Download as PDF, PPTX










![DataFrame In [10]: tips[:10] Out[10]: total_bill tip sex smoker day time size 1 16.99 1.01 Female No Sun Dinner 2 2 10.34 1.66 Male No Sun Dinner 3 3 21.01 3.50 Male No Sun Dinner 3 4 23.68 3.31 Male No Sun Dinner 2 5 24.59 3.61 Female No Sun Dinner 4 6 25.29 4.71 Male No Sun Dinner 4 7 8.770 2.00 Male No Sun Dinner 2 8 26.88 3.12 Male No Sun Dinner 4 9 15.04 1.96 Male No Sun Dinner 2 10 14.78 3.23 Male No Sun Dinner 2](https://image.slidesharecdn.com/slides-151008060416-lva1-app6892/75/pandas-Powerful-data-analysis-tools-for-Python-15-2048.jpg)





















Wes McKinney introduced pandas, a Python data analysis library built on NumPy. Pandas provides data structures and tools for cleaning, manipulating, and working with relational and time-series data. Key features include DataFrame for 2D data, hierarchical indexing, merging and joining data, and grouping and aggregating data. Pandas is used heavily in financial applications and has over 1500 unit tests, ensuring stability and reliability. Future goals include better time series handling and integration with other Python data science packages.
Overview of pandas as a powerful data analysis tool; background on Wes McKinney and his professional journey.
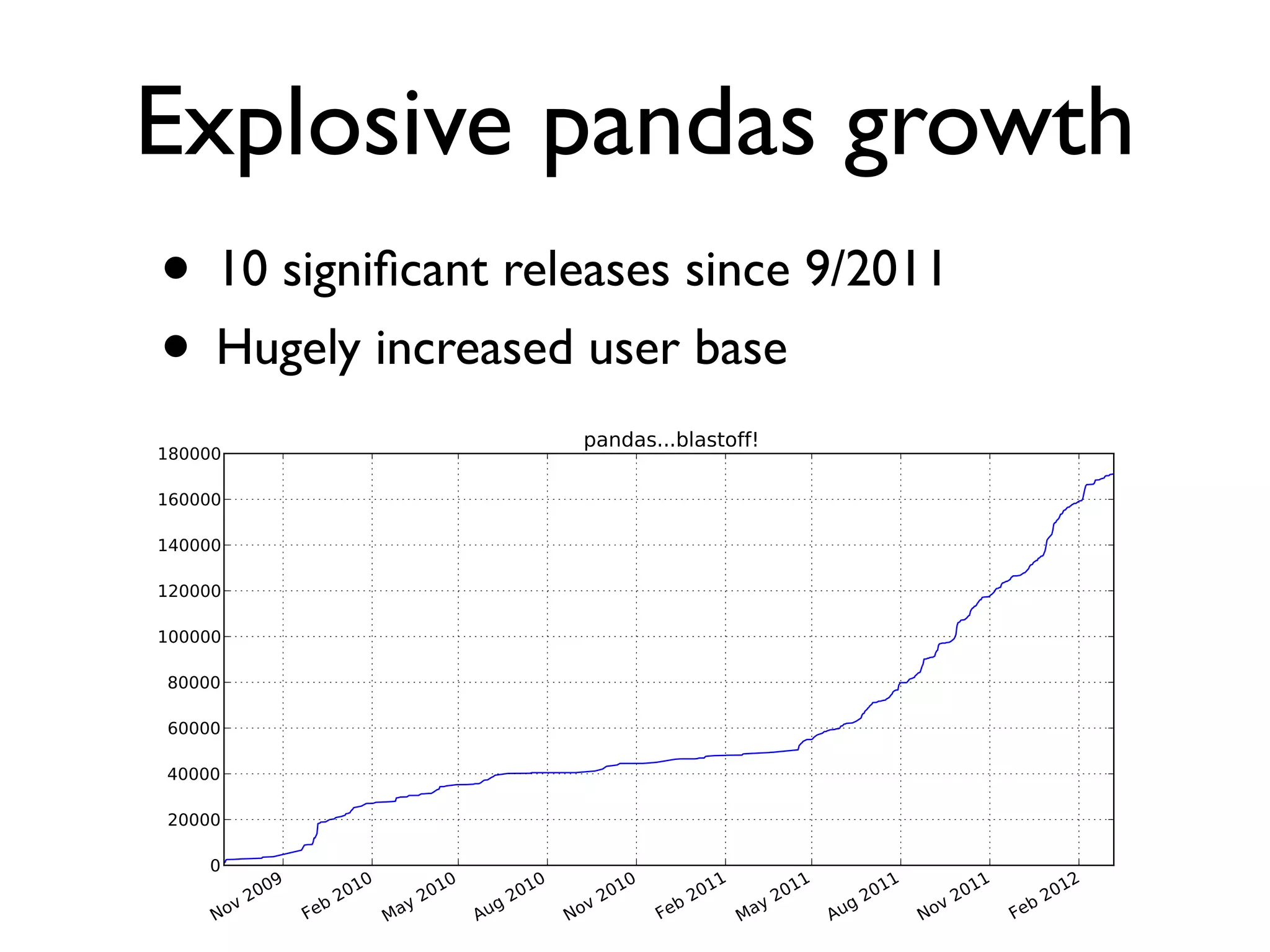
Discusses the rich features of pandas, its performance, and explosive growth; emphasizes simplifying data handling.
