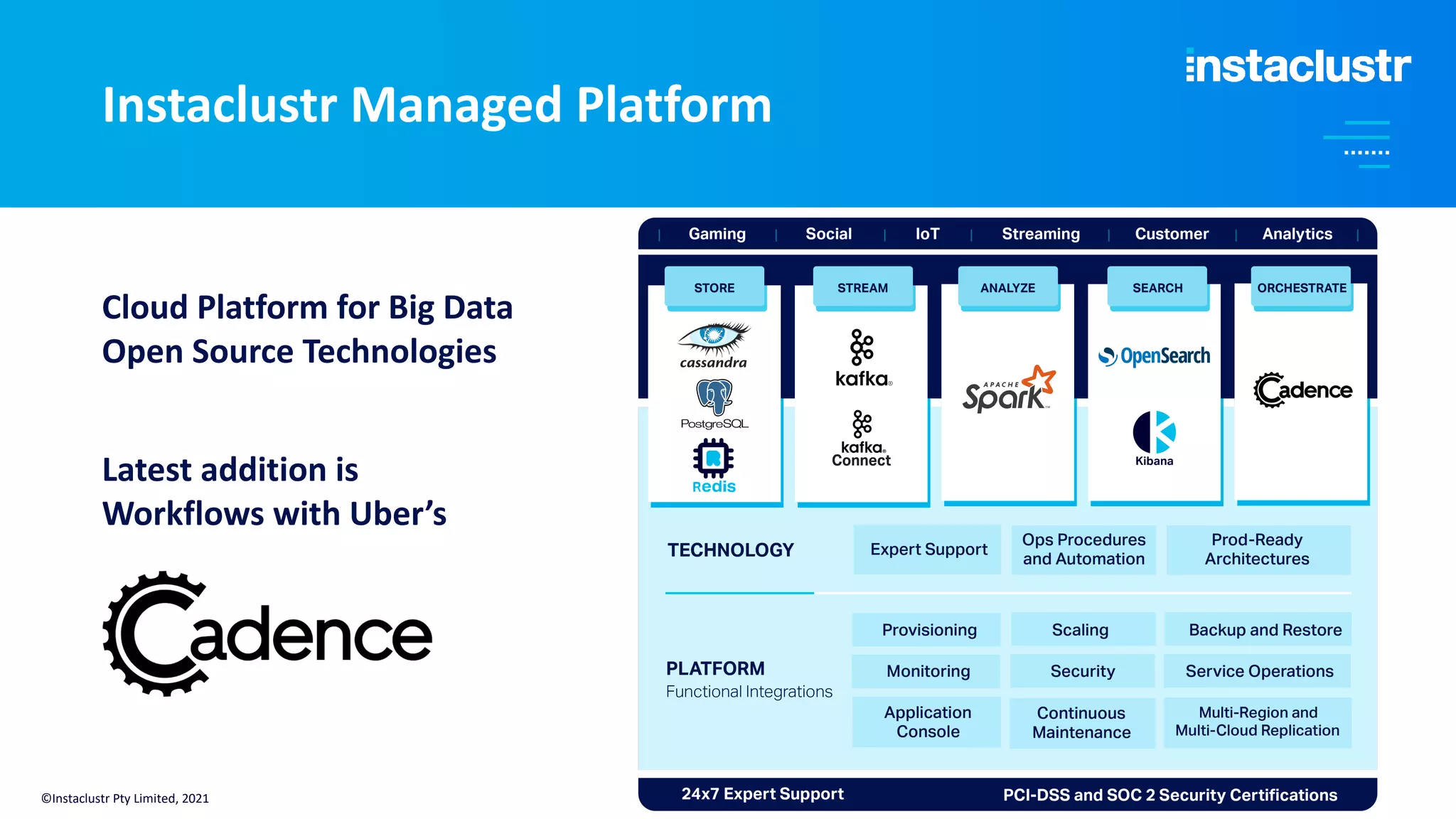
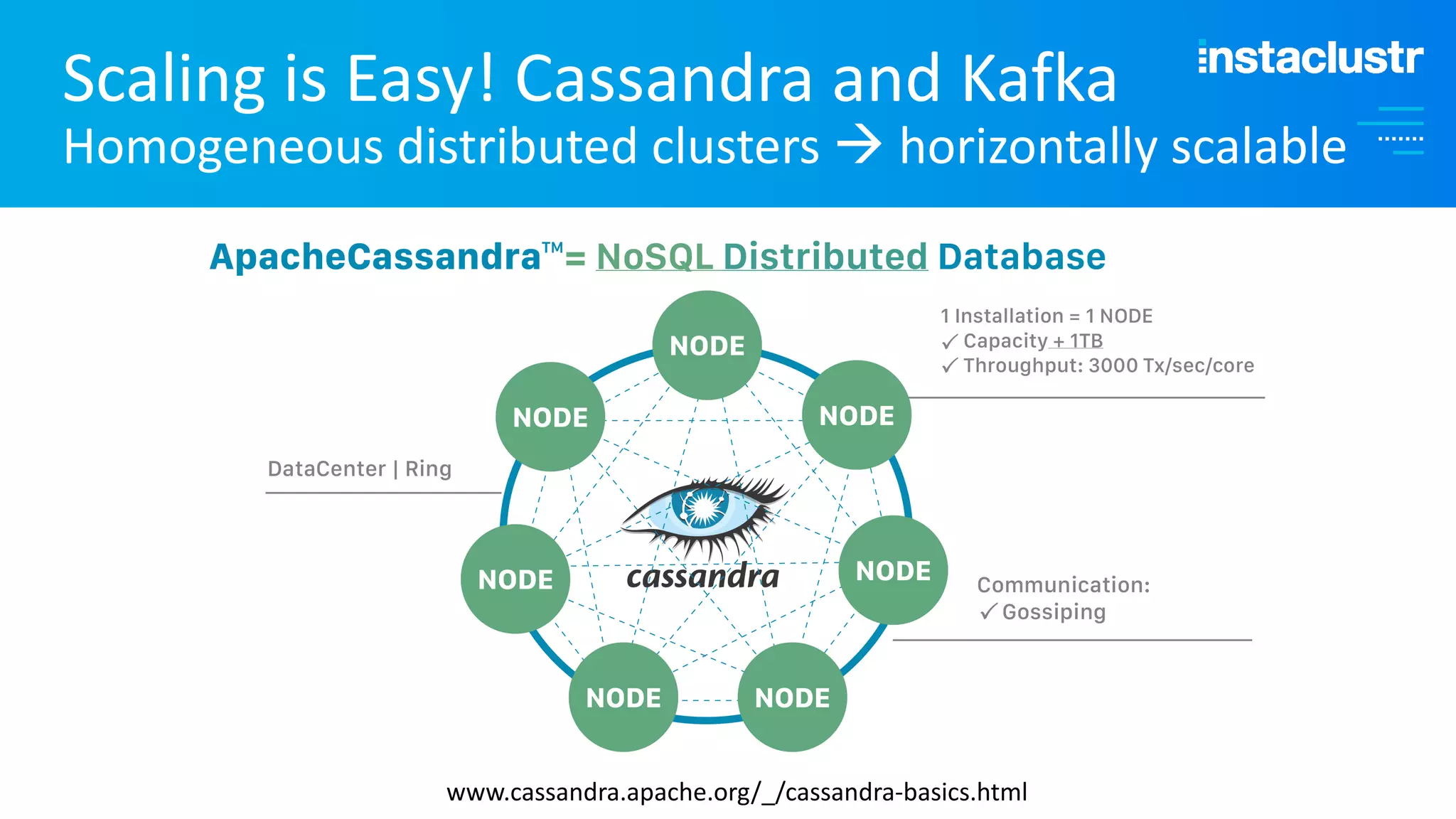
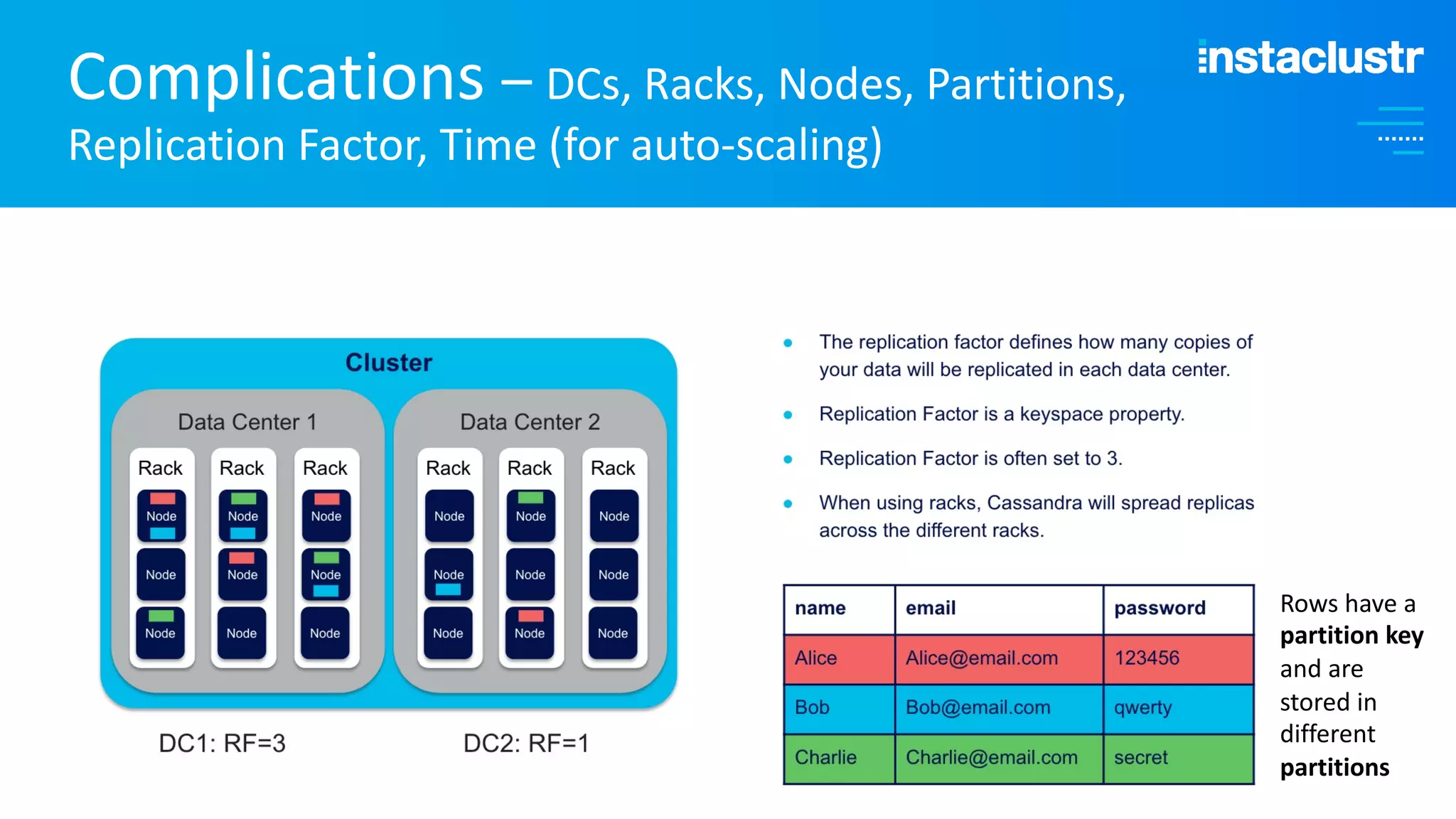
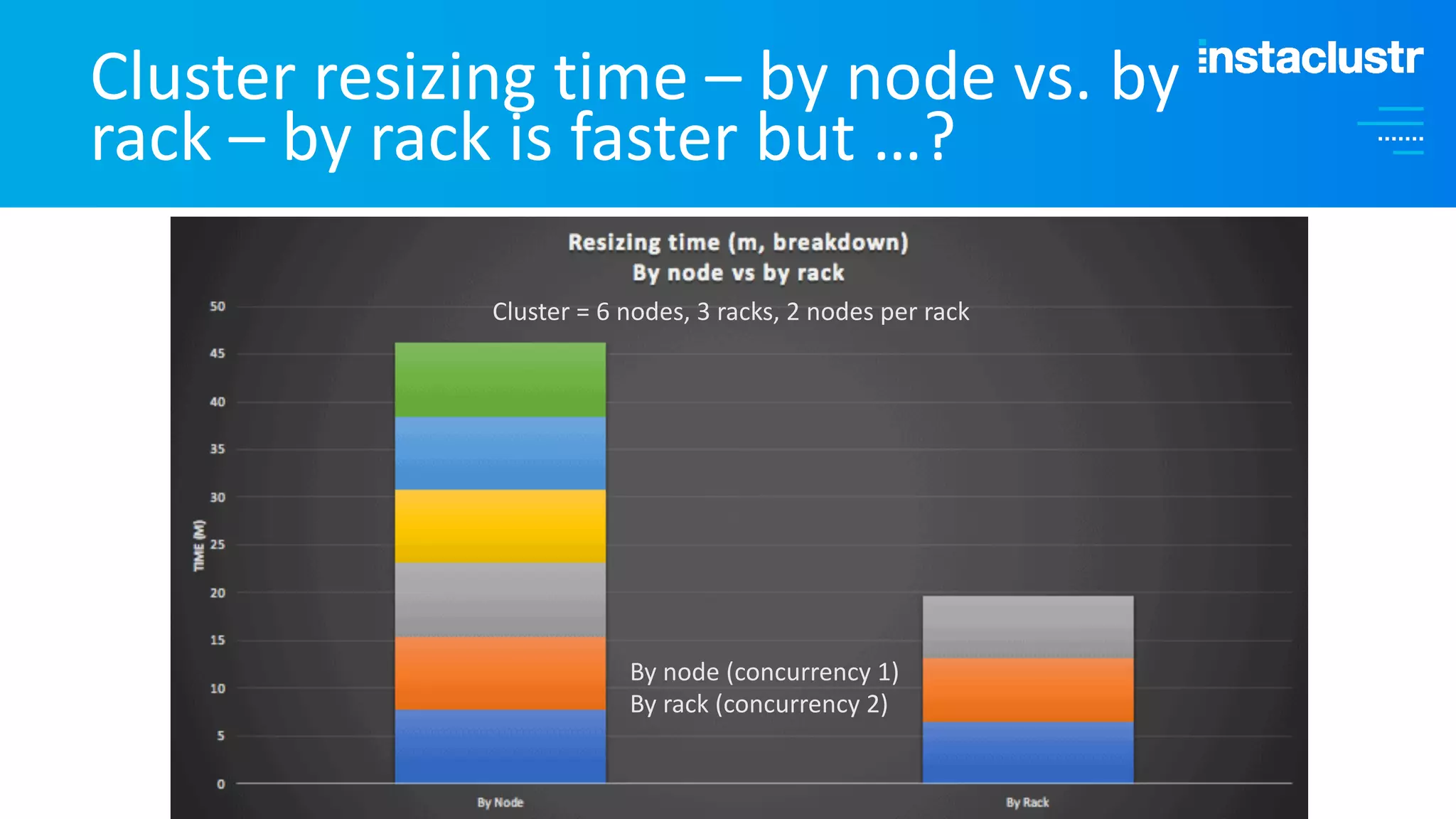
