Downloaded 57 times


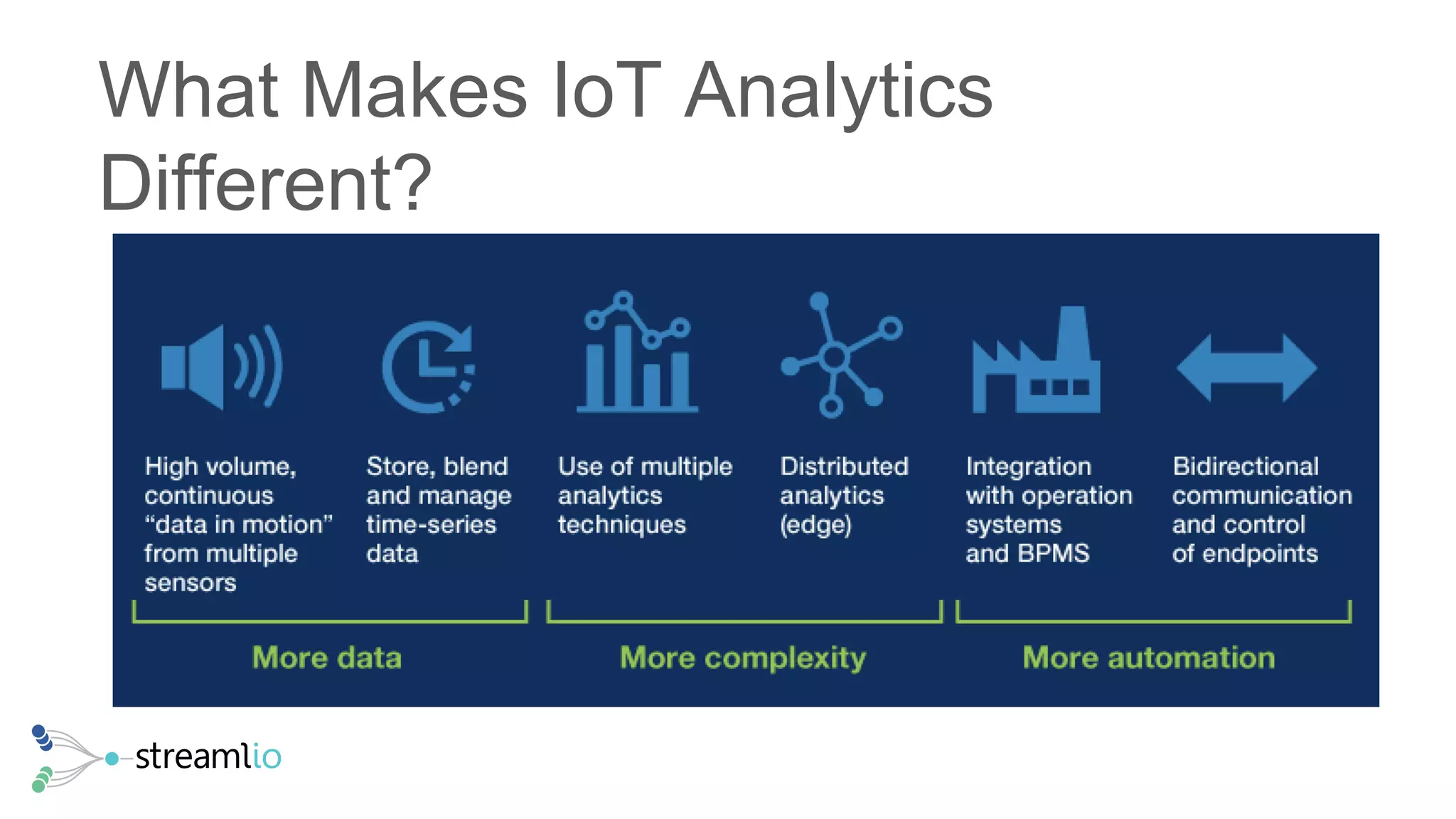

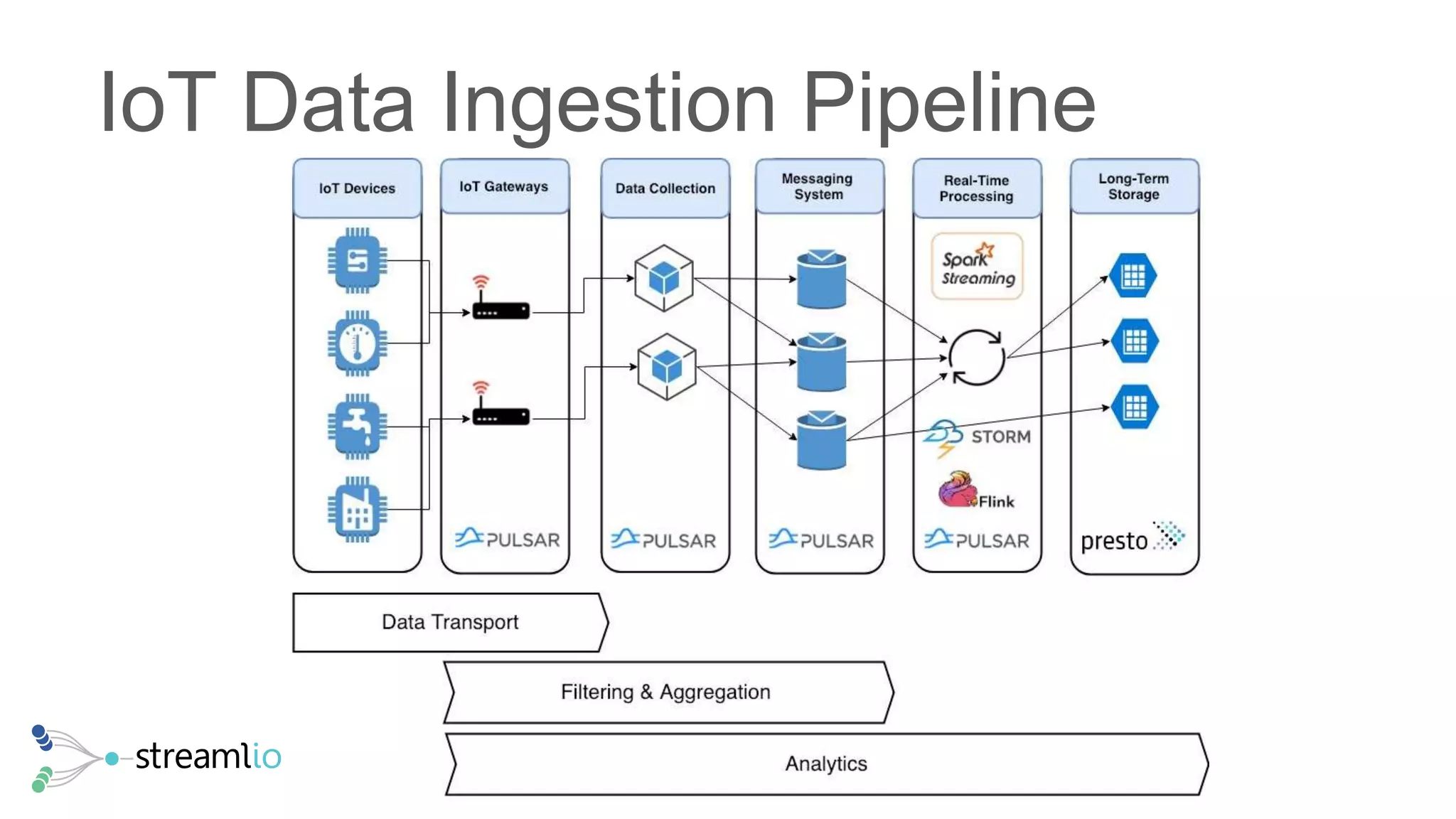

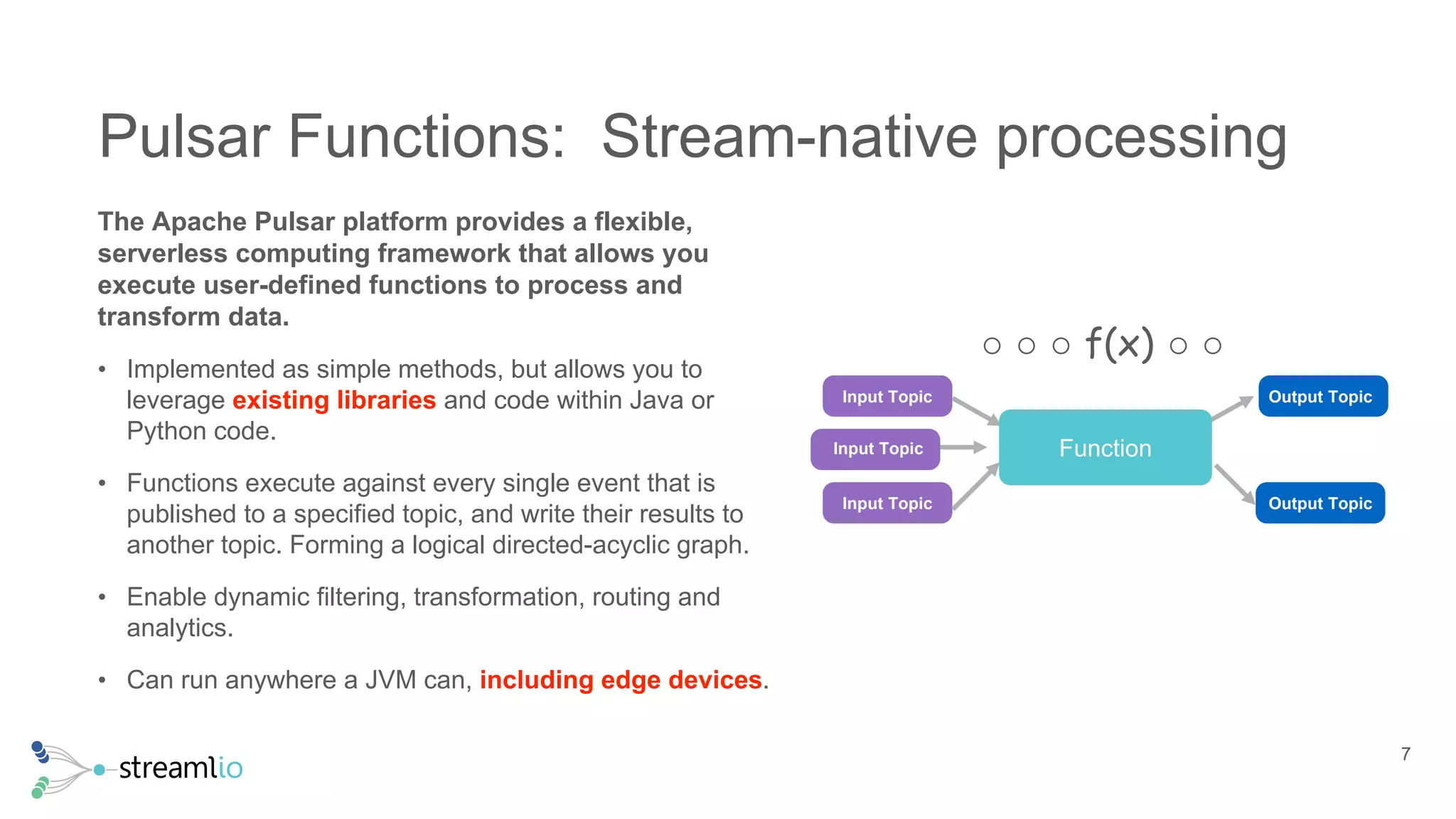
