Download as PDF, PPTX




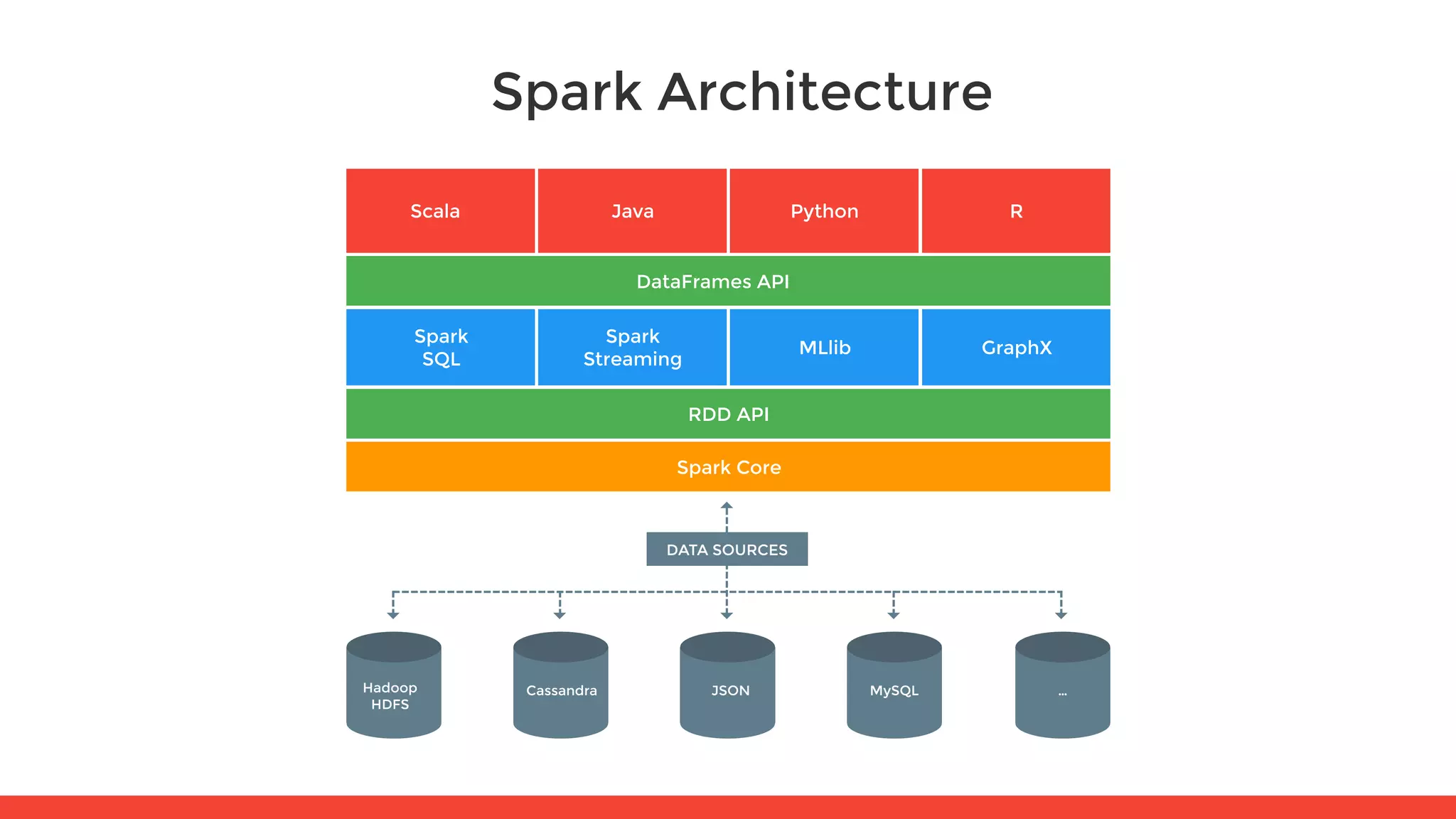
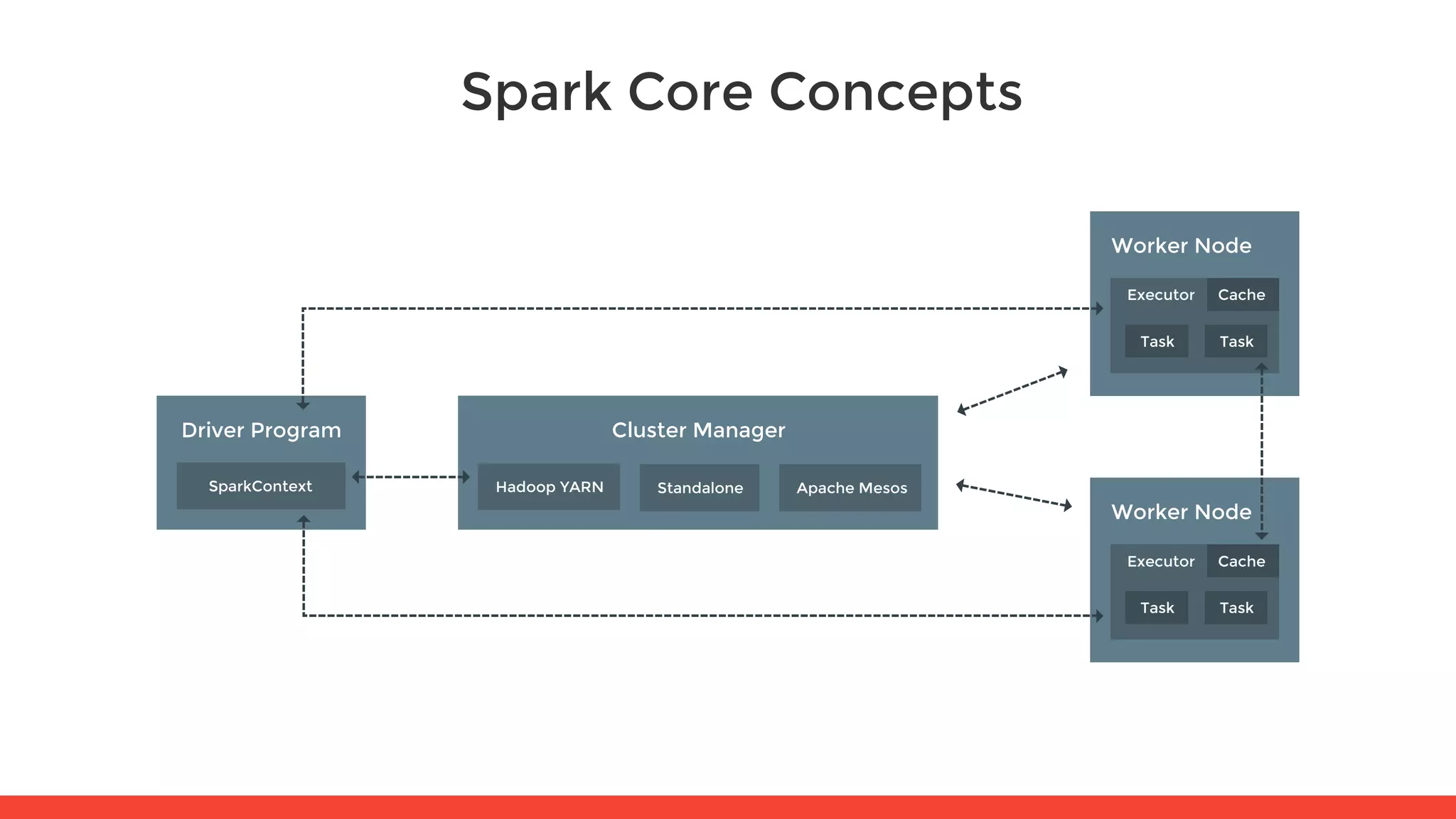



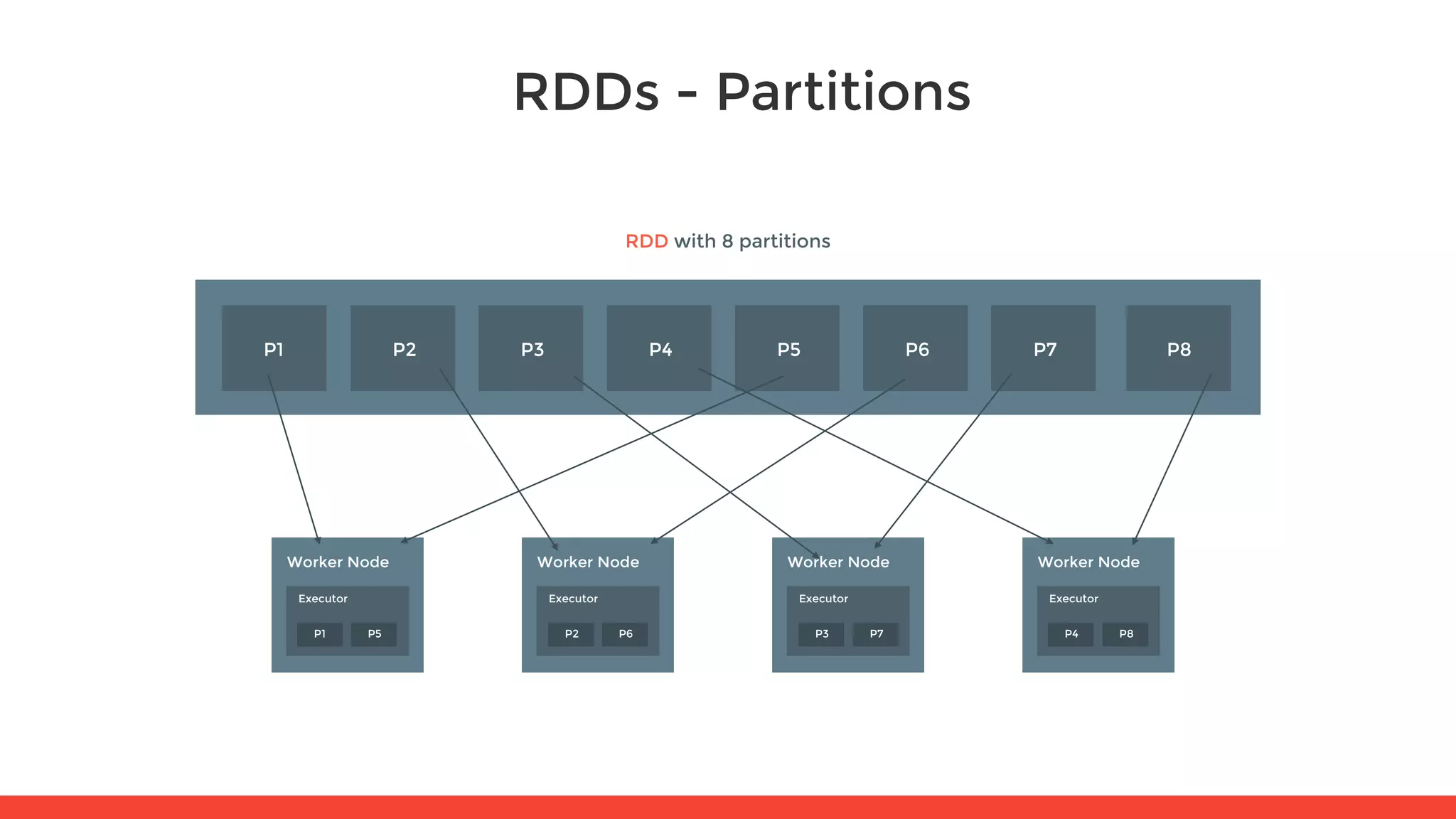







