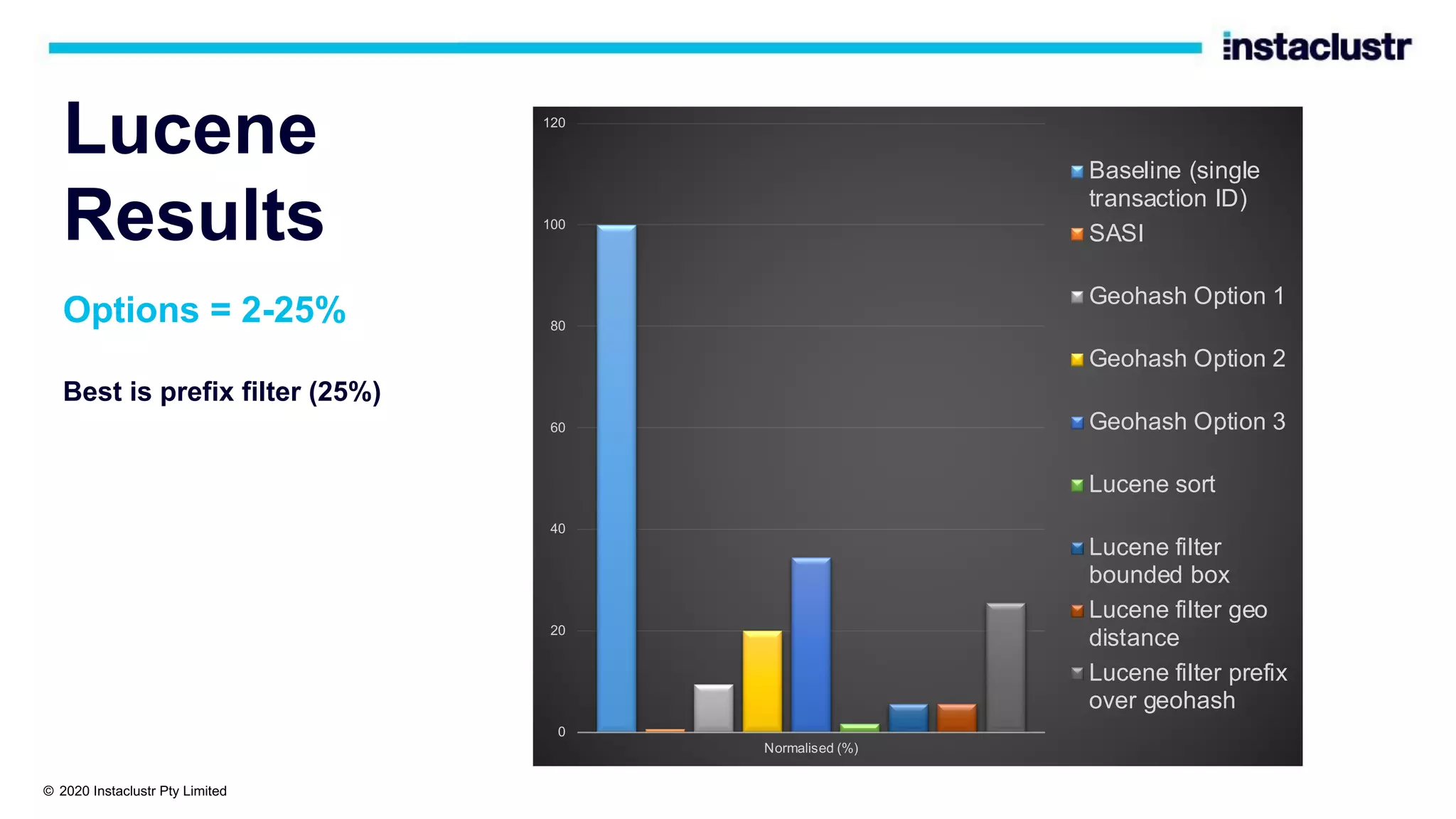
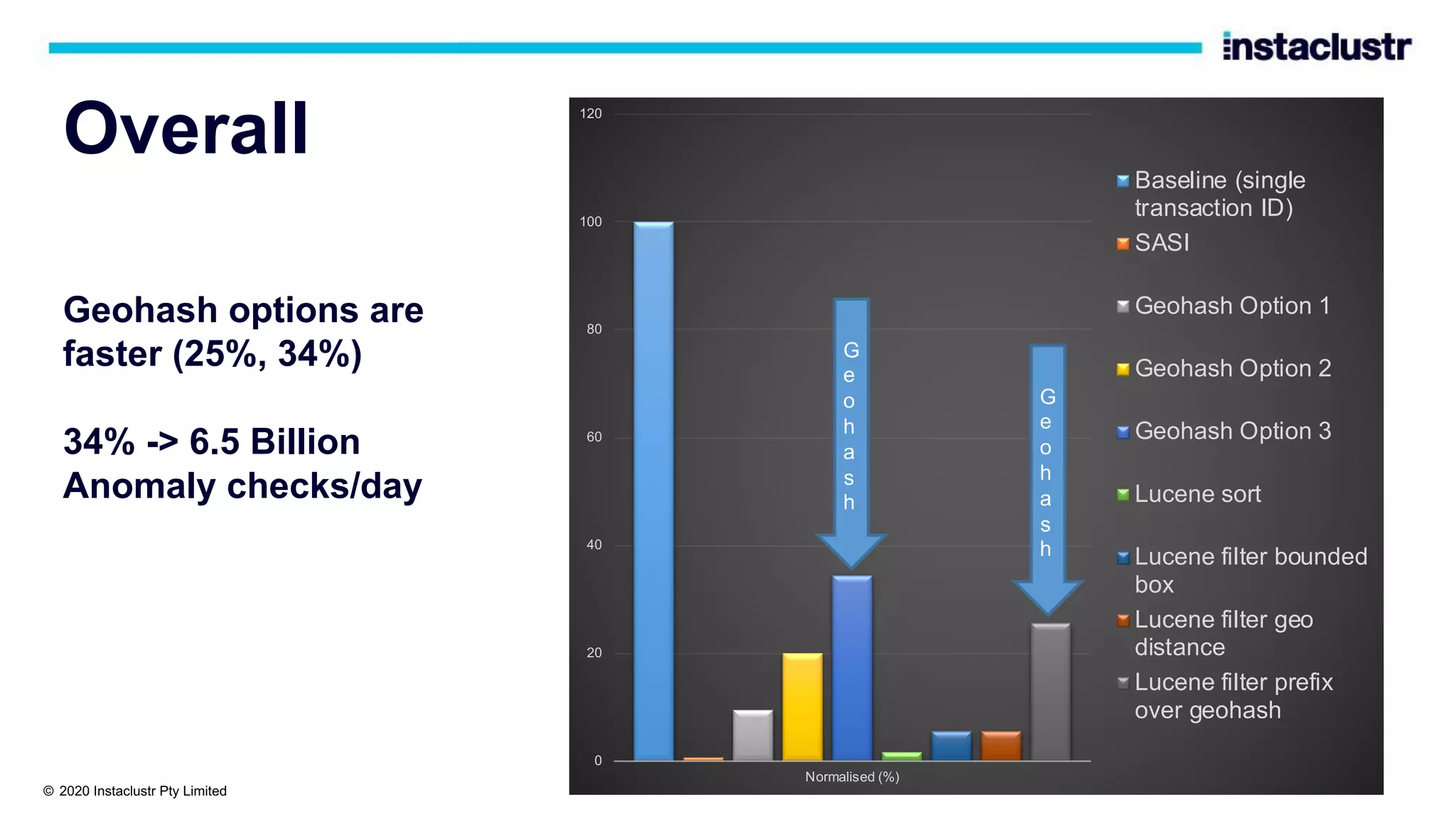
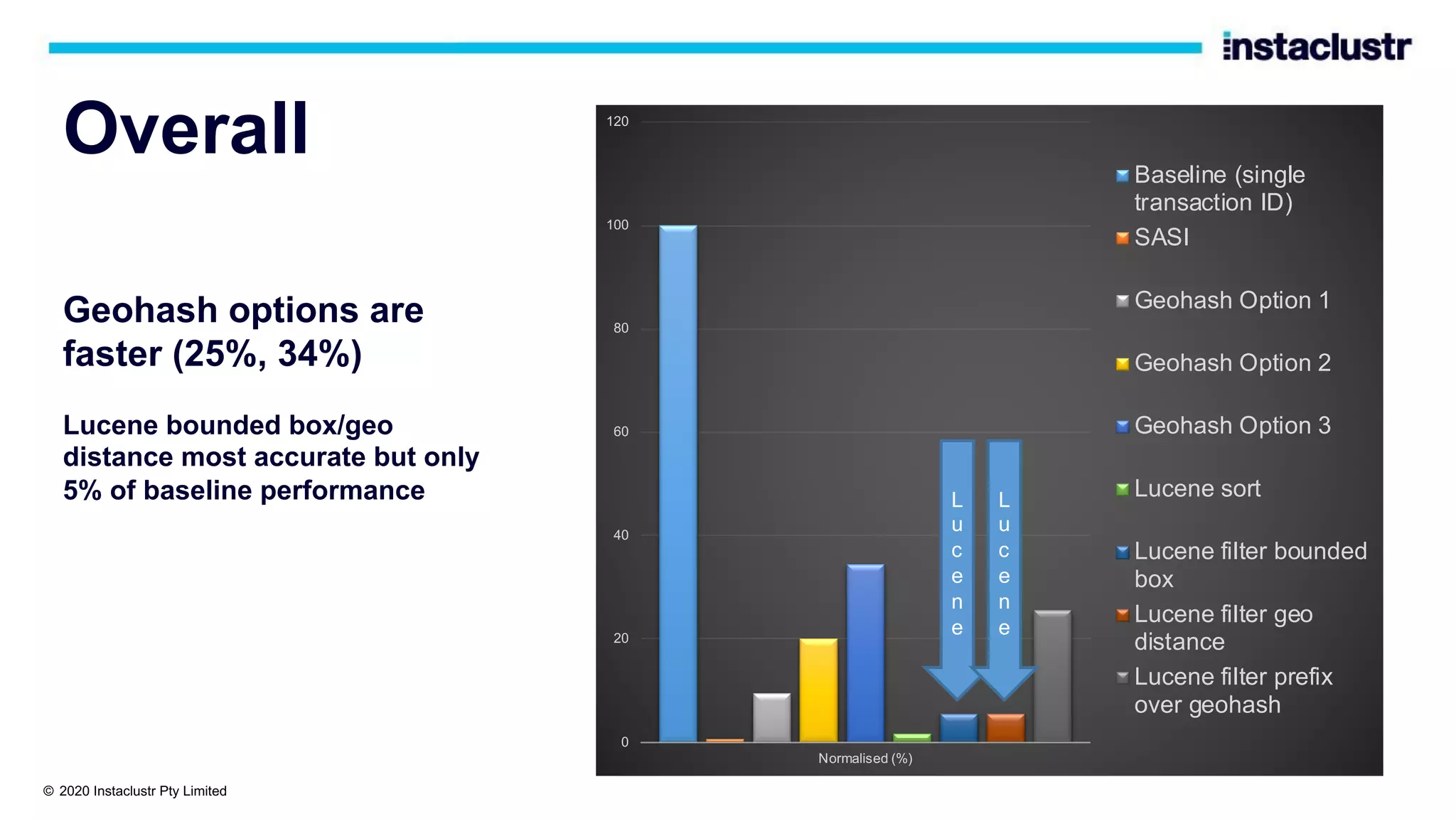
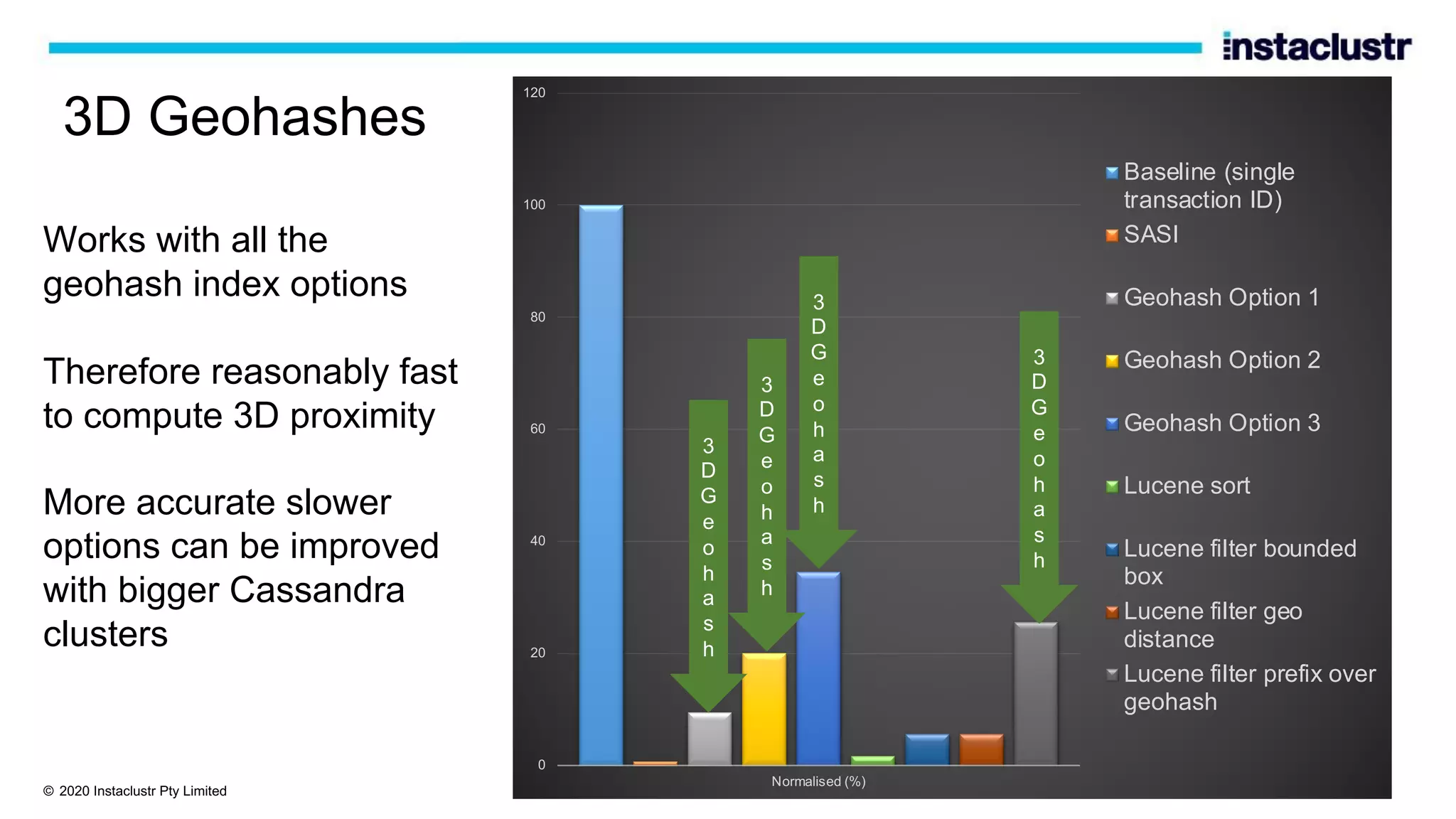
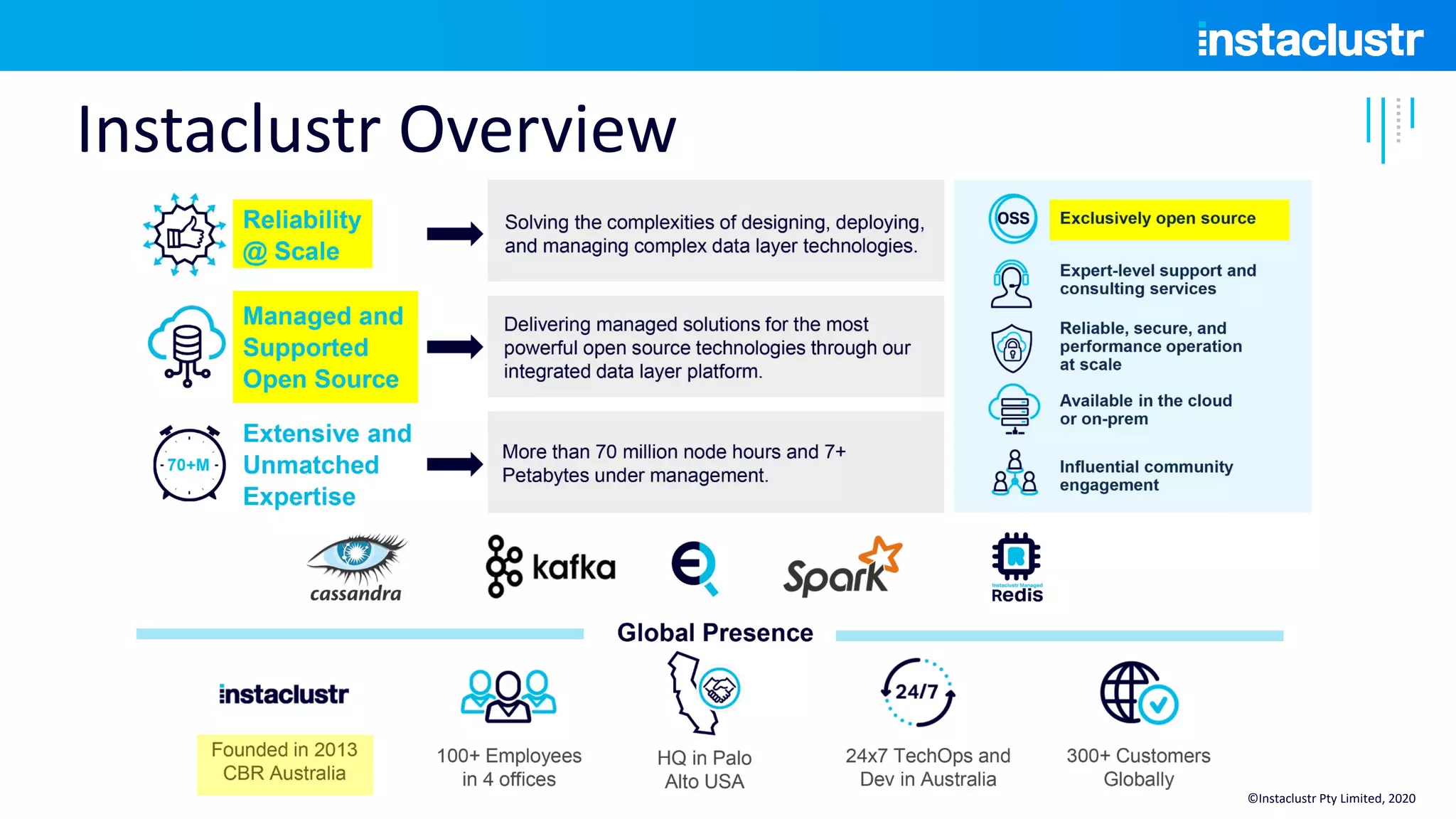
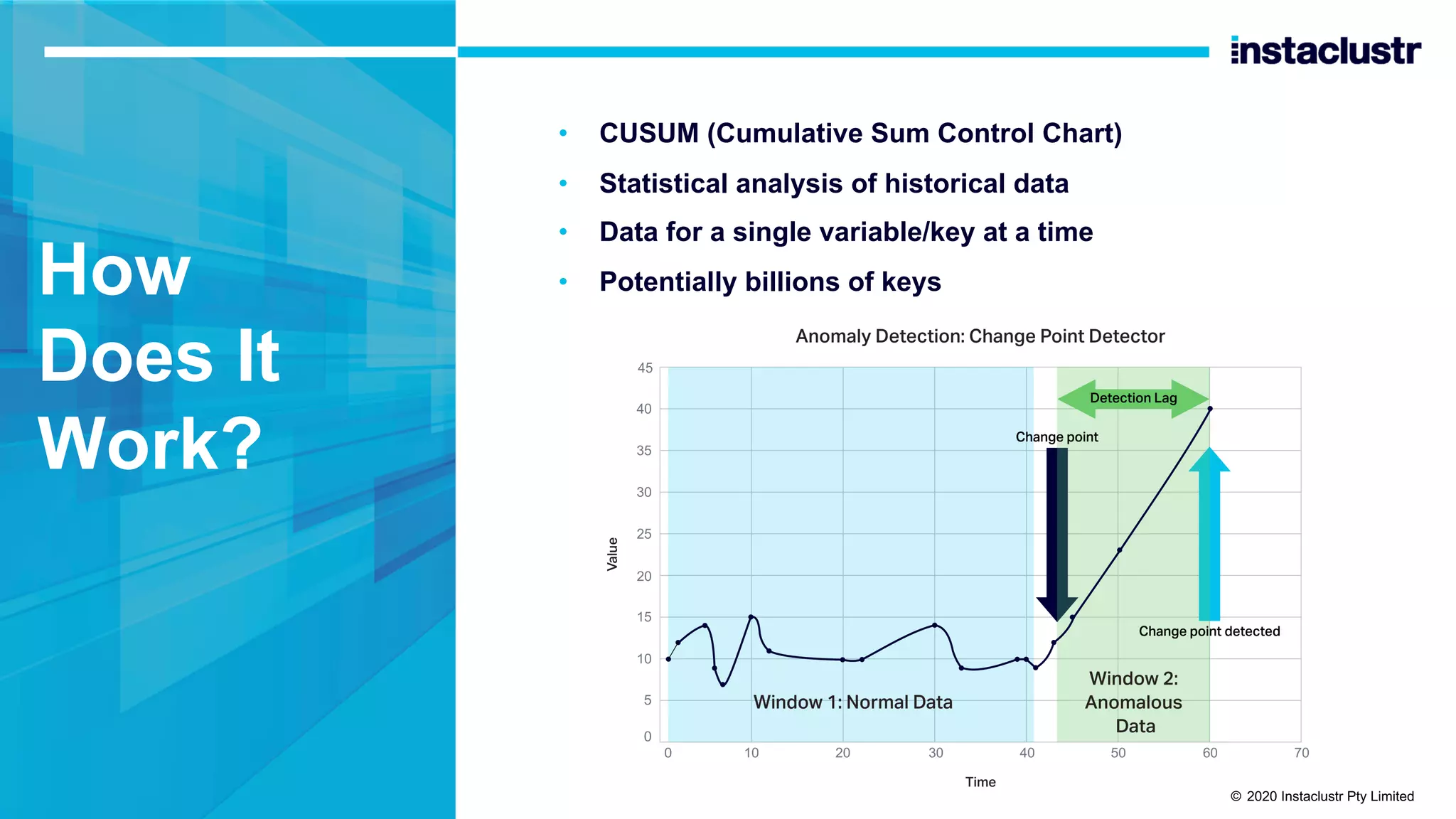
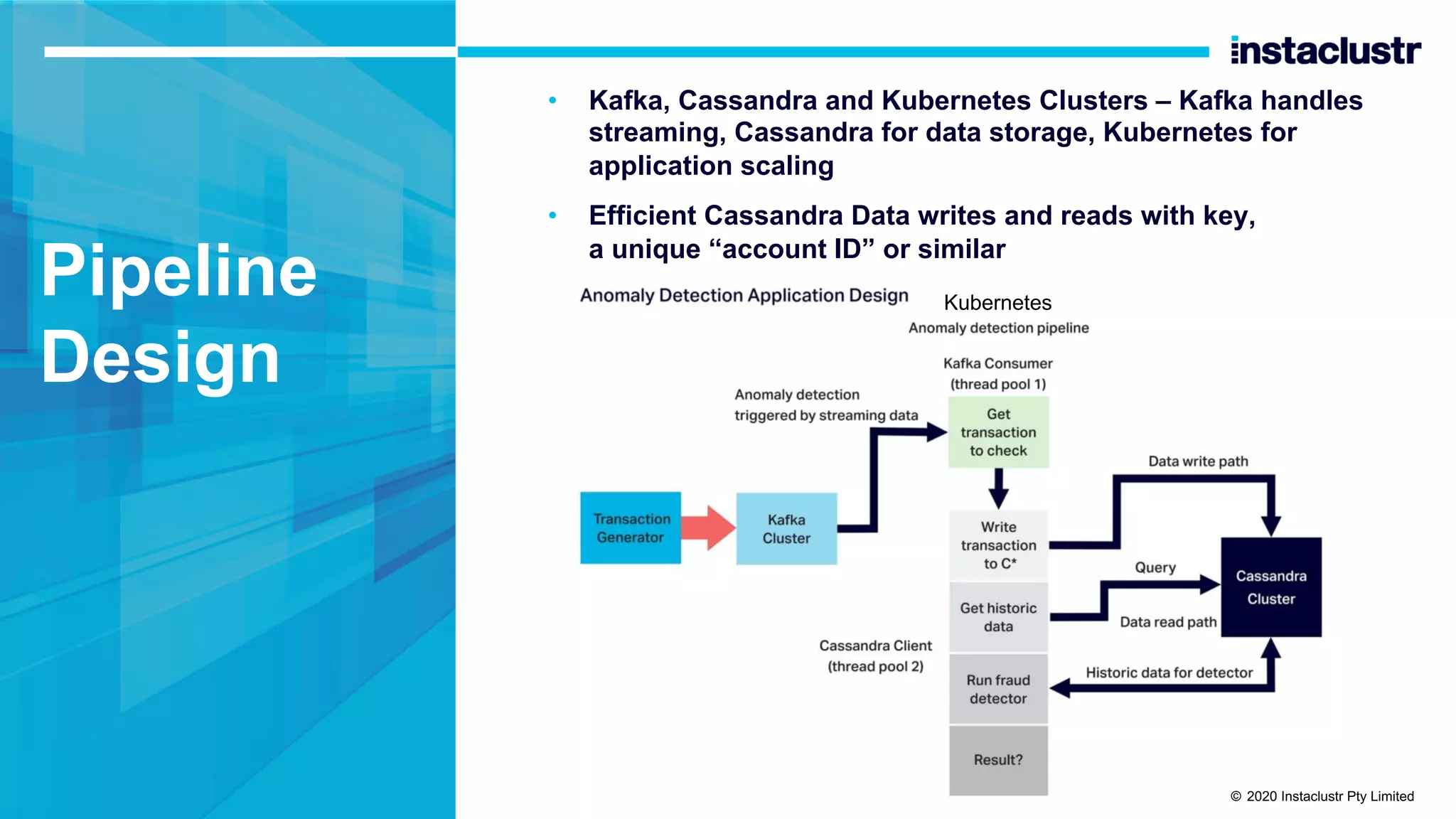
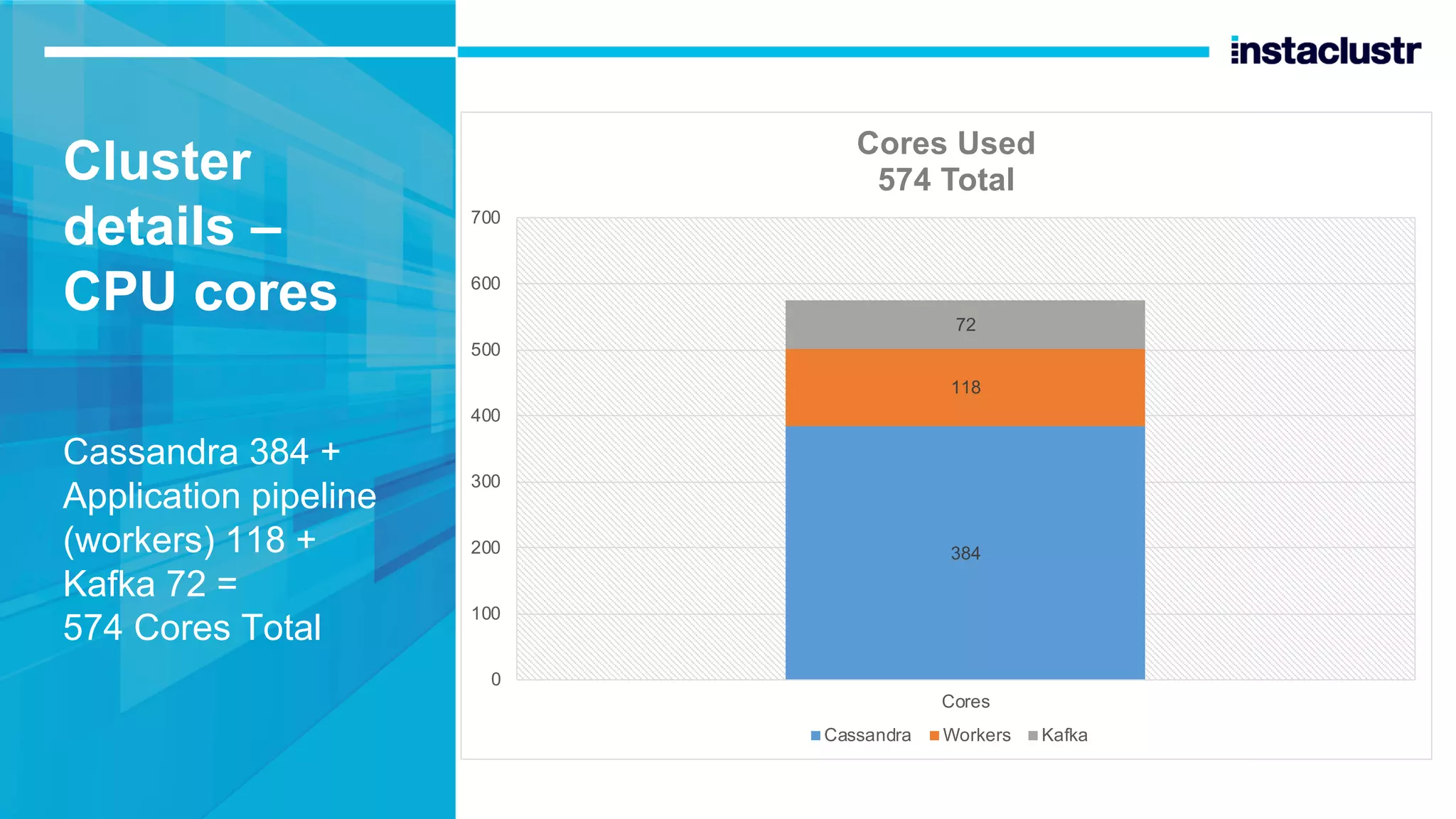
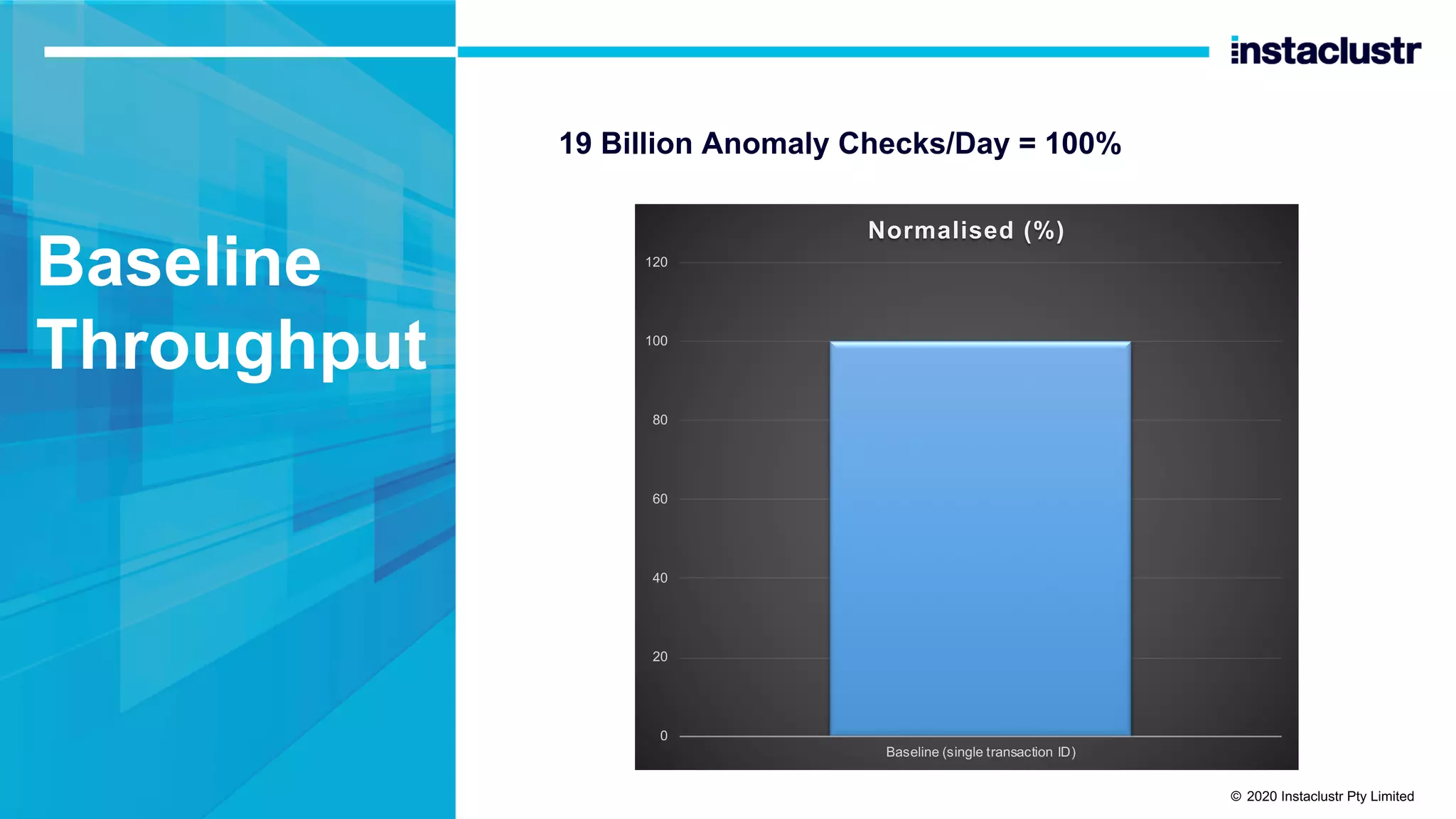