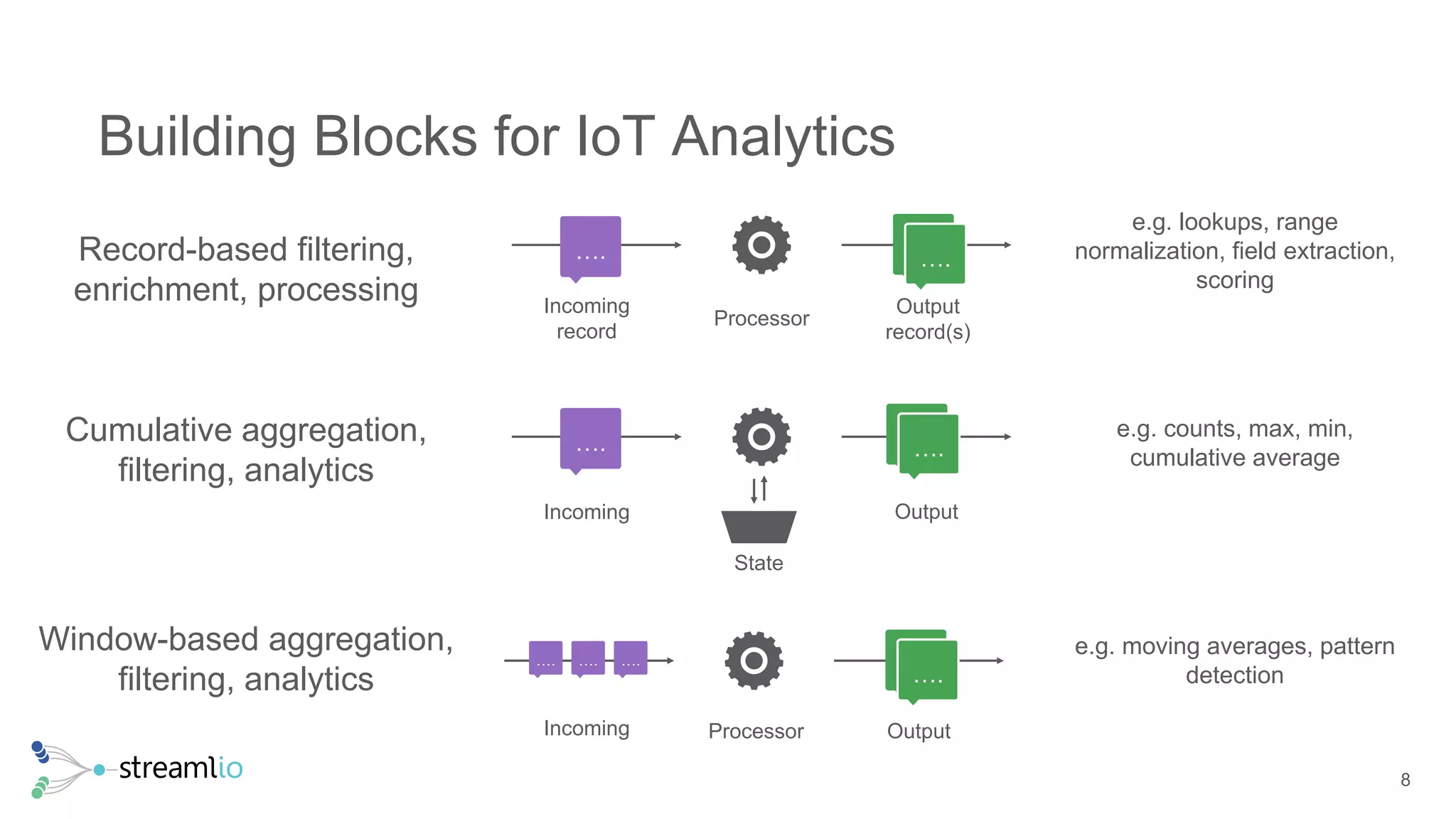








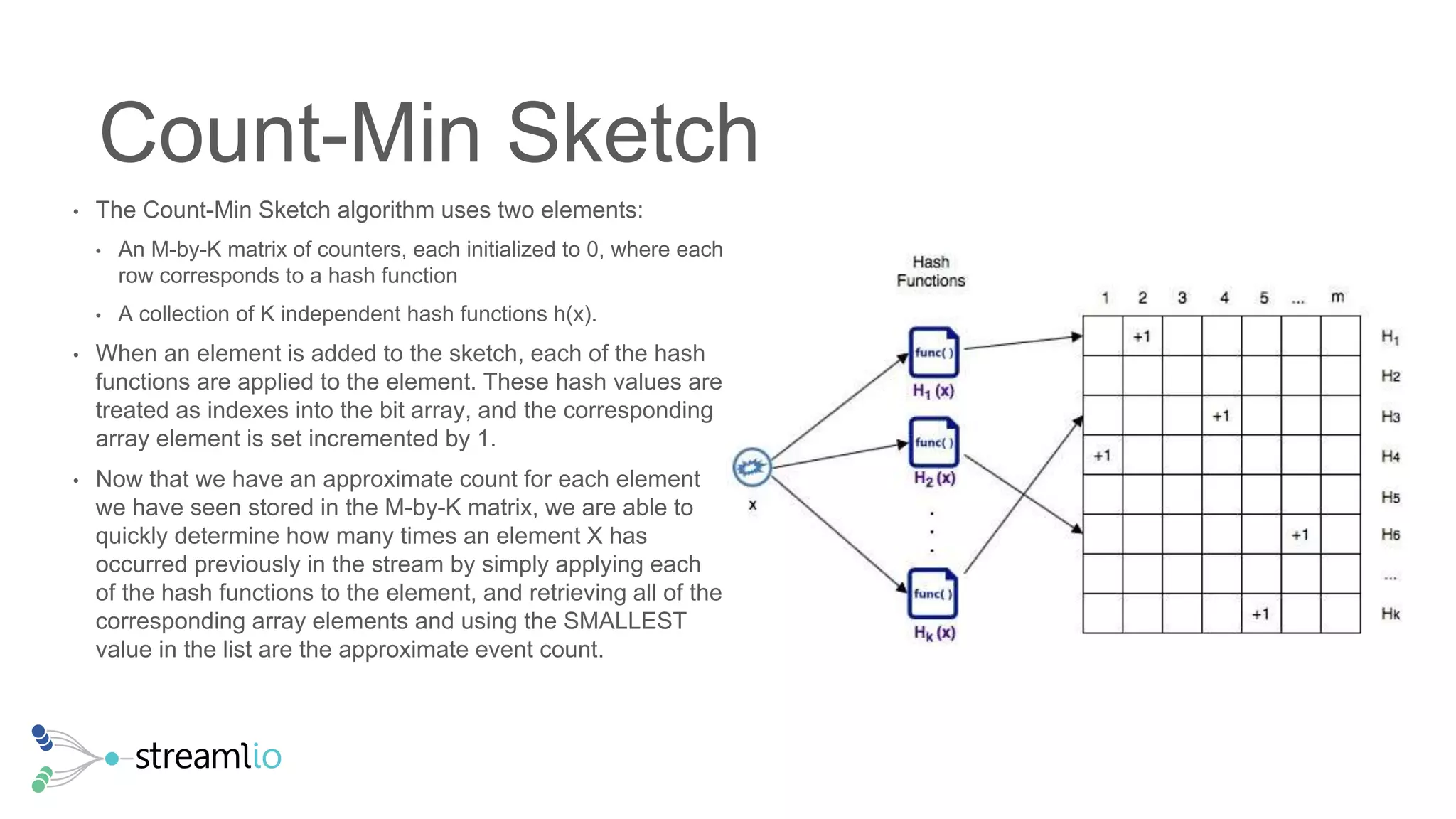


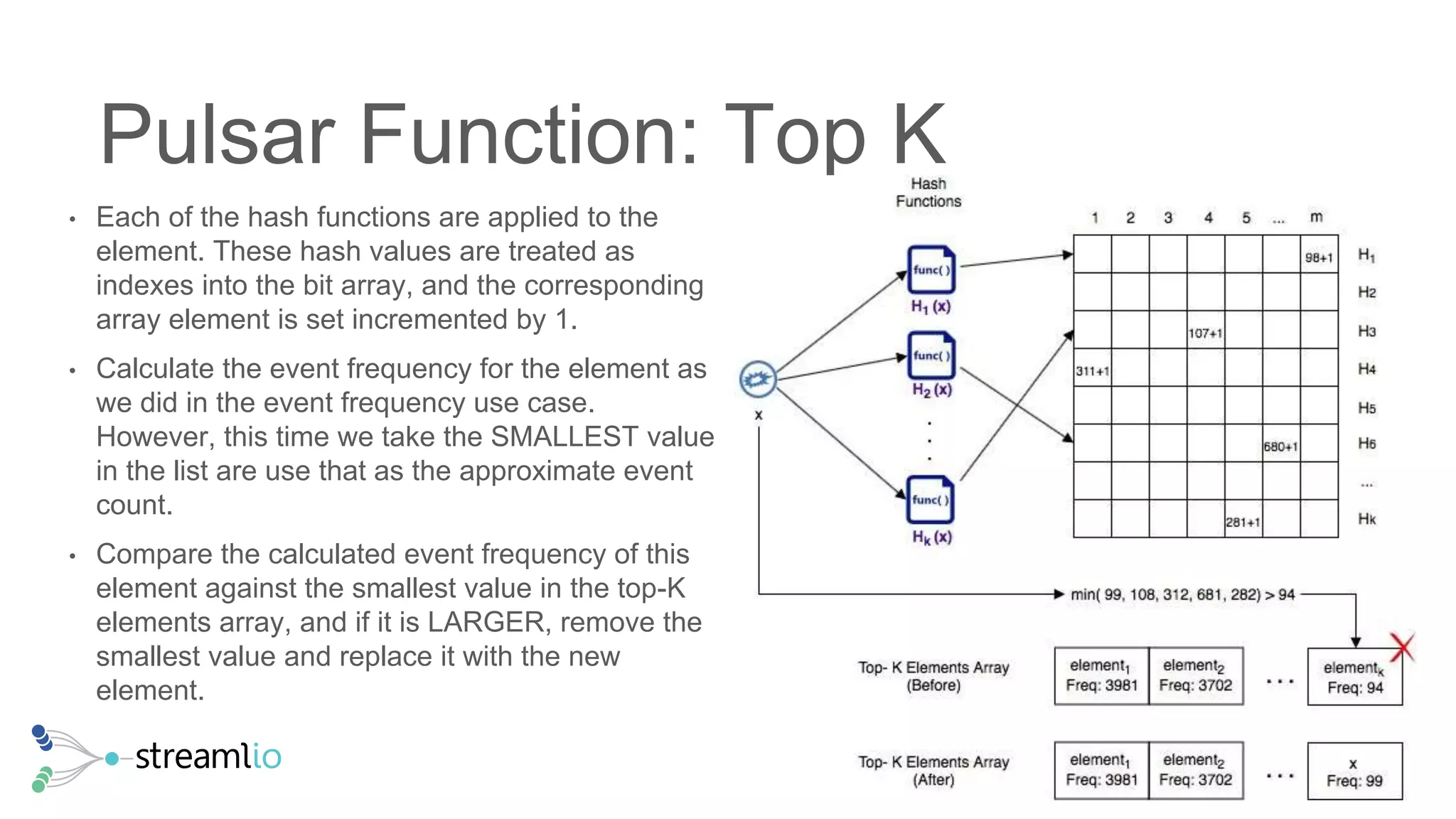
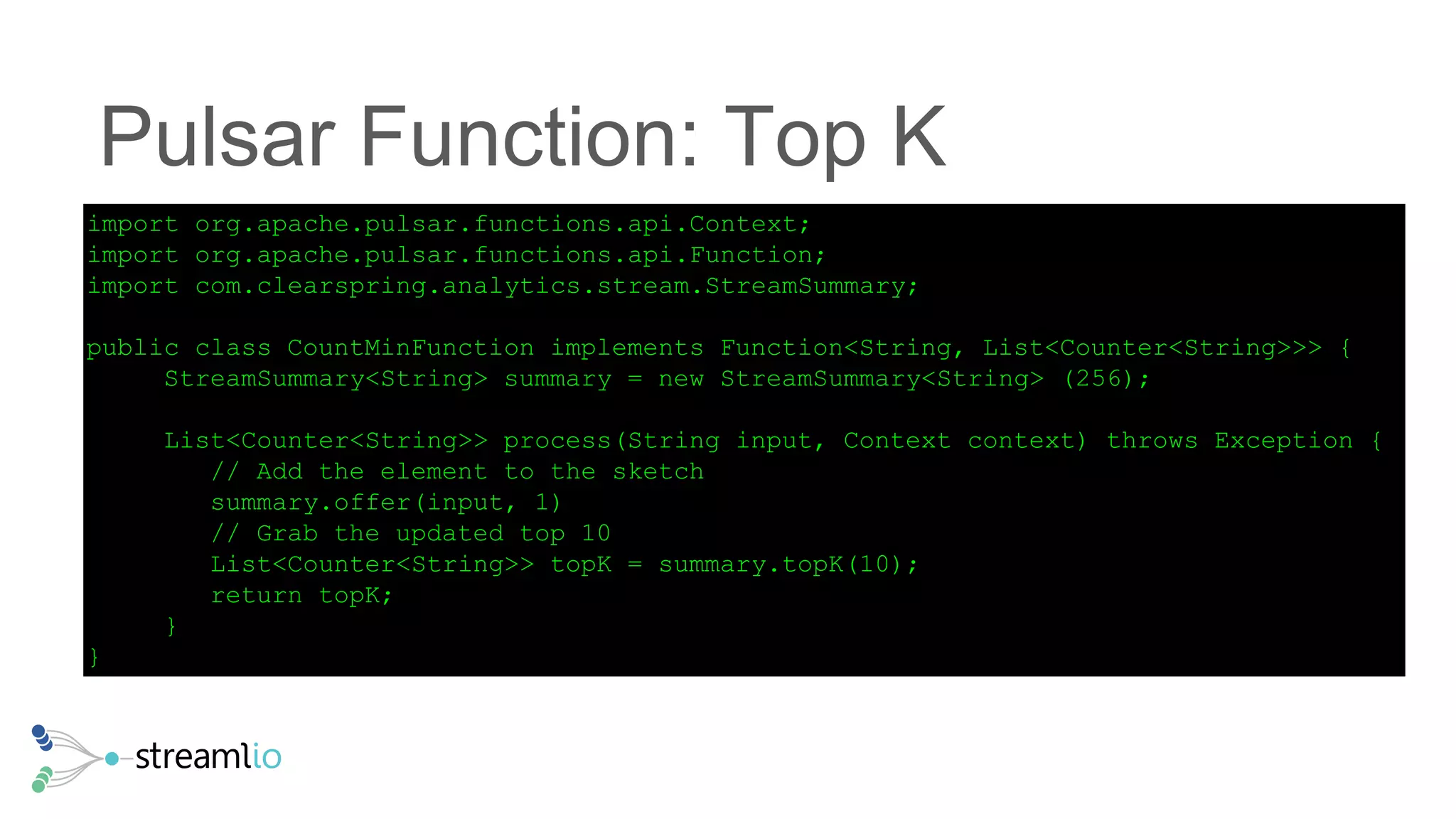
