Download as PDF, PPTX





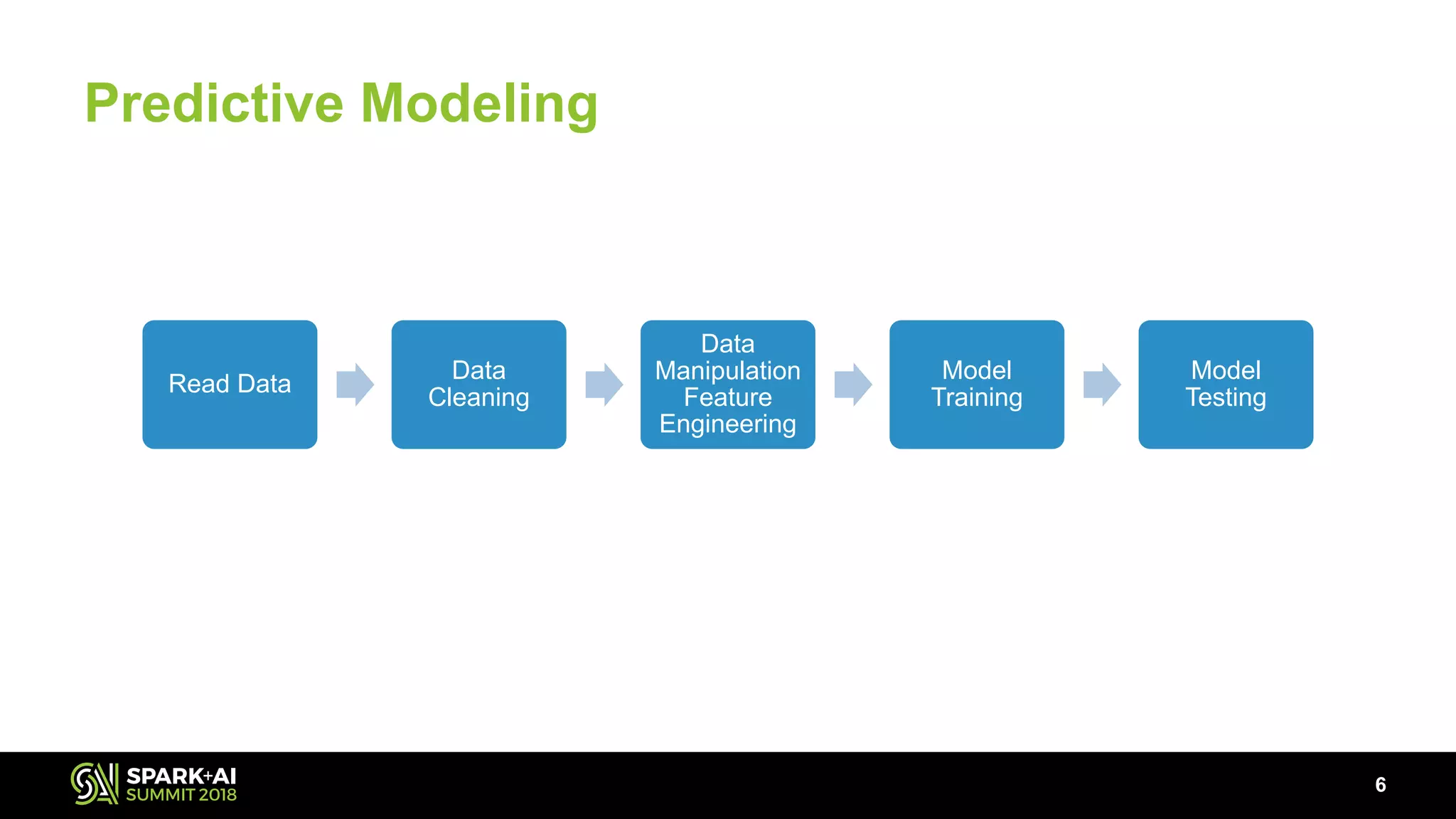
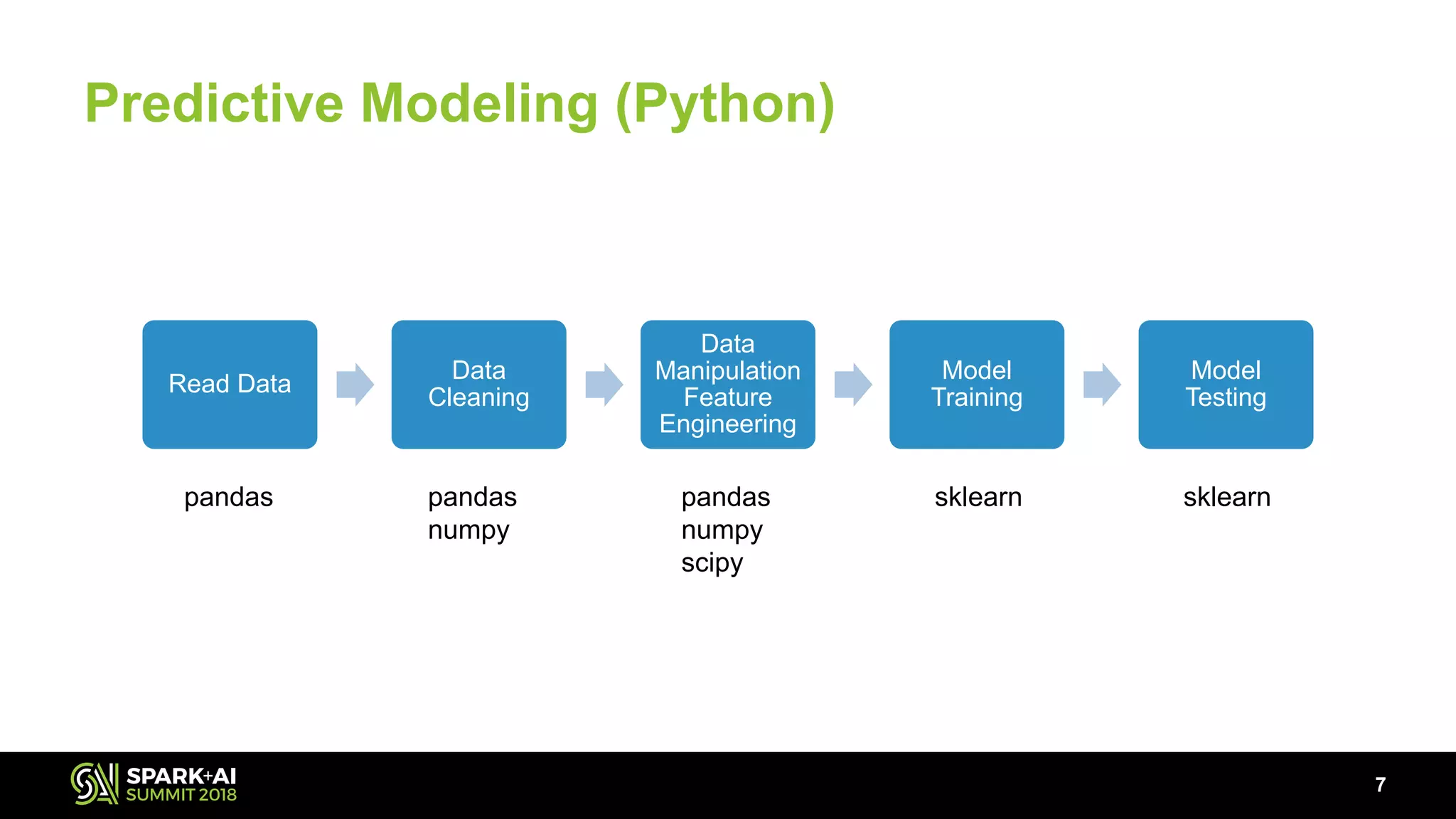