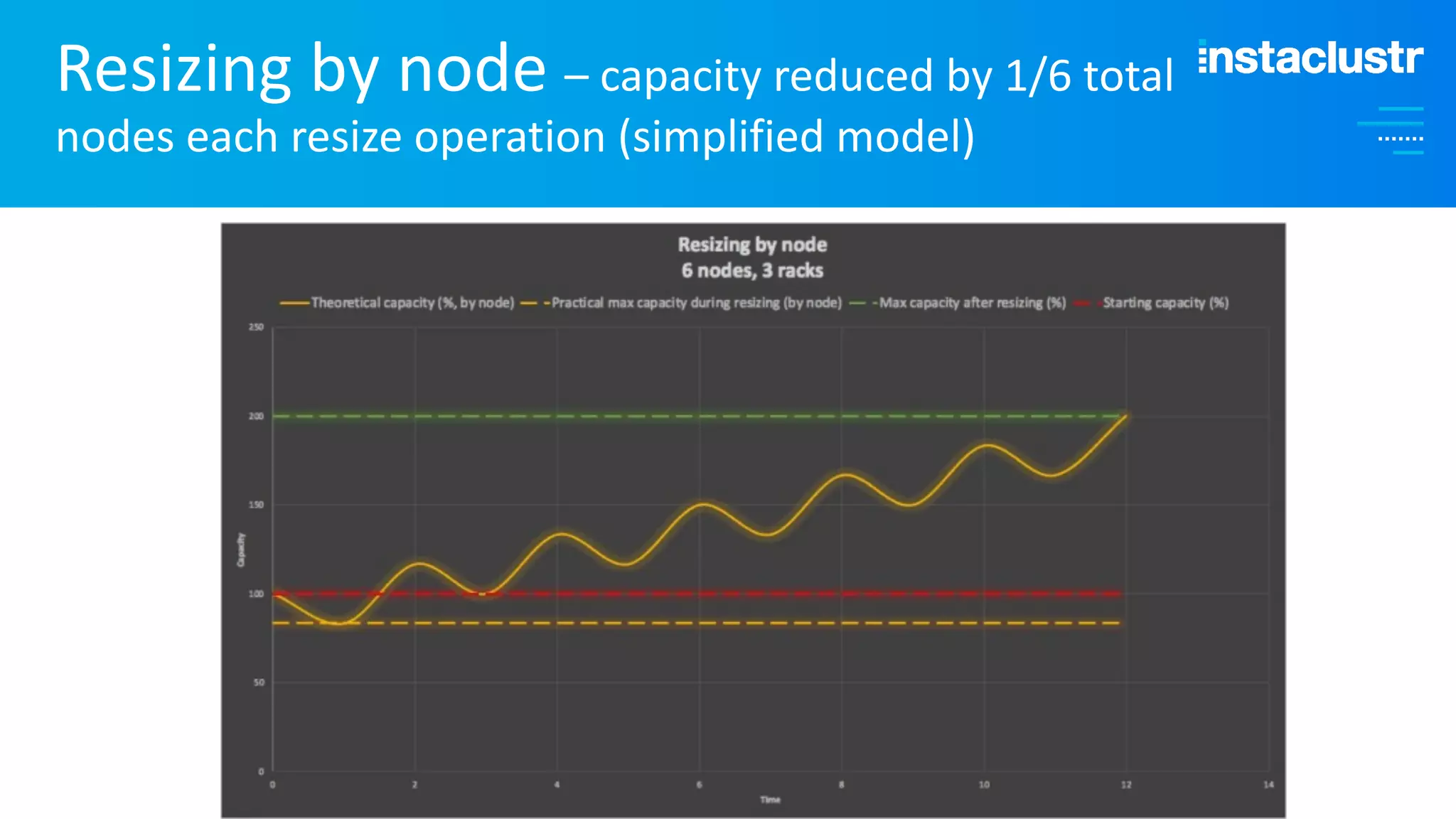
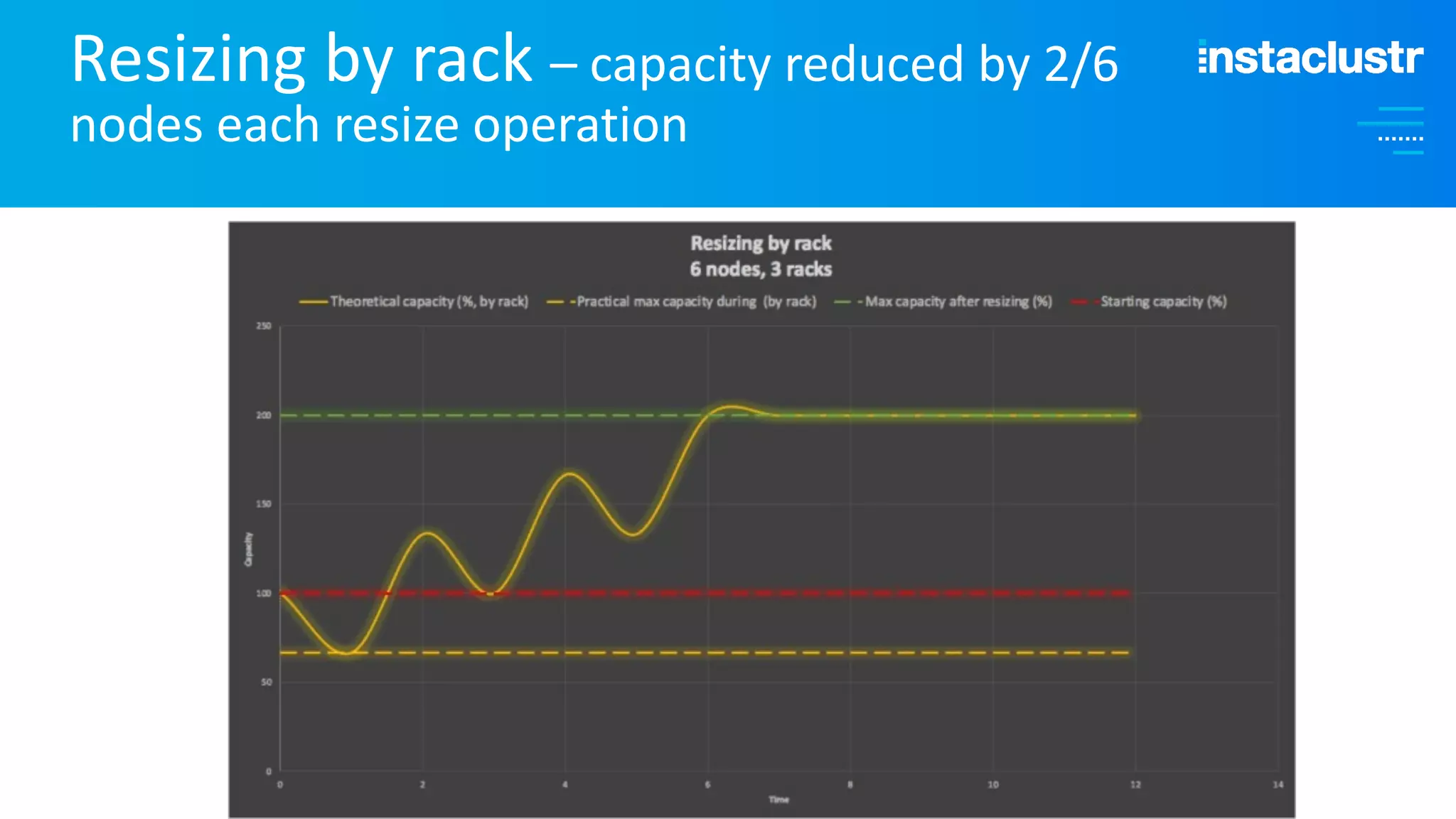
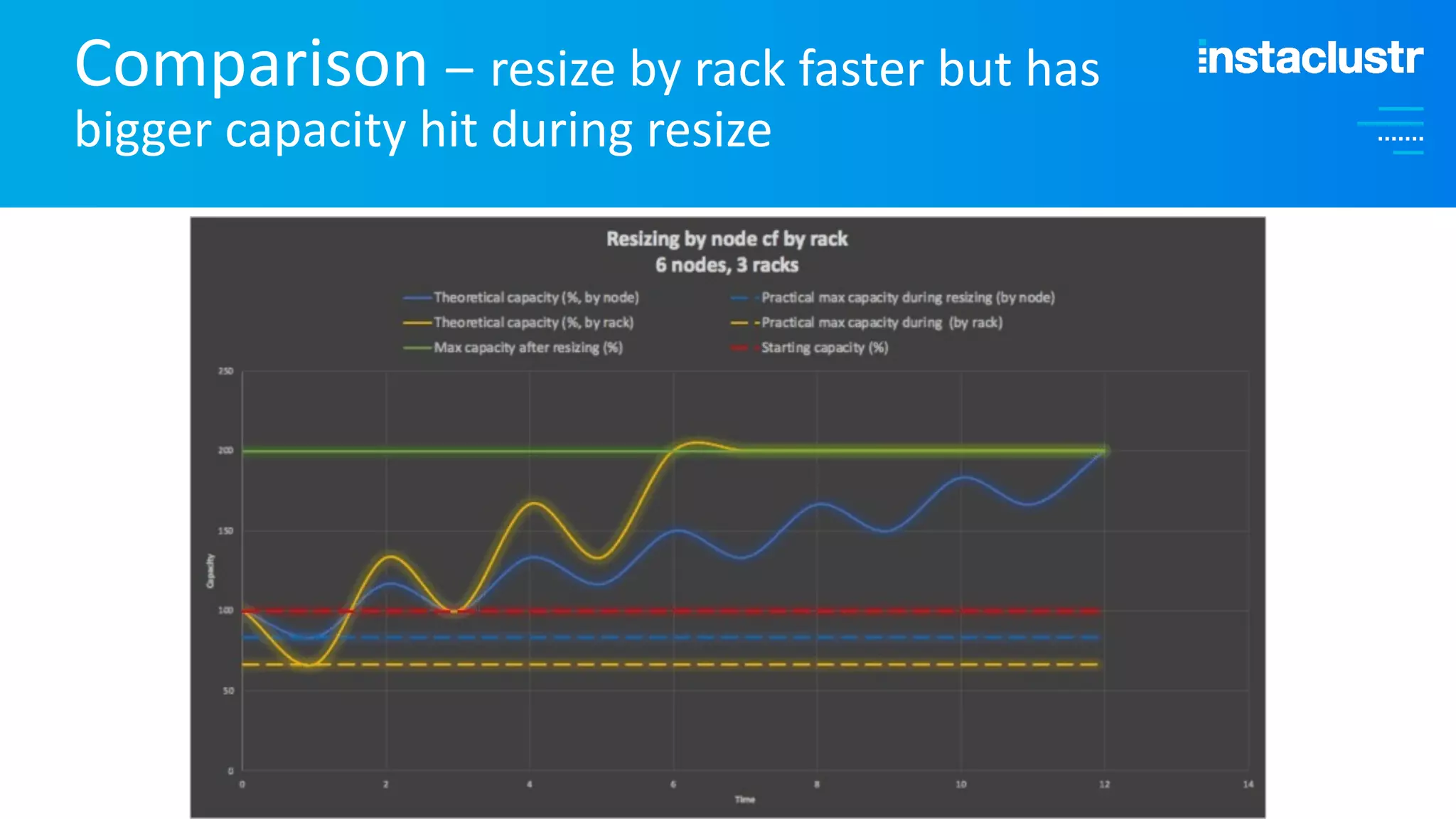