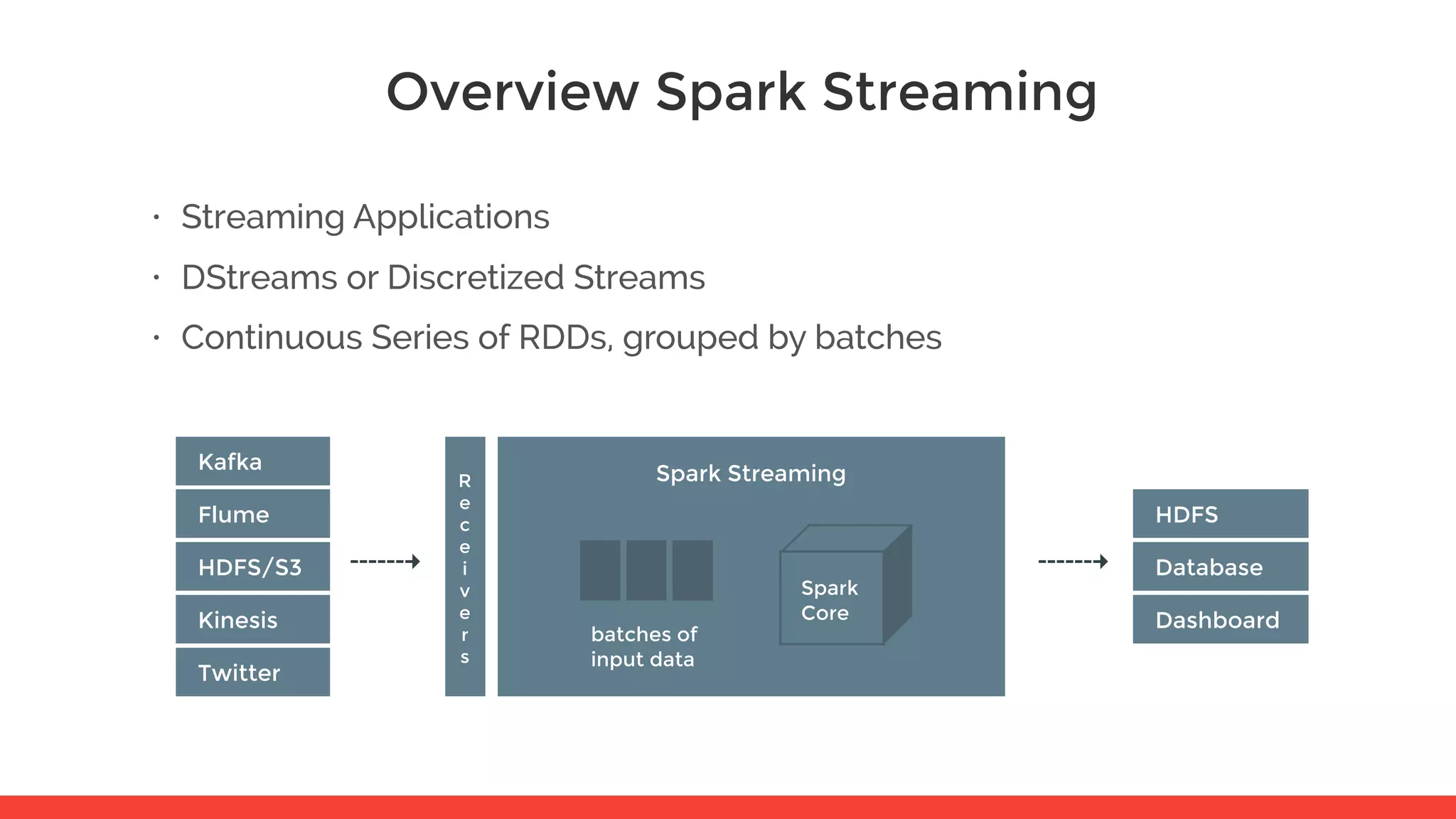


The document introduces Apache Spark and its core concepts, including resilient distributed datasets (RDDs), transformations, and actions. It outlines Spark's architecture, data processing capabilities, and the functionality of Spark SQL and Spark Streaming. Additionally, it provides resources for further learning and practical workshops on the topic.