Downloaded 273 times


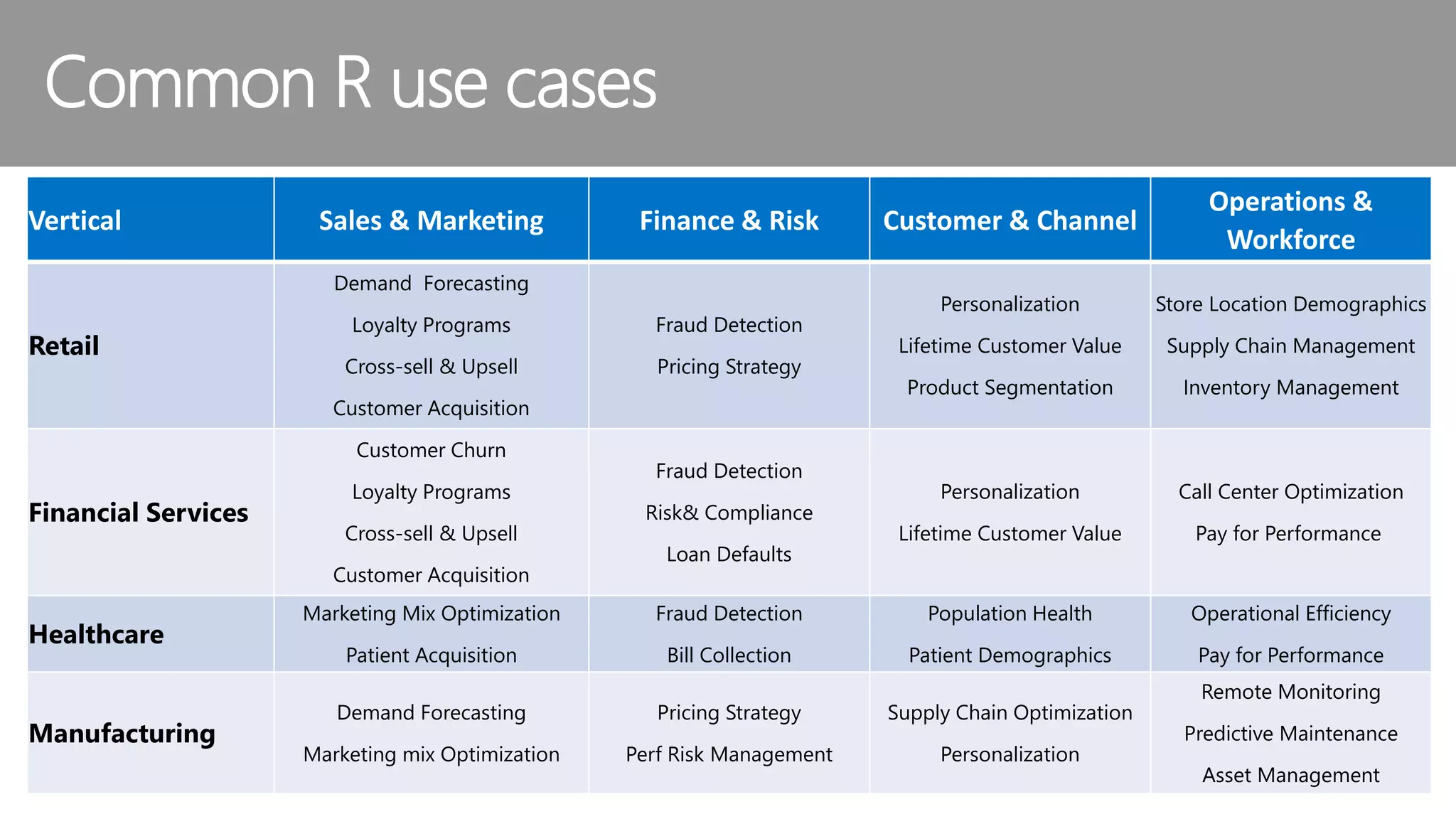

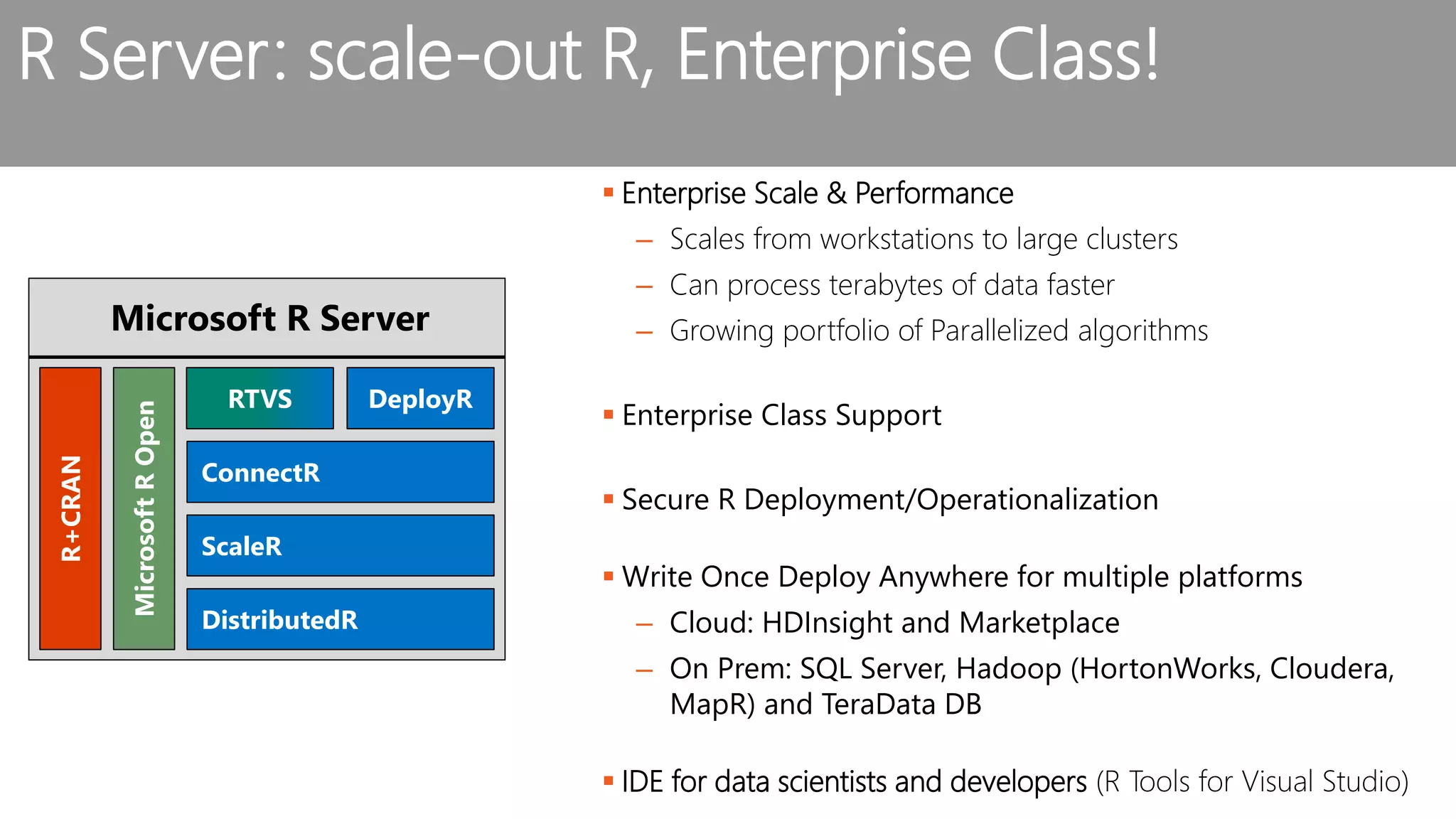

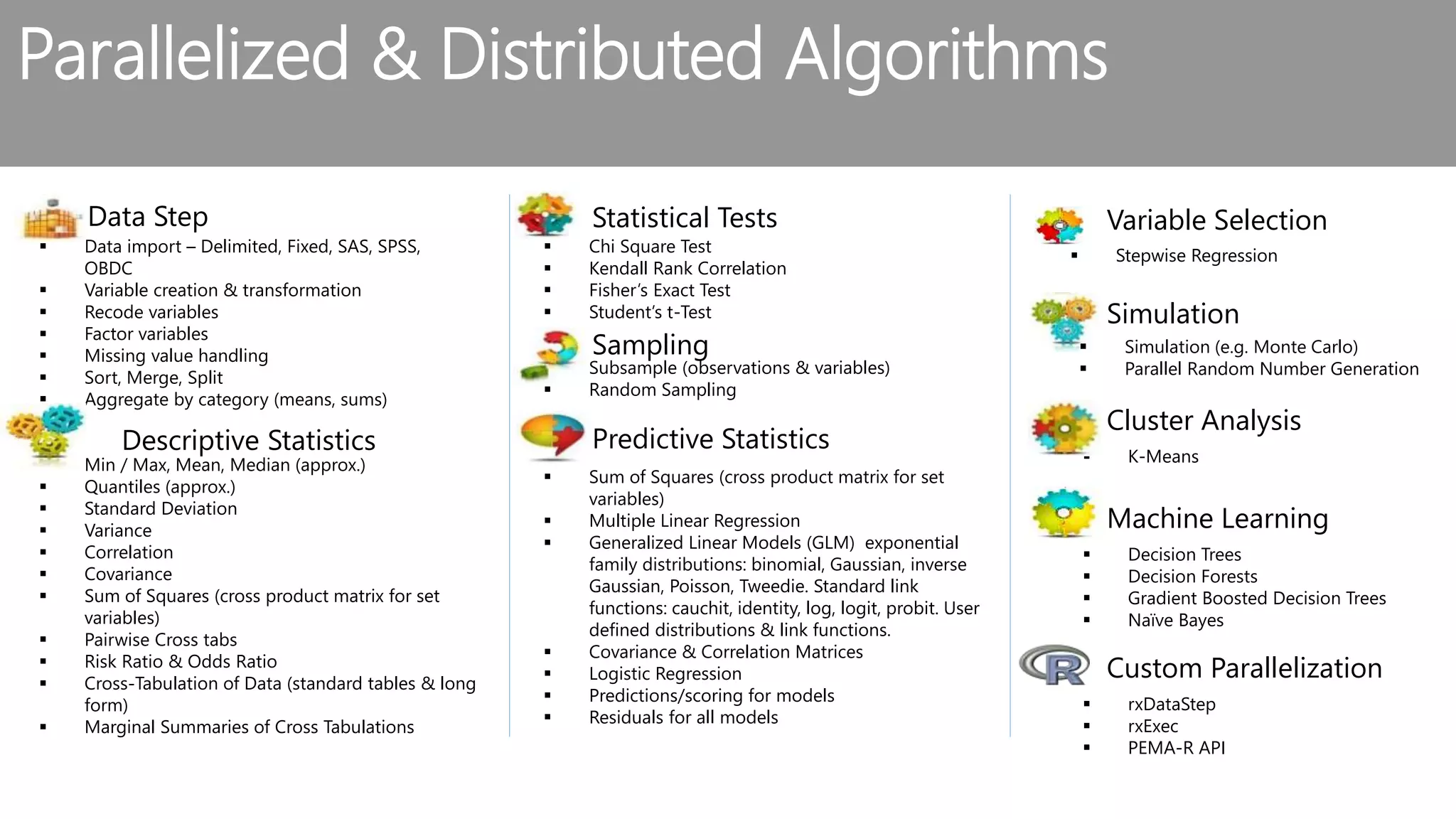
