Download to read offline




![How to fetch by timestamp #1 def fetchOffsetsByTimestamp(targetTimestamp: Long): Option[TimestampOffset] = { …… val targetSeg = { val earlierSegs = segmentsCopy.takeWhile(_.largestTimestamp < targetTimestamp) if (earlierSegs.length < segmentsCopy.length) Some(segmentsCopy(earlierSegs.length)) else None } targetSeg.flatMap(_.findOffsetByTimestamp(targetTimestamp, logStartOffset)) } }](https://image.slidesharecdn.com/kafkatimestampoffsetfinal-180910074044/75/Kafka-timestamp-offset_final-13-2048.jpg)
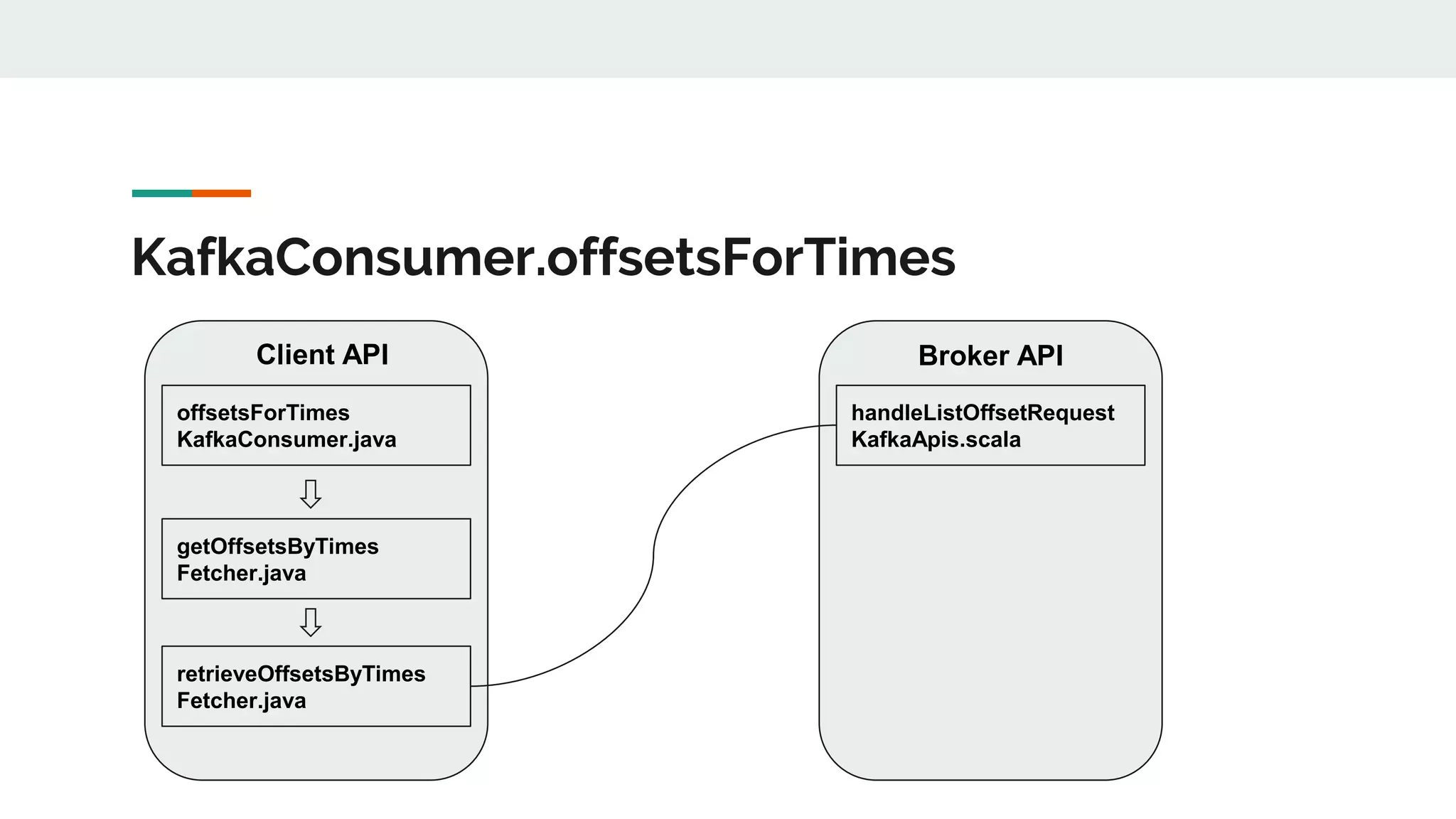
![How to fetch by timestamp #2 def findOffsetByTimestamp(timestamp: Long, startingOffset: Long = baseOffset): Option[TimestampOffset] = { // Get the index entry with a