Downloaded 145 times




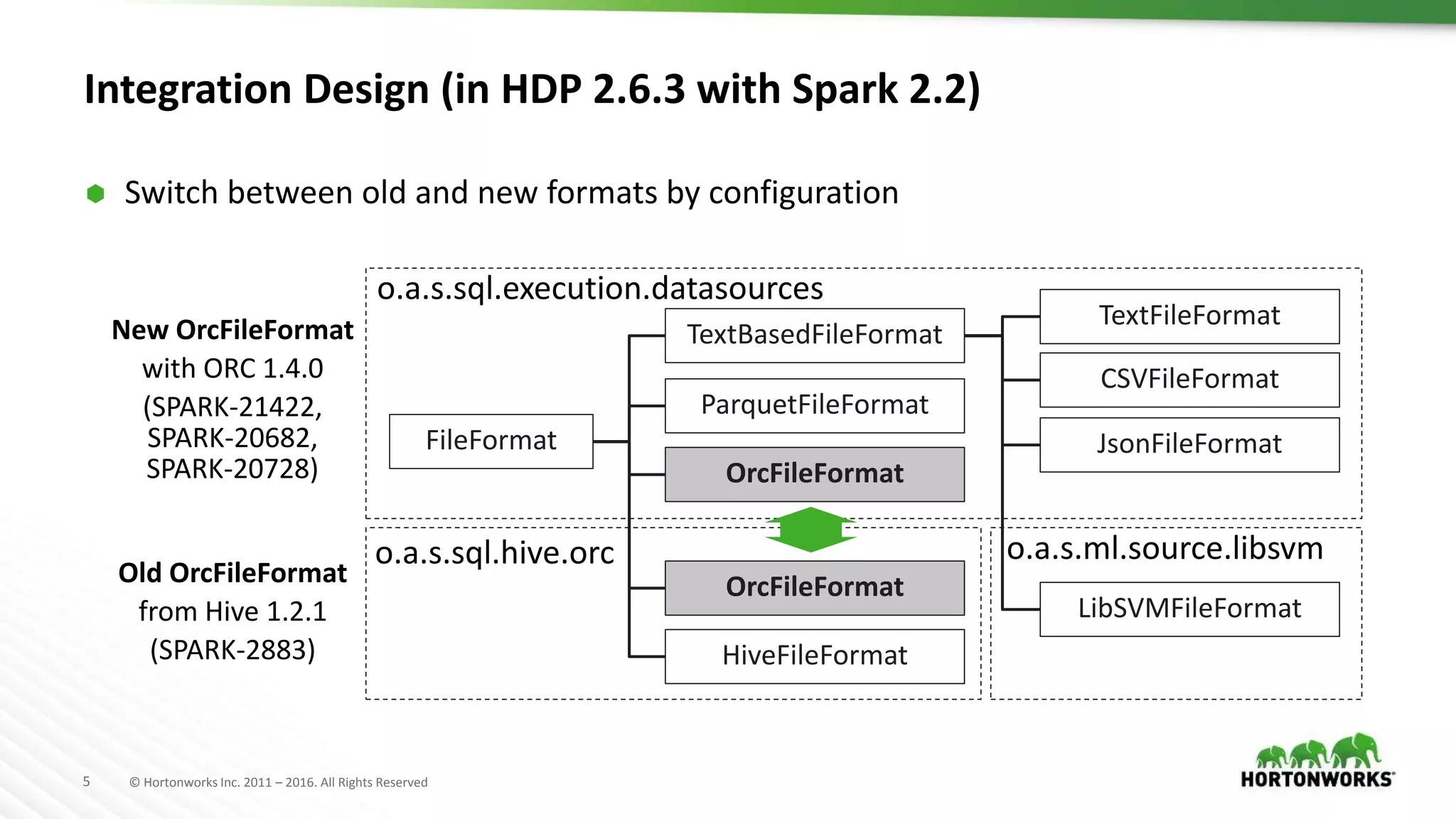

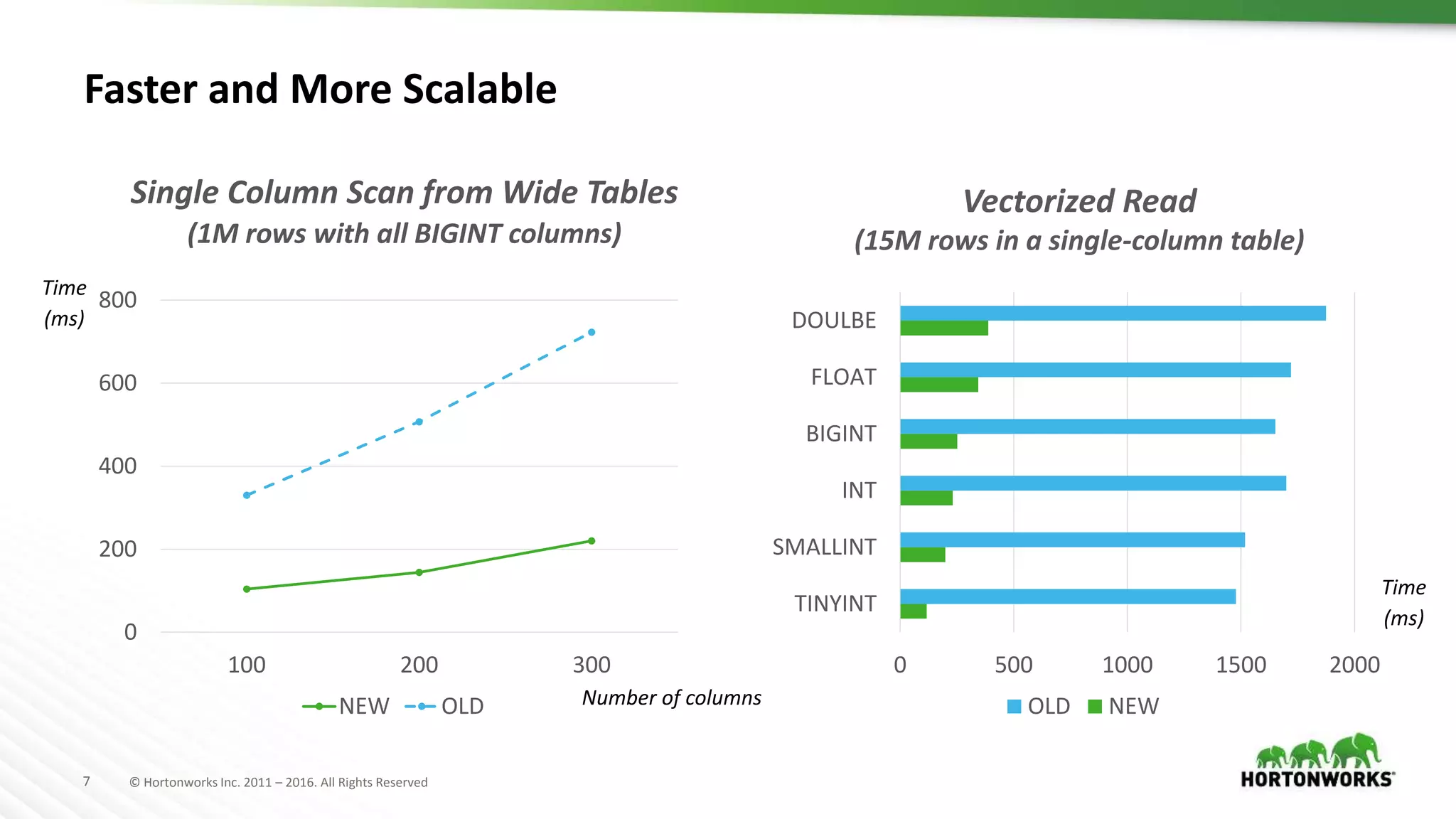








