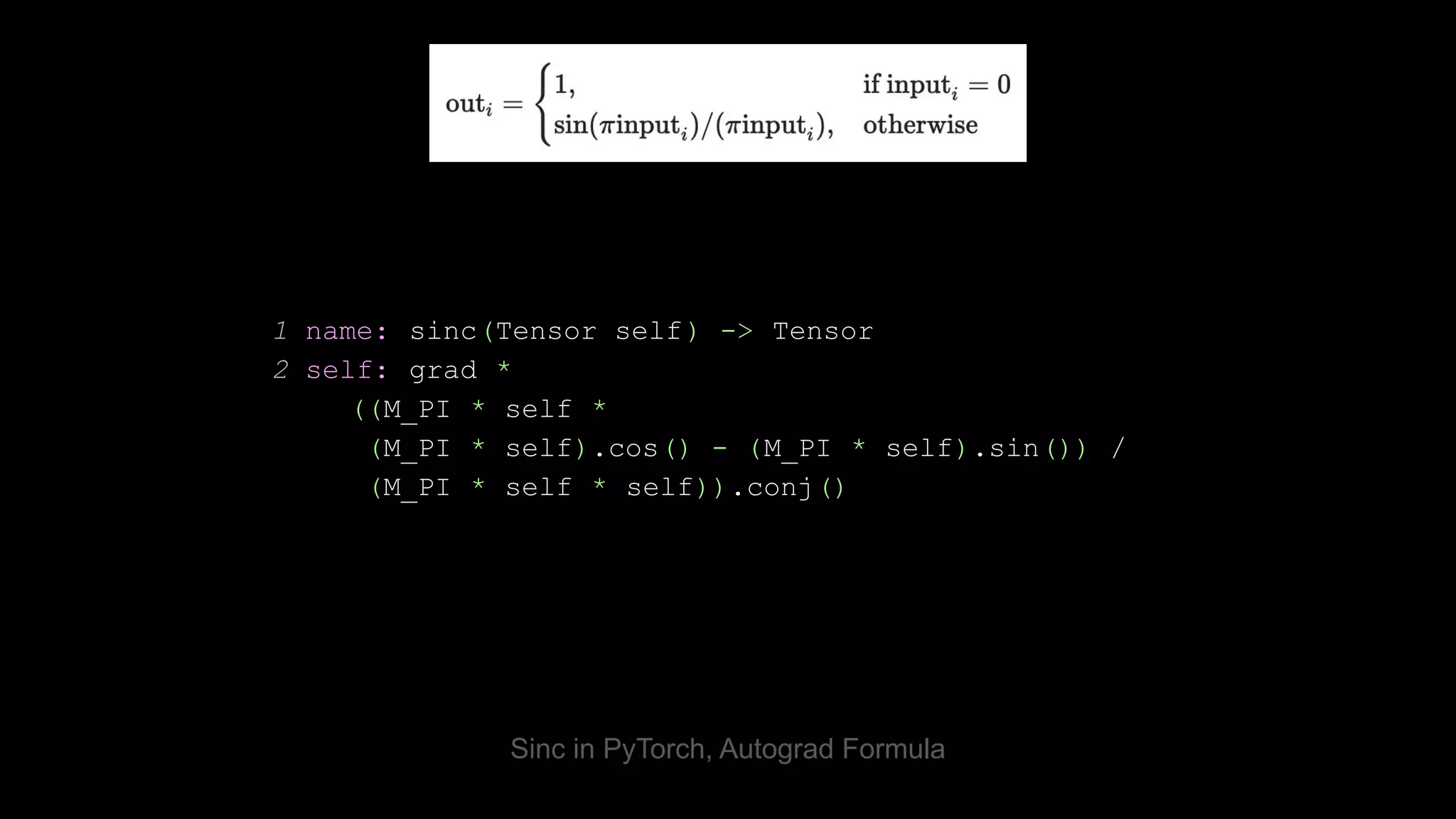
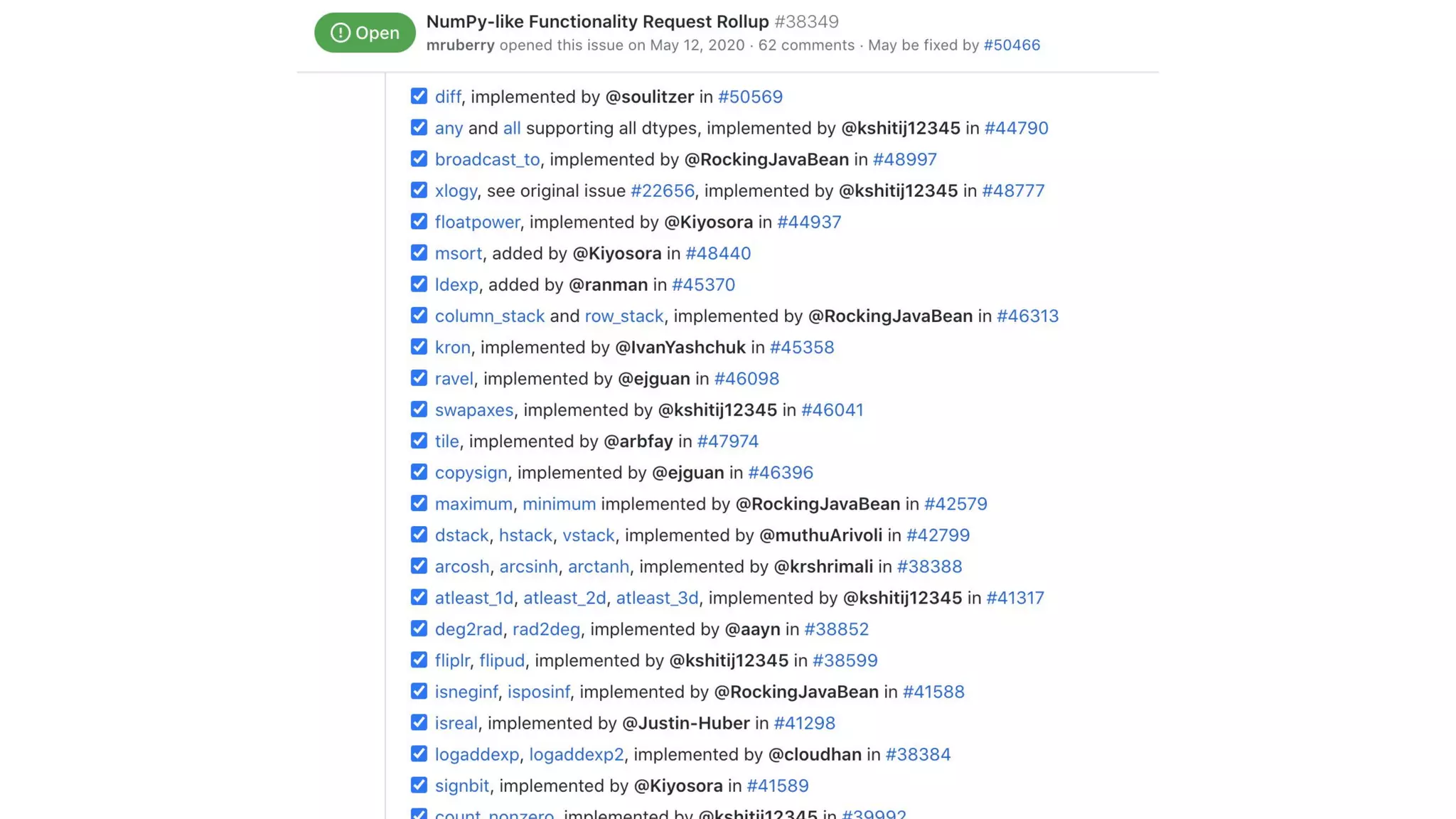
The document discusses porting NumPy operators to PyTorch. It explains that porting requires writing C++ implementations, autograd formulas for differentiable ops, and comprehensive tests. PyTorch's test framework generates tests across tensor properties and devices to validate ops work correctly in various scenarios. The framework and OpInfo metadata makes porting easier and ensures ops are thoroughly tested.