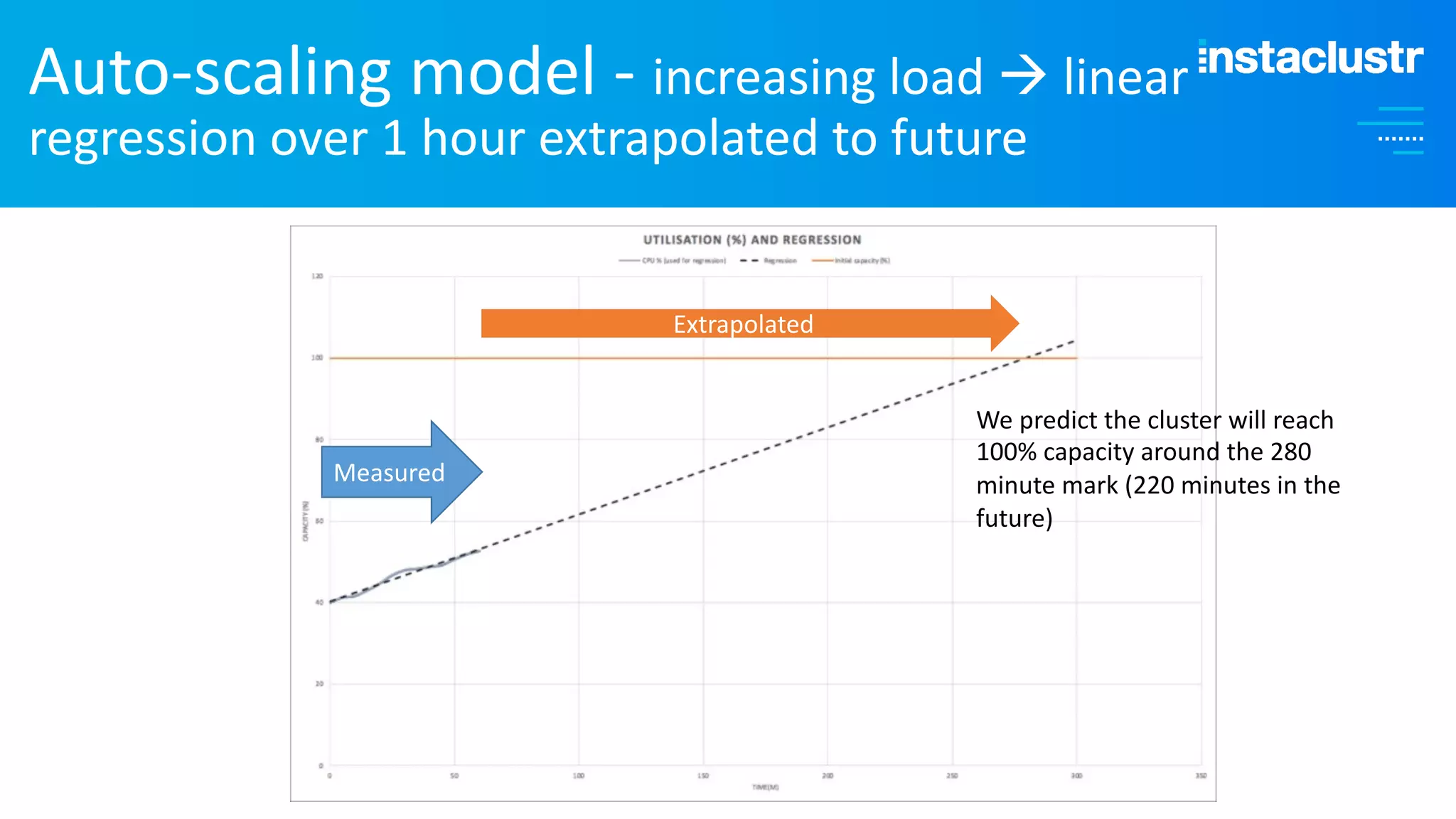
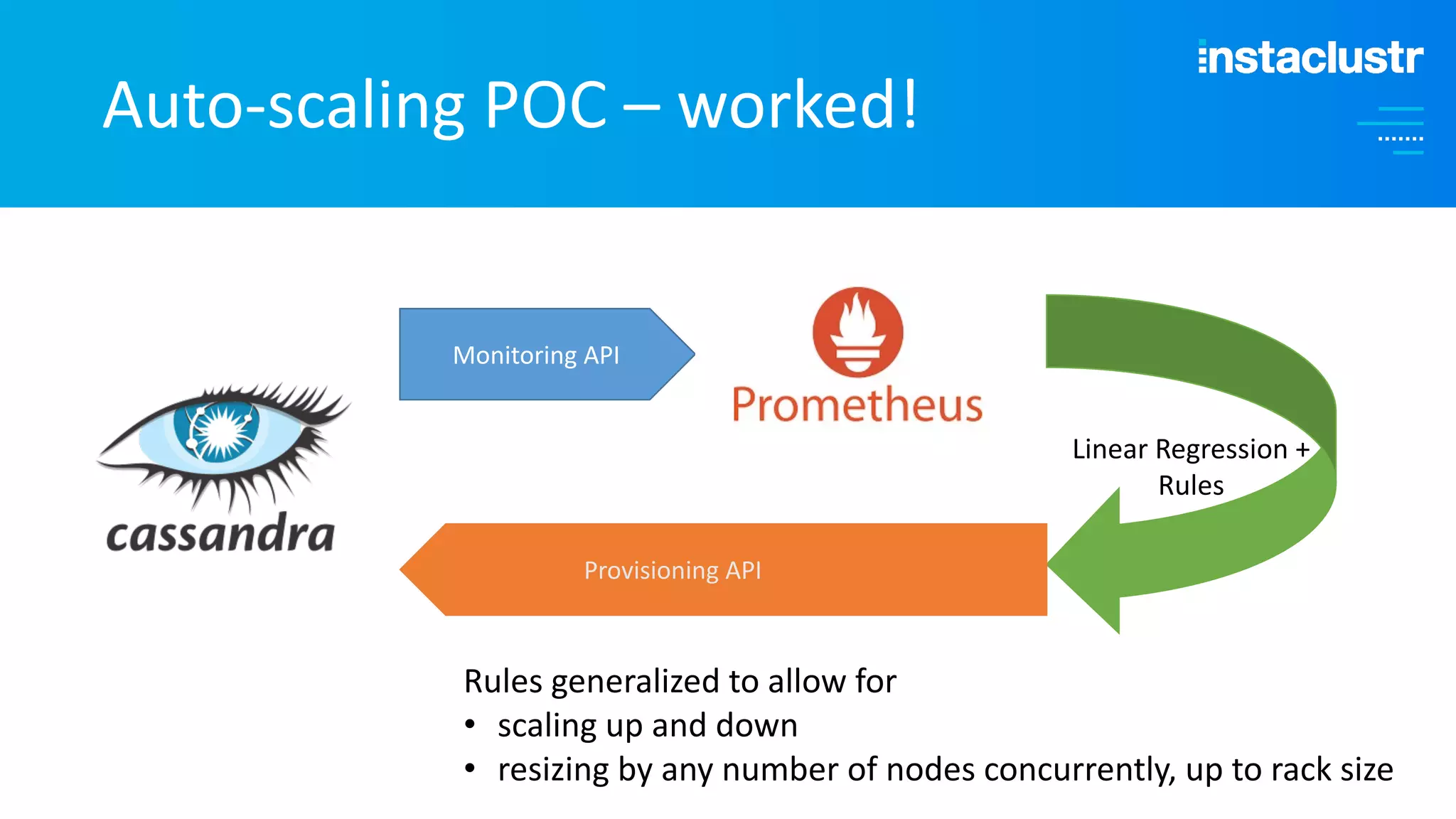
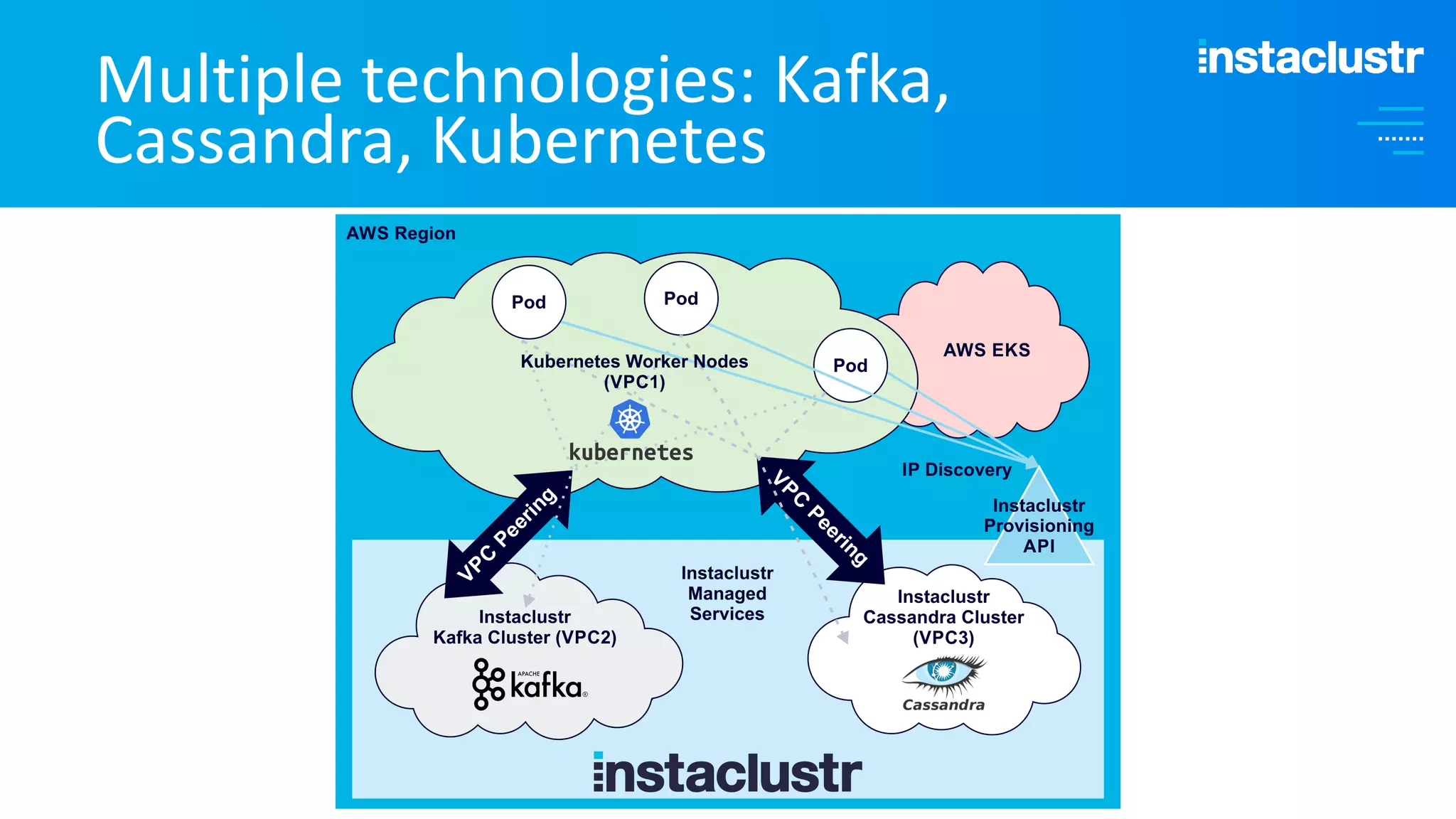
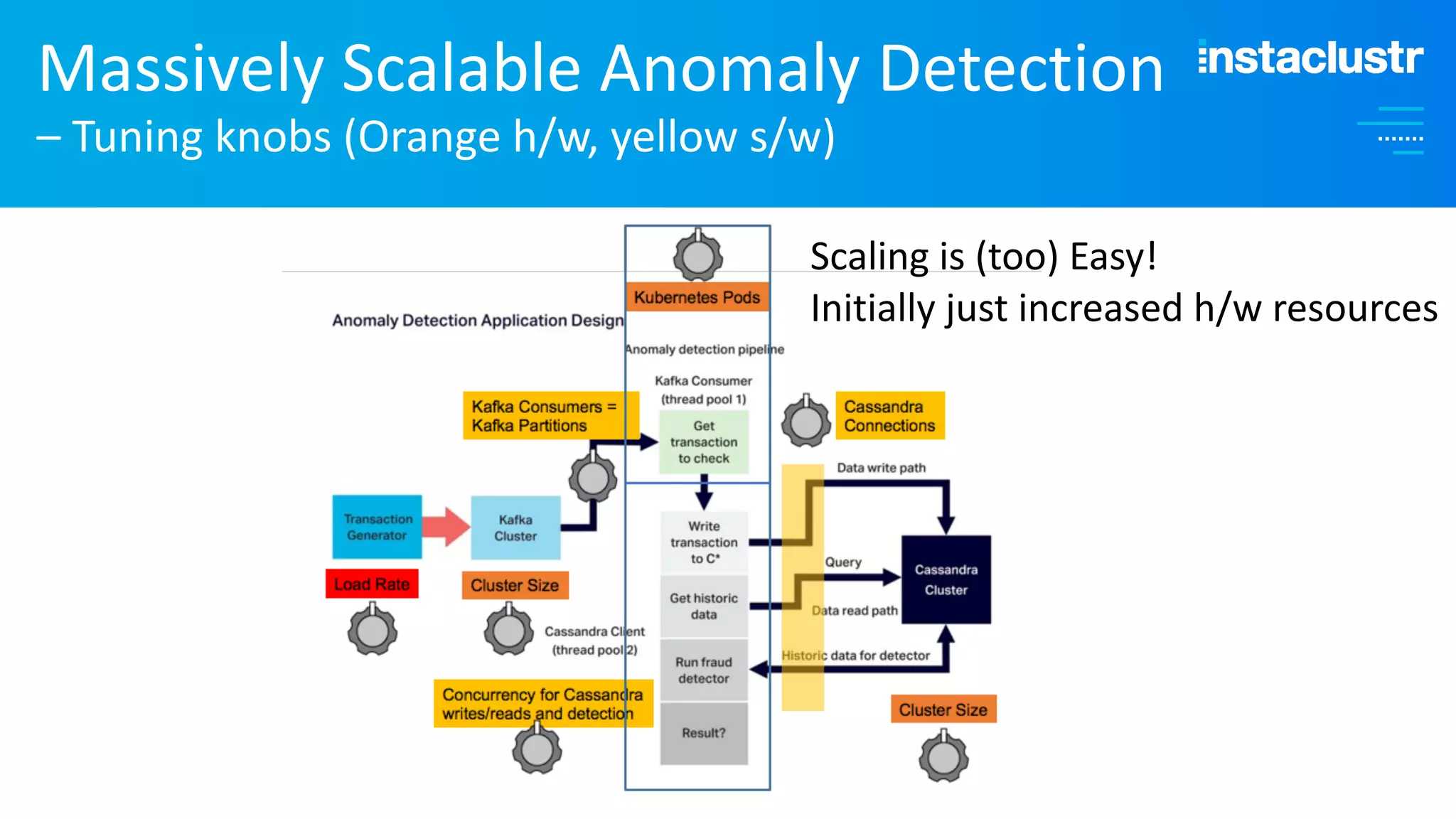
