Download as PDF, PPTX
















MLeap is a framework designed to streamline the deployment of machine learning models from research to production, focusing on serialization and execution efficiency, especially outside the JVM. It allows users to train models in Spark, serialize them into MLeap bundles, and execute them via a REST API with minimal code changes. Future developments include expanding support for other ML frameworks and improving performance benchmarks.
MLeap facilitates scaling machine learning from research to production. The presentation outlines its parts: introduction to MLeap, future roadmap, and a demo.
MLeap addresses issues such as lengthy production times for Spark models. Original requirements focused on eliminating re-coding and optimizing performance.
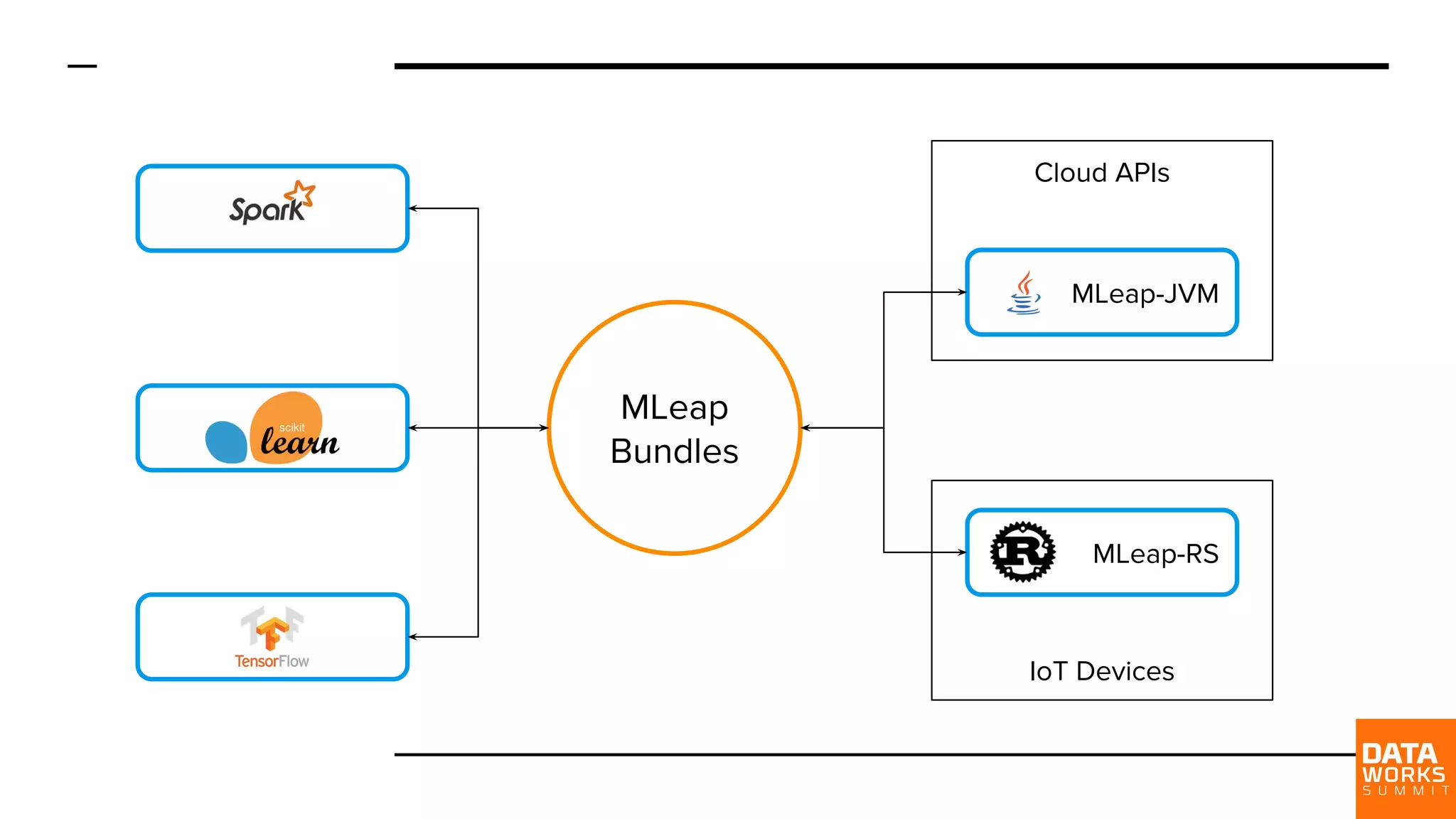
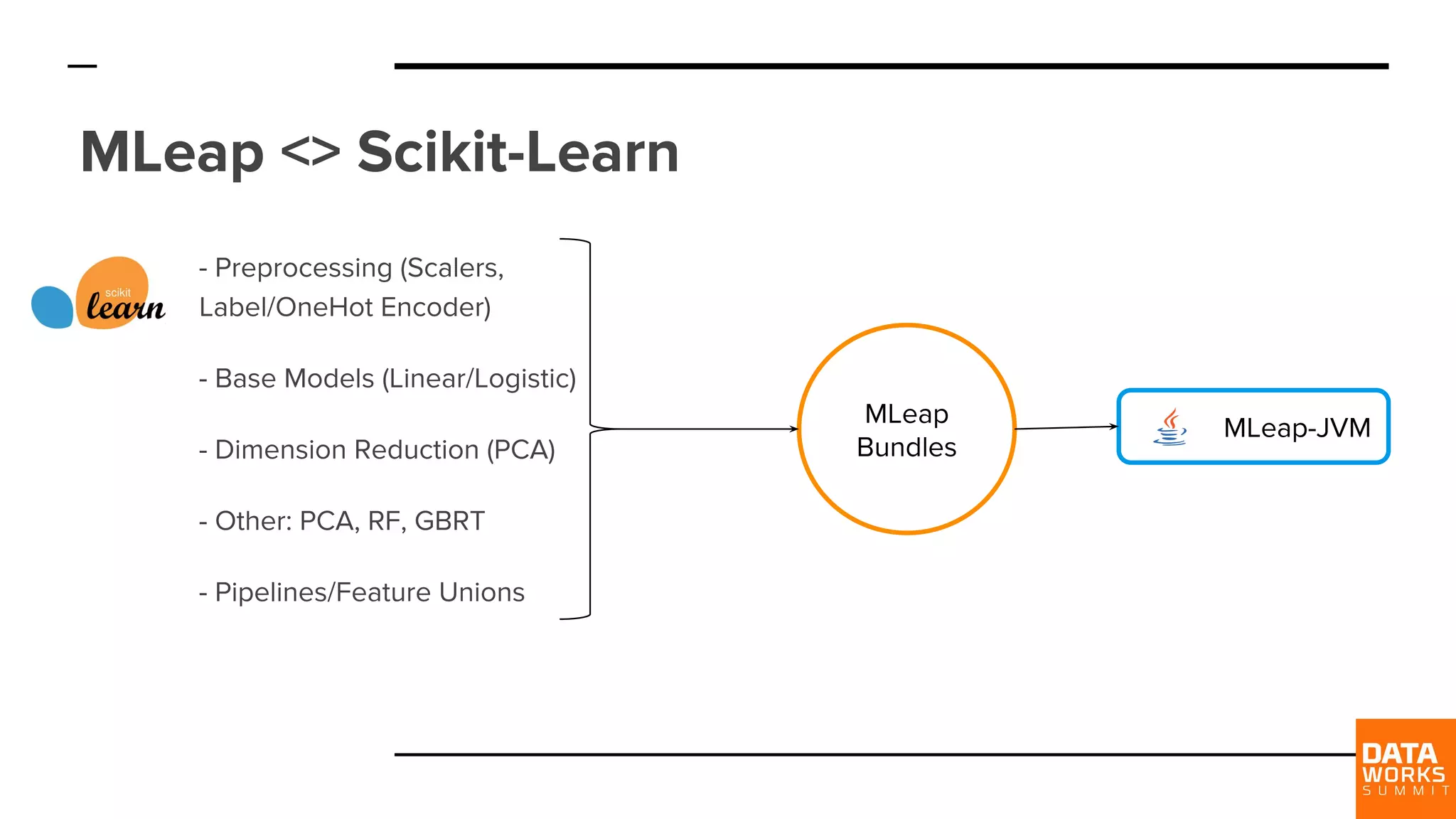
New requirements emphasize executing inference outside JVM and compatibility with other ML frameworks like Scikit-Learn and TensorFlow.
