Downloaded 159 times


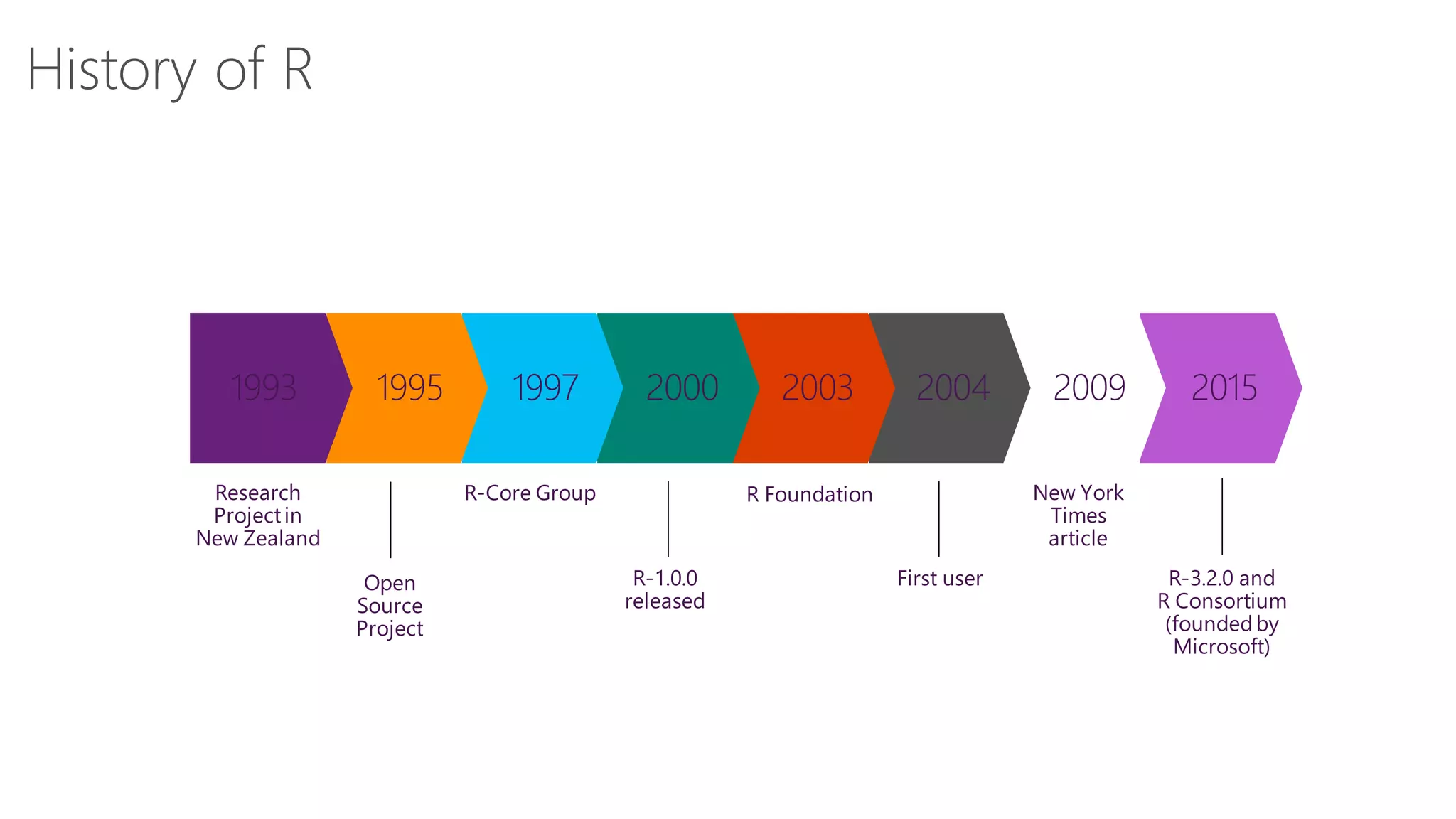


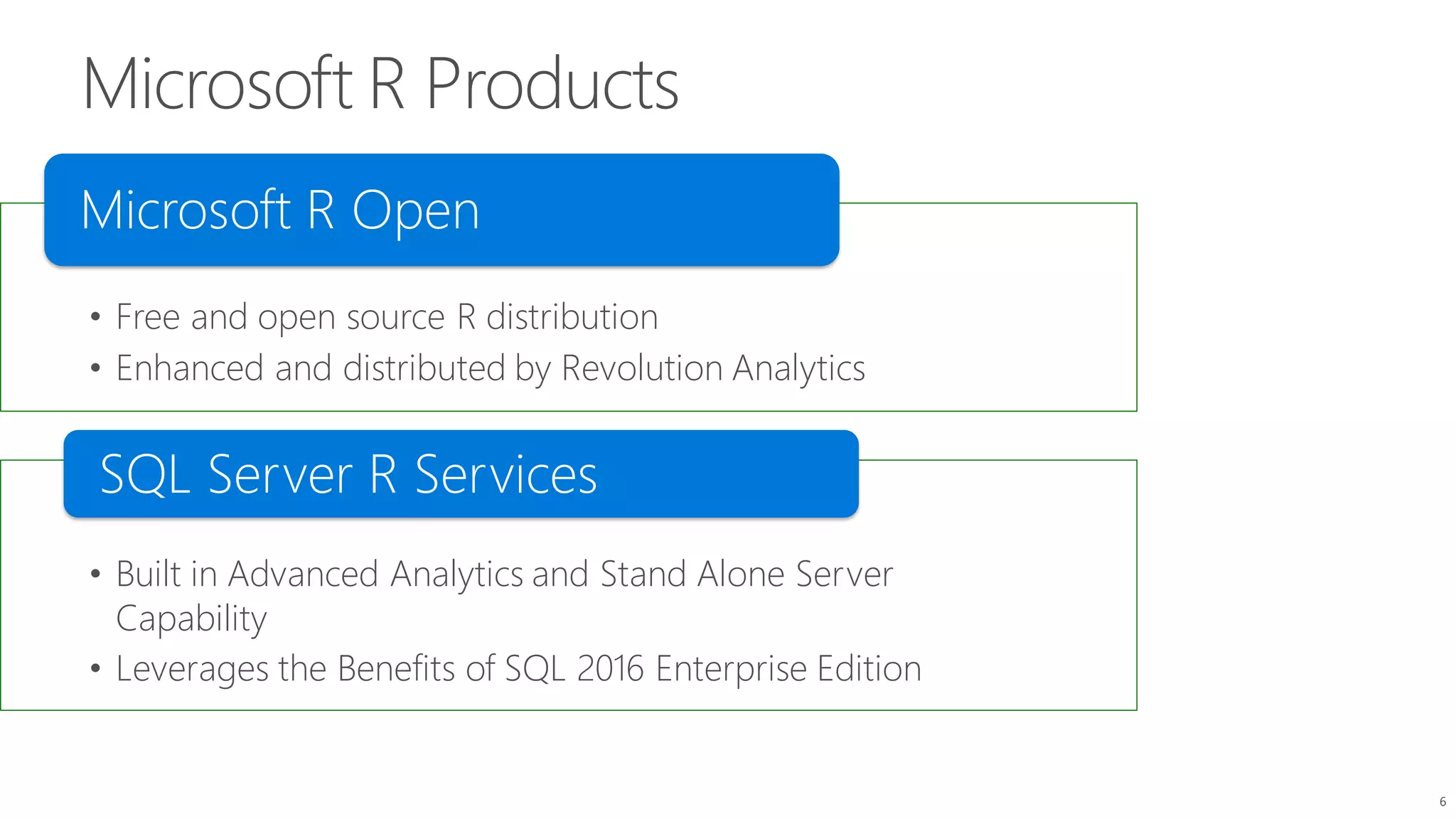

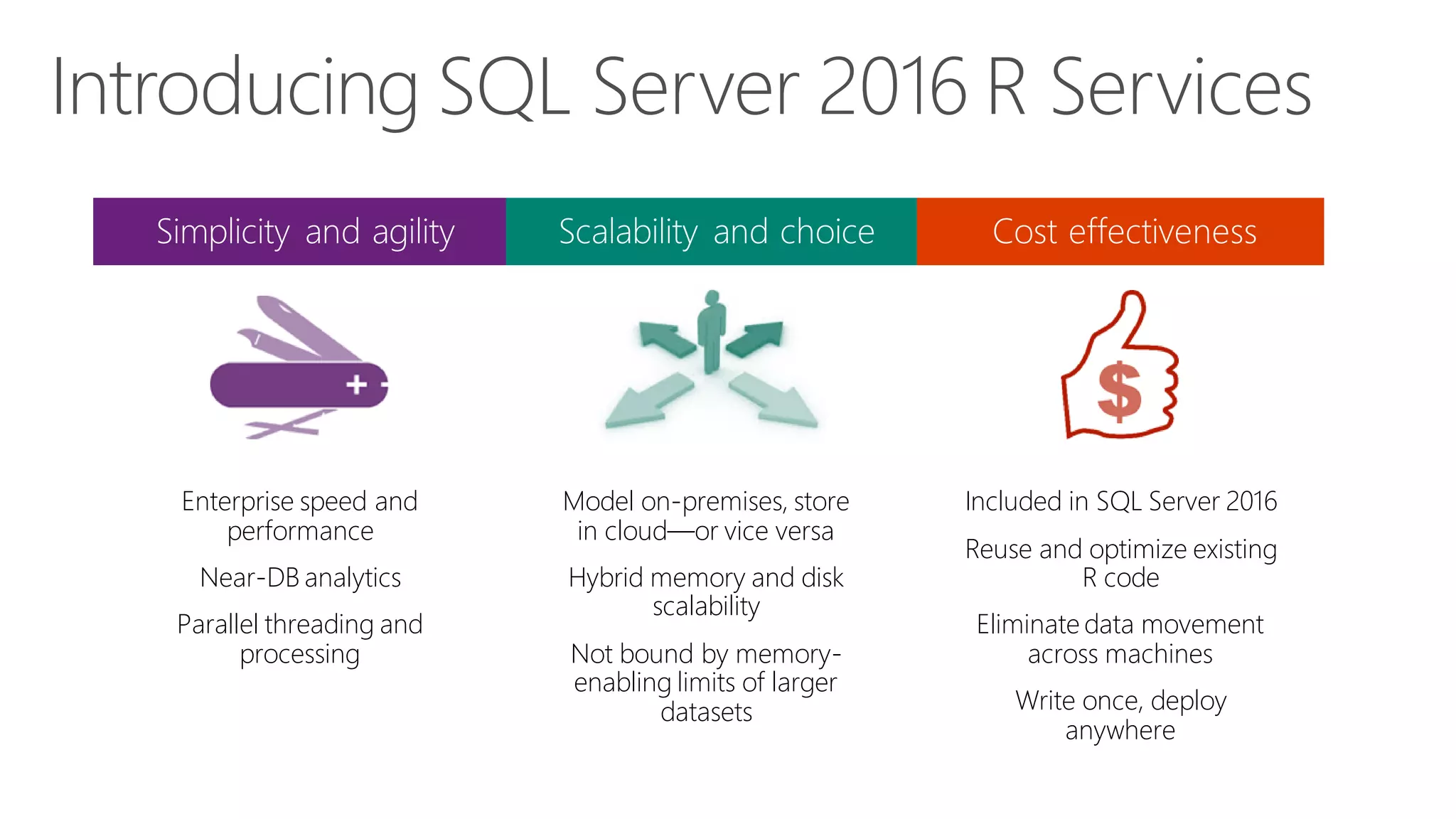

