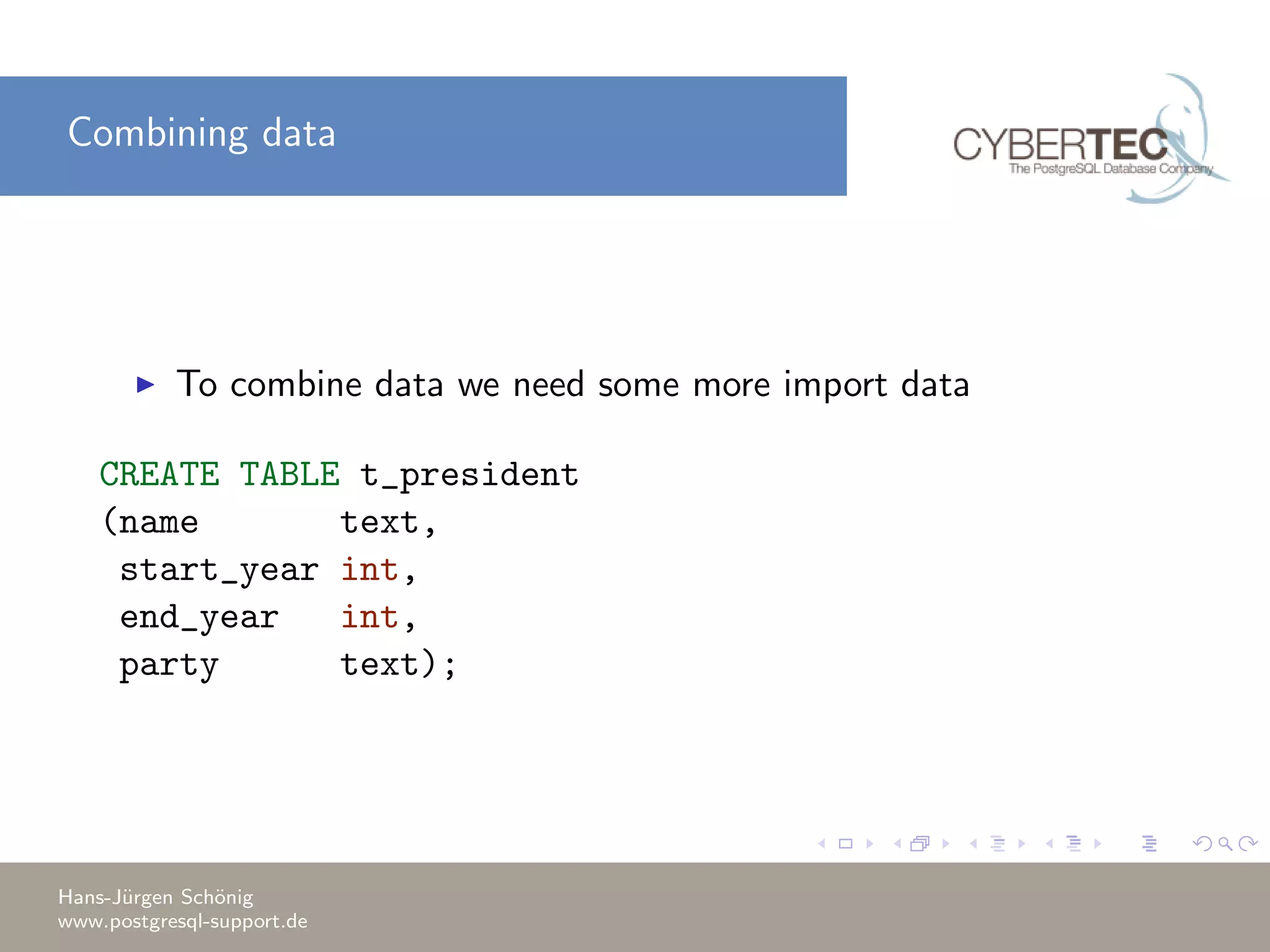
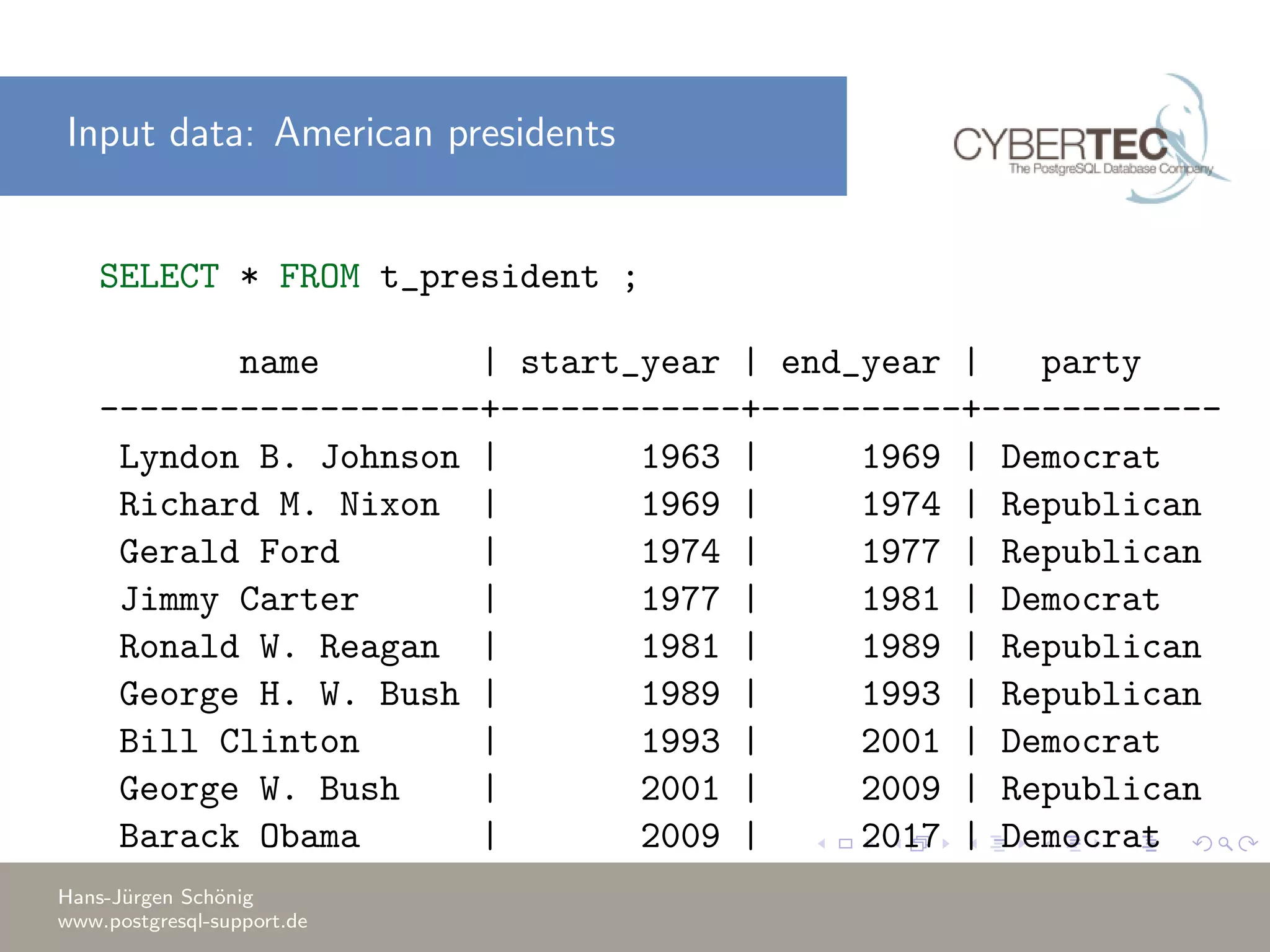
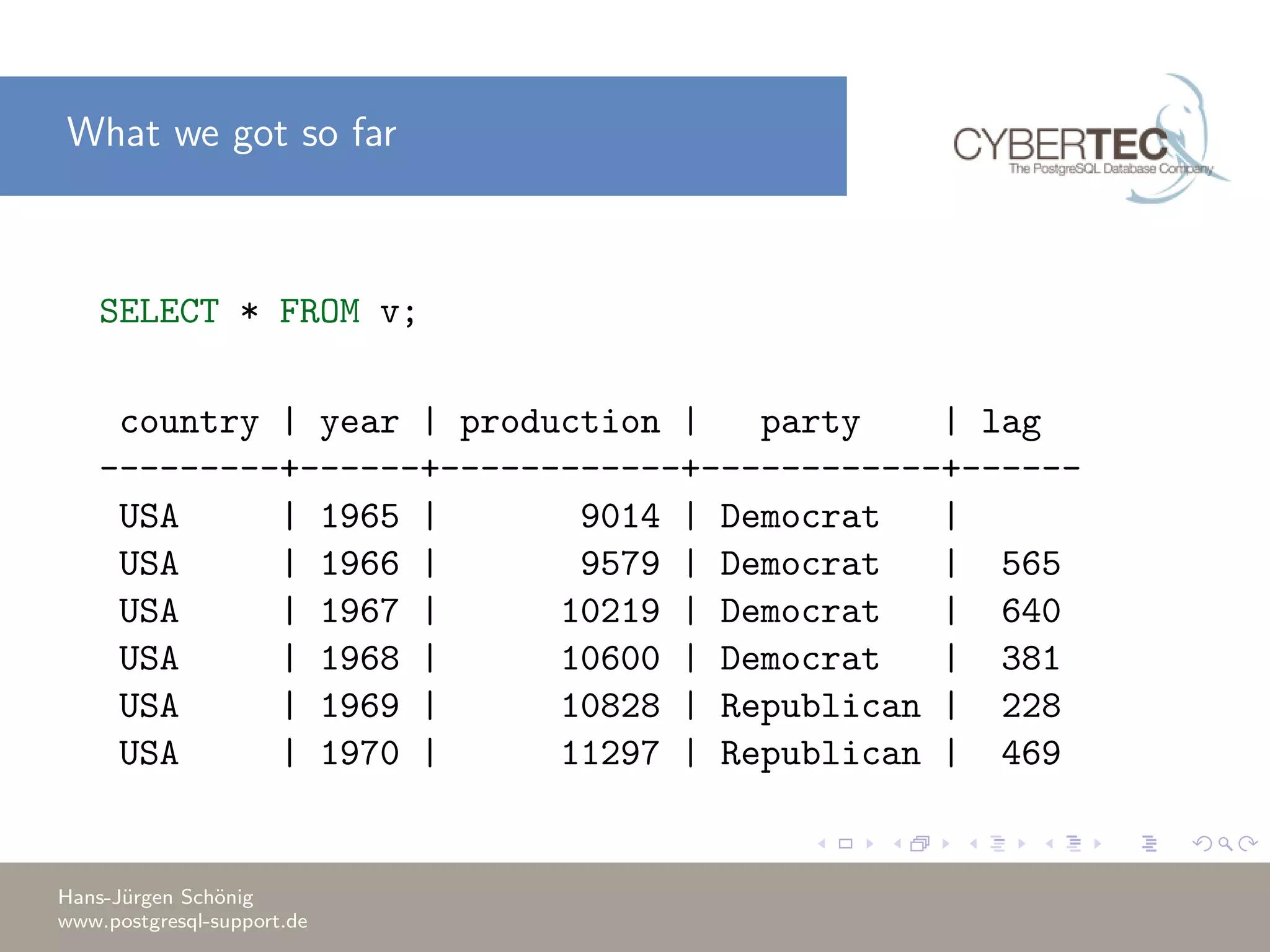
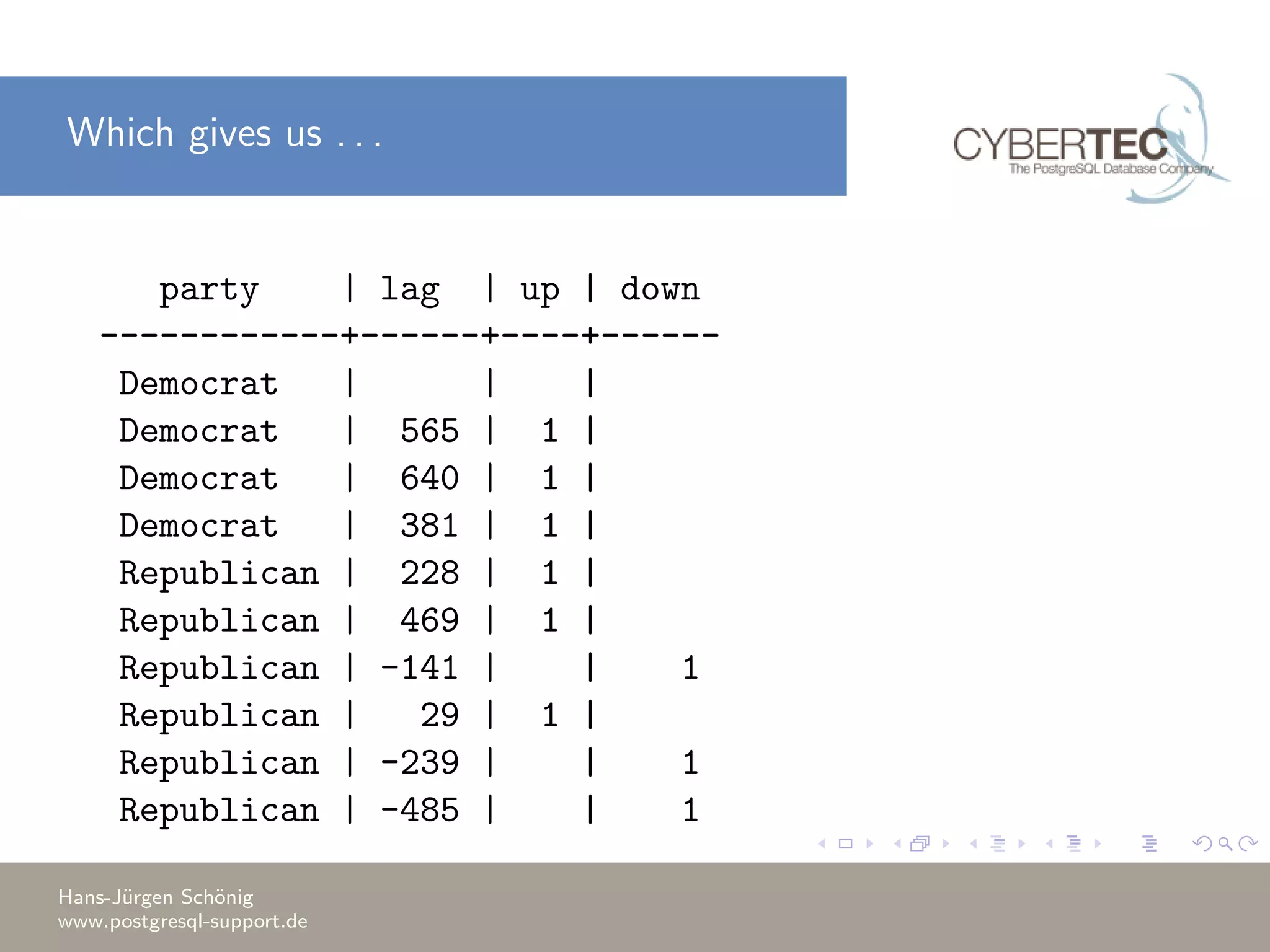
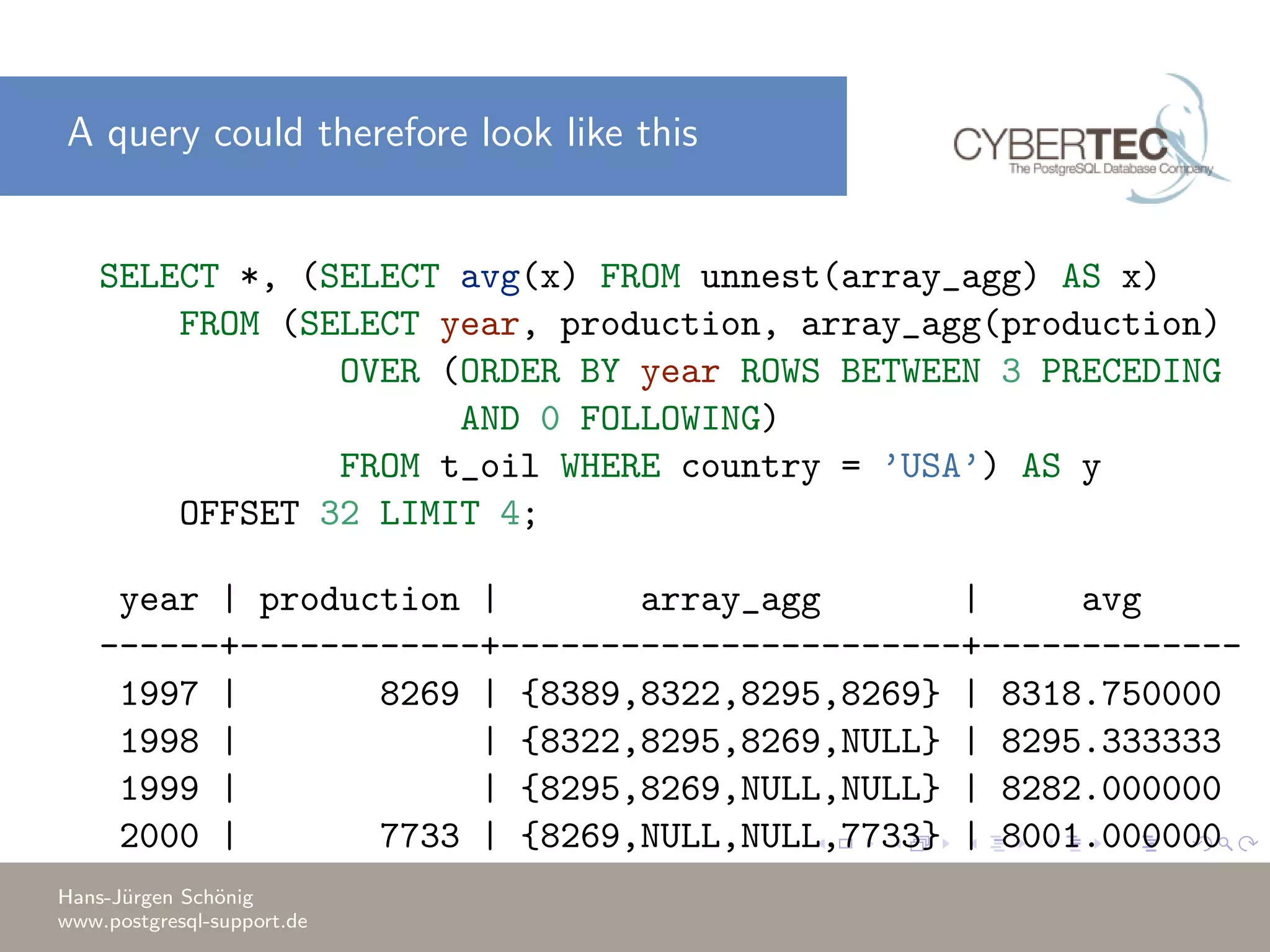
This document covers a training session on data analysis using PostgreSQL, focusing on importing