Download as PDF, PPTX





![The Buffer Interface • NumPy-inspired standard to access C data structures • Cython supports it • Fewer conversions between Python and C data types typedef struct bufferinfo { void *buf; // buffer memory pointer PyObject *obj; // owning object Py_ssize_t len; // memory buffer length Py_ssize_t itemsize; // byte size of one item int readonly; // read-only flag int ndim; // number of dimensions char *format; // item format description Py_ssize_t *shape; // array[ndim]: length of each dimension Py_ssize_t *strides; // array[ndim]: byte offset to next item in each d Py_ssize_t *suboffsets; // array[ndim]: further offset for indirect indexi void *internal; // reserved for owner } Py_buffer;](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-11-2048.jpg)


![With Multiprocessing def test_multi(a, b, pool): assert a.shape == b.shape v = a.shape[0] // 2 h = a.shape[1] // 2 quads = [(slice(None, v), slice(None, h)), (slice(None, v), slice(h, None)), (slice(v, None), slice(h, None)), (slice(v, None), slice(None, h))] results = [pool.apply_async(test_numpy, [a[quad], b[quad]]) for quad in quads] output = numpy.empty_like(a) for quad, res in zip(quads, results): output[quad] = res.get() return output • multiprocessing solution is 6 times slower than NumPy solution](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-14-2048.jpg)
