Downloaded 102 times











![About: CSV CSV developed by IBM in 1972 ▪ Ease of typing CSV lists on punched cards Flexible (not always good) Row-based Human Readable Compressible Splittable ▪ When raw / using spittable format Supported Natively Fast (from a write perspective) Comma Separated Value (CSV) $ cat myTable.csv "student_id","subject","score" 71,"math",97.44 33,"history",88.32 101,"geography",73.11 13,"physics",87.78 scala> val table = spark.read.option("header","true") .option("inferSchema", "true").csv("myTable.csv") table: org.apache.spark.sql.DataFrame = [student_id: int, subject: string ... 1 more field] scala> table.printSchema root |-- student_id: integer (nullable = true) |-- subject: string (nullable = true) |-- score: double (nullable = true) scala> table.show +----------+---------+-----+ |student_id| subject|score| +----------+---------+-----+ | 71| math|97.44| | 33| history|88.32| | 101|geography|73.11| | 13| physics|87.78| +----------+---------+-----+ * Some formatting applied](https://image.slidesharecdn.com/488vinooganesh-200628042751/75/The-Apache-Spark-File-Format-Ecosystem-19-2048.jpg)

![About: JSON Specified in early 2000s Self-Describing Row-based Human Readable Compressible Splittable (in some cases) Supported natively in Spark Supports Complex Data Types Fast (from a write perspective) JSON (JavaScript Object Notation) $ cat myTable.json {"student_id":71,"subject":"math","score":97.44} {"student_id":33,"subject":"history","score":88.32} {"student_id":101,"subject":"geography","score":73.11} {"student_id":13,"subject":"physics","score":87.78} scala> val table = spark.read.json("myTable.json") table: org.apache.spark.sql.DataFrame = [score: double, student_id: bigint ... 1 more field] scala> table.show +-----+----------+---------+ |score|student_id| subject| +-----+----------+---------+ |97.44| 71| math| |88.32| 33| history| |73.11| 101|geography| |87.78| 13| physics| +-----+----------+---------+ * Some formatting applied](https://image.slidesharecdn.com/488vinooganesh-200628042751/75/The-Apache-Spark-File-Format-Ecosystem-21-2048.jpg)


![Inspecting: Avro $ avro-tools tojson part-00000-tid-8566179657485710941-115d547d-6b9a-43cf-957a-c549d3243afb-3-1-c000.avro {"student_id":{"int":71},"subject":{"string":"math"},"score":{"double":97.44}} {"student_id":{"int":33},"subject":{"string":"history"},"score":{"double":88.32}} {"student_id":{"int":101},"subject":{"string":"geography"},"score":{"double":73.11}} {"student_id":{"int":13},"subject":{"string":"physics"},"score":{"double":87.78}} $ avro-tools getmeta part-00000-tid-8566179657485710941-115d547d-6b9a-43cf-957a-c549d3243afb-3-1-c000.avro avro.schema { "type" : "record", "name" : "topLevelRecord", "fields" : [ { "name" : "student_id", "type" : [ "int", "null" ] }, { "name" : "subject", "type" : [ "string", "null" ] }, { "name" : "score", "type" : [ "double", "null" ] } ] } avro.codec snappy * Some formatting applied](https://image.slidesharecdn.com/488vinooganesh-200628042751/75/The-Apache-Spark-File-Format-Ecosystem-24-2048.jpg)