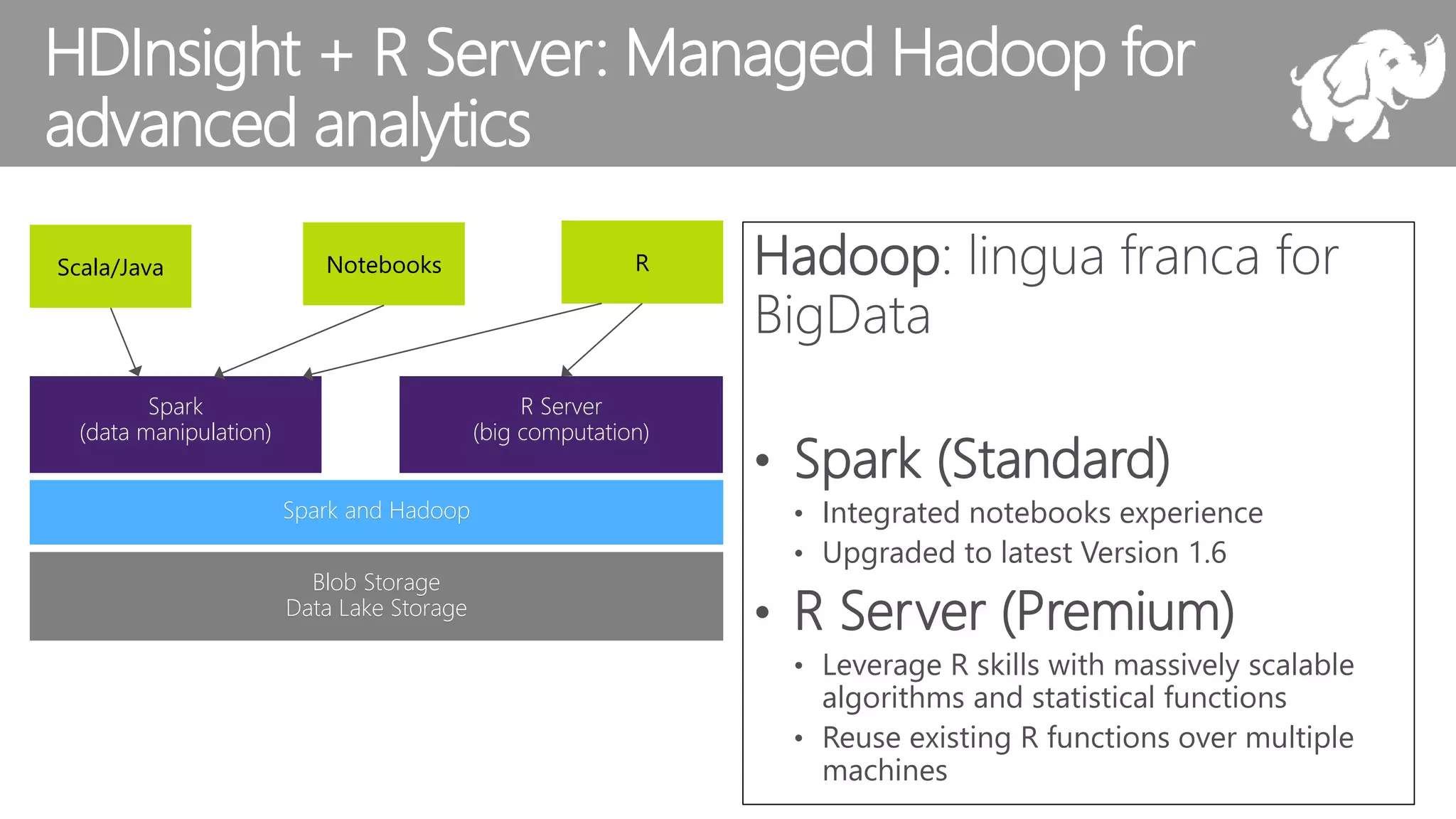
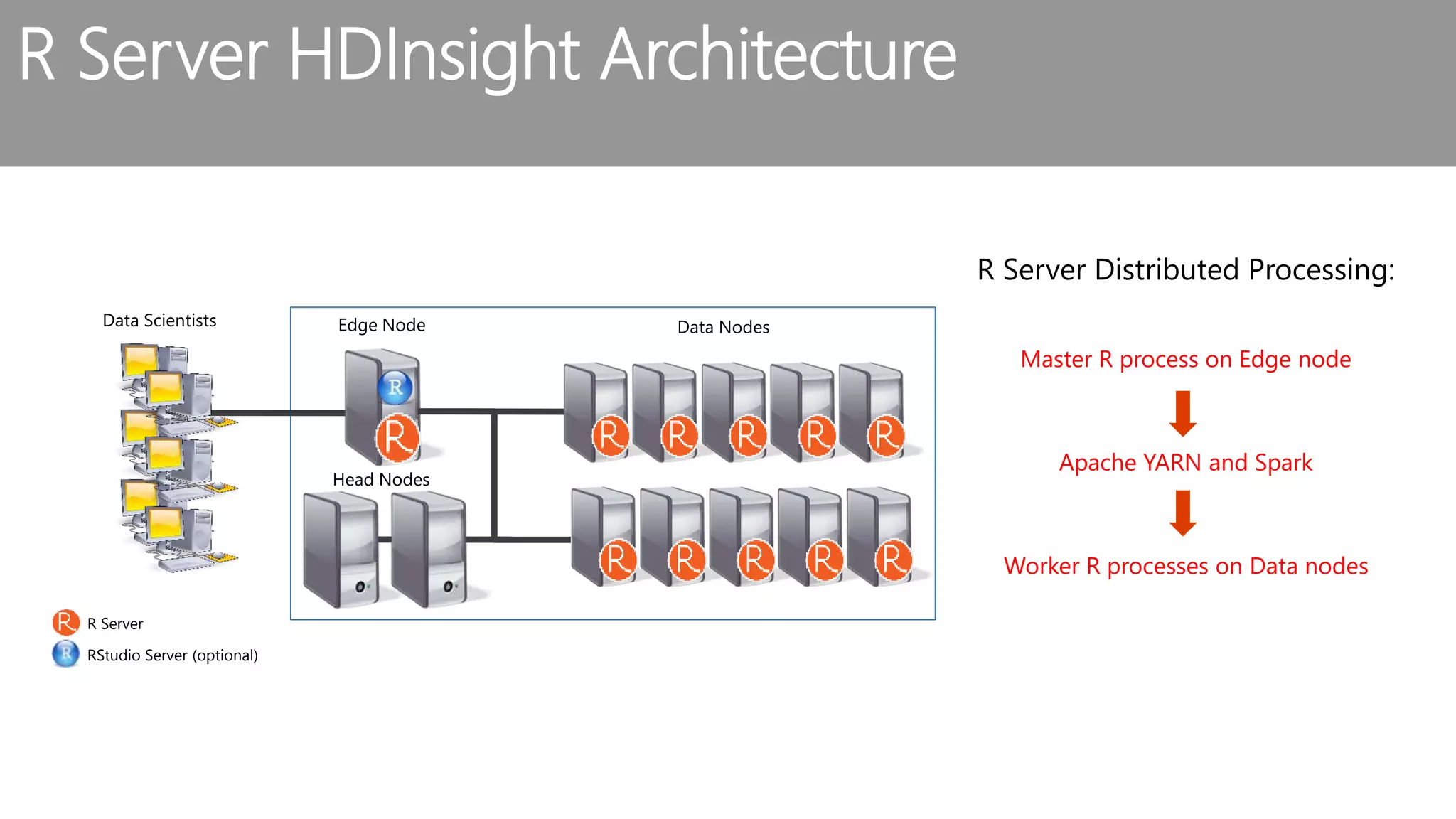
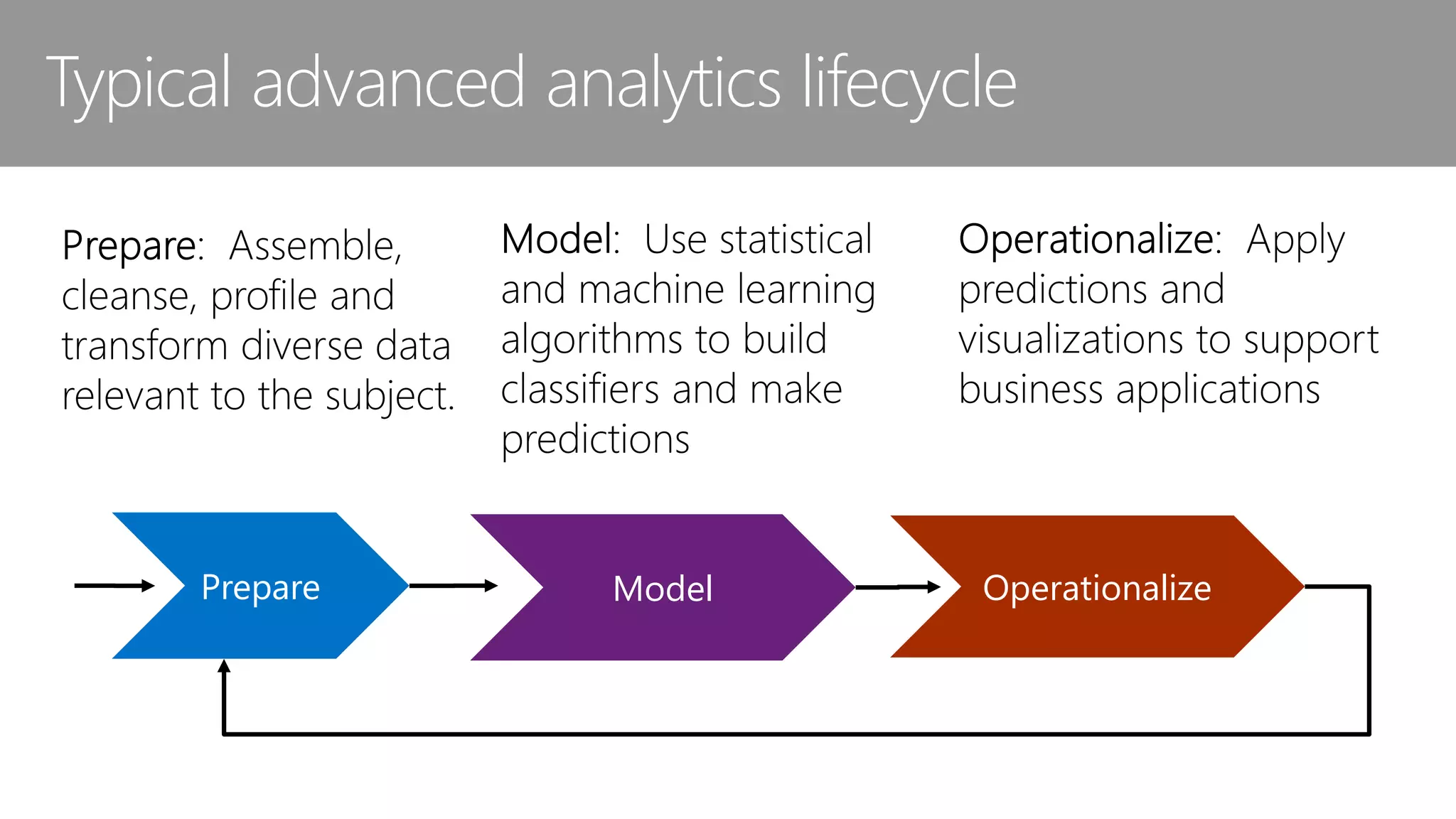



