Download to read offline

![Accelerated Deep Learning Inference from Constrained Embedded Devices https://iaeme.com/Home/journal/IJECET 12 editor@iaeme.com preparing likewise has different burdens, for example, protection concerns, security, high idleness, correspondence power utilization, and dependability. These calculations perform massive arithmetic computations. To accelerate these calculations at a sensible cost in equipment, we can utilize an instruction set extension comprised of two instruction types- hardware loops and dot product instructions. The primary commitments of this paper are as per the following: • We propose an approach for computing neural network functions that are advanced for the utilization of hardware loops and dot product instructions. • The effectiveness of hardware loops and dot product instructions for performing deep learning functions are evaluated, and • To perform Lenet-5 Neural Network on Zync-7000 There have been different ways to deal with accelerate profound learning capacities. The methodologies can be sorted into two sets. In the first set, the approaches which which attempt to enhance the size of the neural organizations, or, all in all, upgrade the software. Approaches in the second set try to optimize the equipment or hardware on which neural networks are running. As the set used here deals with hardware optimization, we will focus on the related approaches for hardware optimization, and only momentarily observe the progress in software optimizations. A simple instruction set is proposed to evaluate the effectiveness of hardware loops and dot product instructions with fully upgraded assembly functions for the fully connected convolutional neural network [1]. A custom instruction set architecture is used for efficient realization of artificial neural networks and can be parameterized to a subjective fixed- point design [2]. A CNN –specific Instruction set architecture is used which deploys the instruction parameters with high flexibility which embeds parallel computation and data reuse parameters in the instructions [3]. The instruction extensions and micro architectural advancements to increase computational thickness and to limit the amount of pressure towards shared memory hierarchy in RISC Processors [4]. A repetitive neural organization into a convolutional neural network, and the profound provisions of the picture were learnt in equal utilizing the convolutional neural network and the intermittent neural organization [5]. The framework of Complex Network Classifier (CNC) is used by integrating network embedding and convolutional neural network to tackle the problem of network classification. By training the classifier on synthetic complex network data, they showed that CNC can not only classify networks with high accuracy and robustness but can also extract the features of the networks automatically [6]. A valued prediction method is used to exploit the spatial correlation of zero- valued activations within the CNN output feature maps, thereby saving convolution operations [7]. The impact of packet loss on data integrity is reduced by taking advantage of the deep network’s ability to understand neural data and by using a data repair method based on convolutions neural network [8]. The instruction set simulation process is used soft-core Reduced Instruction Set Computer (RISC) processor. They provided reliable simulation platform in creating customizable instruction set for Application Specific Instruction Set Processor (ASIP) [9]. RISC-V ISA compatible processor and effects of instruction set is analyzed on the pipeline/micro-architecture design in terms of instructions encoding, functionality of instructions, instruction types, decoder logic complexity, data hazard detection, register file organization and access, functioning of pipeline, effect of branch instructions, control flow, data memory access, operating modes and execution unit hardware resources [10]. Deep learning algorithms are used increasingly in smart applications. Some of them also run in Internet of Things (IoT) devices. IoT Analytics reports that, by 2025, the number of IoT devices will rise to 22 billion. The motivation for our work stems from the fact that the rise of the IoT will increase the need for low-cost devices built around a single microcontroller capable of](https://image.slidesharecdn.com/ijecet1203002-211204062145/75/ACCELERATED-DEEP-LEARNING-INFERENCE-FROM-CONSTRAINED-EMBEDDED-DEVICES-2-2048.jpg)




![Accelerated Deep Learning Inference from Constrained Embedded Devices https://iaeme.com/Home/journal/IJECET 18 editor@iaeme.com An interesting topic for further research is Posit - an alternative floating-point number format that may offer additional advantages, as it has an increased dynamic range at the same word size. Because of the improved dynamic range, weights could be stored in lower precision, thus, again, decreasing the memory requirements. Combining the reduced size requirements with low-cost ISA improvements could make neural networks more ubiquitous in the price- sensitive embedded systems market. REFERENCES [1] J. Vreca et al., "Accelerating Deep Learning Inference in Constrained Embedded Devices Using Hardware Loops and a Dot Product Unit," in IEEE Access, vol. 8, pp. 165913-165926, 2020, doi: 10.1109/ACCESS.2020.3022824. [2] D. Valencia, S. F. Fard and A. Ali mohammad, "An Artificial Neural Network Processor with a Custom Instruction Set Architecture for Embedded Applications," in IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 67, no. 12, pp. 5200-5210, Dec. 2020, doi: 10.1109/TCSI.2020.3003769. [3] X. Chen and Z. Yu, "A Flexible and Energy-Efficient Convolutional Neural Network Acceleration with Dedicated ISA and Accelerator," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 26, no. 7, pp. 1408-1412, July 2018, doi: 10.1109/TVLSI.2018.2810831. [4] M. Gautschi, Pasquale Davide Schiavone, Andreas Traber, Igor Loi, "Near-Threshold RISC-V Core with DSP Extensions for Scalable IoT Endpoint Devices," in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 25, no. 10, pp. 2700-2713, Oct. 2017, doi: 10.1109/TVLSI.2017.2654506. [5] Y. Tian, "Artificial Intelligence Image Recognition Method Based on Convolutional Neural Network Algorithm," in IEEE Access, vol. 8, pp. 125731-125744, 2020, doi: 10.1109/ACCESS.2020.3006097. [6] Xin, J. Zhang and Y. Shao, "Complex network classification with convolutional neural network," in Tsinghua Science and Technology, vol. 25, no. 4, pp. 447-457, Aug. 2020, doi: 10.26599/TST.2019.9010055. [7] Shomron and U. Weiser, "Spatial Correlation and Value Prediction in Convolutional Neural Networks," in IEEE Computer Architecture Letters, vol. 18, no. 1, pp. 10-13, 1 Jan.-June 2019, doi: 10.1109/LCA.2018.2890236 [8] Y. Qie, P. Song and C. Hao, "Data Repair Without Prior Knowledge Using Deep Convolutional Neural Networks," in IEEE Access, vol. 8, pp. 105351-105361, 2020, doi: 10.1109/ACCESS.2020.2999960. [9] A. J. Salim, S. I. M. Salim, N. R. Samsudin and Y. Soo, "Customized instruction set simulation for soft-core RISC processor," 2012 IEEE Control and System Graduate Research Colloquium, Shah Alam, Selangor, 2012, pp. 38-42, doi: 10.1109/ICSGRC.2012.6287132. [10] A. Raveendran, V. B. Patil, D. Selvakumar and V. Desalphine, "A RISC-V instruction set processor-micro-architecture design and analysis," 2016 International Conference on VLSI Systems, Architectures, Technology and Applications (VLSI-SATA), Bangalore, 2016, pp. 1-7, doi: 10.1109/VLSI-SATA.2016.7593047.](https://image.slidesharecdn.com/ijecet1203002-211204062145/75/ACCELERATED-DEEP-LEARNING-INFERENCE-FROM-CONSTRAINED-EMBEDDED-DEVICES-8-2048.jpg)