![1 >> import numpy as np 2 >> a = np.array(((1, 2), (3, 4))) array([[1, 2], [3, 4]]) 3 >> b = np.array(((-1, -2), (-3, -4))) 4 >> np.add(a, b) array([[0, 0], [0, 0]]) 5 >> np.matmul(a, b) array([[ -7, -10], [-15, -22]]) Simple NumPy Snippets](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-4-2048.jpg)
![1 >> import numpy as np 2 >> a = np.array(((1, 2), (3, 4))) array([[1, 2], [3, 4]]) 3 >> b = np.array(((-1, -2), (-3, -4))) 4 >> np.add(a, b) array([[0, 0], [0, 0]]) 5 >> np.matmul(a, b) array([[ -7, -10], [-15, -22]]) Simple NumPy Snippets Tensor creation](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-5-2048.jpg)
![1 >> import numpy as np 2 >> a = np.array(((1, 2), (3, 4))) array([[1, 2], [3, 4]]) 3 >> b = np.array(((-1, -2), (-3, -4))) 4 >> np.add(a, b) array([[0, 0], [0, 0]]) 5 >> np.matmul(a, b) array([[ -7, -10], [-15, -22]]) Simple NumPy Snippets Addition](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-6-2048.jpg)
![1 >> import numpy as np 2 >> a = np.array(((1, 2), (3, 4))) array([[1, 2], [3, 4]]) 3 >> b = np.array(((-1, -2), (-3, -4))) 4 >> np.add(a, b) array([[0, 0], [0, 0]]) 5 >> np.matmul(a, b) array([[ -7, -10], [-15, -22]]) Simple NumPy Snippets Matrix multiplication](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-7-2048.jpg)
