Download as PDF, PPTX



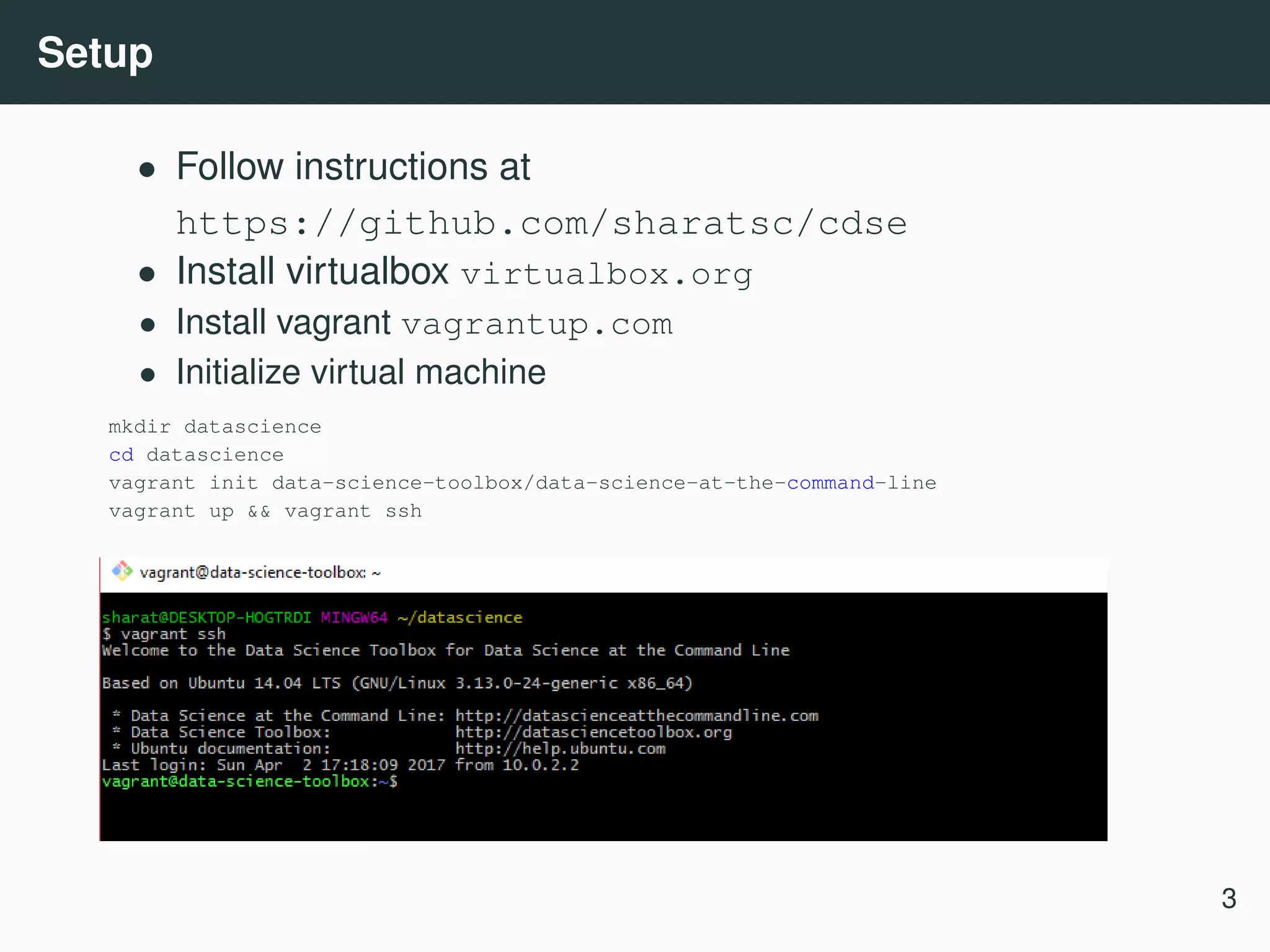






![Boston housing dataset Python workflow 3 import urllib import pandas as pd # Obtain data urllib.urlretrieve(’https://raw.githubusercontent.com/sharatsc/cdse/master/boston-housin df = pd.read_csv(’boston.csv’) # Scrub data df = df.fillna(0) # Model data from statsmodels import regression from statsmodels.formula import api as smf formula = ’medv~’ + ’ + ’.join(df.columns - [’medv’]) model = smf.ols(formula=formula, data=df) res=model.fit() res.summary() Command line workflow URL="https://raw.githubusercontent.com/sharatsc/cdse/master/boston-housing/boston.csv" curl $URL| Rio -e ’model=lm("medv~.", df);model’ 3 https://github.com/sharatsc/cdse/blob/master/boston-housing 11](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-12-2048.jpg)



![Scrubbing web data: Scrape • Scrape is a python command line tool to parse html documents • Queries can be made in CSS selector or XPath syntax htmldoc=$(cat << EOF <div id=a> <a href="x.pdf">x</a> </div> <div id=b> <a href="png.png">y</a> <a href="pdf.pdf">y</a> </div> EOF ) # Select liks that end with pdf and are within div with id=b (Use CSS3 selector) echo $htmldoc | scrape -e "$b a[href$=pdf]" # Select all anchors (use Xpath) echo $htmldoc | scrape -e "//a" <a href="pdf.pdf">y</a> 13](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-16-2048.jpg)
