Downloaded 27 times





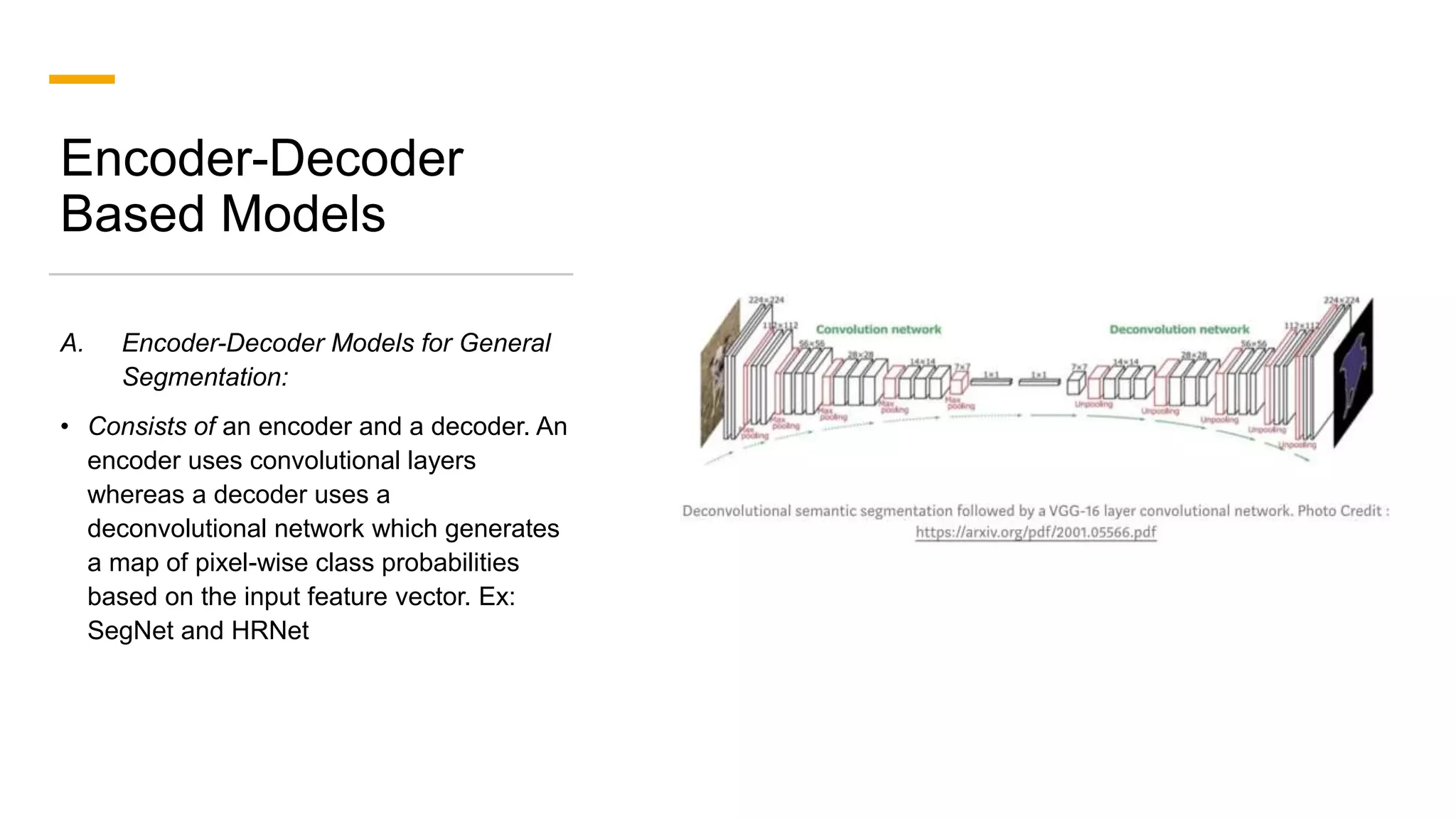