data, performing aggregations, and utilizing window functions. It highlights best practices for data import performance, including the use of bulk loads and transactions, as well as advanced analytics techniques like windowing and ranking. Additionally, the document includes examples of SQL queries for data manipulation and analysis to support complex tasks.
























































![Applying a function A simple function could look like this: SELECT avg(x) FROM unnest(’{8295,8269,NULL,NULL}’::int4[]) AS x; avg ----------------------- 8282.0000000000000000 (1 row) Hans-J¨urgen Sch¨onig www.postgresql-support.de](https://image.slidesharecdn.com/dataanalysis-150313062033-conversion-gate01/75/PostgreSQL-Data-analysis-and-analytics-65-2048.jpg)

![A simple example the aggregate can be created like this: CREATE FUNCTION my_final(int[]) RETURNS numeric AS $$ SELECT avg(x) FROM unnest($1) AS x; $$ LANGUAGE sql; CREATE AGGREGATE artificial_avg(int) ( SFUNC = array_append, STYPE = int[], INITCOND = ’{}’, FINALFUNC = my_final ); Hans-J¨urgen Sch¨onig www.postgresql-support.de](https://image.slidesharecdn.com/dataanalysis-150313062033-conversion-gate01/75/PostgreSQL-Data-analysis-and-analytics-68-2048.jpg)


