Downloaded 23 times






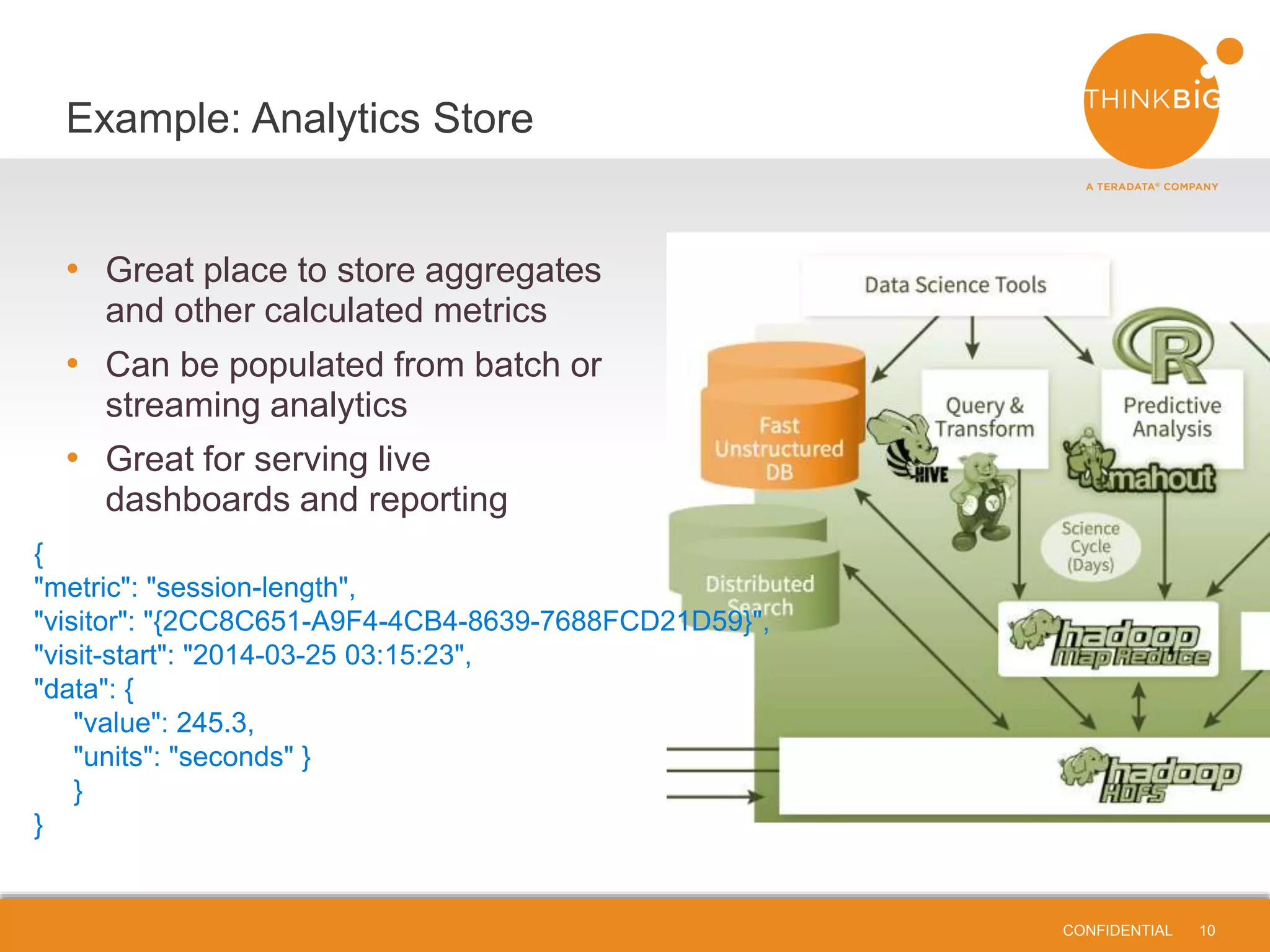
![CONFIDENTIAL | 9 Overview - Sometimes you just need a fast and safe place to store data between jobs, applications, iterations Scenarios - Data extraction jobs - Ingestion processing status - Broadcasting “last best” parameters in machine learning, genetic algorithms, and other model fitting { "process": "db-extractor", "system": "database1", "tables": { "table1": { "columns": ["ts"], "values": ["2014-03-25 03:15:23"] }, "table2": { "columns": [ "client_id" ], "values": ["43110221"] } } } Example: Add Statefulness CONFIDENTIAL 9](https://image.slidesharecdn.com/nosqlhadoopformongodb-141001123922-phpapp01/75/Lightning-Talk-Why-and-How-to-Integrate-MongoDB-and-NoSQL-into-Hadoop-Big-Data-Platforms-9-2048.jpg)

![• Time is a very common dimension on which to organize data • Great for processing incoming data and for filtering any time-based queries… • …but can complicate other access patterns Hive partitions correspond to directories on HDFS /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=1/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=2/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=3/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=4/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=5/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=6/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=7/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=8/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=9/000000_0 /apps/hive/warehouse/omniture_daily/year=2012/month=3/day=10/000000_0 […] CONFIDENTIAL | Time-Partitioned Data CONFIDENTIAL 13](https://image.slidesharecdn.com/nosqlhadoopformongodb-141001123922-phpapp01/75/Lightning-Talk-Why-and-How-to-Integrate-MongoDB-and-NoSQL-into-Hadoop-Big-Data-Platforms-13-2048.jpg)
![CONFIDENTIAL | Top 10 ≃ Bottom 2000 Distribution of geographic locations detected in clickstream data: > sum(subset(df, rank <= 10)$count) [1] 36986 > sum(subset(df, rank > max(df$rank) - 2000)$count) [1] 33971 In this sample clickstream data set, the top 10 cities account for more traffic than the bottom 2,000 combined Optimizations are usually designed for the most common cases - “Biggest bang for the buck” due to size, frequency, etc. - What are the chances that the optimizations you pick to handle the most common cases work well for the long tail? - What if a new business opportunity depends on the long tail? Welcome to the Long Tail CONFIDENTIAL 14 > sum(subset(df, rank <= 10)$count) [1] 36986 > sum(subset(df, rank > max(df$rank) - 2000)$count) [1] 33971](https://image.slidesharecdn.com/nosqlhadoopformongodb-141001123922-phpapp01/75/Lightning-Talk-Why-and-How-to-Integrate-MongoDB-and-NoSQL-into-Hadoop-Big-Data-Platforms-14-2048.jpg)


![Hive indices contain physical location of original data, including byte offsets: { "city": "taunton", "state": "ma", "country": "usa”, "bucketname": "hdfs://sandbox.hortonworks.com:8020/apps/hive/warehouse/omniture_daily/yea r=2012/month=3/day=10/000000_0”, "offsets": [ 4748045, 3522685 ], "year": 2012 "day": 10, "month": 3, } CONFIDENTIAL | Sample Index entry CONFIDENTIAL 17](https://image.slidesharecdn.com/nosqlhadoopformongodb-141001123922-phpapp01/75/Lightning-Talk-Why-and-How-to-Integrate-MongoDB-and-NoSQL-into-Hadoop-Big-Data-Platforms-17-2048.jpg)

![Specific file on HDFS containing the records of interest CONFIDENTIAL | Querying the Index in Mongo $ mongo localhost MongoDB shell version: 2.4.6 connecting to: localhost > use clickstream; switched to db clickstream > db.locidx.find( {'state':'ma', 'city':'taunton'} ); { "_id" : ObjectId("5426f42e6a6b0b1939528f80"), "bucketname” : "hdfs://sandbox.hortonworks.com:8020/apps/hive/warehouse/omniture_d aily/year=2012/month=3/day=10/000000_0”, "offsets" : [ 4748045, 3522685 ], "month" : 3, "state" : "ma", "year" : 2012, "day" : 10, "country" : "usa", "city" : "taunton” } CONFIDENTIAL 19 Byte offsets within that file containing the records of interest](https://image.slidesharecdn.com/nosqlhadoopformongodb-141001123922-phpapp01/75/Lightning-Talk-Why-and-How-to-Integrate-MongoDB-and-NoSQL-into-Hadoop-Big-Data-Platforms-19-2048.jpg)




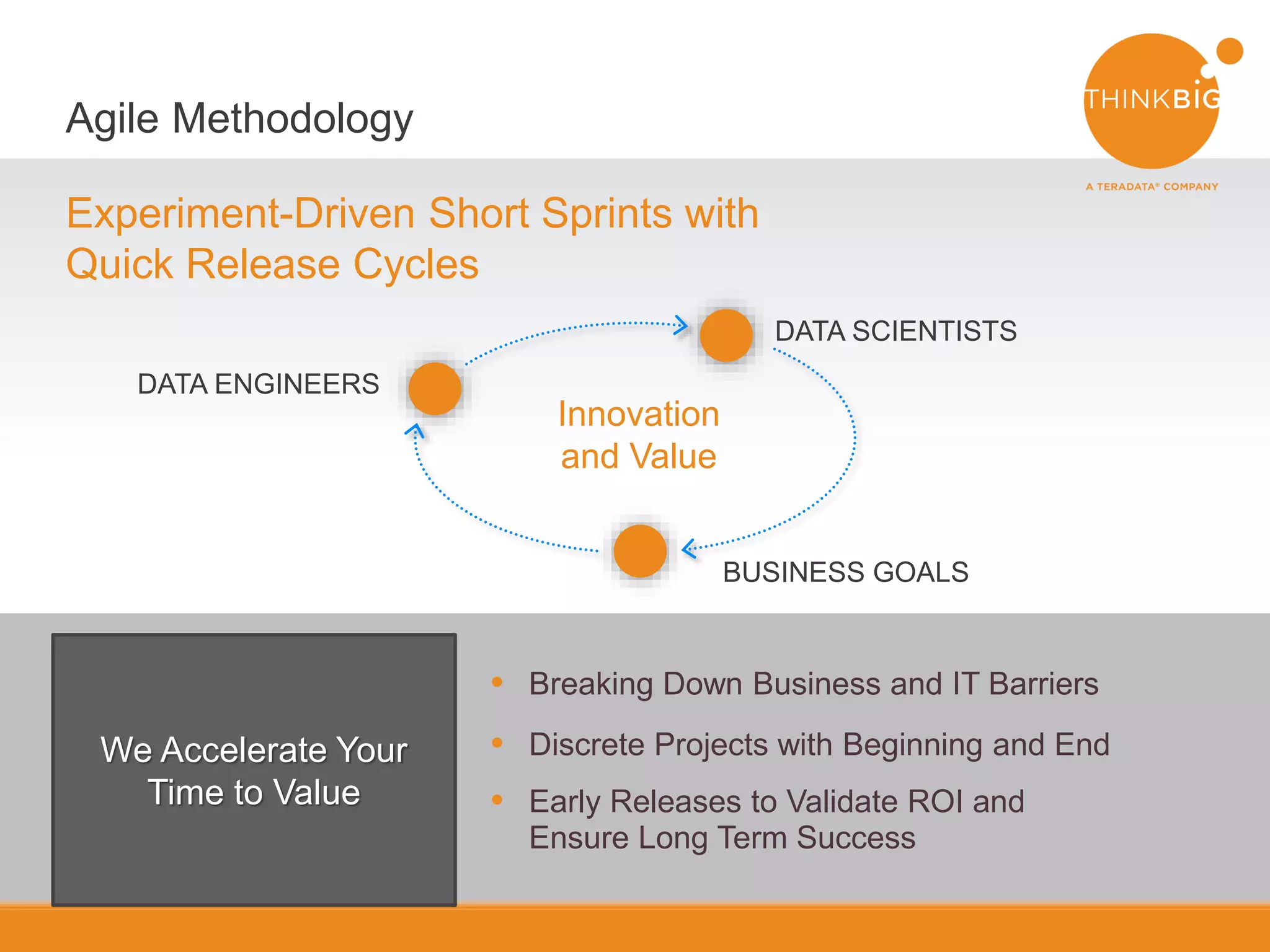
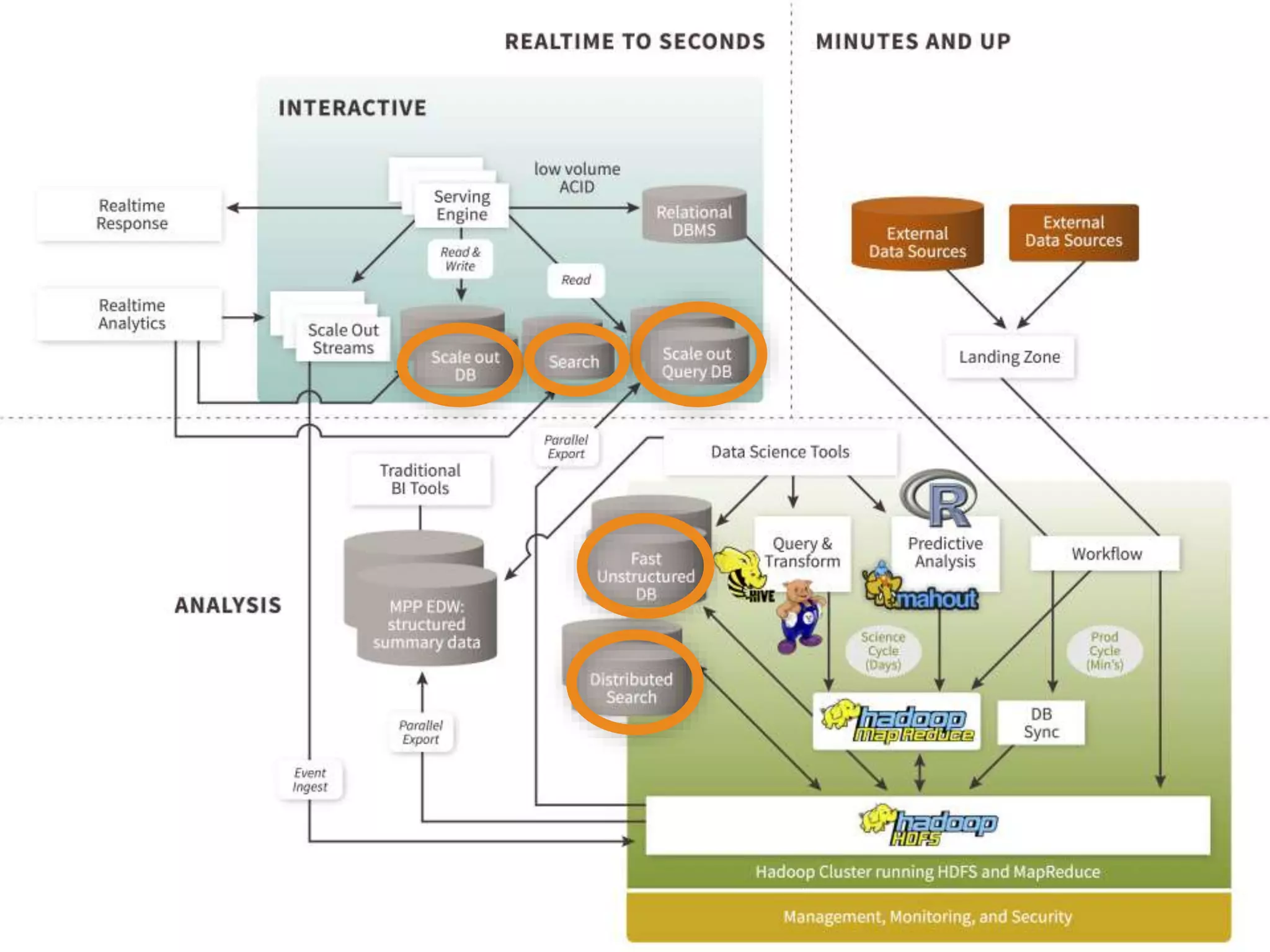
The document discusses the integration of NoSQL databases with Hadoop to enhance big data solutions, emphasizing the complementary nature of their functionalities. It covers various use cases, such as analytics stores and secondary indexing, showcasing practical examples of preserving state and enabling fast, flexible querying. The text highlights the importance of agile methodologies in data project delivery and mentions the MongoDB connector for seamless data handling with Hadoop.