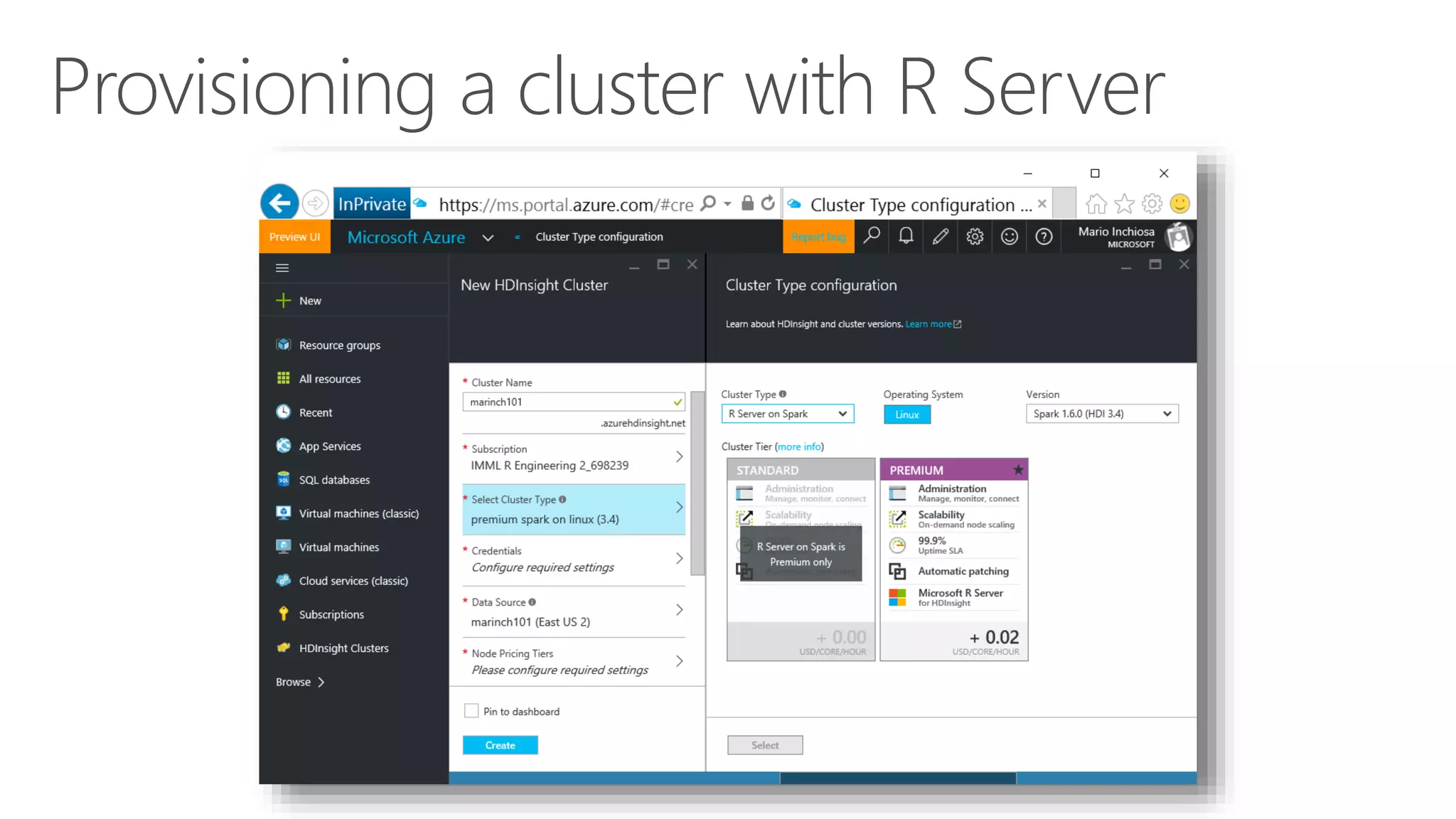
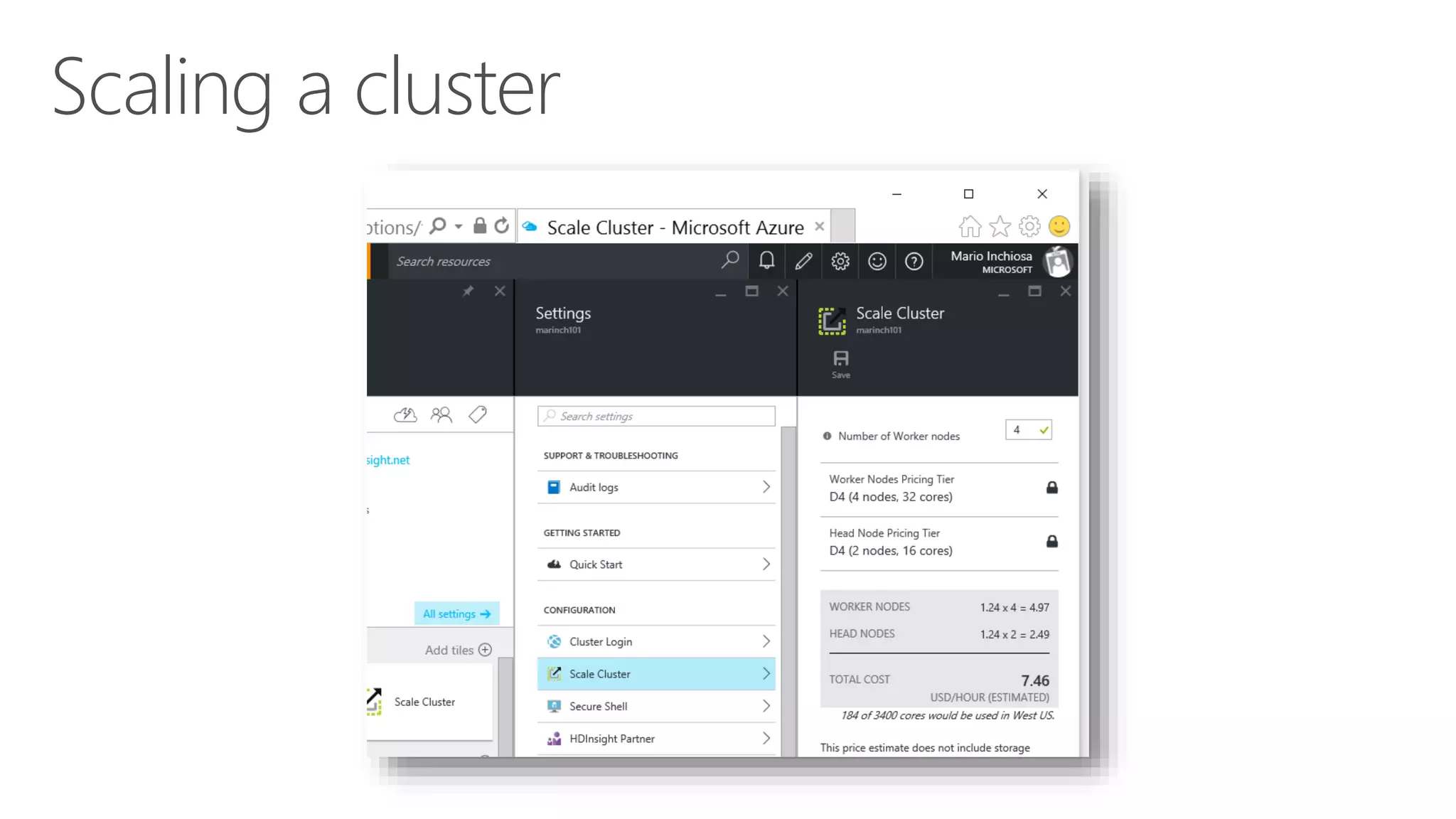
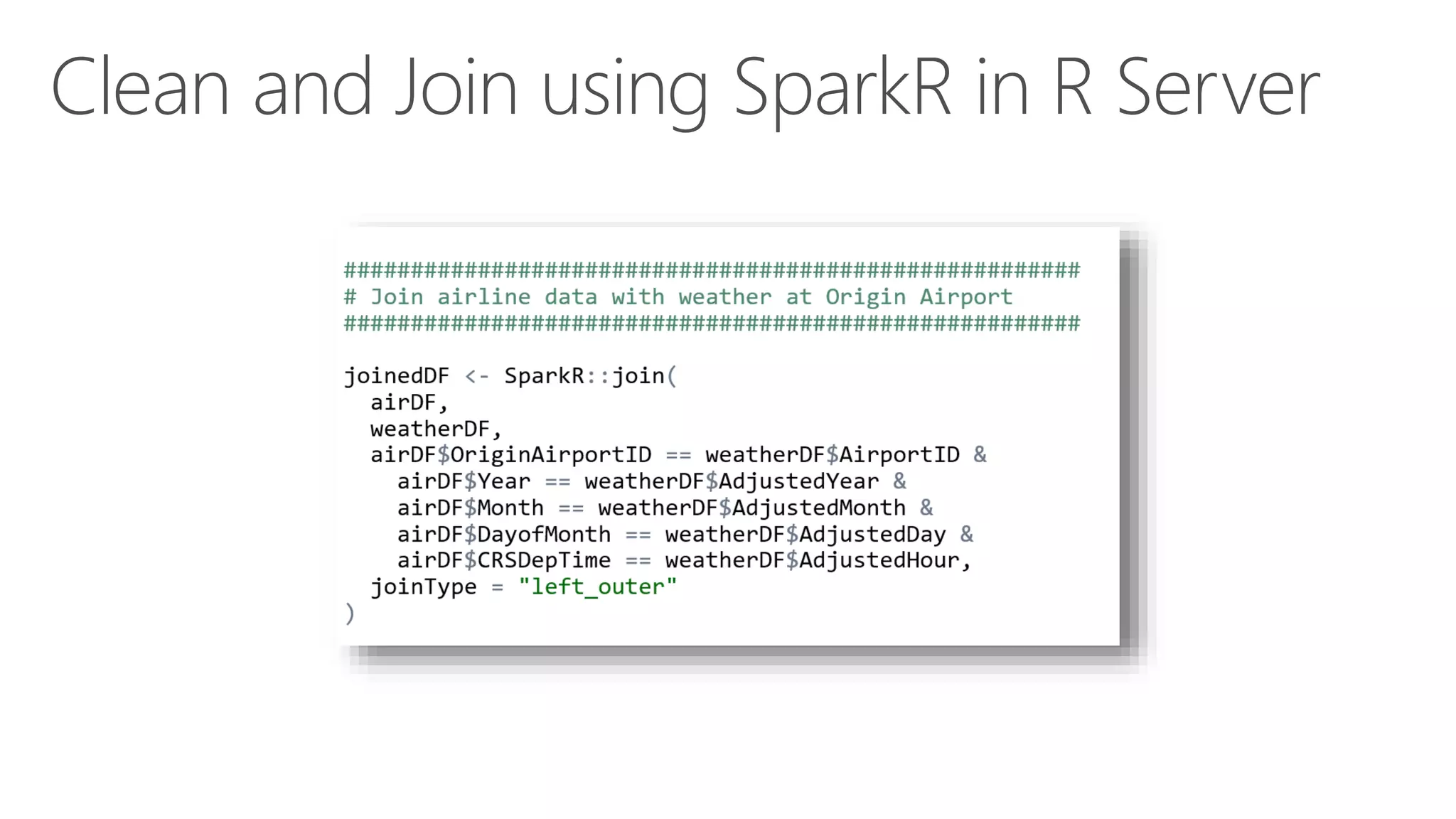



