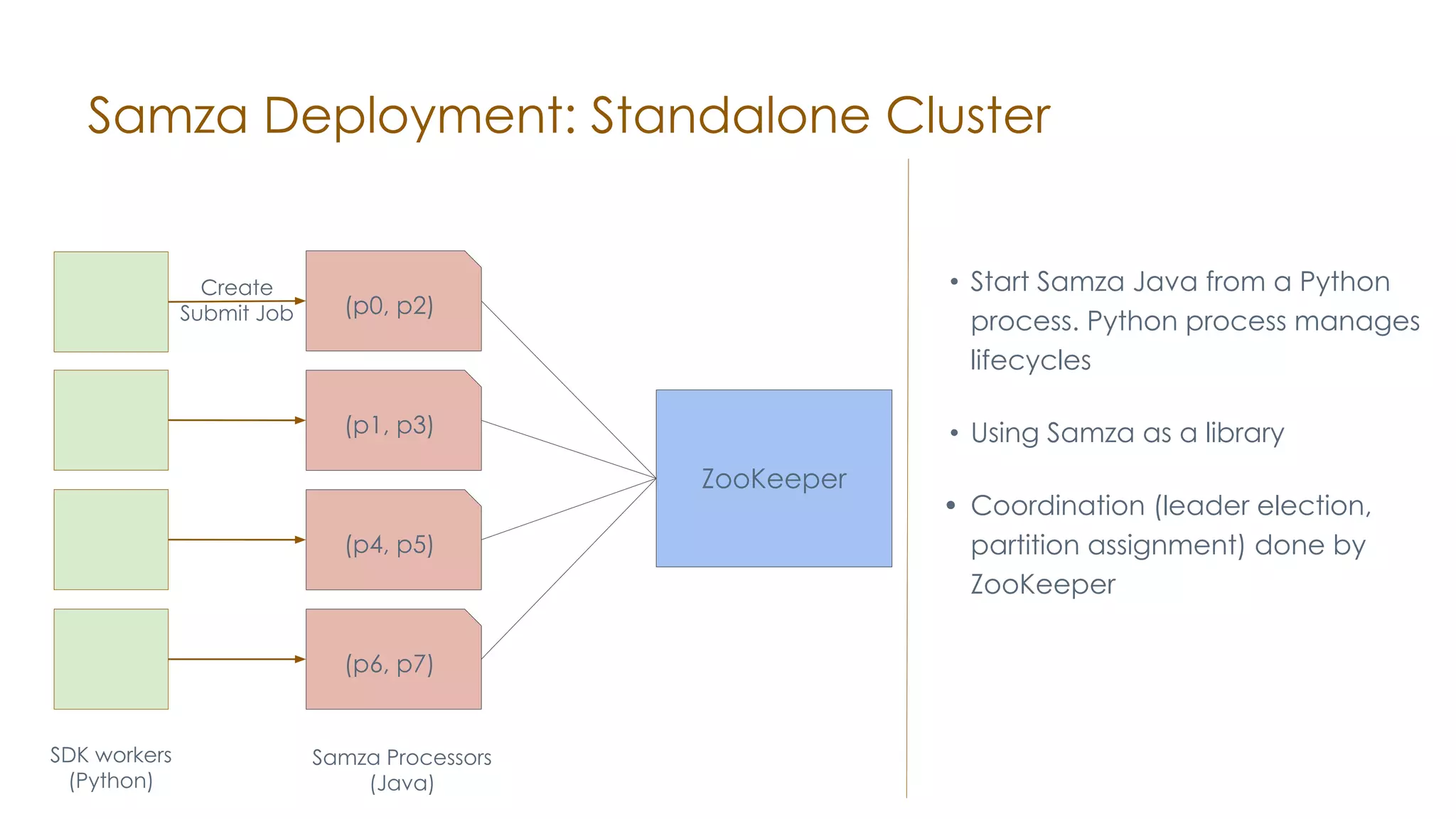
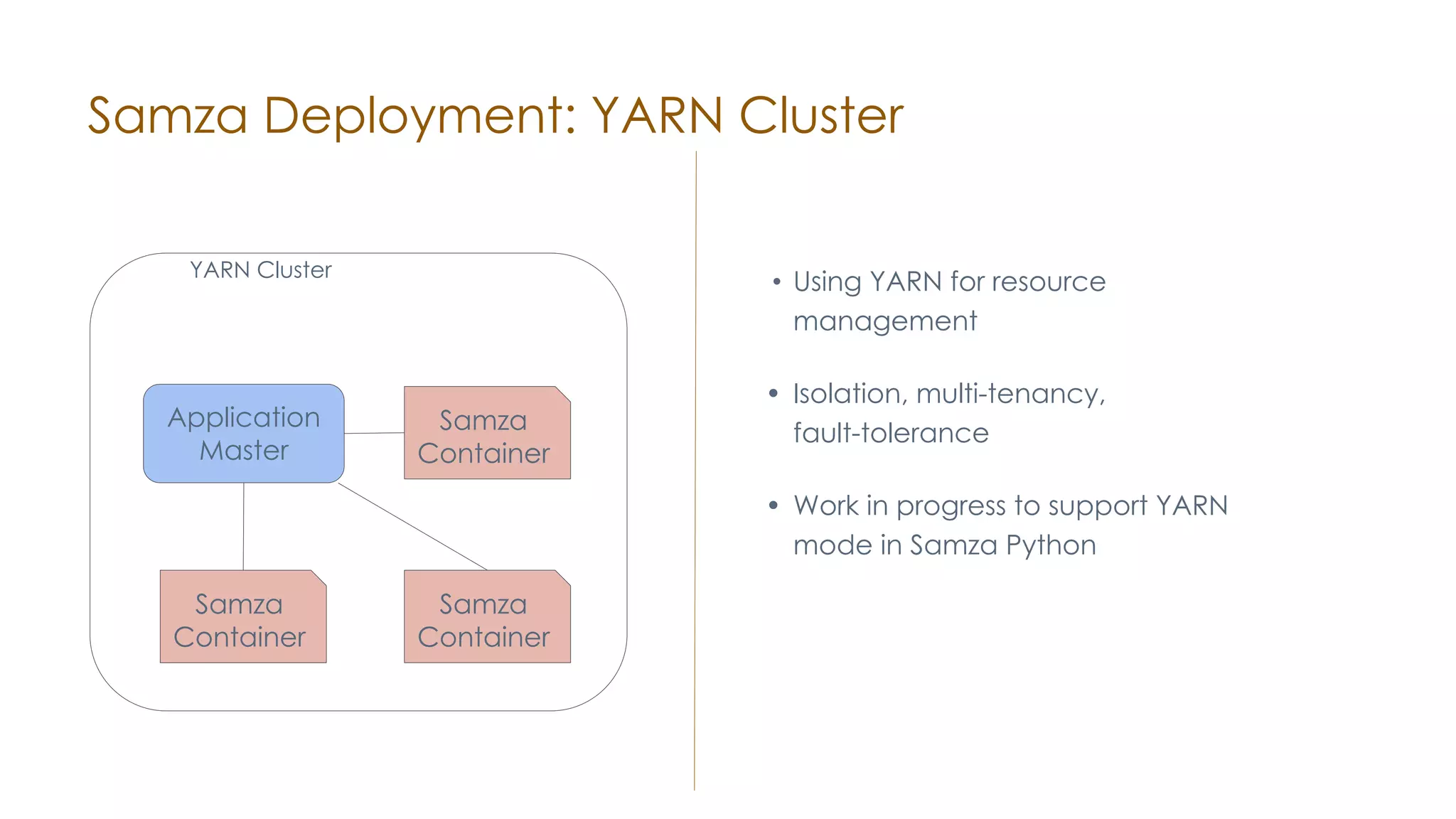
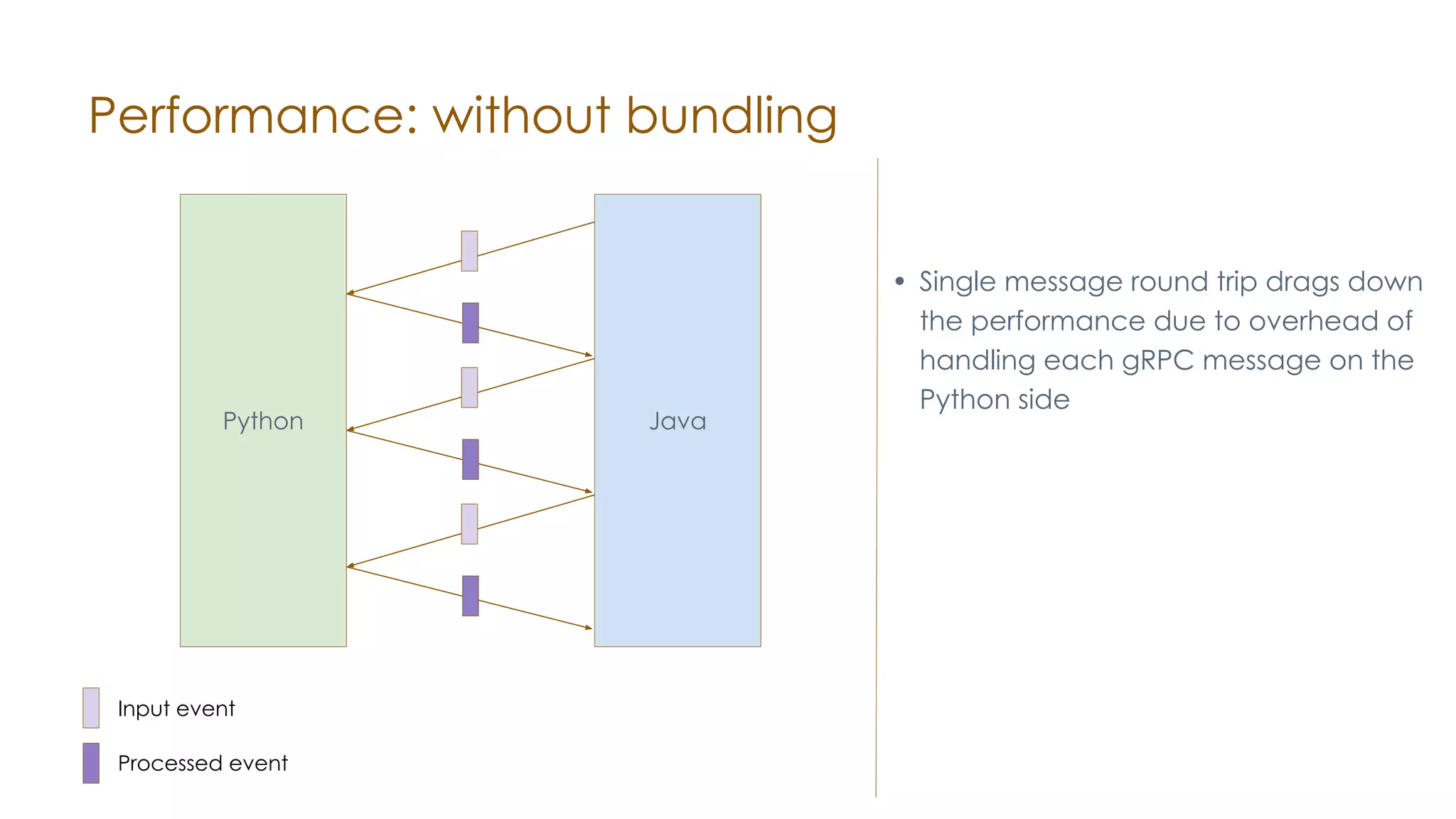
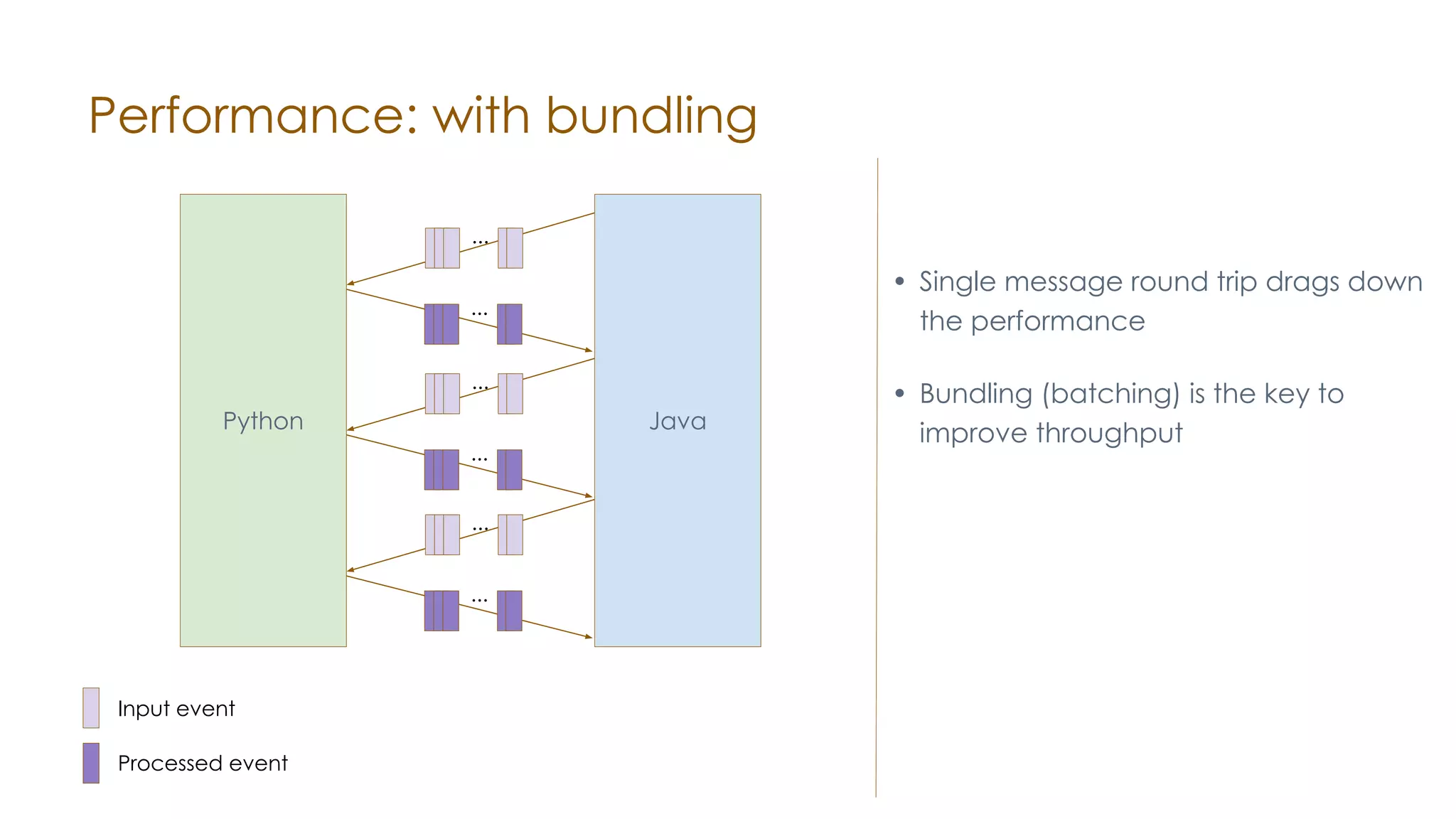
