

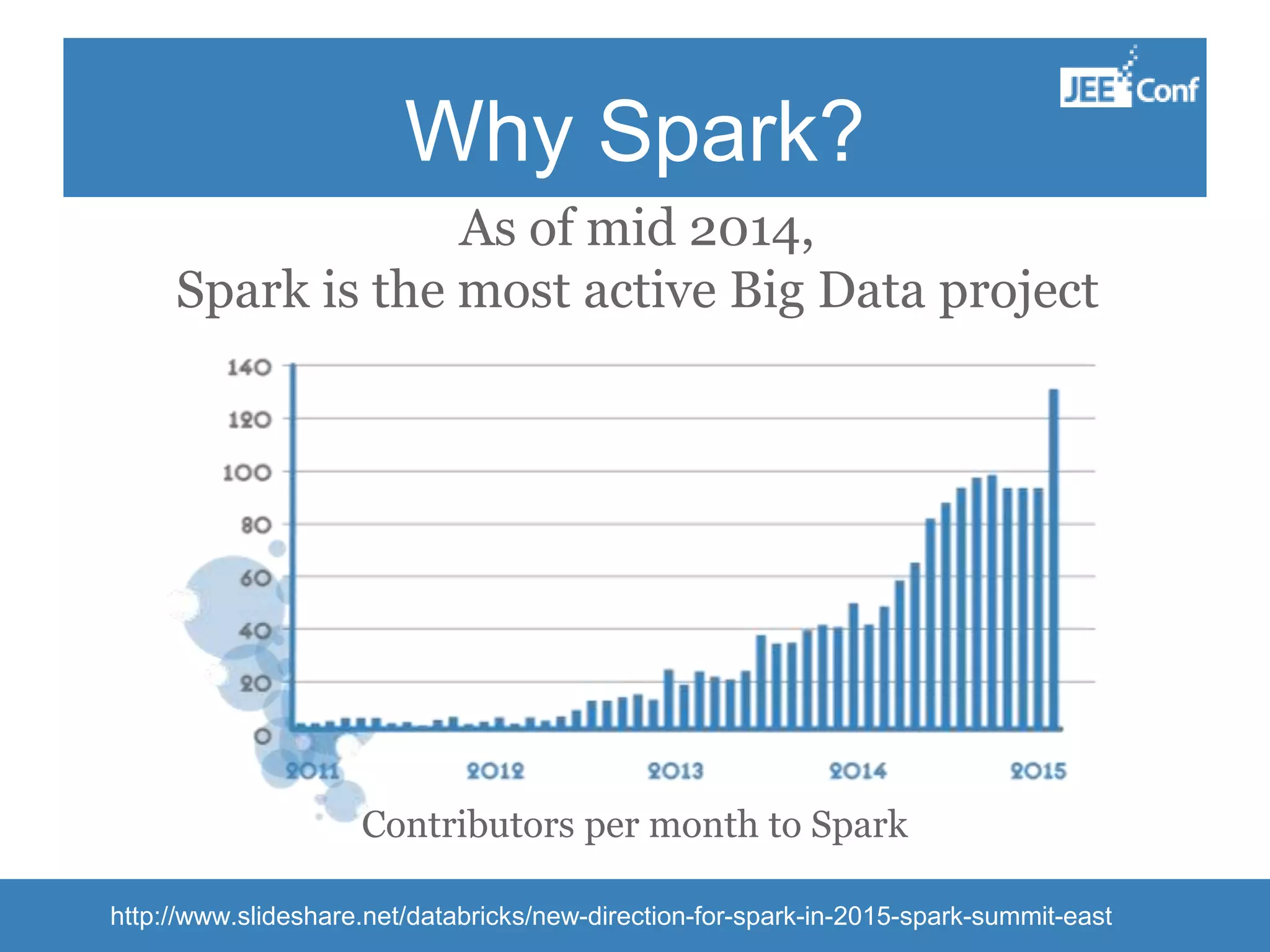
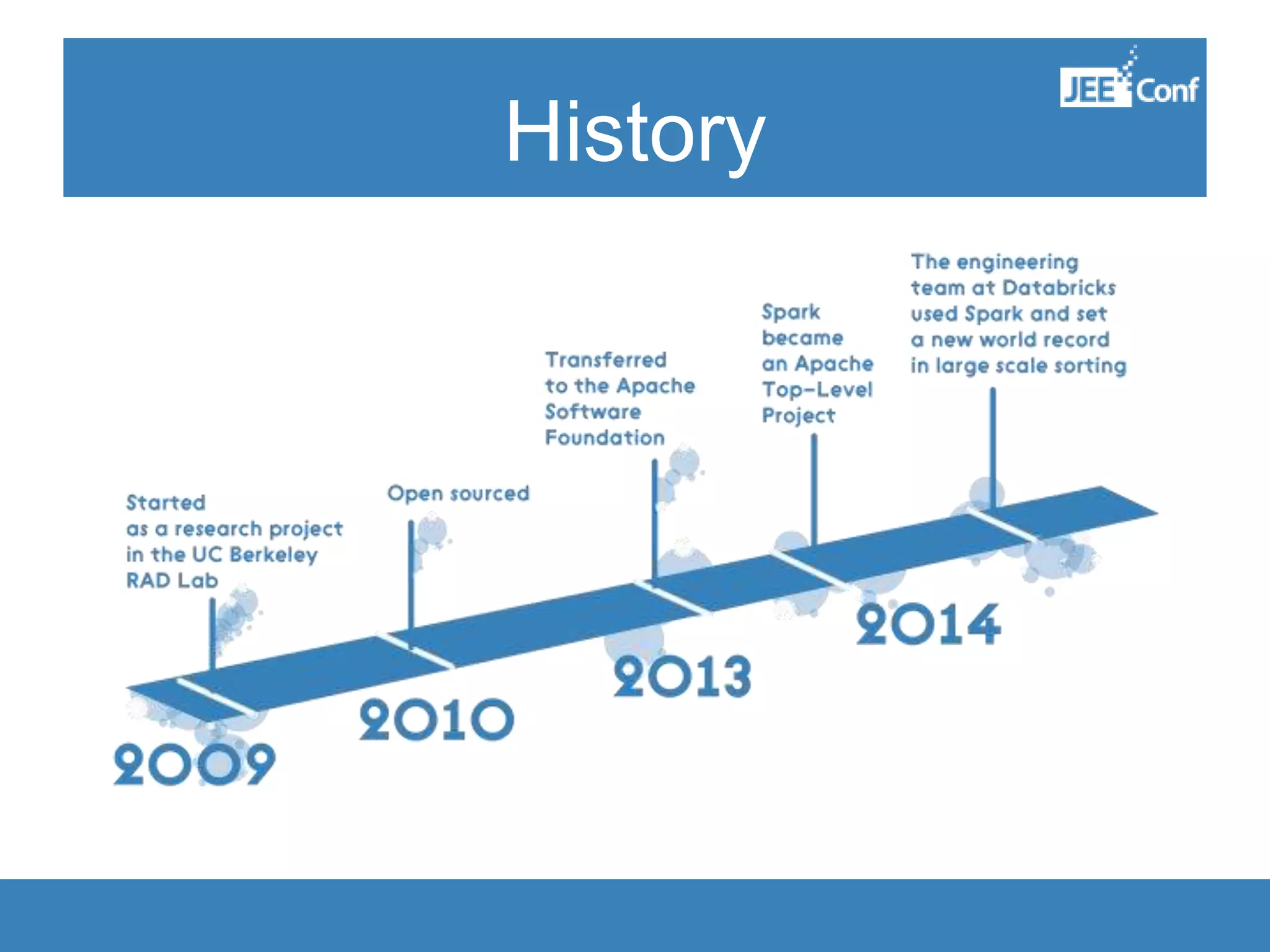




