Download as PDF, PPTX


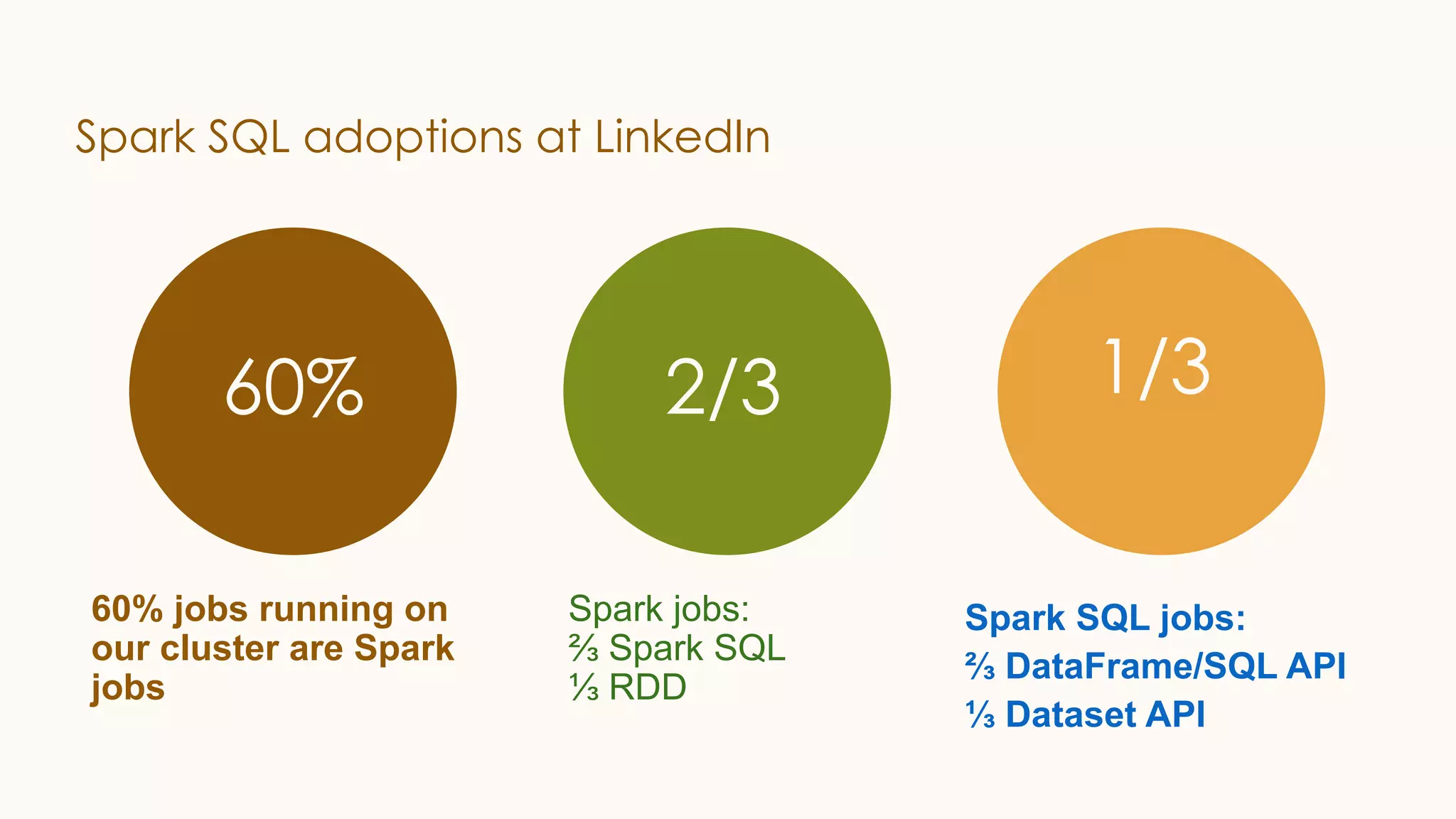






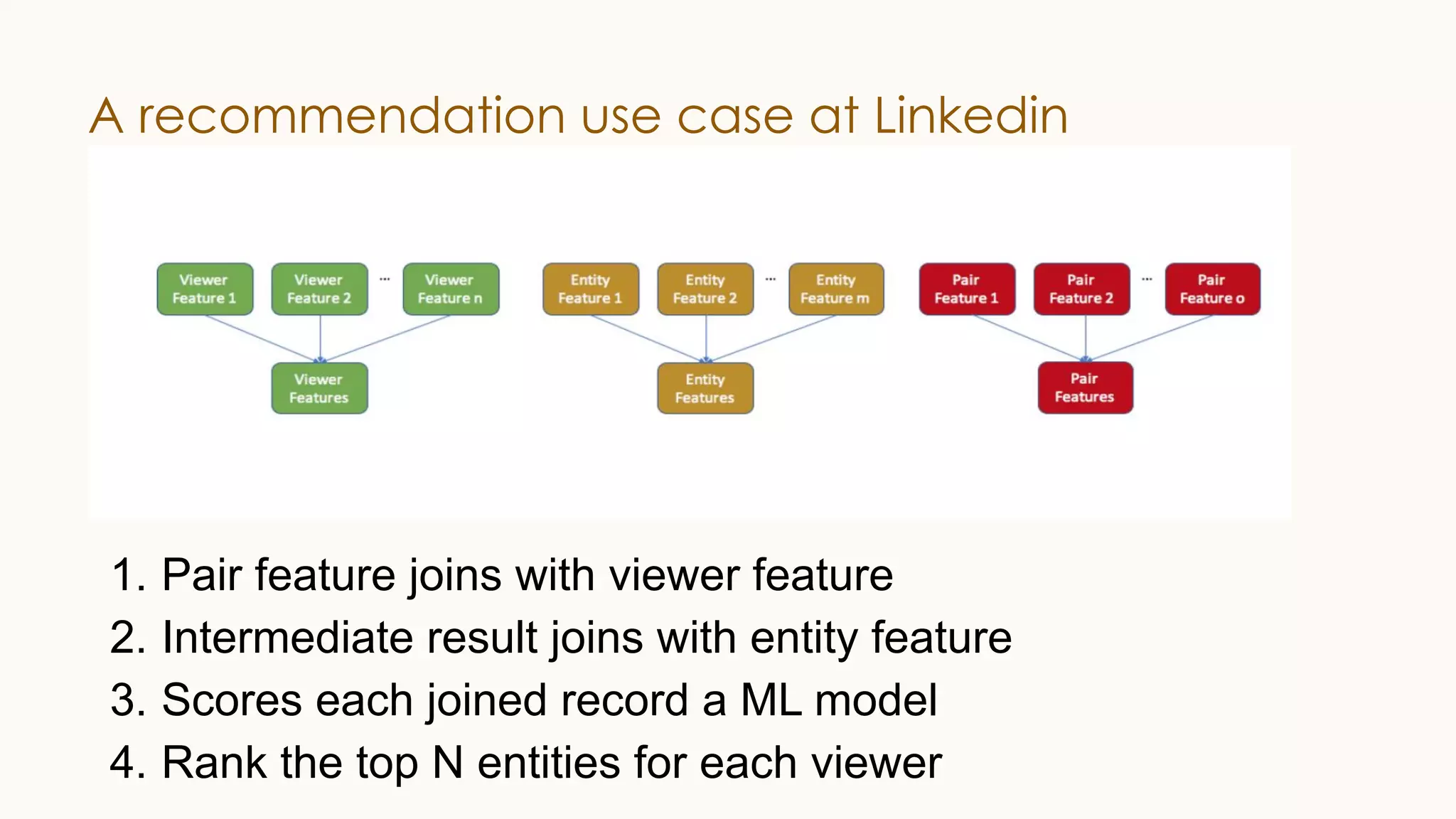

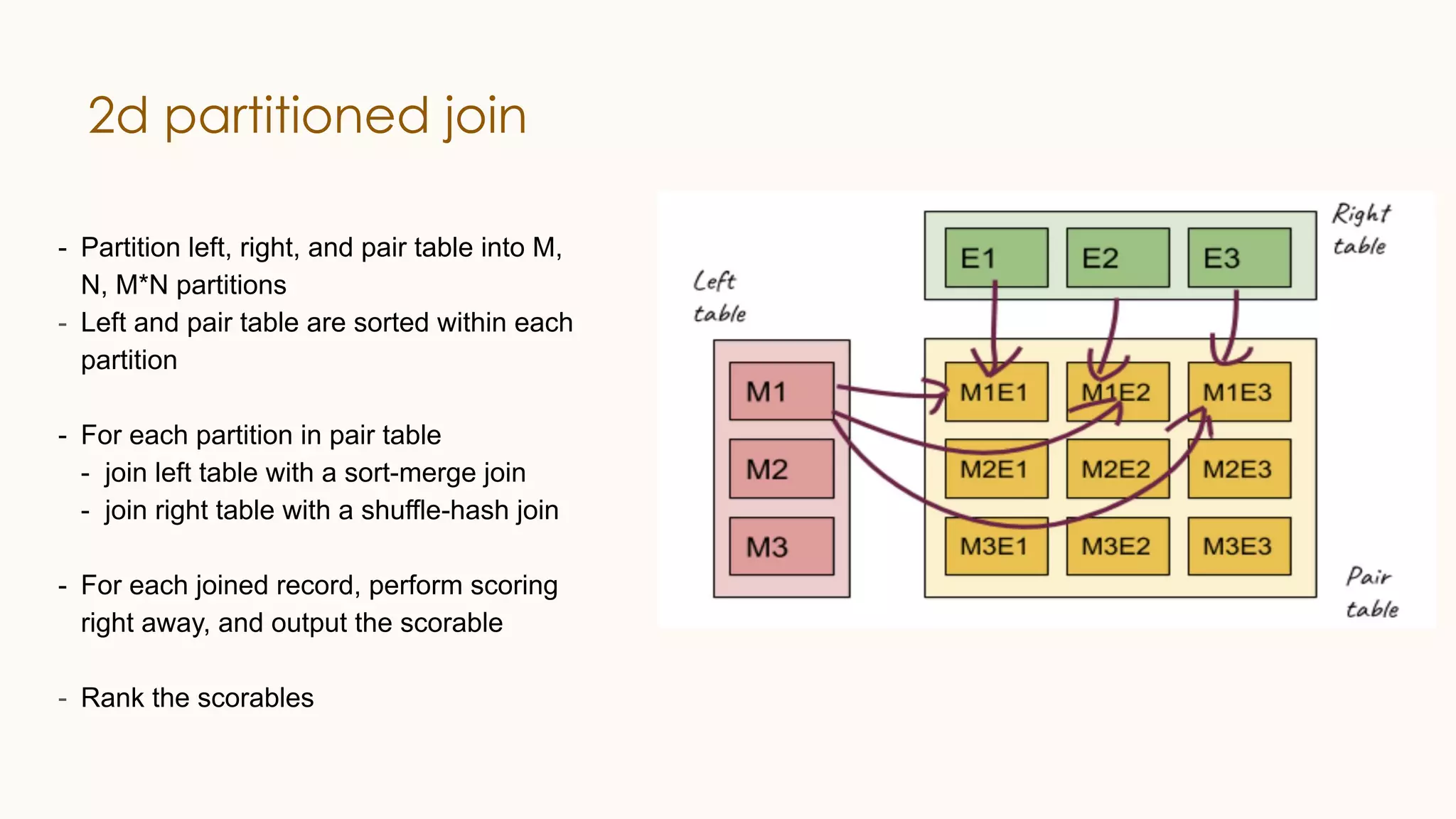