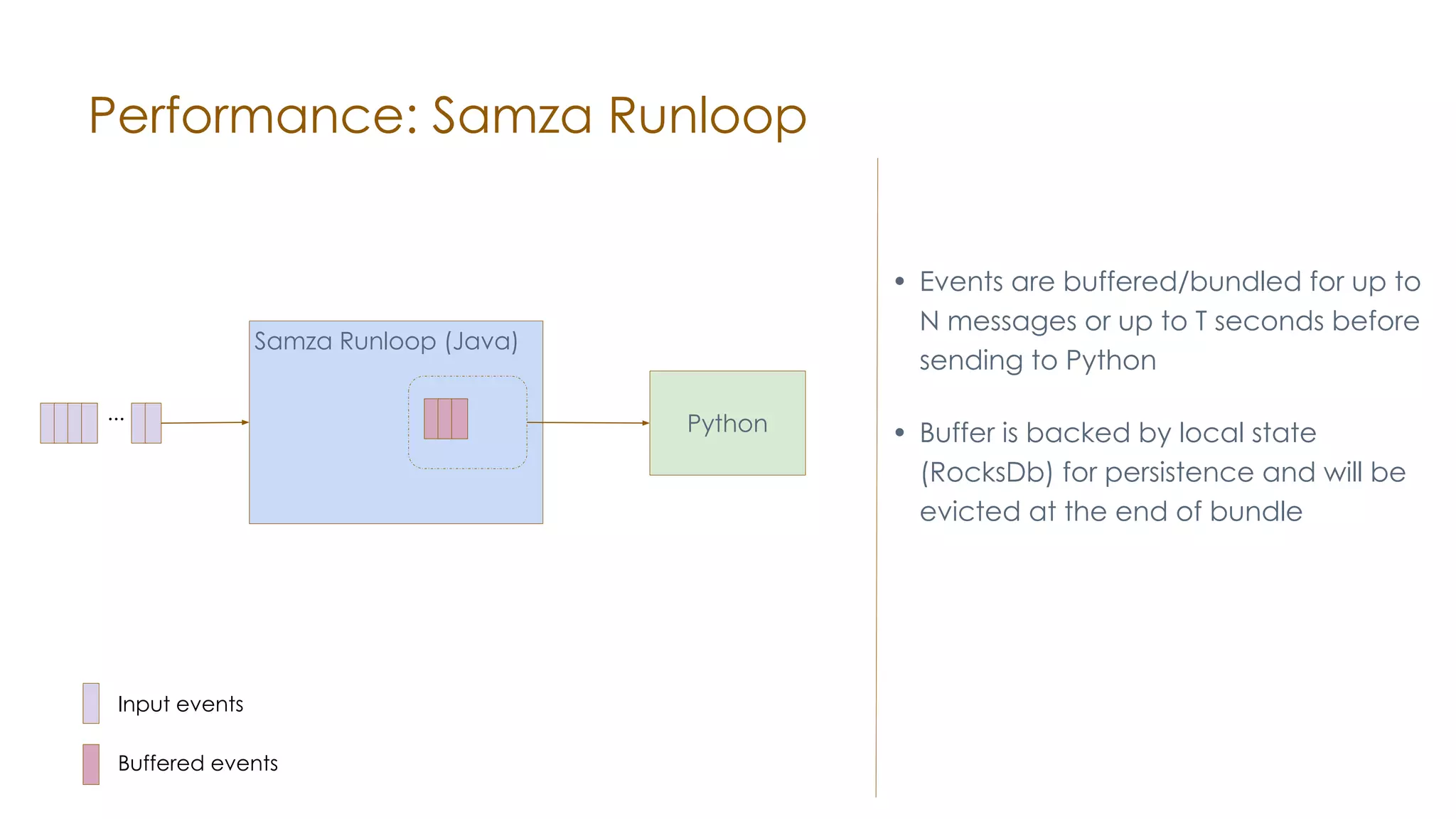
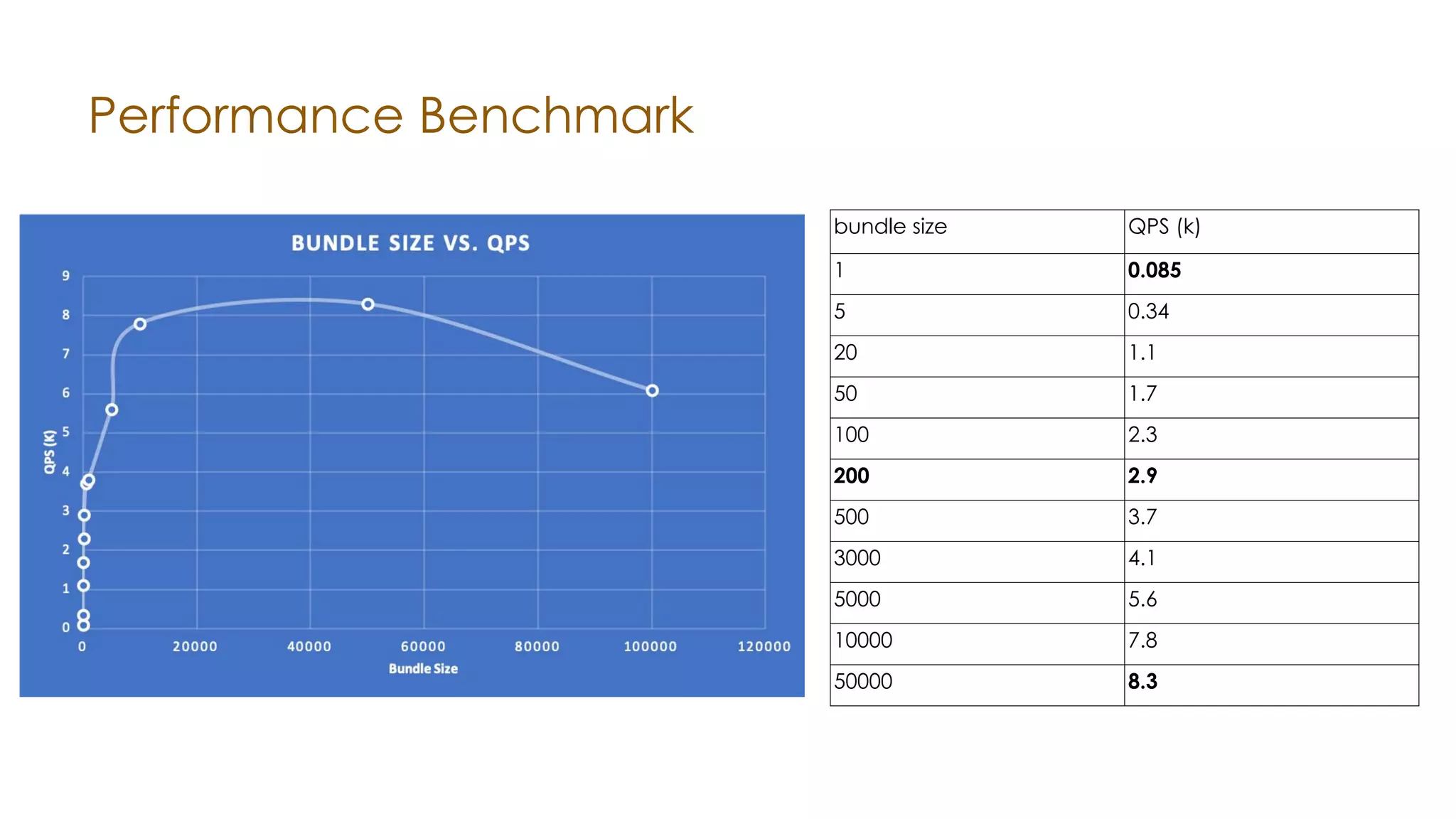
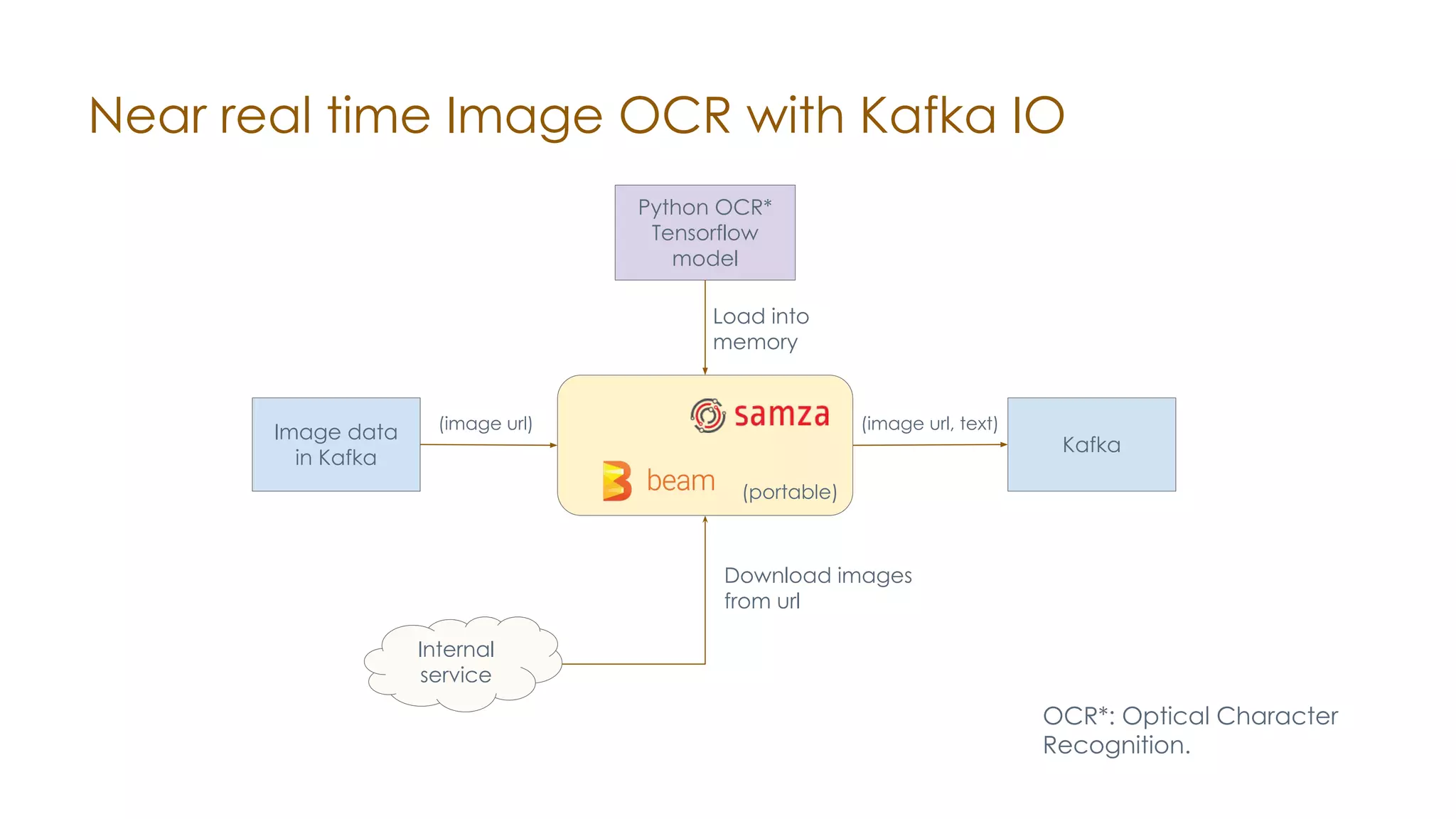
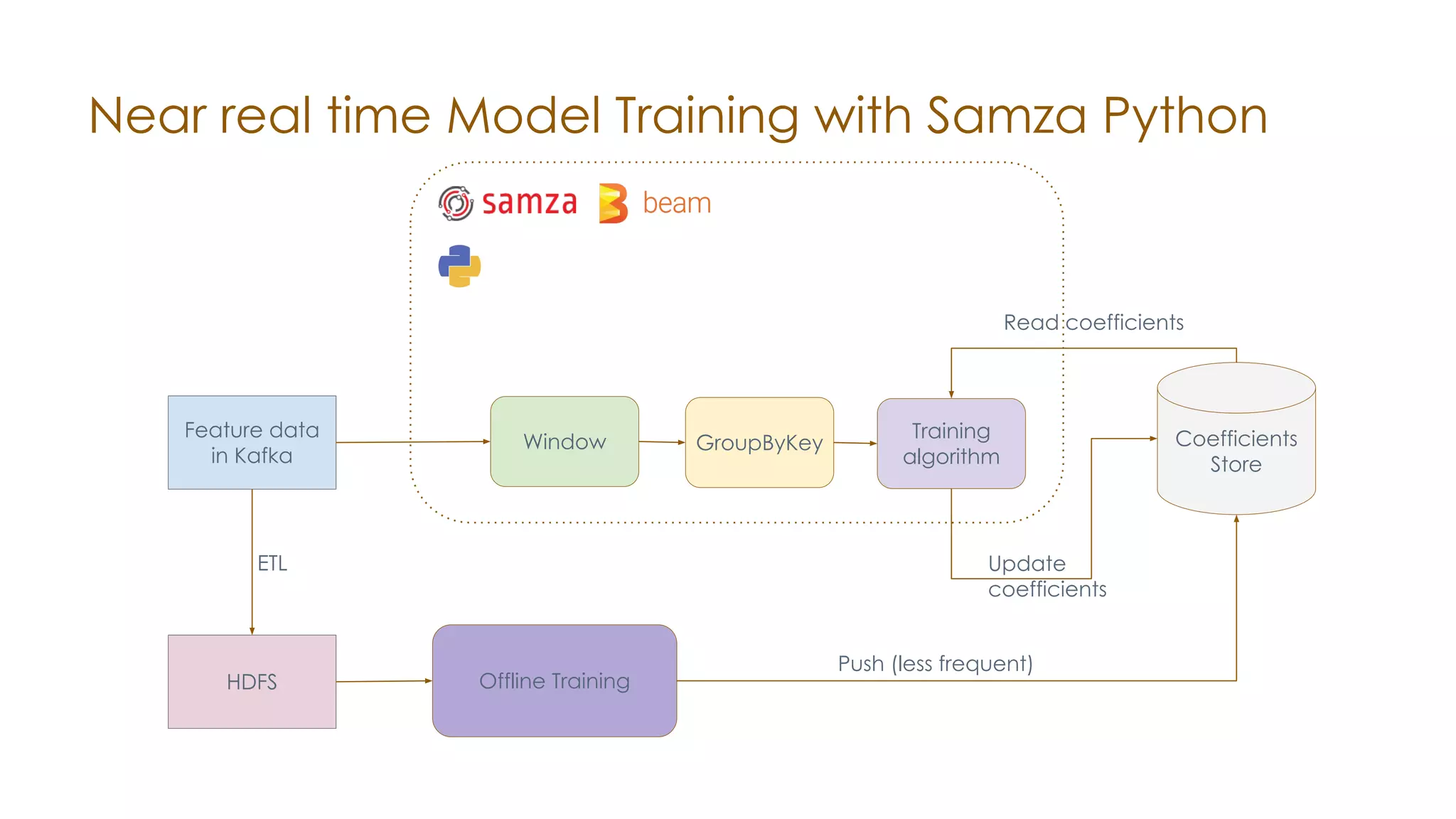
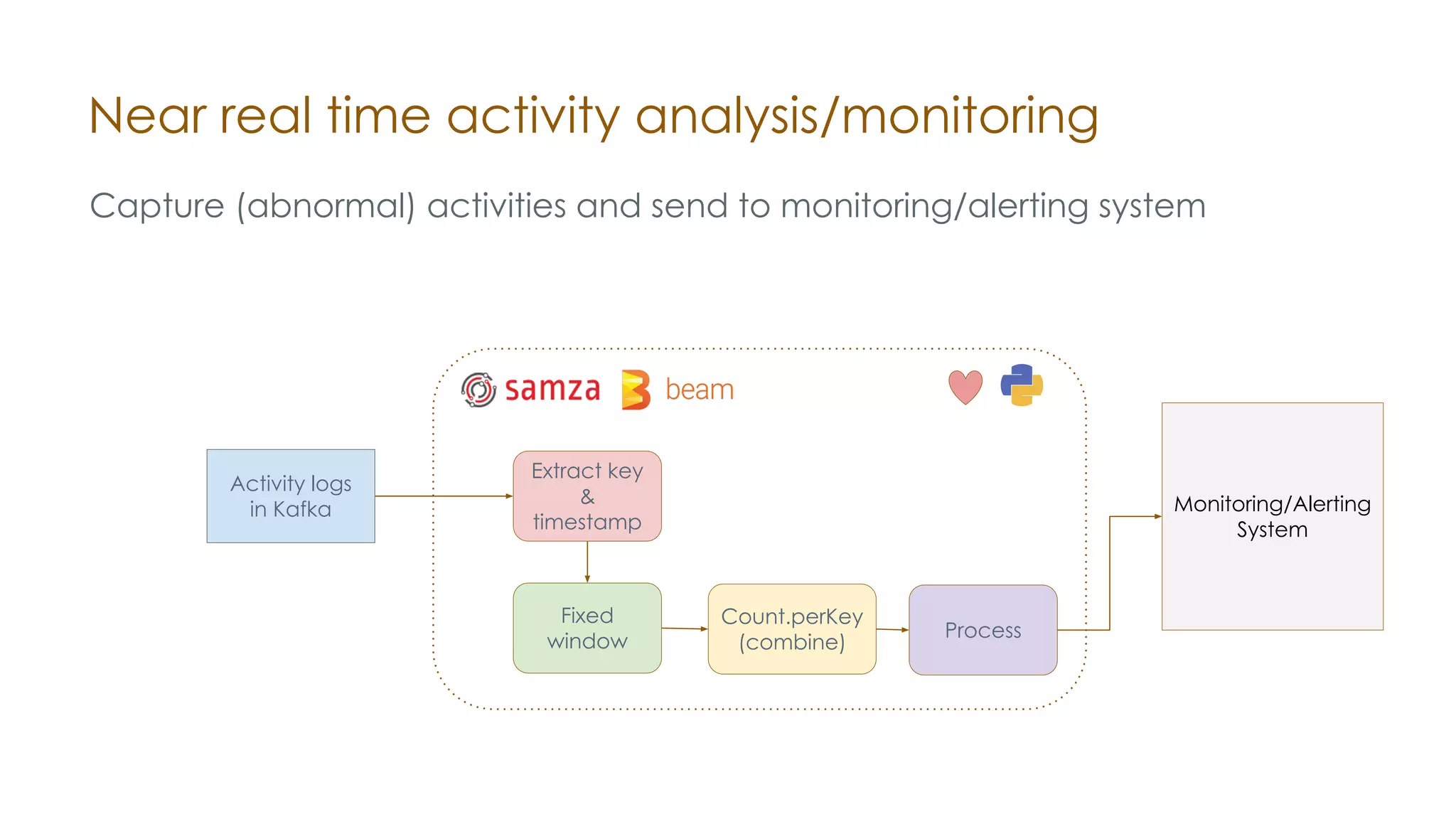