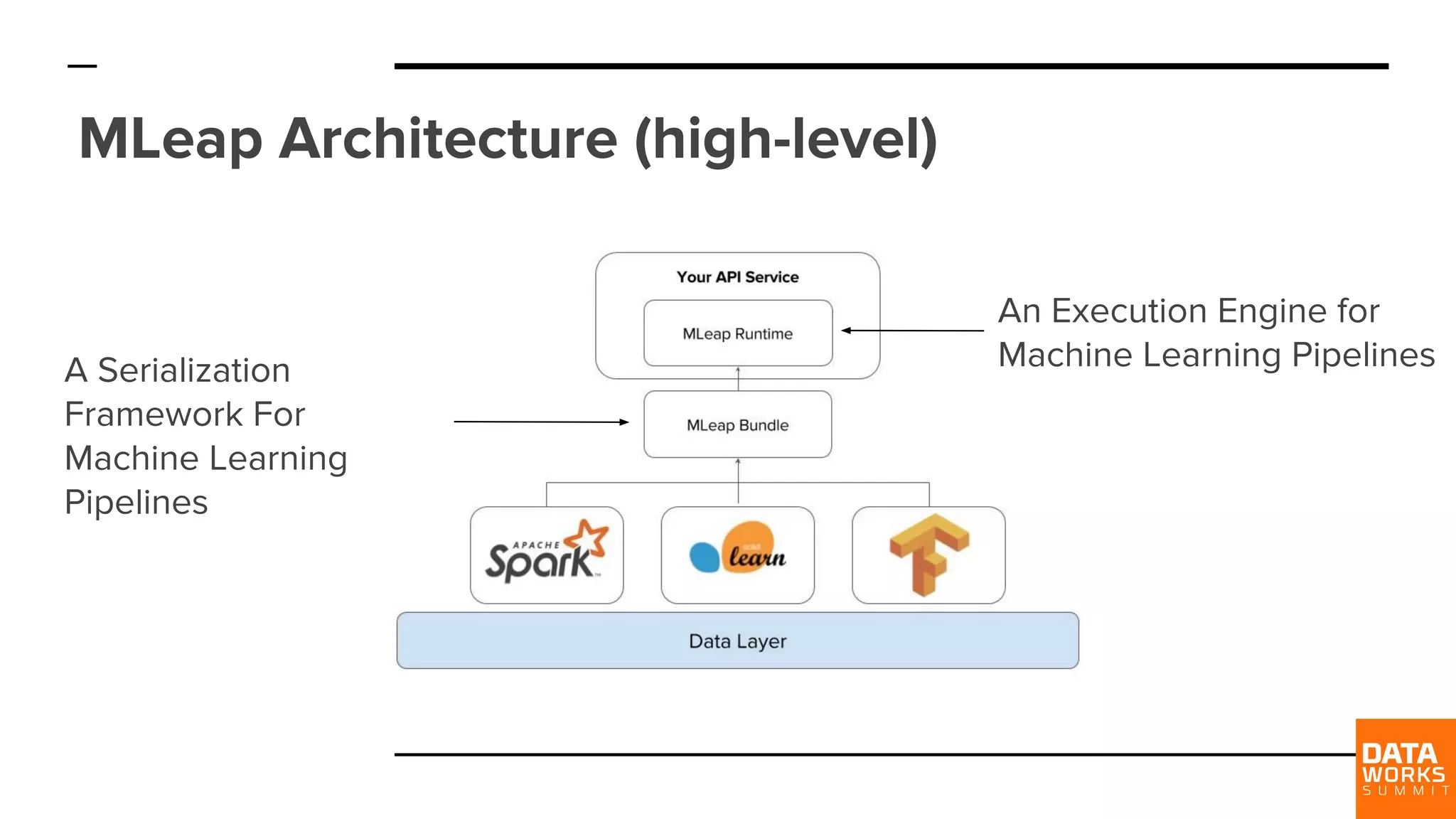
MLeap consists of a serialization framework and an execution engine for machine learning pipelines, facilitating smooth transitions from research to production.