![CSS selectors .class selects all elements with class=’class’ div p selects all <p> elements inside div elements div > p selects <p> elements where parent is <div> [target=blank] selects all elements with target="blank" [href^=https] selects urls beginning with https [href$=pdf] selects urls ending with pdf More examples at https://www.w3schools.com/cssref/css_selectors.asp 14](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-17-2048.jpg)
![XPath Query author selects all <author> elements at the current level //author selects all <author> elements at any level //author[@class=’x’] selects <author> elements with class=famous //book//author All <author> elements that are below <book> element" //author/* All children of <author> nodes More examples at https://msdn.microsoft.com/en-us/library/ms256086 15](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-18-2048.jpg)
![Scrubbing JSON data: JQ 5 • JQ is a portable command line utility to manipulate and filter JSON data • Filters can be defined to access individual fields, transform records or produce derived objets • Filters can be composed and combined • Provides builtin functions an operators Example: curl ’https://api.github.com/repos/stedolan/jq/commits’ | jq ’.[0]’ 5 https://stedolan.github.io/jq/ 17](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-20-2048.jpg)
![Basic filters # Identity ’.’ echo ’"Hello world"’ | jq ’.’ "Hello world" # Examples ’.foo’, ’.foo.bar’, ’.foo|.bar’, ’.["foo"] echo ’{"foo": 42, "bar": 10}’ | jq ’.foo’ 42 echo ’{"foo": {"bar": 10, "baz": 20}} | jq ’.foo.bar’ 10 #Arrays ’.[]’, ’.[0]’, ’.[1:3]’ echo ’["foo", "bar"]’ | jq ’.[0]’ "foo" echo ’["foo", "bar", "baz"]’ | jq ’.[1:3]’ ["bar", "baz"] # Pipe ’.foo|.bar’, ’.[]|.bar’ echo ’[{"f": 10}, {"f": 20}, {"f": 30}]’ | jq ’.[] | .f 10 20 30 18](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-21-2048.jpg)
![Object construction Object construction allows you to derive new objects out of existing ones. # Field selection echo {"foo": "F", "bar": "B", "baz": "Z"} | jq ’{"foo": .foo}’ {"foo": "F"} # Array expansion echo ’{"foo": "A", "bar": ["X", "Y"]}’ | jq ’{"foo": .foo, "bar": .bar[]}’ {"foo": "F", "bar": "X"} {"foo": "F", "bar": "Y"} # Expression evaluation, key and value can be substituted echo ’{"foo": "A", "bar": ["X", "Y"]}’ | jq ’{(.foo): .bar[]}’ {"A": "X"} {"A": "Y"} 19](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-22-2048.jpg)