Discusses the rich features of pandas, its performance, and explosive growth; emphasizes simplifying data handling.
Highlights impressive test coverage of pandas with details on test function growth over time.
Introduction to IPython as a key tool for enhancing productivity in Python programming.
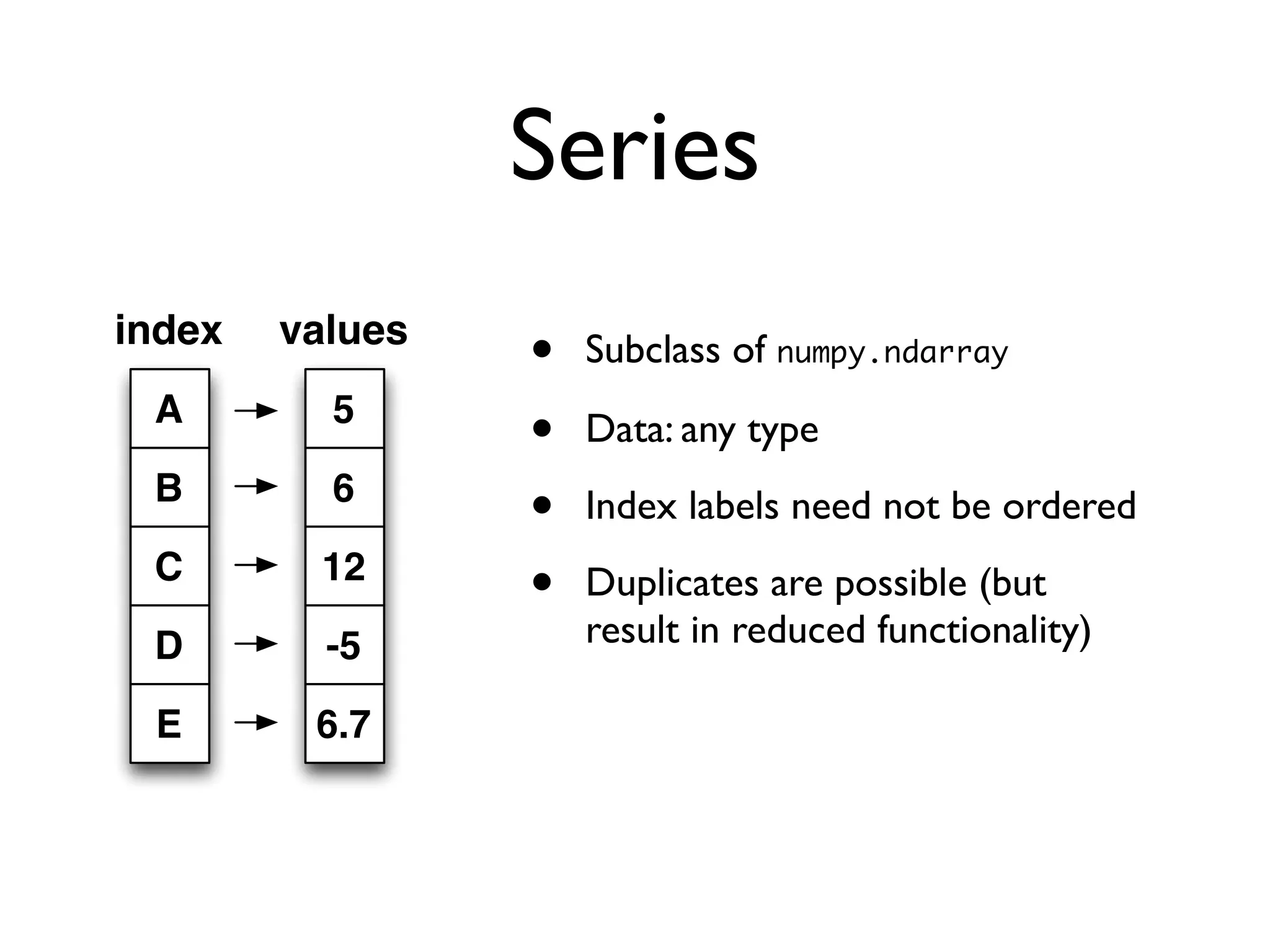