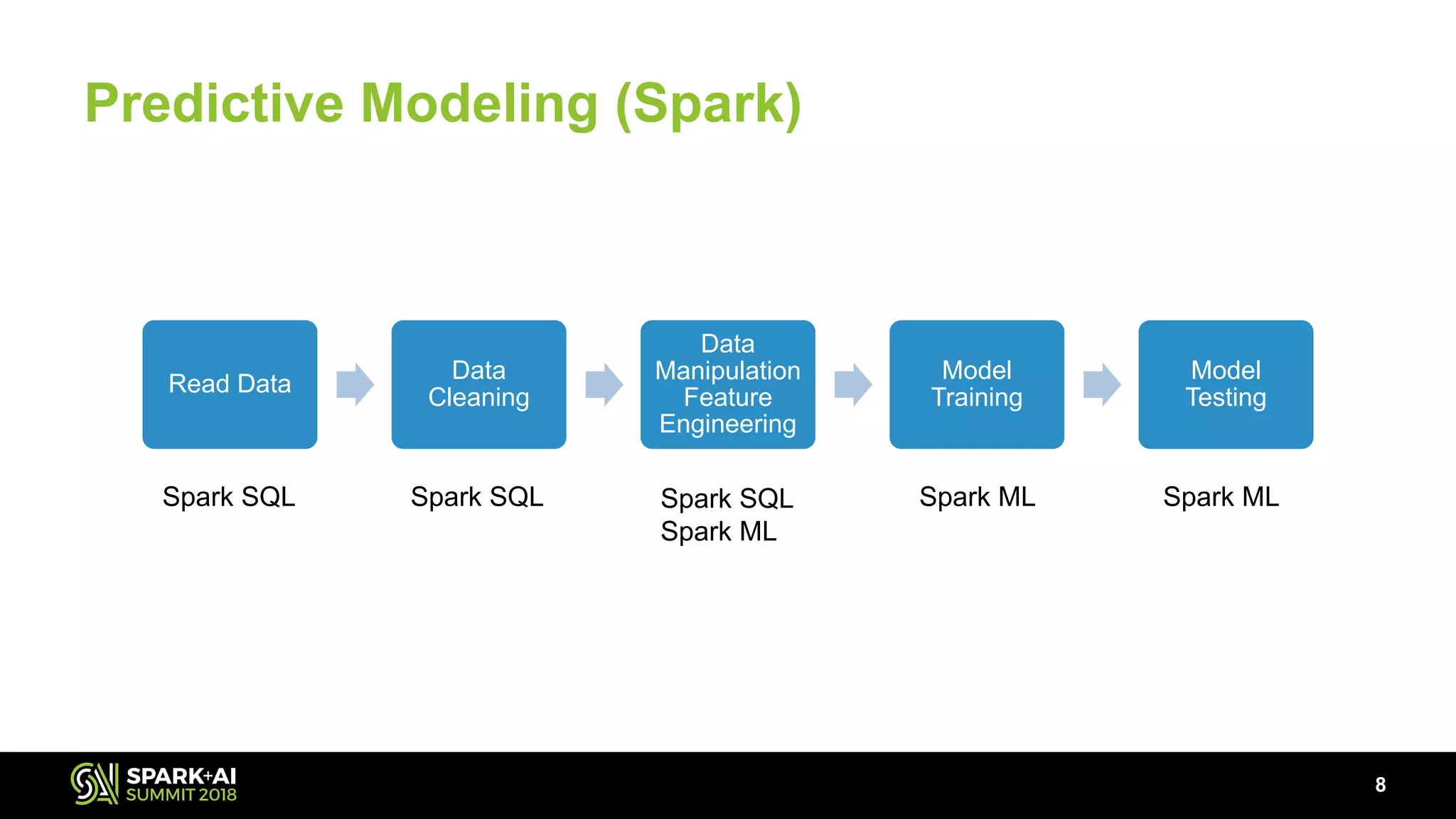

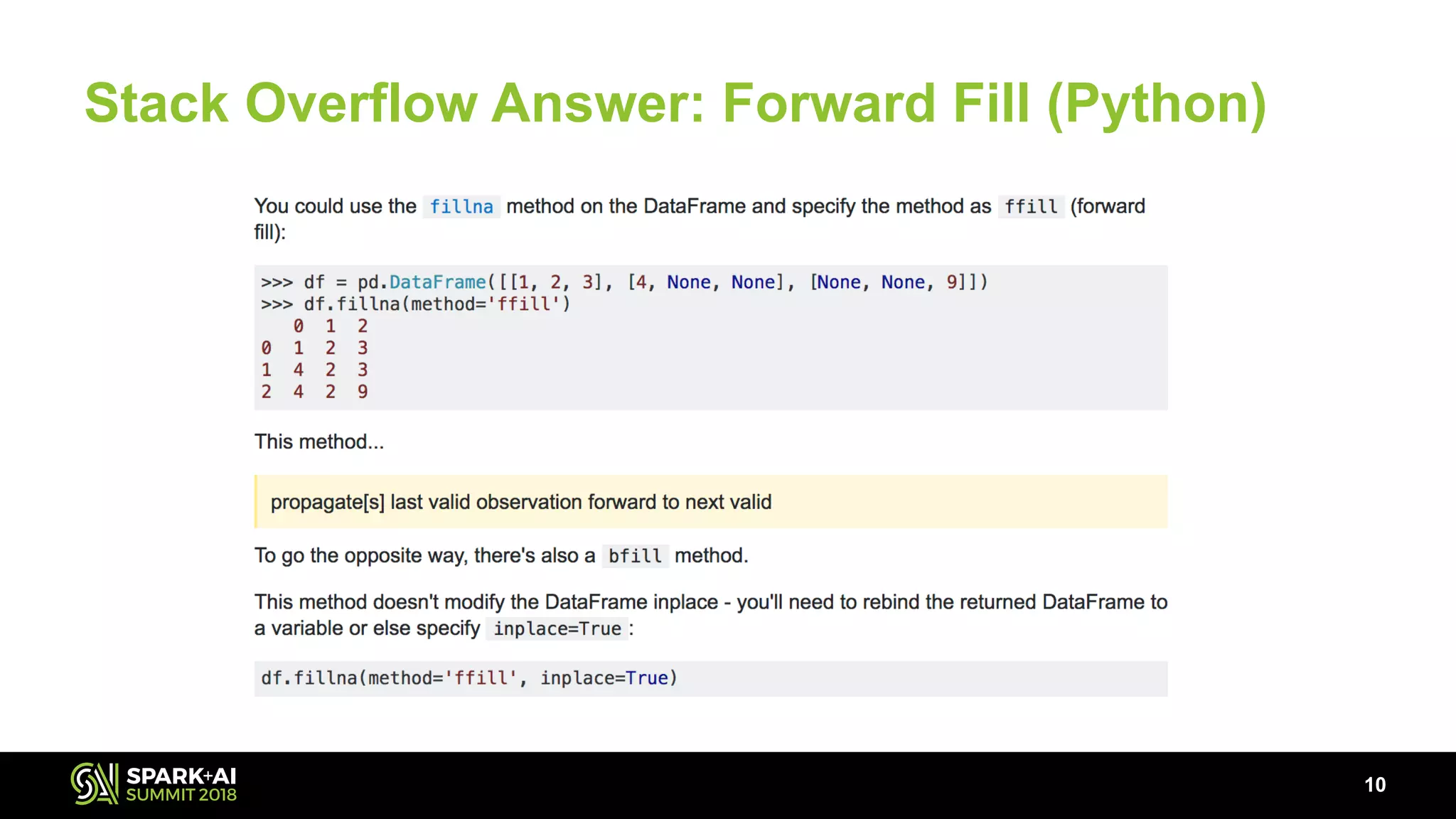
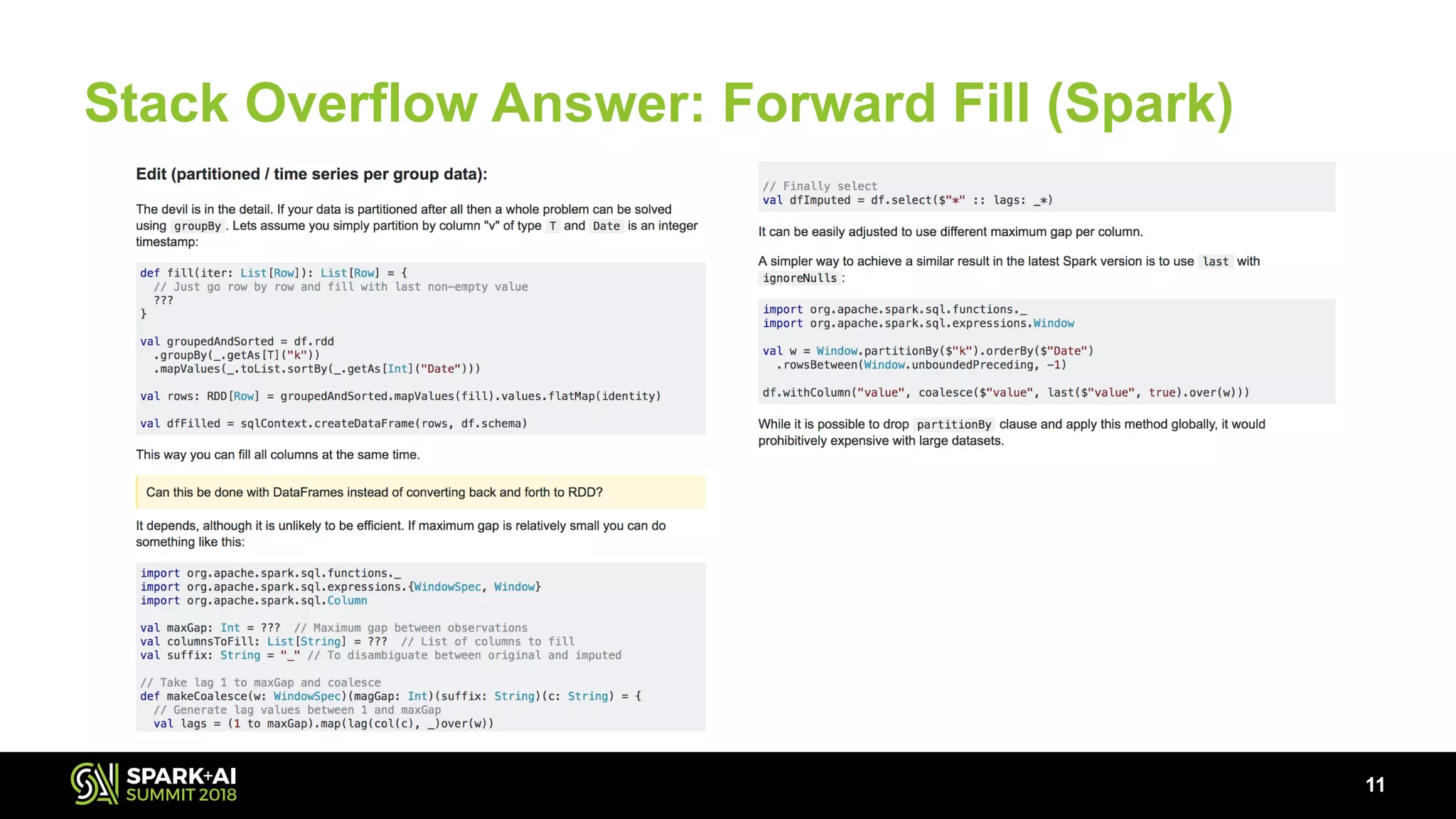