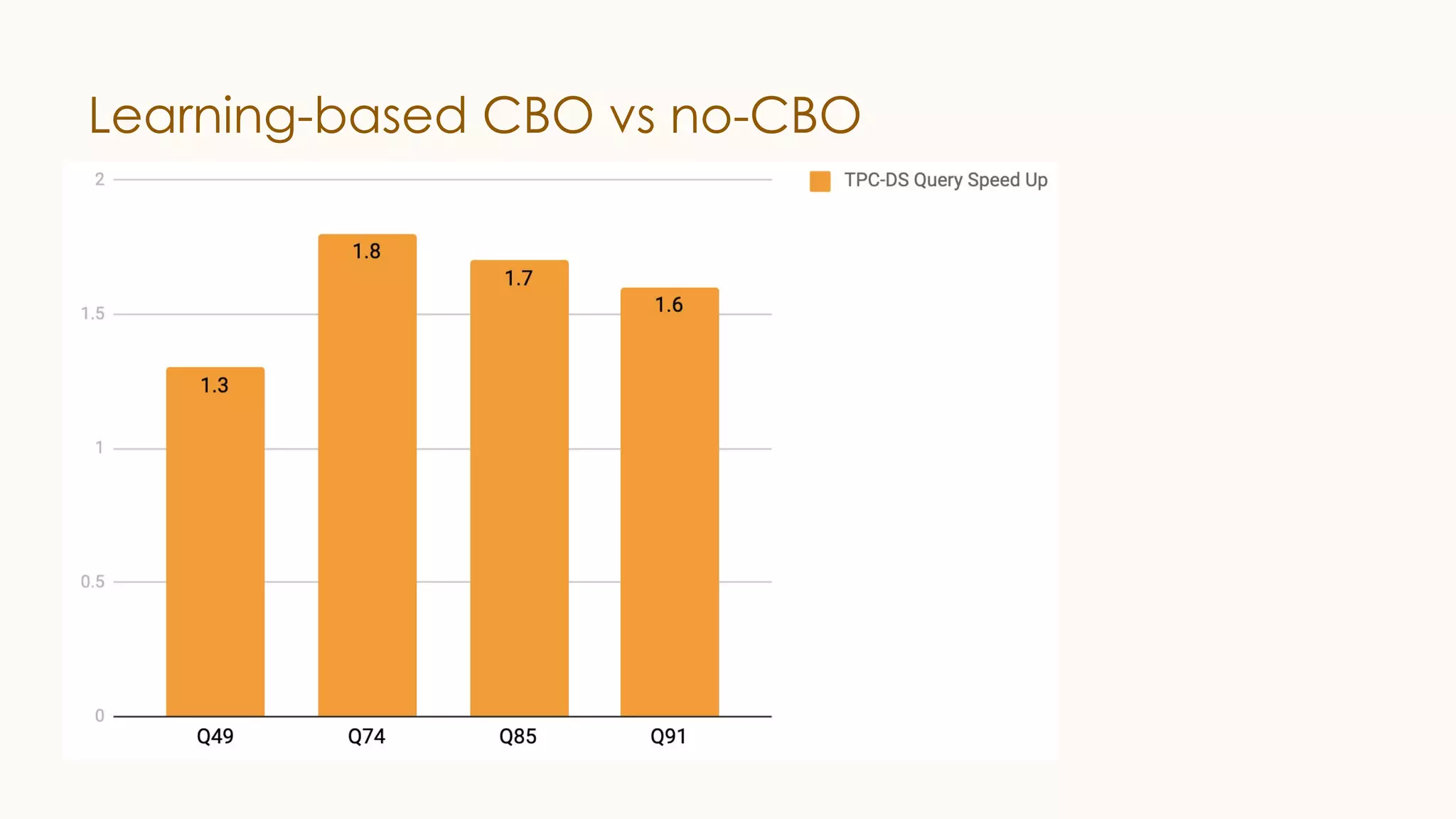


The document discusses enhancements to Spark SQL at LinkedIn, focusing on automated column pruning, two-dimensional partitioned joins, and adaptive execution. It outlines current challenges such as excessive conversion overhead and the need for cost-based optimization, while presenting strategies to improve performance with techniques like learning-based CBO. Additionally, it highlights the roadmap for Spark SQL optimizations and integrates machine learning for better query execution rates.