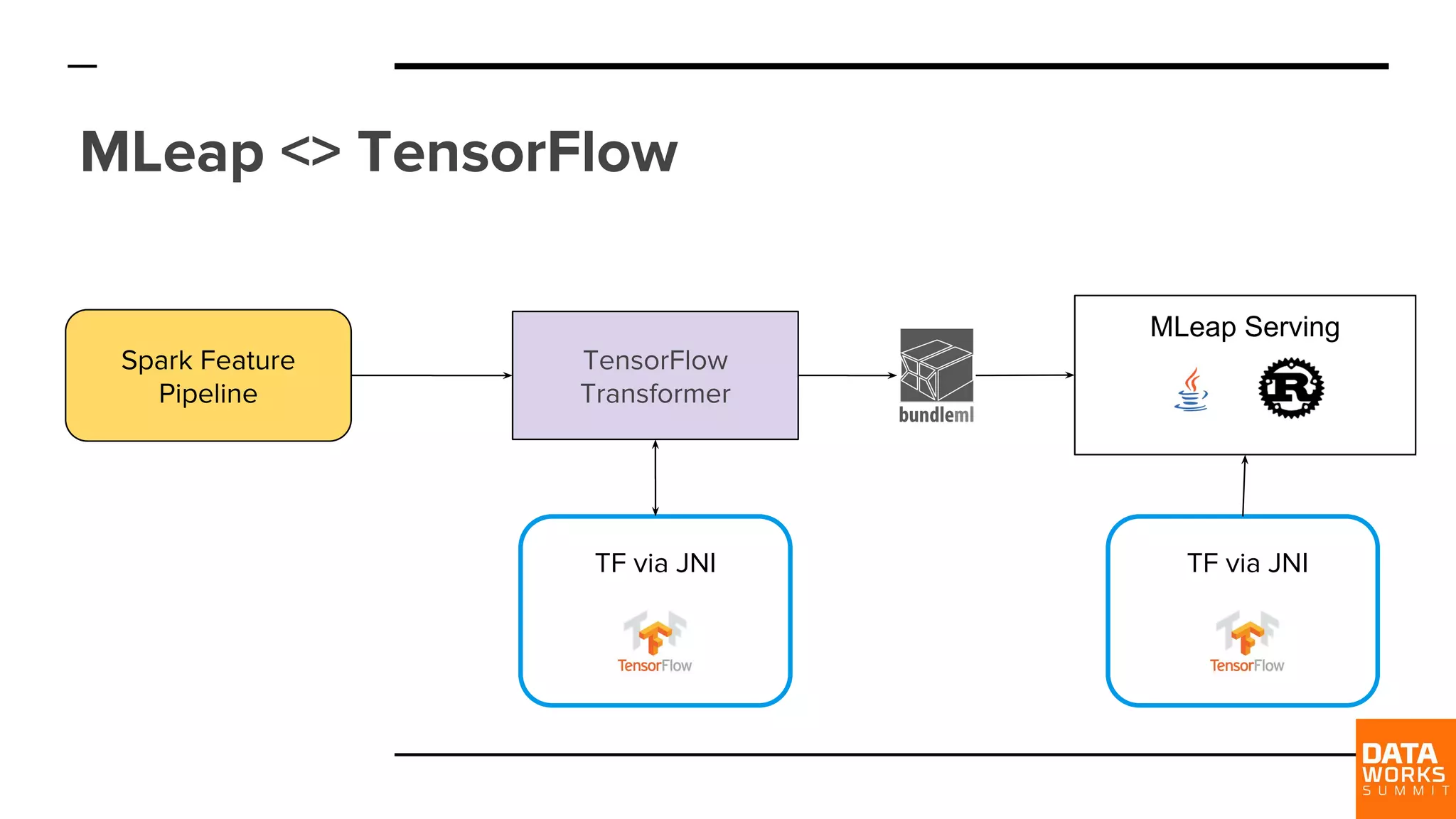
The workflow involves writing ML pipelines in Spark, serializing them to MLeap bundles, and executing via a REST API—minimizing dependencies.