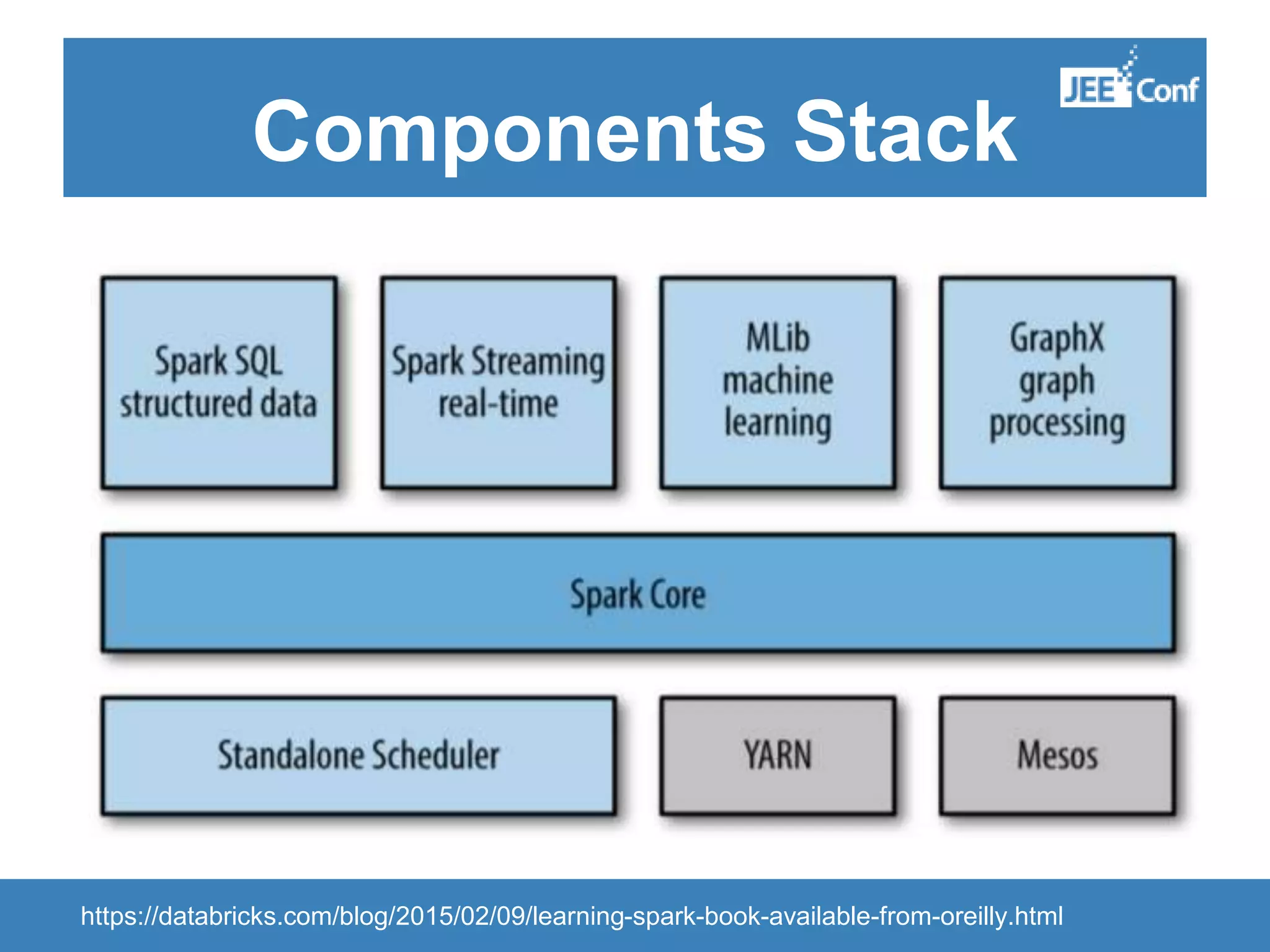

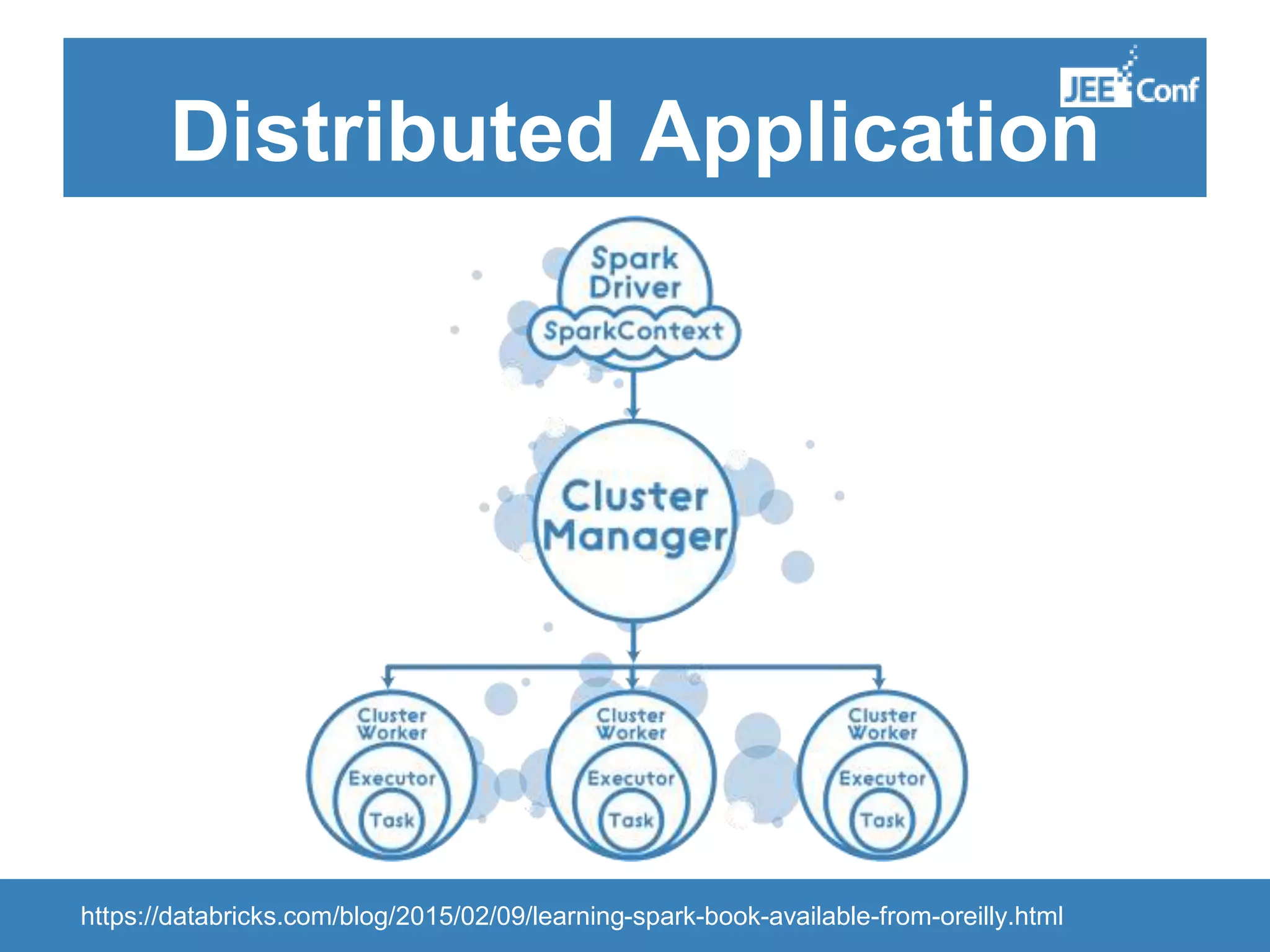

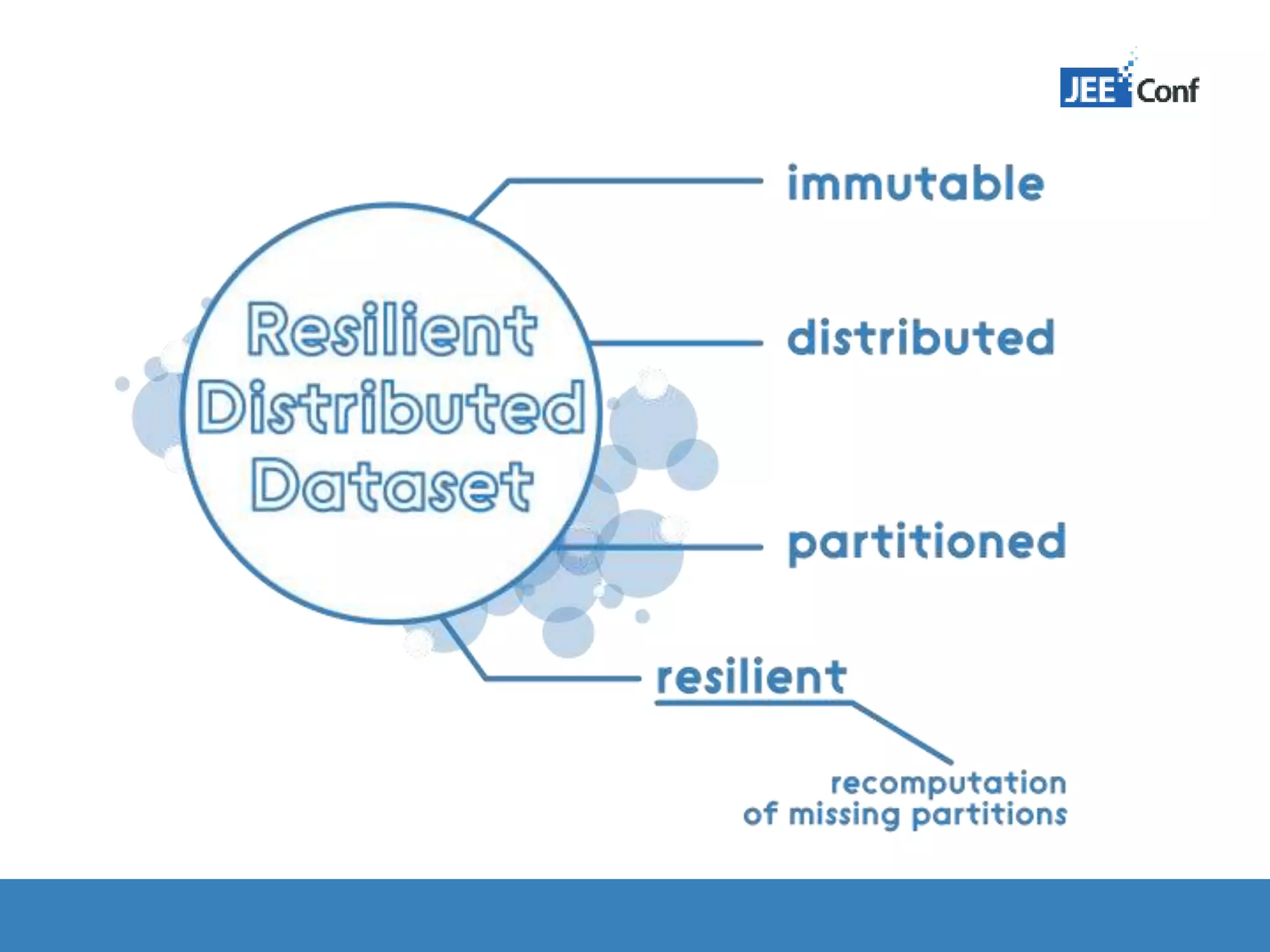