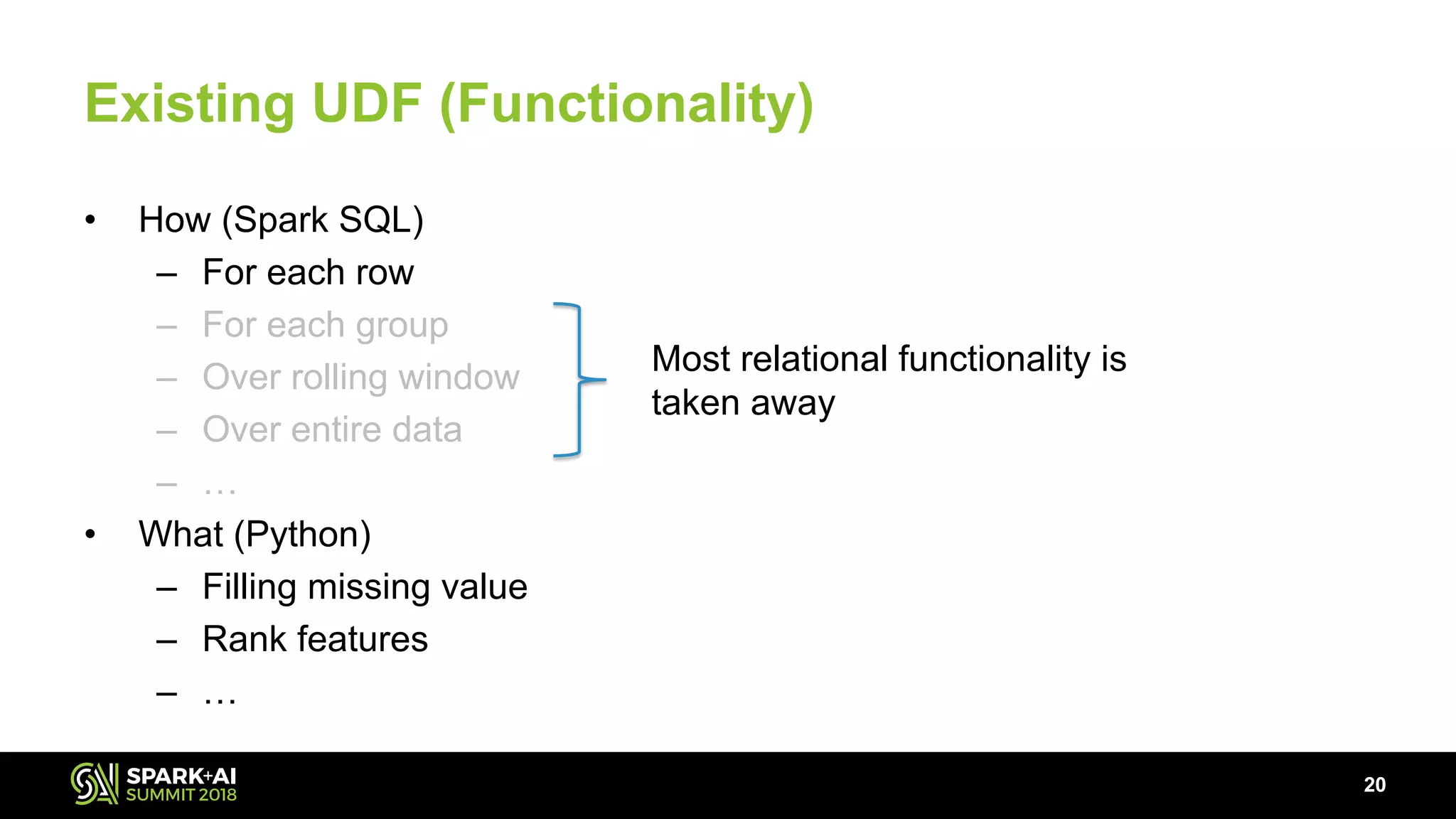


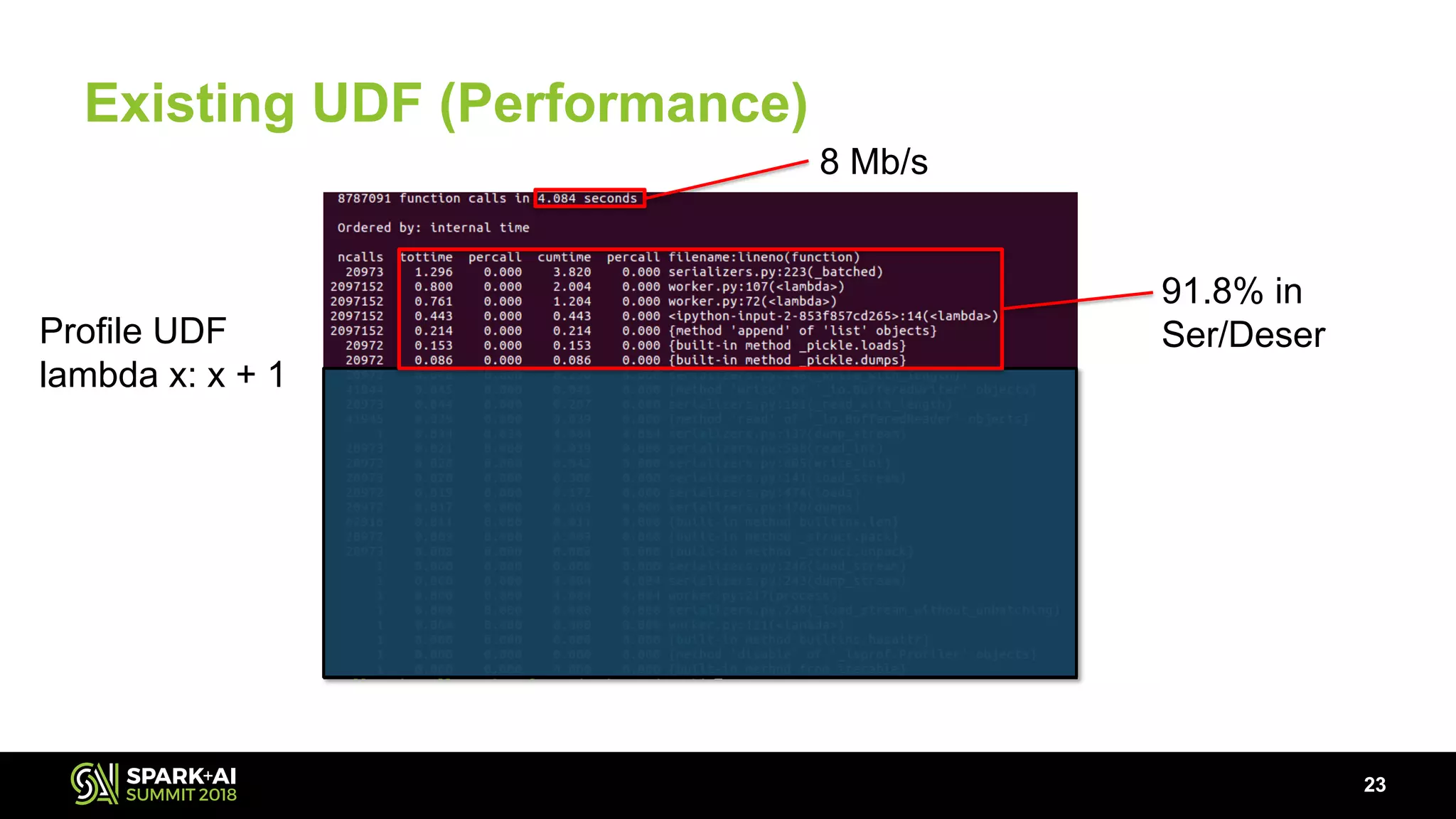




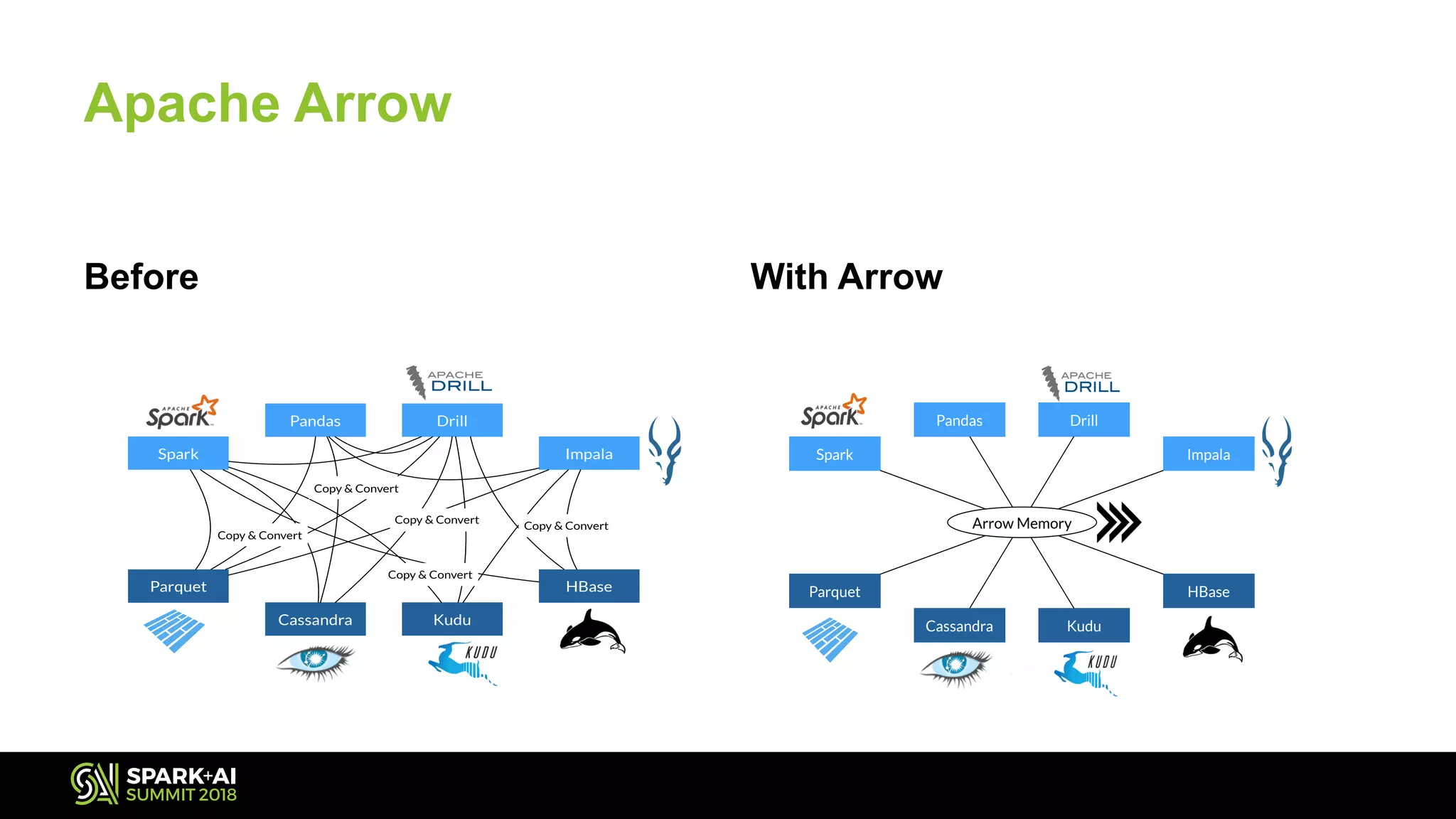