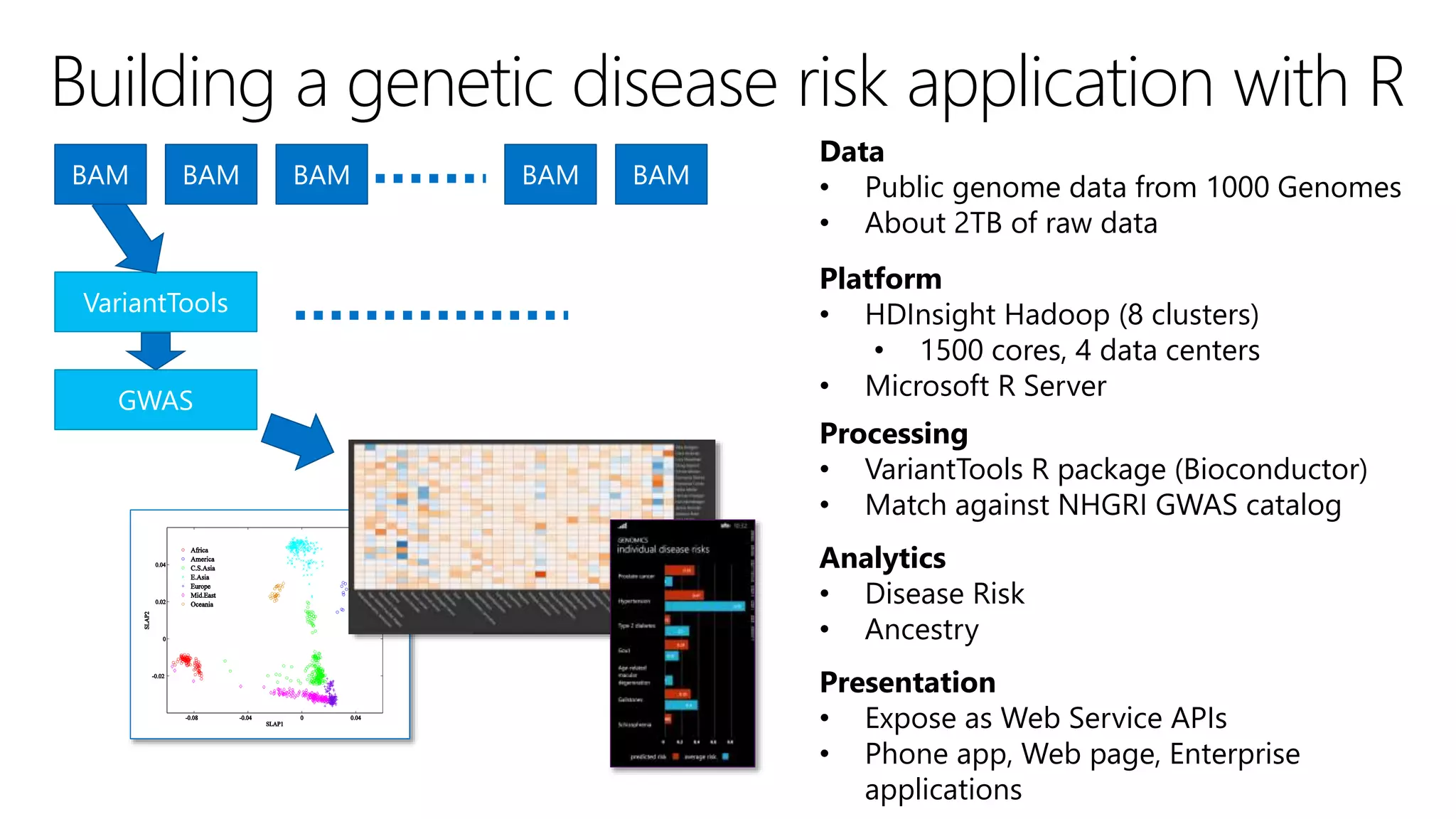
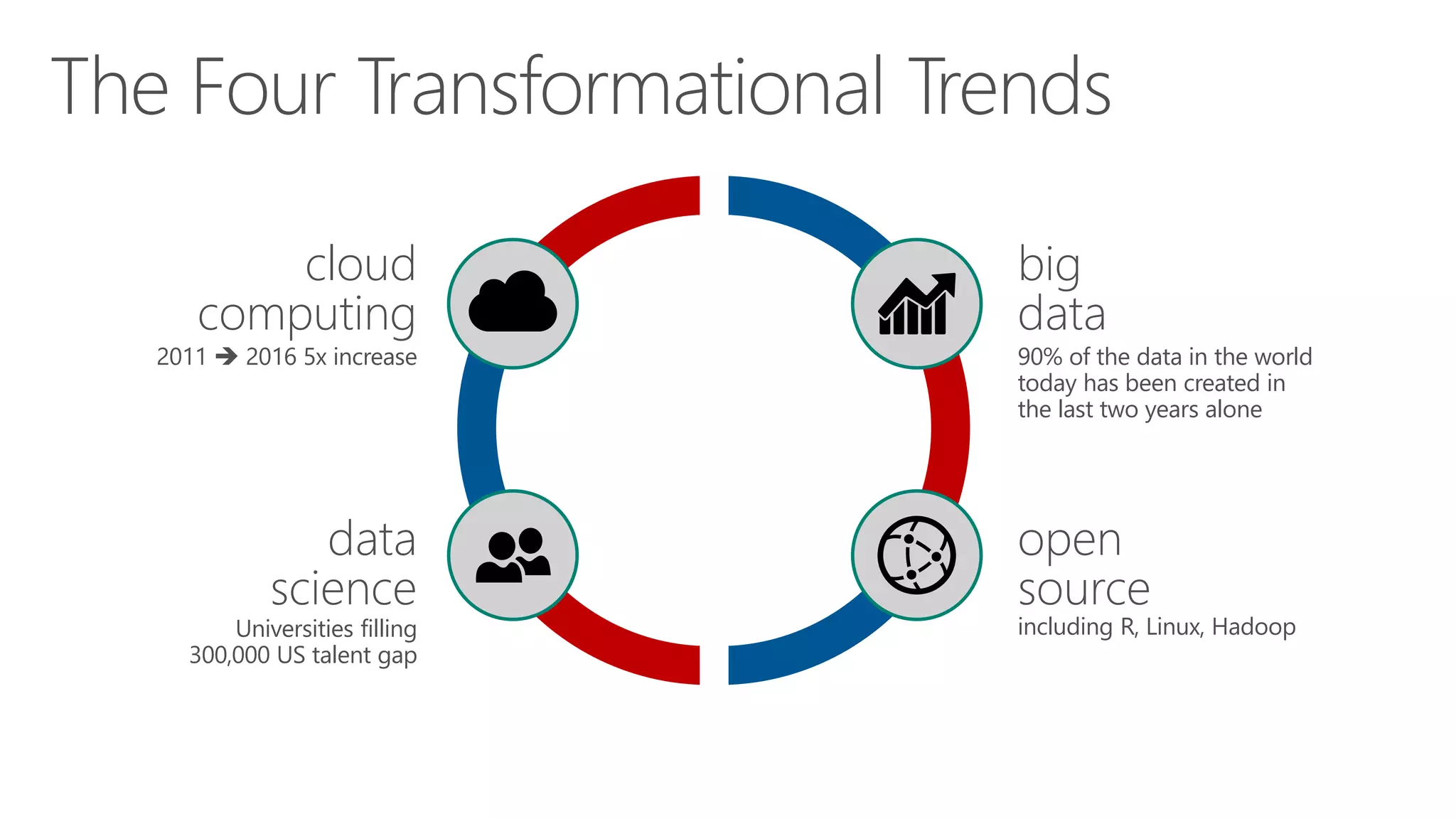


The document outlines the challenges and solutions for building a scalable data science platform using R, emphasizing the limitations of open-source R in enterprise environments. It introduces R Server as an enterprise-class solution that scales efficiently, supports extensive data analysis capabilities, and integrates with various data platforms. Additionally, it highlights applications across multiple sectors such as finance, healthcare, and manufacturing, showcasing its utility in advanced analytics and machine learning workloads.