![Inspecting: ORC $ orc-tools meta part-00000-34aef610-c8d4-46fb-84c9- b43887d2b37e-c000.snappy.orc Processing data file part-00000-34aef610-c8d4-46fb-84c9- b43887d2b37e-c000.snappy.orc [length: 574] Structure for part-00000-34aef610-c8d4-46fb-84c9-b43887d2b37e- c000.snappy.orc File Version: 0.12 with ORC_135 Rows: 4 Compression: SNAPPY Compression size: 262144 Type: struct<score:double,student_id:bigint,subject:string> Stripe Statistics: Stripe 1: Column 0: count: 4 hasNull: false Column 1: count: 4 hasNull: false bytesOnDisk: 35 min: 73.11 max: 97.44 sum: 346.65 Column 2: count: 4 hasNull: false bytesOnDisk: 9 min: 13 max: 101 sum: 218 Column 3: count: 4 hasNull: false bytesOnDisk: 37 min: geography max: physics sum: 27 File Statistics: Column 0: count: 4 hasNull: false Column 1: count: 4 hasNull: false bytesOnDisk: 35 min: 73.11 max: 97.44 sum: 346.65 Column 2: count: 4 hasNull: false bytesOnDisk: 9 min: 13 min: 101 sum: 218 Column 3: count: 4 hasNull: false bytesOnDisk: 37 min: geography max: physics sum: 27 Stripes: Stripe: offset: 3 data: 81 rows: 4 tail: 75 index: 123 Stream: column 0 section ROW_INDEX start: 3 length 11 Stream: column 1 section ROW_INDEX start: 14 length 44 Stream: column 