timestamp less than or equal to the target timestamp val timestampOffset = timeIndex.lookup(timestamp) val position = offsetIndex.lookup(math.max(timestampOffset.offset, startingOffset)).position // Search the timestamp Option(log.searchForTimestamp(timestamp, position, startingOffset)).map { timestampAndOffset => TimestampOffset(timestampAndOffset.timestamp, timestampAndOffset.offset) } } Using BinarySearch For Search](https://image.slidesharecdn.com/kafkatimestampoffsetfinal-180910074044/75/Kafka-timestamp-offset_final-14-2048.jpg)
](https://image.slidesharecdn.com/kafkatimestampoffsetfinal-180910074044/75/Kafka-timestamp-offset_final-17-2048.jpg)

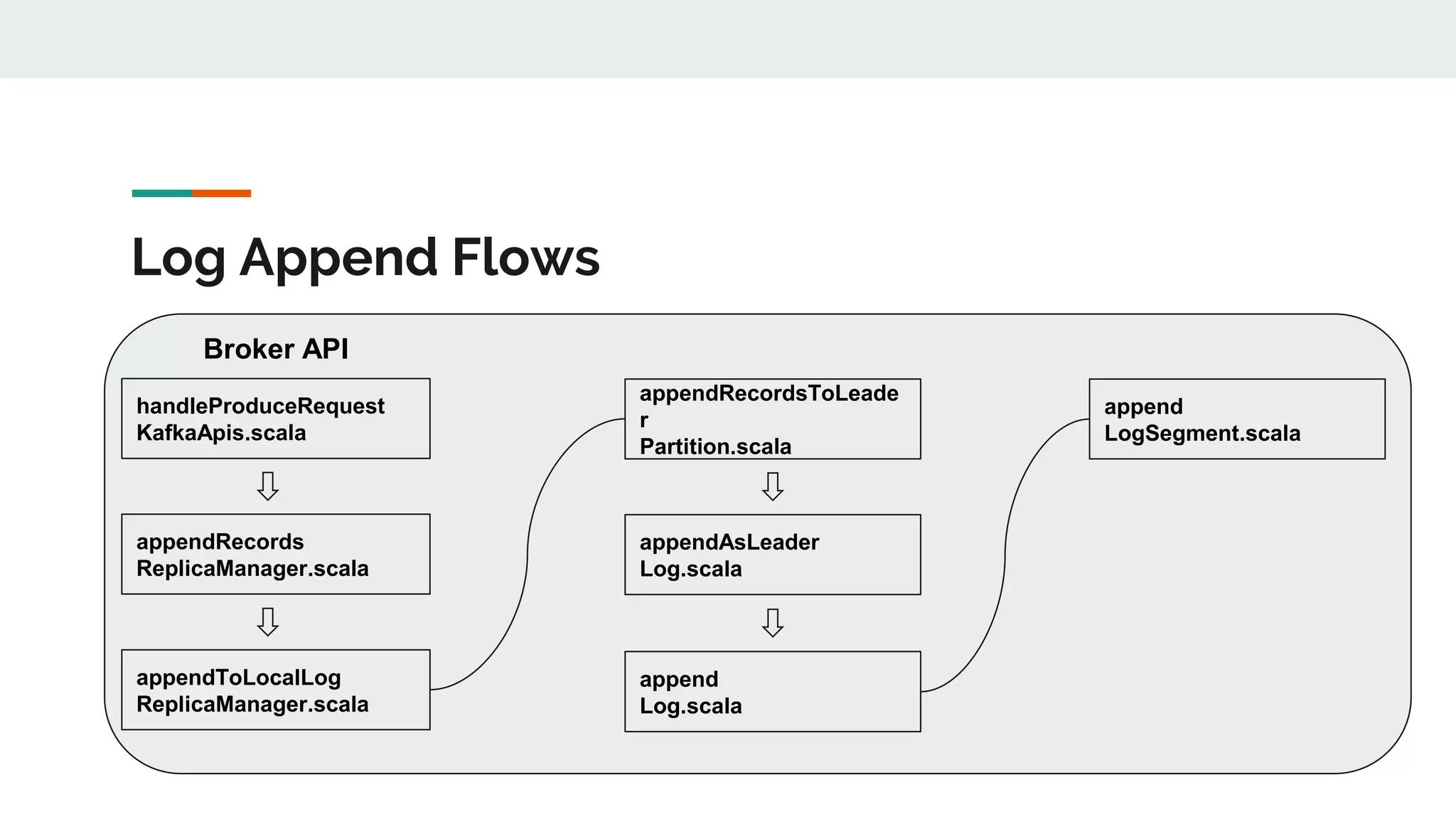