![Operators Addition • Numbers are added by normal arithmetic. • Arrays are added by being concatenated into a larger array. • Strings are added by being joined into a larger string. • Objects are added by merging, that is, inserting all the key-value pairs from both objects into a single combined object. # Adding fields echo ’{"foo": 10}’ | jq ’.foo + 1’ 11 # Adding arrays echo ’{"foo": [1,2,3], "bar": [11,12,13]}’ | jq ’.foo + .bar’ [1,2,3,11,12,13] 20](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-23-2048.jpg)


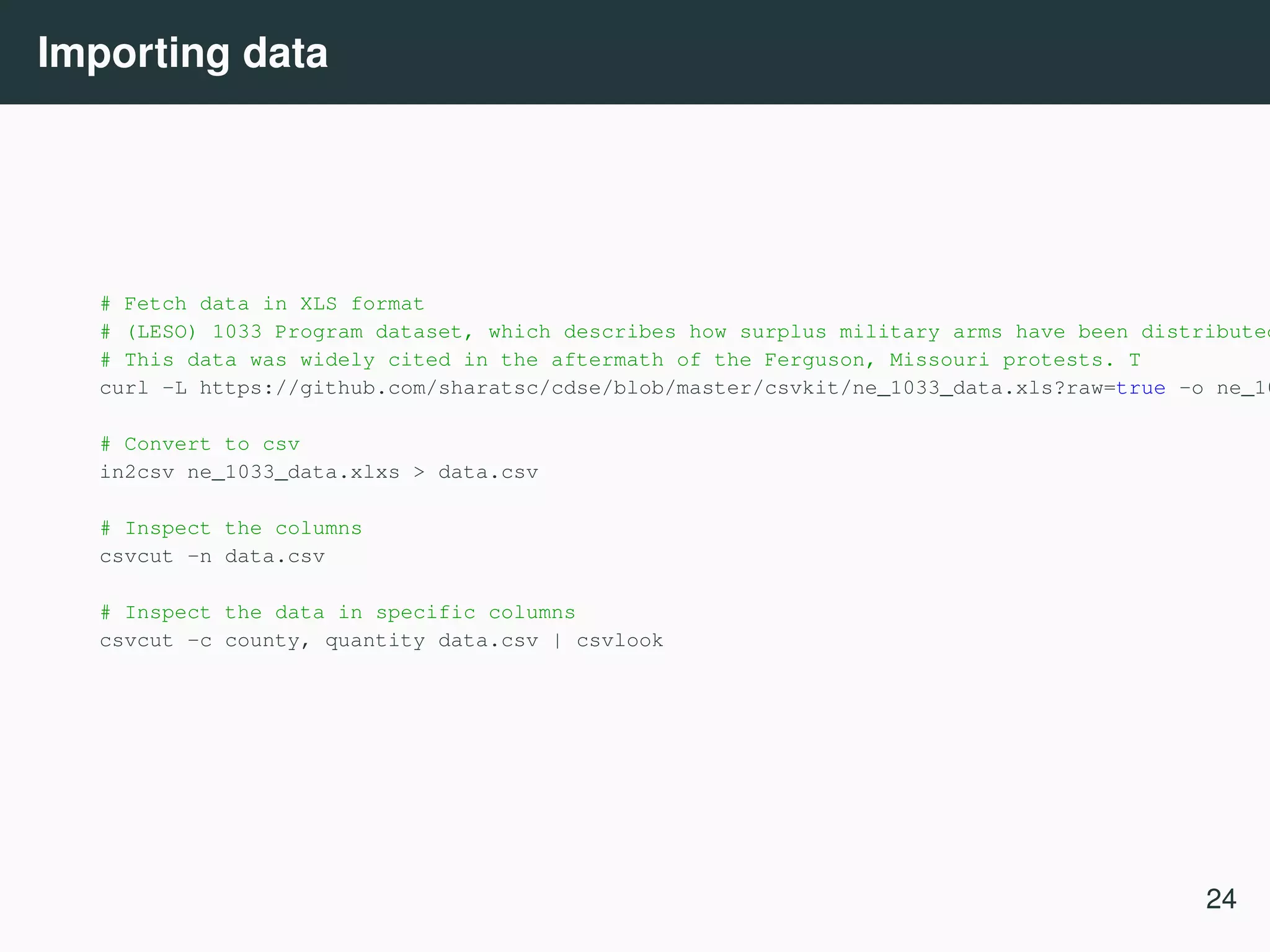
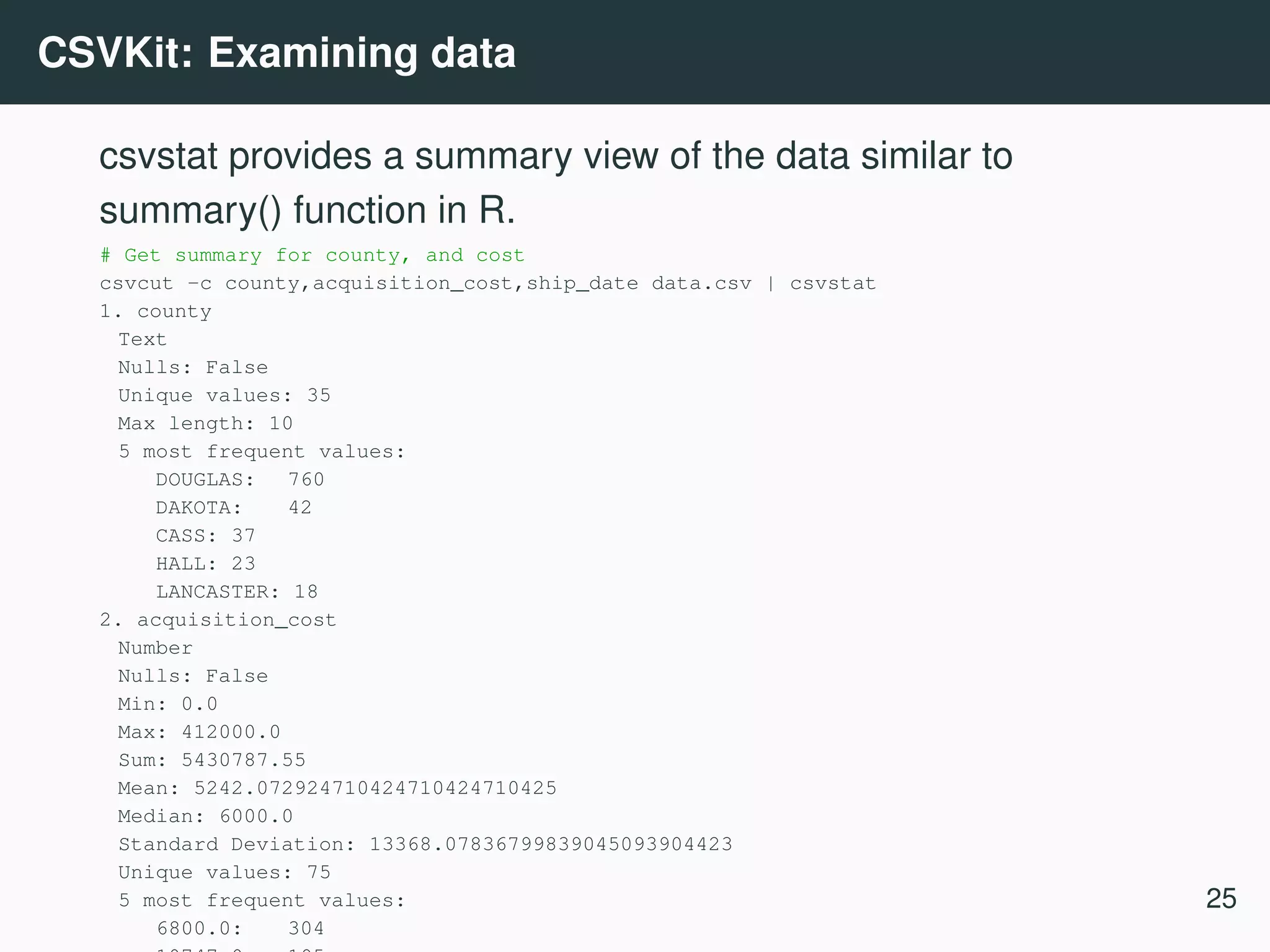
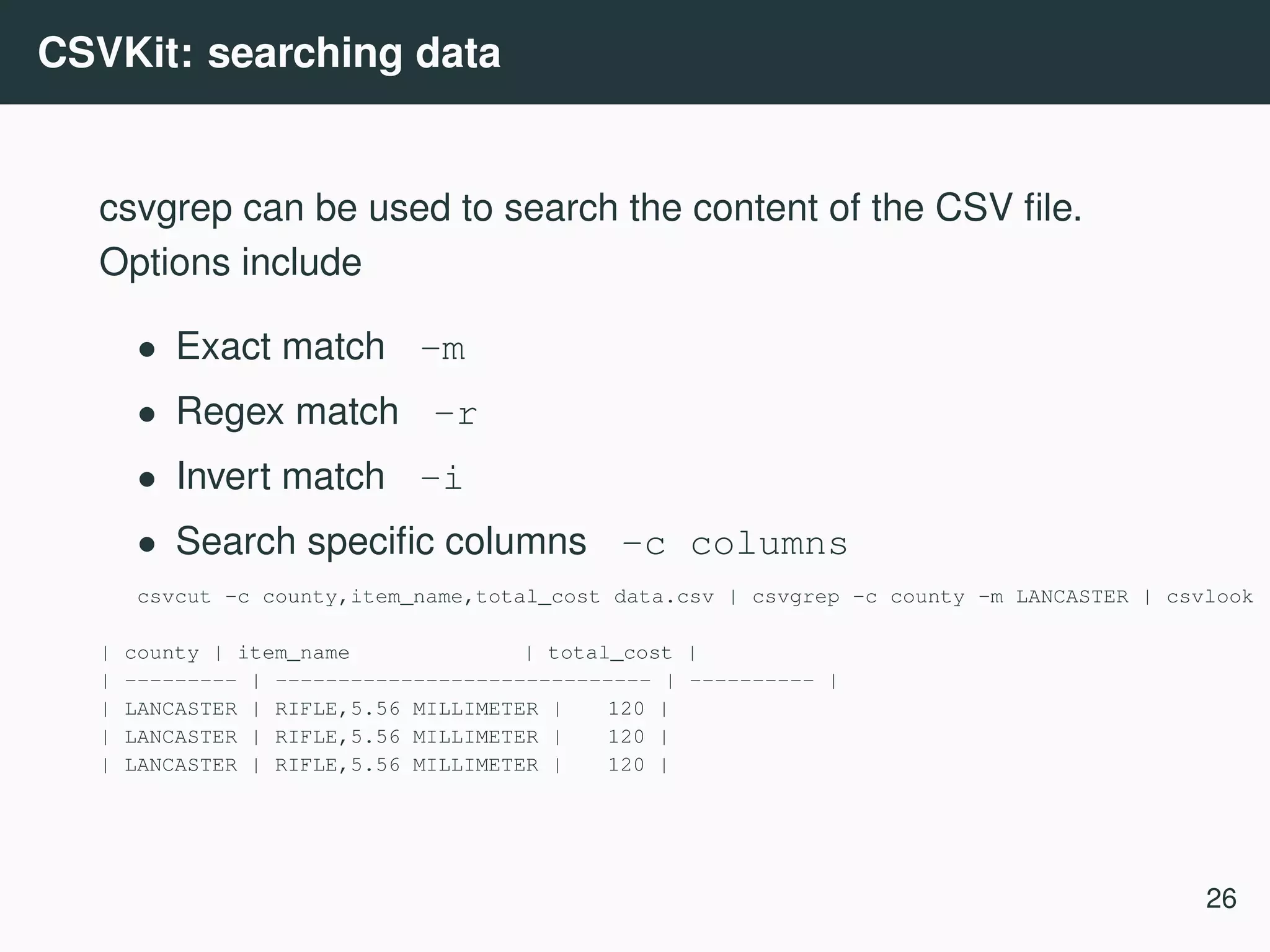
![CSVKit (Groskopf and contributors [2016]) csvkit 6 is a suite of command line tools for converting and working with CSV, the defacto standard for tabular file formats. Example use cases • Importing data from excel, sql • Select subset of columns • Reorder columns • Mergeing multiple files (row and column wise) • Summary statistics 6 https://csvkit.readthedocs.io/ 23](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-27-2048.jpg)




![GNU parallel • GNU parallel (Tange [2011]) is a tool for executing jobs in parallel on one or more machines. • It can be used to parallelize across arguments, lines and files. Examples # Parallelize across lines seq 1000 | parallel "echo {}" # Parallelize across file content cat input.csv | parallel -C, "mv {1} {2}" cat input.csv | parallel -C --header "mv {source} {dest}" 30](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-35-2048.jpg)






![Detour: Feature hashing • Feature hashing can be used to reduce dimensions of sparse features. • Unlike random projections ? , retains sparsity • Preserves dot products (random projection preserves distances). • Model can fit in memory. • Unsigned ? Consider a hash function h(x) : [0 . . . N] → [0 . . . m], m << N. φi(x) = j:h(j)=i xj • Signed ? Consider additionaly a hash function ξ(x) : [0 . . . N] → {1, −1}. φi(x) = ξ(j)xj 37](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-43-2048.jpg)

![fragileInput format Label Importance [Tag]|namespace Feature . . . | namespace Feature . . . namespace = String[:Float] feature = String[:Float] Examples: • 1 | 1:0.01 32:-0.1 • example|namespace normal text features • 1 3 tag|ad-features ad description |user-features name address age 39](https://image.slidesharecdn.com/commandline-170414014348/75/Data-science-at-the-command-line-45-2048.jpg)








This workshop document outlines a data science workflow focusing on command line tools, particularly for rapid prototyping and reproducibility in data science. It covers obtaining, scrubbing, exploring, modeling, and interpreting data using tools like curl, jq, csvkit, and vowpal wabbit. The workshop is geared towards practical applications, with hands-on exercises incorporating real-world data examples.