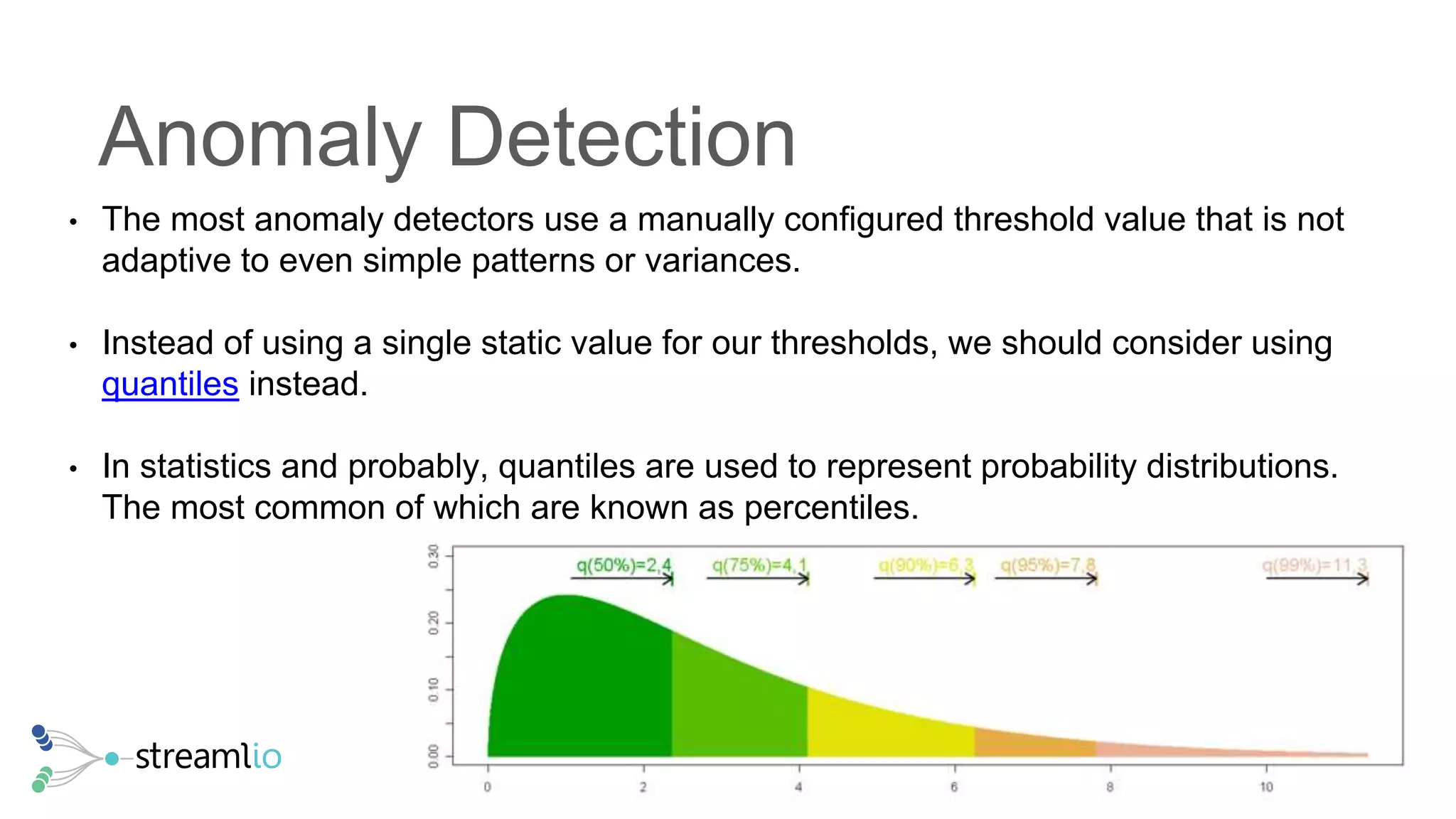




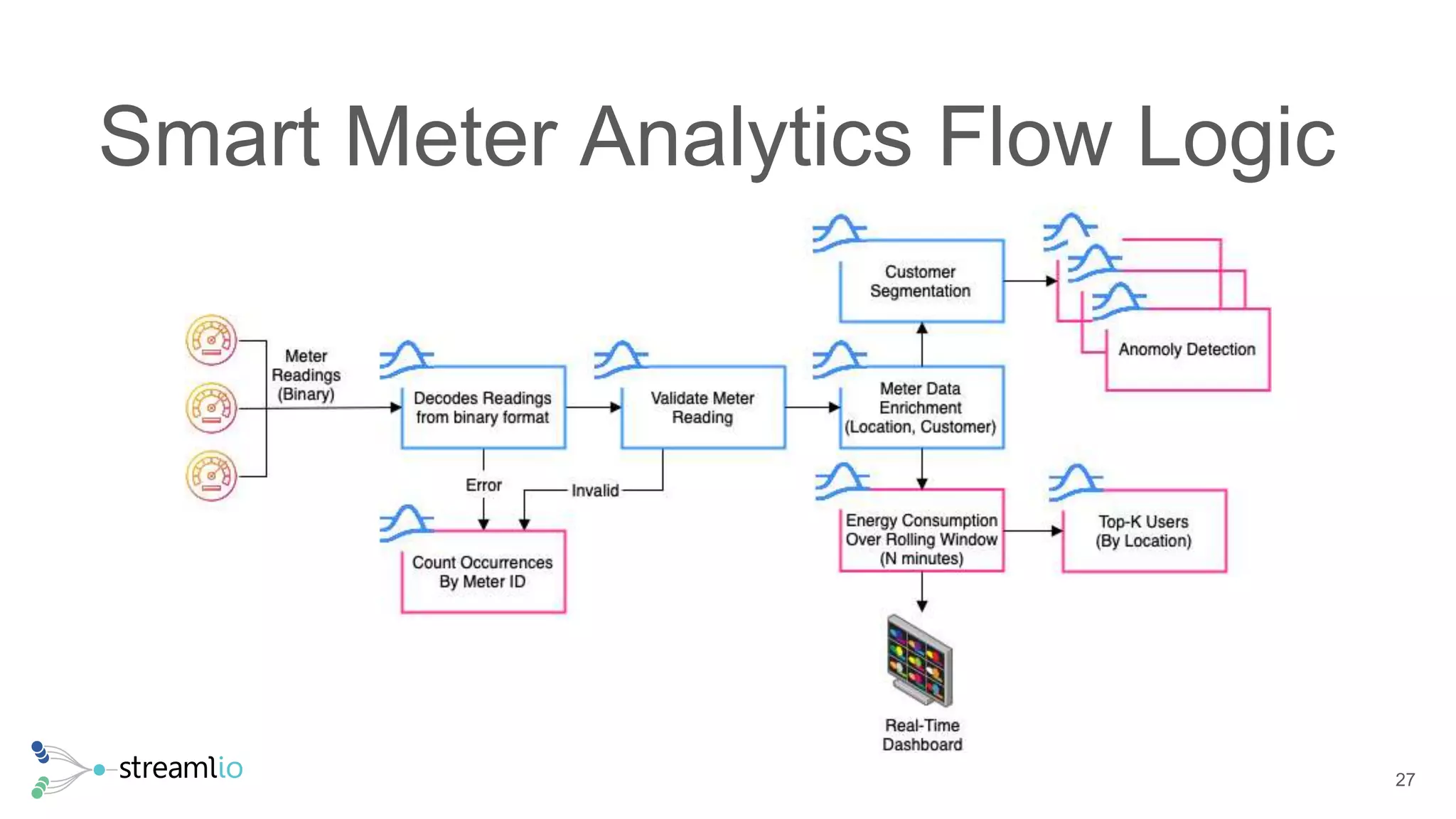
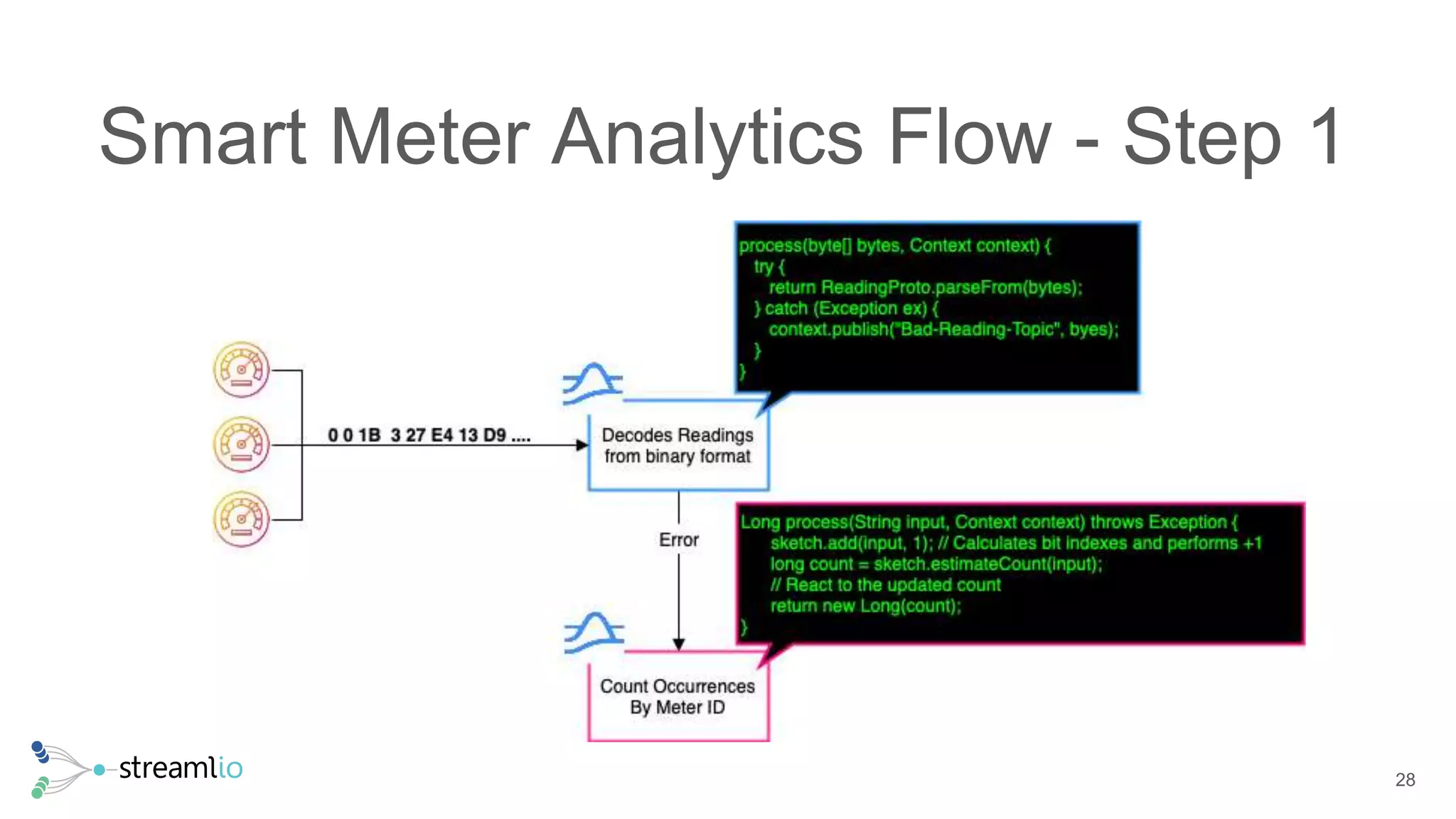
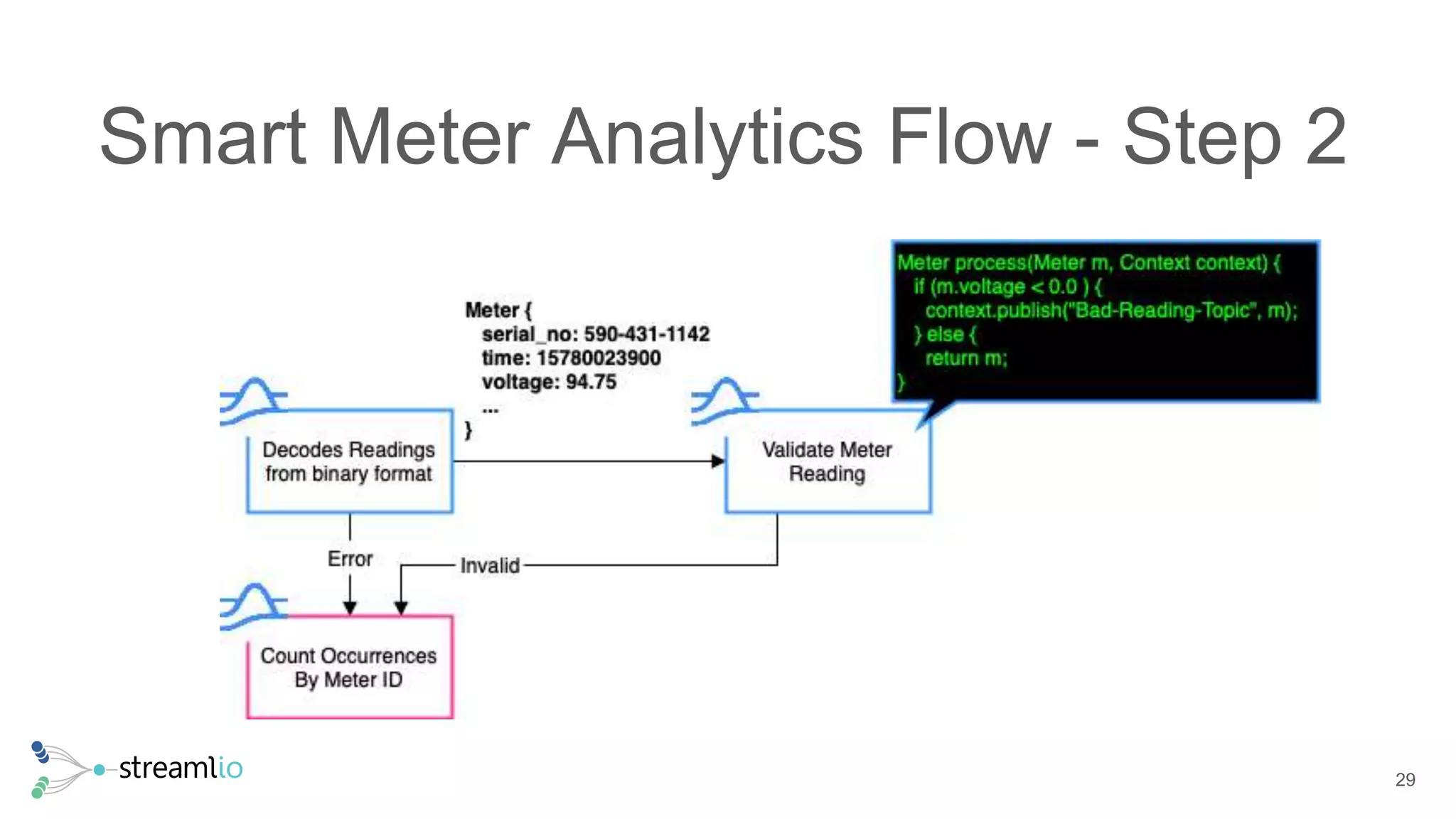