![When Segmnet is rolled? def shouldRoll(messagesSize: Int, maxTimestampInMessages: Long, maxOffsetInMessages: Long, now: Long): Boolean = { val reachedRollMs = timeWaitedForRoll(now, maxTimestampInMessages) > maxSegmentMs - rollJitterMs size > maxSegmentBytes - messagesSize || (size > 0 && reachedRollMs) || offsetIndex.isFull || timeIndex.isFull || !canConvertToRelativeOffset(maxOffsetInMessages) } 1] size > maxSegmentBytes - messageSize 2] size > 0 && reachedRollMs 3] offsetIndex.isFull 4] timeIndex.isFull 5] canCovertToRelativeOffset is false](https://image.slidesharecdn.com/kafkatimestampoffsetfinal-180910074044/75/Kafka-timestamp-offset_final-22-2048.jpg)
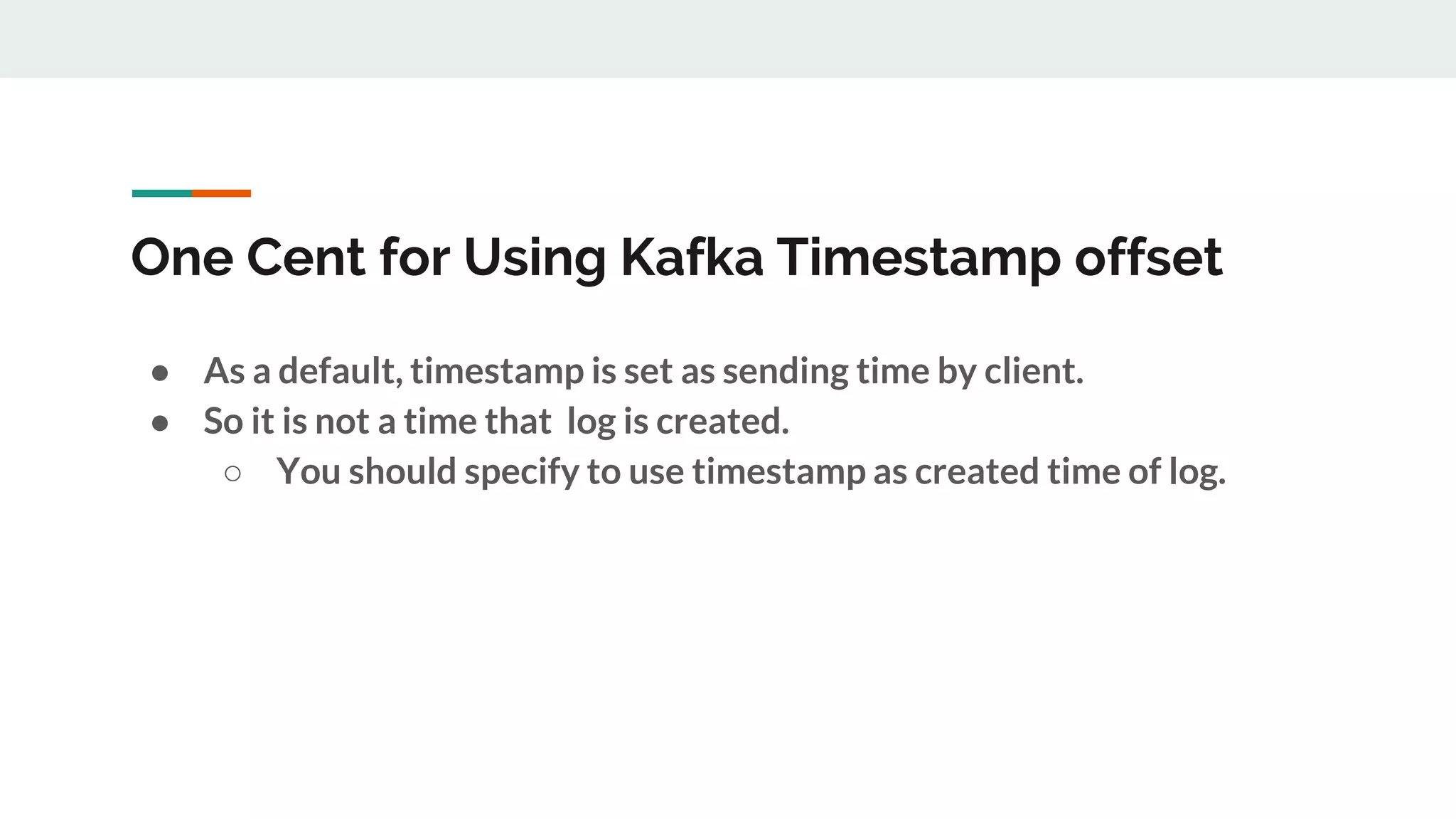

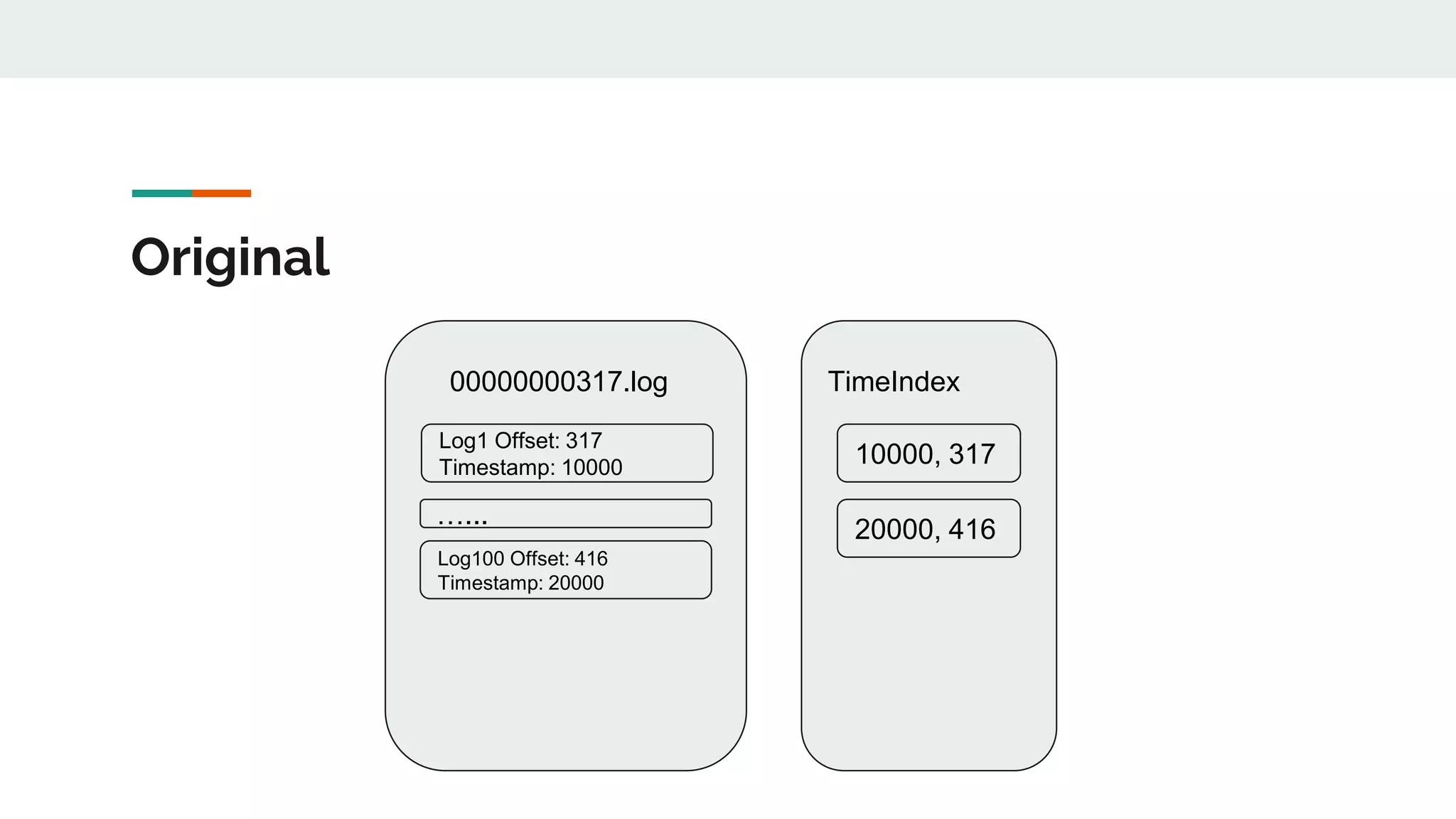
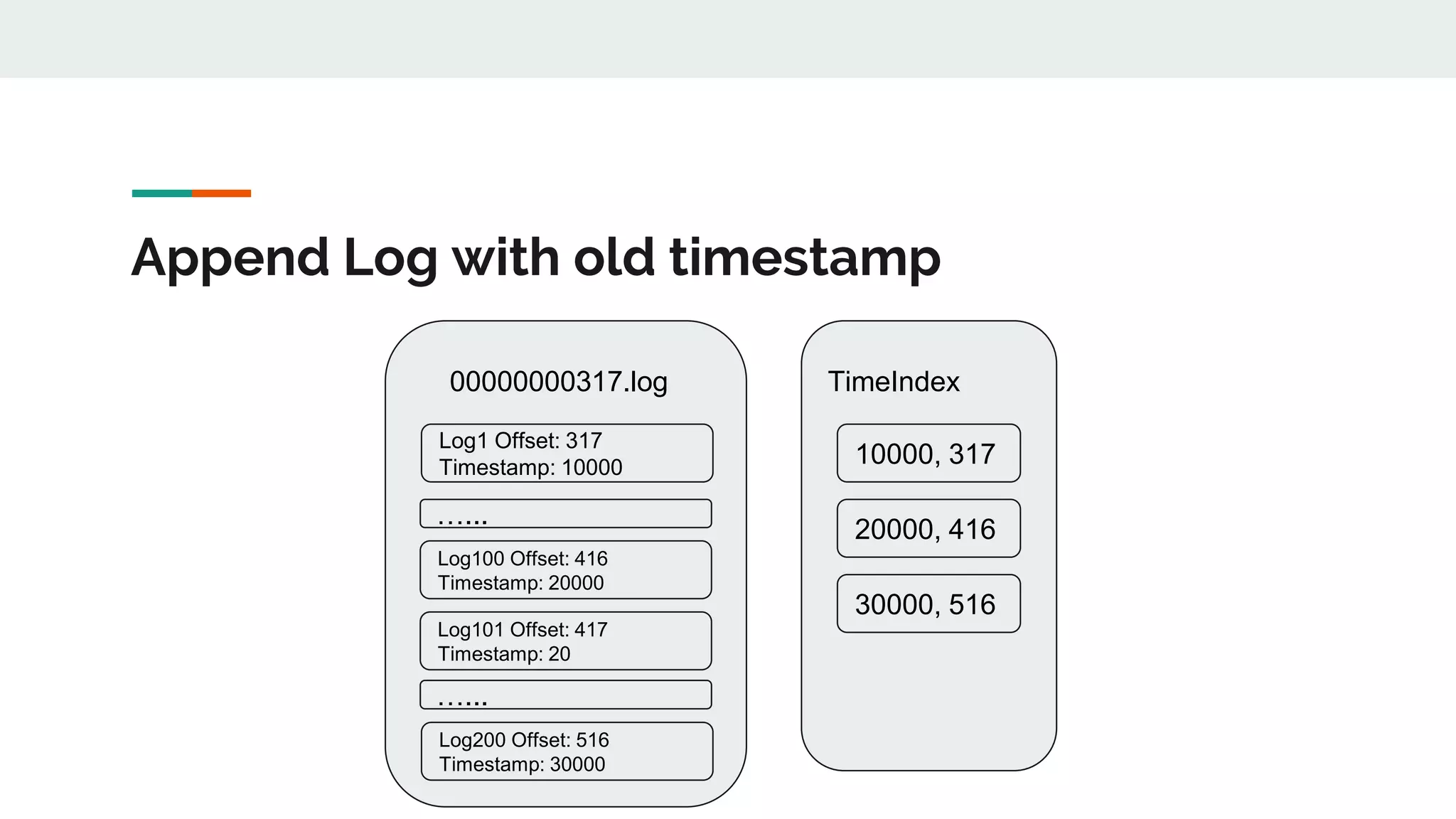