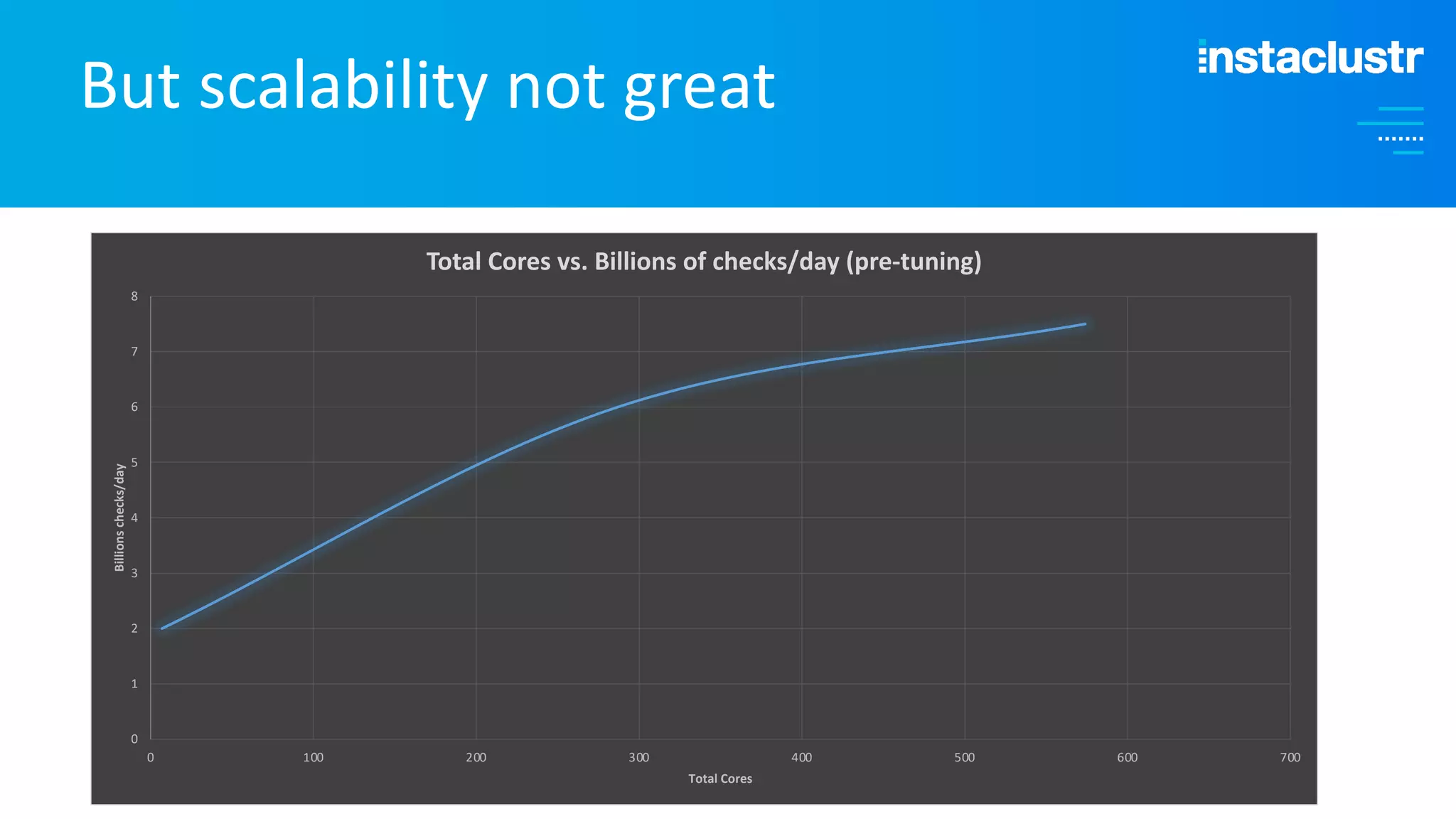
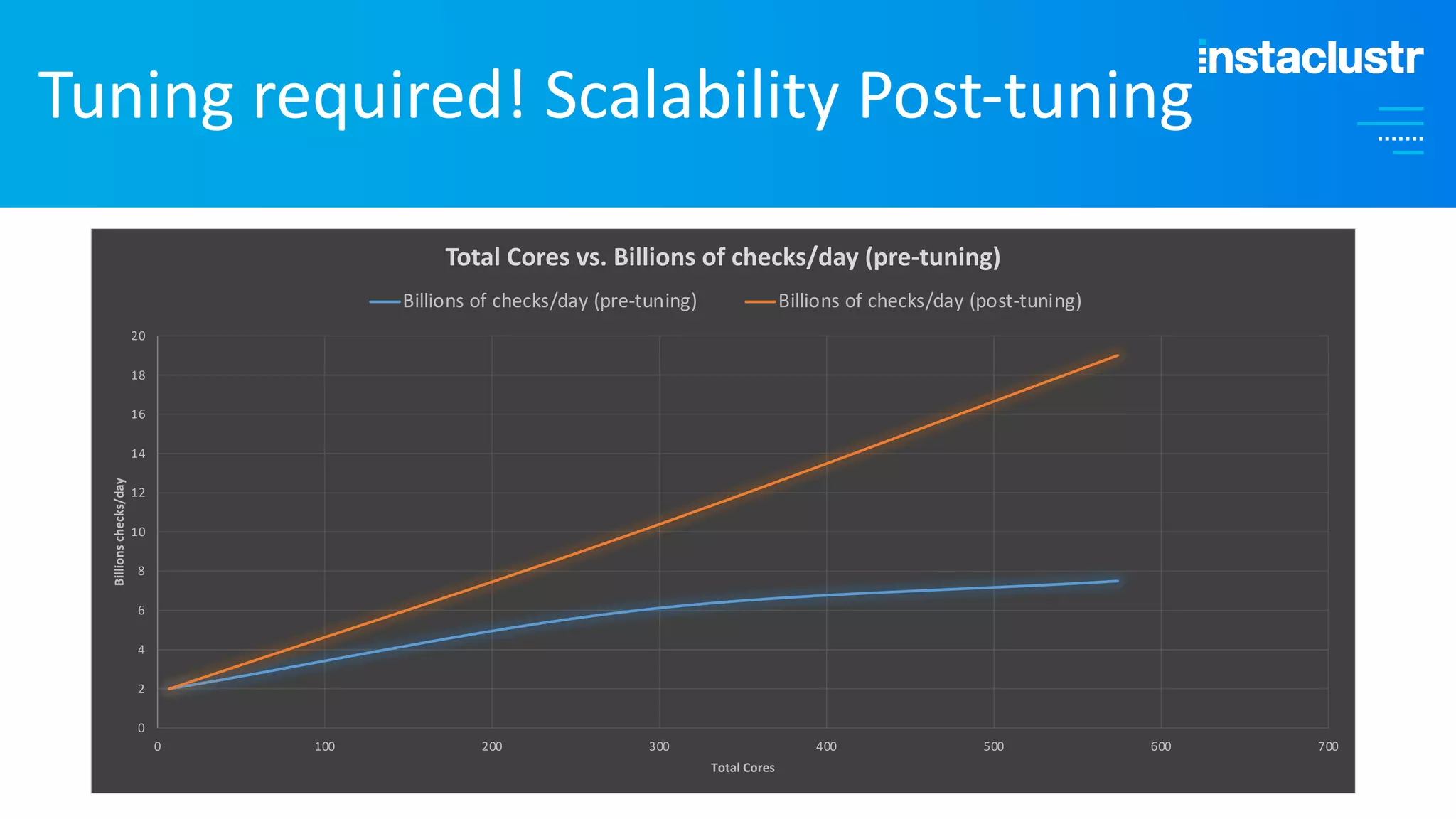
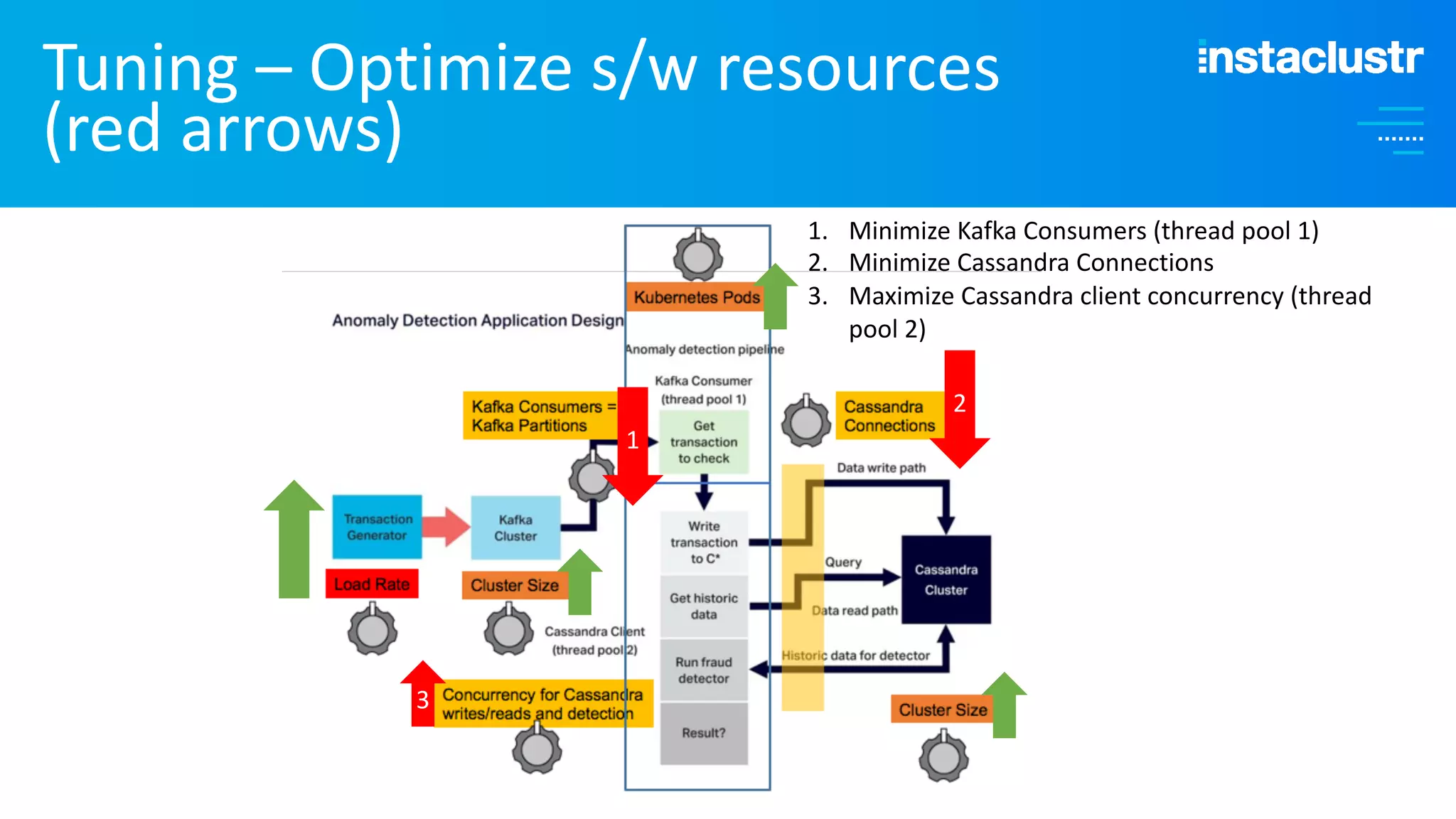