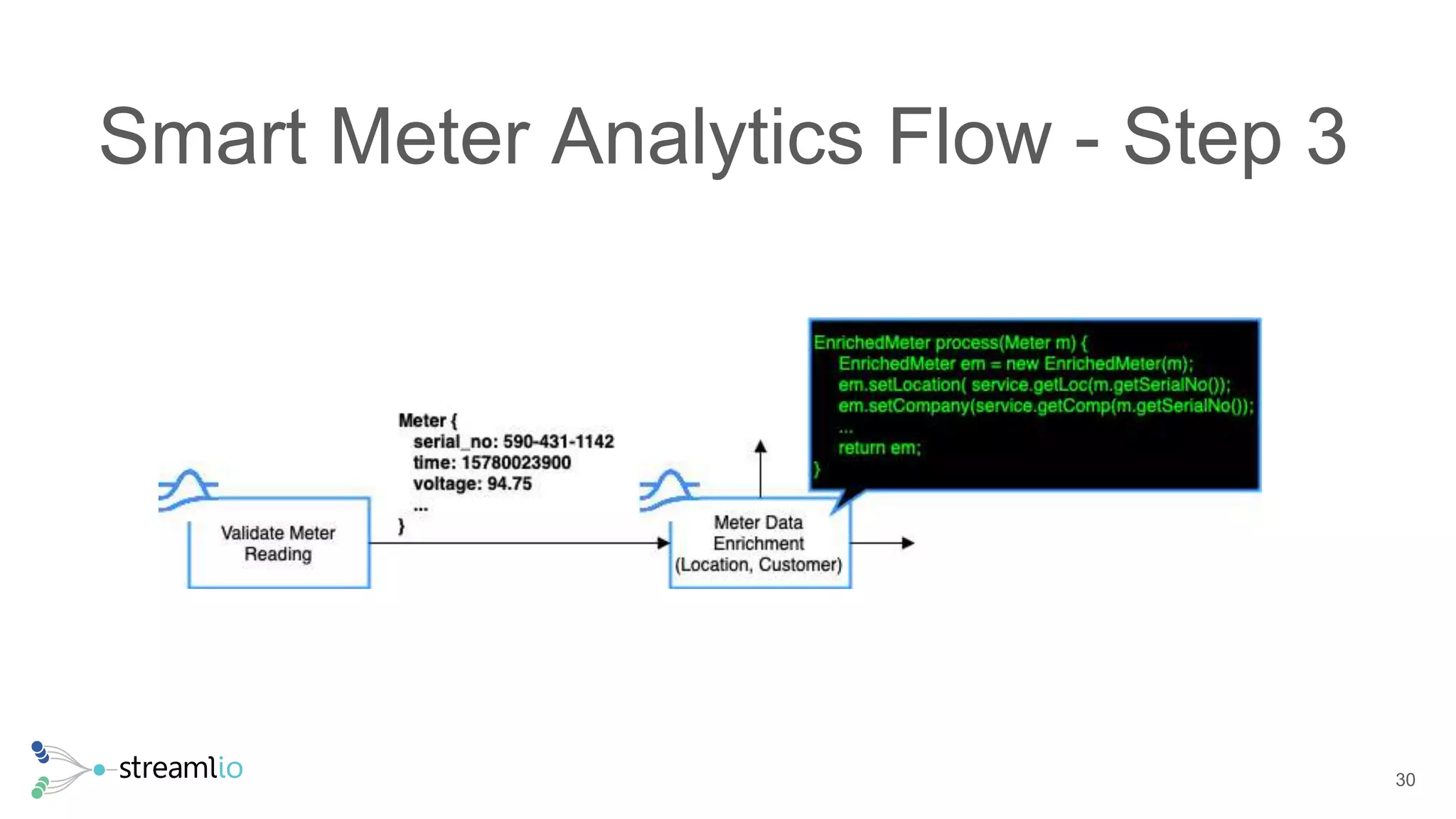
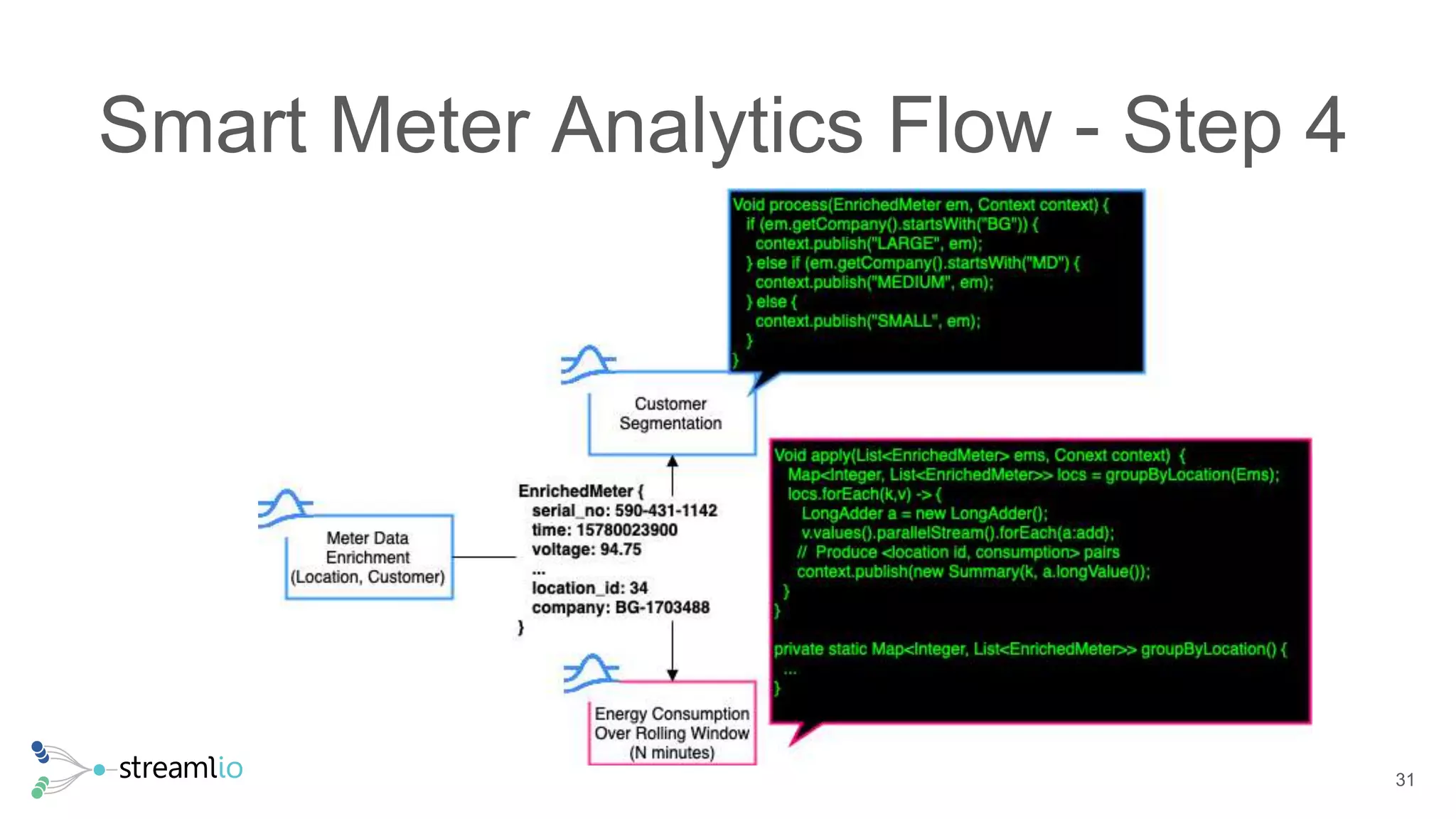
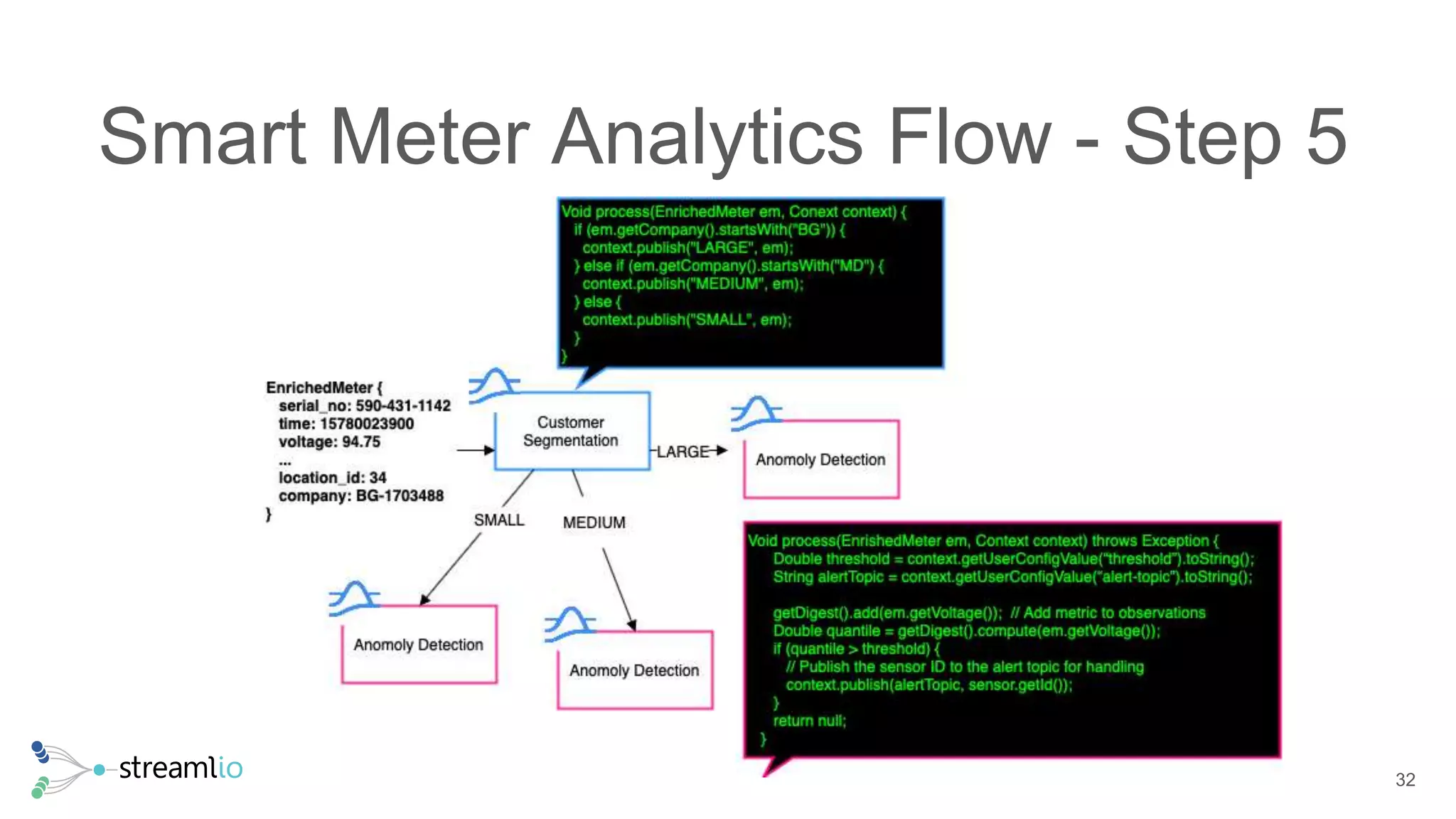
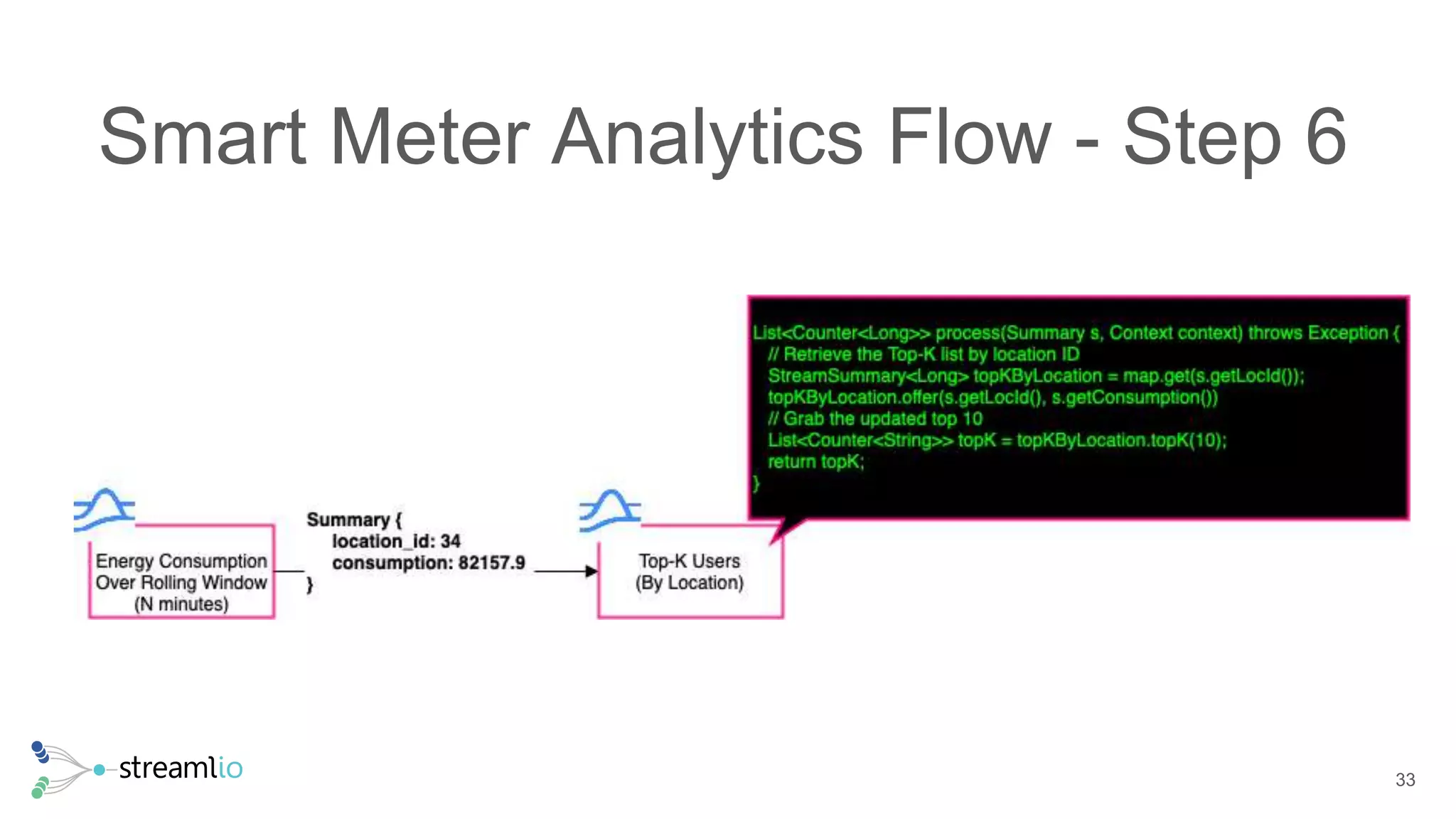