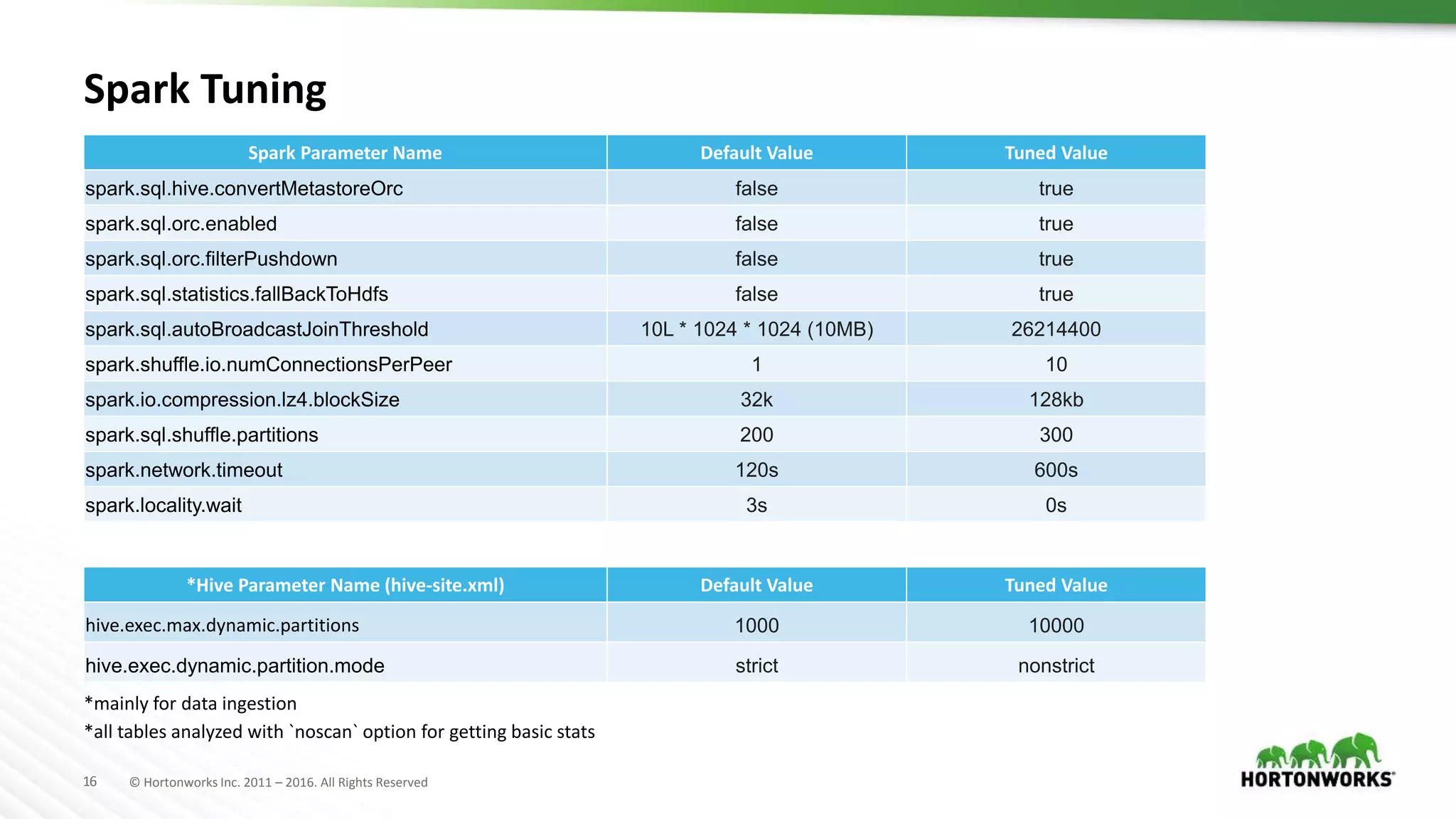

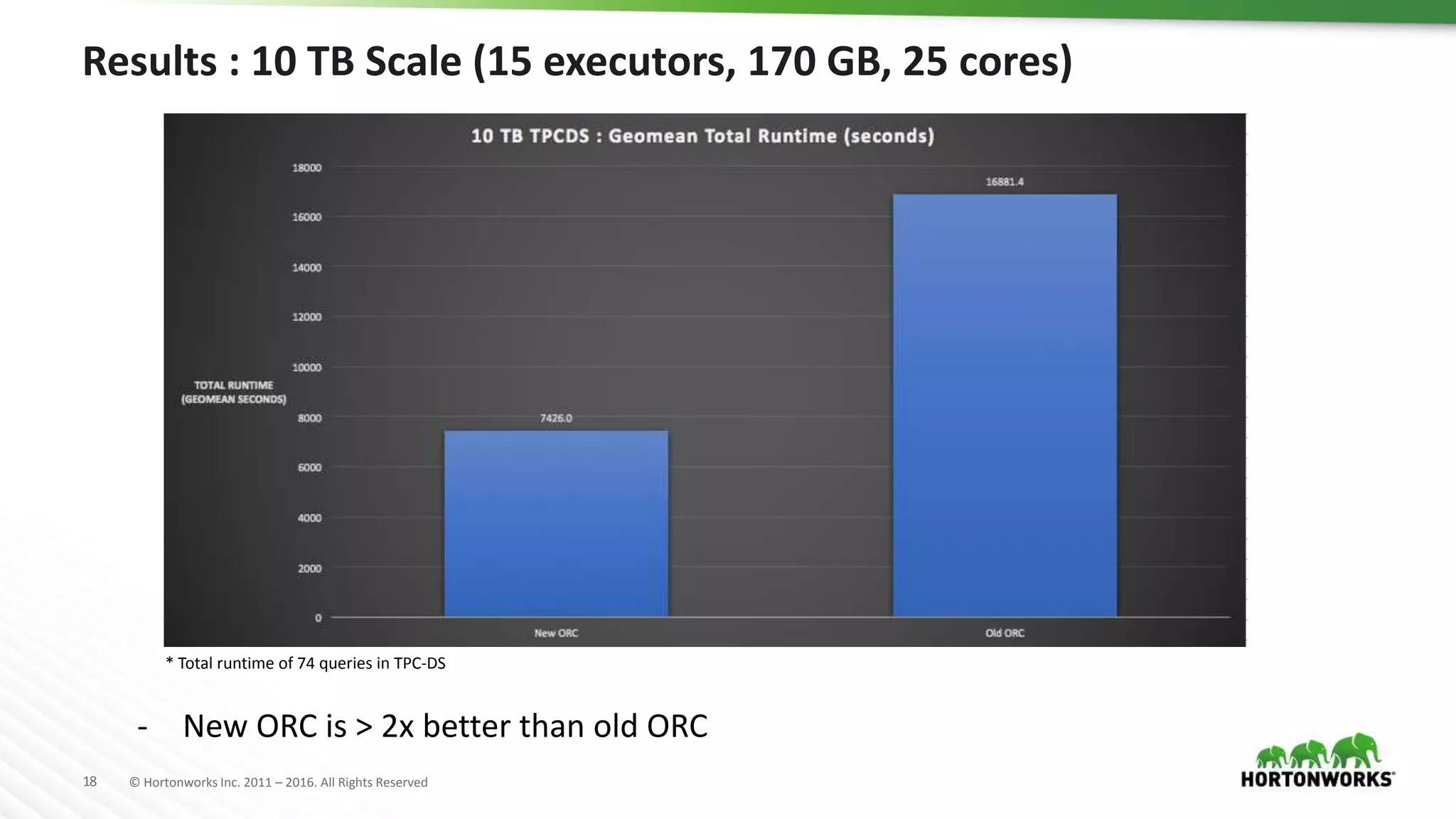
