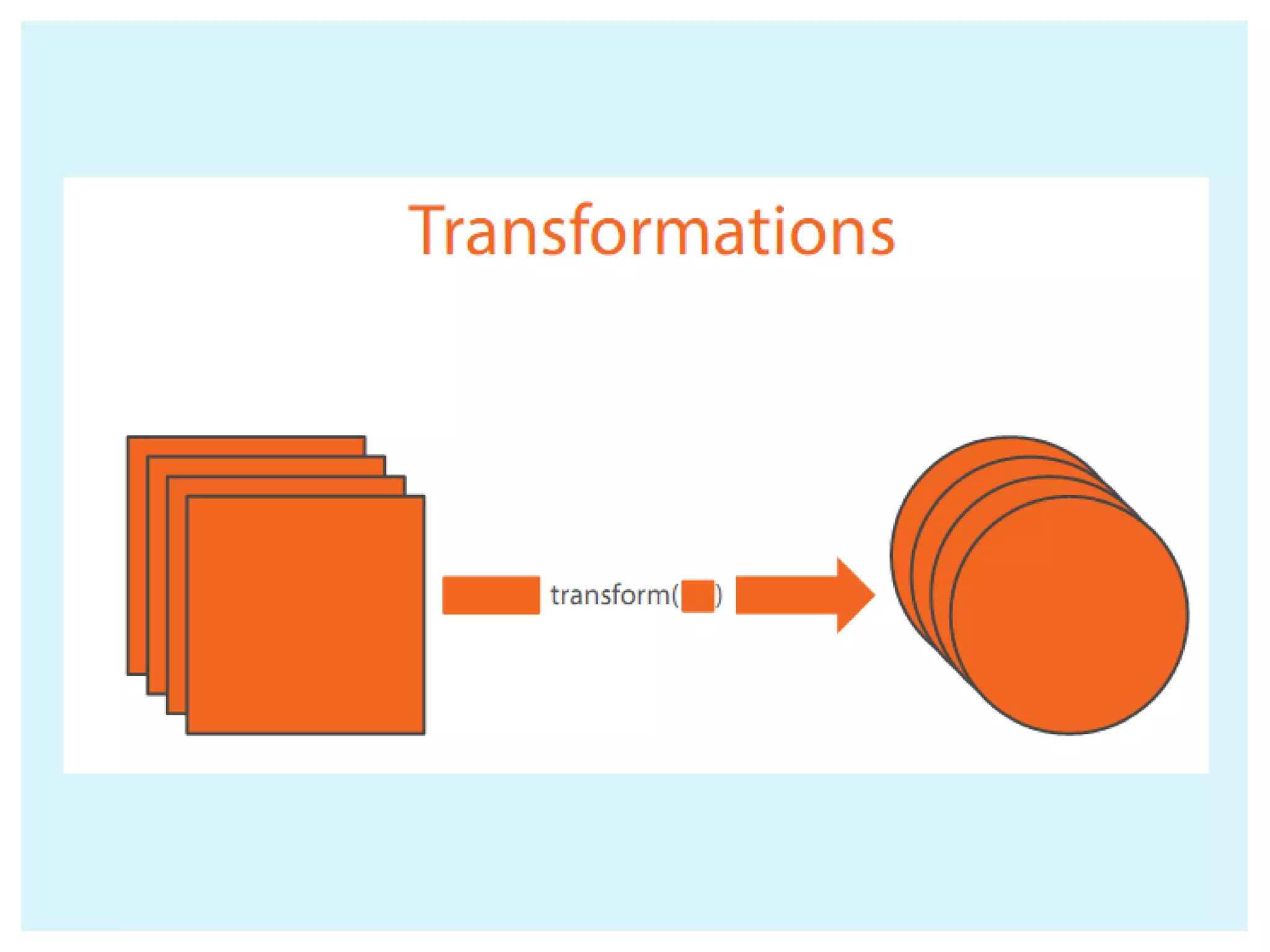
![ The most basic abstraction of spark Spark operations are two main categories: Transformations [lazily evalutaed only storing the intent] Actions val textFile = sc.textFile("file:///spark/README.md") textFile.first // action RDD [RESILIETNT