2 section ROW_INDEX start: 58 length 26 Stream: column 3 section ROW_INDEX start: 84 length 42 Stream: column 1 section DATA start: 126 length 35 Stream: column 2 section DATA start: 161 length 9 Stream: column 3 section DATA start: 170 length 30 Stream: column 3 section LENGTH start: 200 length 7 Encoding column 0: DIRECT Encoding column 1: DIRECT Encoding column 2: DIRECT_V2 Encoding column 3: DIRECT_V2 File length: 574 bytes Padding length: 0 bytes Padding ratio: 0% * Some formatting applied](https://image.slidesharecdn.com/488vinooganesh-200628042751/75/The-Apache-Spark-File-Format-Ecosystem-28-2048.jpg)



![Inspecting: Parquet (1) $ parquet-tools meta part-00000-5adea6d5-53ae-49cc-8f70-a7365519b6bf-c000.snappy.parquet file: file:part-00000-5adea6d5-53ae-49cc-8f70-a7365519b6bf-c000.snappy.parquet creator: parquet-mr version 1.10.1 (build a89df8f9932b6ef6633d06069e50c9b7970bebd1) extra: org.apache.spark.sql.parquet.row.metadata = {"type":"struct","fields":[{"name":"score","type":"double","nullable":true,"metadata":{}},{"name":"student _id","type":"long","nullable":true,"metadata":{}},{"name":"subject","type":"string","nullable":true,"metad ata":{}}]} file schema: spark_schema -------------------------------------------------------------------------------- score: OPTIONAL DOUBLE R:0 D:1 student_id: OPTIONAL INT64 R:0 D:1 subject: OPTIONAL BINARY O:UTF8 R:0 D:1 row group 1: RC:4 TS:288 OFFSET:4 -------------------------------------------------------------------------------- score: DOUBLE SNAPPY DO:0 FPO:4 SZ:101/99/0.98 VC:4 ENC:PLAIN,BIT_PACKED,RLE ST:[min: 73.11, max: 97.44, num_nulls: 0] student_id: INT64 SNAPPY DO:0 FPO:105 SZ:95/99/1.04 VC:4 ENC:PLAIN,BIT_PACKED,RLE ST:[min: 13, max: 101, num_nulls: 0] subject: BINARY SNAPPY DO:0 FPO:200 SZ:92/90/0.98 VC:4 ENC:PLAIN,BIT_PACKED,RLE ST:[min: geography, max: physics, num_nulls: 0] * Some formatting applied](https://image.slidesharecdn.com/488vinooganesh-200628042751/75/The-Apache-Spark-File-Format-Ecosystem-32-2048.jpg)
![Inspecting: Parquet (2) $ parquet-tools dump part-00000-5adea6d5-53ae-49cc-8f70-a7365519b6bf- c000.snappy.parquet row group 0 ------------------------------------------------------------------------- score: DOUBLE SNAPPY DO:0 FPO:4 SZ:101/99/0.98 VC:4 ENC:RLE,BIT_ [more]... student_id: INT64 SNAPPY DO:0 FPO:105 SZ:95/99/1.04 VC:4 ENC:RLE,BIT_ [more]... subject: BINARY SNAPPY DO:0 FPO:200 SZ:92/90/0.98 VC:4 ENC:RLE,BIT [more]... score TV=4 RL=0 DL=1 --------------------------------------------------------------------- page 0: DLE:RLE RLE:BIT_PACKED VLE:PLAIN ST:[min: 73.11, max: 97. [more]... VC:4 student_id TV=4 RL=0 DL=1 --------------------------------------------------------------------- page 0: DLE:RLE RLE:BIT_PACKED VLE:PLAIN ST:[min: 13, max: 101, n [more]... VC:4 subject TV=4 RL=0 DL=1 --------------------------------------------------------------------- page 