![1 >> np.fft.fft(np.exp(2j * np.pi * np.arange(8) / 8)) array([-3.44509285e-16 +1.14423775e-17 j, 8.00000000e+00 -8.11483250e-16 j, 2.33486982e-16 +1.22464680e-16 j, 0.00000000e+00 +1.22464680e-16 j, 9.95799250e-17 +2.33486982e-16 j, 0.00000000e+00 +7.66951701e-17 j, 1.14423775e-17 +1.22464680e-16 j, 0.00000000e+00 +1.22464680e-16 j]) 2 >> A = np.array([[1,-2j],[2j,5]]) 3 >> np.linalg.cholesky(A) array([[1.+0.j, 0.+0.j], [0.+2.j, 1.+0.j]]) More Complicated NumPy Snippets](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-8-2048.jpg)


![1 >> import numpy as np 2 >> a = np.array(((1, 2), (3, 4))) array([[1, 2], [3, 4]]) 3 >> b = np.array(((-1, -2), (-3, -4))) 4 >> np.add(a, b) array([[0, 0], [0, 0]]) 5 >> np.matmul(a, b) array([[ -7, -10], [-15, -22]]) Simple NumPy Snippets (Again)](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-12-2048.jpg)
![1 >> import torch 2 >> a = torch.tensor(((1, 2), (3, 4))) tensor([[1, 2], [3, 4]]) 3 >> b = np.array(((-1, -2), (-3, -4))) 4 >> np.add(a, b) array([[0, 0], [0, 0]]) 5 >> np.matmul(a, b) array([[ -7, -10], [-15, -22]]) Simple NumPy Snippets to PyTorch Snippets Tensor creation](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-13-2048.jpg)
![1 >> import torch 2 >> a = torch.tensor(((1, 2), (3, 4))) tensor([[1, 2], [3, 4]]) 3 >> b = torch.tensor(((-1, -2), (-3, -4))) 4 >> torch.add(a, b) tensor([[0, 0], [0, 0]]) 5 >> np.matmul(a, b) array([[ -7, -10], [-15, -22]]) Addition Simple NumPy Snippets to PyTorch Snippets](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-14-2048.jpg)