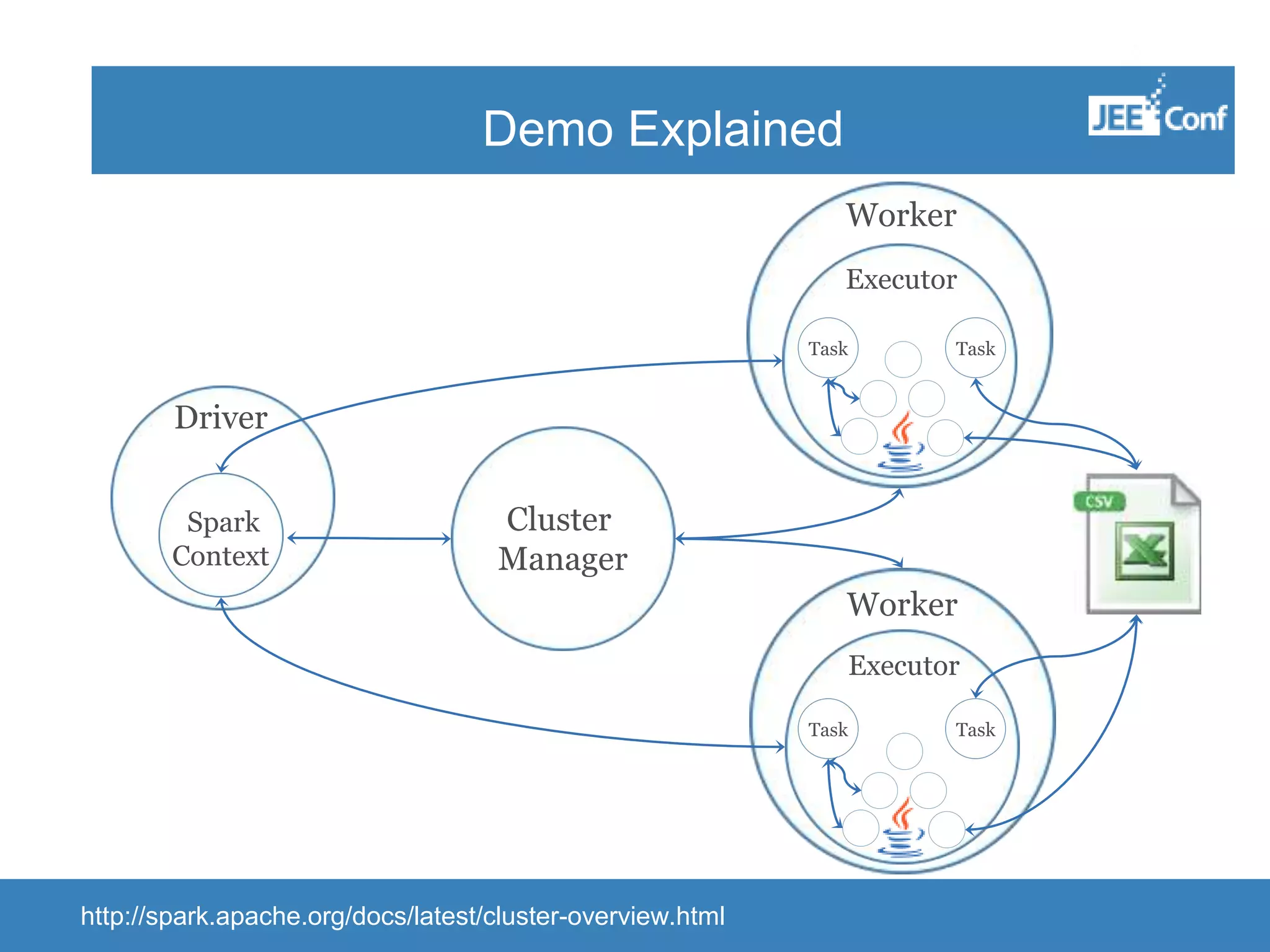




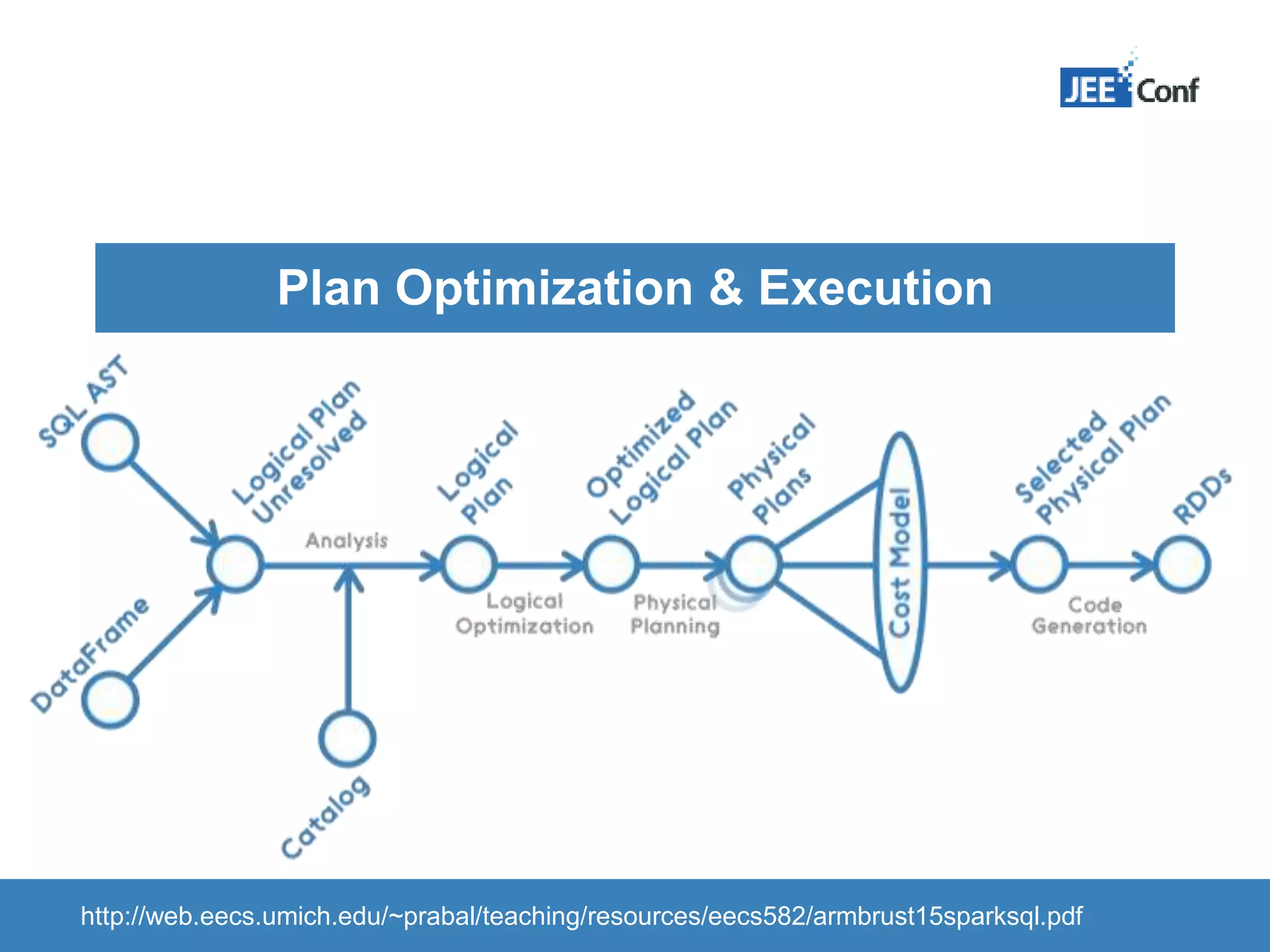