DISTRIBUTION DATASET]](https://image.slidesharecdn.com/apache-spark-180815134328/75/Apache-spark-Architecture-Overview-libraries-10-2048.jpg)






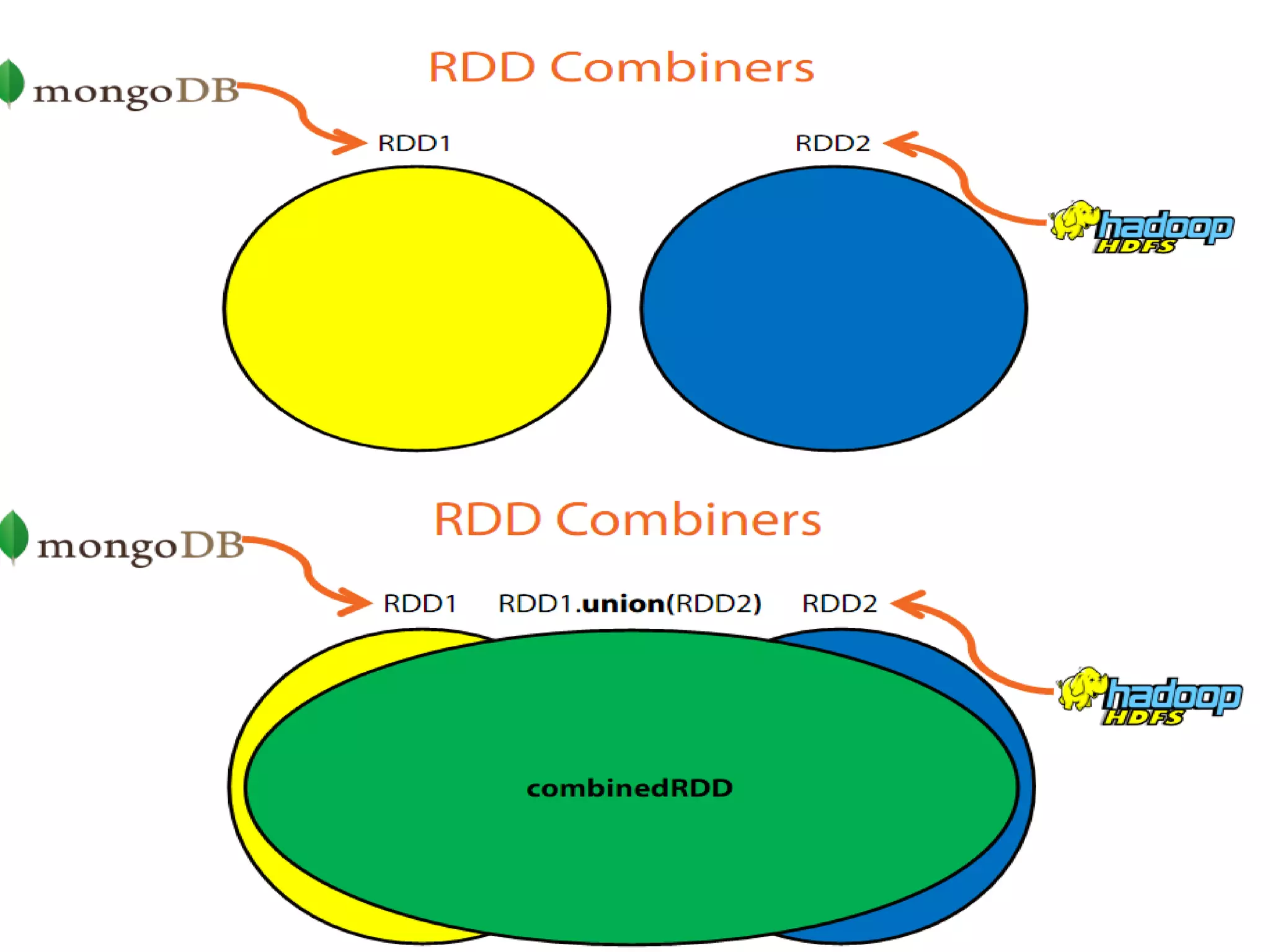
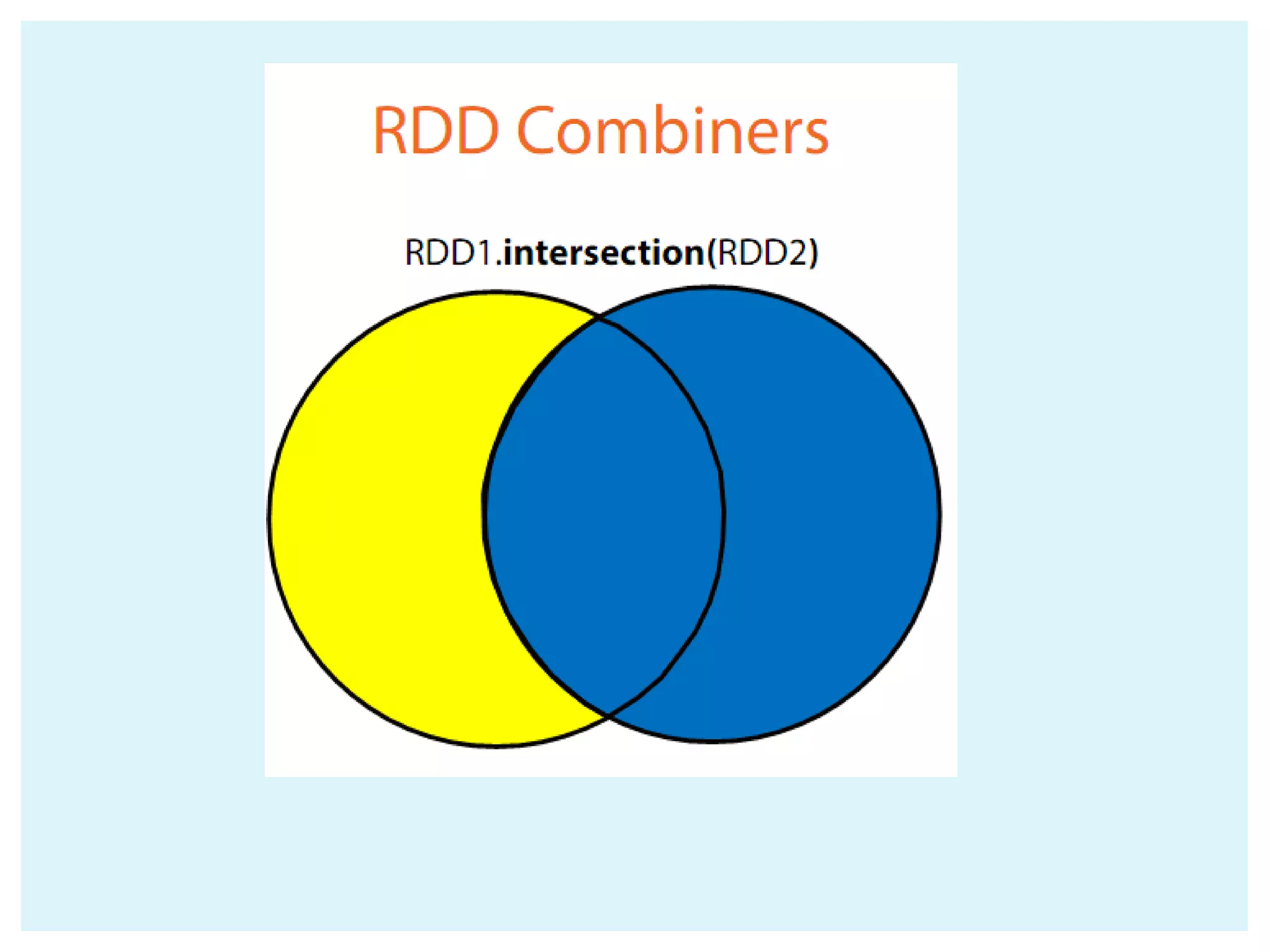
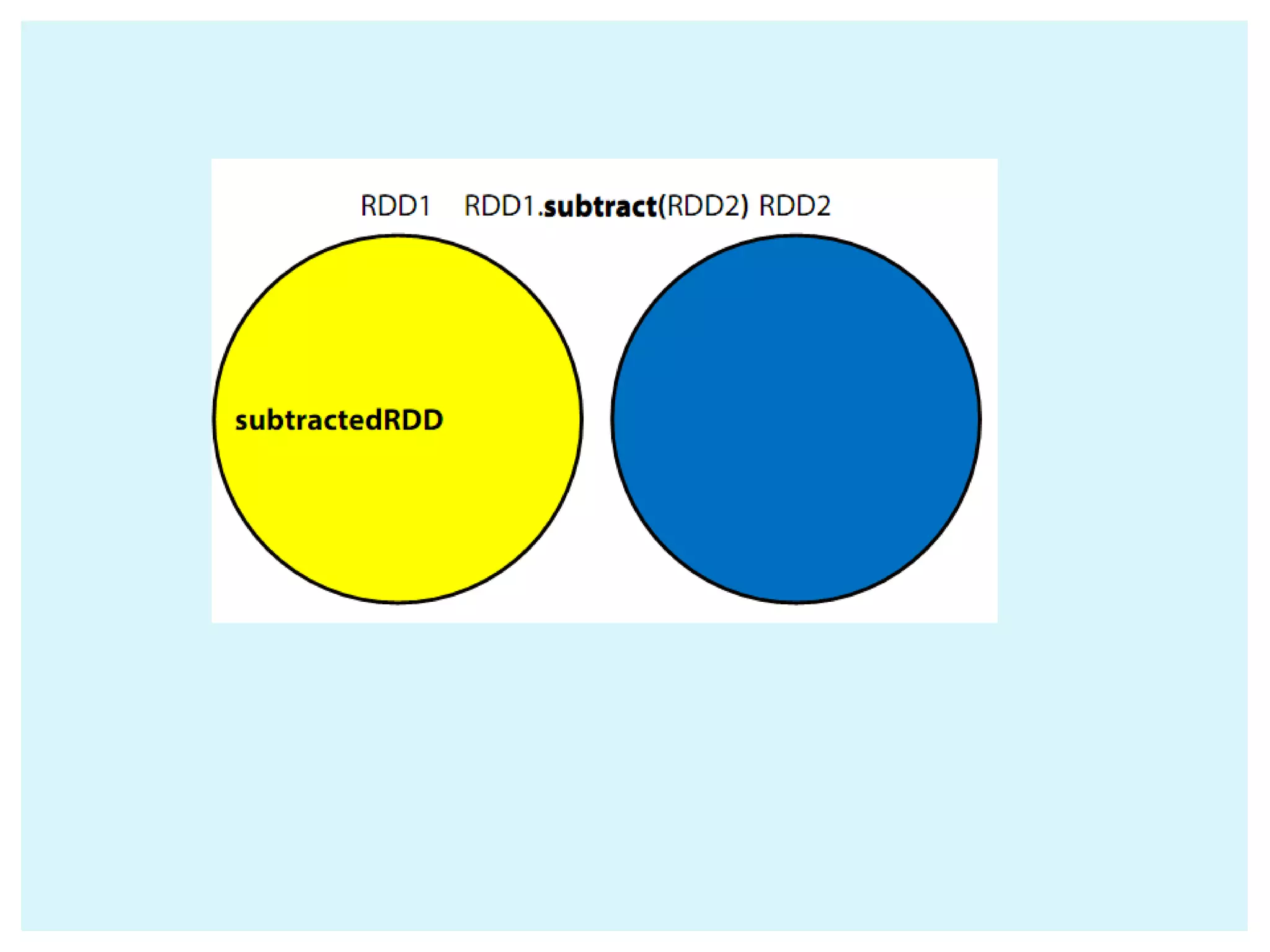