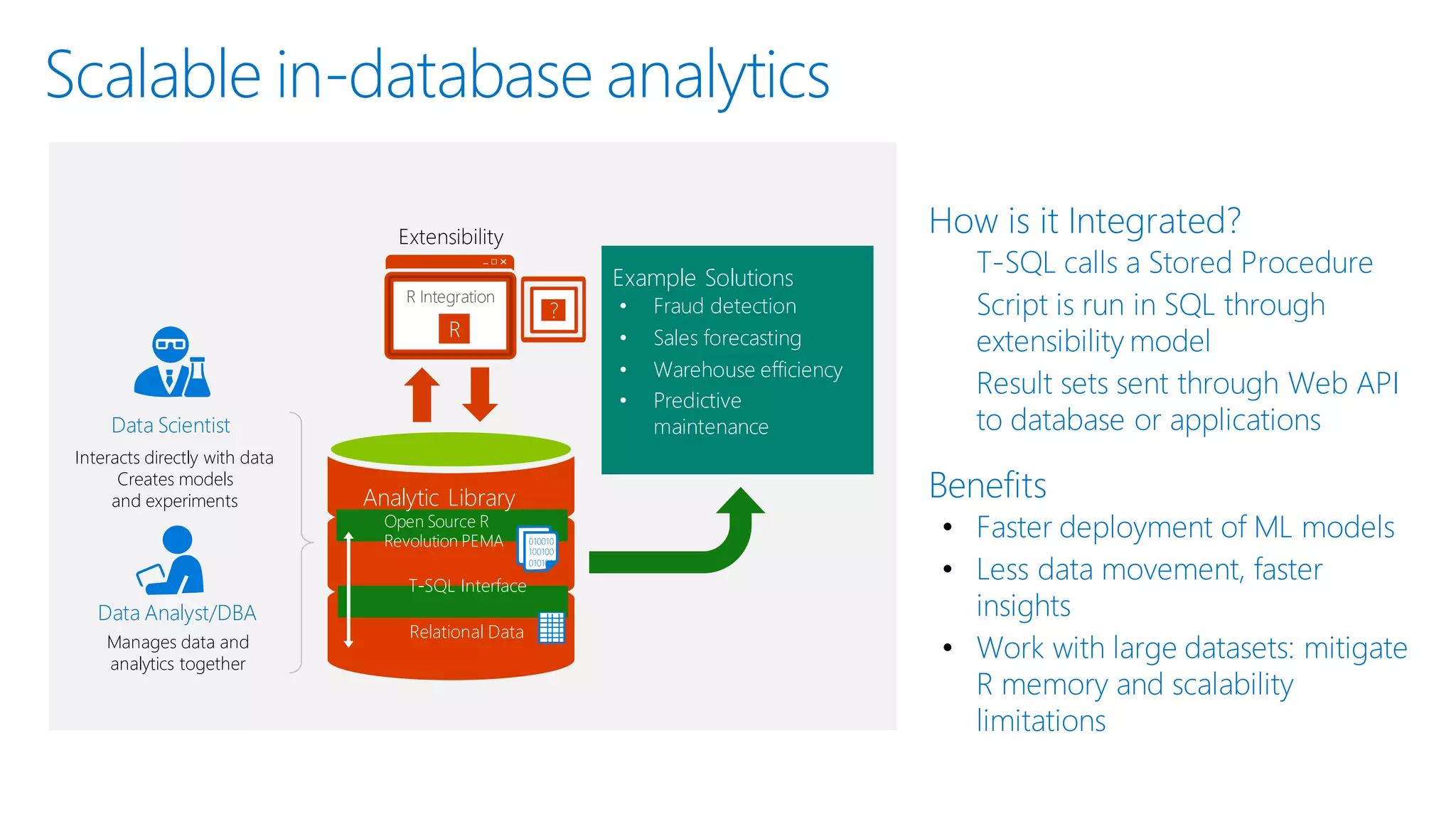
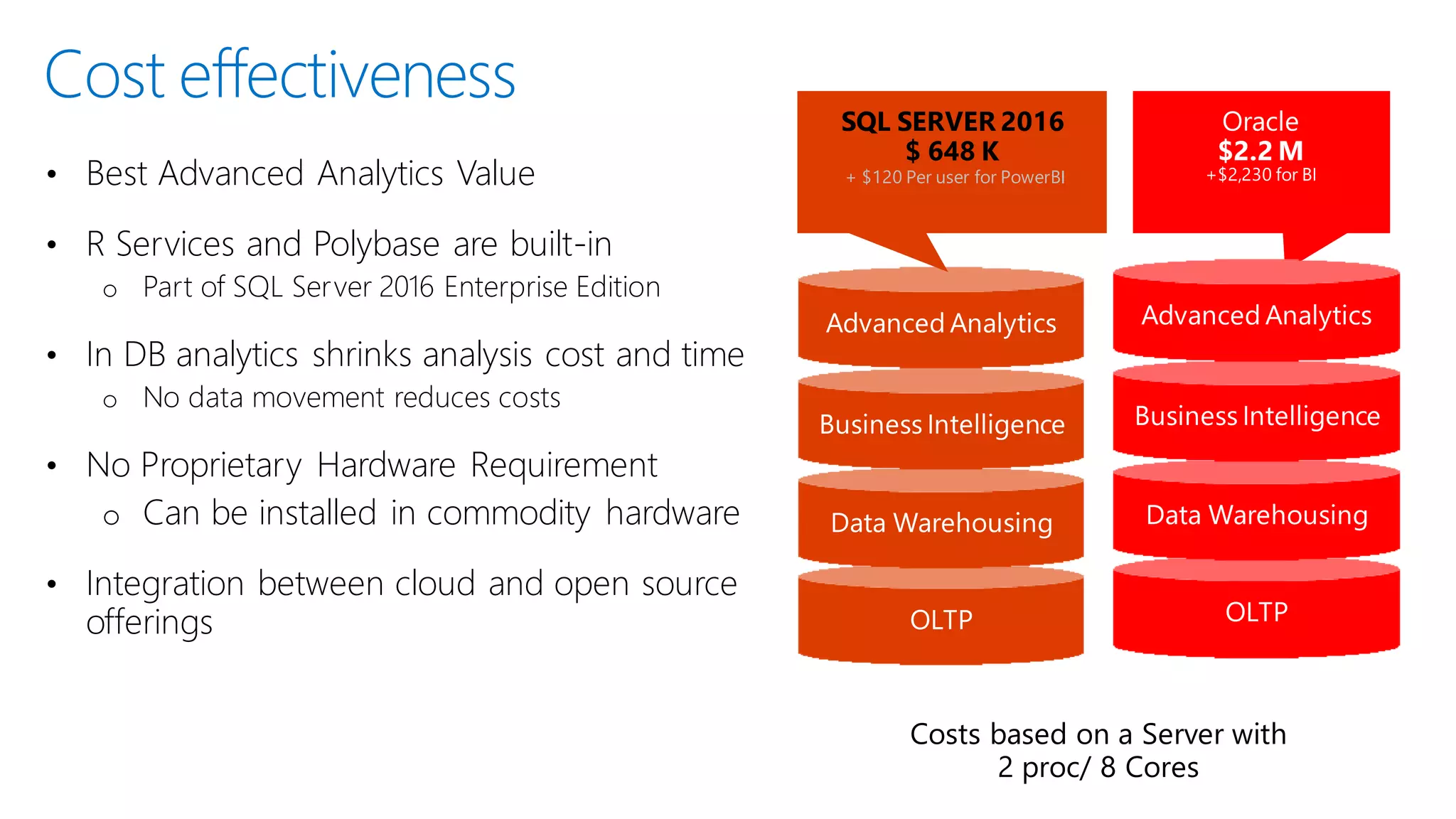

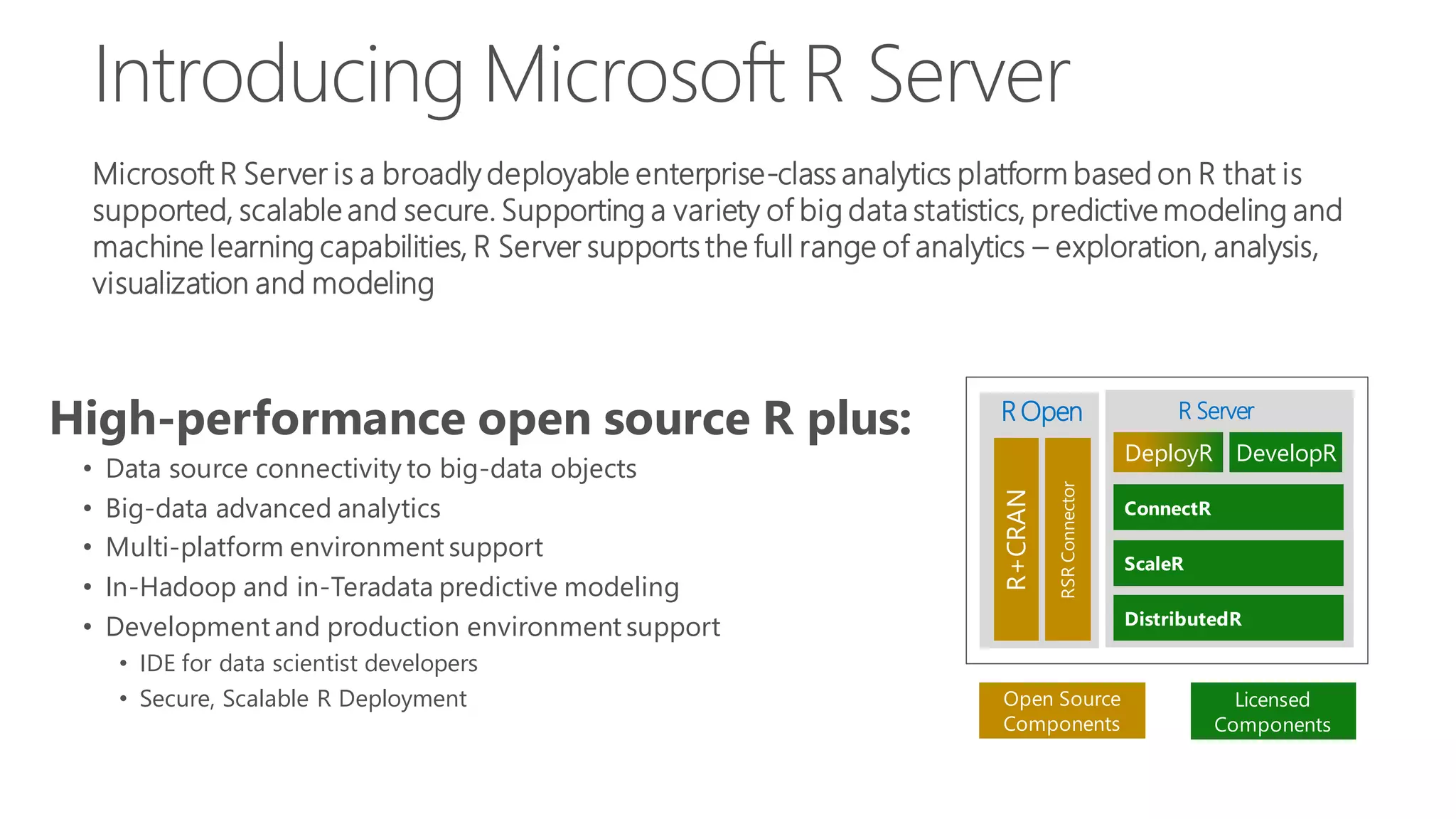
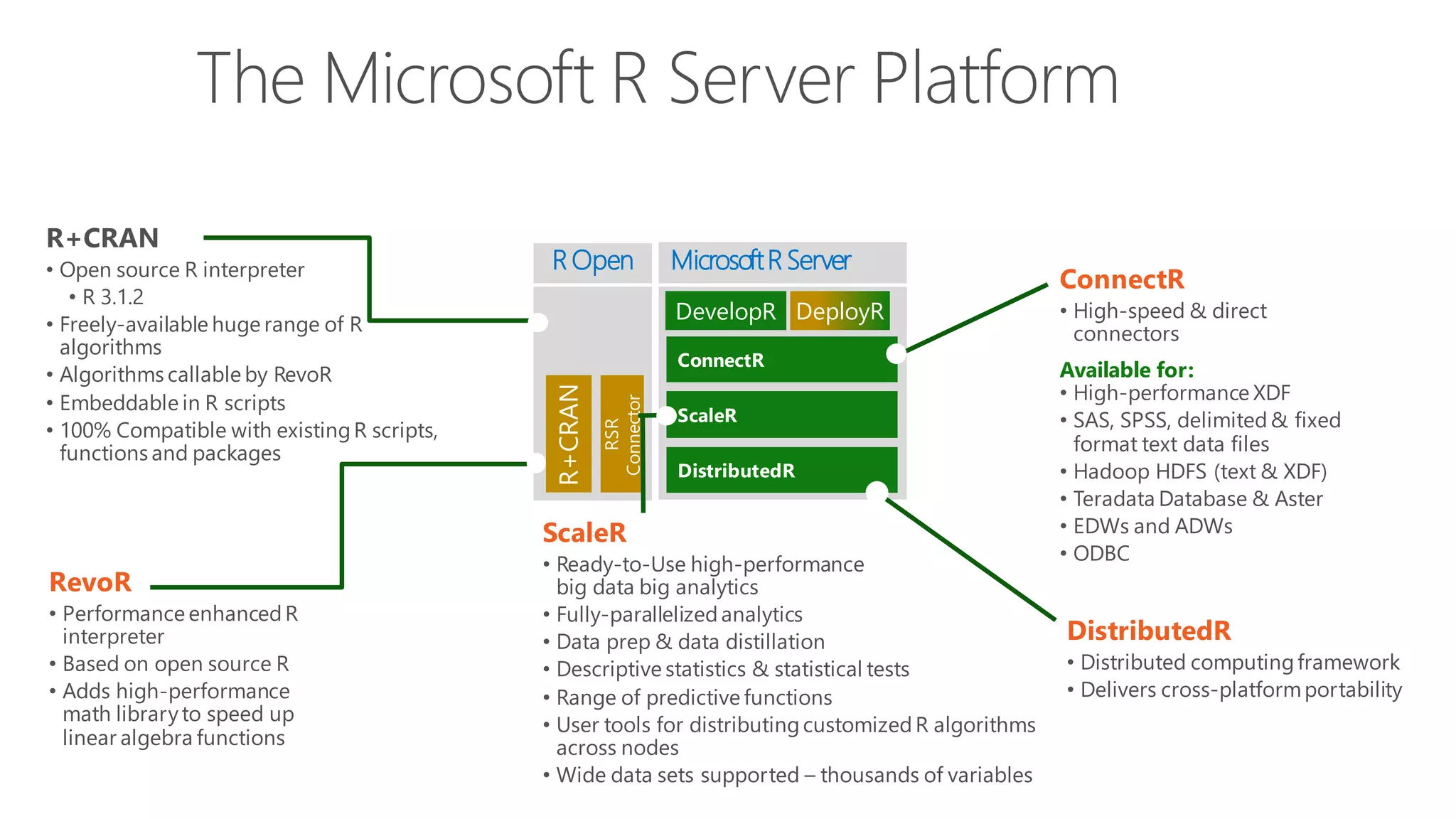