![The Buffer Interface From Cython import numpy import cython @cython.boundscheck(False) @cython.wraparound(False) def func(object[double, ndim=2] buf1 not None, object[double, ndim=2] buf2 not None, object[double, ndim=2] output=None,): cdef unsigned int x, y, inner, outer if buf1.shape != buf2.shape: raise TypeError('Arrays have different shapes: %s, %s' % (buf1.shape, buf2.shape)) if output is None: output = numpy.empty_like(buf1) outer = buf1.shape[0] inner = buf1.shape[1]](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-15-2048.jpg)
![The Buffer Interface From Cython II for x in xrange(outer): for y in xrange(inner): output[x, y] = ((buf1[x, y] + buf2[x, y]) * 2 + buf1[x, y] * buf2[x, y]) return output](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-16-2048.jpg)
![Memory Views -Quadrant import numpy import cython @cython.boundscheck(False) @cython.wraparound(False) cdef add_arrays_2d_views(double[:,:] buf1, double[:,:] buf2, double[:,:] output): cdef unsigned int x, y, inner, outer outer = buf1.shape[0] inner = buf1.shape[1] for x in xrange(outer): for y in xrange(inner): output[x, y] = ((buf1[x, y] + buf2[x, y]) * 2 + buf1[x, y] * buf2[x, y]) return output](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-17-2048.jpg)
![Memory Views - Whole I @cython.boundscheck(False) @cython.wraparound(False) def add_arrays_2d(object[double, ndim=2] buf1 not None, object[double, ndim=2] buf2 not None, object[double, ndim=2] output=None,): cdef unsigned int v, h if buf1.size != buf2.size: raise TypeError('Arrays have different sizes: %d, %d' % (buf1.size, buf2.size)) if buf1.shape != buf2.shape: raise TypeError('Arrays have different shapes: %s, %s' % (buf1.shape, buf2.shape)) if output is None: output = numpy.empty_like(buf1)](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-18-2048.jpg)
![Memory Views - Whole II v = buf1.shape[0] // 2 h = buf1.shape[1] // 2 quad1 = slice(None, v), slice(None, h) quad2 = slice(None, v), slice(h, None) quad3 = slice(v, None), slice(h, None) quad4 = slice(v, None), slice(None, h) add_arrays_2d_views(buf1[quad1], buf2[quad1], output[quad1]) add_arrays_2d_views(buf1[quad2], buf2[quad2], output[quad2]) add_arrays_2d_views(buf1[quad3], buf2[quad3], output[quad3]) add_arrays_2d_views(buf1[quad4], buf2[quad4], output[quad4]) return output](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-19-2048.jpg)