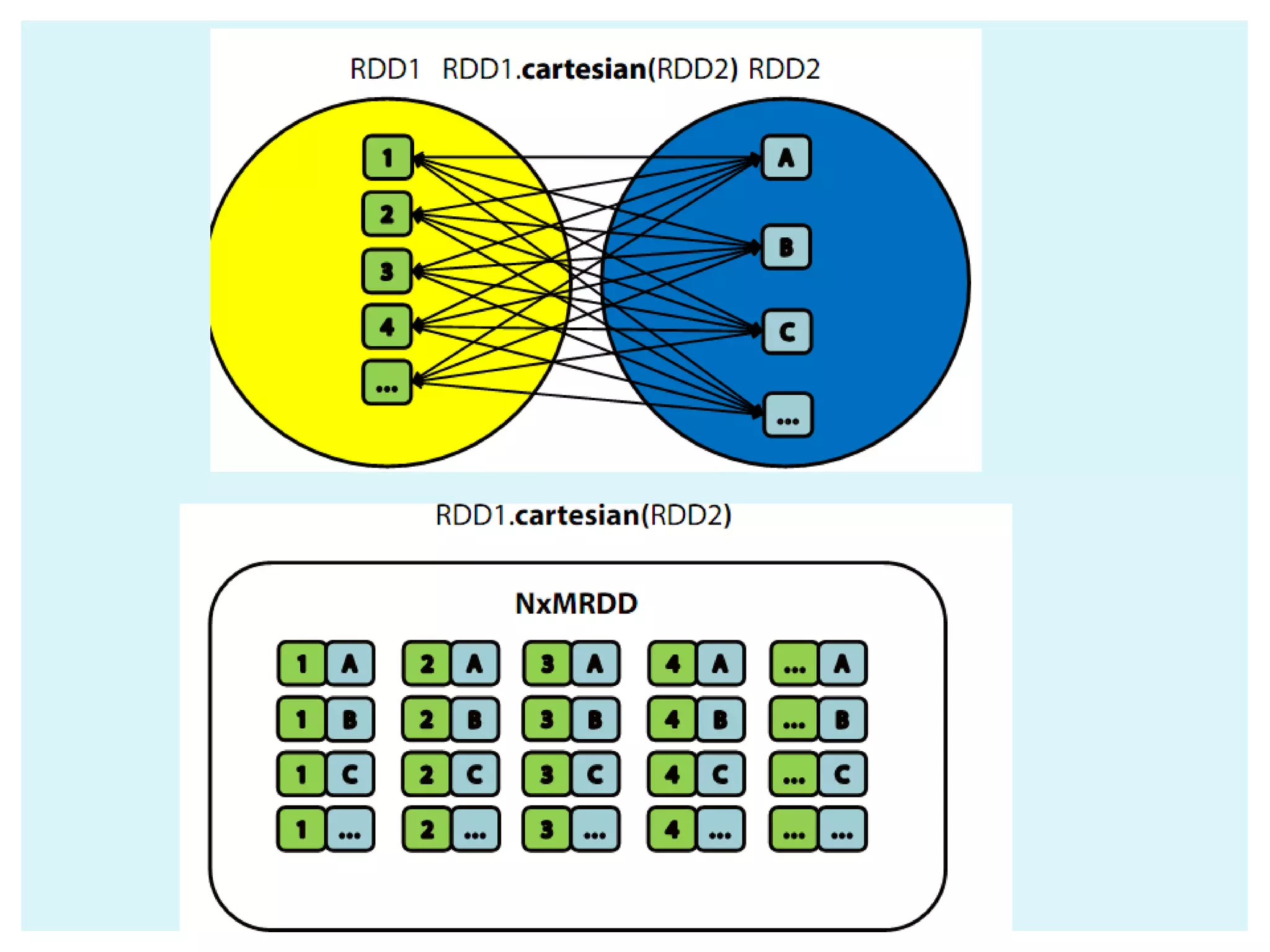
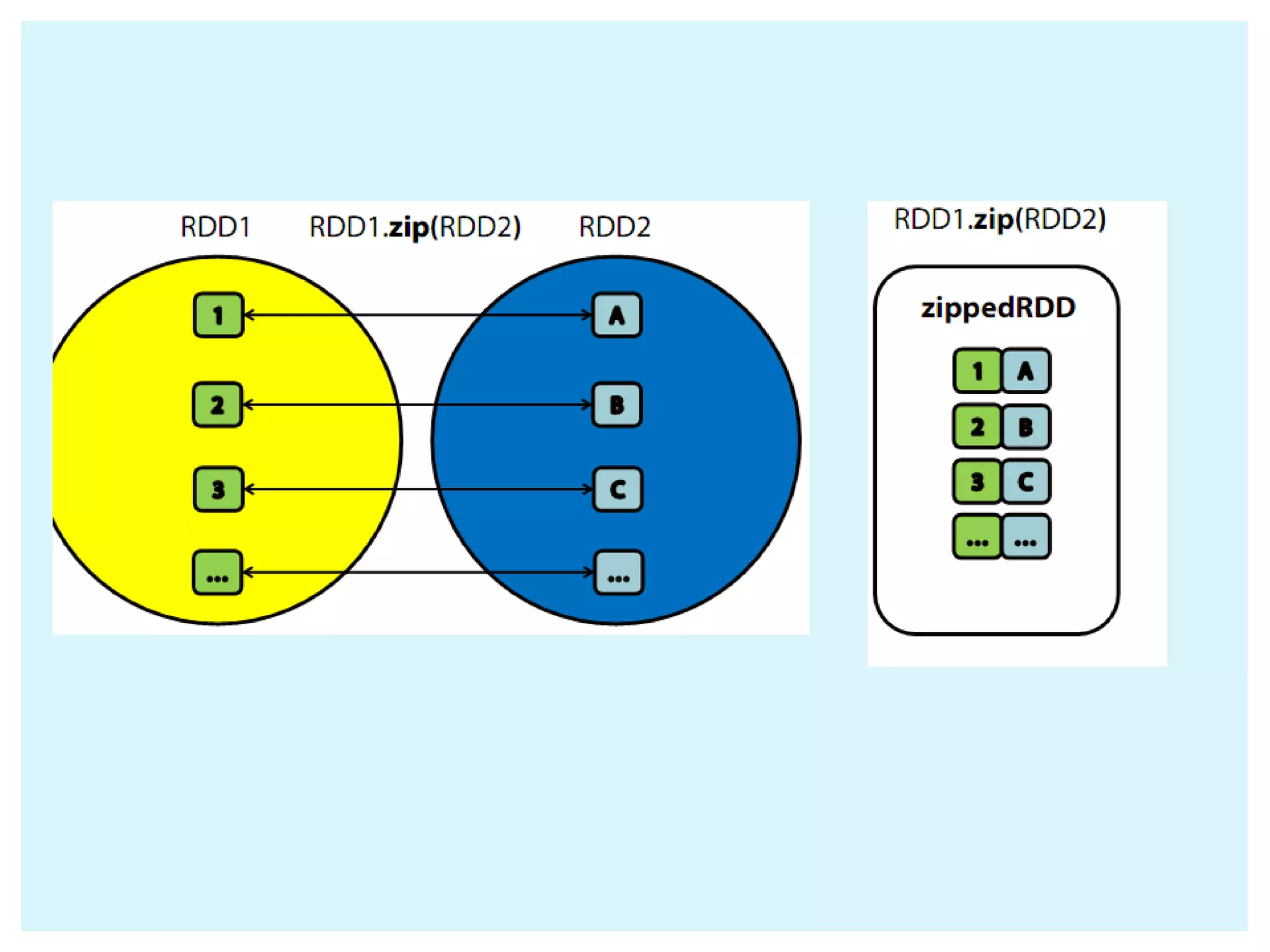
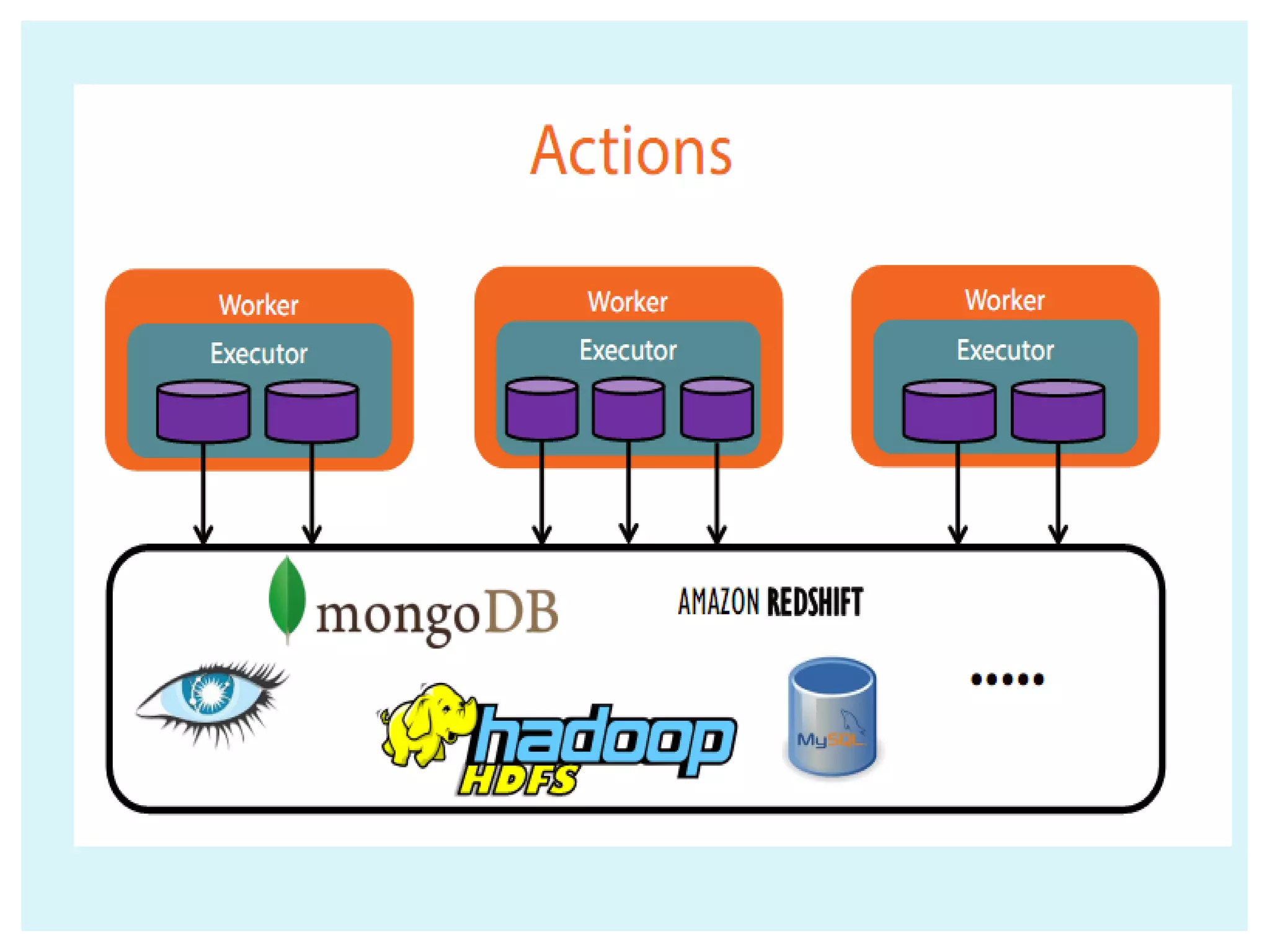
![ Collect() Count() Take(num) takeOrdered(num)(ordering) Reduce(function) Aggregate(zeroValue)(seqOp,compOp) Foreach(function) Actions return different types