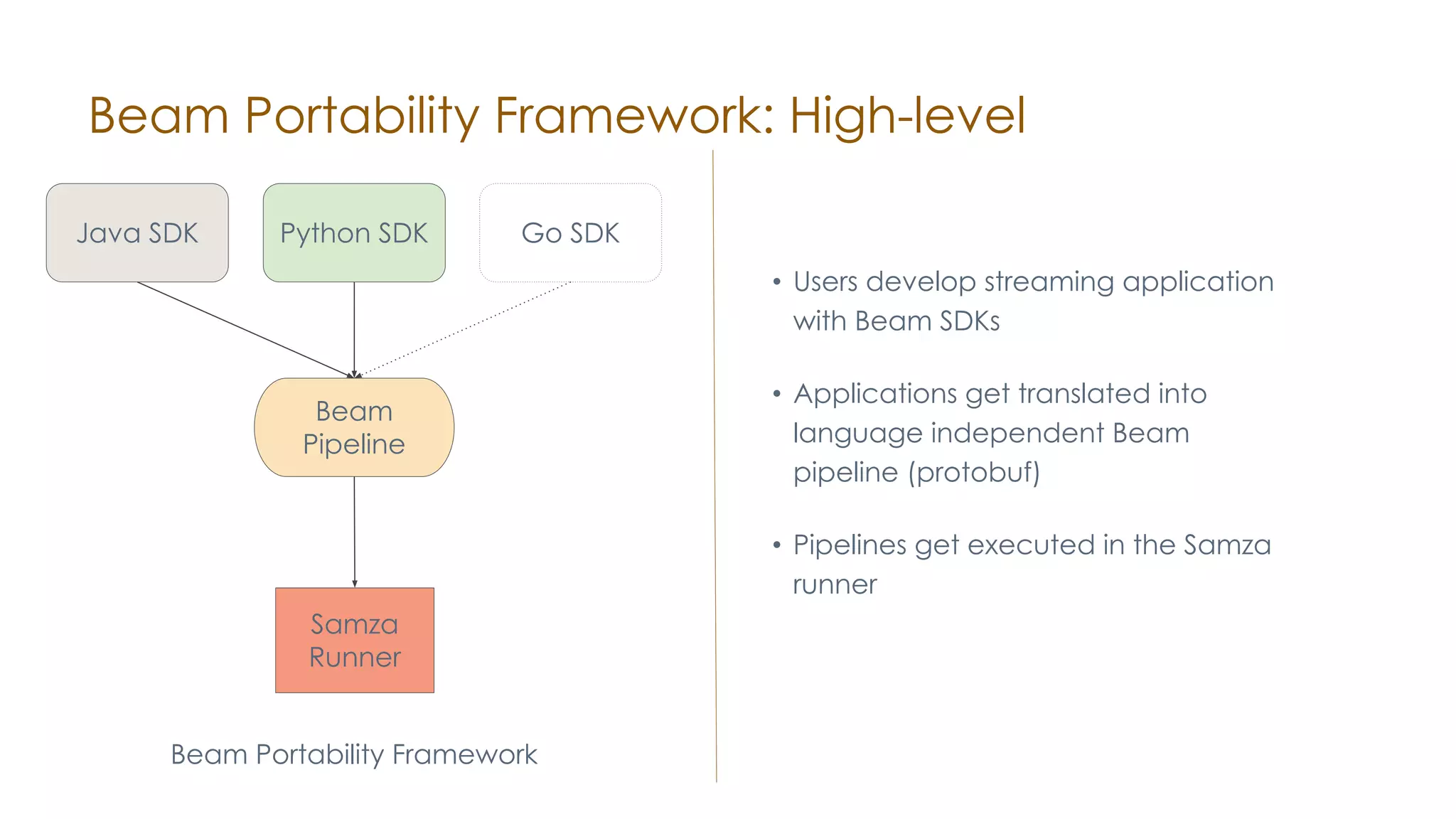
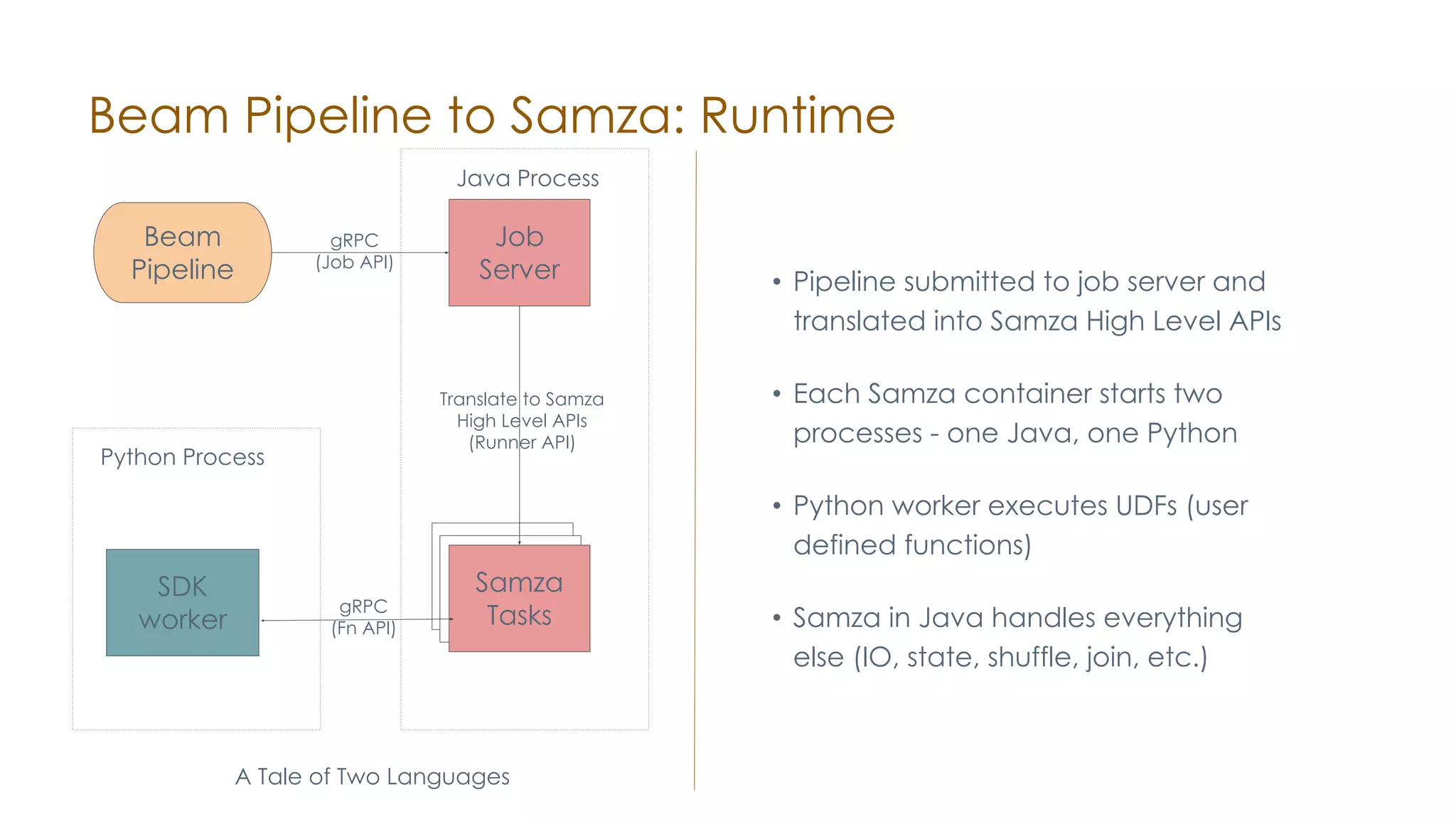
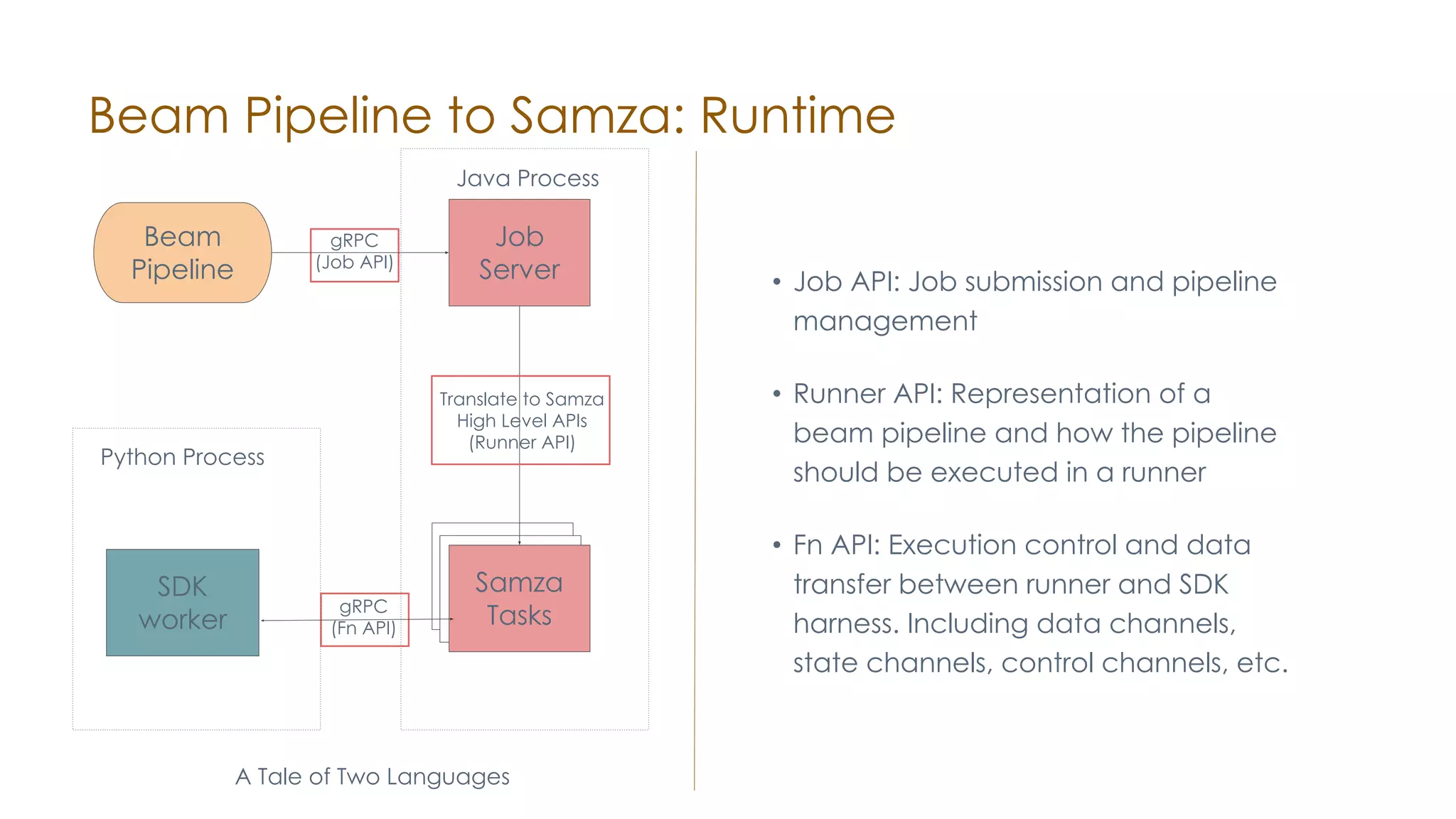
The document discusses the integration of Apache Samza and Apache Beam for stream processing in Python, highlighting the motivation of expanding stream processing capabilities beyond Java. It details the architecture of the system, including how Python applications are translated into a language-independent Beam pipeline executed by Samza, and outlines key features such as IO handling and state management. Future developments mentioned include enhancements for machine learning use cases and support for additional programming languages.










![Stream-Table Join in Samza Python (K1, V1) Kafka Input StreamTableJoinOp (K1, Entry 1) (K2, Entry 2) ... Remote/Local Table (K1, [V1, Entry1]) PTransform Output • Table read is provided as stream-table join. • Useful for enriching the events to be processed](https://image.slidesharecdn.com/streamprocessinginpythonwithapachesamzabeam-191004201919/75/Stream-processing-in-python-with-Apache-Samza-and-Beam-15-2048.jpg)