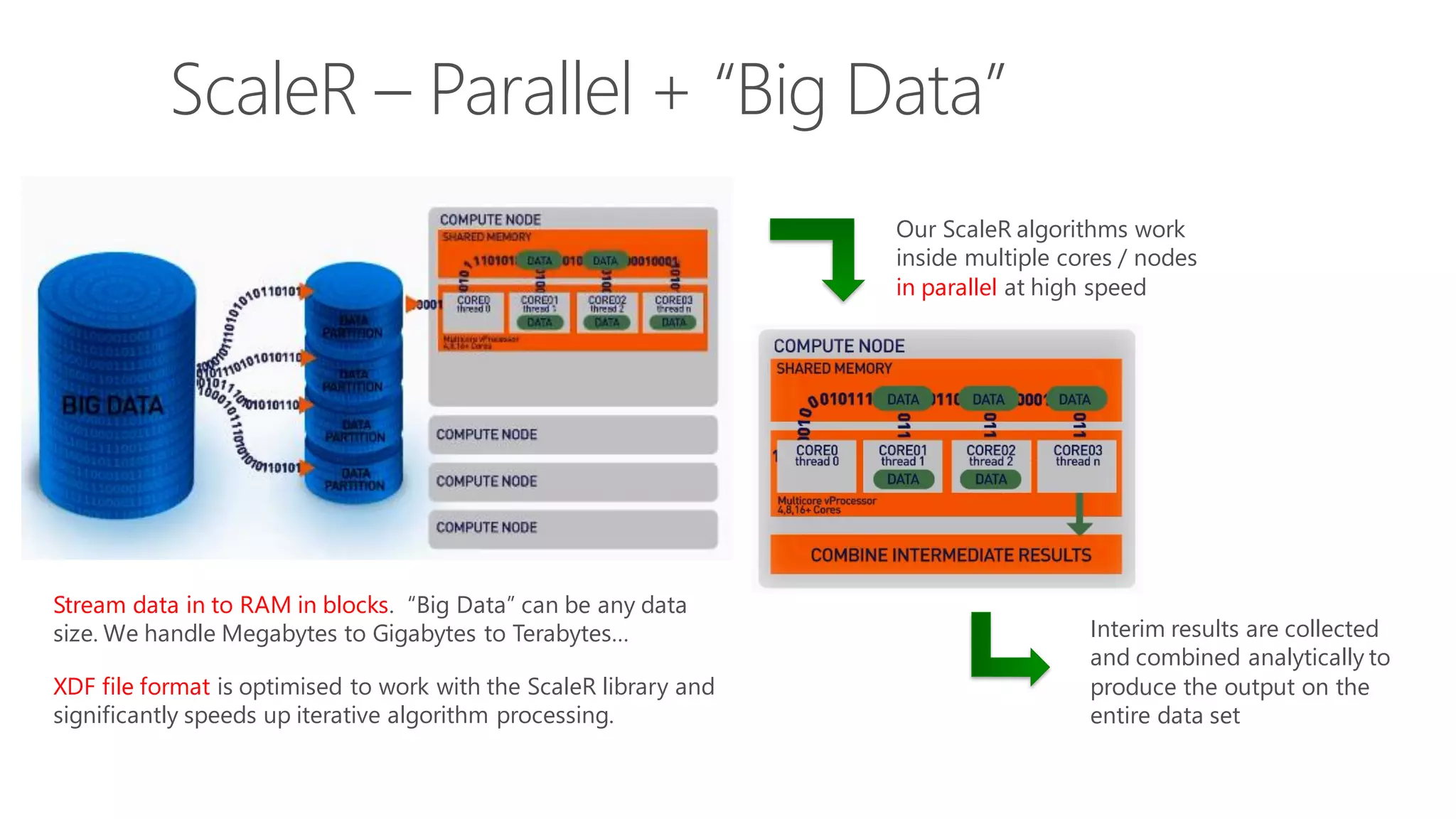




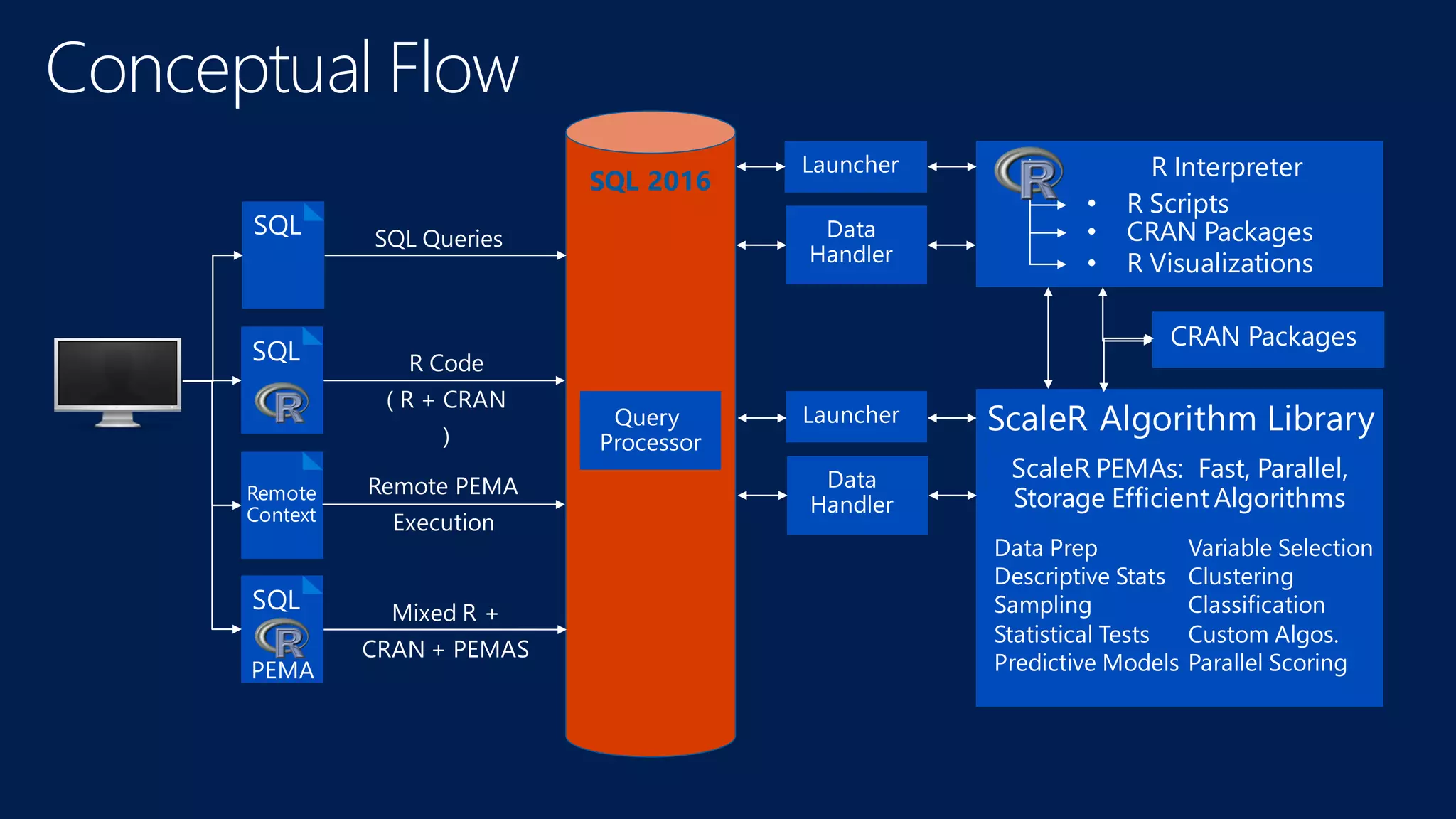
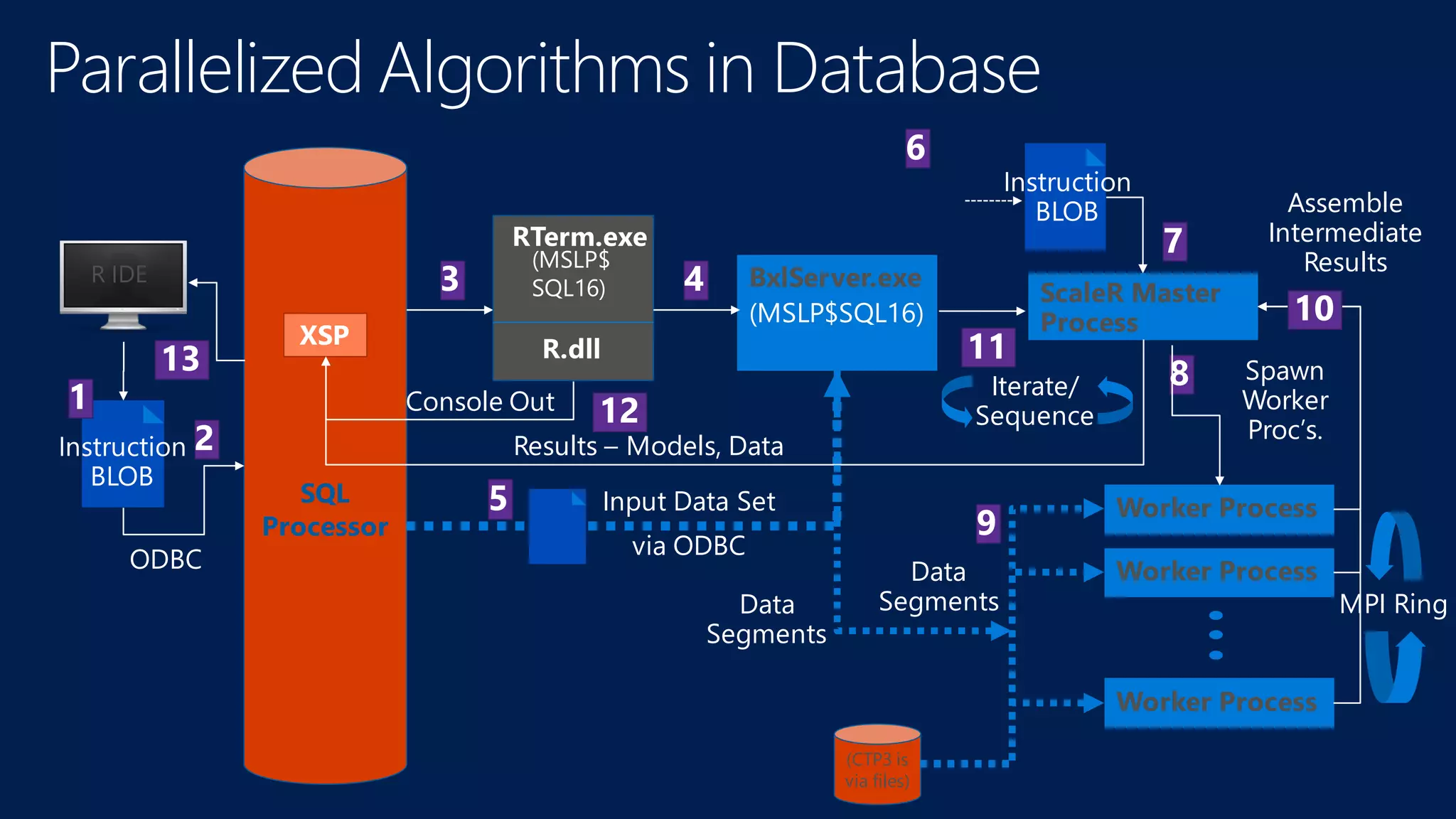



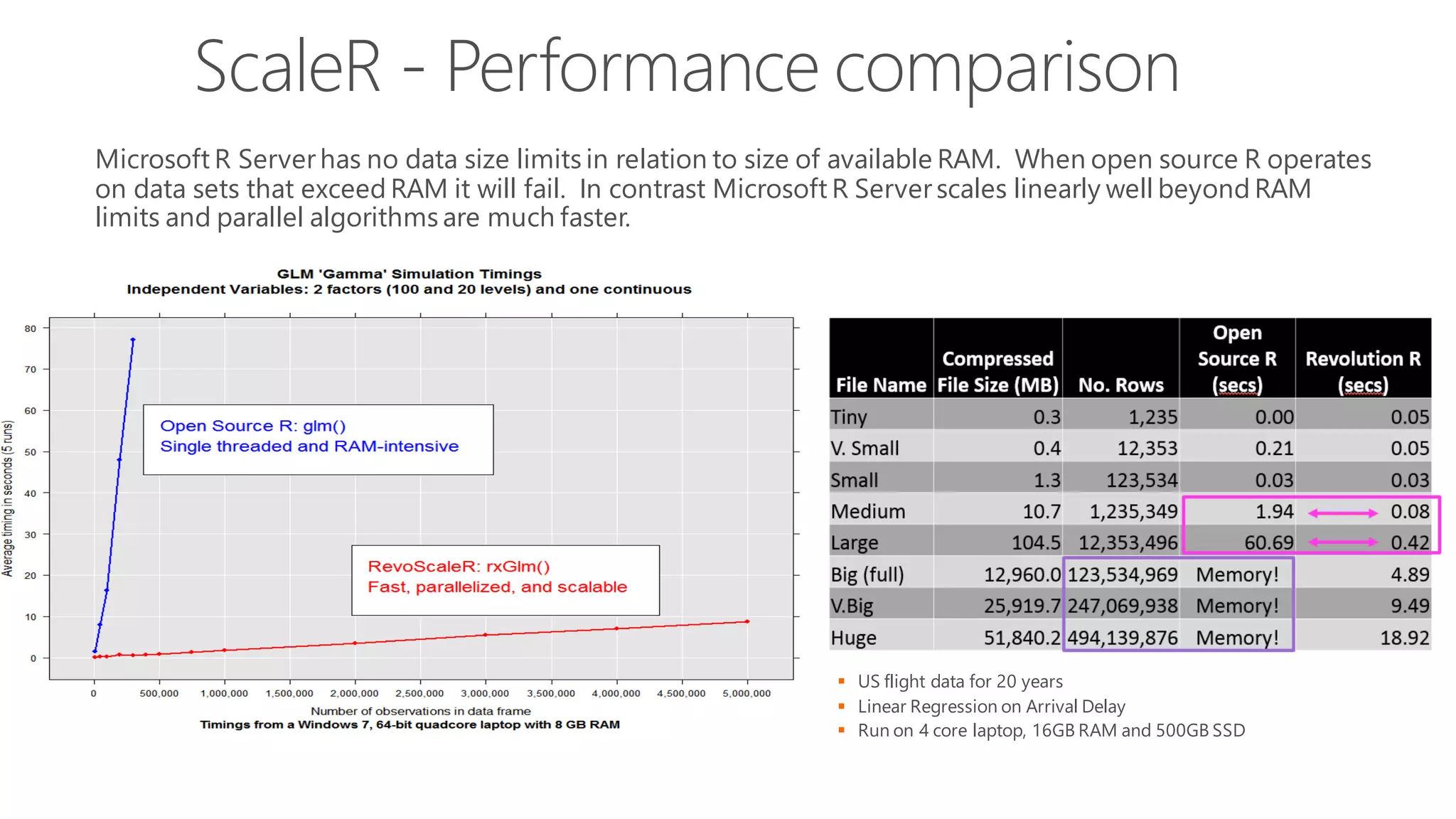