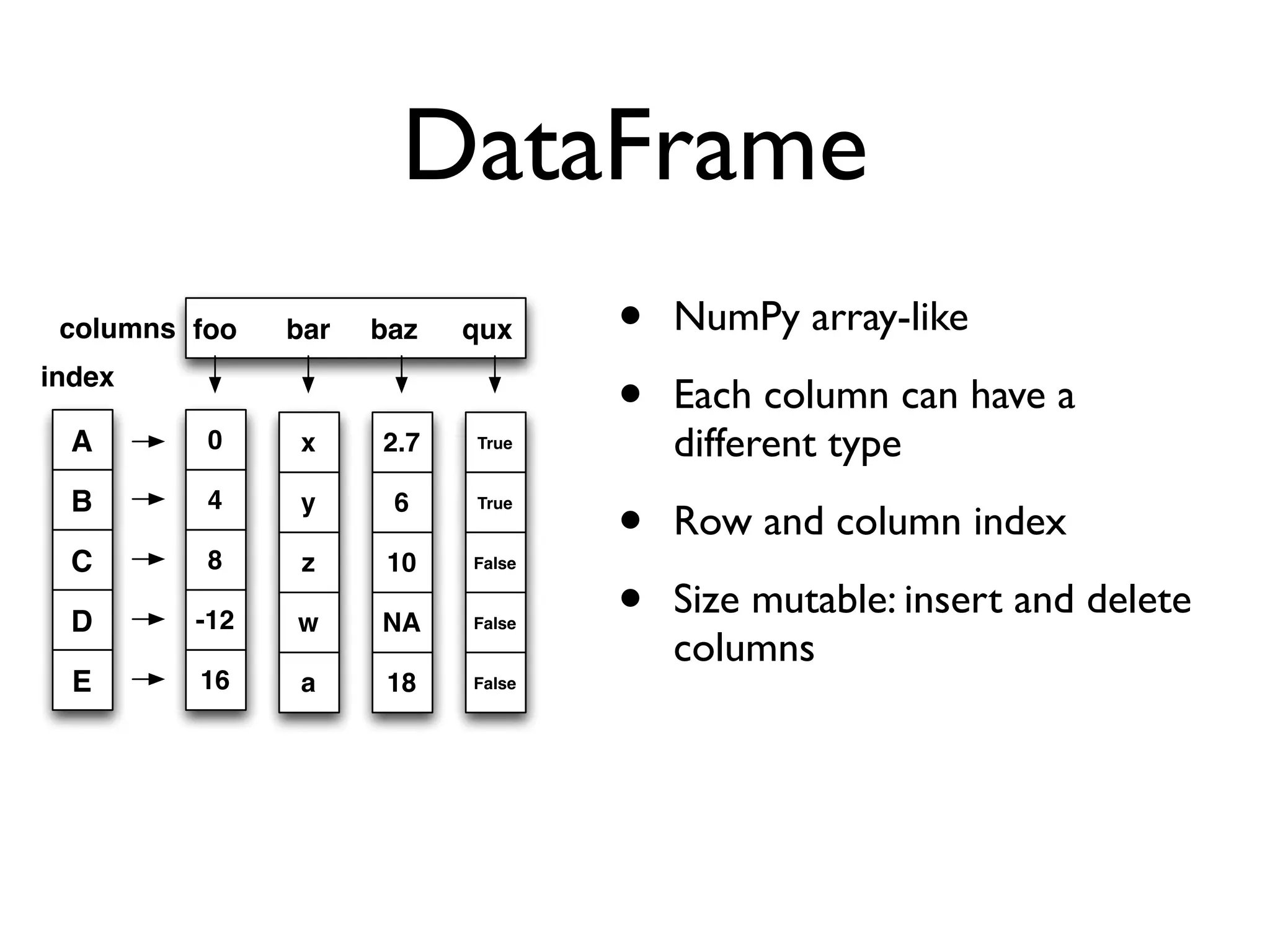
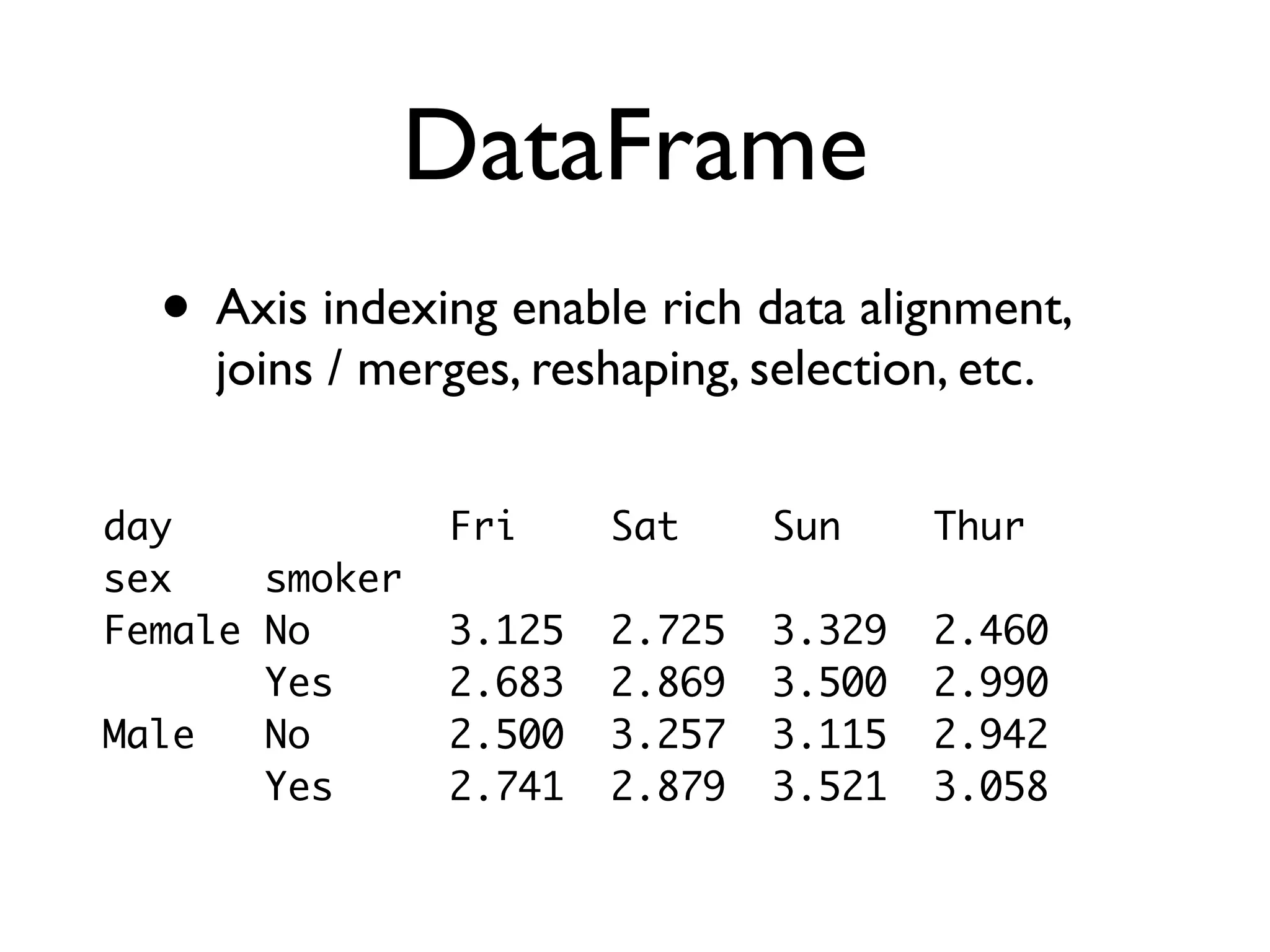
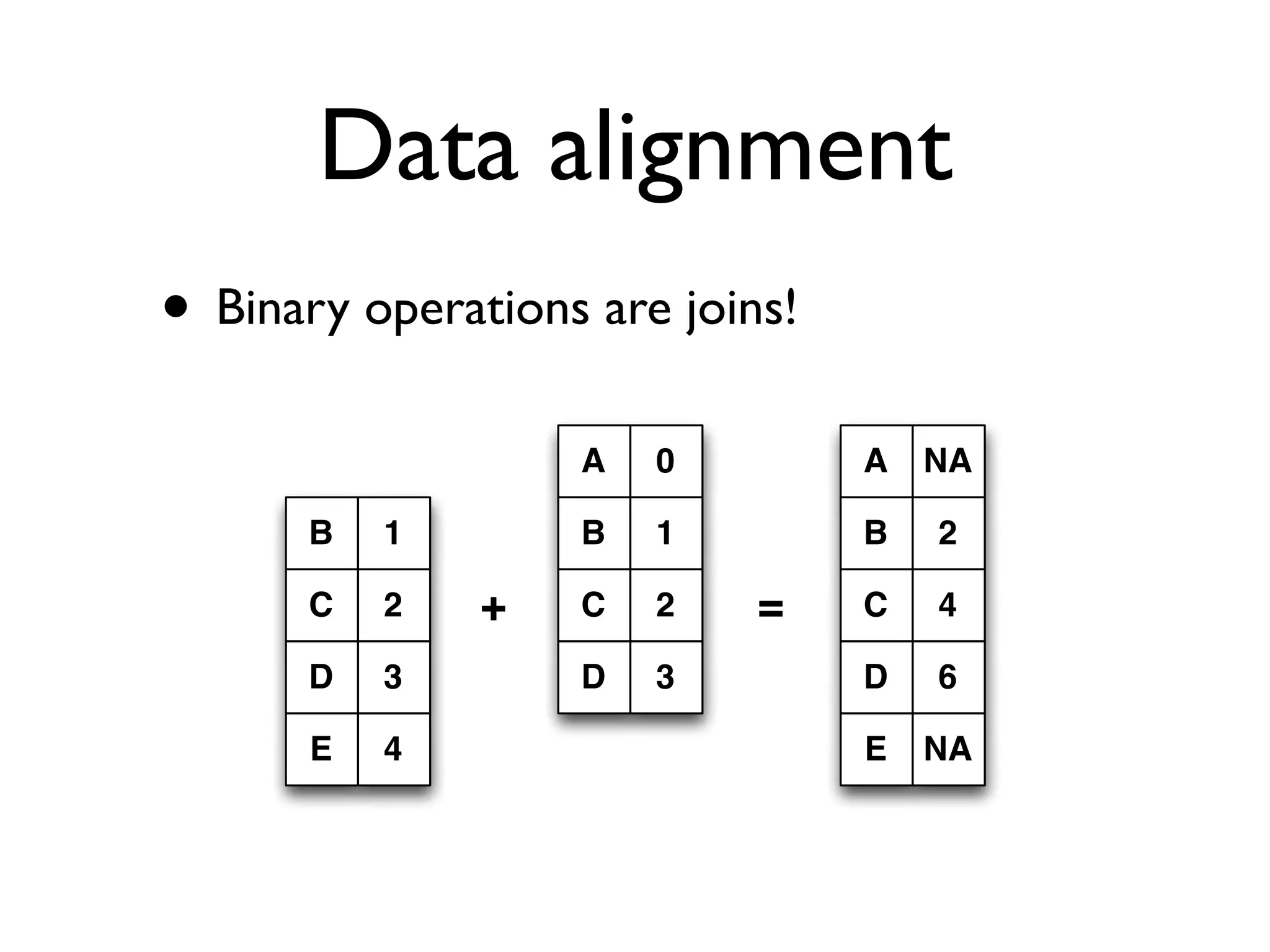
Describes Series and DataFrame structures, their functionalities, and data alignment capabilities.
Describes Series and DataFrame structures, their functionalities, and data alignment capabilities.