![1 >> import torch 2 >> a = torch.tensor(((1, 2), (3, 4))) tensor([[1, 2], [3, 4]]) 3 >> b = torch.tensor(((-1, -2), (-3, -4))) 4 >> torch.add(a, b) tensor([[0, 0], [0, 0]]) 5 >> torch.matmul(a, b) tensor([[ -7, -10], [-15, -22]]) Simple NumPy Snippets to PyTorch Snippets Matrix multiplication](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-15-2048.jpg)
![1 >> import torch 2 >> a = torch.tensor(((1, 2), (3, 4))) tensor([[1, 2], [3, 4]]) 3 >> b = torch.tensor(((-1, -2), (-3, -4))) 4 >> torch.add(a, b) tensor([[0, 0], [0, 0]]) 5 >> torch.matmul(a, b) tensor([[ -7, -10], [-15, -22]]) Simple PyTorch Snippets](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-16-2048.jpg)
![1 >> np.fft.fft(np.exp(2j * np.pi * np.arange(8) / 8)) array([-3.44509285e-16 +1.14423775e-17 j, 8.00000000e+00 -8.11483250e-16 j, 2.33486982e-16 +1.22464680e-16 j, 0.00000000e+00 +1.22464680e-16 j, 9.95799250e-17 +2.33486982e-16 j, 0.00000000e+00 +7.66951701e-17 j, 1.14423775e-17 +1.22464680e-16 j, 0.00000000e+00 +1.22464680e-16 j]) 2 >> A = np.array([[1,-2j],[2j,5]]) 3 >> np.linalg.cholesky(A) array([[1.+0.j, 0.+0.j], [0.+2.j, 1.+0.j]]) More Complicated NumPy Snippets (Again)](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-17-2048.jpg)
![1 >> torch.fft.fft(torch.exp(2j * math.pi * torch.arange(8) / 8)) 2 tensor([ 3.2584e-07+3.1787e-08j, 8.0000e+00+4.8023e-07j, 3 -3.2584e-07+3.1787e-08j, -1.6859e-07+3.1787e-08j, 4 -3.8941e-07-2.0663e-07j, 1.3691e-07-1.9412e-07j, 5 3.8941e-07-2.0663e-07j, 1.6859e-07+3.1787e-08j]) 1 >> A = torch.tensor([[1,-2j],[2j,5]]) 2 >> torch.linalg.cholesky(A) 3 tensor([[1.+0.j, 0.+0.j], 4 [0.+2.j, 1.+0.j]]) More Complicated PyTorch Snippets](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-18-2048.jpg)