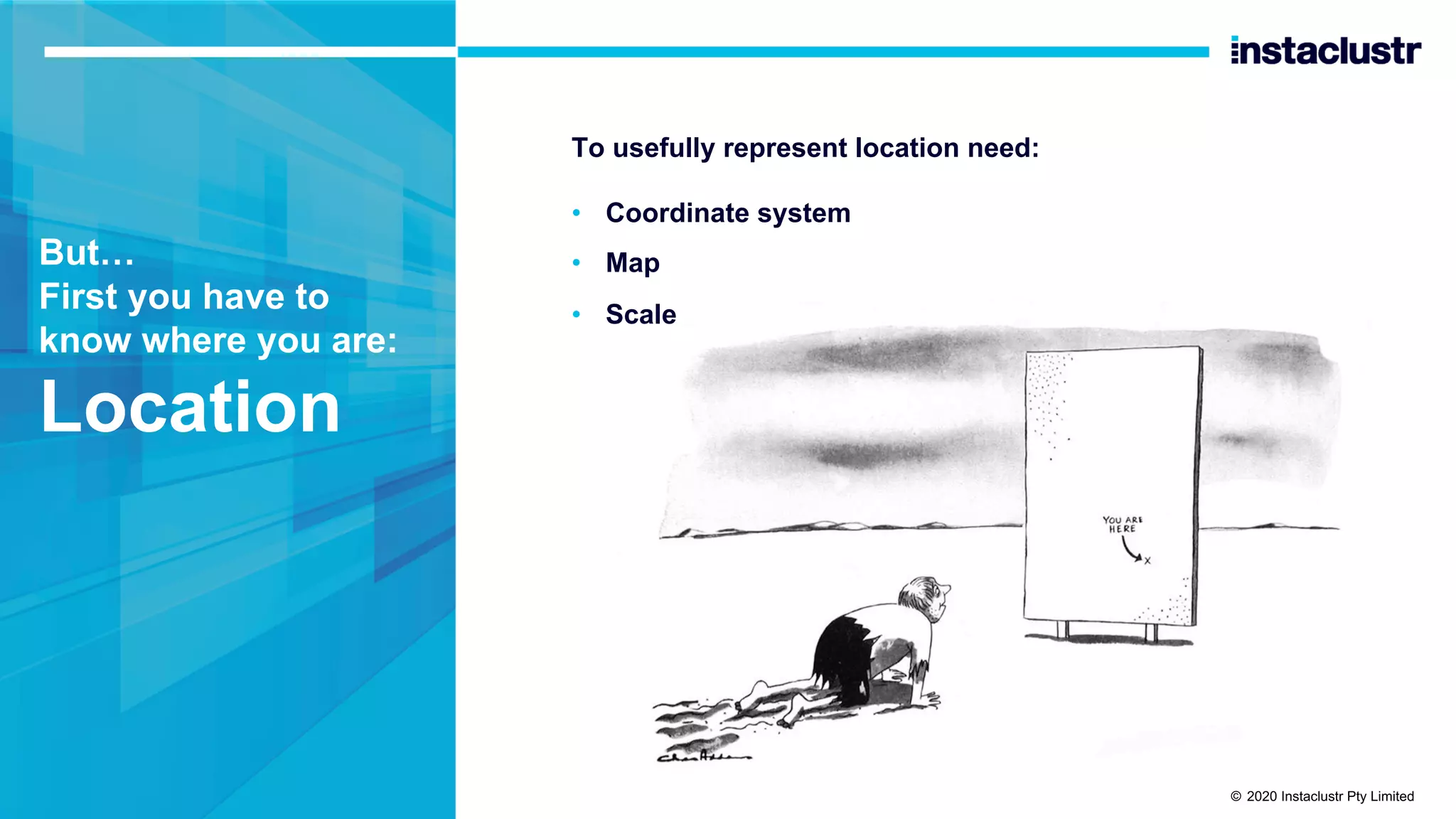
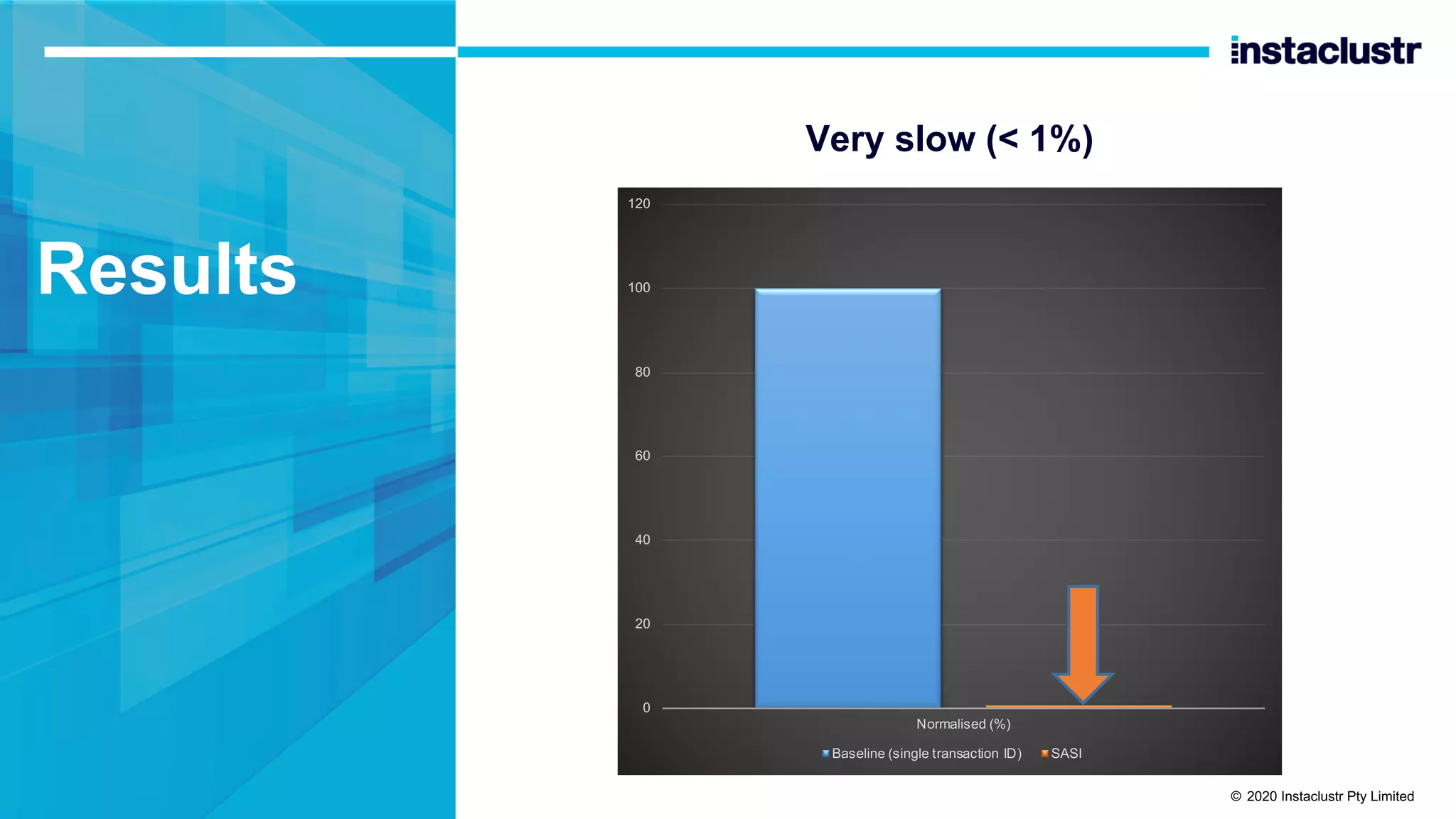
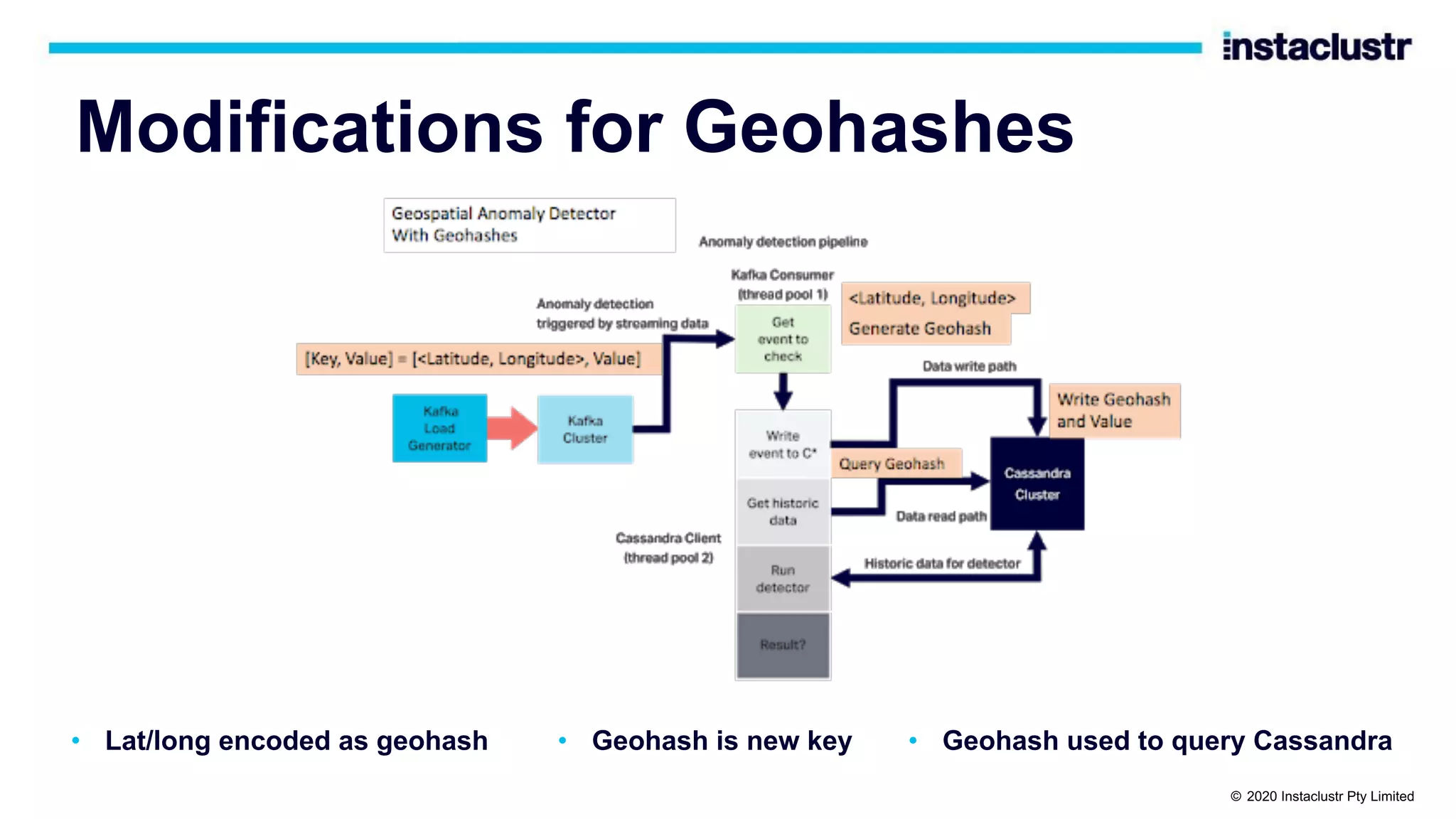
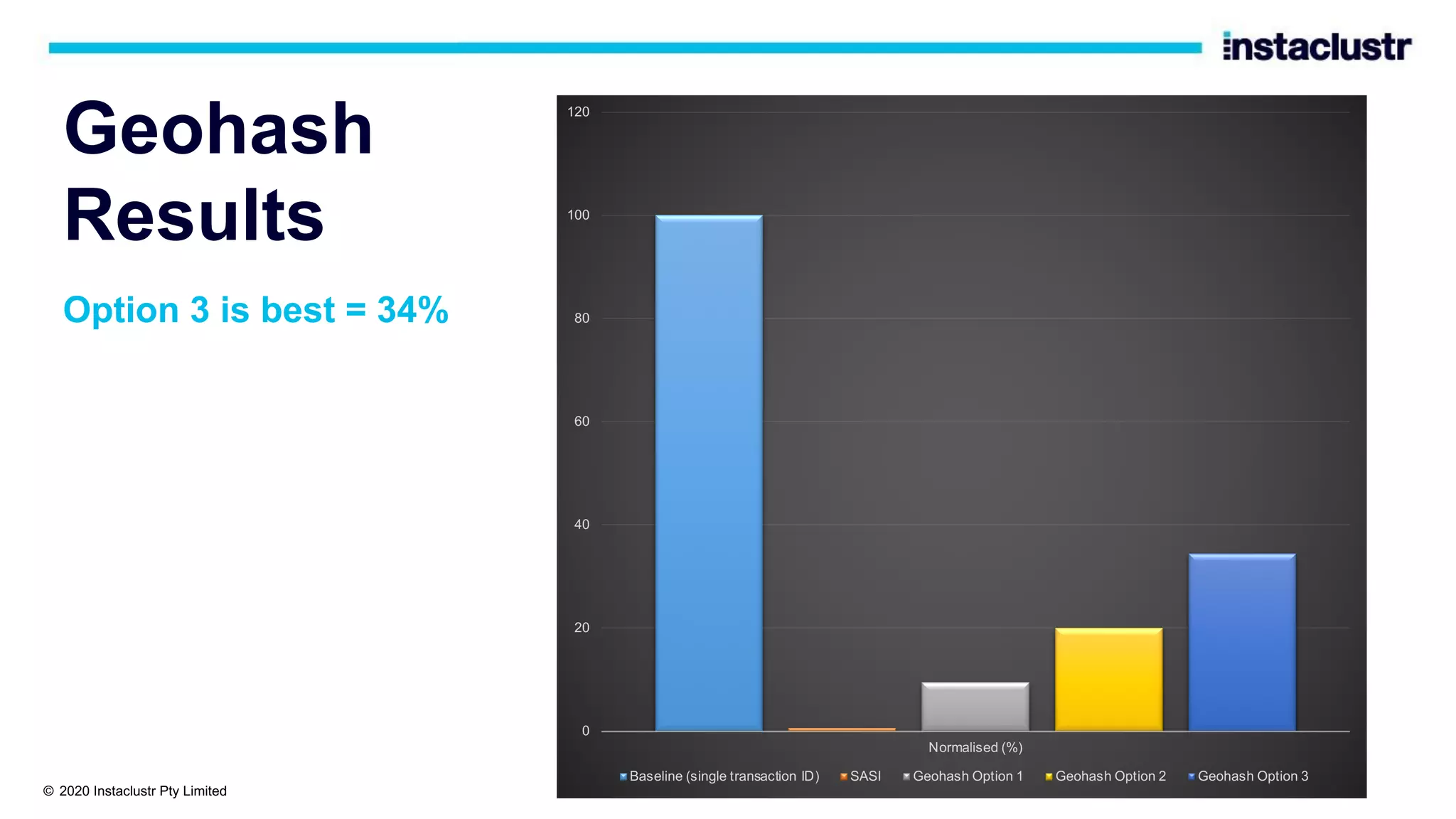
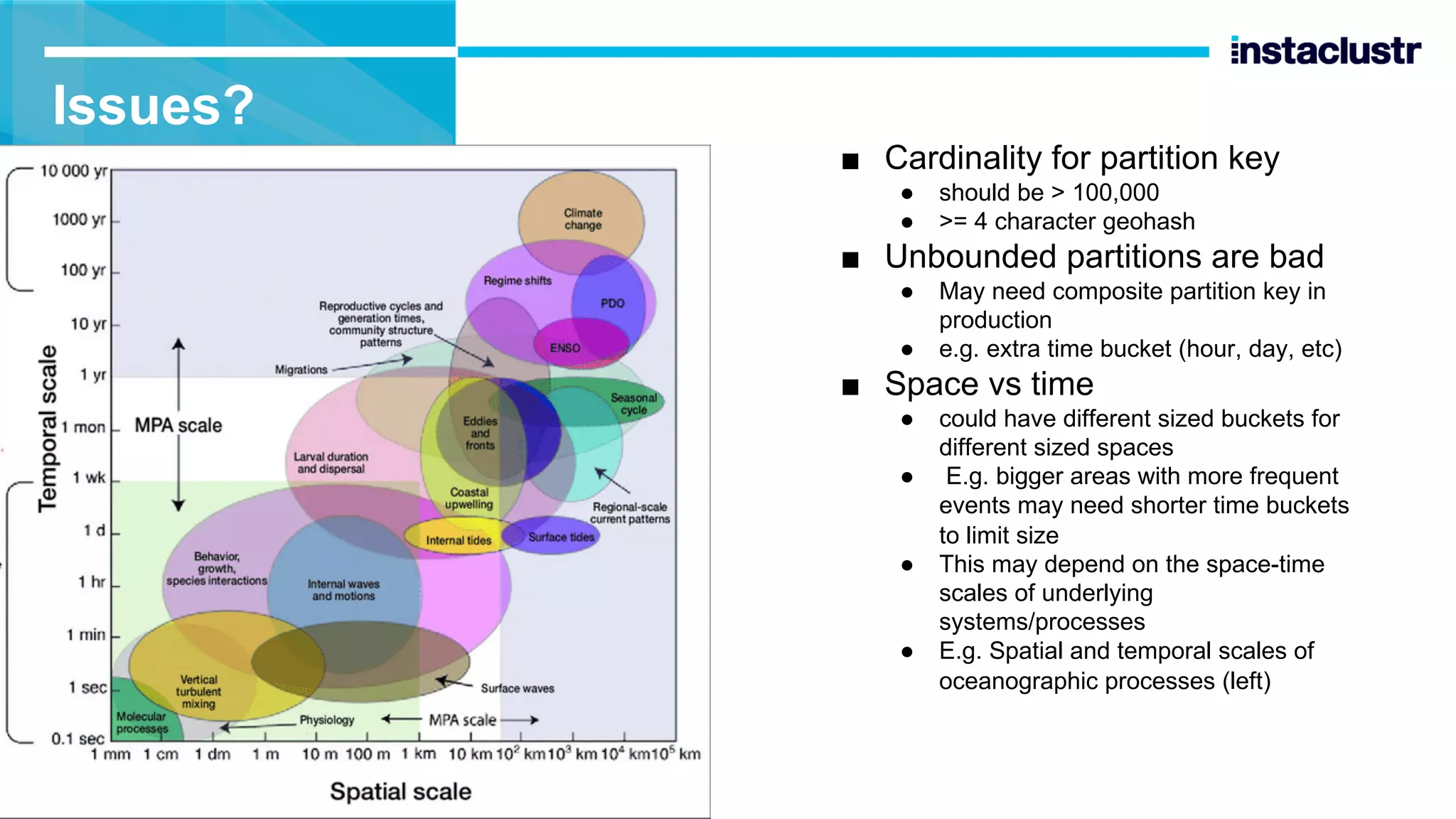
The document discusses the implementation of massively scalable real-time geospatial data processing using Apache Kafka and Cassandra, focusing on anomaly detection and spatial data representation. It