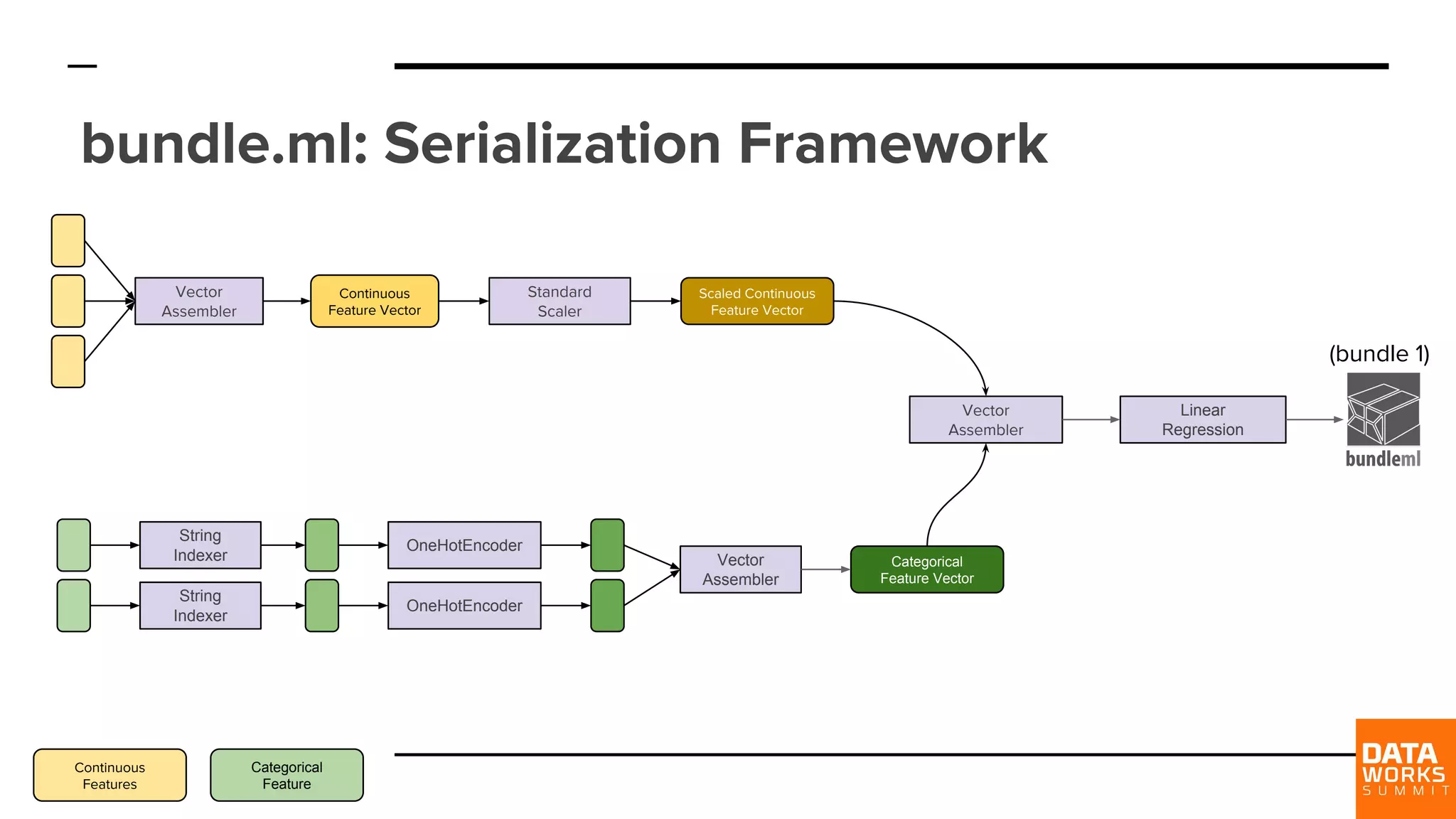
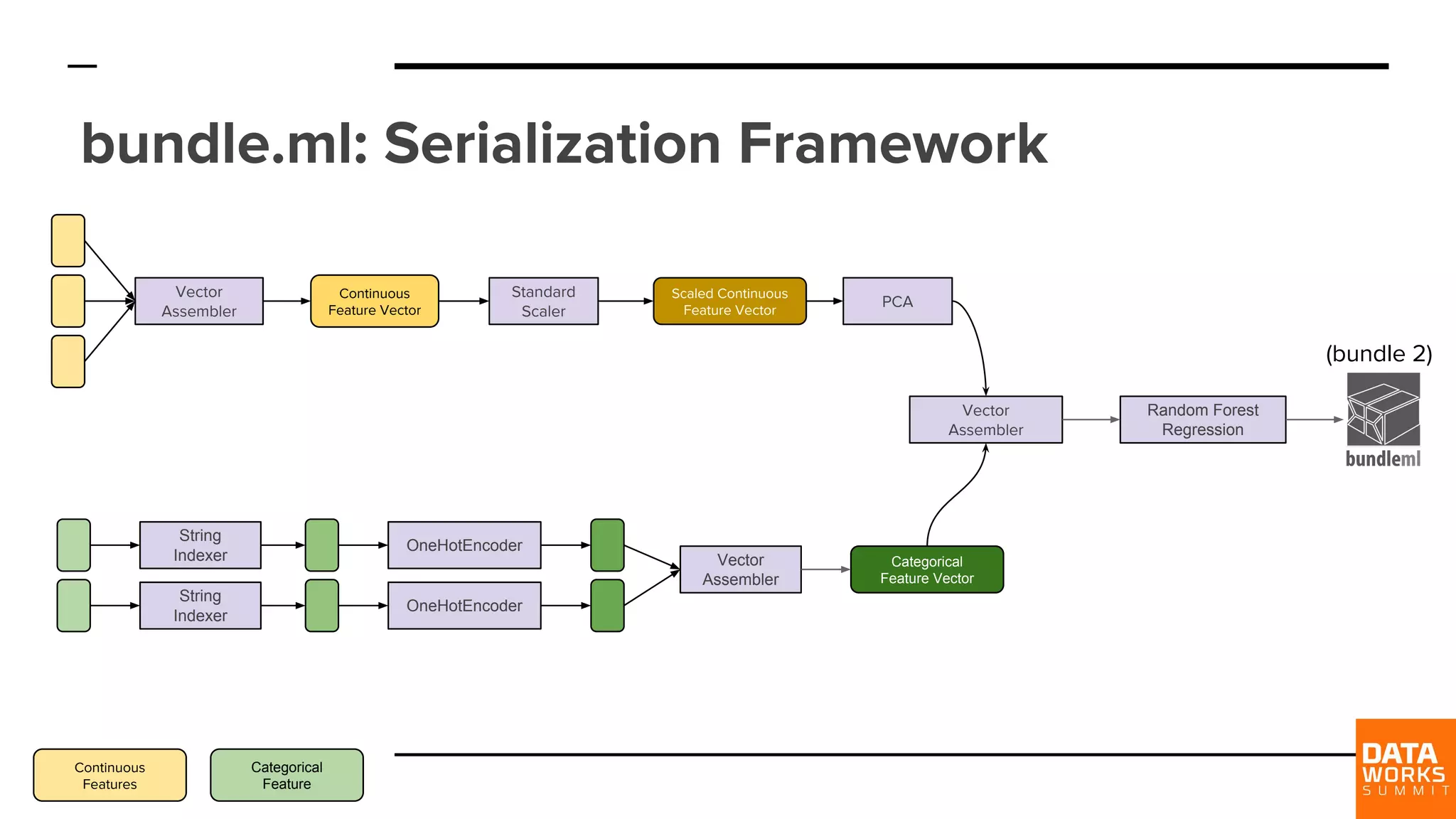
Explains 'bundle.ml' as a serialization format containing metadata, model execution data, and connections for model input/output.