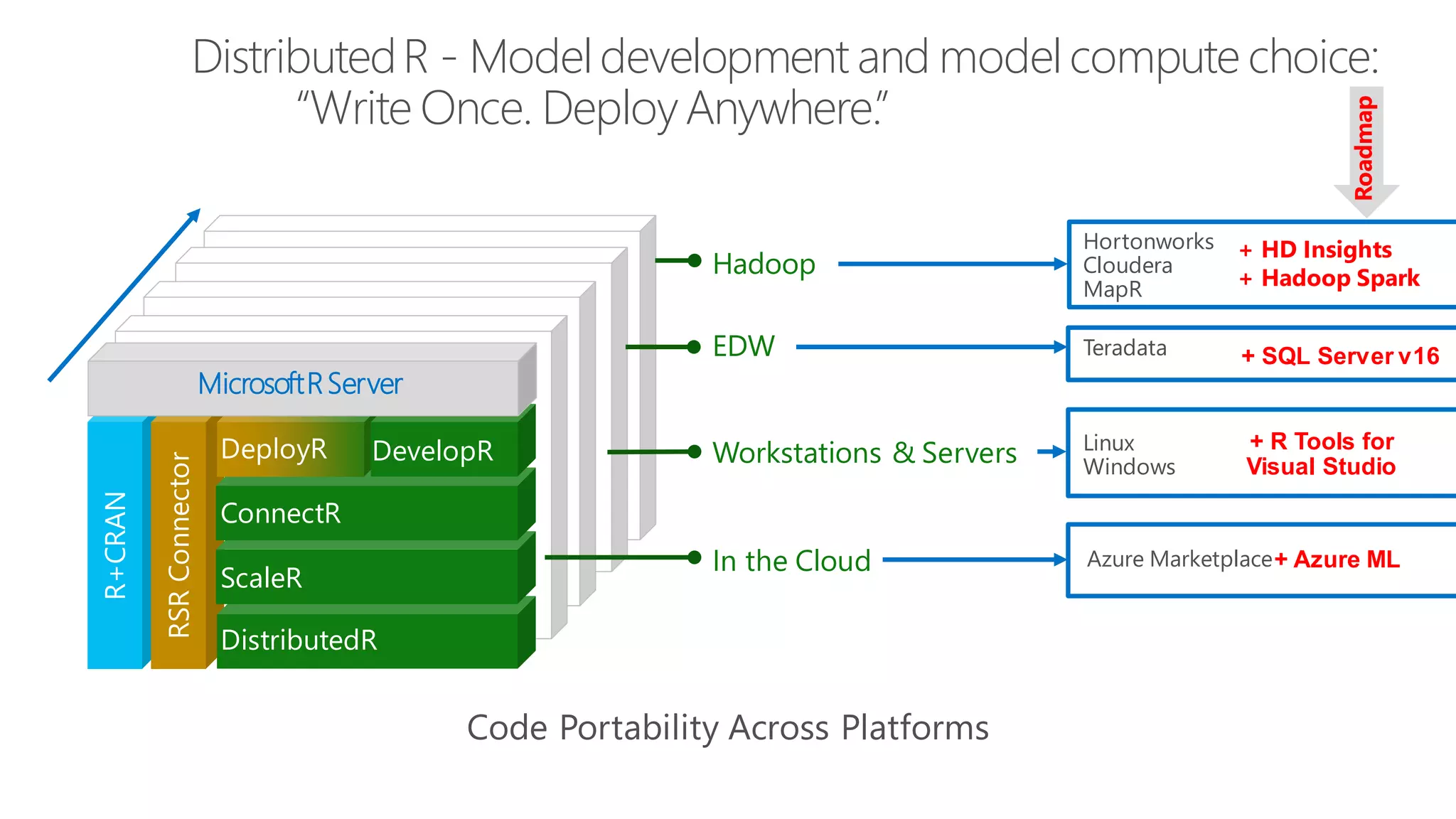
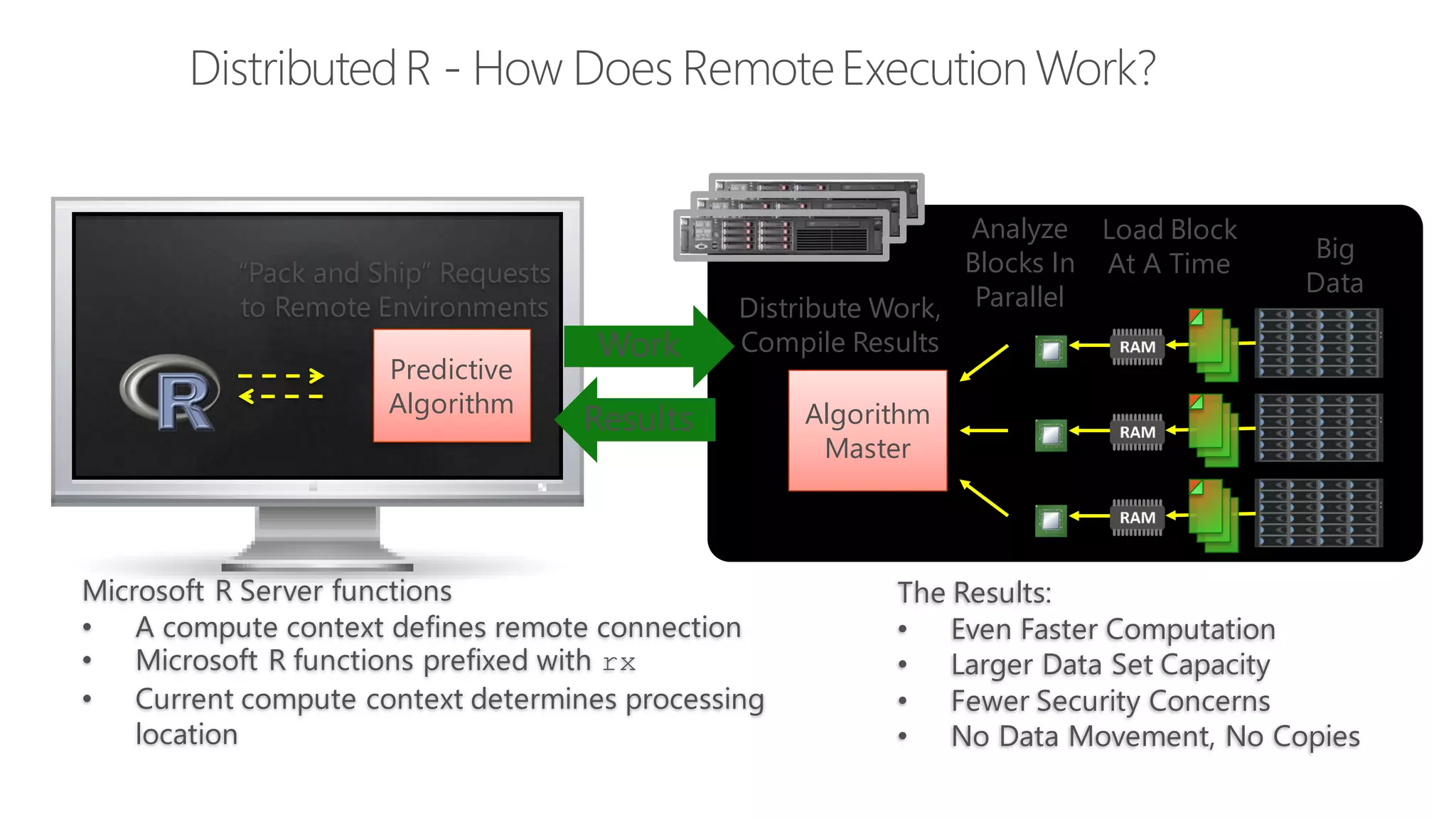
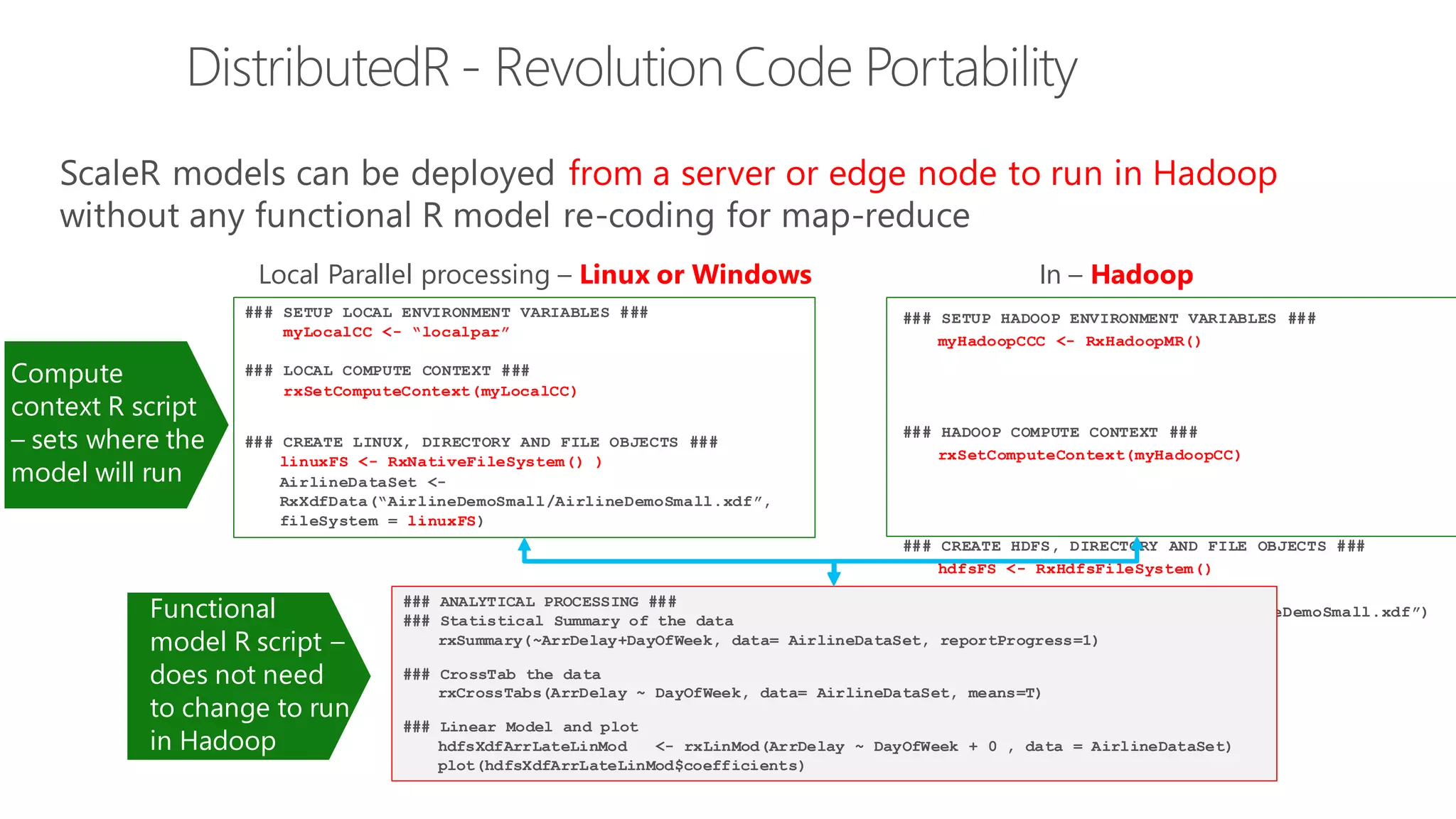
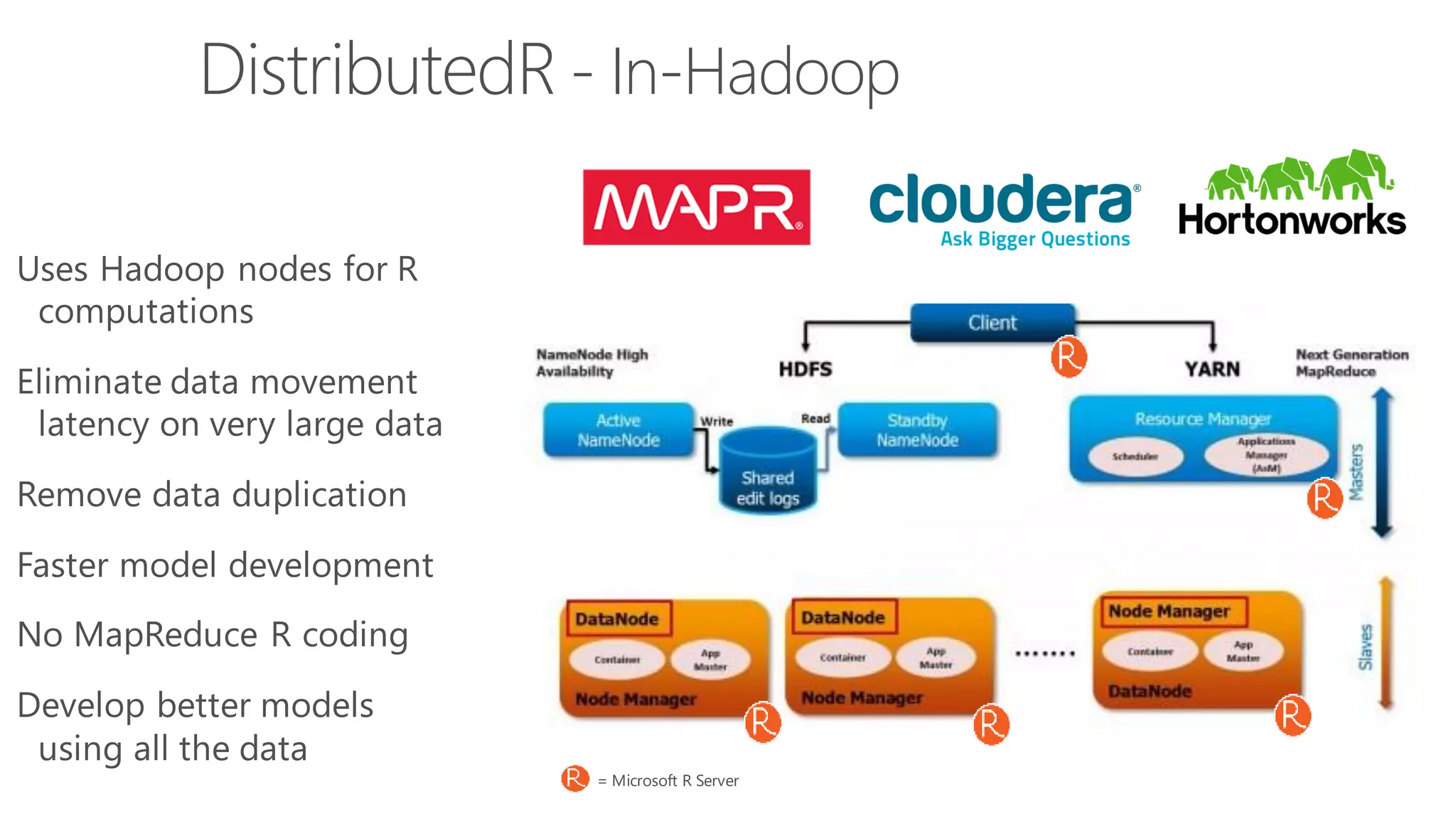
