Download as PDF, PPTX


![BigDebug Project Overview Titian: Data Provenance for Fine- Grained Tracing [PVLDB 2016] Vega: Incremental Computation for Interactive Debugging [SoCC 2016] Collaboration with Tyson Condie, Miryung Kim, and Todd Millstein BigDebug: Debugging Primitives for Interactive Big Data Processing in Spark [ICSE 2016] Automated Debugging in Data Intensive Scalable Computing Systems [Under Submission]](https://image.slidesharecdn.com/021gulzarinterlandi-170613024818/75/Debugging-Big-Data-Analytics-in-Apache-Spark-with-BigDebug-with-Muhammad-Gulzar-and-Matteo-Interlandi-3-2048.jpg)







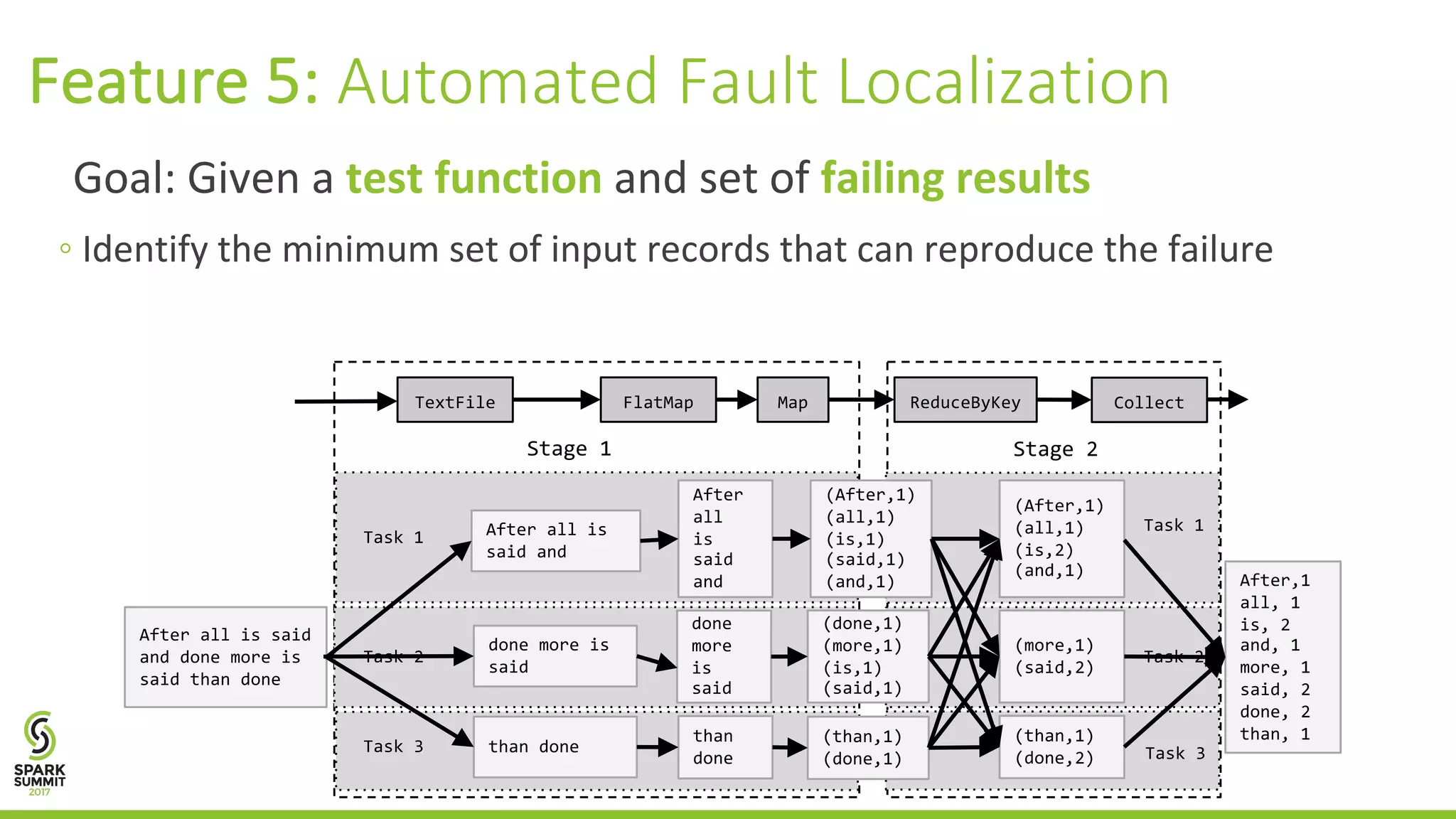
![We apply data provenance and delta debugging [Zeller et al. ] in tandem Feature 5: Automated Fault Localization](https://image.slidesharecdn.com/021gulzarinterlandi-170613024818/75/Debugging-Big-Data-Analytics-in-Apache-Spark-with-BigDebug-with-Muhammad-Gulzar-and-Matteo-Interlandi-18-2048.jpg)
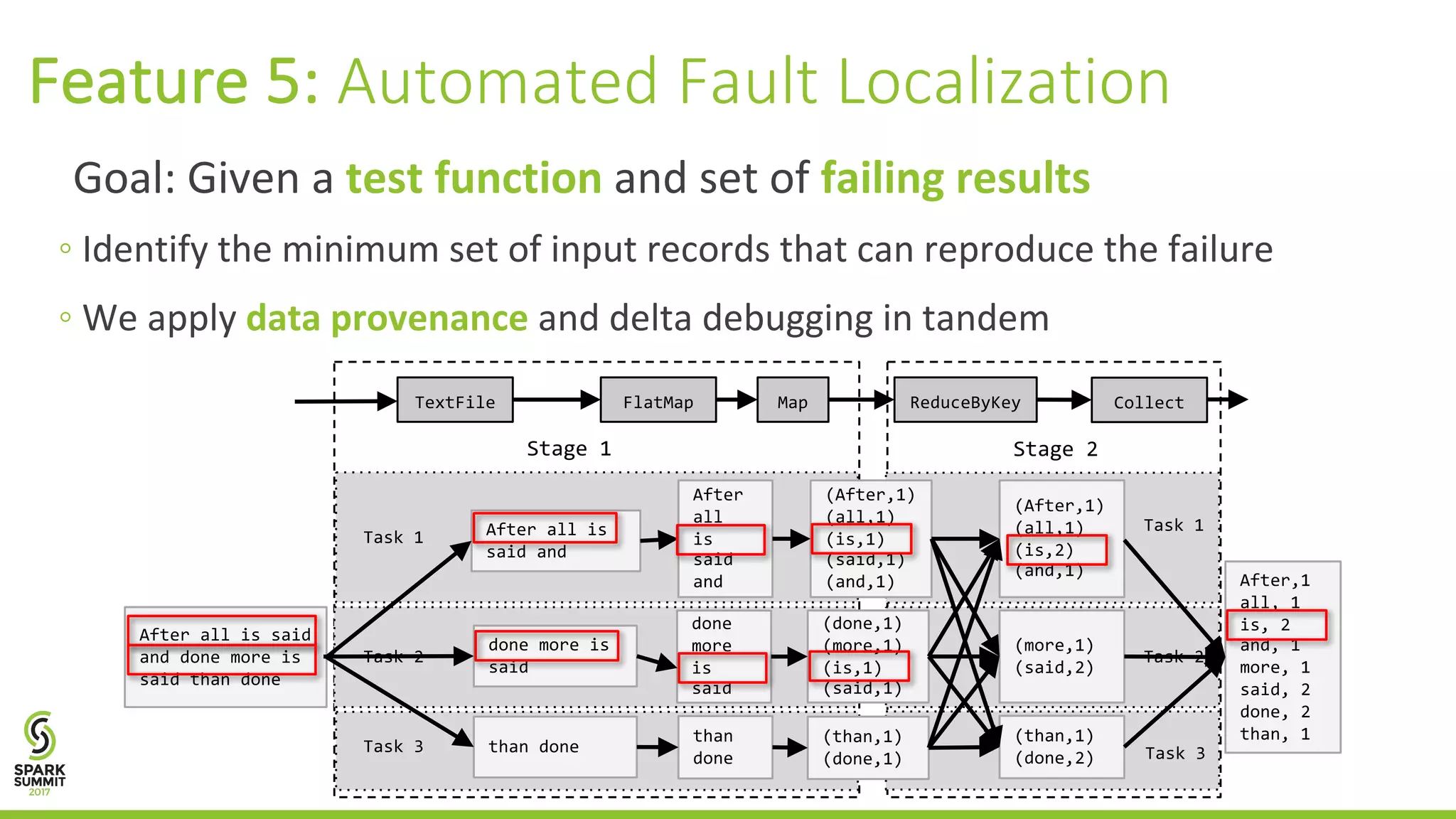