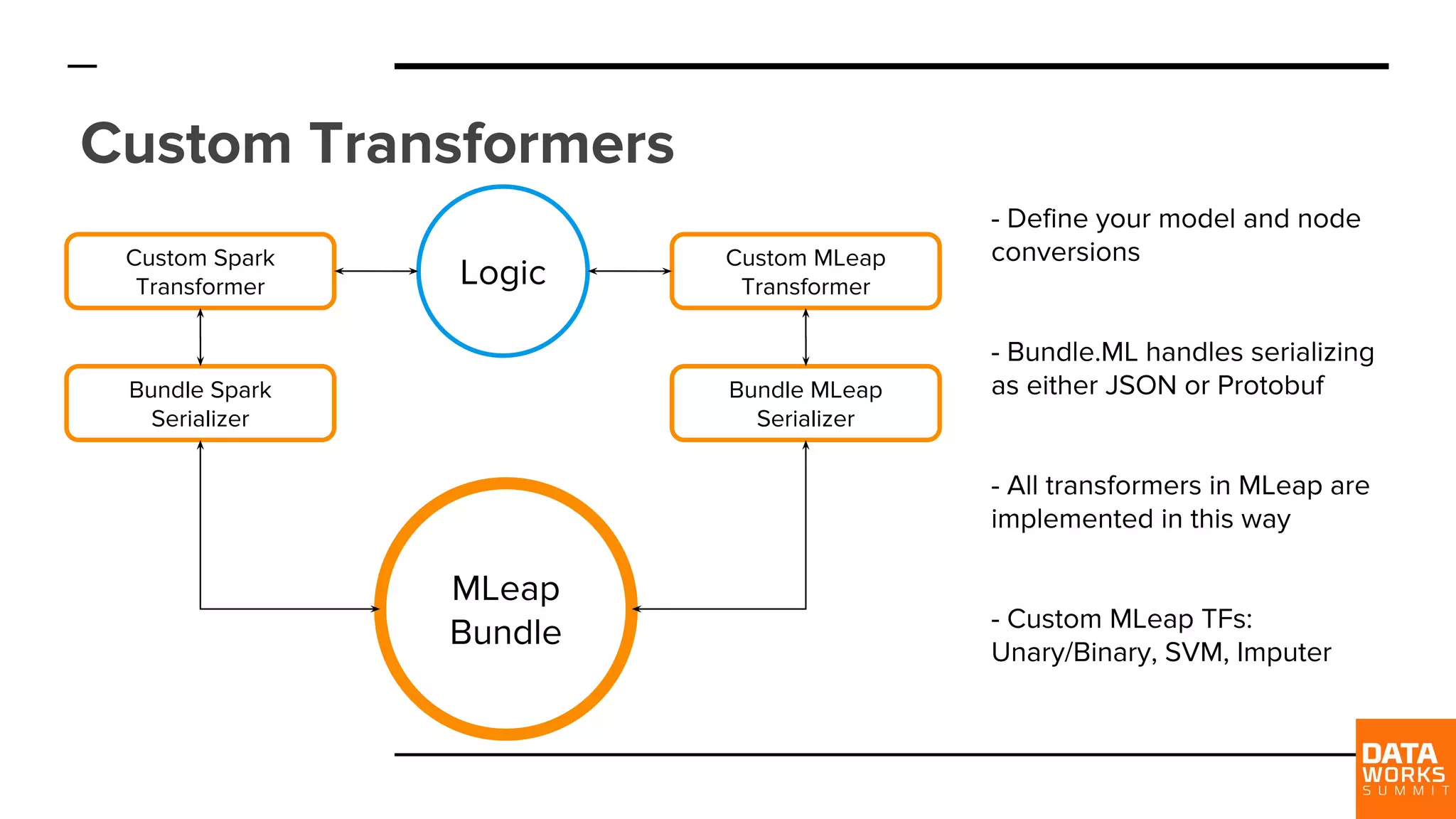
Details on creating custom transformers for Spark and MLeap, and how serialization is handled in various formats like JSON and Protobuf.
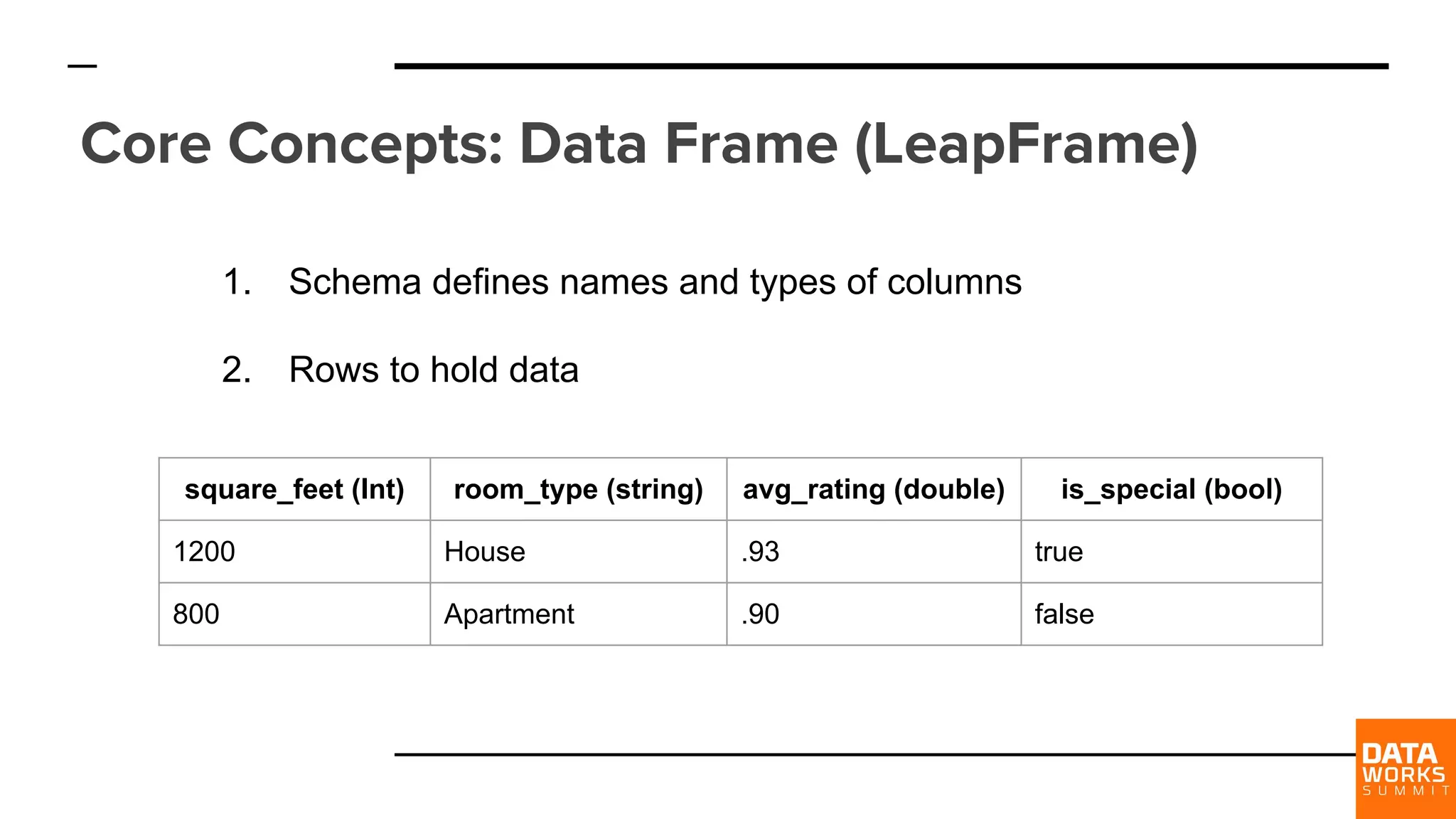
Defines core concepts such as LeapFrame which denote how data is structured, including types and schemas essential for ML models.
MLeap Serving enables deployment on IoT and cloud APIs. Discusses compatibility with Scikit-Learn and TensorFlow.
