Download as PDF, PPTX



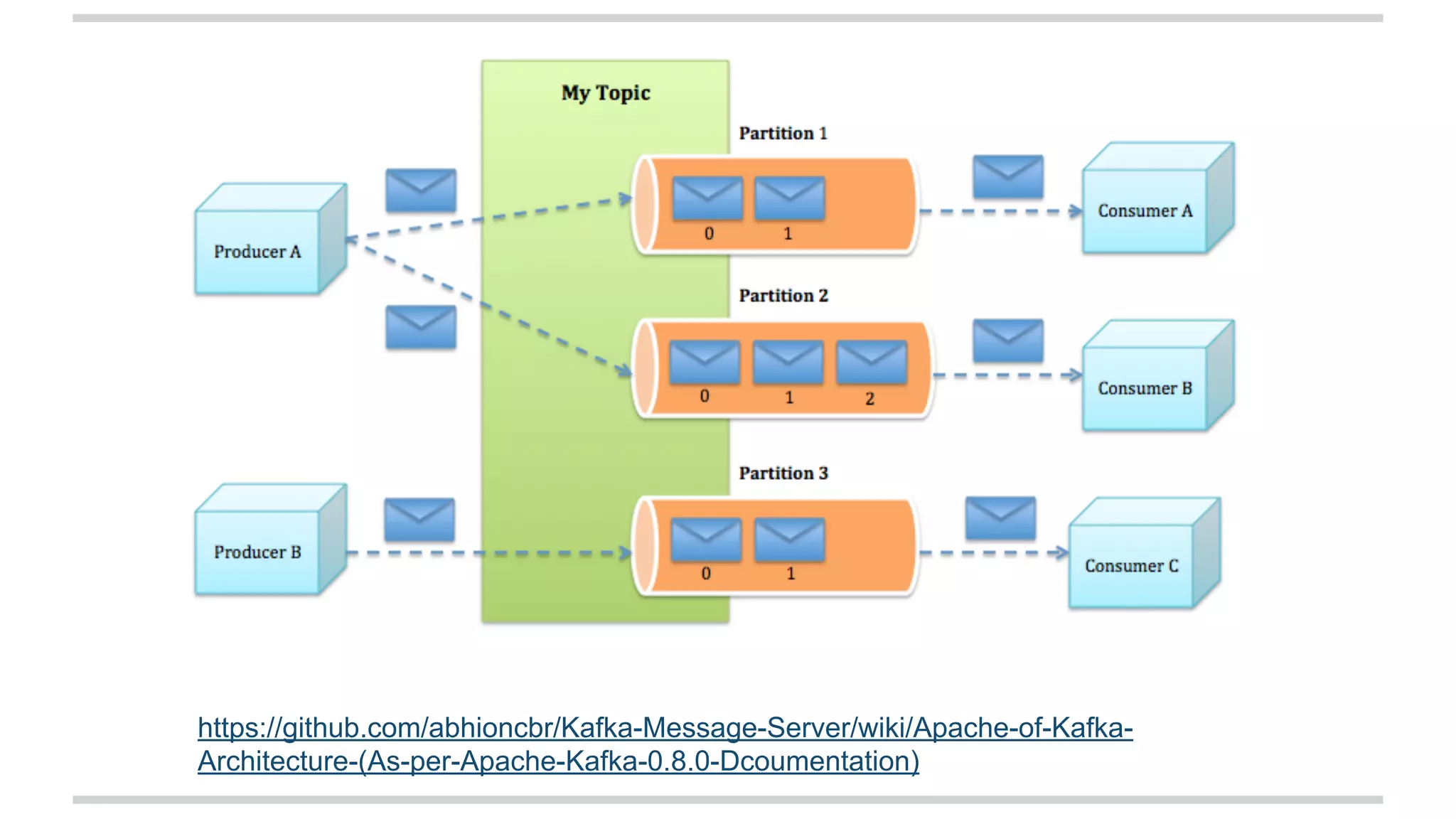










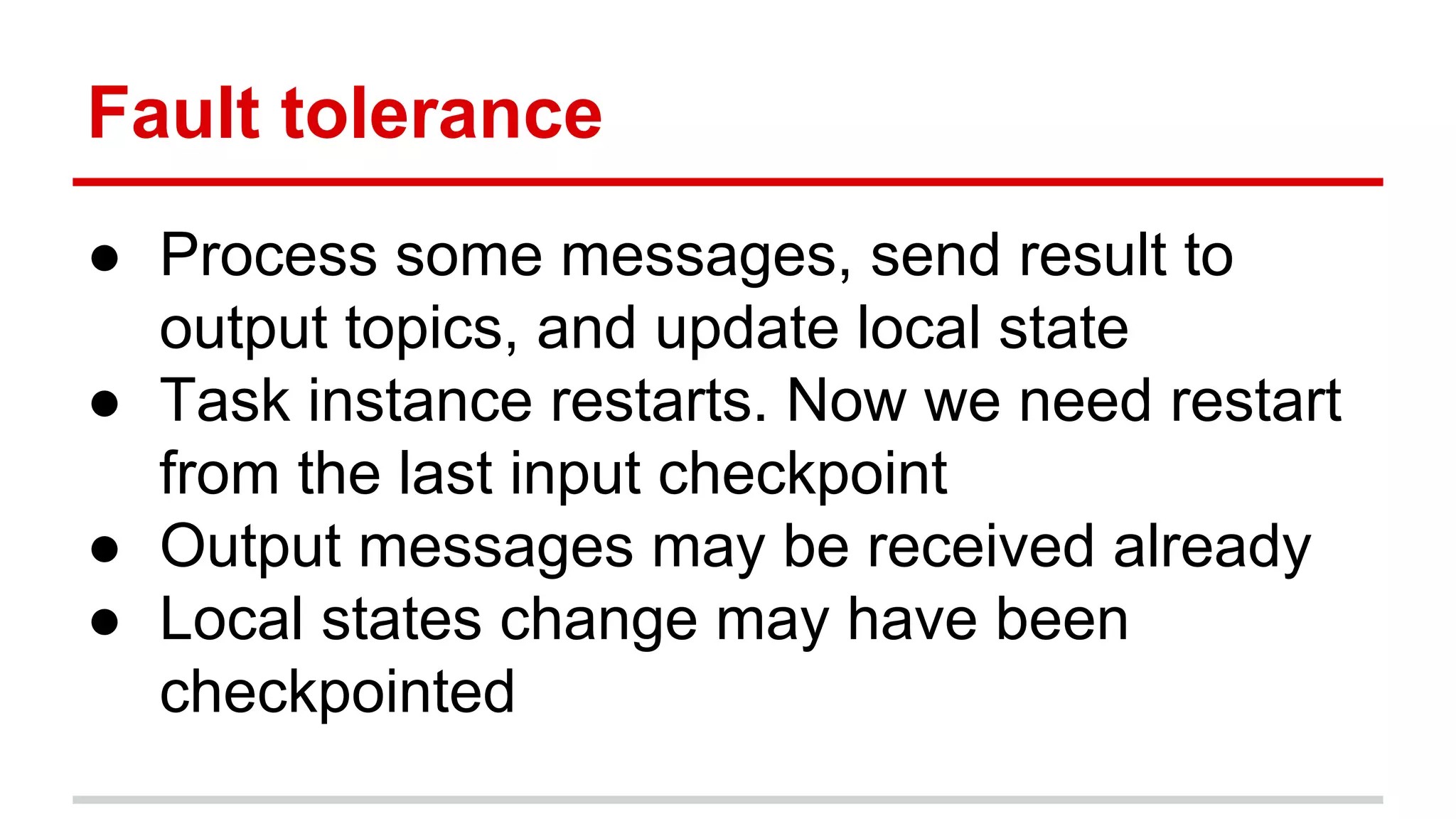
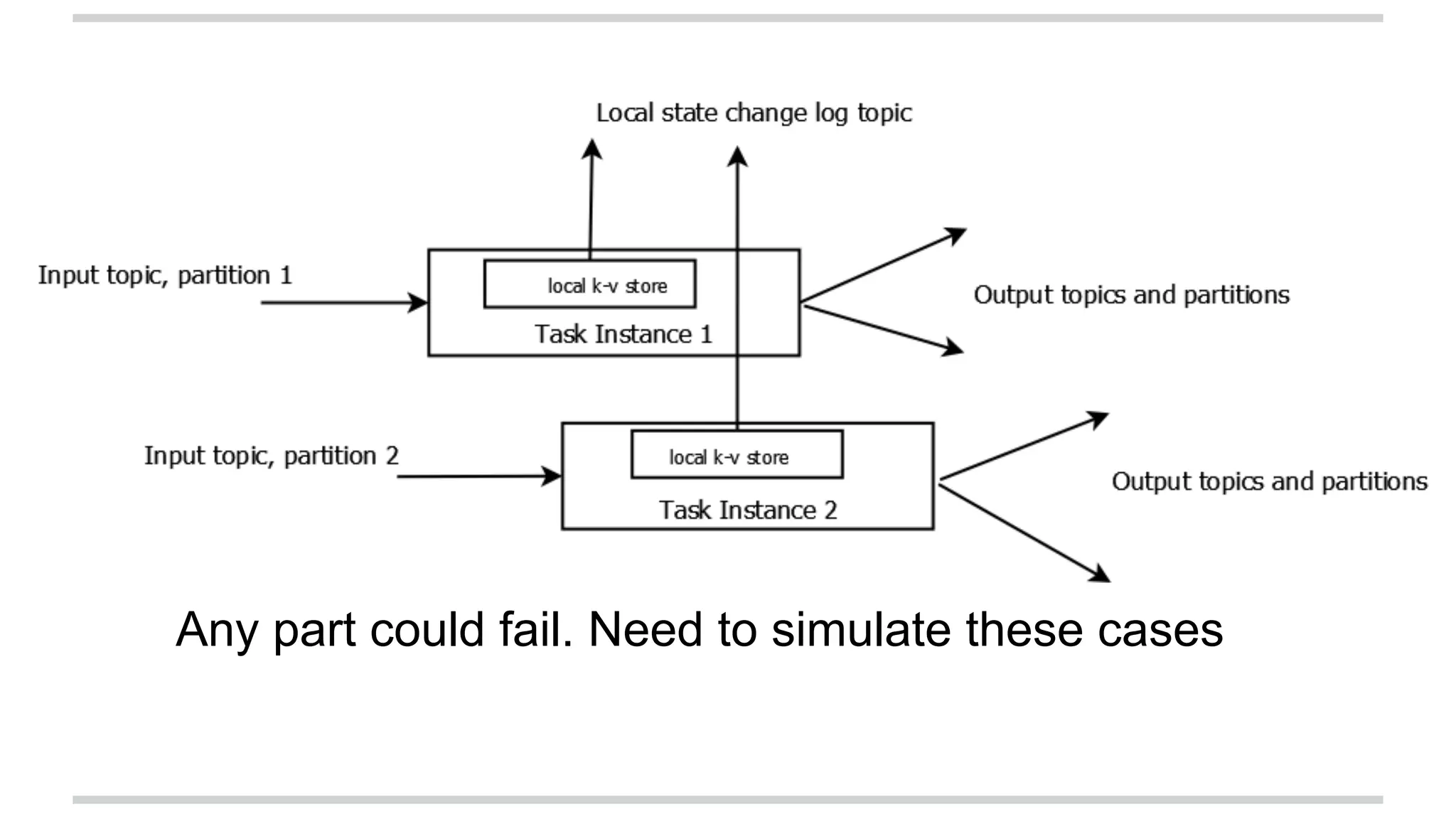