according to each action saveAsObjectFile(path) saveAsTextFile(path) // saves as text file External connector foreach(T => Unit) // one object at a time - foreachPartition(Iterator[T] => Unit) // one partition at a time ACTIONS IN SPARK](https://image.slidesharecdn.com/apache-spark-180815134328/75/Apache-spark-Architecture-Overview-libraries-24-2048.jpg)








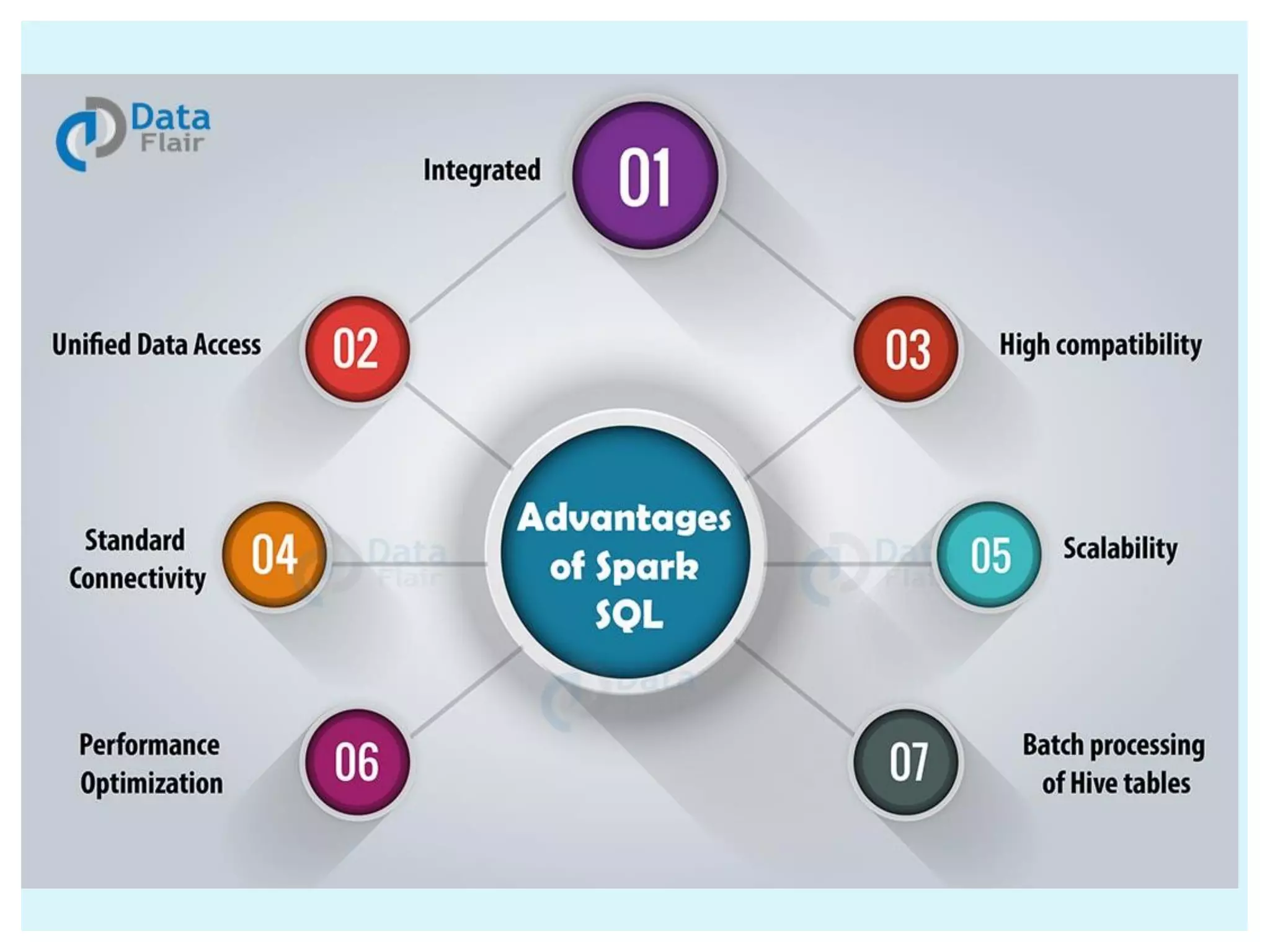
![DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources. Run SQL or HiveQL queries on existing warehouses.[Hive Integration] Connect through JDBC or ODBC.