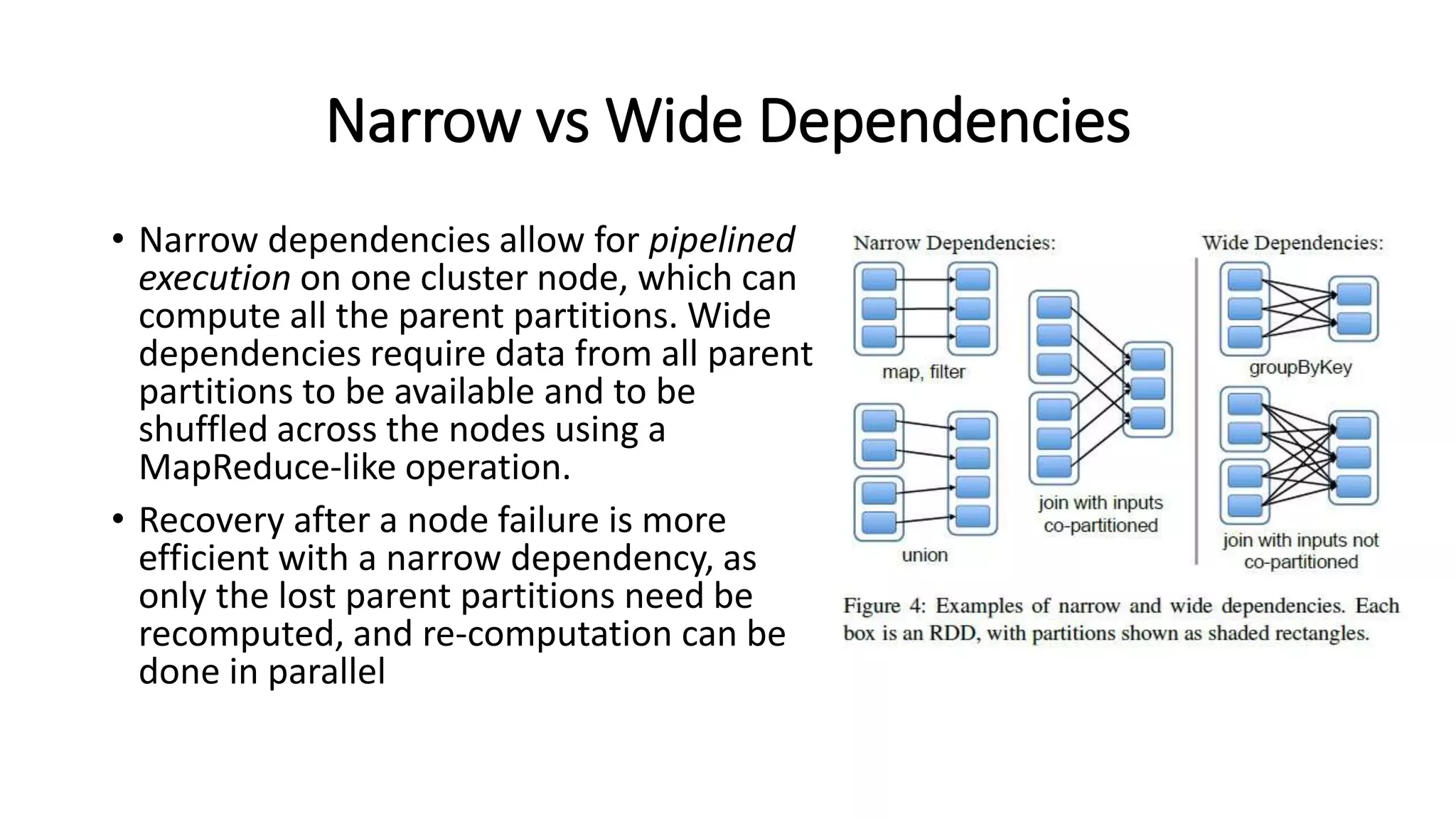
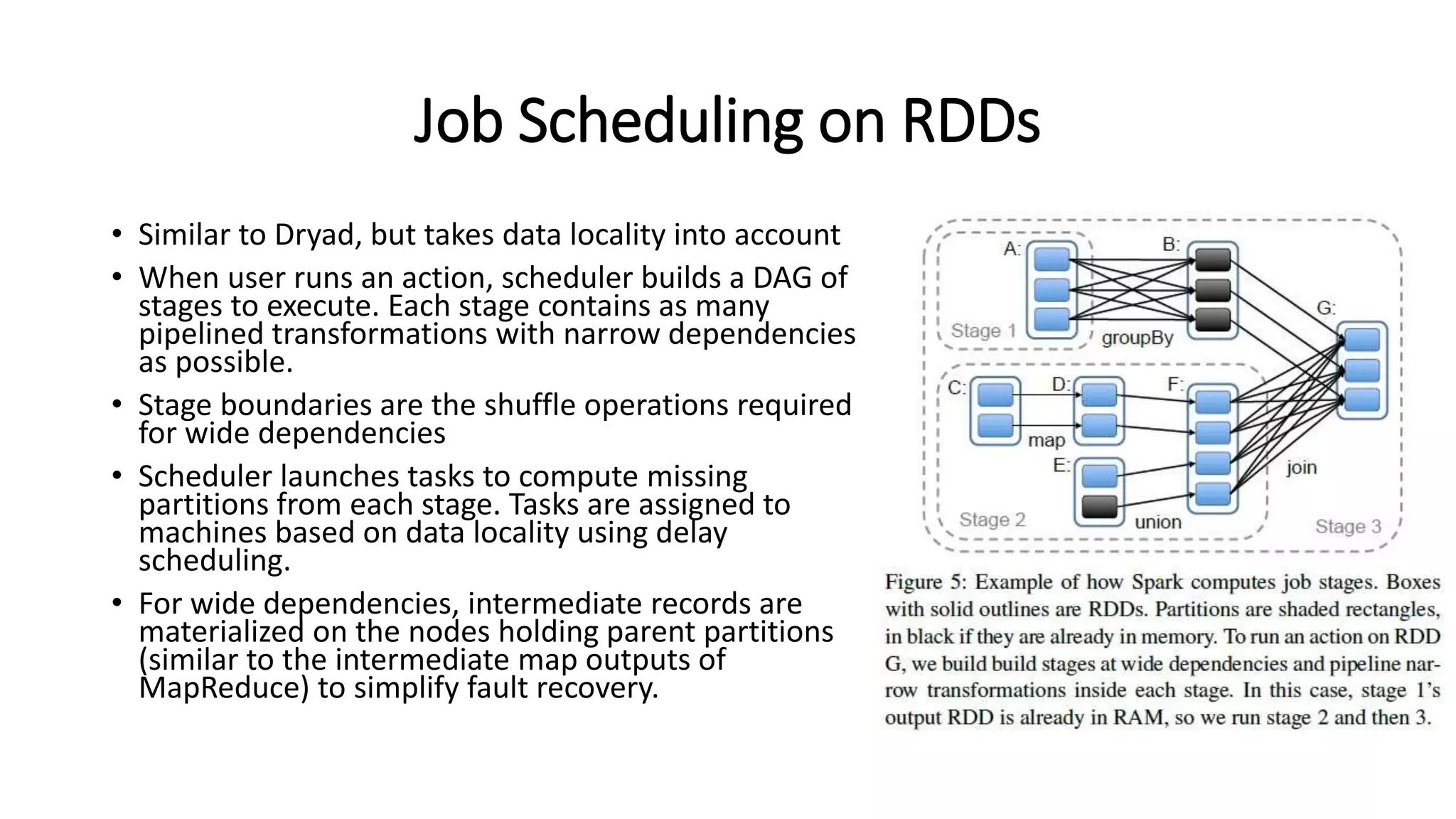
The document summarizes the foundational papers of Apache Spark, discussing its advantages over MapReduce, particularly in applications requiring iterative data processing. It introduces the concept of Resilient Distributed Datasets (RDDs) for fault-tolerant in-memory computing and explains their operations, lazy transformations, and the significance of data lineage. It further details job scheduling, dependency management, shared variables like broadcast and accumulators, and debuggability with RDDs.