Explains hierarchical indexing and group operations, enabling easier data manipulation.
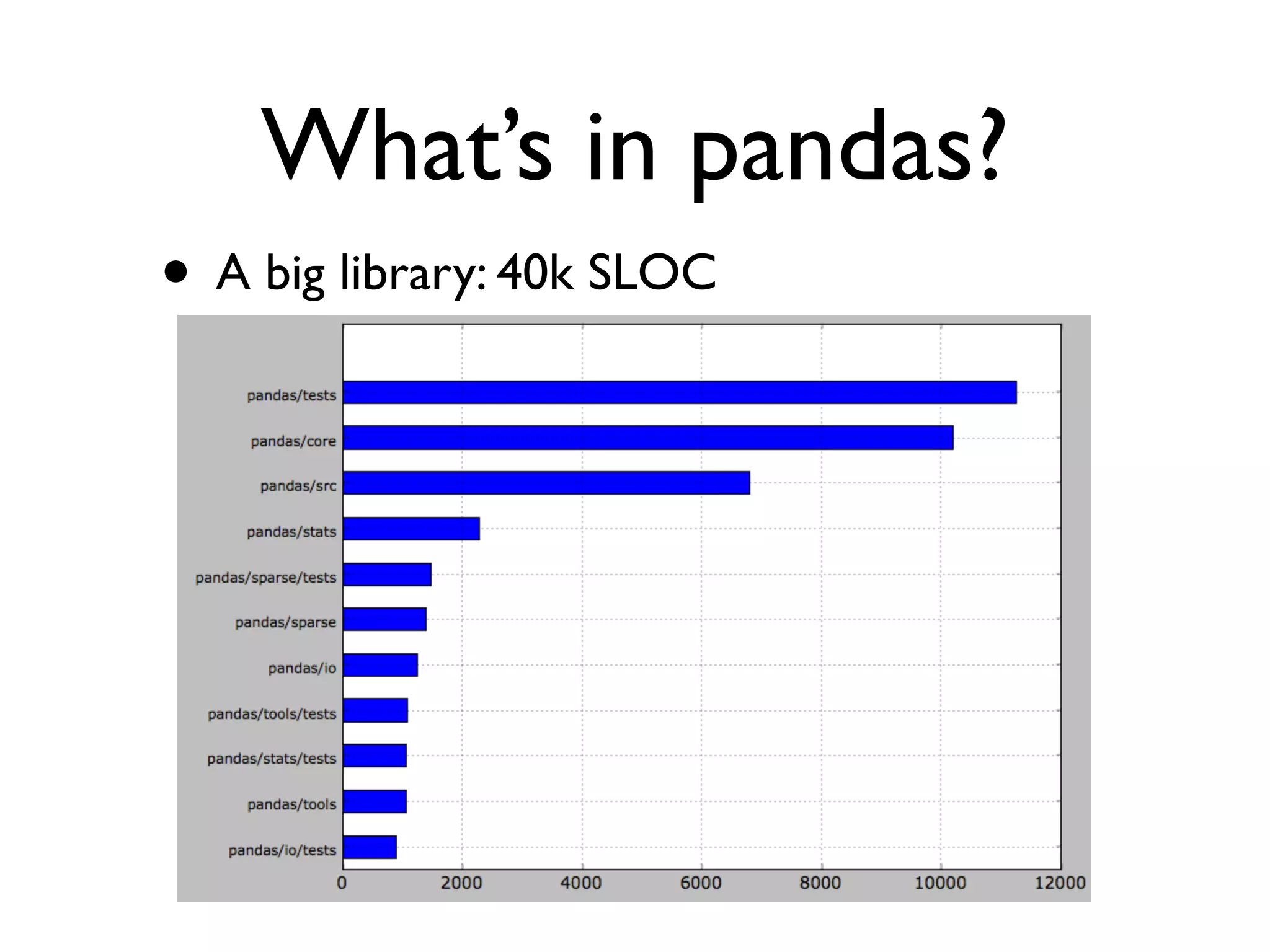
Details on pandas library components, testing framework, and fast algorithms for data processing.
Details on pandas library components, testing framework, and fast algorithms for data processing.
Justifies the use of Python as a robust environment for data analysis and statistical computing.
Outlines roadmap for pandas development focusing on time series improvement and big data integration.
Thanks and call to follow on social media, reinforcing engagement with the pandas community.