![We apply data provenance and delta debugging [Zeller et al. ] in tandem Feature 5: Automated Fault Localization Test](https://image.slidesharecdn.com/021gulzarinterlandi-170613024818/75/Debugging-Big-Data-Analytics-in-Apache-Spark-with-BigDebug-with-Muhammad-Gulzar-and-Matteo-Interlandi-19-2048.jpg)
![We apply data provenance and delta debugging [Zeller et al. ] in tandem Feature 5: Automated Fault Localization Test Split](https://image.slidesharecdn.com/021gulzarinterlandi-170613024818/75/Debugging-Big-Data-Analytics-in-Apache-Spark-with-BigDebug-with-Muhammad-Gulzar-and-Matteo-Interlandi-20-2048.jpg)
![We apply data provenance and delta debugging [Zeller et al. ] in tandem Feature 5: Automated Fault Localization Test Split In average BigDebug is able to localize faults within 63% of the original job running time](https://image.slidesharecdn.com/021gulzarinterlandi-170613024818/75/Debugging-Big-Data-Analytics-in-Apache-Spark-with-BigDebug-with-Muhammad-Gulzar-and-Matteo-Interlandi-21-2048.jpg)
![We apply data provenance and delta debugging [Zeller et al. ] in tandem Feature 5: Automated