Download as PDF, PPTX


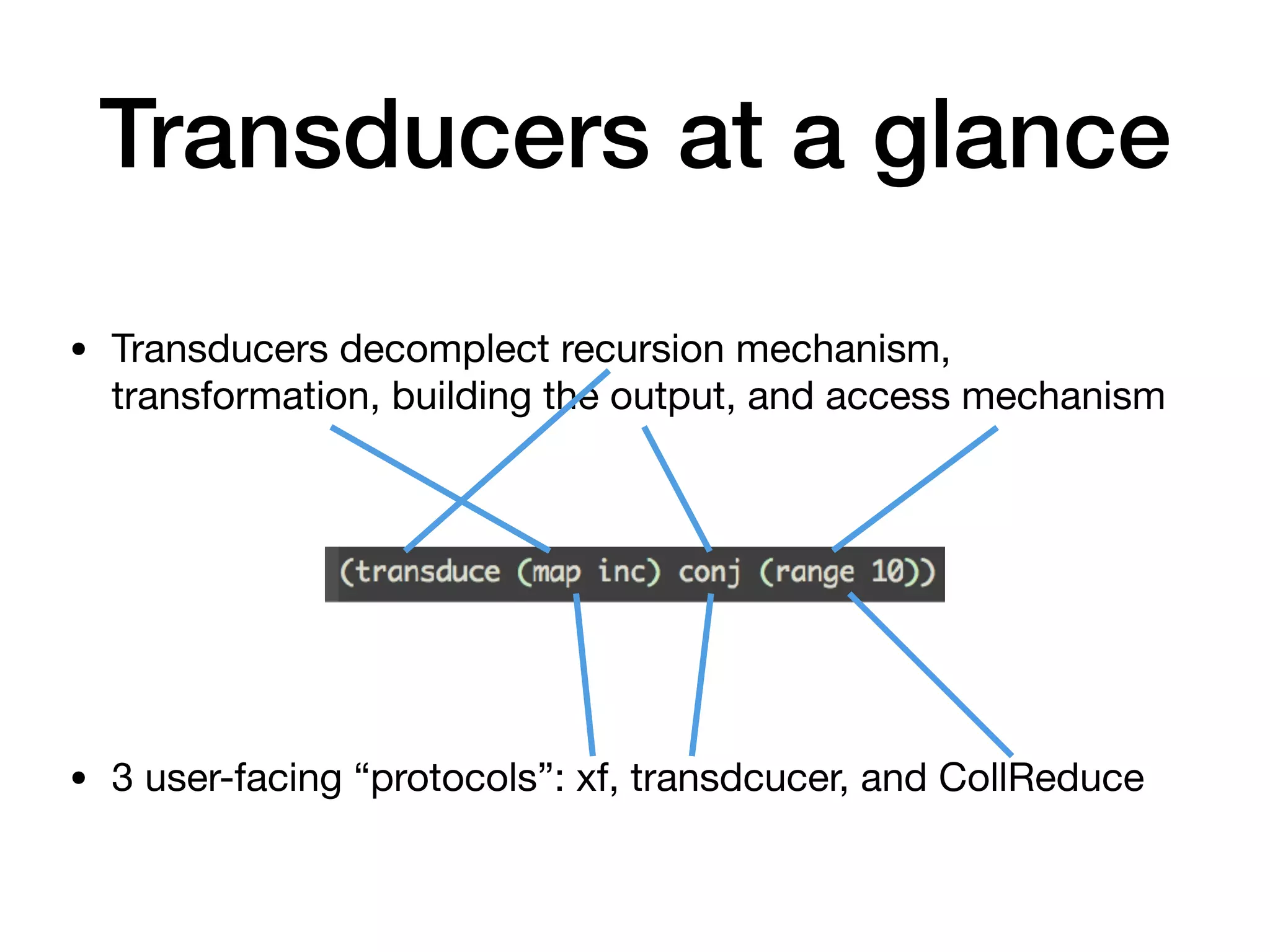















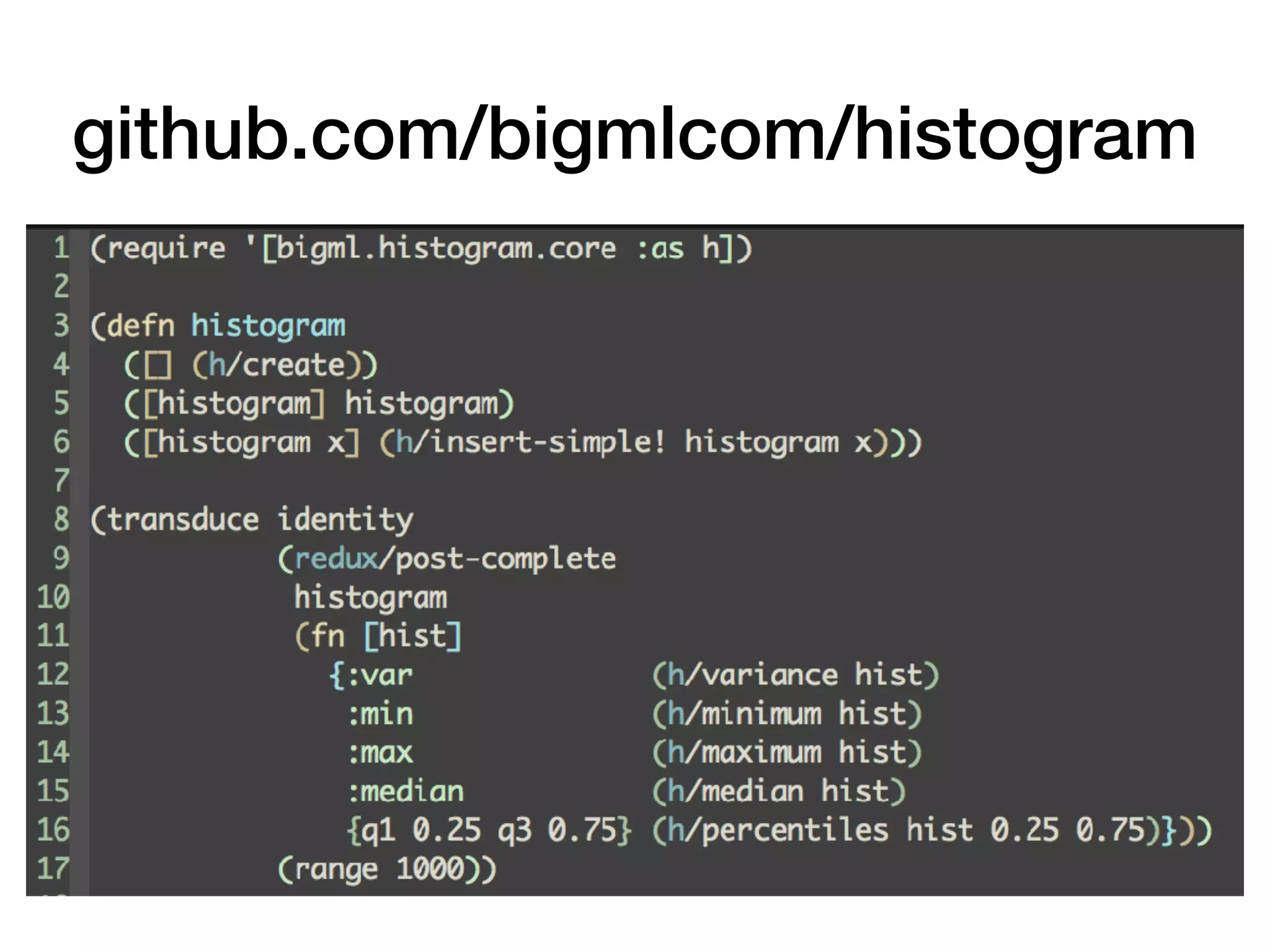











The document discusses online statistical analysis using transducers and sketch algorithms, highlighting their effectiveness in handling large datasets through modularization and performance optimization. It covers various statistical methods and techniques, including histograms and distributions, and emphasizes that approximations can often be sufficient. Key takeaways include the usefulness of transducers for efficiency and the importance of having readily available distributions for data analysis.