![OpenMP with Cython - Threads II @cython.boundscheck(False) @cython.wraparound(False) cdef int add_arrays_2d_views(double[:,:] buf1, double[:,:] buf2, double[:,:] output) nogil: cdef unsigned int x, y, inner, outer outer = buf1.shape[0] inner = buf1.shape[1] for x in xrange(outer): for y in xrange(inner): output[x, y] = ((buf1[x, y] + buf2[x, y]) * 2 + buf1[x, y] * buf2[x, y]) return 0](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-22-2048.jpg)
![OpenMP with Cython - Threads III @cython.boundscheck(False) @cython.wraparound(False) def add_arrays_2d(double[:,:] buf1 not None, double[:,:] buf2 not None, double[:,:] output=None,): cdef unsigned int v, h, thread_id if buf1.shape[0] != buf2.shape[0] or buf1.shape[1] != buf2.shape[1]: raise TypeError('Arrays have different shapes: (%d, %d) (%d, %d)' % ( buf1.shape[0], buf1.shape[1], buf2.shape[0], buf1.shape[1],)) if output is None: output = numpy.zeros_like(buf1)](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-23-2048.jpg)
![OpenMP with Cython - Threads IV v = buf1.shape[0] // 2 h = buf1.shape[1] // 2 ids = [] with nogil, parallel.parallel(num_threads=4): thread_id = parallel.threadid() with gil: ids.append(thread_id) if thread_id == 0: add_arrays_2d_views(buf1[:v,:h], buf2[:v,:h], output[:v,:h]) elif thread_id == 1: add_arrays_2d_views(buf1[:v,h:], buf2[:v,h:], output[:v,h:]) elif thread_id == 2: add_arrays_2d_views(buf1[v:,h:], buf2[v:,h:], output[v:,h:]) elif thread_id == 3: add_arrays_2d_views(buf1[v:,:h], buf2[v:,:h], output[v:,:h]) print ids return output](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-24-2048.jpg)
![OpenMP with Cython - Parallel Range II @cython.boundscheck(False) @cython.wraparound(False) def func(object[double, ndim=2] buf1 not None, object[double, ndim=2] buf2 not None, object[double, ndim=2] output=None, int num_threads=2): cdef unsigned int x, y, inner, outer if buf1.shape != buf2.shape: raise TypeError('Arrays have different shapes: %s, %s' % (buf1.shape, buf2.shape)) if output is None: output = numpy.empty_like(buf1) outer = buf1.shape[0] inner = buf1.shape[1]](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-26-2048.jpg)