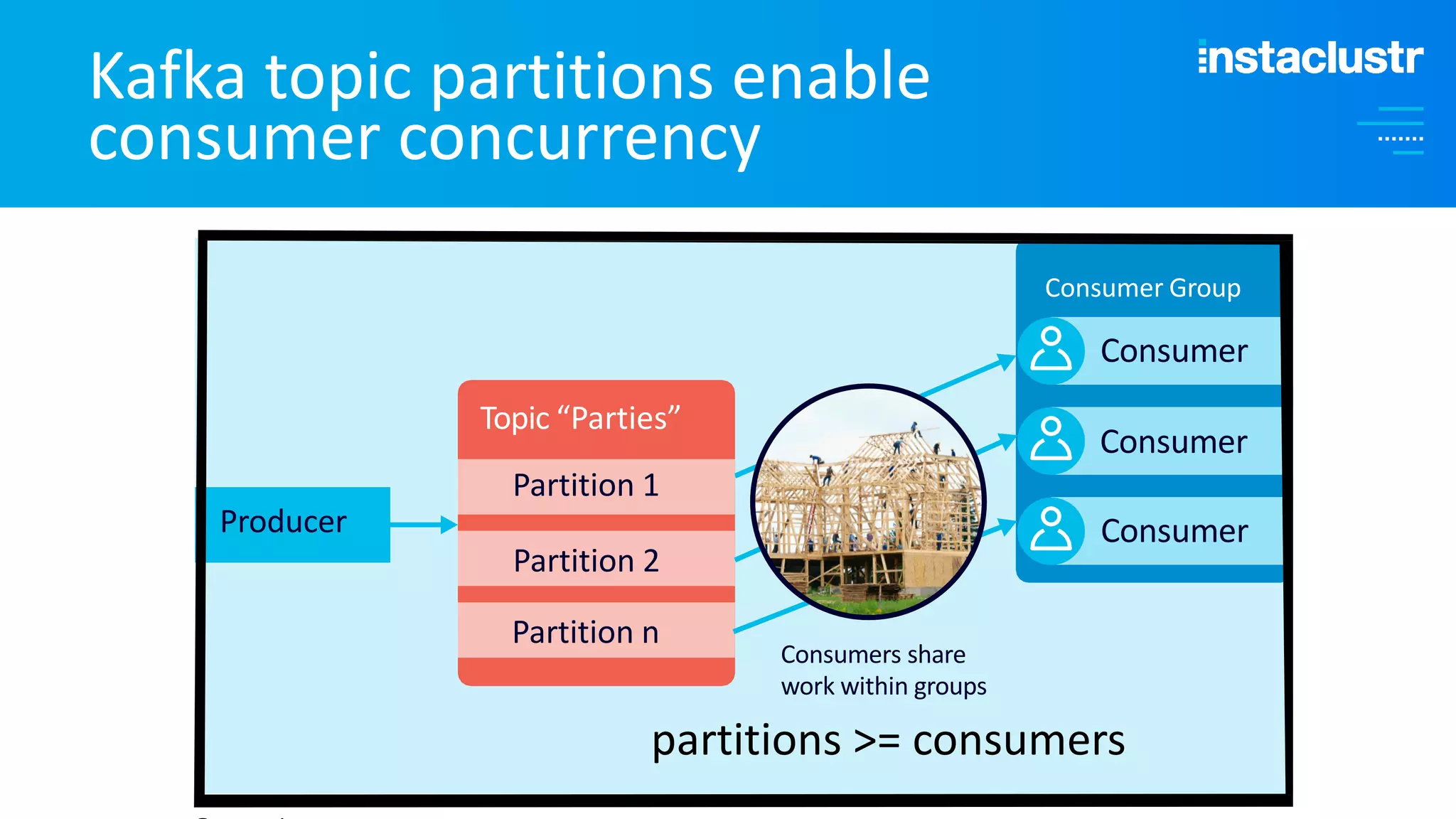
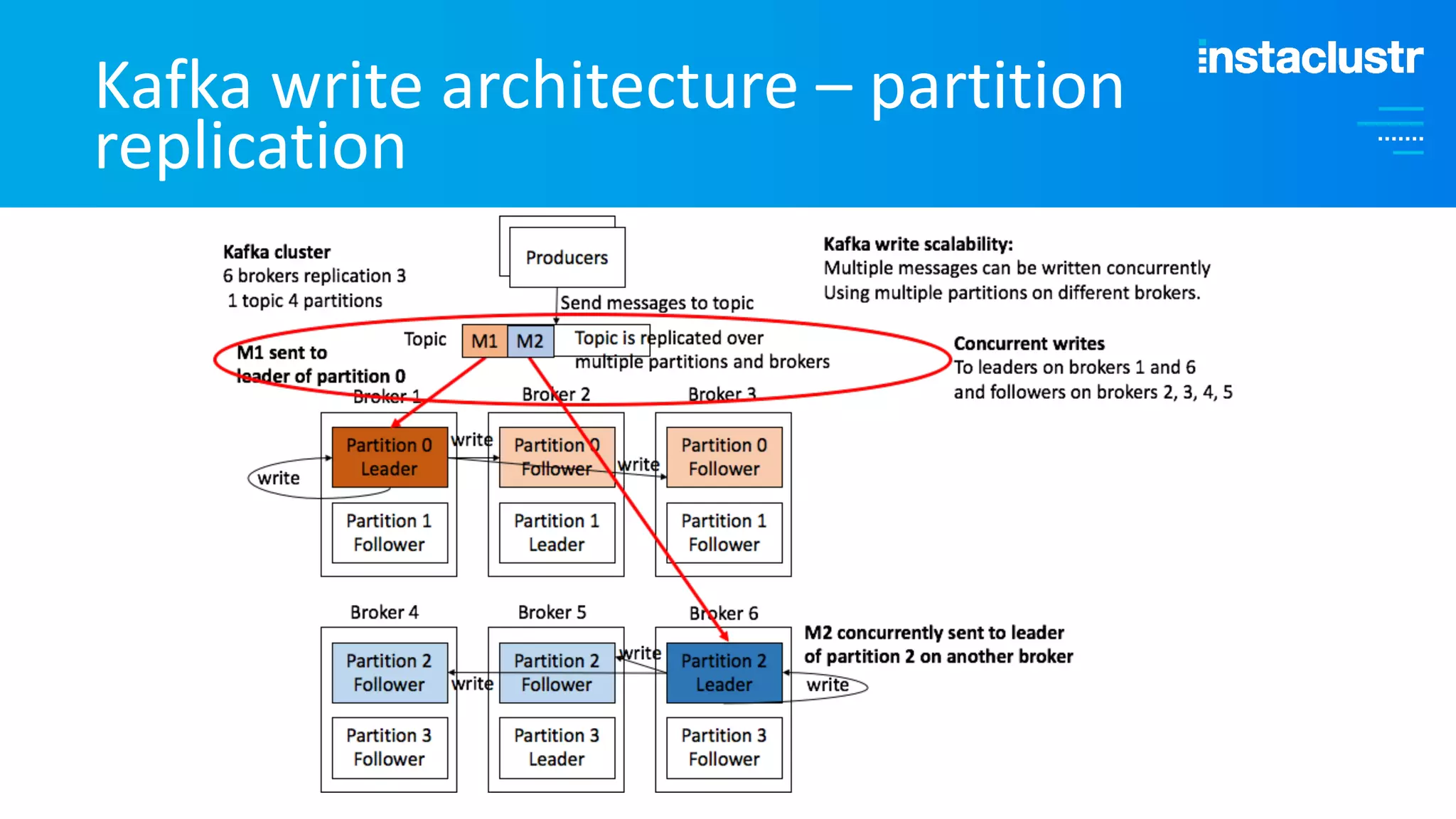
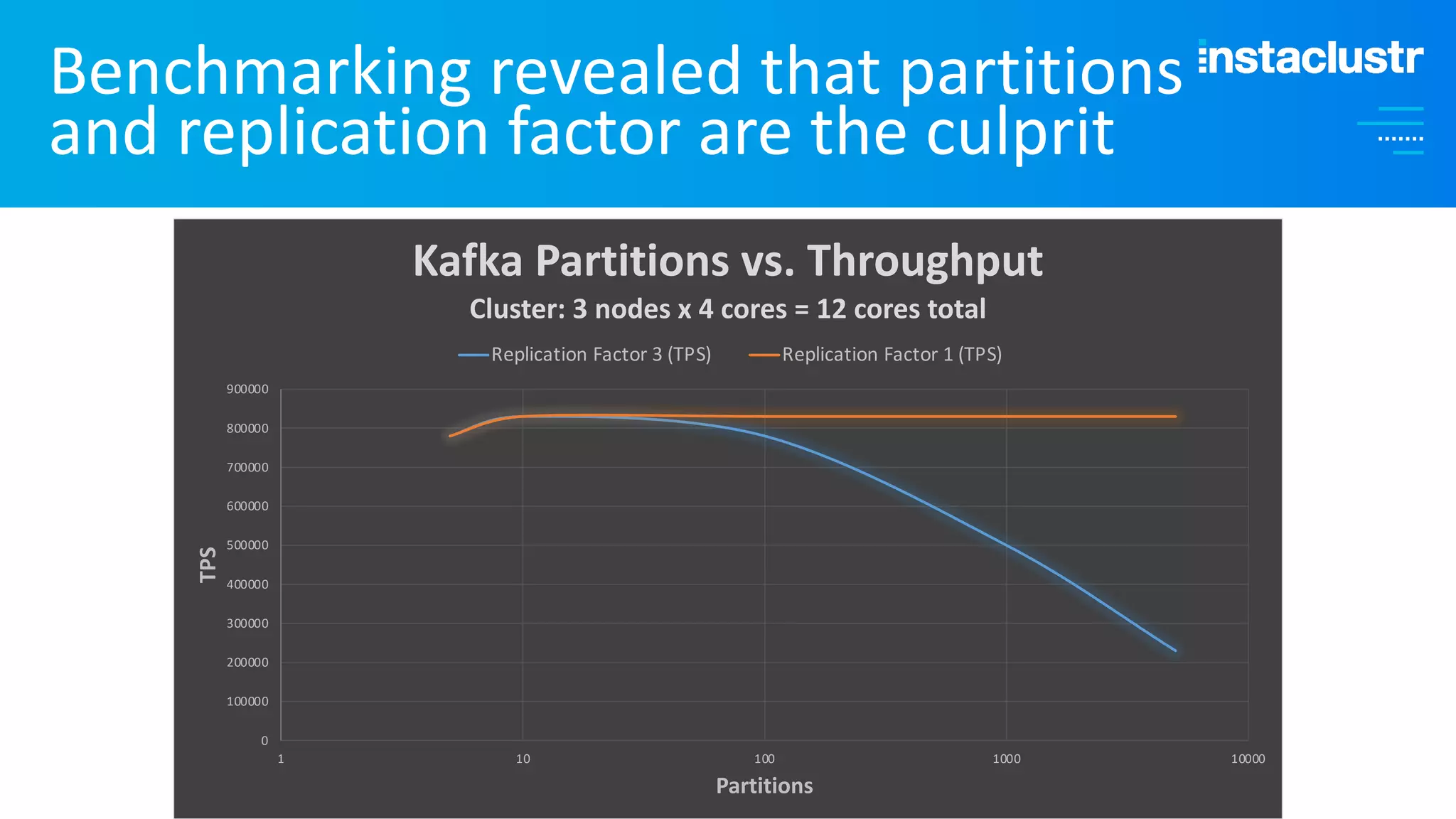
The document discusses the complexities and strategies involved in scaling open-source big data applications, focusing on technologies like Cassandra and Kafka. It highlights the methods of resizing clusters through horizontal and vertical scaling, emphasizing the importance of careful planning to avoid capacity issues during the resizing process. Additionally, it touches on anomaly detection and benchmarking challenges related to Kafka's architecture and partitioning.