Download as PDF, PPTX






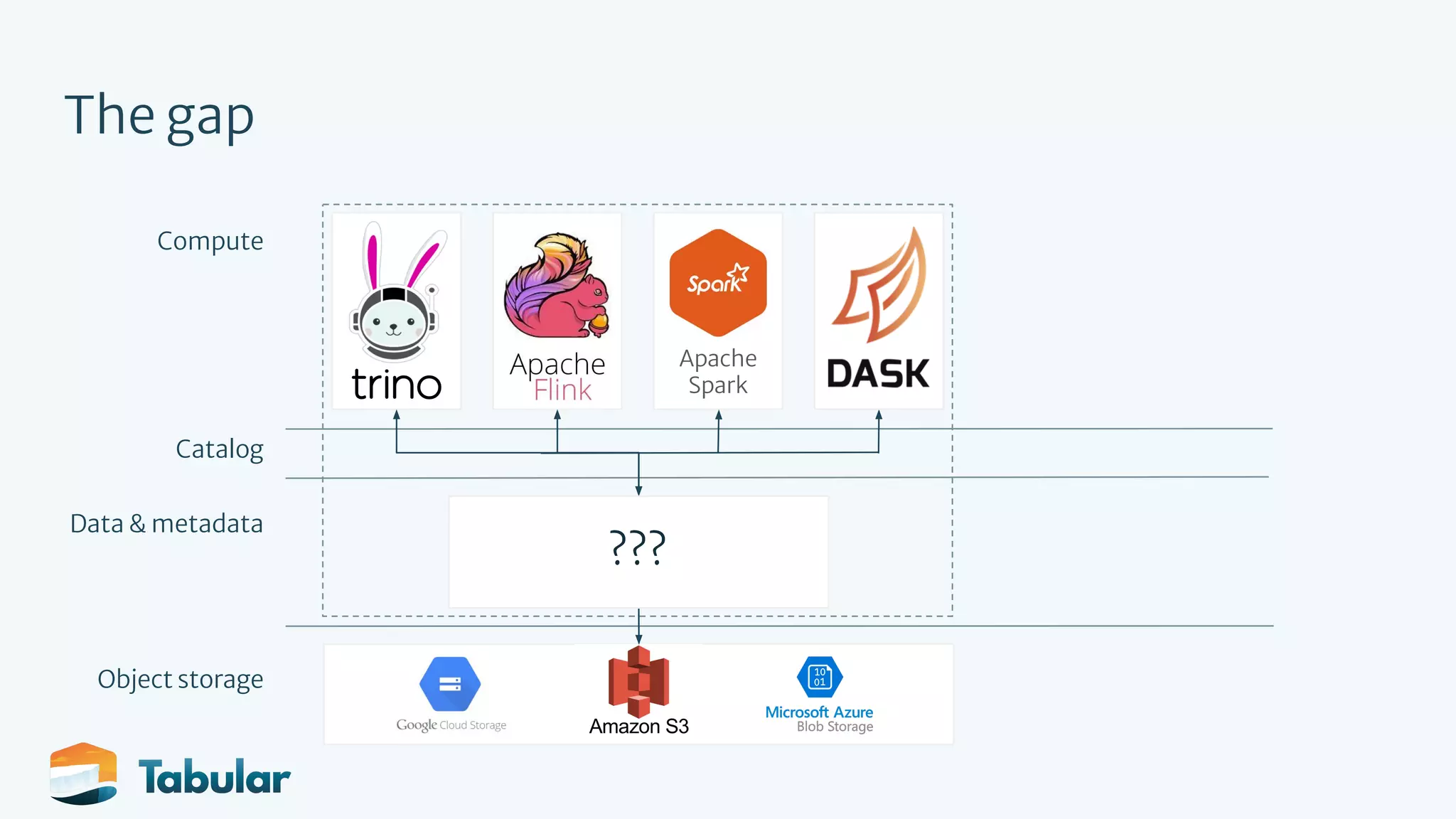


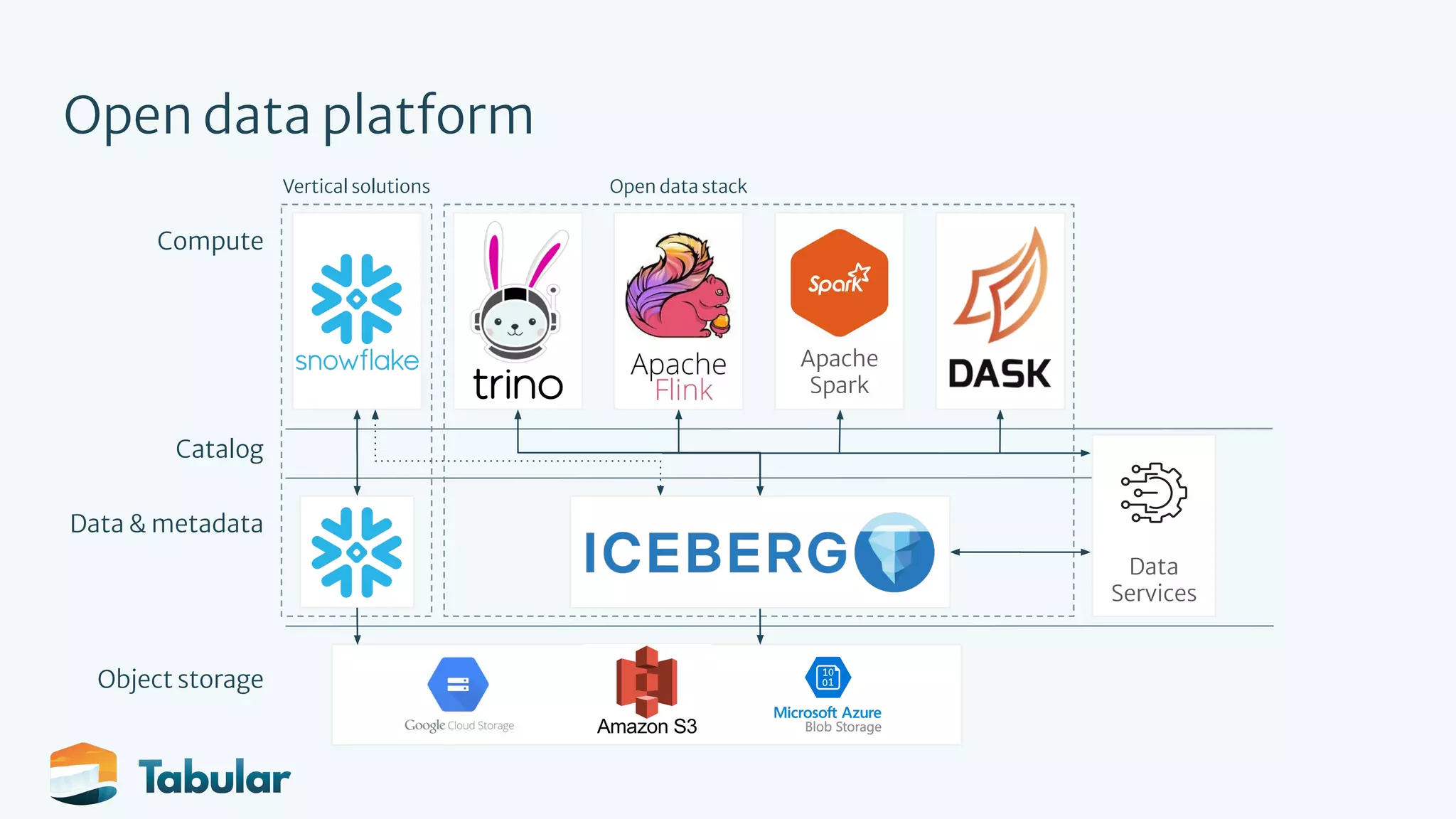








The document outlines the development of an open data platform using Apache Iceberg, which serves as a table format for analytic data, providing transactional guarantees and performance enhancements. It highlights the need for a multi-engine architecture that leverages various tools like Spark, Trino, and Flink, while addressing usability and productivity issues within data management. Key goals of Iceberg include improving transactions, performance, and usability through features like schema evolution and reliable updates.