![1 >> t = torch.tensor((1, 2, 3)) 2 >> a = t.numpy() 3 array([1, 2, 3]) 3 >> b = np.array((-1, -2, -3)) 4 >> result = a + b array([0, 0, 0]) 5 >> torch.from_numpy(result) tensor([0, 0, 0]) PyTorch and NumPy Interoperability](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-19-2048.jpg)
![1 >> import torch 2 >> a = torch.tensor(((1., 2), (3, 4)), device='cuda') tensor([[1, 2], [3, 4]], device='cuda:0') 3 >> b = torch.tensor(((-1, -2), (-3, -4)), device='cuda') 4 >> torch.add(a, b) tensor([[0, 0], [0, 0]], device='cuda:0') 5 >> torch.matmul(a.float(), b.float()) tensor([[ -7., -10.], [-15., -22.]], device='cuda:0') Simple PyTorch Snippets on CUDA](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-21-2048.jpg)
![1 >> a = torch.tensor((1., 2.), requires_grad=True) 2 >> b = torch.tensor((3., 4.)) 3 >> result = (a * b).sum() 4 >> result.backward() 5 >> a.grad tensor([3., 4.]) Autograd in PyTorch](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-22-2048.jpg)
![1 def sinc(x): 2 y = math.pi * torch.where(x == 0, 1.0e-20, x) 3 return torch.sin(y)/y 4 5 scripted_sinc = torch.jit.script(sinc) graph(%x.1 : Tensor): %1 : float = prim::Constant[value=3.1415926535897931 ] %3 : int = prim::Constant[value=0] %5 : float = prim::Constant[value=9.9999999999999995e-21 ] %4 : Tensor = aten::eq(%x.1, %3) %7 : Tensor = aten::where(%4, %5, %x.1) %y.1 : Tensor = aten::mul(%7, %1) %10 : Tensor = aten::sin(%y.1) %12 : Tensor = aten::div(%10, %y.1) return (%12) Computational Graphs in PyTorch](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-23-2048.jpg)
![1 >> t = torch.randn(10) 2 >> linear_layer = torch.nn.Linear(10, 5) 3 >> linear_layer(t) tensor([ 0.0066, 0.2467, -0.0137, -0.4091, -1.1756], grad_fn=<AddBackward0>) Deep Learning in PyTorch](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-24-2048.jpg)



![1 static void sinc_kernel(TensorIteratorBase& iter) { 2 AT_DISPATCH_FLOATING_AND_COMPLEX_TYPES_AND1( kBFloat16, iter.common_dtype(), "sinc_cpu", [&]() { 3 cpu_kernel( 4 iter, 5 [=](scalar_t a) -> scalar_t { 6 if (a == scalar_t(0)) { 7 return scalar_t(1); 8 } else { 9 scalar_t product = c10::pi<scalar_t> * a; 10 return std::sin(product) / product; 11 } 12 }); 13 }); 14 } Sinc in PyTorch, CPU kernel](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-28-2048.jpg)






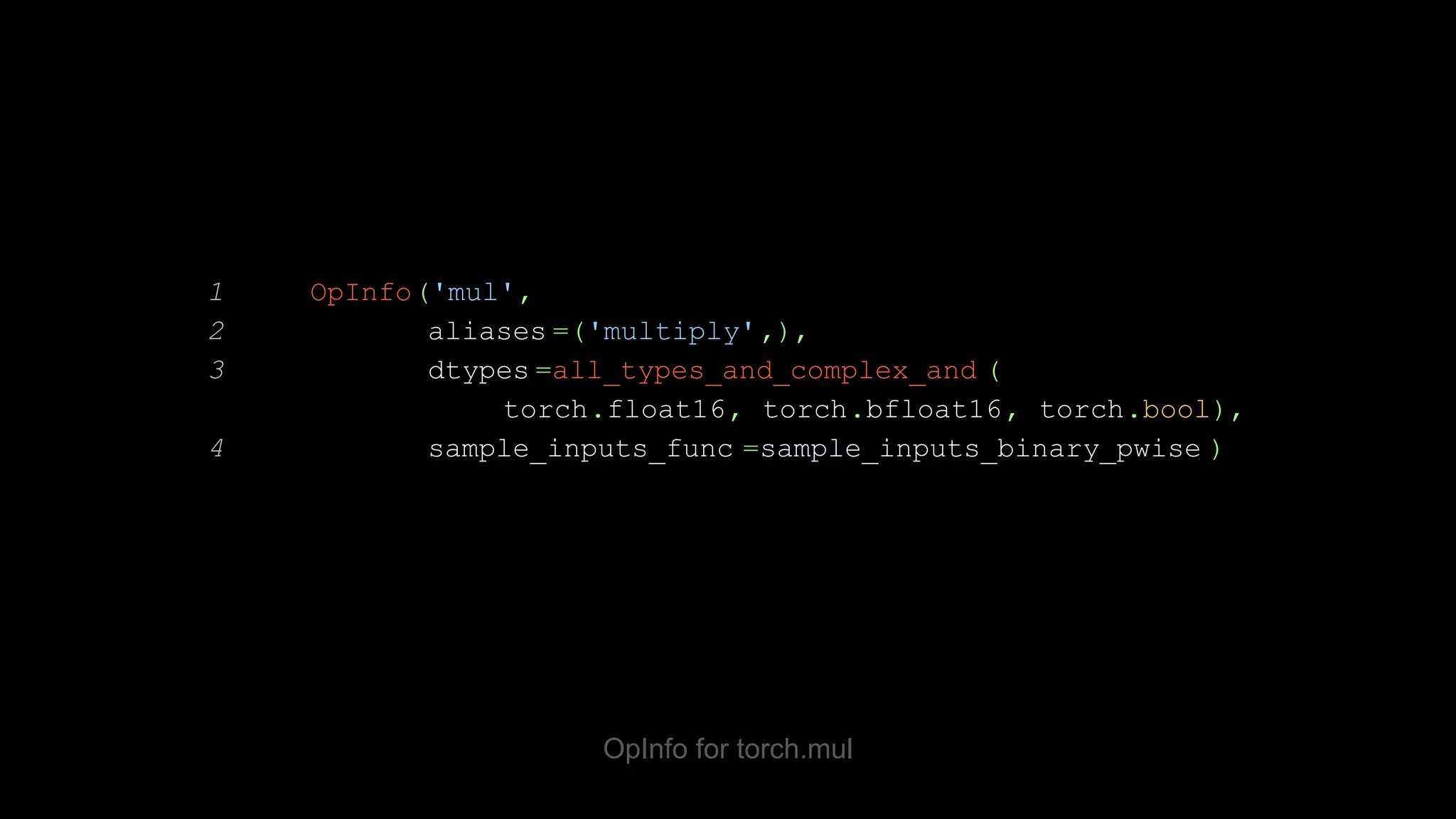
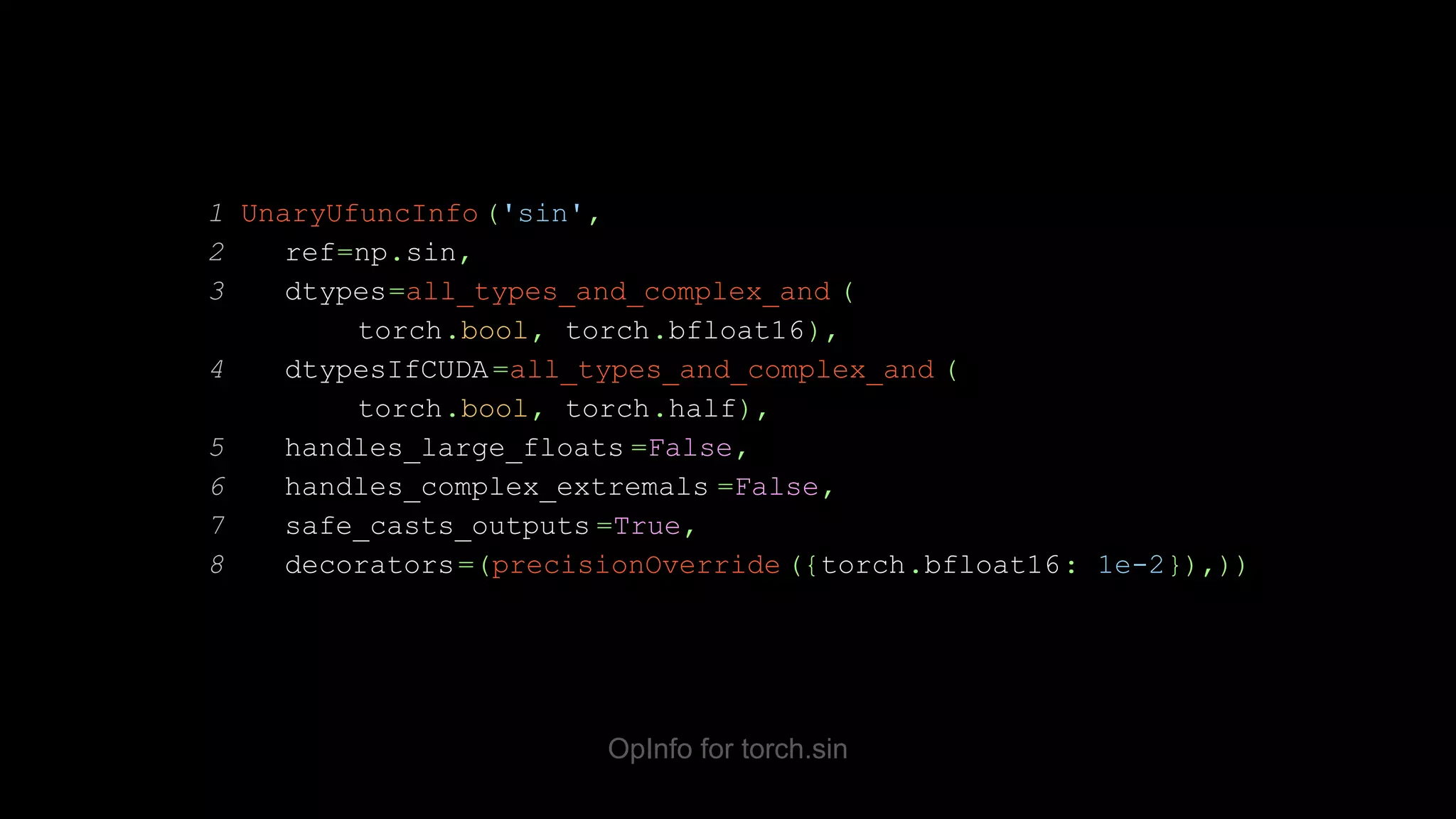
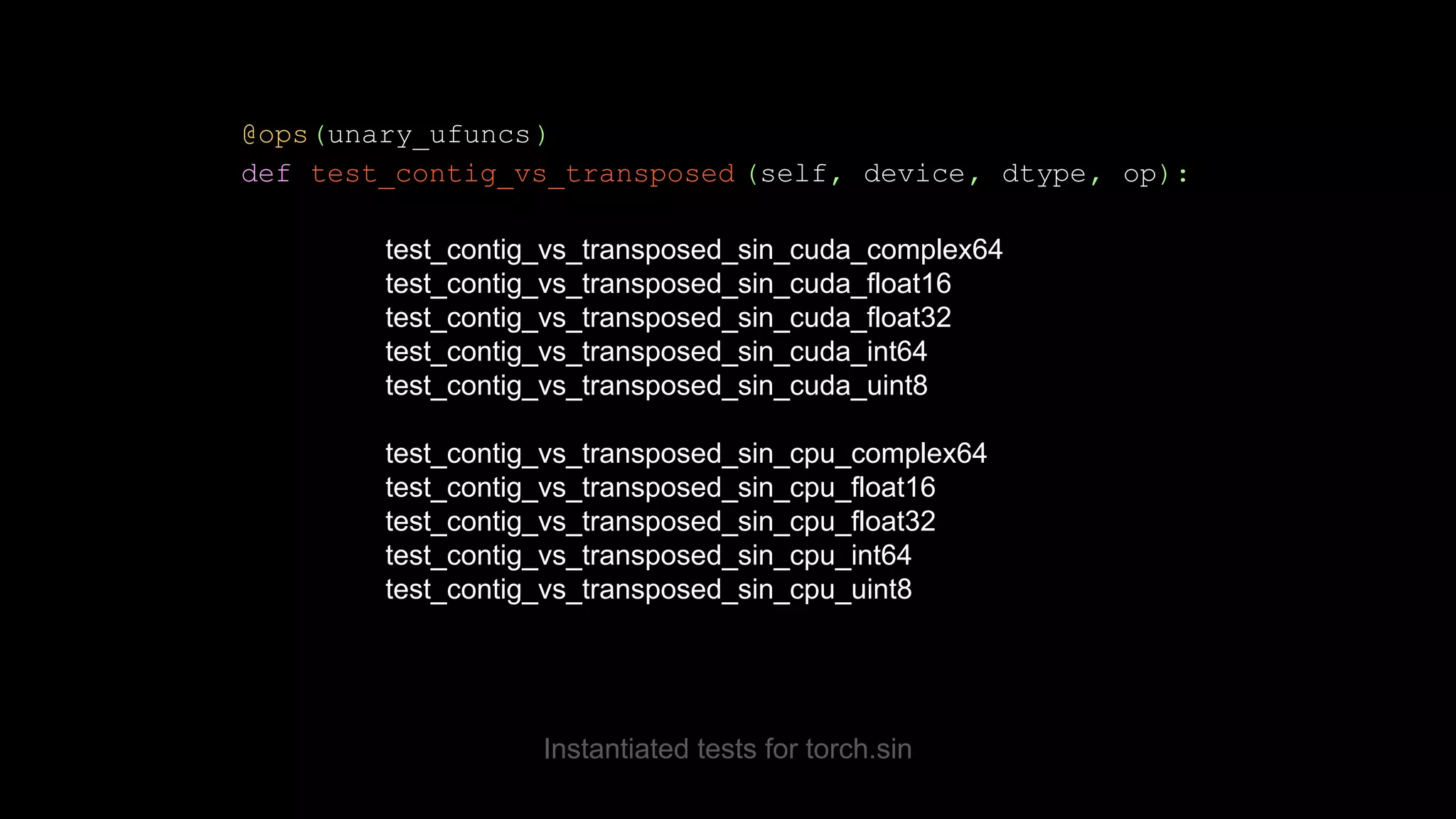
![OpInfo test template 1 @ops(unary_ufuncs) 2 def test_contig_vs_transposed (self, device, dtype, op): 3 contig = make_tensor((789, 357), device=device, dtype=dtype, low=op.domain[0], high=op.domain[1]) 4 non_contig = contig.T 5 self.assertTrue(contig.is_contiguous()) 6 