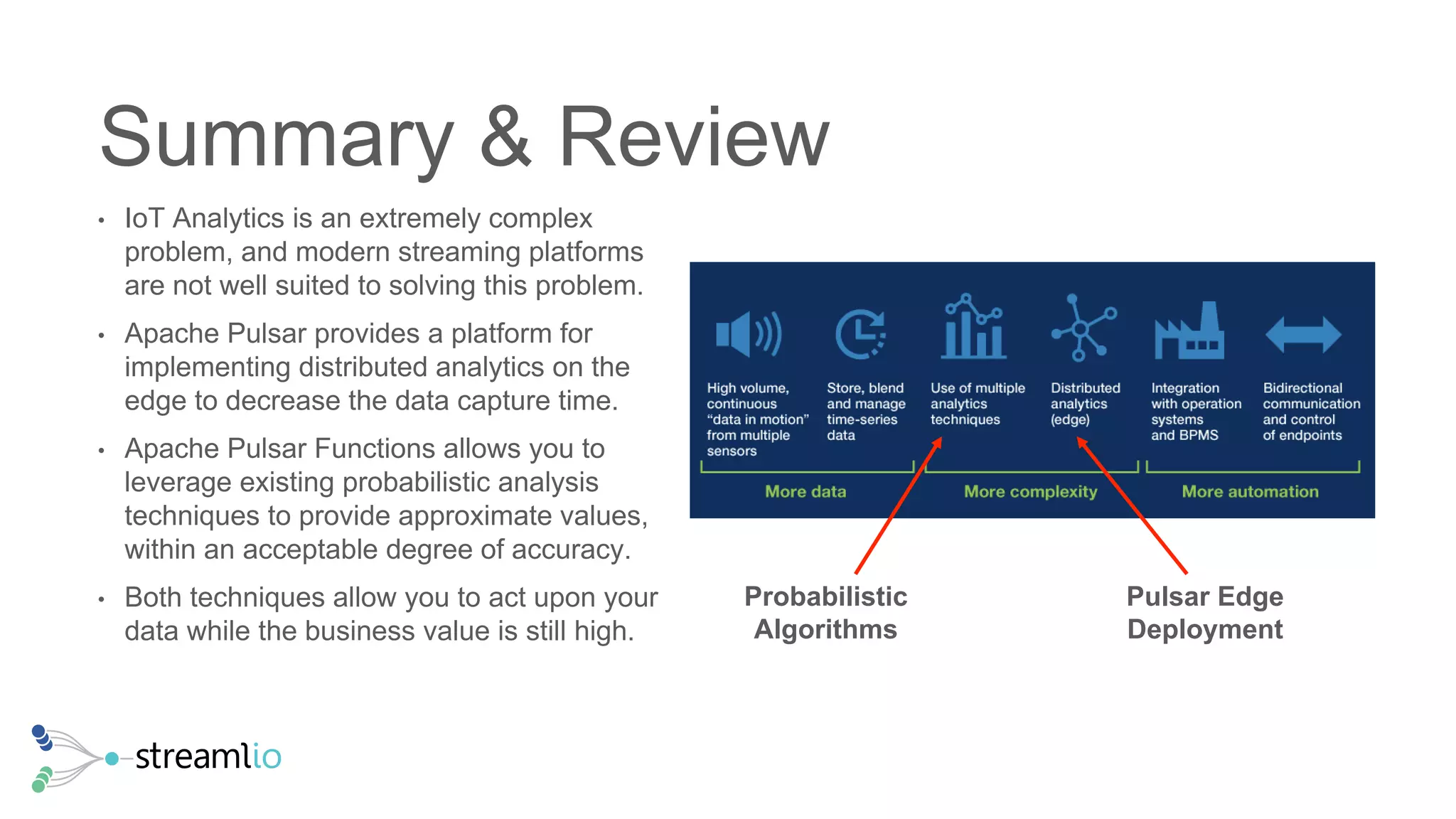



The document discusses real-time IoT analytics using Apache Pulsar, emphasizing the need to process and analyze high-velocity sensor data at the edge of networks rather than solely relying on data lakes. It presents Apache Pulsar Functions as a serverless solution that facilitates dynamic filtering, transformation, and probabilistic analytics to quickly identify anomalies and optimize operations. The text also highlights the importance of approximation techniques, such as data sketches and event frequency algorithms, to handle vast data streams in resource-constrained environments.