[Standard Connectivity] It is includes with spark DATAFRAMES](https://image.slidesharecdn.com/apache-spark-180815134328/75/Apache-spark-Architecture-Overview-libraries-35-2048.jpg)





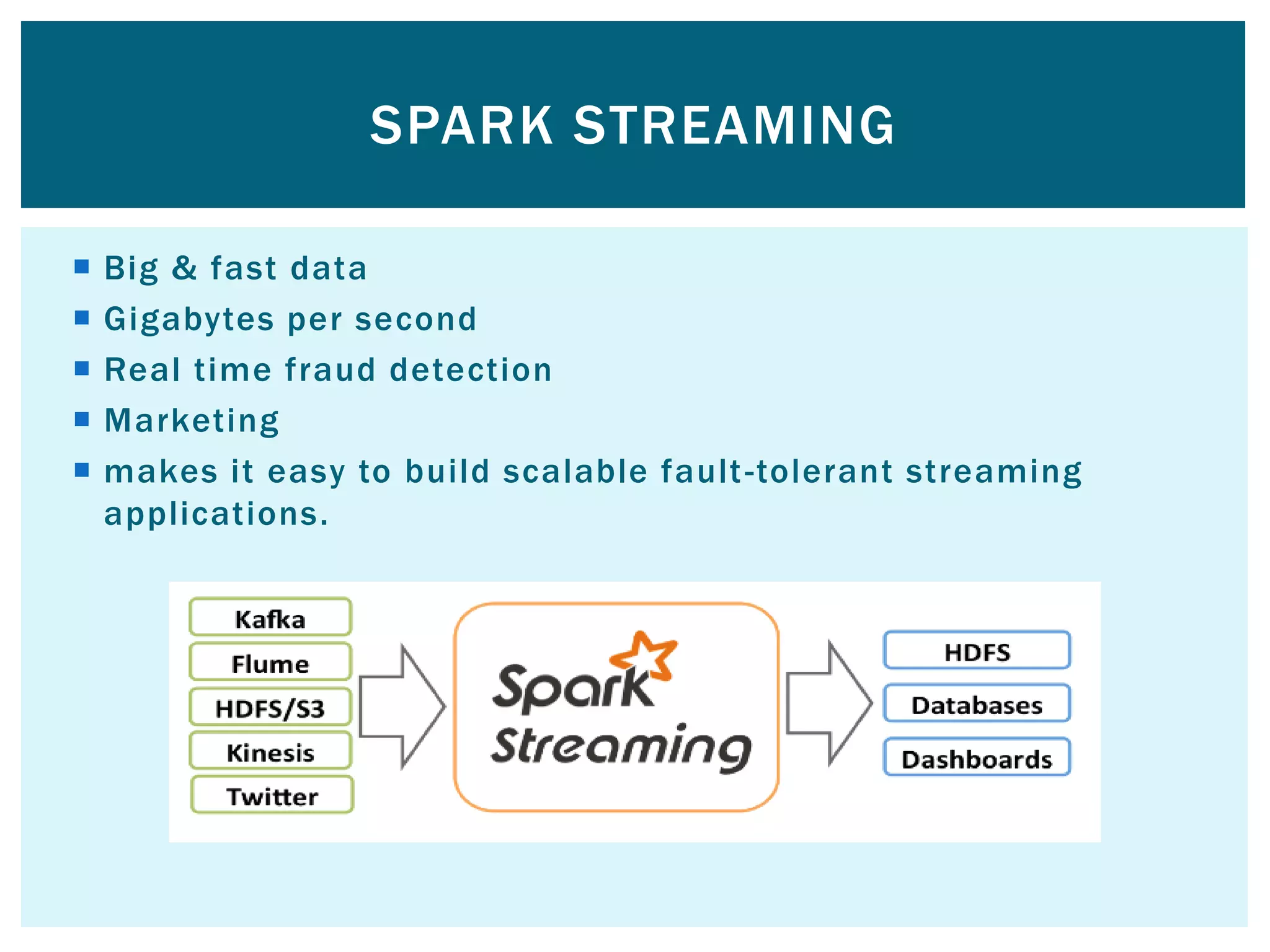
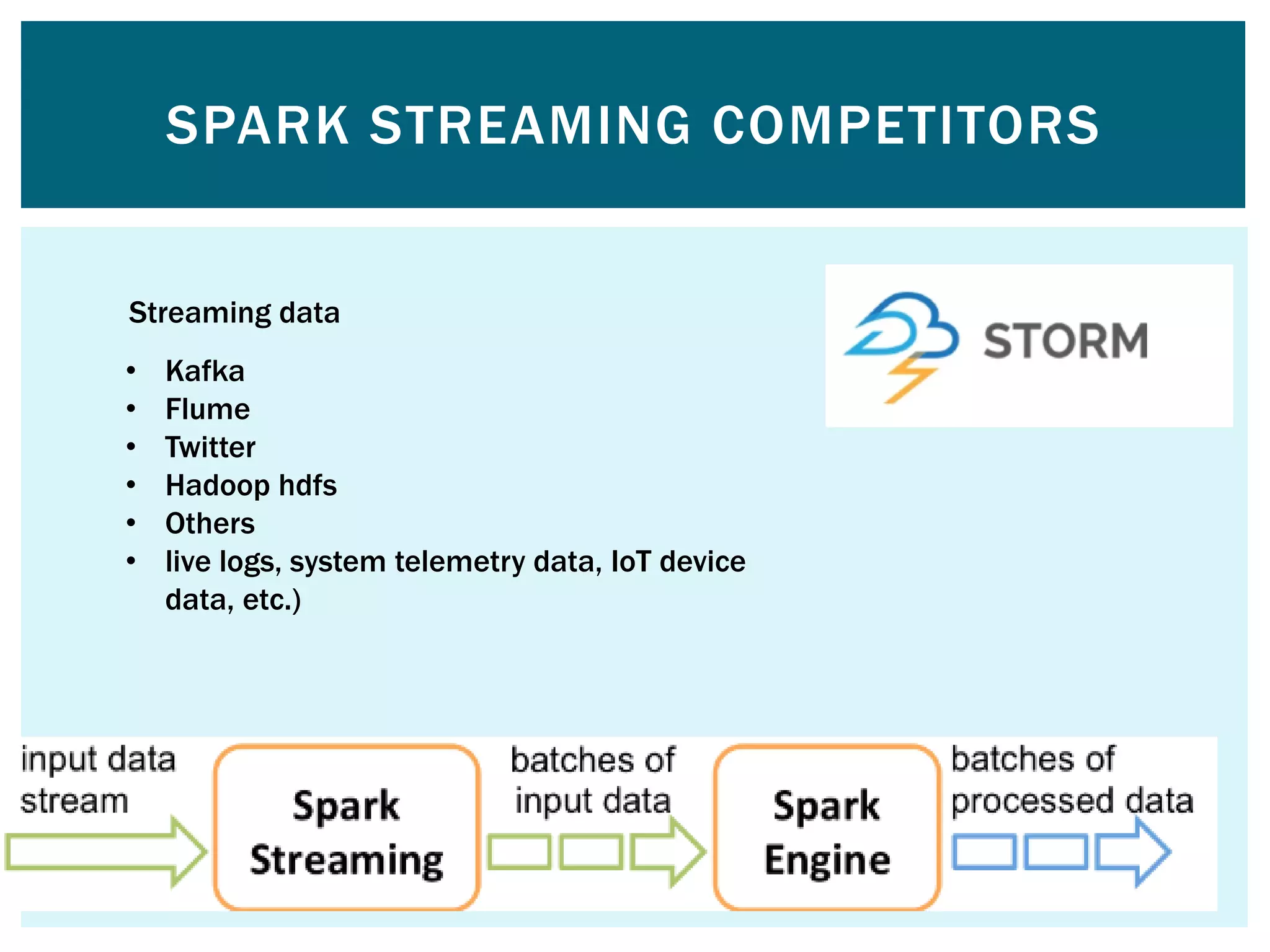