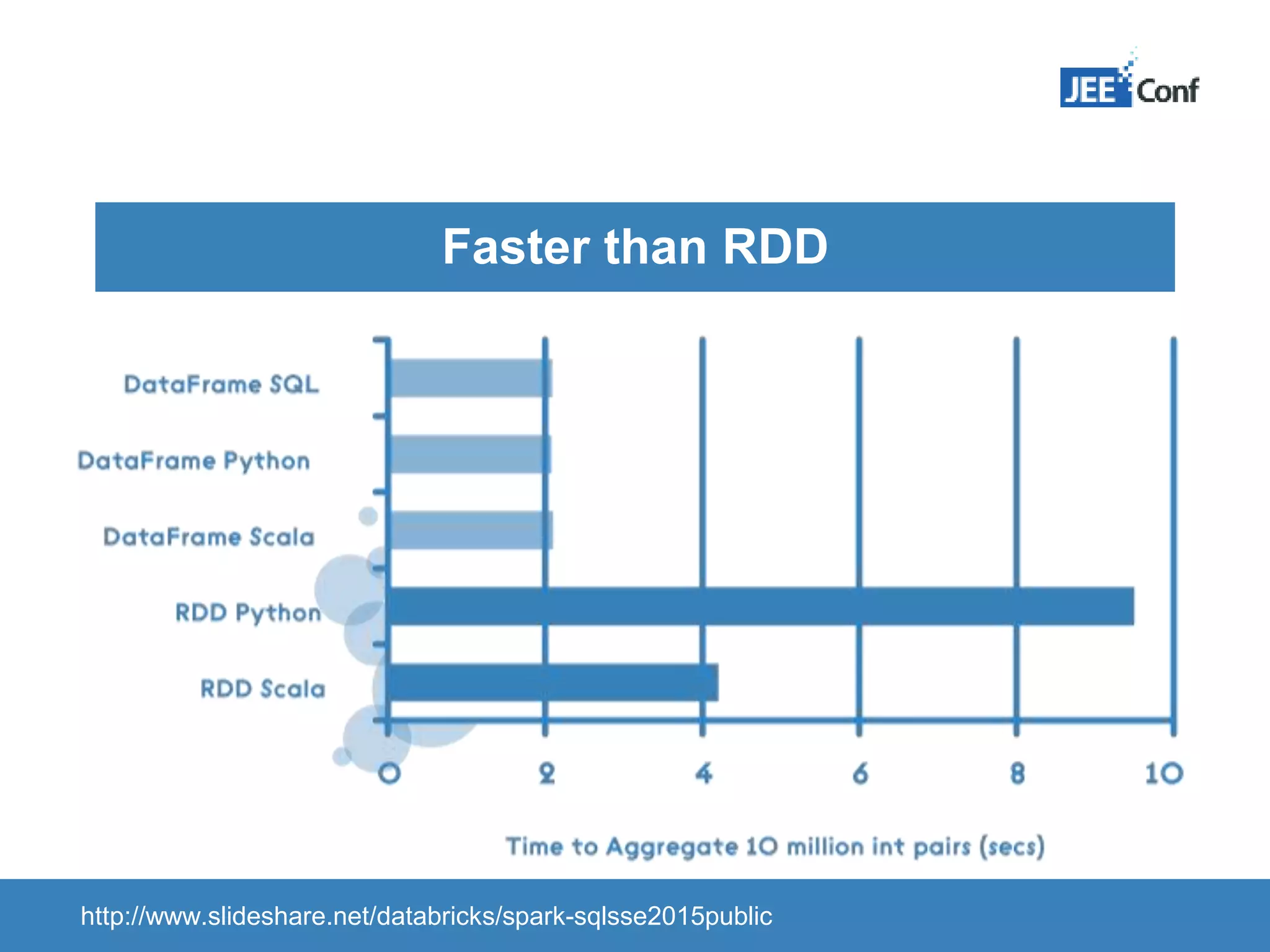








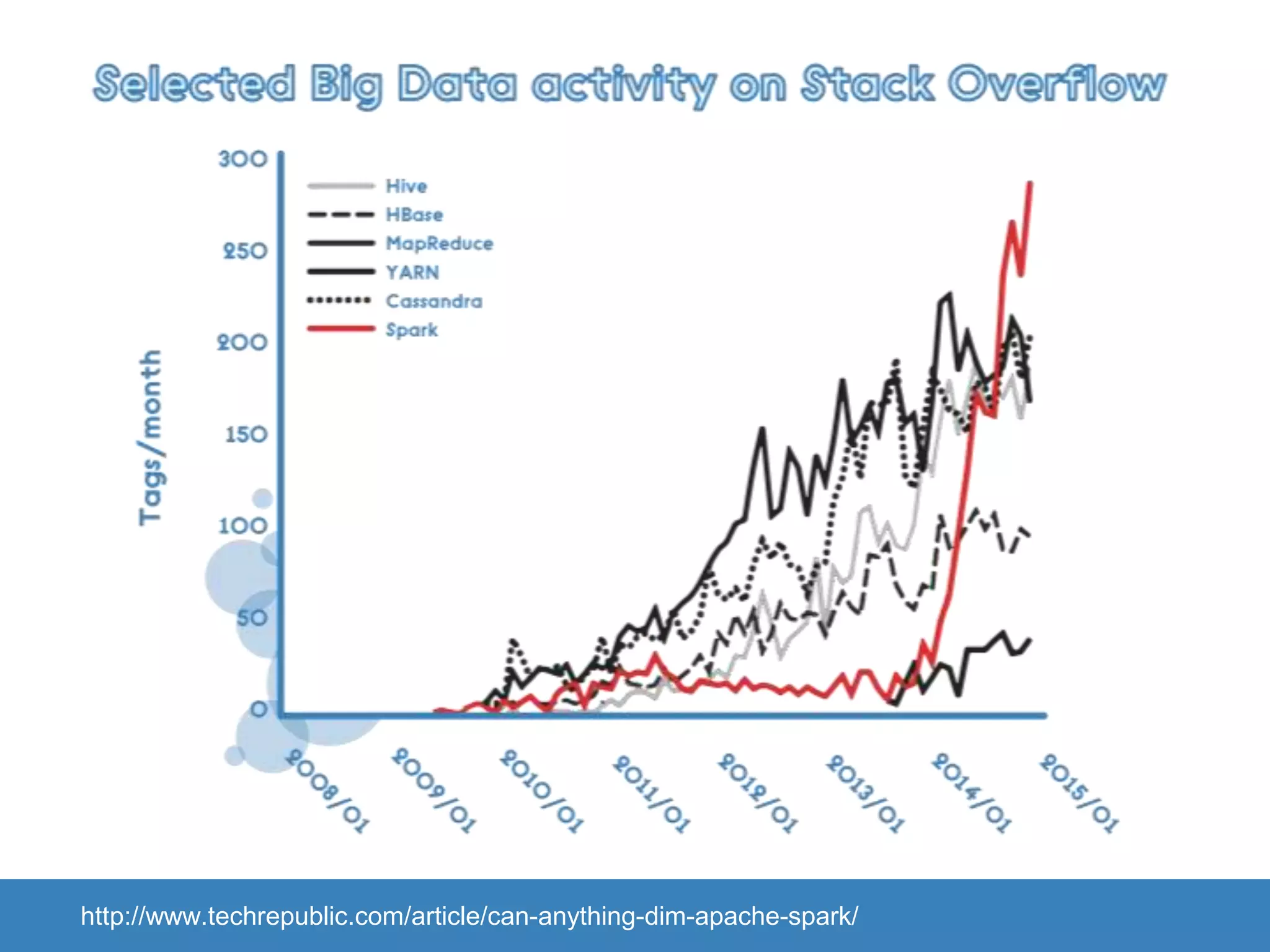




The document provides an introduction to Apache Spark, highlighting its capabilities as a fast and general-purpose platform for large-scale data processing. It discusses key components such as the RDD API, data processing techniques, and integration use cases while emphasizing Spark's performance advantages over Hadoop. The document also covers project developments, resources for learning Spark, and lessons learned from practical applications.