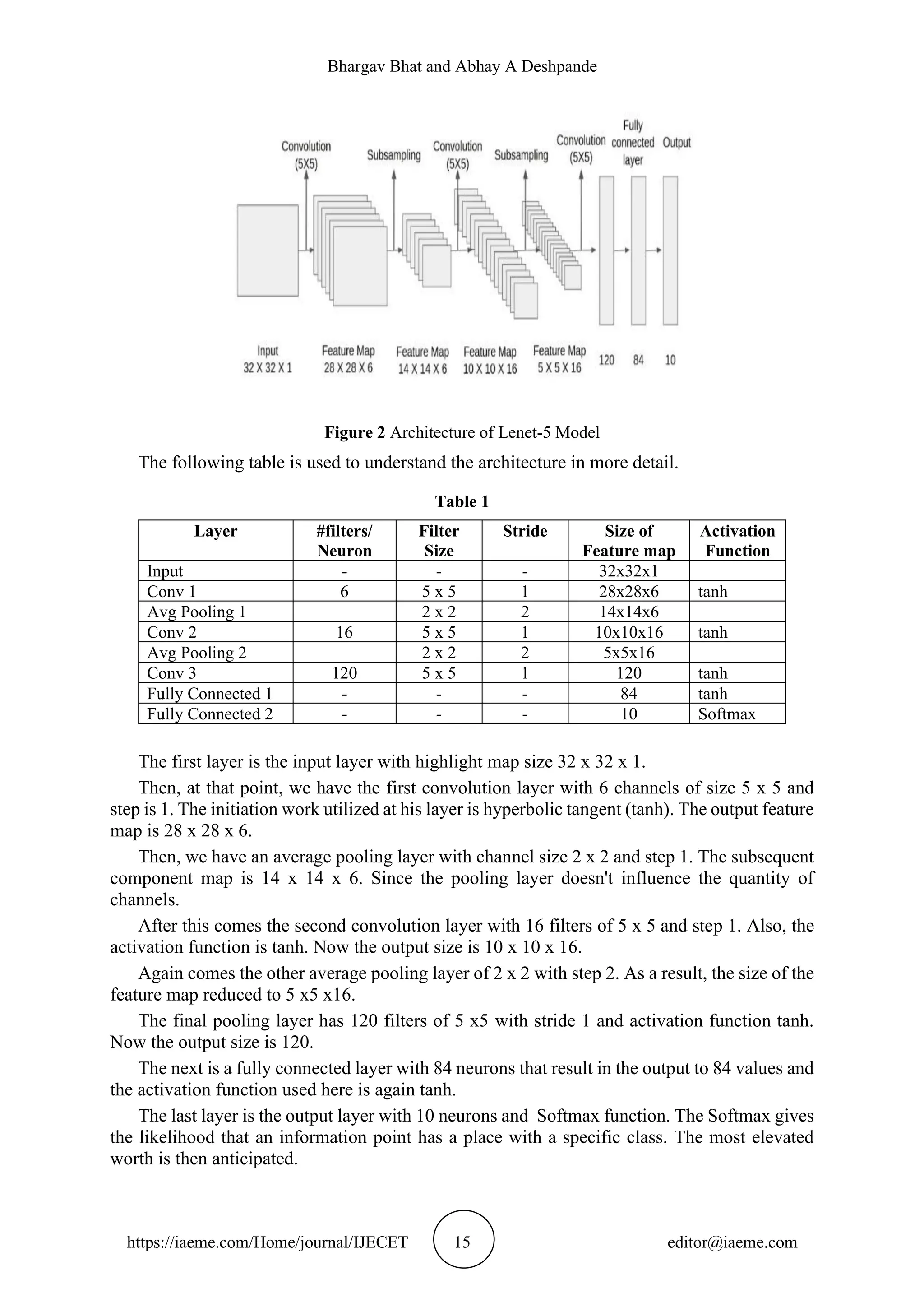
This document presents a study on optimizing deep learning inference in constrained embedded devices using hardware looping and loop unrolling techniques with a focus on a convolutional neural network (CNN). It evaluates the performance improvements achieved through these techniques on a Lenet-5 model implemented on a Zynq-7000 FPGA, demonstrating significant reductions in cycle count. The findings suggest that hardware loops and dot product instructions are effective in accelerating deep learning functions in resource-limited environments, setting the stage for future advancements in neural networks for embedded systems.