Fault Localization …. Test Split In average BigDebug is able to localize faults within 63% of the original job running time In average BigDebug is able to localize faults within 63% of the original job running time](https://image.slidesharecdn.com/021gulzarinterlandi-170613024818/75/Debugging-Big-Data-Analytics-in-Apache-Spark-with-BigDebug-with-Muhammad-Gulzar-and-Matteo-Interlandi-22-2048.jpg)

![Running Example val log = "s3n://xcr:wJY@ws/logs/enroll.log" val text_file = sc.textFile(log) text_file .map{line=>(line.split()[2],line.split()[3])} .map{t => (t._1 , getYears(t._2))} .groupByKey() .map(v => (v._1 , average(v._2))) .collect() 1 Michael Sophomore 03/12/1996 2 Justin Freshman 05/01/1998 .. .. ..](https://image.slidesharecdn.com/021gulzarinterlandi-170613024818/75/Debugging-Big-Data-Analytics-in-Apache-Spark-with-BigDebug-with-Muhammad-Gulzar-and-Matteo-Interlandi-24-2048.jpg)

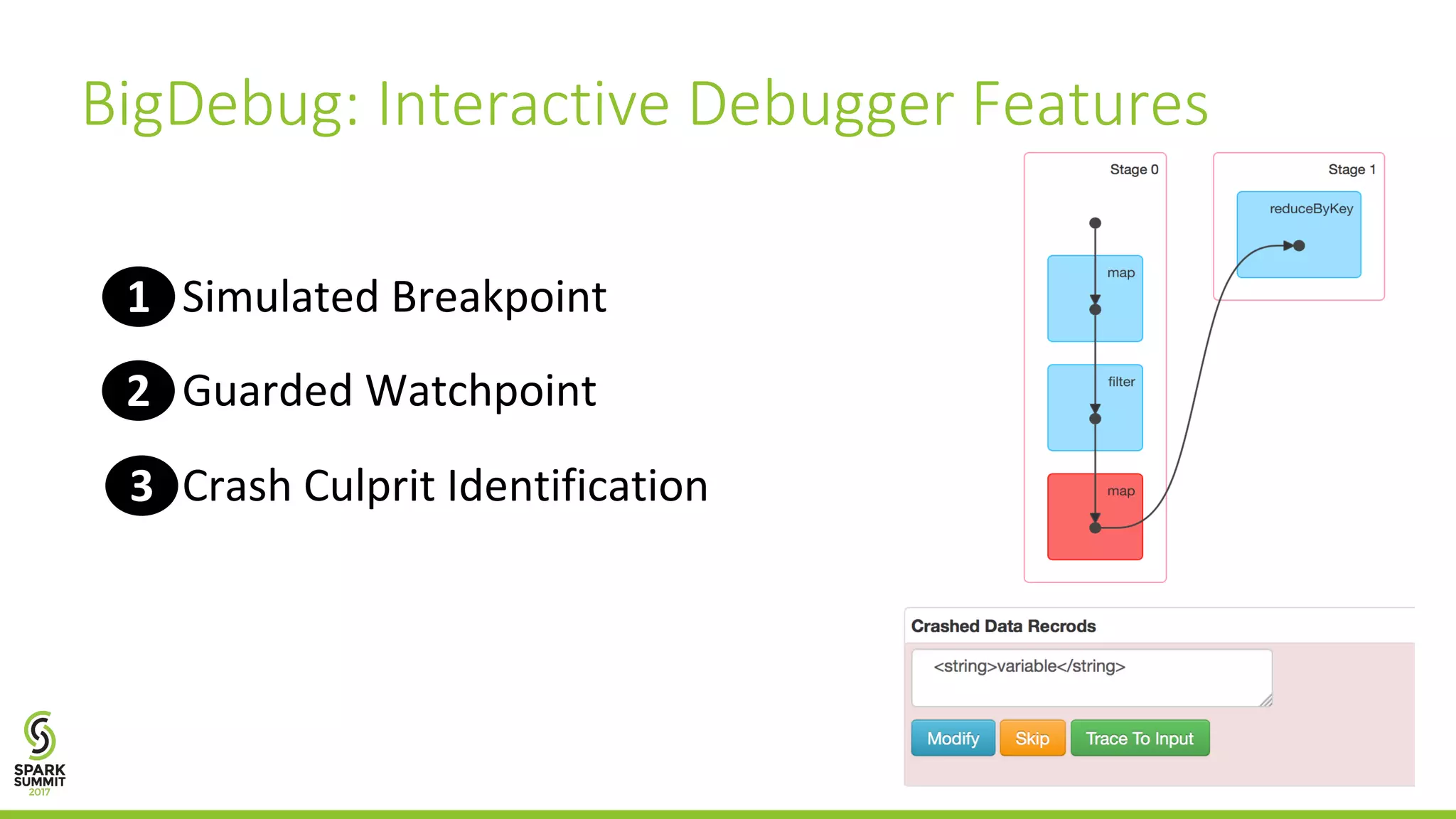
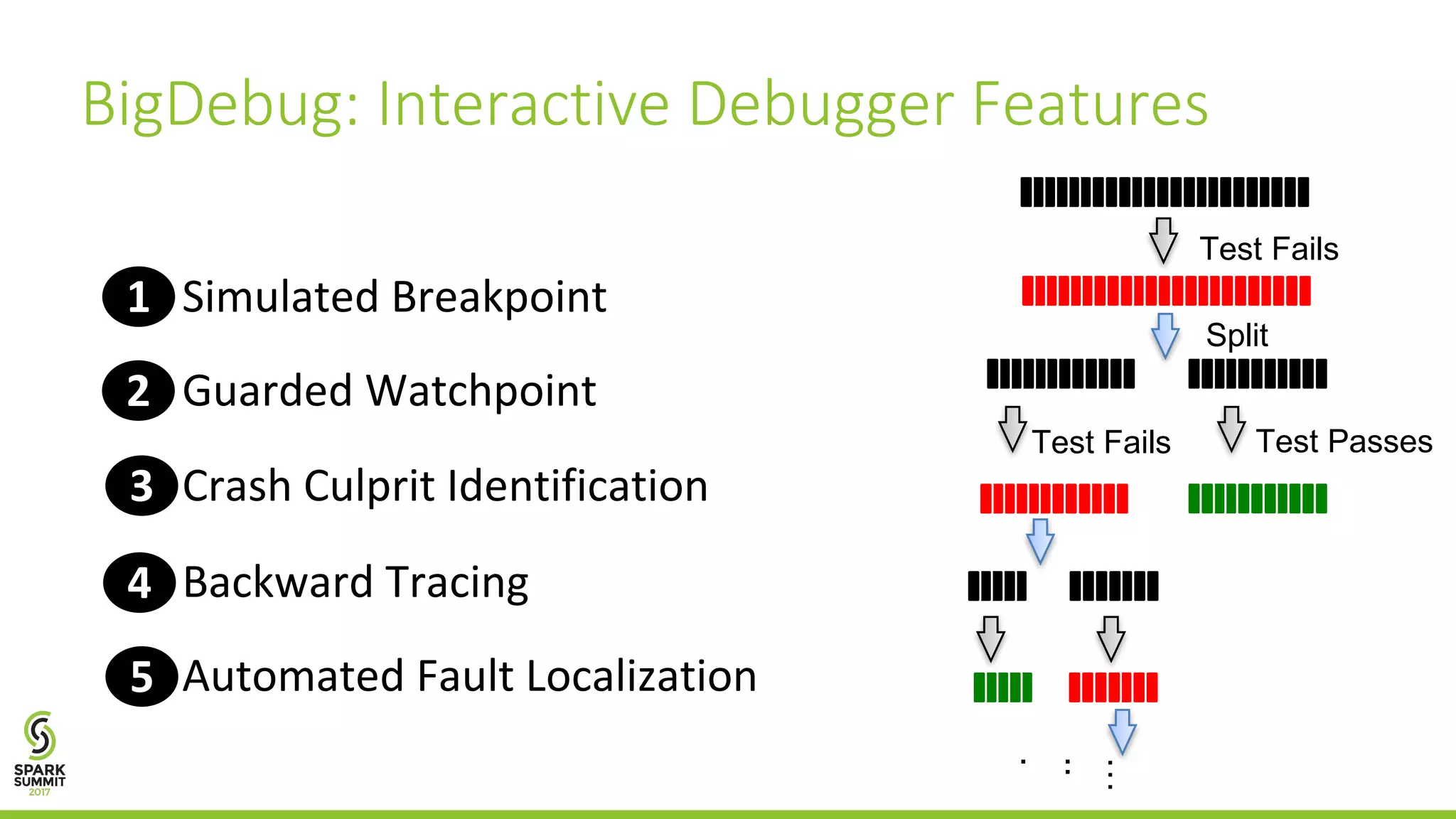
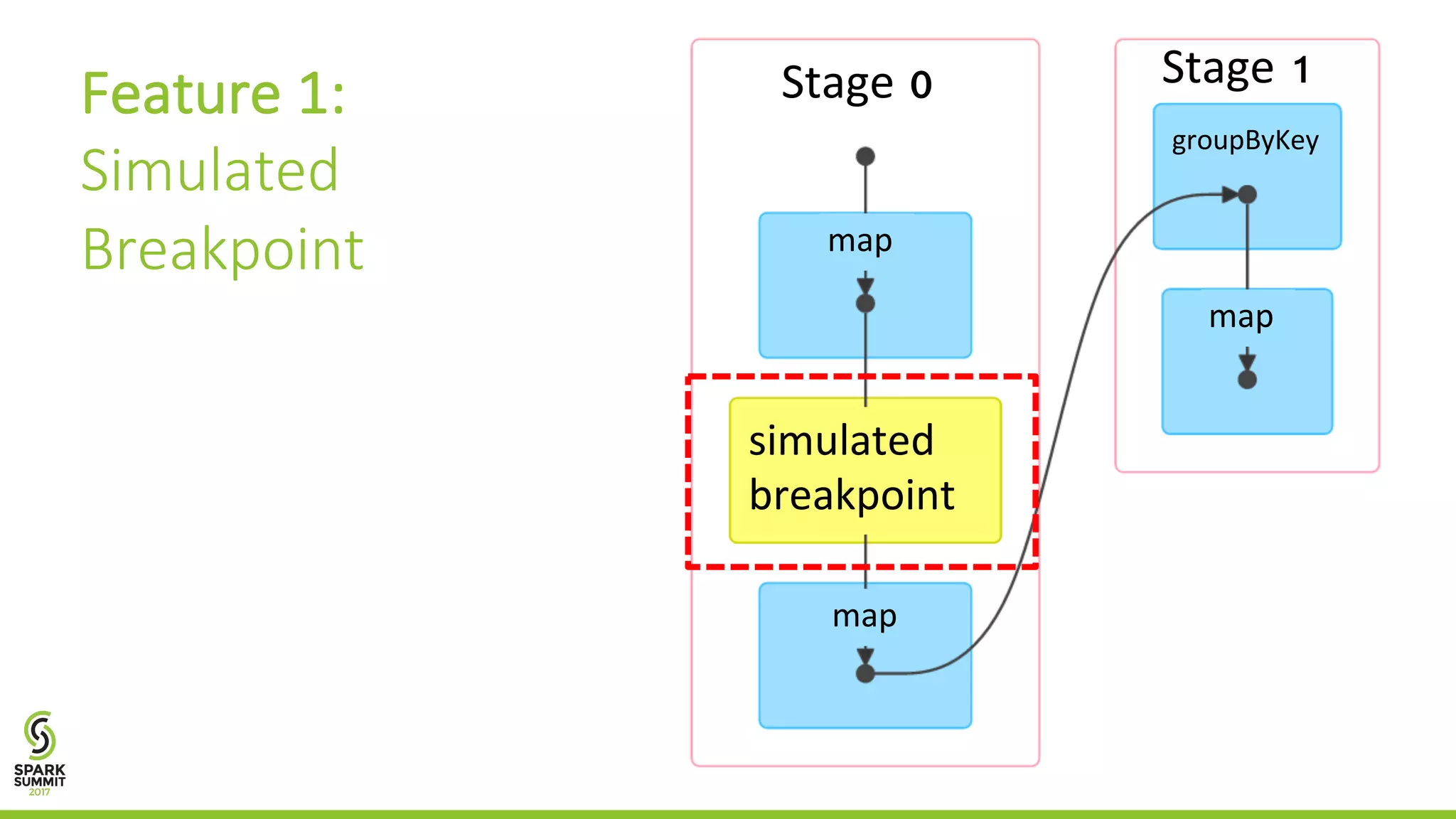
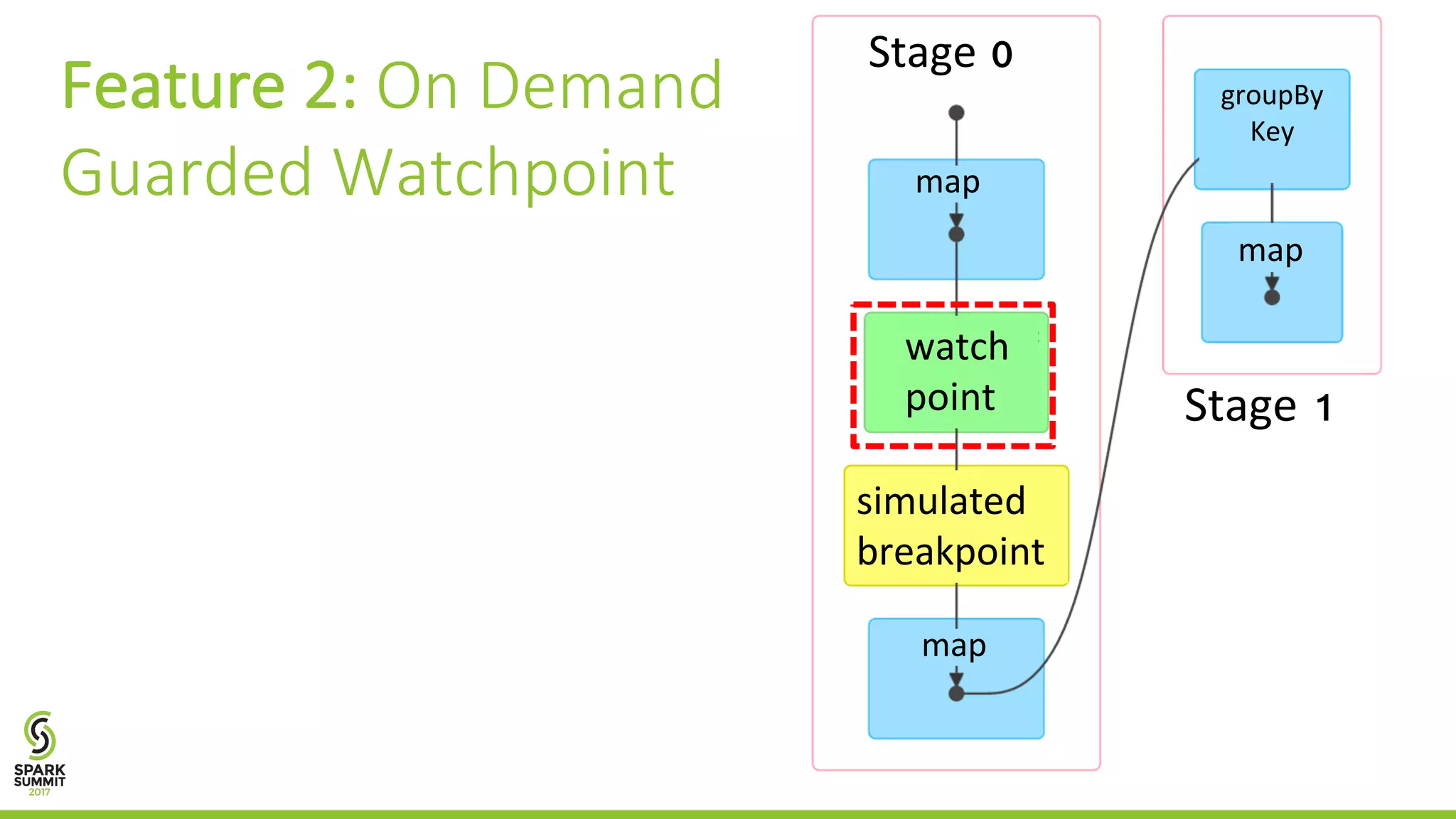
The document discusses the BigDebug project, which aims to improve debugging support for big data analytics in Apache Spark due to the limitations of existing frameworks like Hadoop and Spark. It elaborates on various debugging features such as simulated breakpoints, guarded watchpoints, crash culprit identification, and backward tracing to enhance user interaction during the debugging process. The average performance of BigDebug is noted to localize faults within 63% of the original job's runtime.