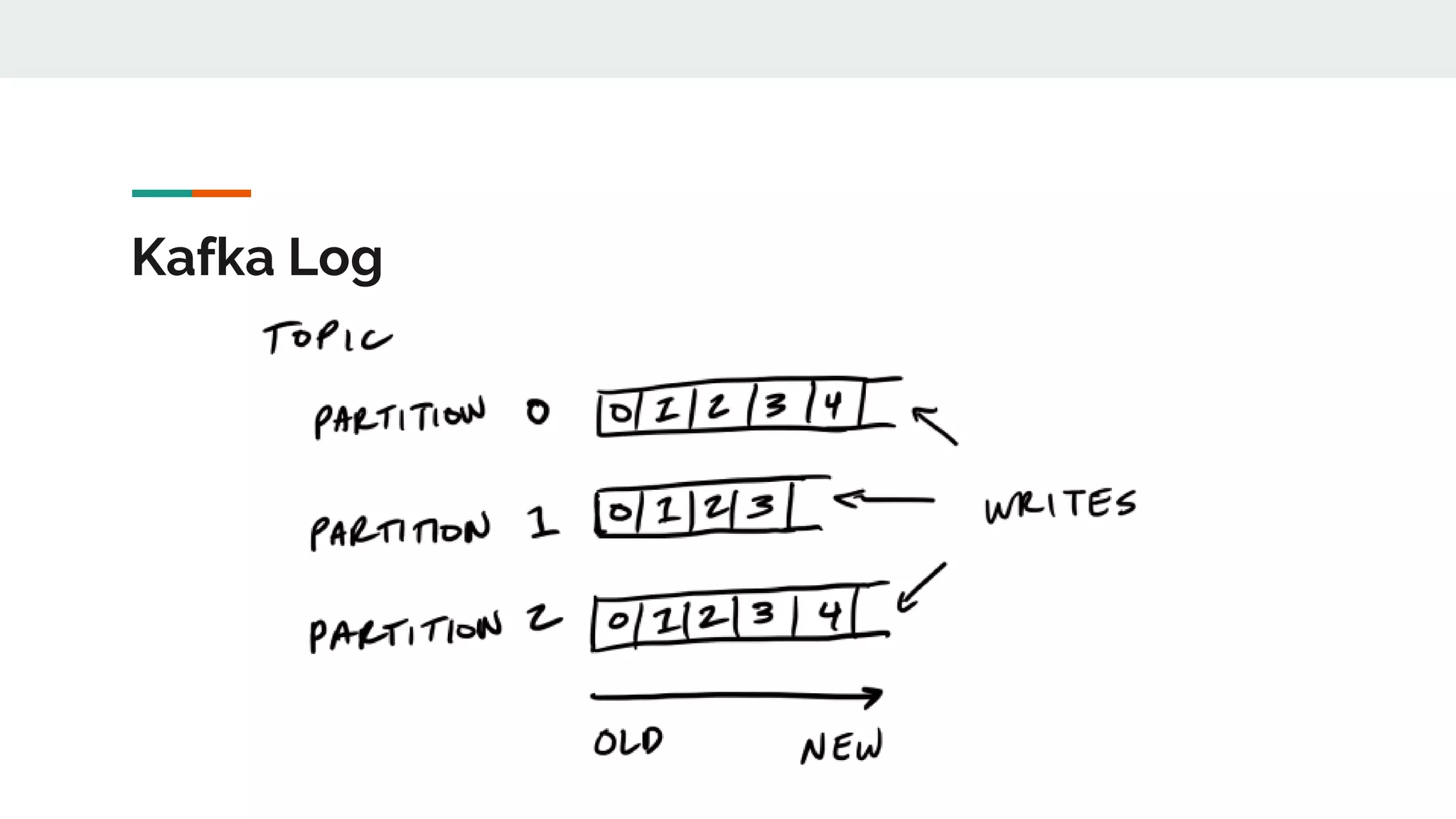
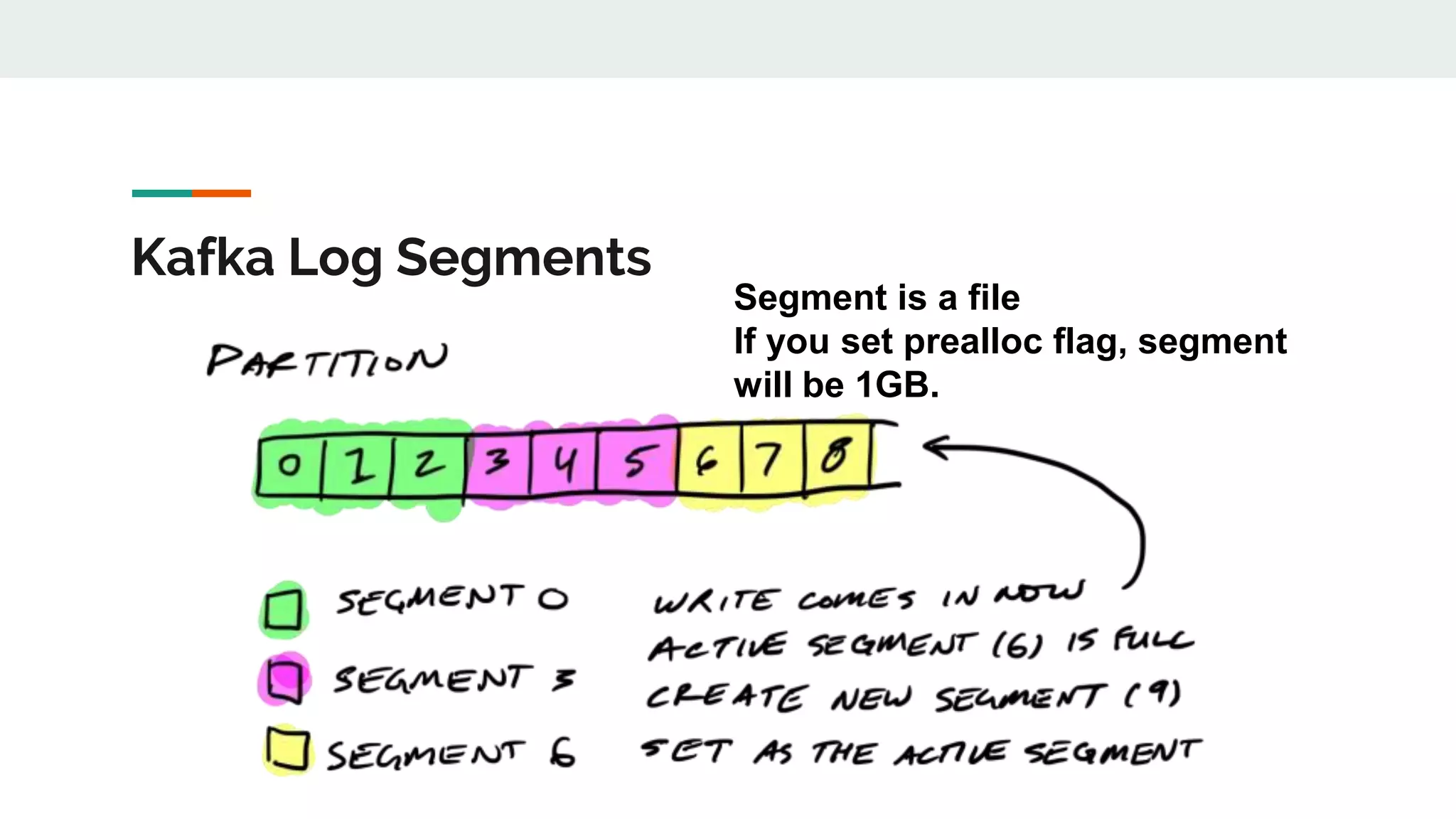
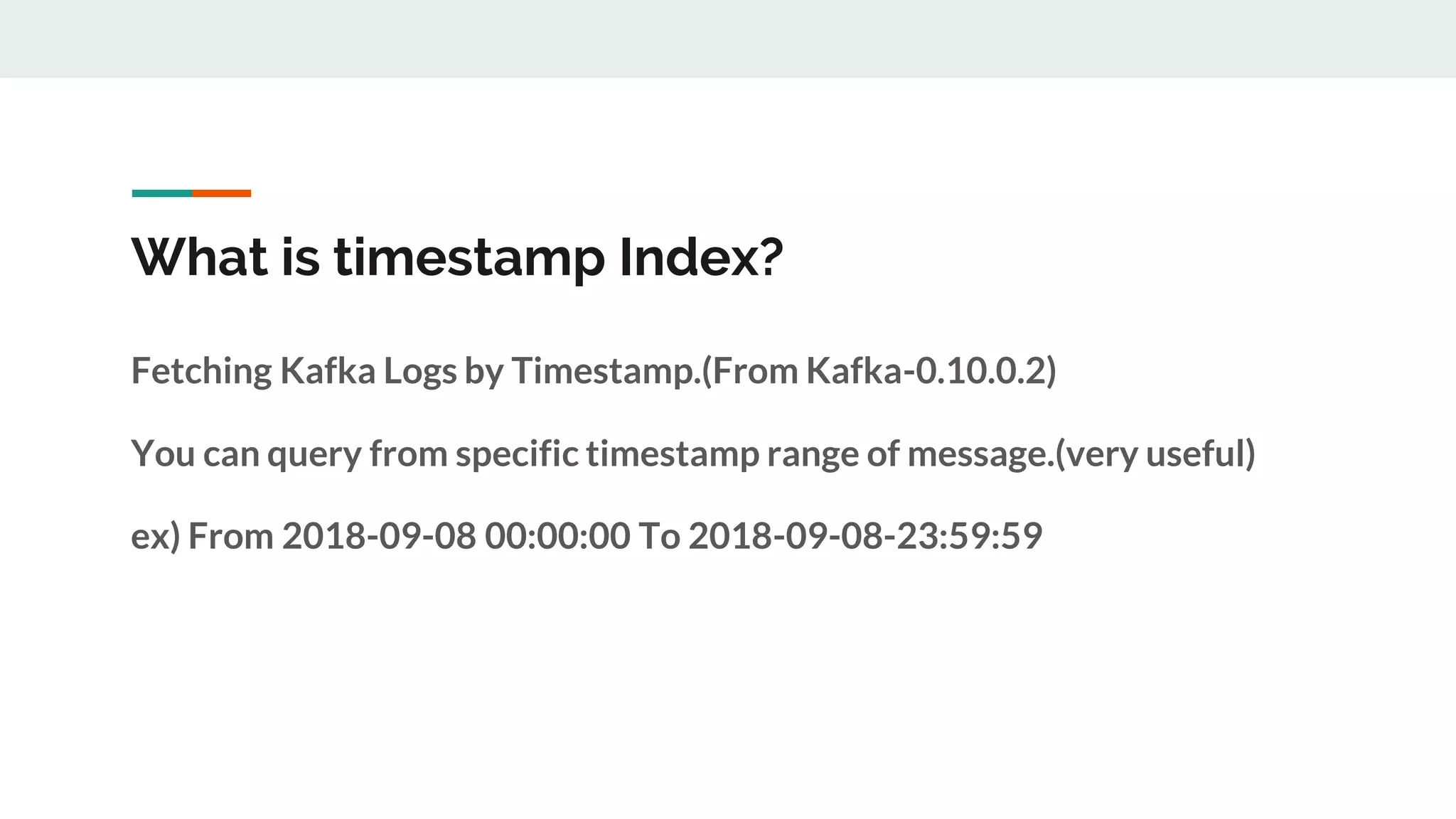
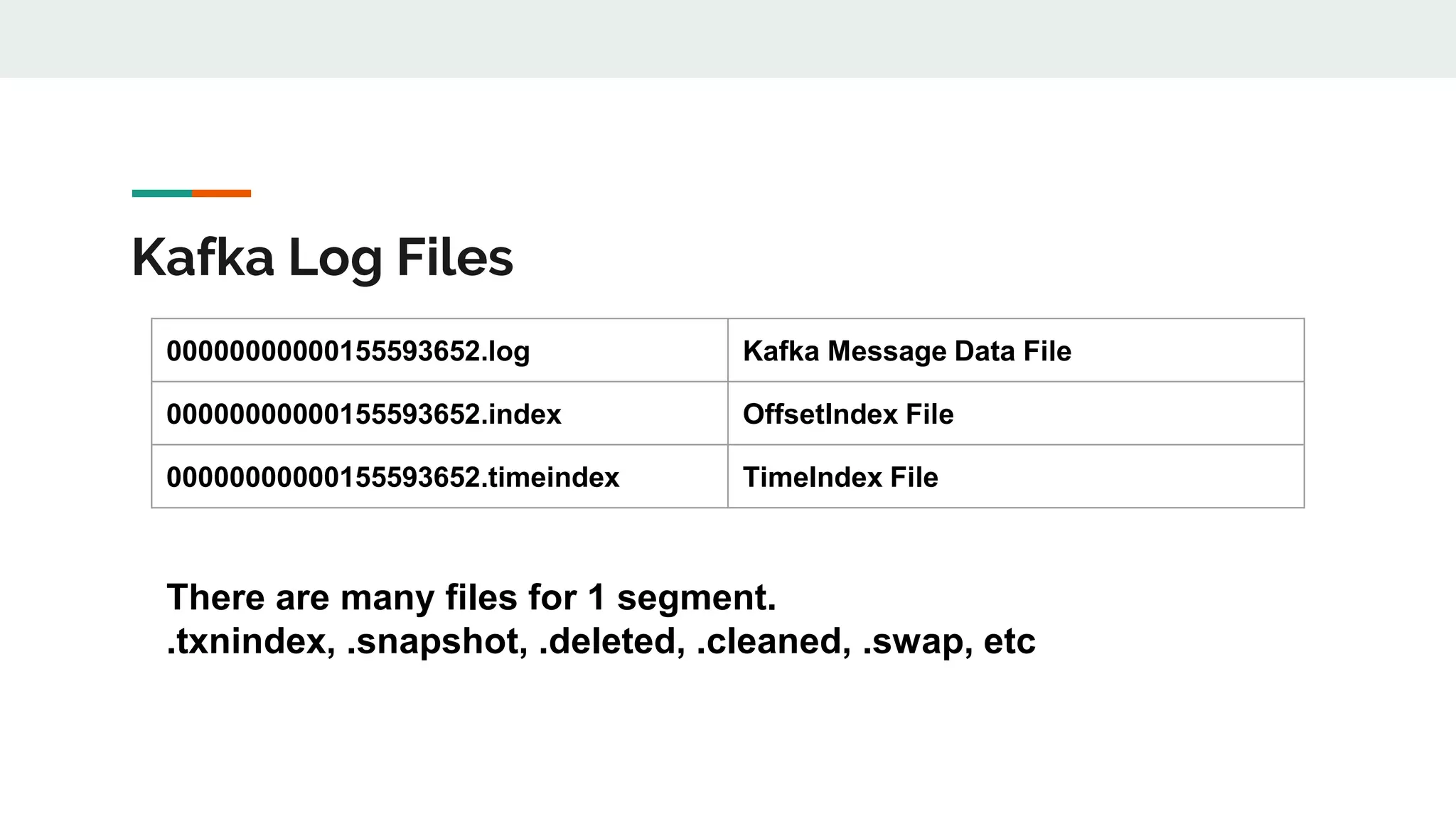
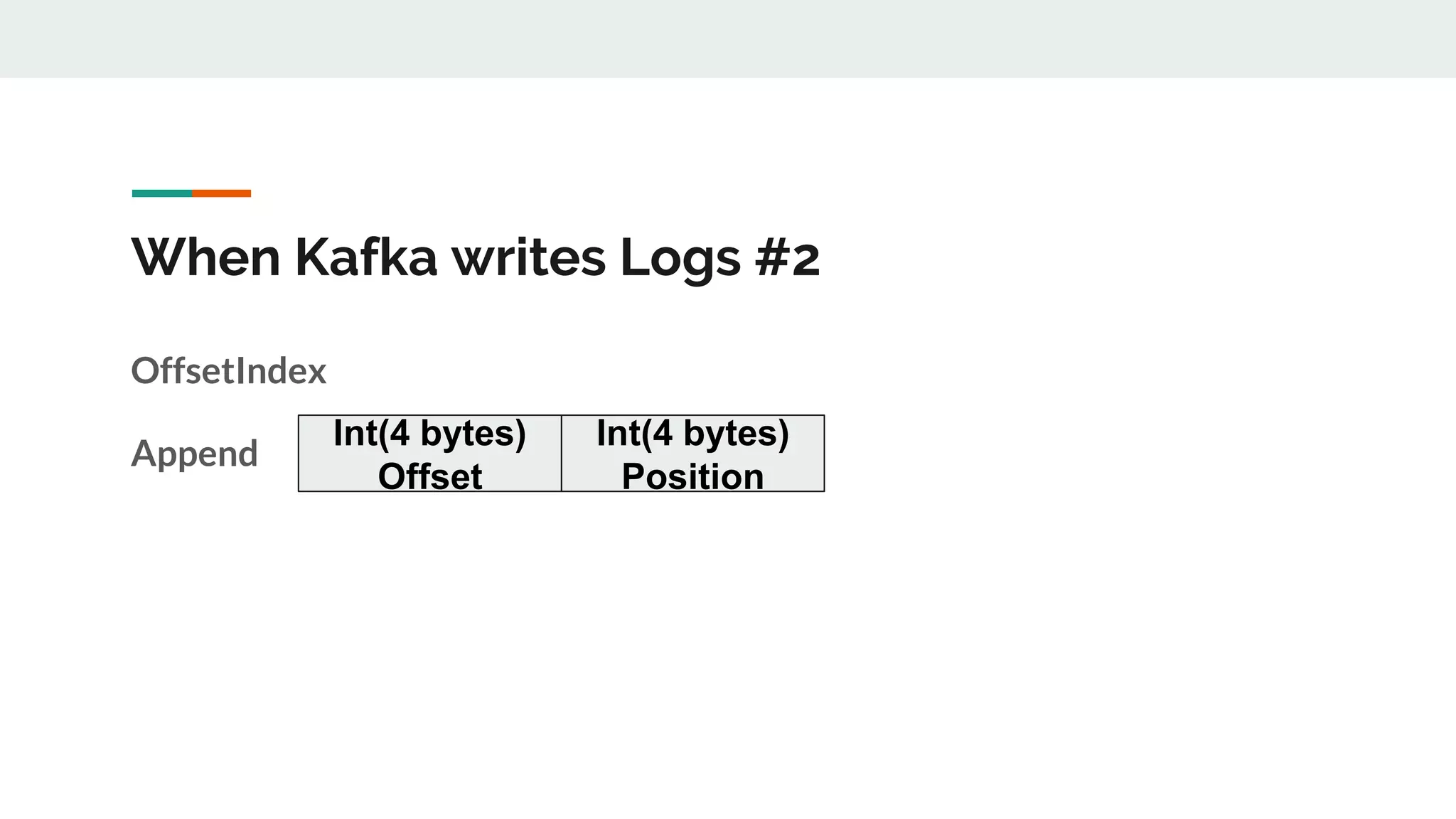
This document discusses Kafka timestamps and offsets. It explains that Kafka assigns timestamps to messages by default as the sending time from the client. The timestamps are stored in the timeindex file, which uses binary search to fetch logs by timestamp. When a log segment rolls, it is typically due to the segment size exceeding the max, the time since the oldest message exceeding the max, or the indexes becoming full. If a message is appended with an older timestamp than what is in the timeindex, it will overwrite the existing entries.