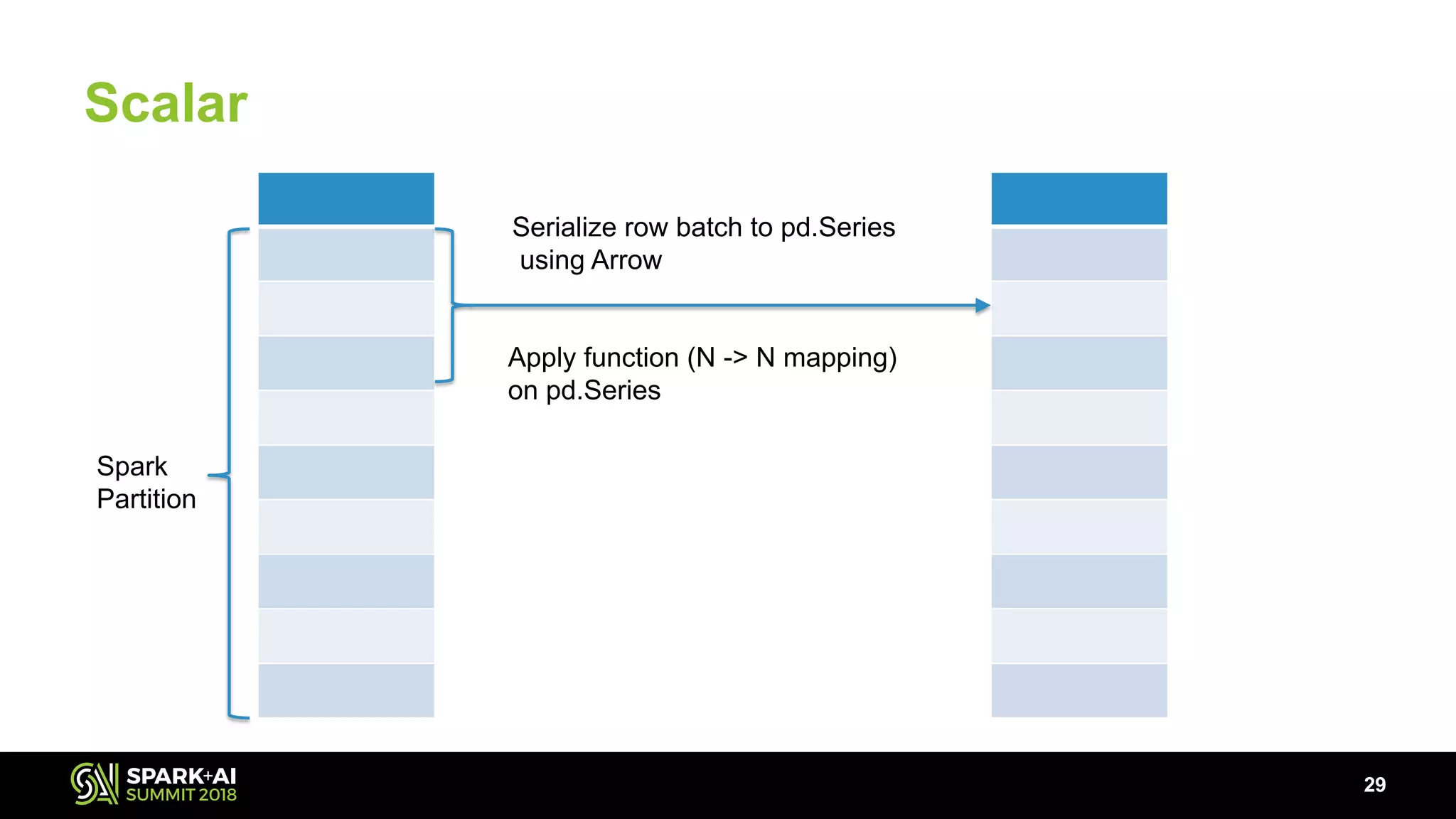



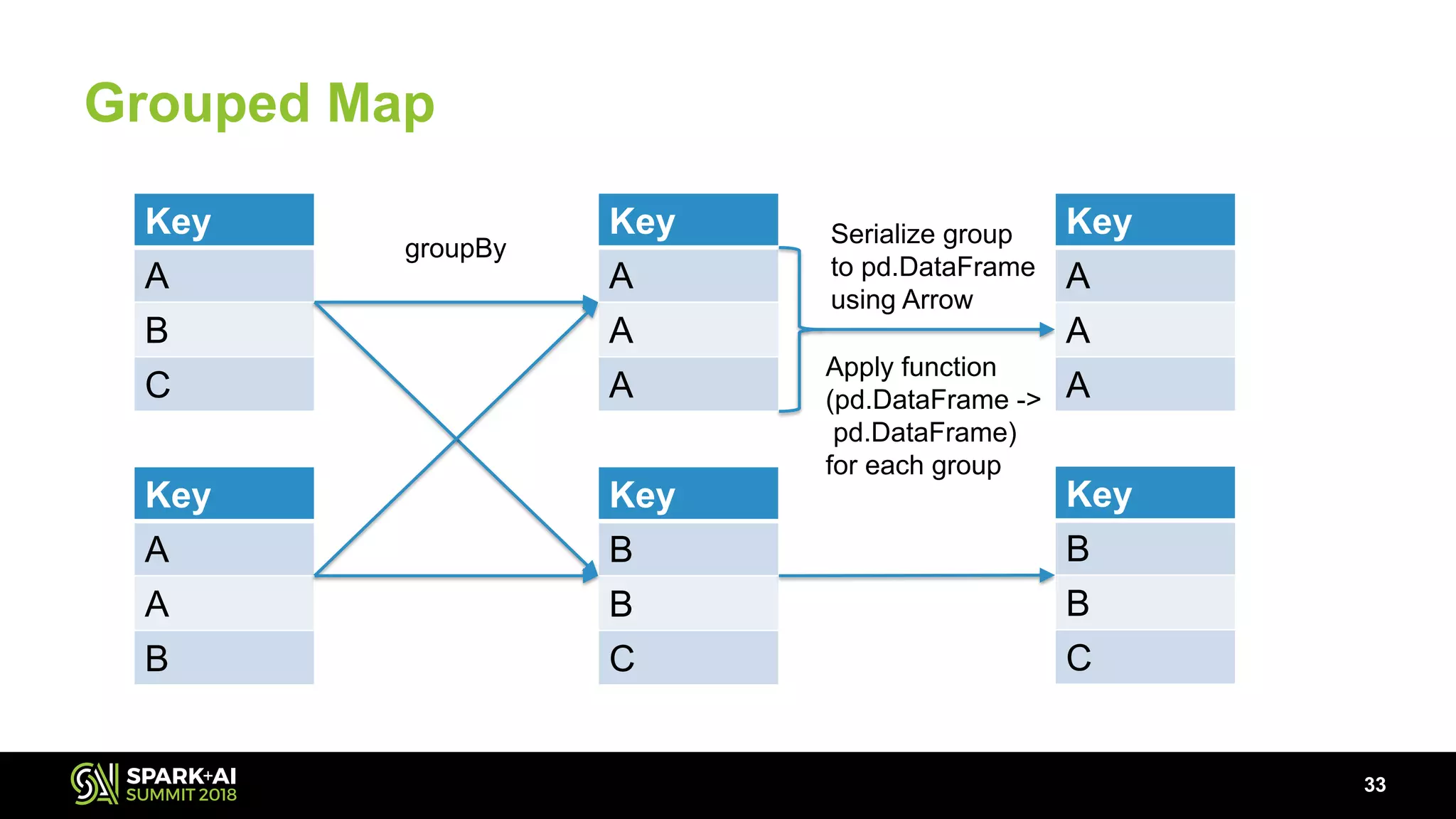






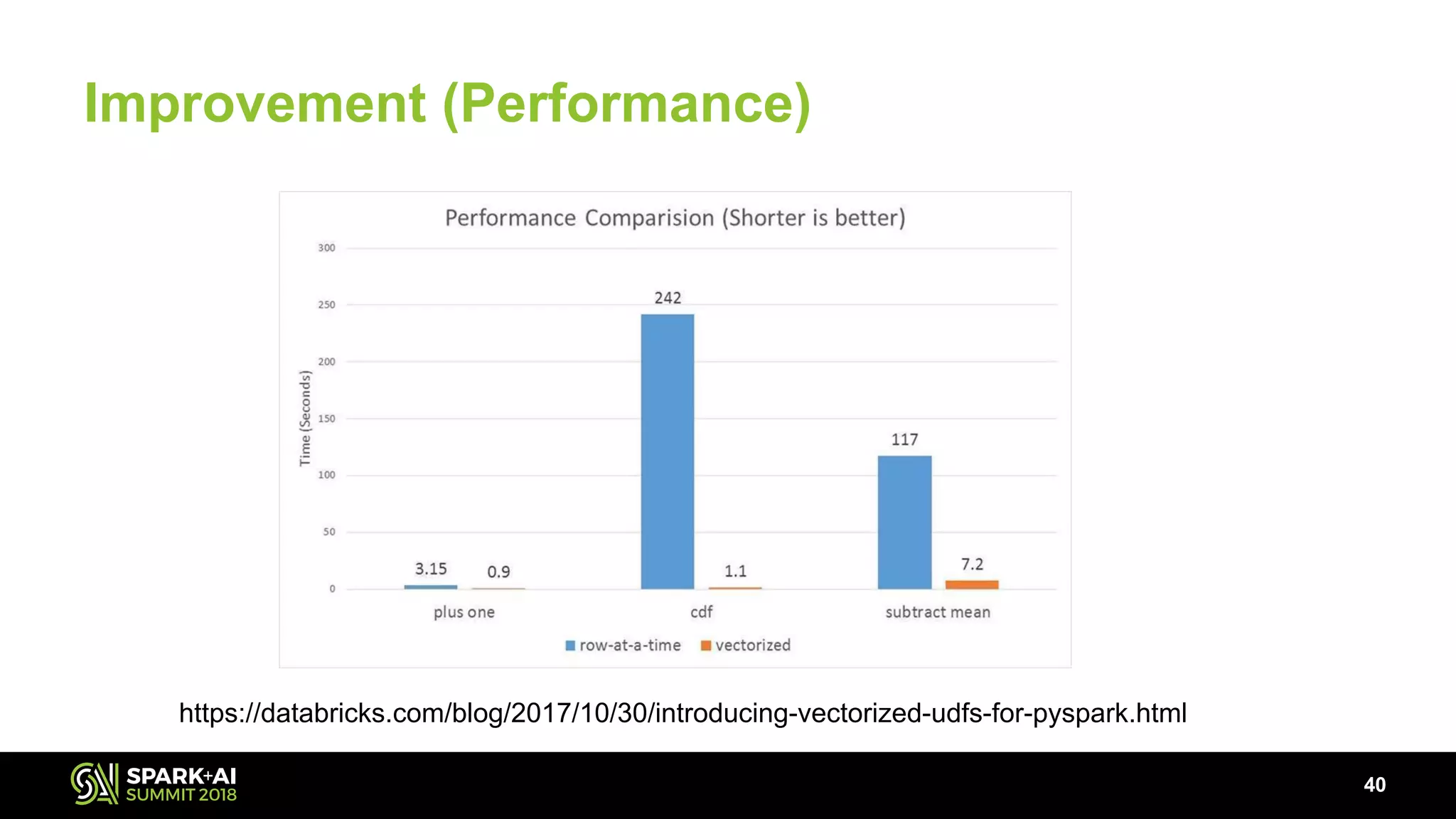





The document discusses the use of Pandas User Defined Functions (UDFs) for scalable data analysis in Python and PySpark, highlighting the functionality and performance improvements introduced in Spark 2.3. It emphasizes the existing feature gaps between Python and Spark, particularly in data manipulation and the significance of Apache Arrow for efficient data transfer. The presentation also outlines ongoing developments in UDFs, including planned enhancements for grouped aggregates and window functions.