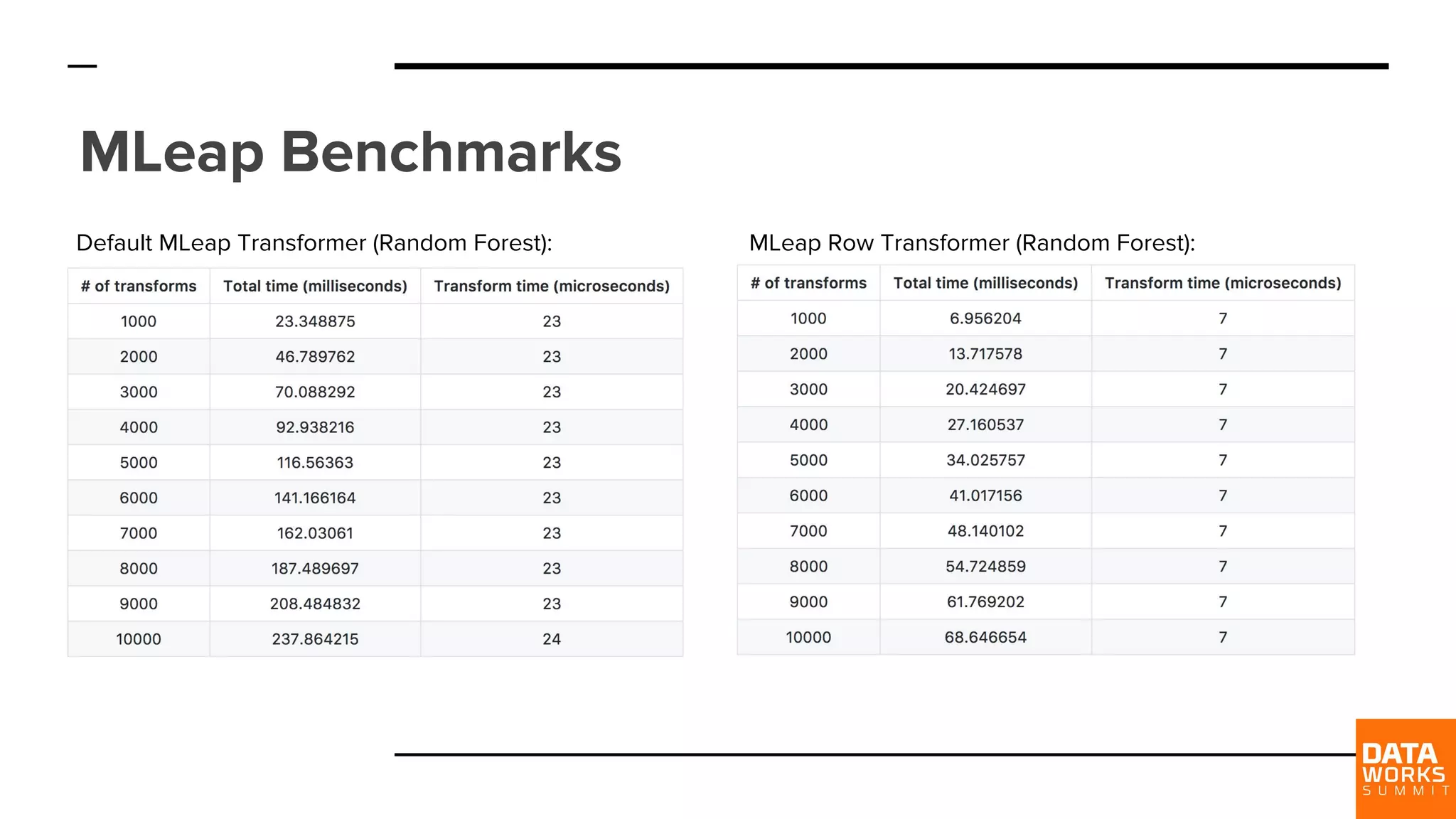
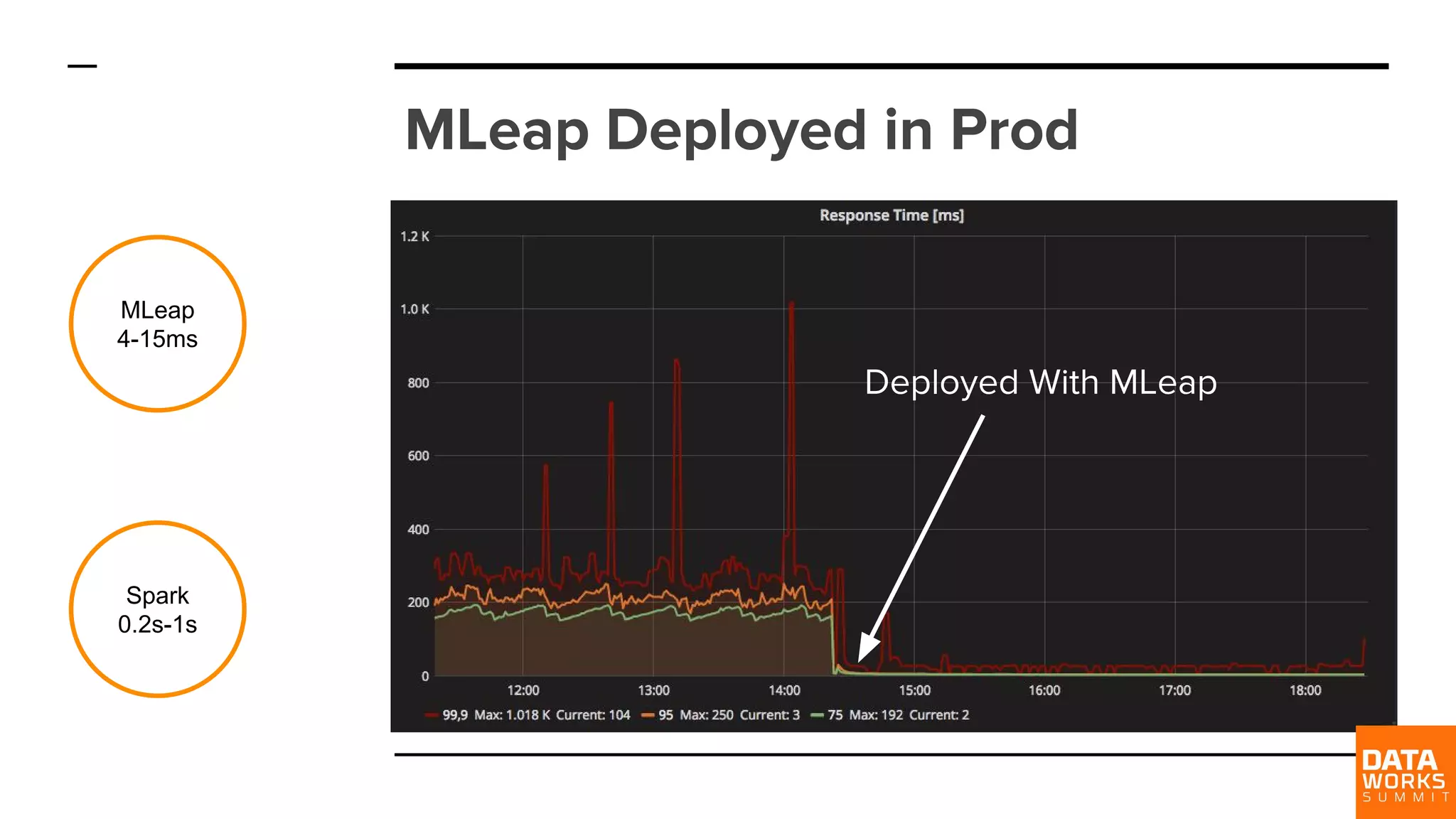
MLeap shows significant performance improvements, reducing execution times to 4-15 ms compared to Spark's 0.2s-1s.