![OpenMP with Cython - Parallel Range III inner = buf1.shape[1] with nogil, cython.boundscheck(False), cython.wraparound(False): for x in parallel.prange(outer, schedule='static', num_threads=num_threads): for y in xrange(inner): output[x, y] = ((buf1[x, y] + buf2[x, y]) * 2 + buf1[x, y] * buf2[x, y]) return output](https://image.slidesharecdn.com/sharedmemoryparallelismwithpythonbymikemuller-140421111934-phpapp02/75/Shared-Memory-Parallelism-with-Python-by-Dr-Ing-Mike-Muller-27-2048.jpg)
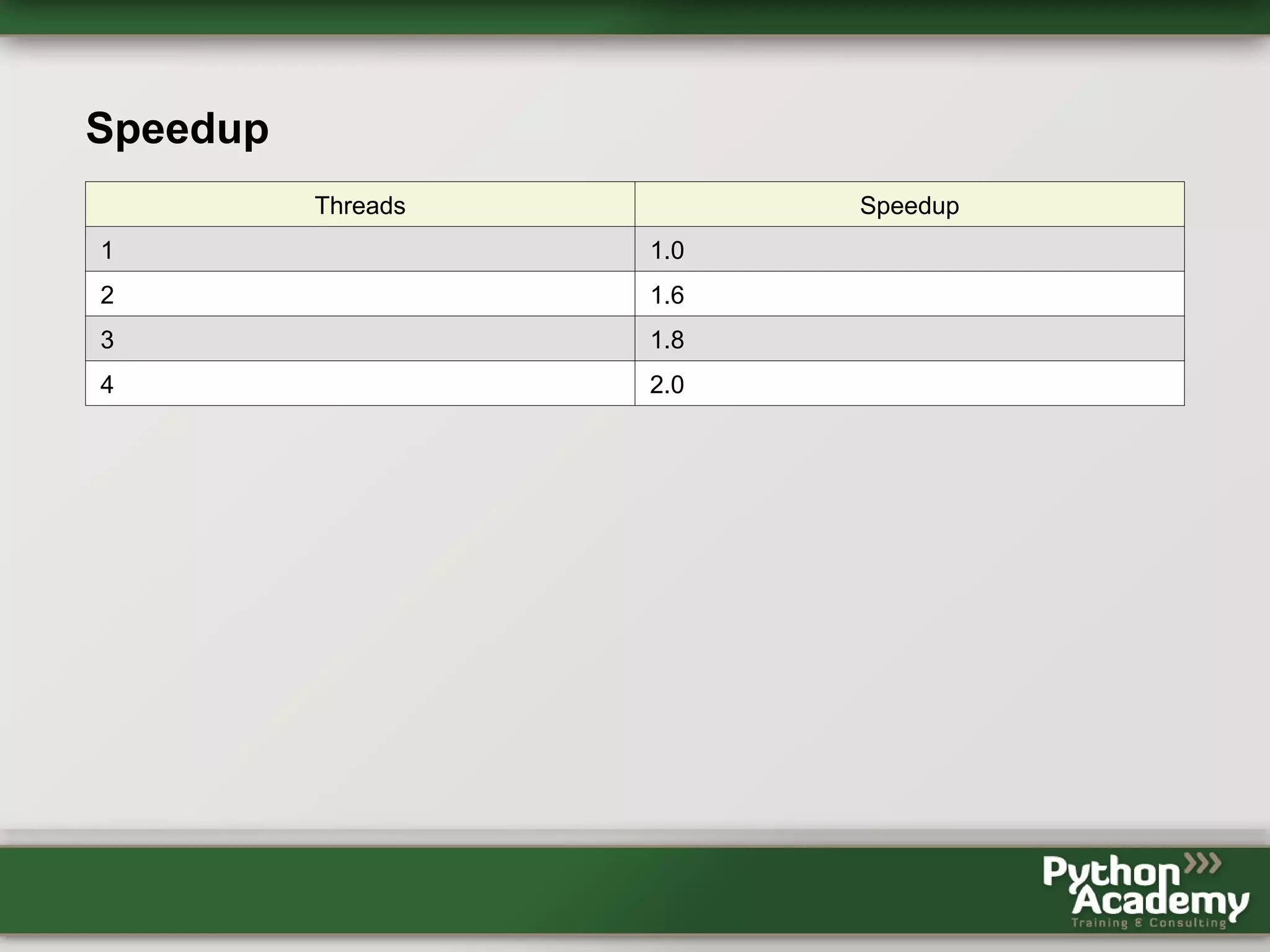


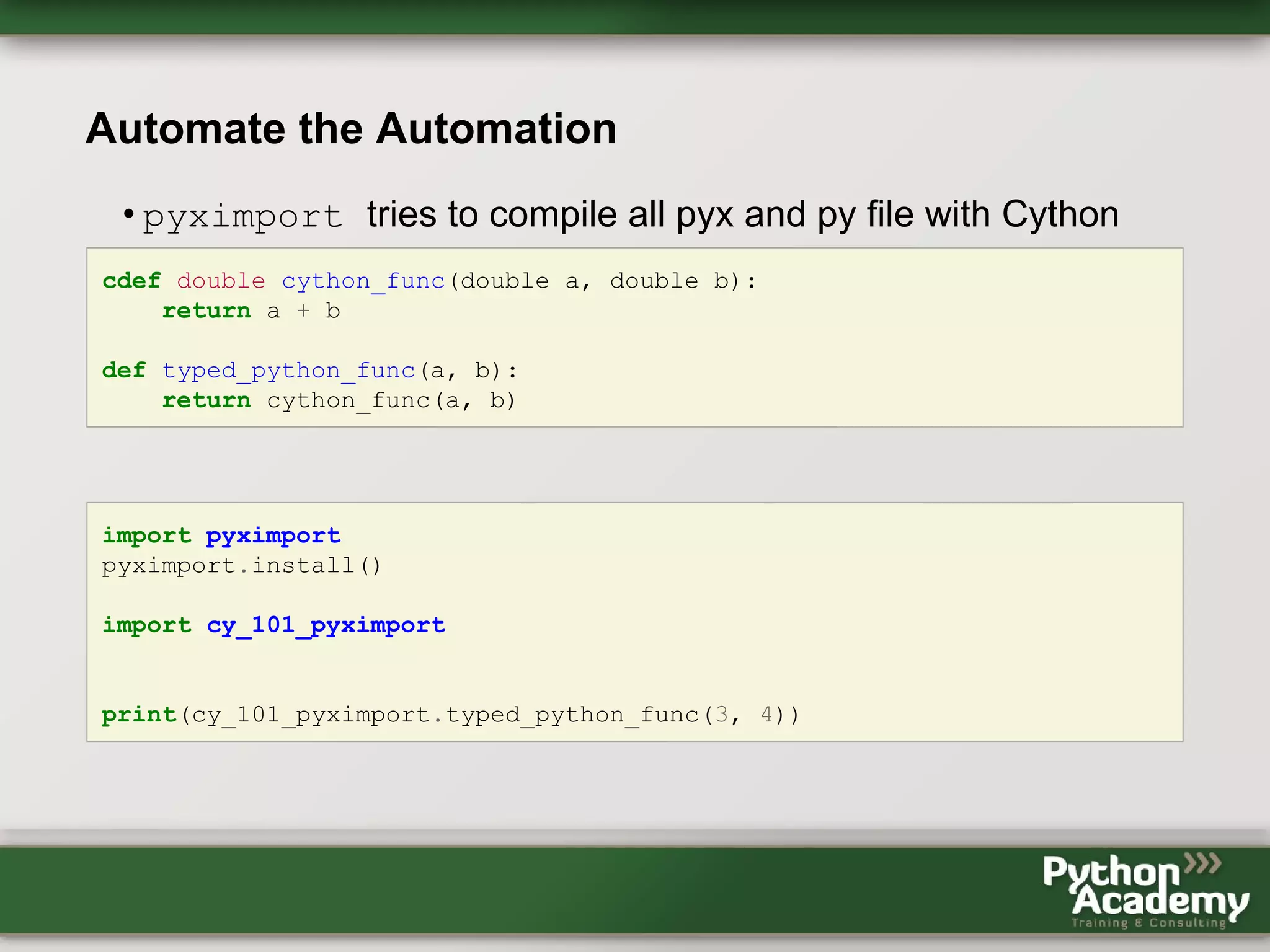
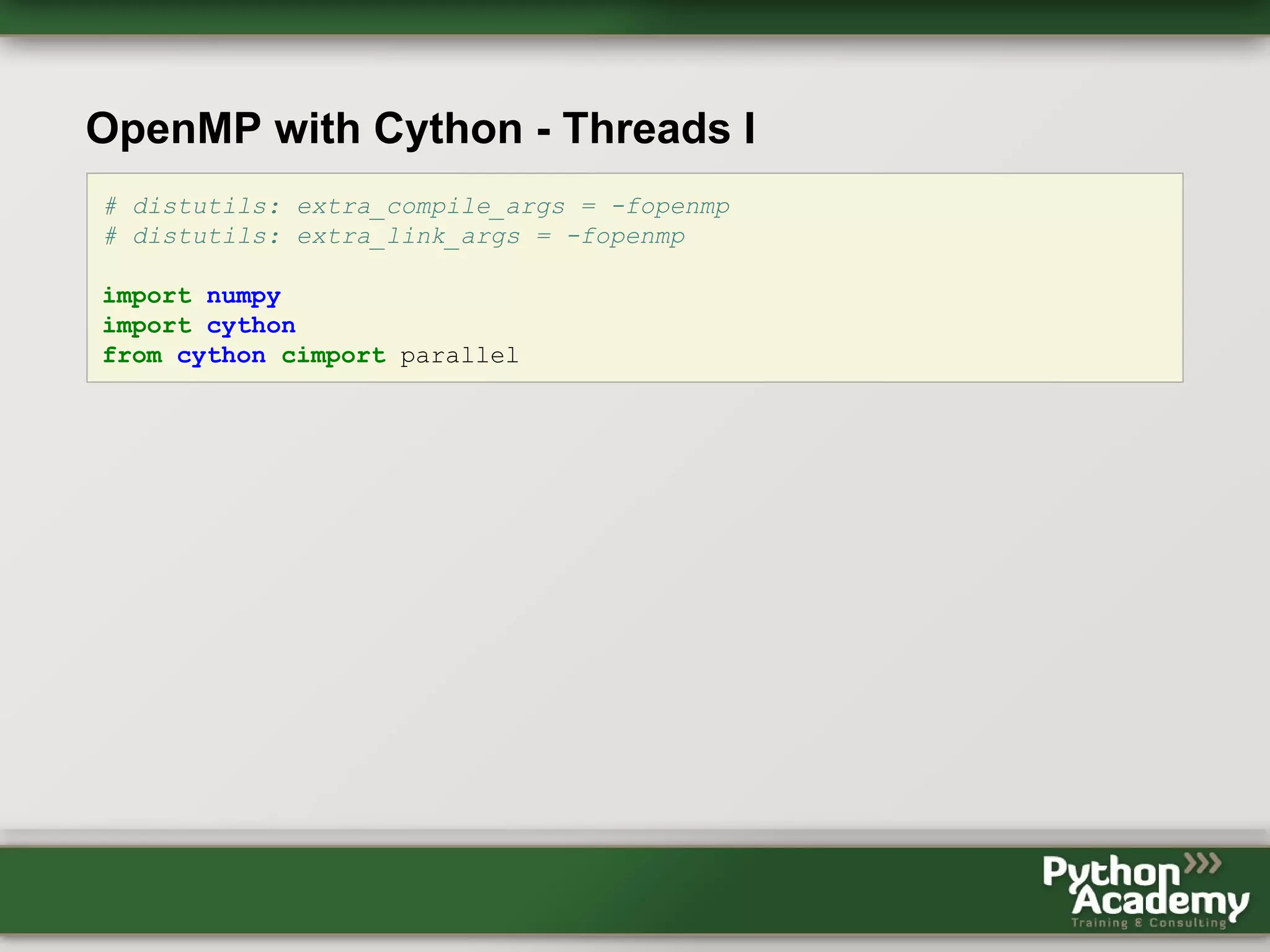
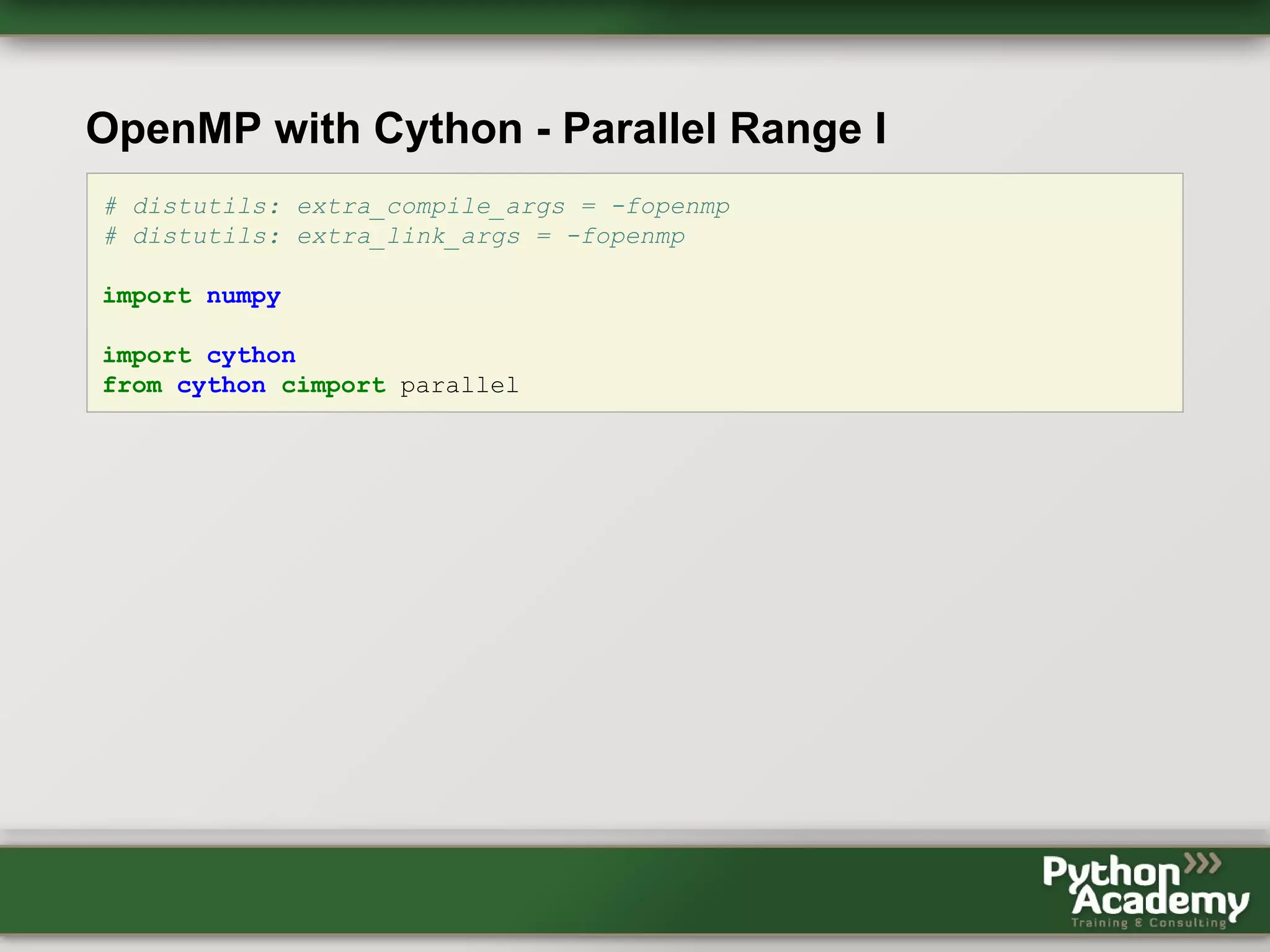
Cython can be used to write Python extensions and interface with C/C++ code. It allows gradually adding C-like features to Python code. Cython code can be compiled to Python extensions and provide performance improvements over pure Python. OpenMP support in Cython allows releasing the GIL and performing parallel operations across threads to further improve performance of CPU-bound tasks. Benchmark results showed near-linear speedups from using 2-4 threads. However, using Cython and OpenMP requires more code and loses some Python safety, and requires knowledge of C in addition to Python.