outlines various methods for location querying and indexing, including the use of bounding boxes, secondary indexes, and geohashes, while addressing challenges such as efficiency and processing speed. Additionally, it explores the design of data pipelines and the use of clustering columns in Cassandra for better querying performance.


















![Bounding Boxes and Cassandra? • Use ”country” partition key, Lat/long/time clustering keys • But can’t run the query with multiple inequalities CREATE TABLE latlong ( country text, lat double, long double, time timestamp, PRIMARY KEY (country, lat, long, time) ) WITH CLUSTERING ORDER BY (lat ASC, long ASC, time DESC); select * from latlong where country='nz' and lat>= -39.58 and lat <= -38.67 and long >= 175.18 and long <= 176.08 limit 50; InvalidRequest: Error from server: code=2200 [Invalid query] message="Clustering column "long" cannot be restricted (preceding column "lat" is restricted by a non-EQ relation)" © 2020 Instaclustr Pty Limited](https://image.slidesharecdn.com/brebnerpaulgeospatialtrack-201001231718/75/Massively-Scalable-Real-time-Geospatial-Anomaly-Detection-with-Apache-Kafka-and-Cassandra-ApacheCon-2020-26-2048.jpg)
















![Search Options • Sort • Sophisticated but complex semantics (see the docs) SELECT value FROM latlong_lucene WHERE expr(latlong_index, '{ sort: [ {field: "place", type: "geo_distance", latitude: " + <lat> + ", longitude: " + <long> + "}, {field: "time", reverse: true} ] }') and geohash1=<geohash> limit 50; © 2020 Instaclustr Pty Limited](https://image.slidesharecdn.com/brebnerpaulgeospatialtrack-201001231718/75/Massively-Scalable-Real-time-Geospatial-Anomaly-Detection-with-Apache-Kafka-and-Cassandra-ApacheCon-2020-50-2048.jpg)


![Search Options: Prefix Filter Prefix search is useful for searching larger areas over a single geohash column as you can search for a substring SELECT value FROM latlong_lucene WHERE expr(latlong_index, '{ filter: [ {type: "prefix", field: "geohash1", value: <geohash>} ] }') limit 50 Similar to inequality over clustering column © 2020 Instaclustr Pty Limited](https://image.slidesharecdn.com/brebnerpaulgeospatialtrack-201001231718/75/Massively-Scalable-Real-time-Geospatial-Anomaly-Detection-with-Apache-Kafka-and-Cassandra-ApacheCon-2020-53-2048.jpg)