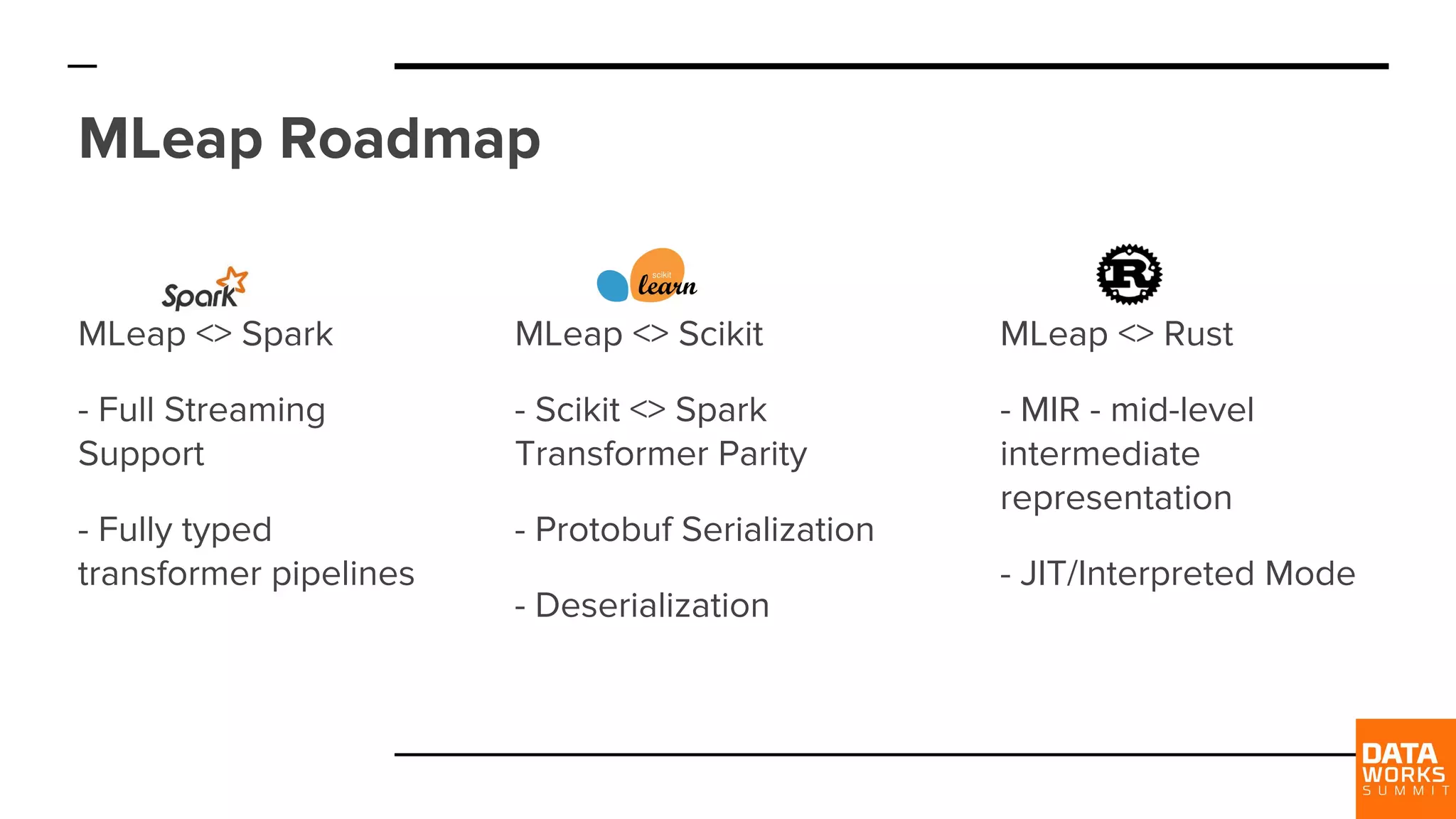
Future development plans include full streaming support and expanded compatibility with frameworks like Rust and Scikit-Learn.
Encourages community contributions, sharing experiences, and seeking product managers for MLeap to foster growth and collaboration.