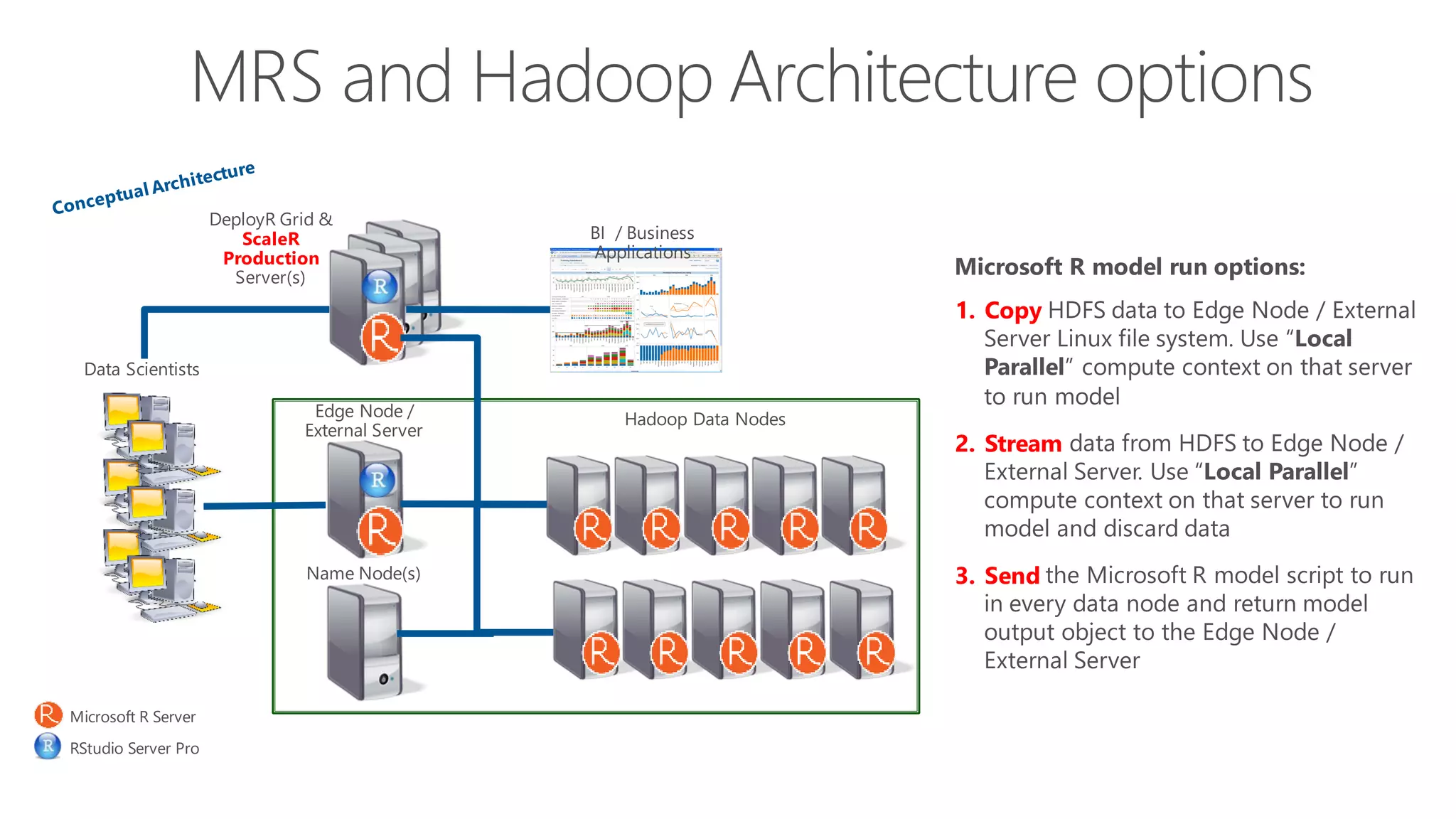
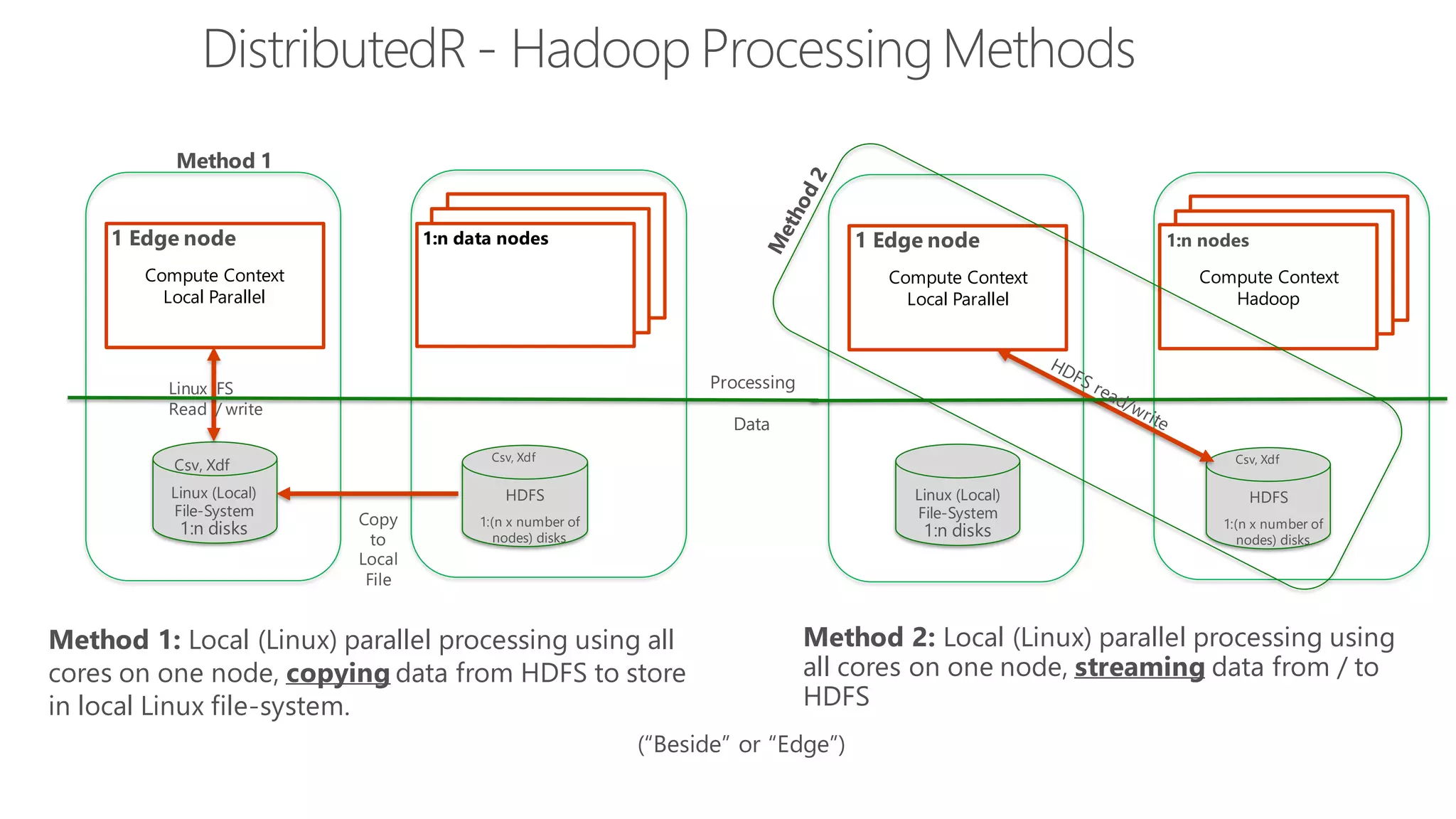
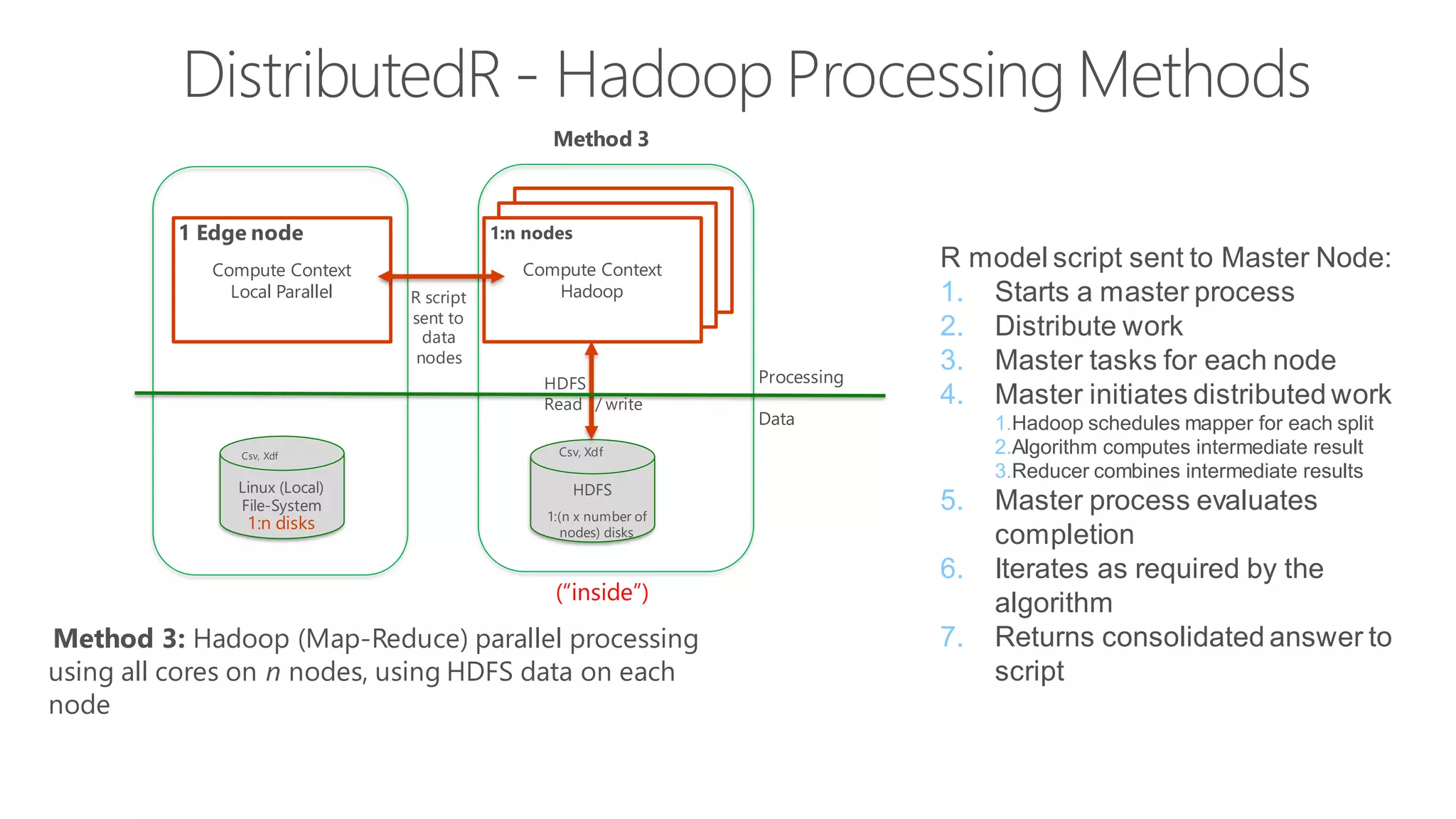
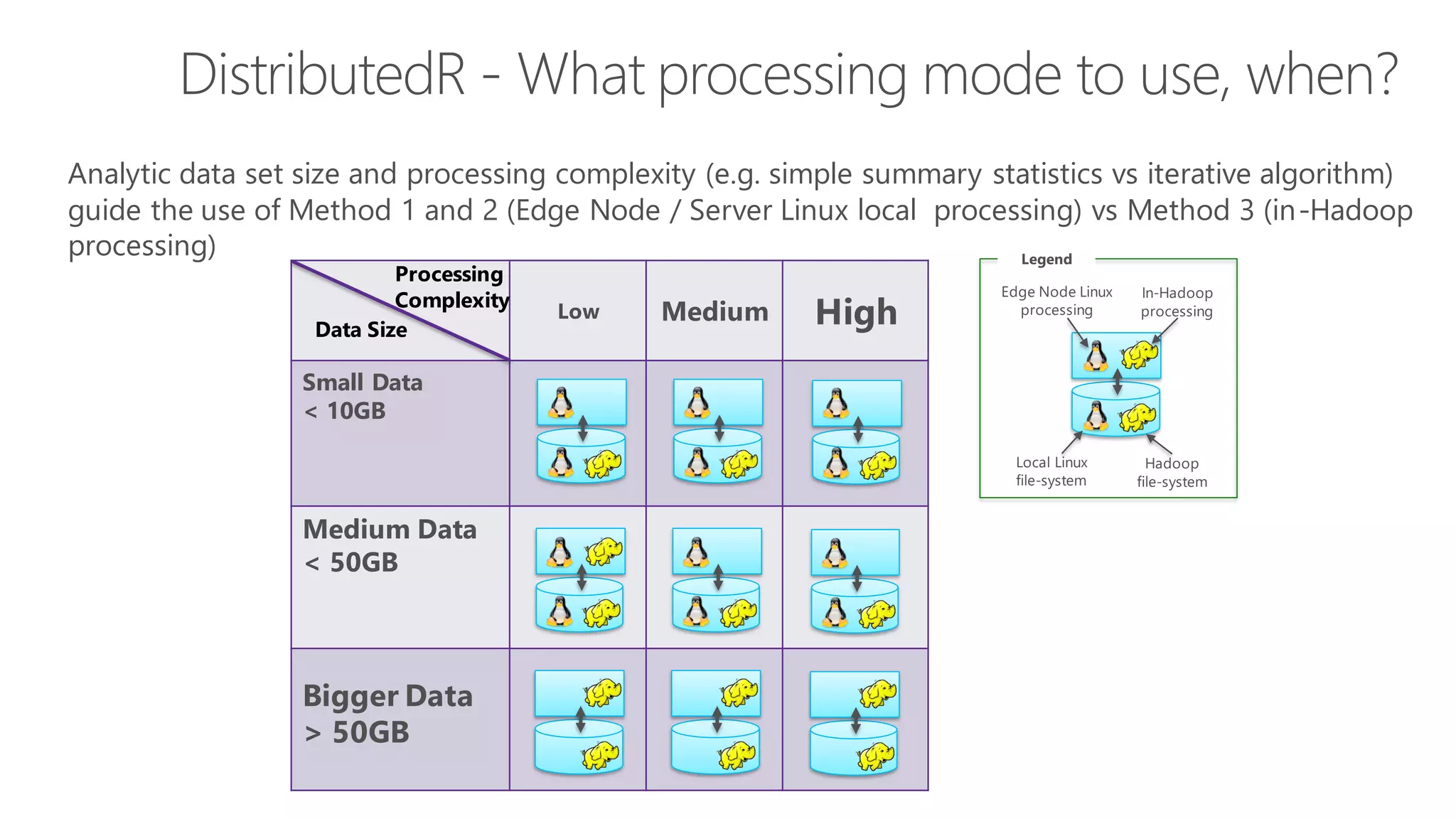