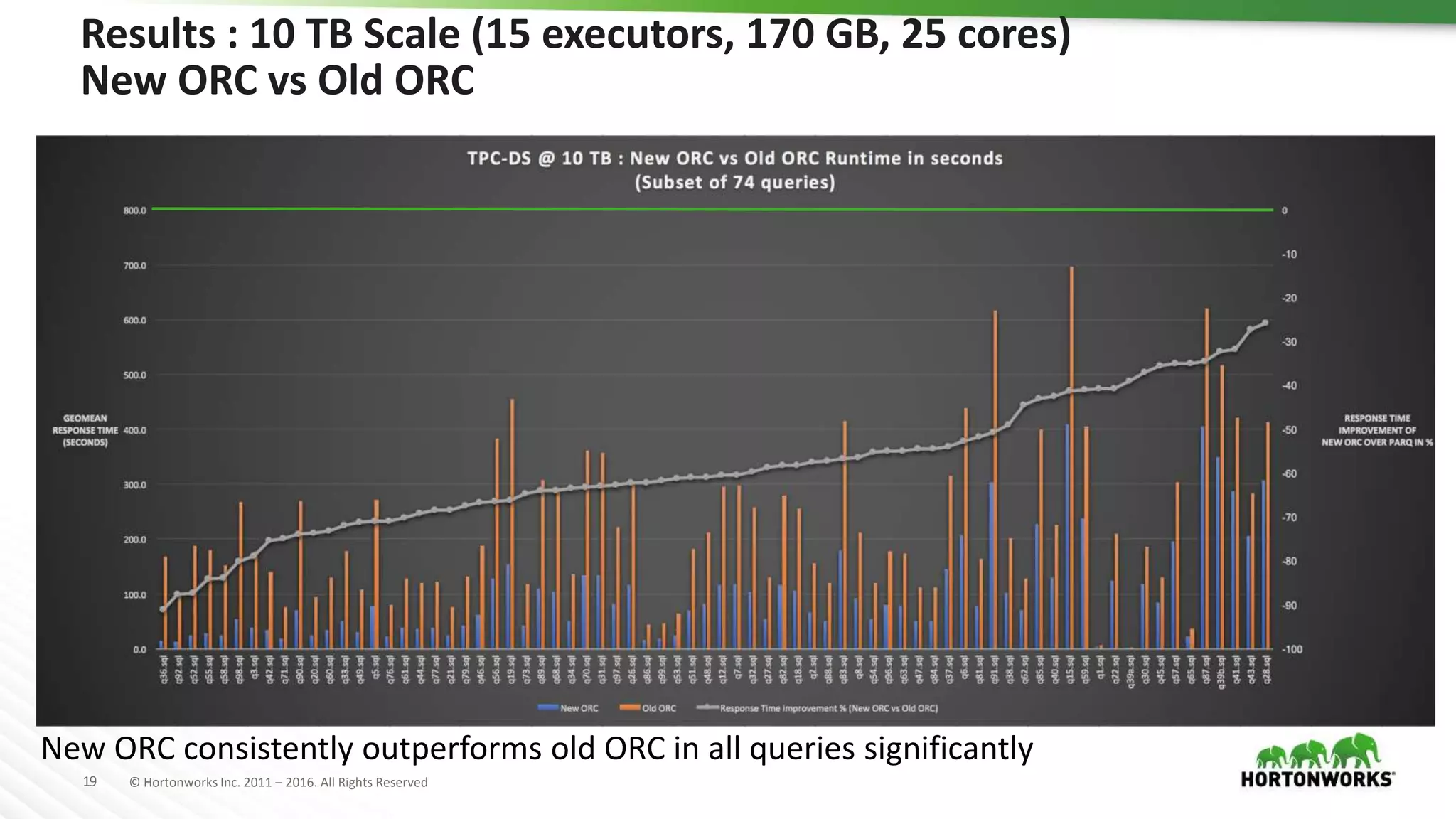
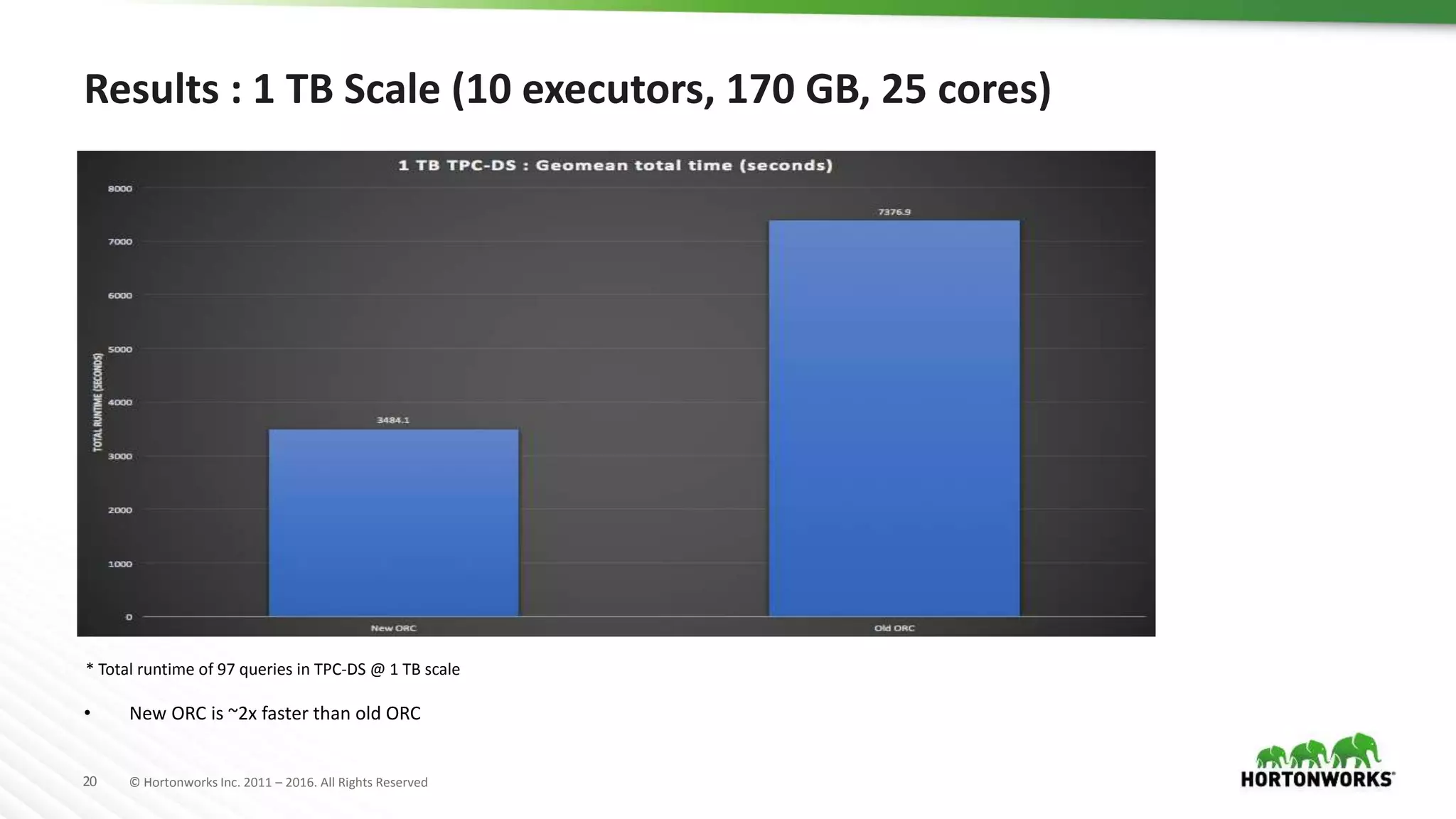
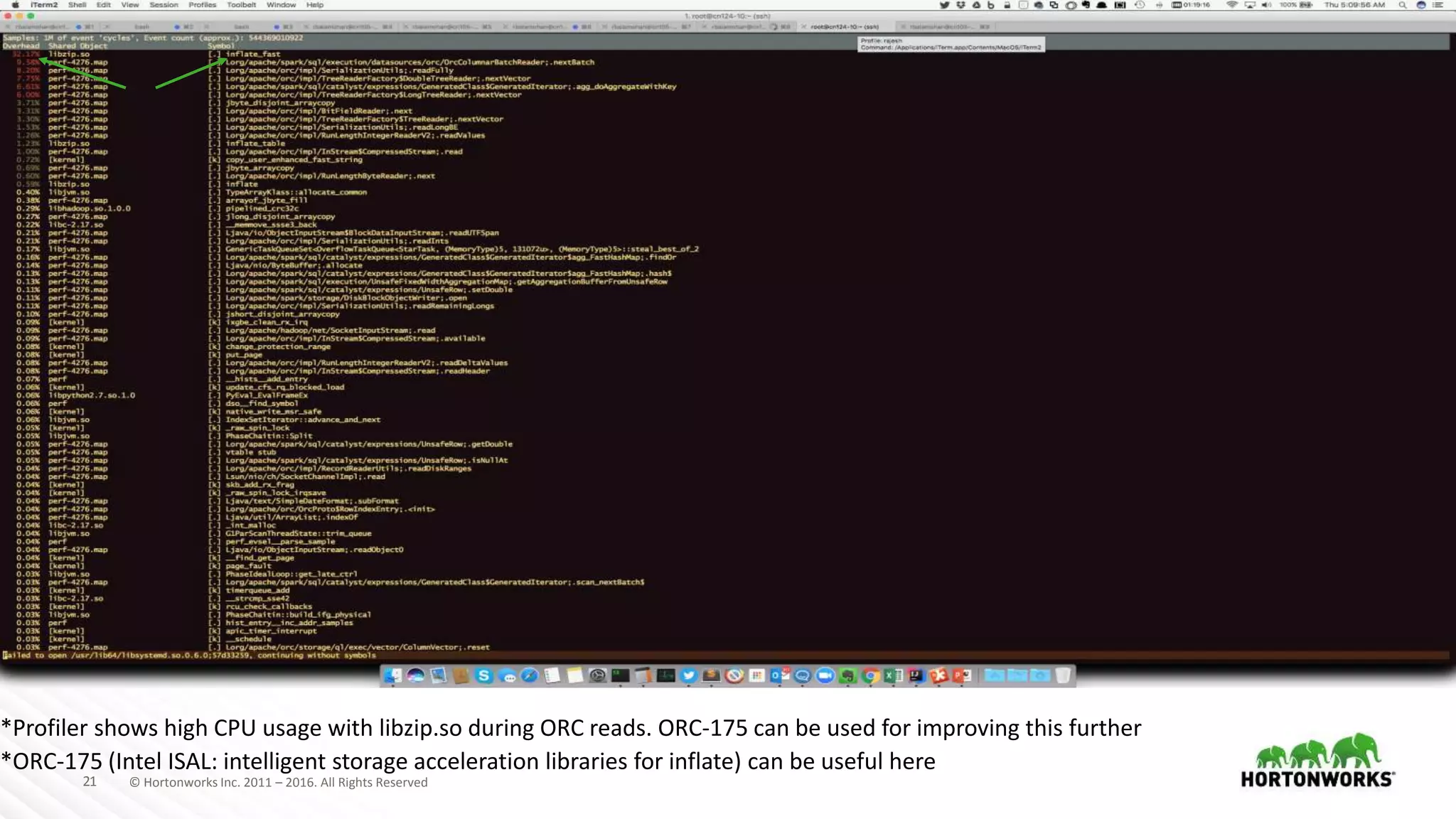