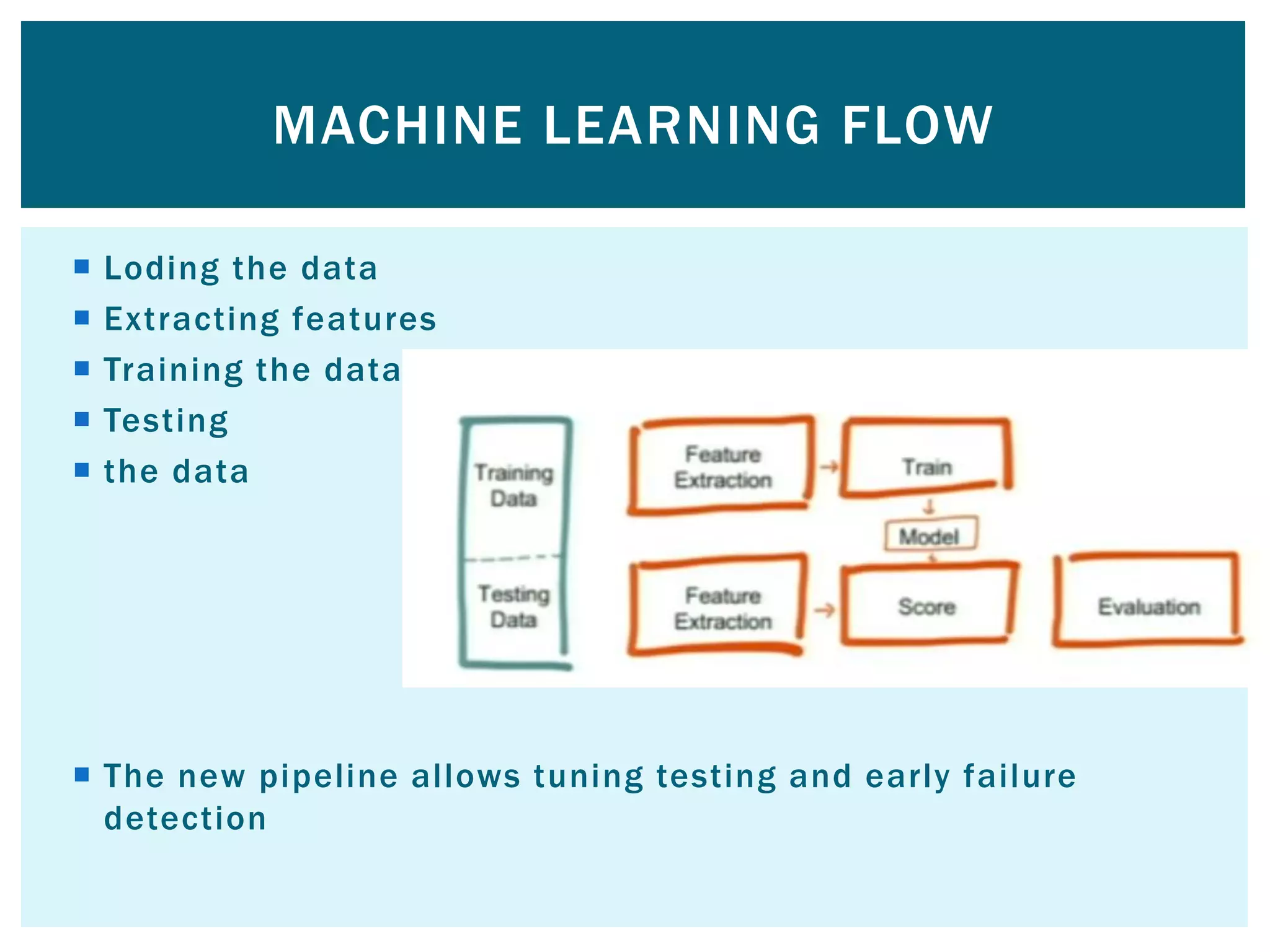


![ Word to vector algorithm This algorithm takes an input text and outputs a set of vectors representing a dictionary of words [to see word similarity] We cache the rdds because mlib will have multiple passes o the same data so this memory cache can reduce processing time alot breeze numerical processing library used inside of spark It has ability to perform mathematical operations on vectors MLIB DEMO](https://image.slidesharecdn.com/apache-spark-180815134328/75/Apache-spark-Architecture-Overview-libraries-49-2048.jpg)