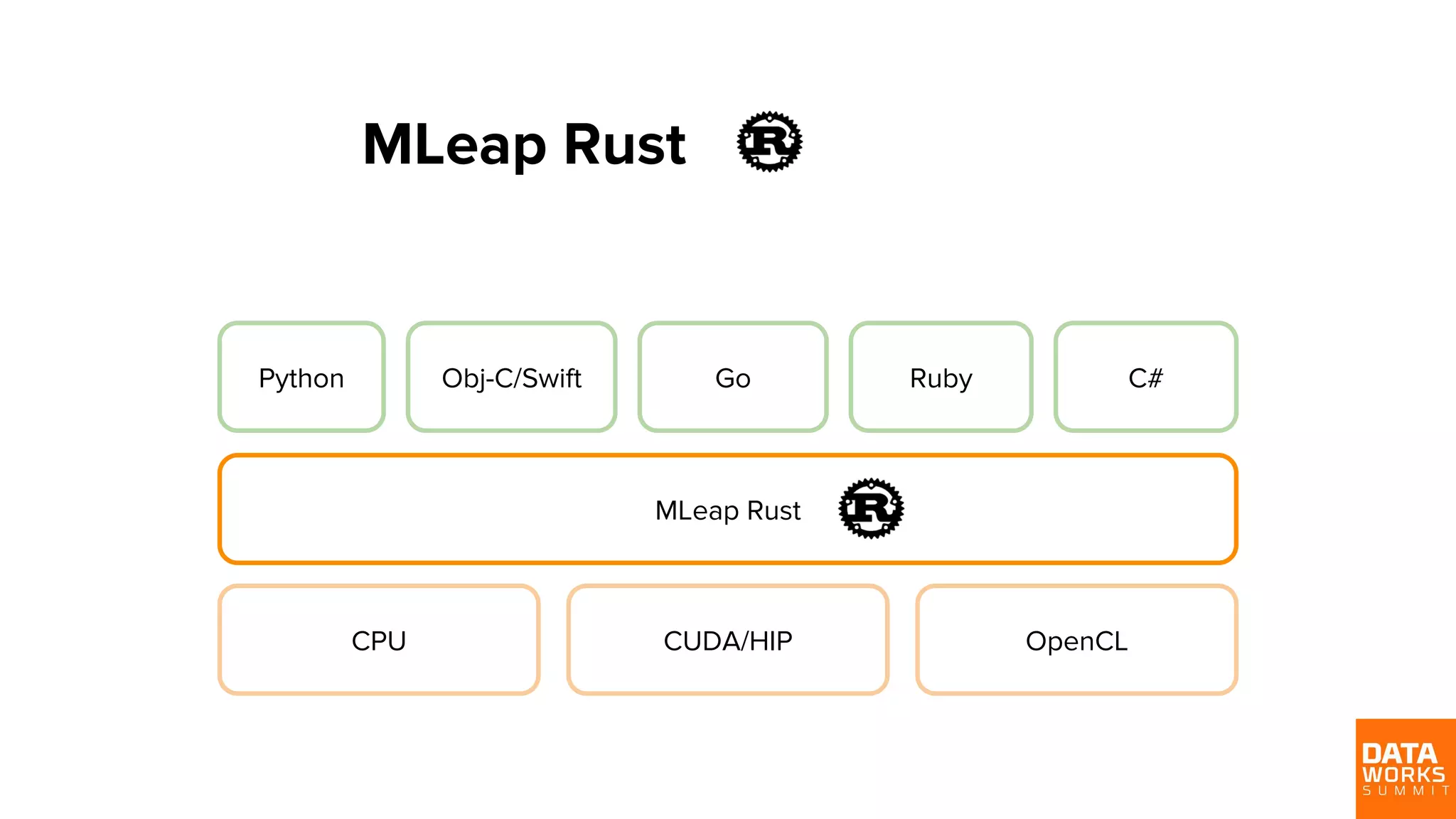
Explores diverse programming language support for MLeap including Rust, Python, and others to enhance interoperability.
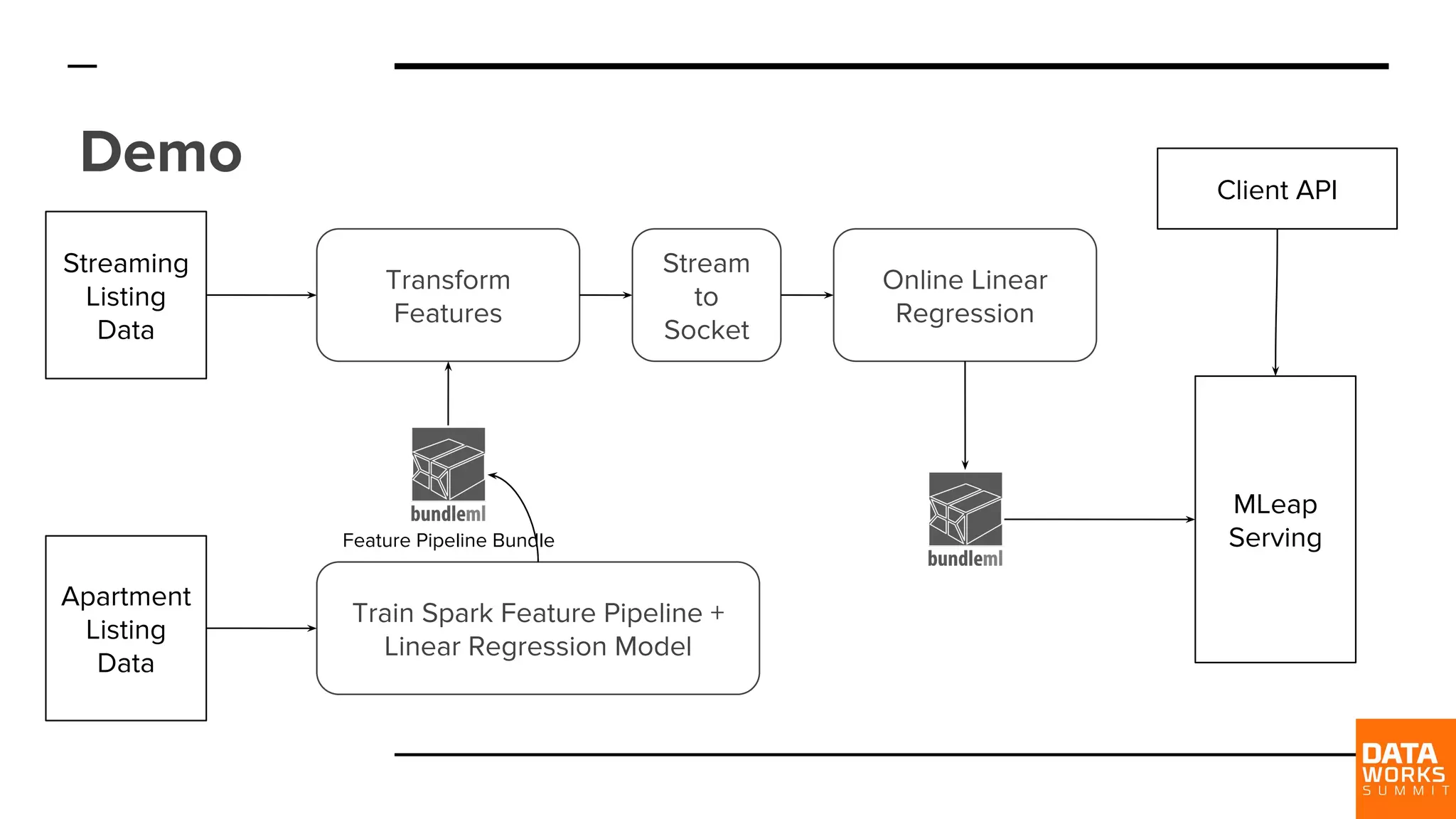
Demonstrates a live training session utilizing Spark Feature Pipeline with a linear regression model, showcasing real-time data transformation.
Thanking the audience, providing contact details, and encouraging engagement with MLeap community and projects.