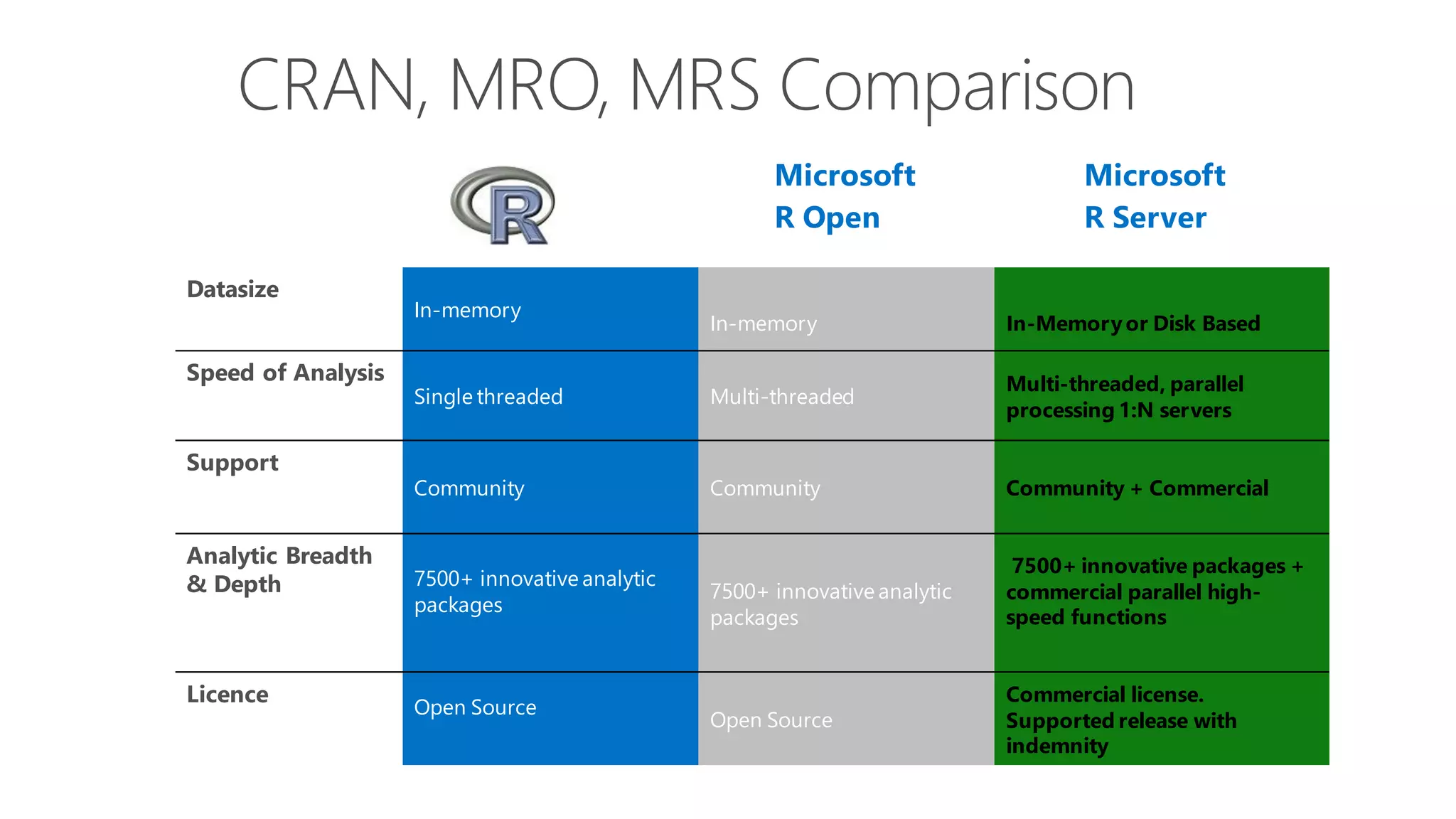

The document introduces Microsoft R Server and Microsoft R Open. It discusses that R is a popular open source programming language and platform for statistics, analytics, and data science. Microsoft R Server allows for distributed computing on big data using R and brings enterprise-grade support and capabilities to the open source R platform. It can perform analytics both in-database using SQL Server and in Hadoop environments without moving data.