Downloaded 62 times



![Optimization process Recode CRAN R to Rx R Before trainit <- glm(as.formula(specs[[i]]), data = training.data, family='binomial', maxit=iters) fits <- predict(trainit, newdata=test.data, type='response') After trainit <- rxGlm(as.formula(specs[[i]]), data = training.data, family='binomial', maxIterations=iters) fits <- rxPredict(trainit, newdata=test.data, type='response') Copyright © 2014 Accenture. All rights reserved. 7](https://image.slidesharecdn.com/accentureandrevolutionanalyticsonteradatav31-140917130022-phpapp02/75/Quick-and-Dirty-Scaling-Out-Predictive-Models-Using-Revolution-Analytics-on-Teradata-7-2048.jpg)




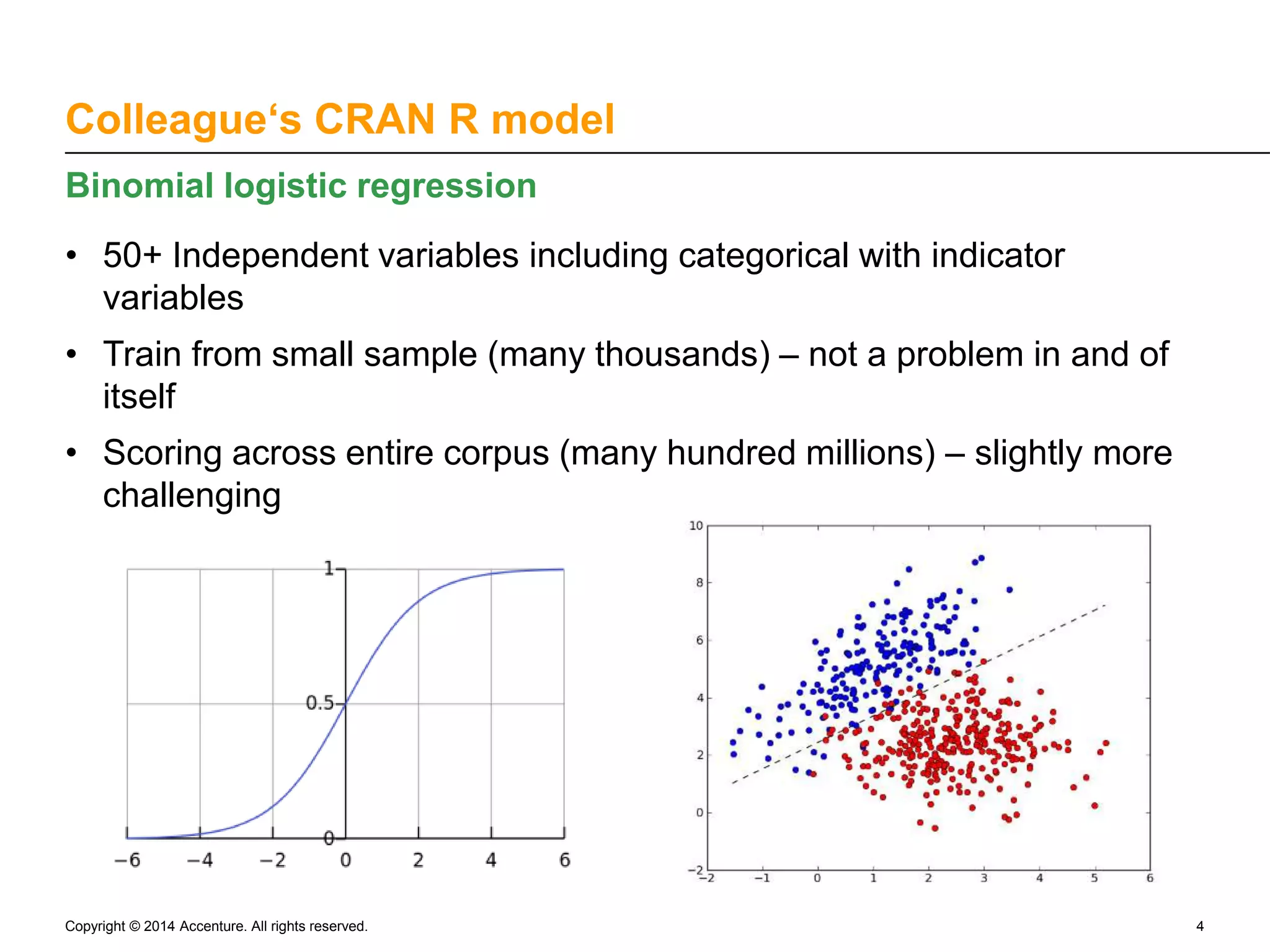
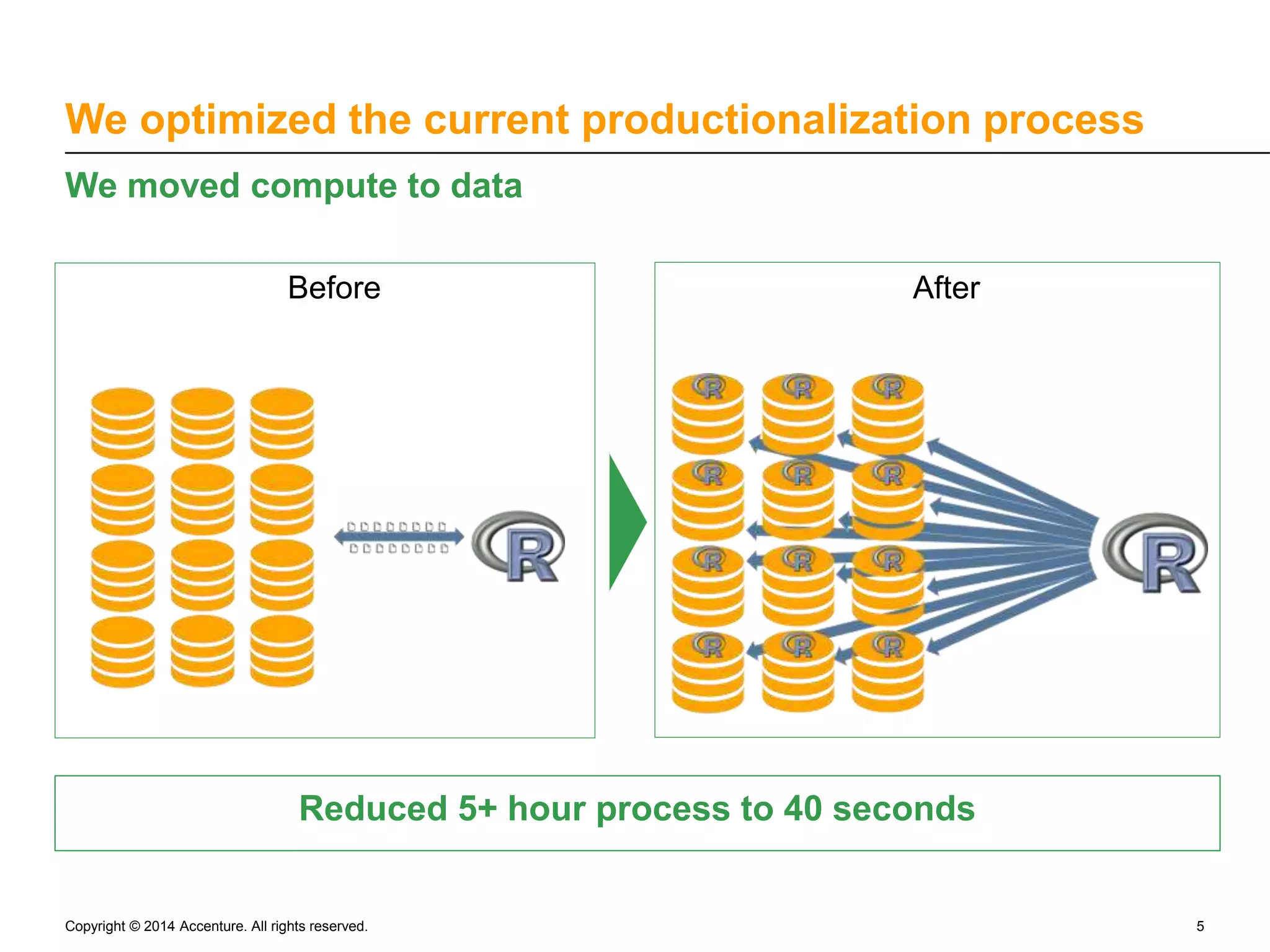
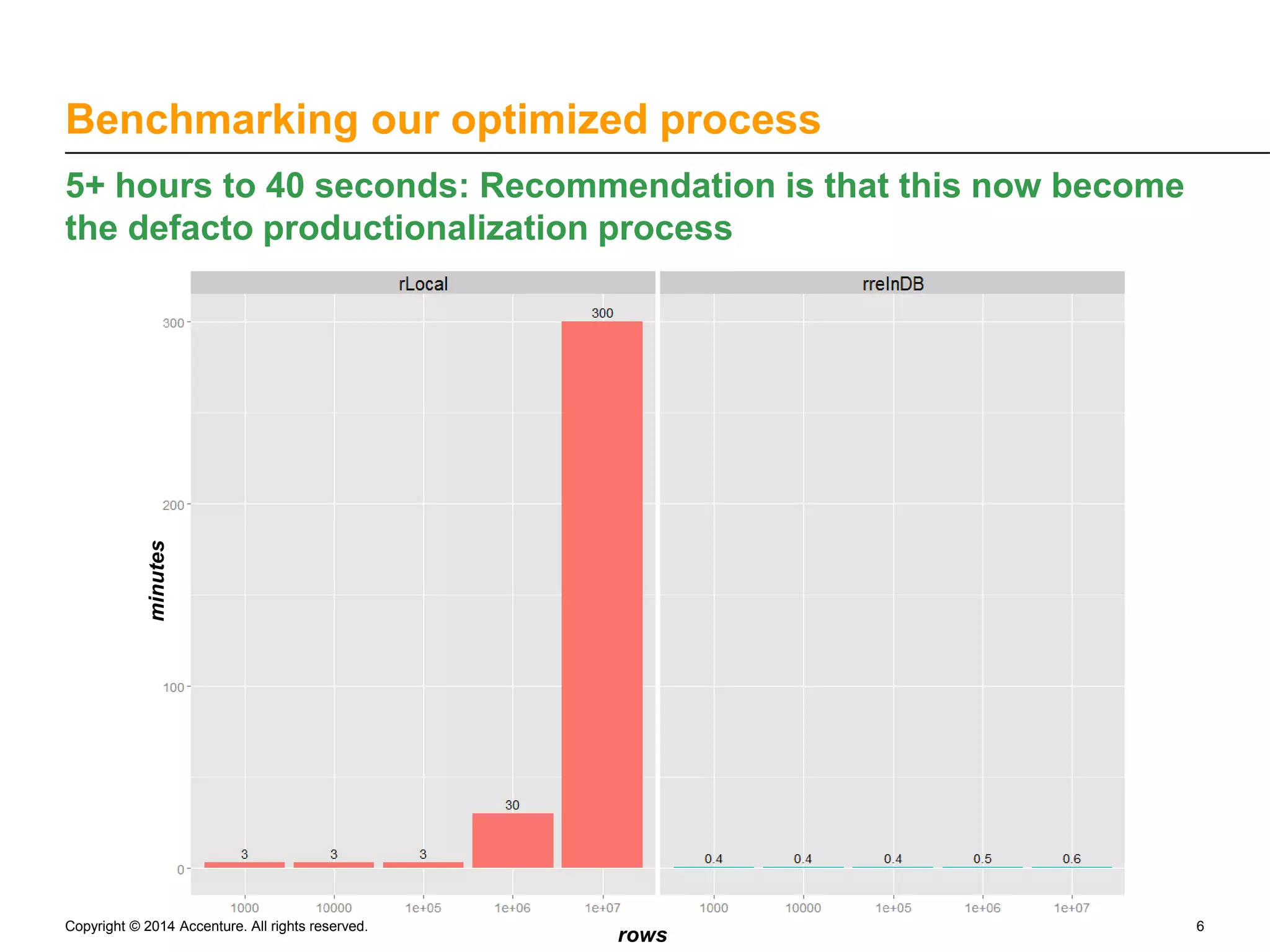
The document discusses the rapid productionalization of predictive models using in-database modeling with Revolution Analytics on Teradata, led by Skylar Lyon from Accenture Analytics. Key achievements include optimizing a predictive modeling process from over 5 hours to just 40 seconds by moving computation closer to the data. The new method allows for larger training datasets and supports Hadoop, enhancing the capabilities of the data science team.