0: DLE:RLE RLE:BIT_PACKED VLE:PLAIN ST:[min: geography, max: [more]... VC:4 DOUBLE score --------------------------------------- *** row group 1 of 1, values 1 to 4 *** value 1: R:0 D:1 V:97.44 value 2: R:0 D:1 V:88.32 value 3: R:0 D:1 V:73.11 value 4: R:0 D:1 V:87.78 INT64 student_id --------------------------------------- *** row group 1 of 1, values 1 to 4 *** value 1: R:0 D:1 V:71 value 2: R:0 D:1 V:33 value 3: R:0 D:1 V:101 value 4: R:0 D:1 V:13 BINARY subject --------------------------------------- *** row group 1 of 1, values 1 to 4 *** value 1: R:0 D:1 V:math value 2: R:0 D:1 V:history value 3: R:0 D:1 V:geography value 4: R:0 D:1 V:physics * Some formatting applied](https://image.slidesharecdn.com/488vinooganesh-200628042751/75/The-Apache-Spark-File-Format-Ecosystem-33-2048.jpg)












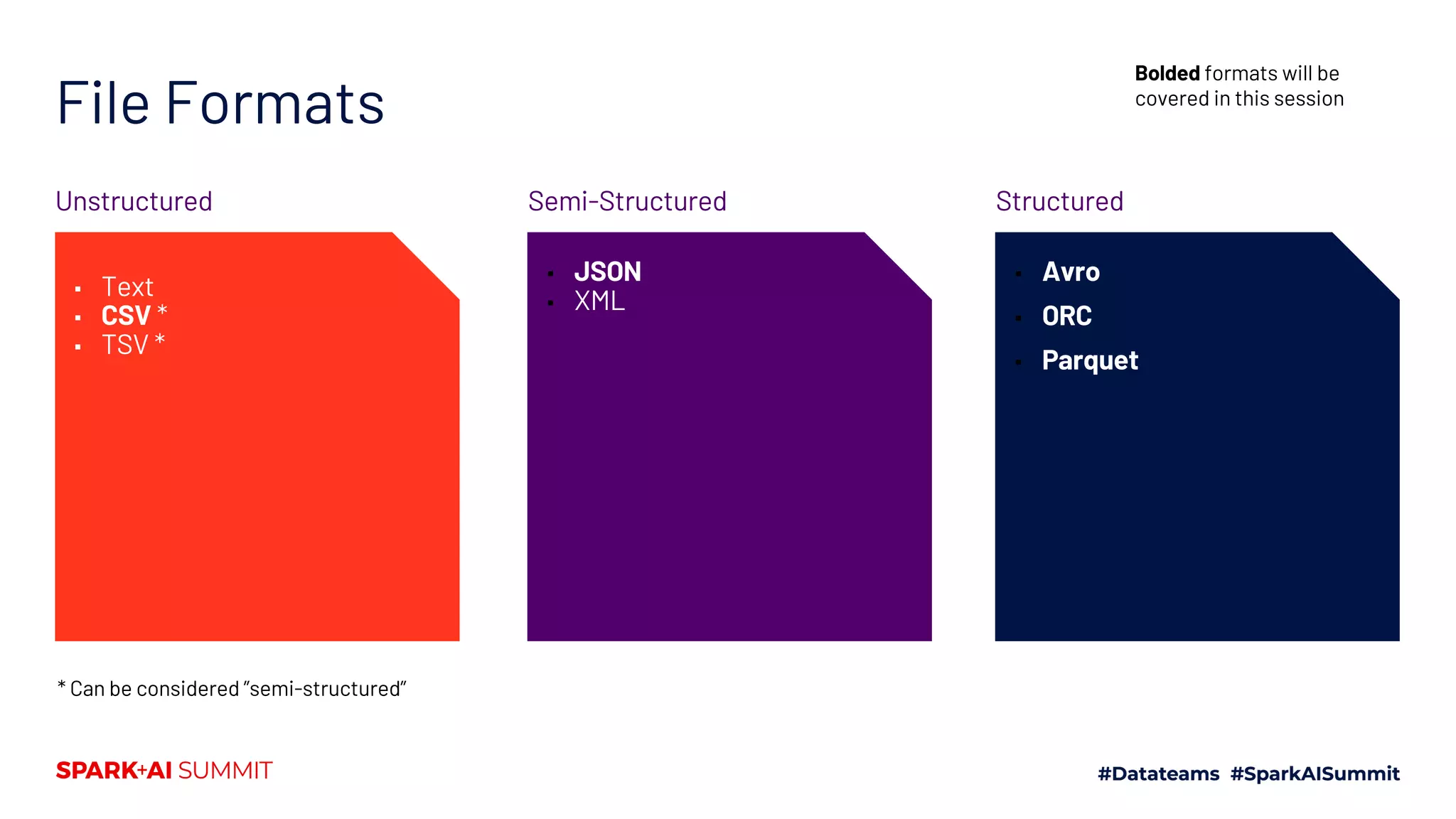
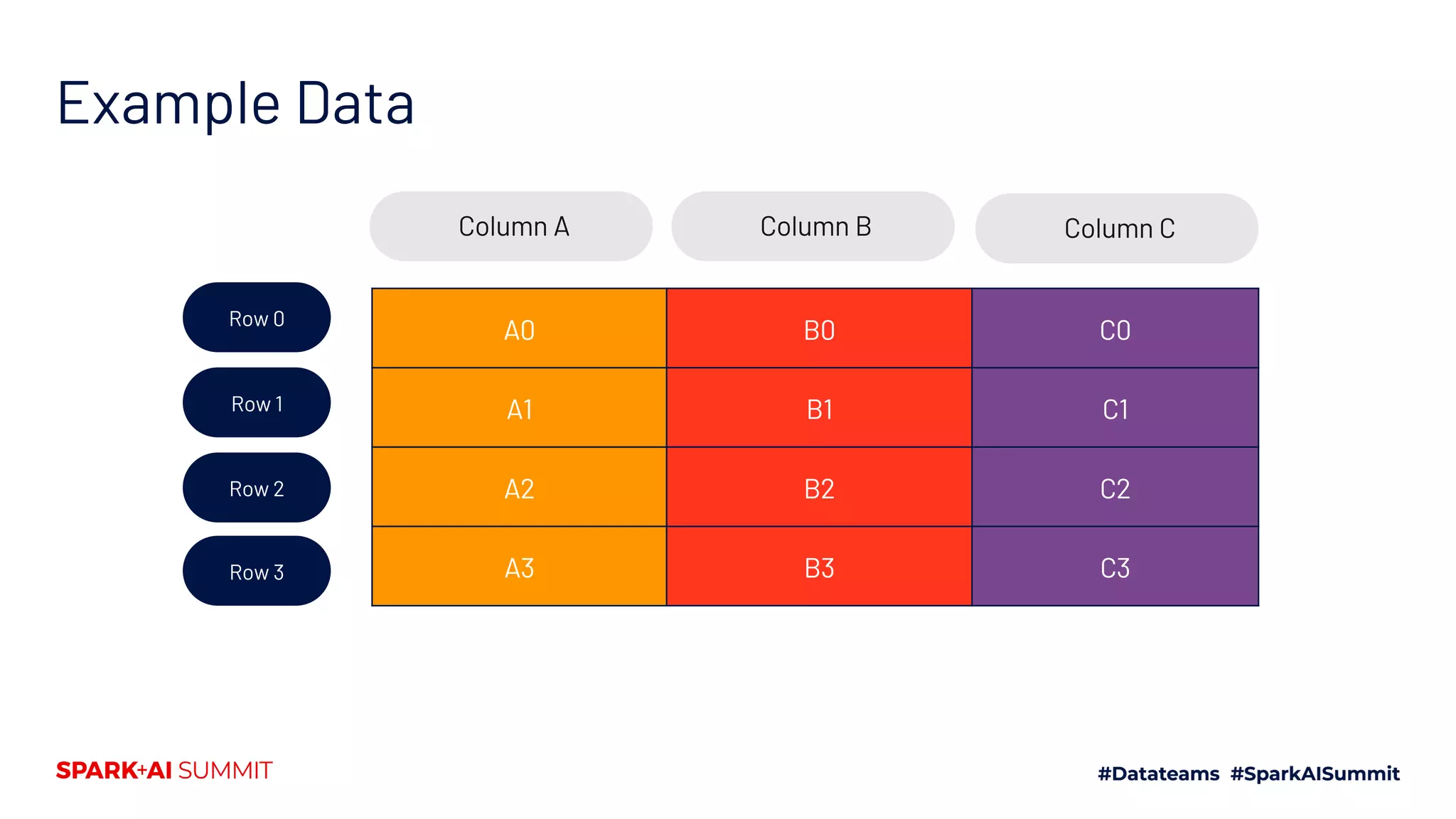
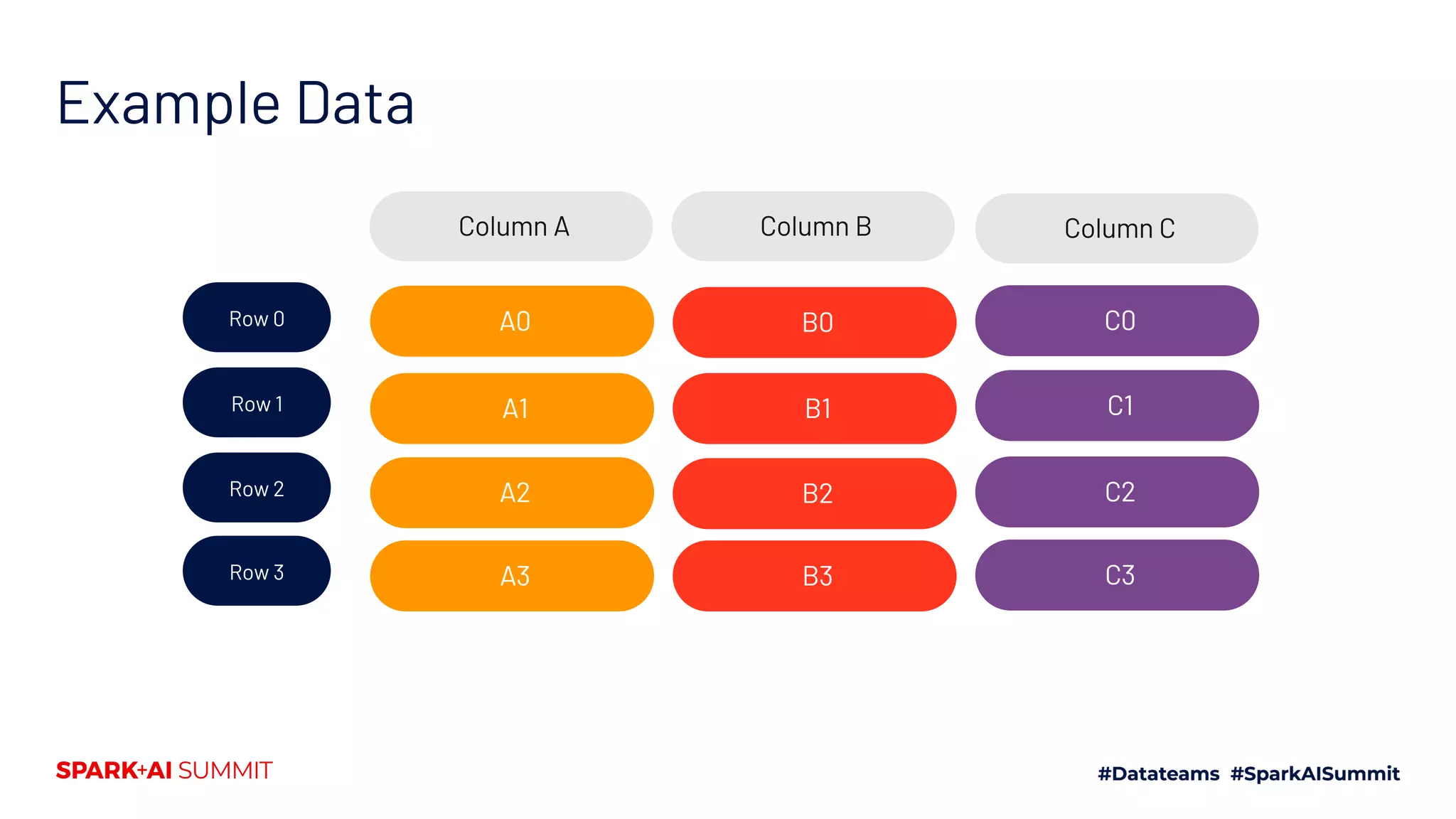
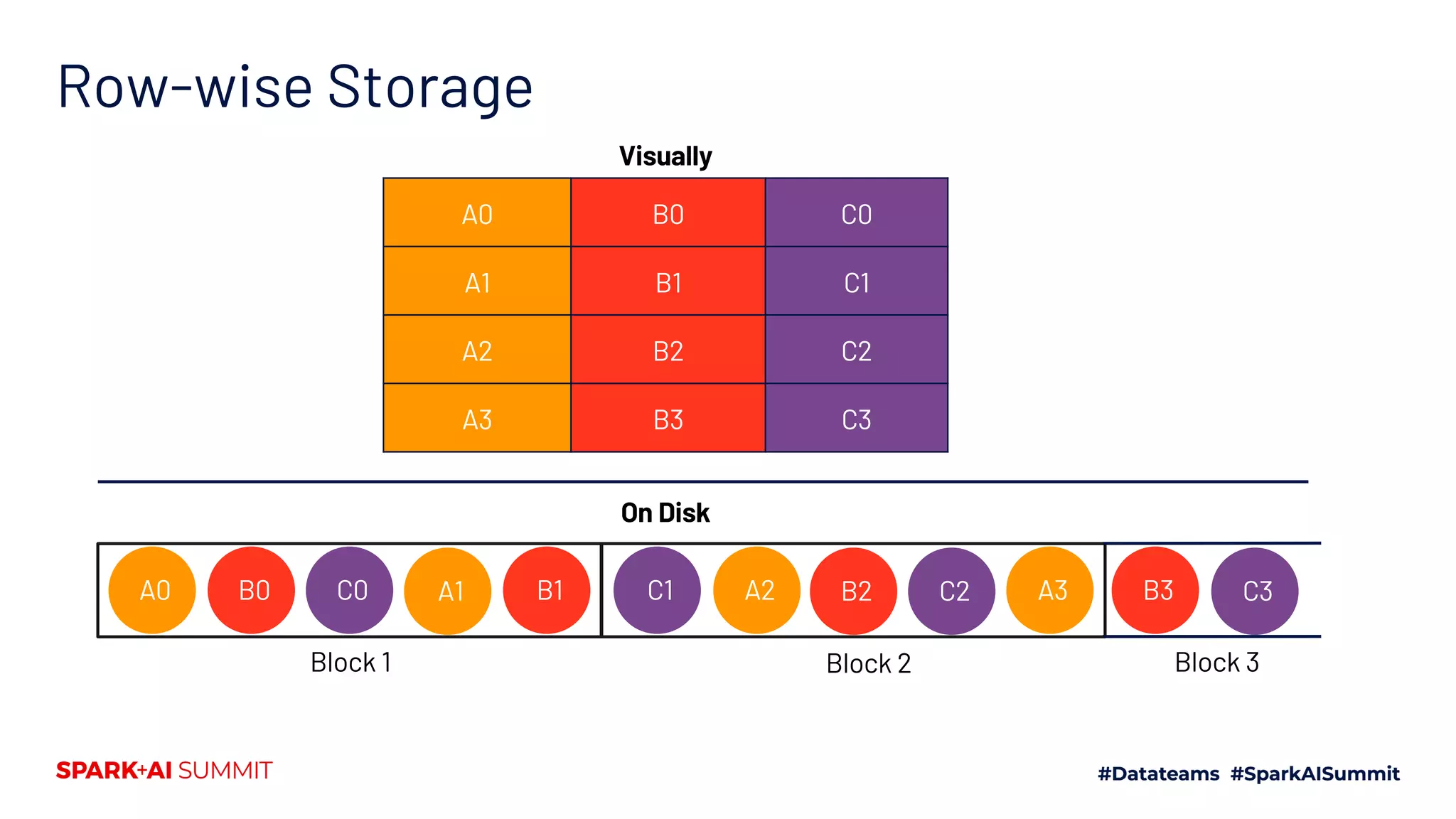
The document explores the Spark file format ecosystem as presented by Vinoo Ganesh, CTO of Veraset, focusing on data storage solutions for OLTP and OLAP workflows. It covers various file formats such as CSV, JSON, Avro, ORC, and Parquet, detailing their characteristics and optimal use cases. The session aims to educate on file format configurations and their impact on data processing efficiency and access patterns.