self.assertFalse(non_contig.is_contiguous()) 7 torch_kwargs, _ = op.sample_kwargs(device, dtype, contig) 8 self.assertEqual( op(contig, **torch_kwargs).T, op(non_contig, **torch_kwargs))](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-39-2048.jpg)



![NumPy PyTorch 1 >> a = np.array((1, 2, 3)) 2 >> np.reciprocal(a) array([1, 0, 0]) np.reciprocal vs torch.reciprocal 1 >> t = torch.tensor((1, 2, 3)) 2 >> torch.reciprocal(t) tensor([ 1.0000, 0.5000, 0.3333])](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-44-2048.jpg)
![NumPy PyTorch 1 >> a = np.diag( np.array((1., 2, 3))) 2 >> w, v = np.linalg.eig(a) array([1., 2., 3.]), array([ [1., 0., 0.], [0., 1., 0.], [0., 0., 1.]])) np.linalg.eig vs torch.linalg.eig 1 >> t = torch.diag( torch.tensor((1., 2, 3))) 2 >> w, v = torch.linalg.eig(t) torch.return_types.linalg_eig( eigenvalues=tensor( [1.+0.j, 2.+0.j, 3.+0.j]), eigenvectors=tensor( [[1.+0.j, 0.+0.j, 0.+0.j], [0.+0.j, 1.+0.j, 0.+0.j], [0.+0.j, 0.+0.j, 1.+0.j]]))](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-45-2048.jpg)
![NumPy PyTorch 1 >> a = np.array( (complex(1, 2), complex(2, 1))) 2 >> np.amax(a) (2+1j) 3 >> np.sort(a) array([1.+2.j, 2.+1.j], dtype=complex64) Ordering complex numbers in NumPy vs. PyTorch 1 >> t = torch.tensor( (complex(1, 2), complex(2, 1))) 2 >> torch.amax(t) RUNTIME ERROR 3 >> torch.sort(t) RUNTIME ERROR](https://image.slidesharecdn.com/fromnumpytopytorch-210509135655/75/From-NumPy-to-PyTorch-46-2048.jpg)





