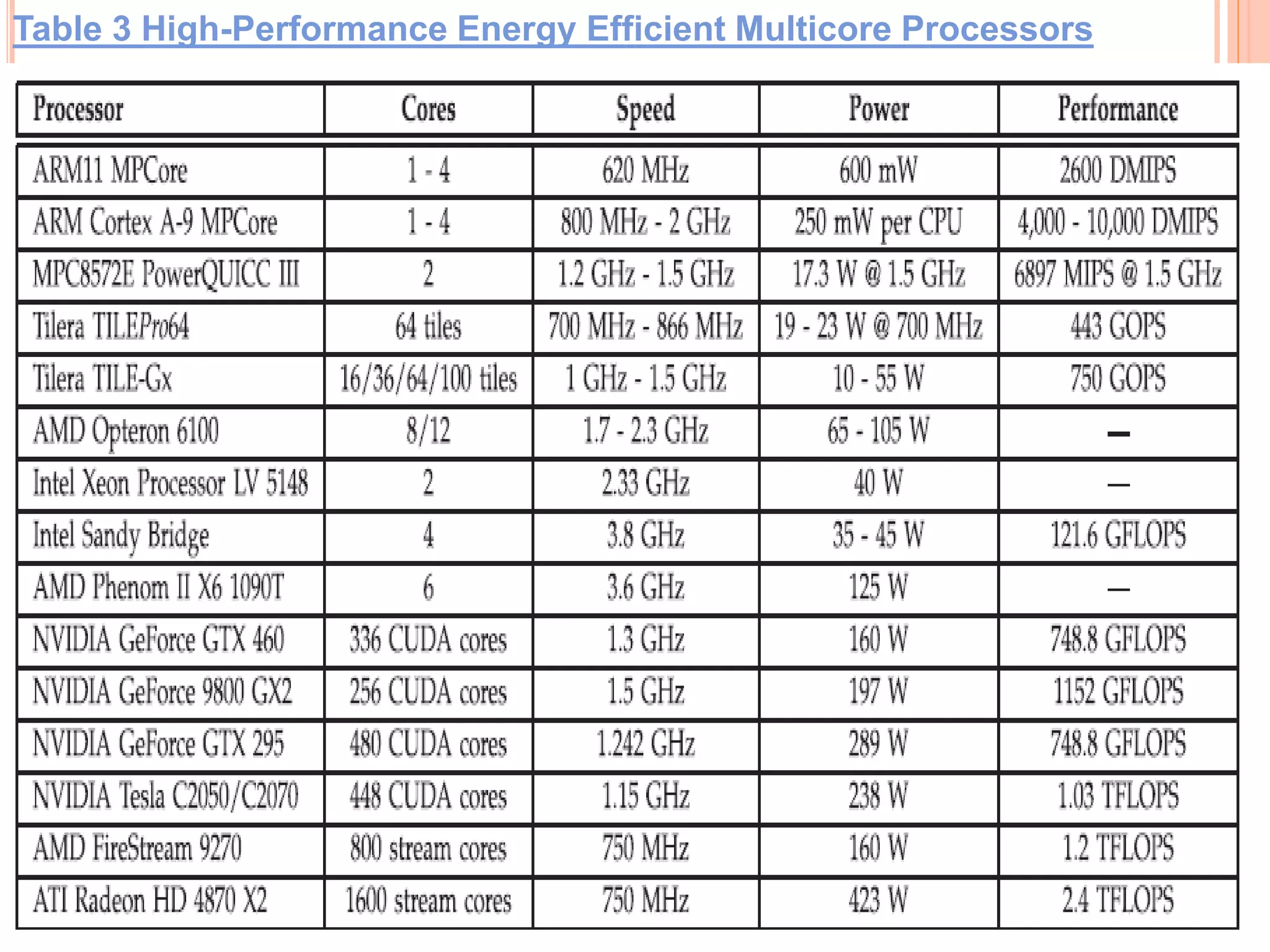
The document discusses high-performance energy efficient multicore embedded computing. It describes the challenges of achieving both high performance and low power consumption. Several approaches are examined at the architectural level, including heterogeneous multicore processors, cache partitioning, and wireless interconnects. Hardware-assisted middleware approaches like power gating and software approaches like task scheduling and migration are also covered. Finally, examples of commercial high-performance energy efficient multicore processors are provided. The document concludes that high-performance energy efficient computing is an important research area with applications from consumer electronics to supercomputing.





















![31 7. References [1] W. Dally, J. Balfour, D. Black-Shaffer, J. Chen, R. Harting, V.Parikh, J. Park, and D. Sheffield, “Efficient Embedded Computing,” Computer, vol. 41, no. 7, pp. 27-32, July 2008. [2] J. Balfour, “Efficient Embedded Computing,” PhD thesis, EE Dept., Stanford Univ., May 2010. [3] P. Gepner, D. Fraser, M. Kowalik, and R. Tylman, “New Multi- Core Intel Xeon Processors Help Design Energy Efficient Solution for High Performance Computing,” Proc. Int’l MultiConf. Computer Science and Information Technology (IMCSIT), Oct. 2009. [4] P. Crowley, M. Franklin, J. Buhler, and R. Chamberlain, “Impact of CMP Design on High-Performance Embedded Computing,” Proc. High Performance Embedded Computing (HPEC) Workshop, Sept. 2006. DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING](https://image.slidesharecdn.com/high-performanceenergyefficientmulticoreembeddedcomputing-150219062436-conversion-gate01/75/High-performance-energy-efficient-multicore-embedded-computing-31-2048.jpg)
![ [5] Top500, “Top 500 Supercomputer Sites,” http://www.top500. org/, June 2011. [6] Green500, “Ranking the World’s Most Energy- Efficient Supercomputers,” http://www.green500.org/, June 2011. [7] K. Hwang, “Advanced Parallel Processing with Supercomputer Architectures,” Proc. IEEE, vol. 75, no. 10, pp. 1348-1379, Oct. 1987. [8] A. Klietz, A. Malevsky, and K. Chin-Purcell, “Mix-and- Match High Performance Computing,” IEEE Potentials, vol. 13, no. 3, pp. 6-10, Aug./Sept. 1994. And Many More. 32 DEPARTMENT OF COMPUTER SCIENCE & ENGINEERING](https://image.slidesharecdn.com/high-performanceenergyefficientmulticoreembeddedcomputing-150219062436-conversion-gate01/75/High-performance-energy-efficient-multicore-embedded-computing-32-2048.jpg)