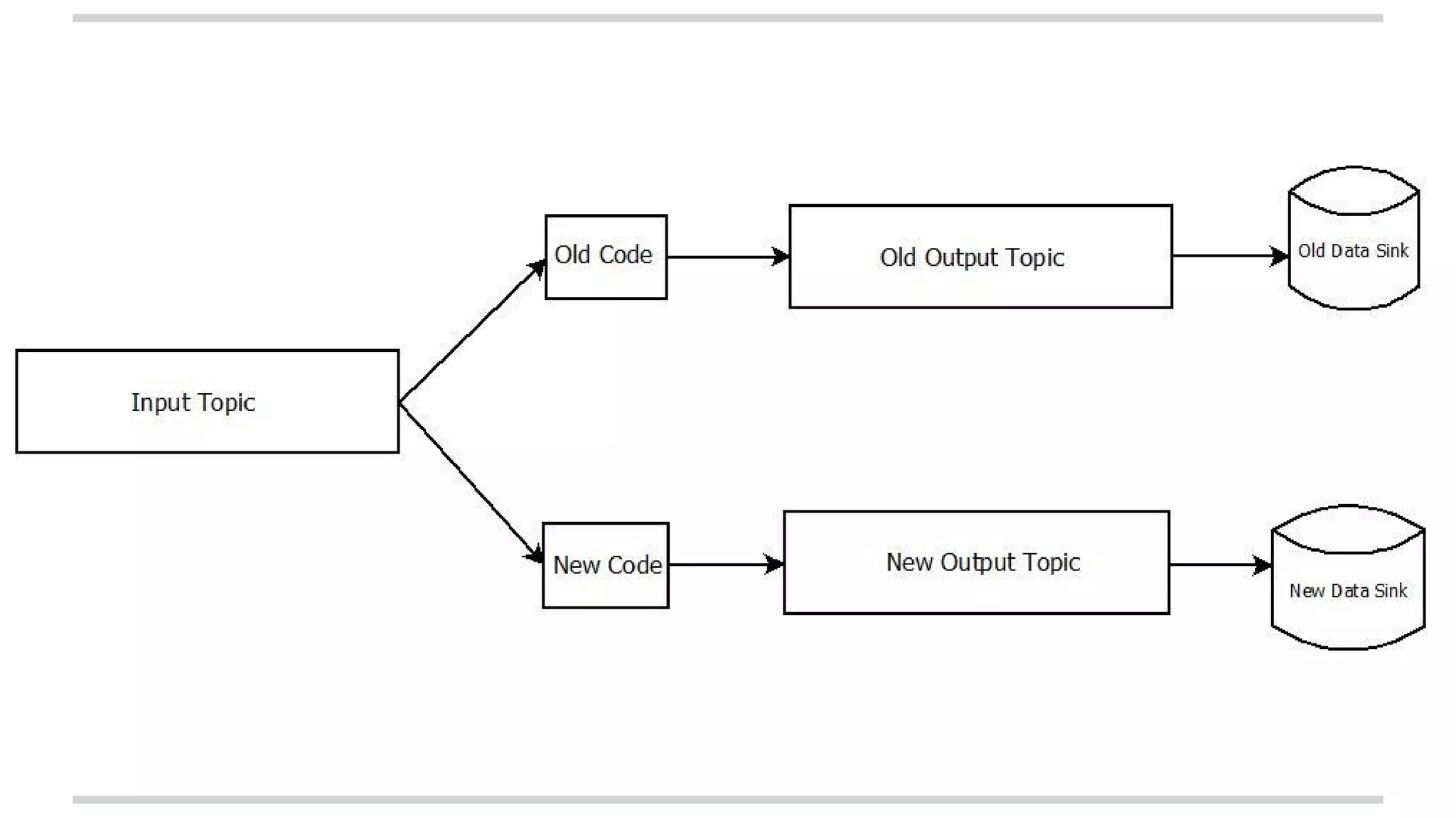



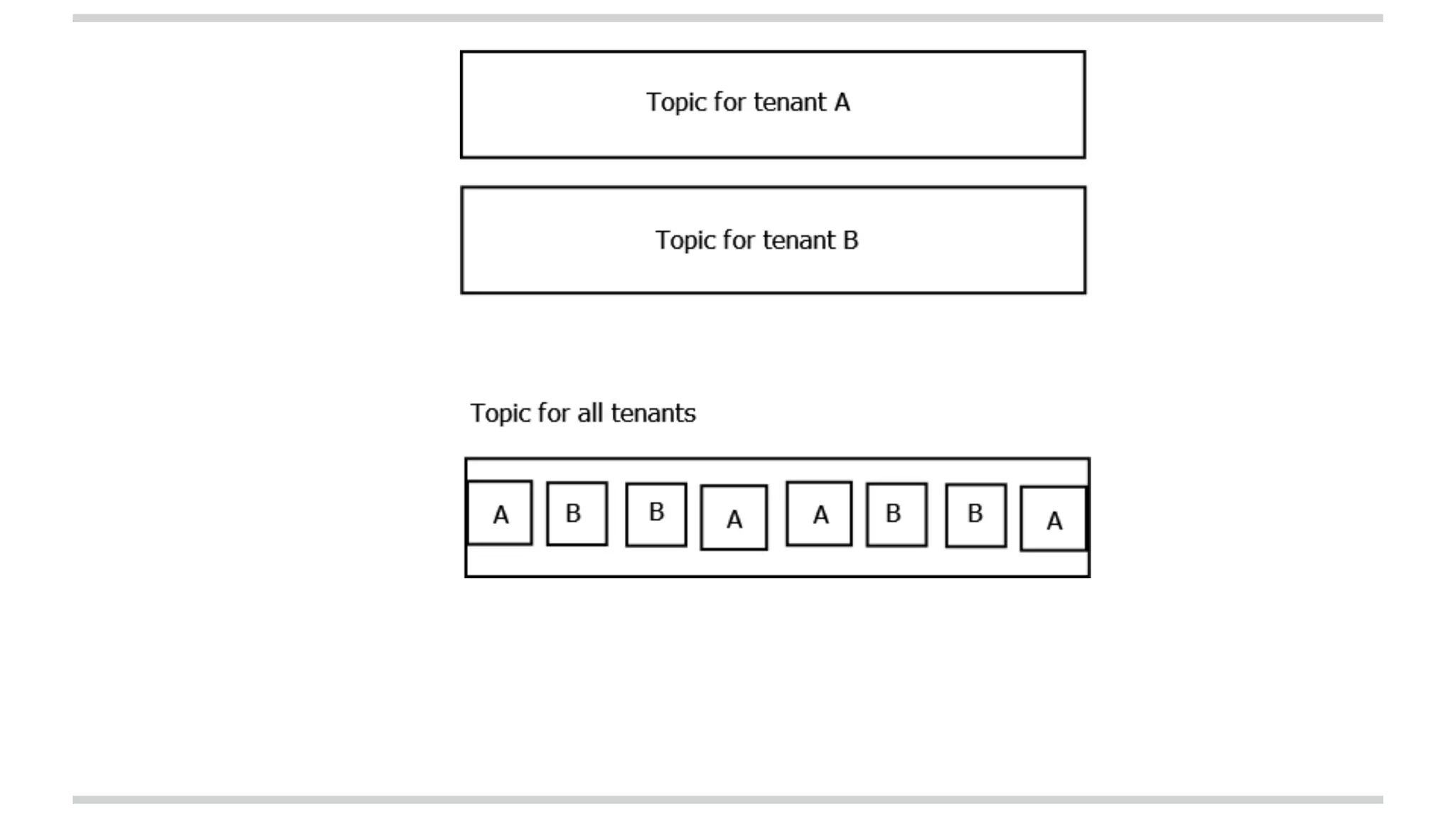







The document explains stateful stream processing using Apache Kafka, Apache Samza, and YARN, highlighting their roles, functionalities, and reasons for selecting this stack over alternatives like Spark Streaming and Storm. It discusses the architecture of Samza in relation to Kafka for managing state, fault tolerance, multi-tenancy, and various strategies for reprocessing and handling performance issues. Additionally, it covers aspects like local state management, testing, and troubleshooting in a distributed streaming context.