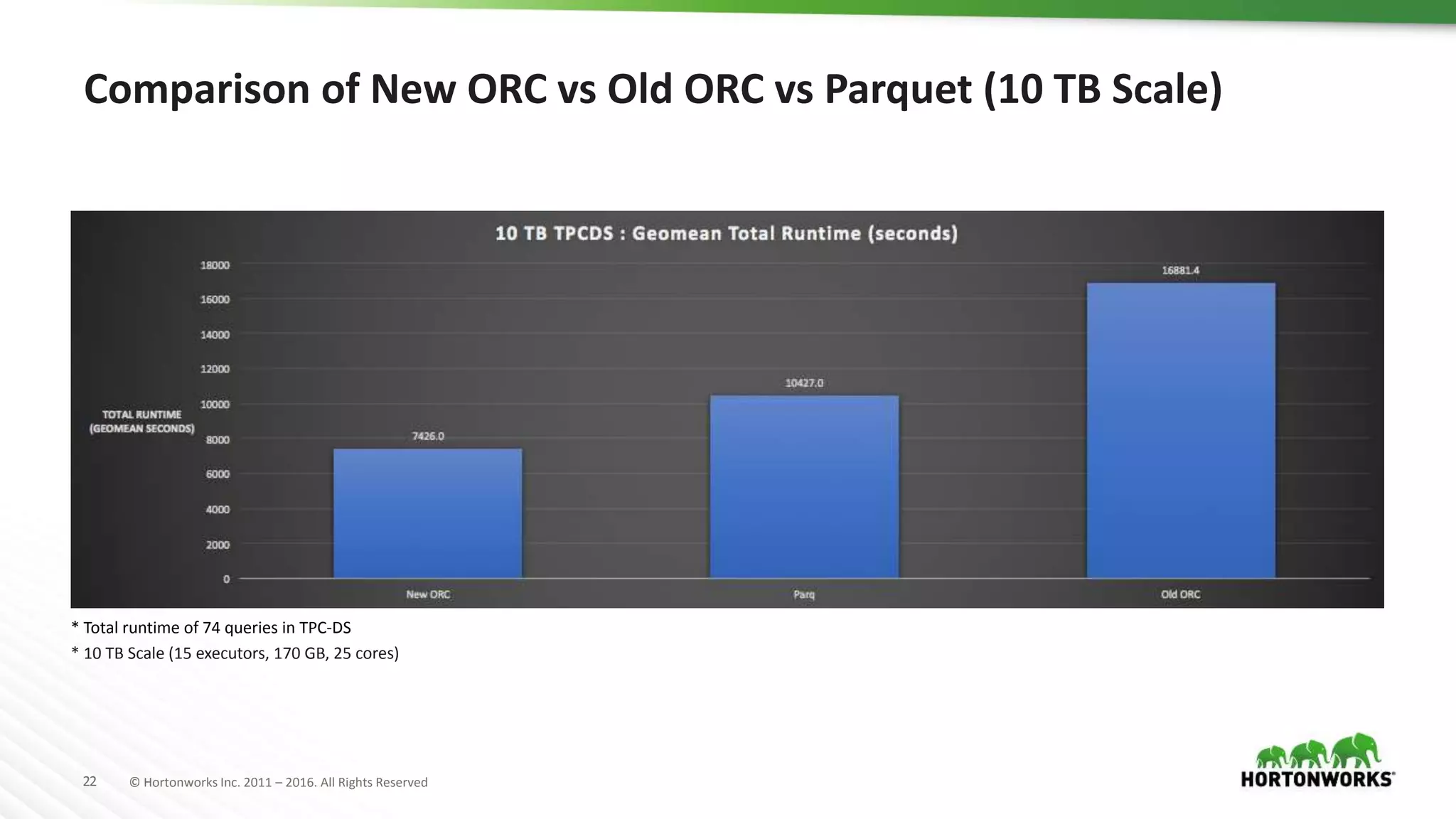



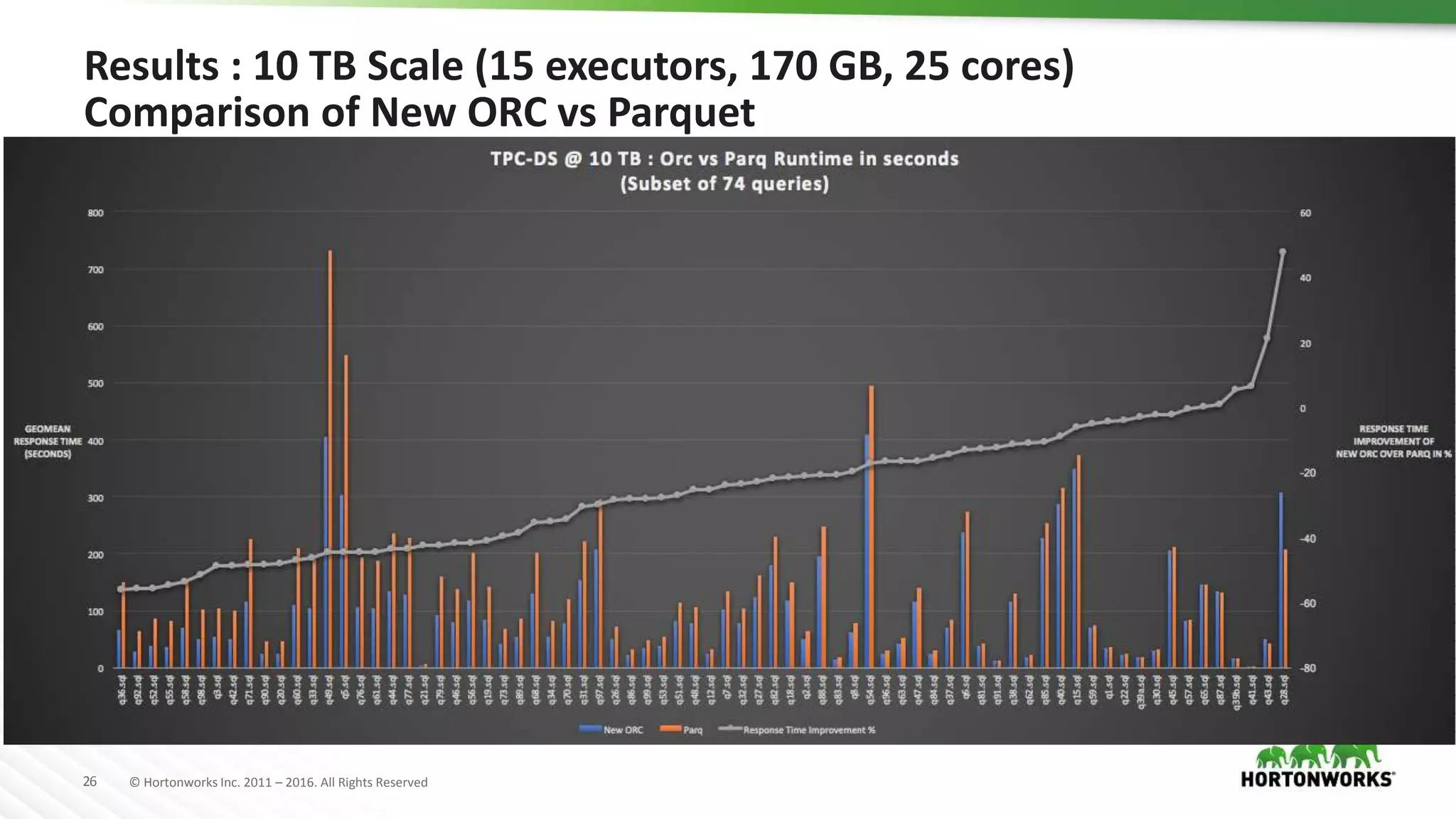

The document provides a performance update on the integration of Apache ORC (version 1.4) with Apache Spark, highlighting the advantages such as speed, stability, and usability improvements. Benchmark tests show that the new ORC format outperforms the old ORC format by over 2x at a 10 TB scale in multiple queries. It outlines ongoing developments and future enhancements aimed at optimizing performance and user experience.