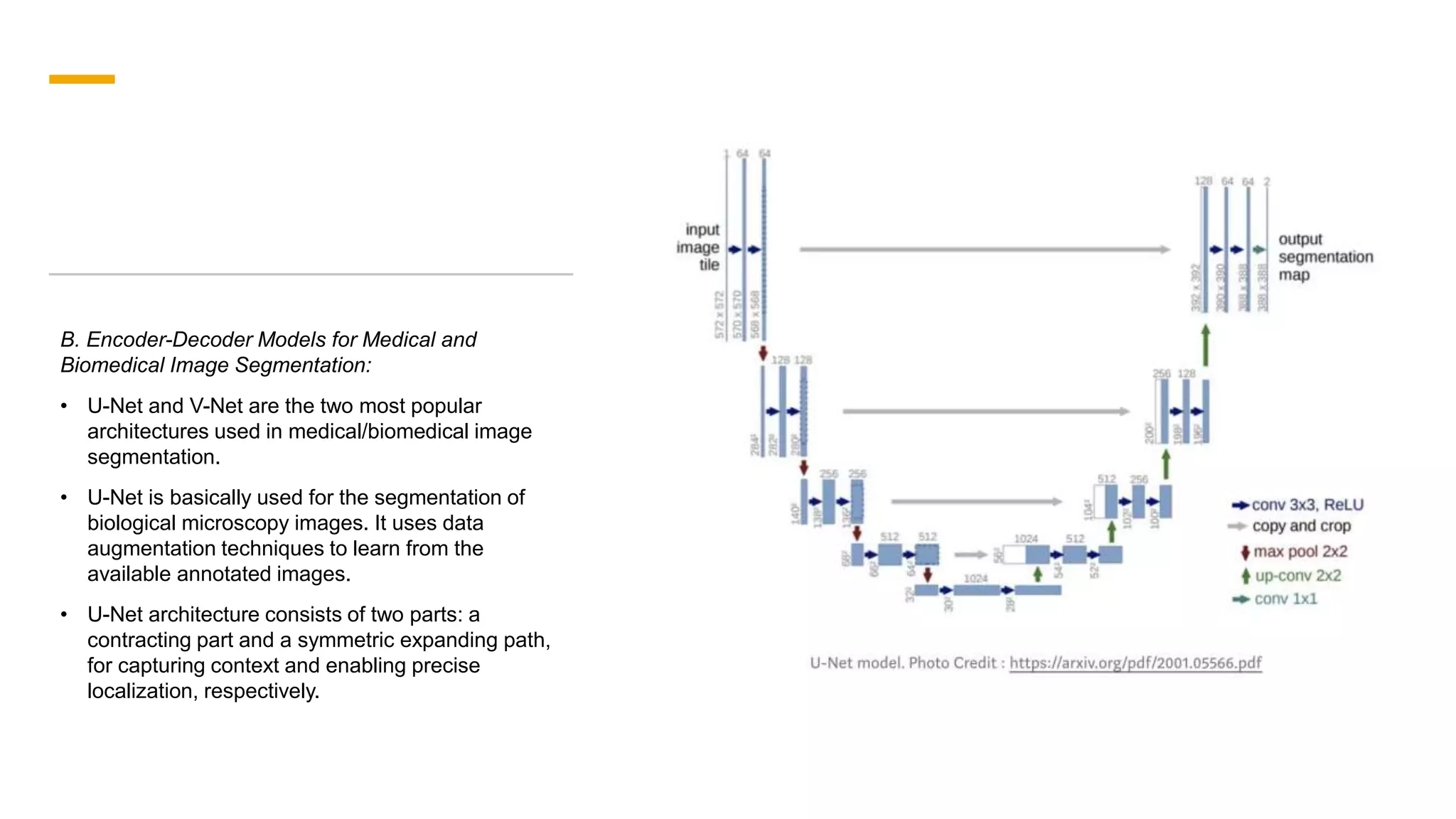
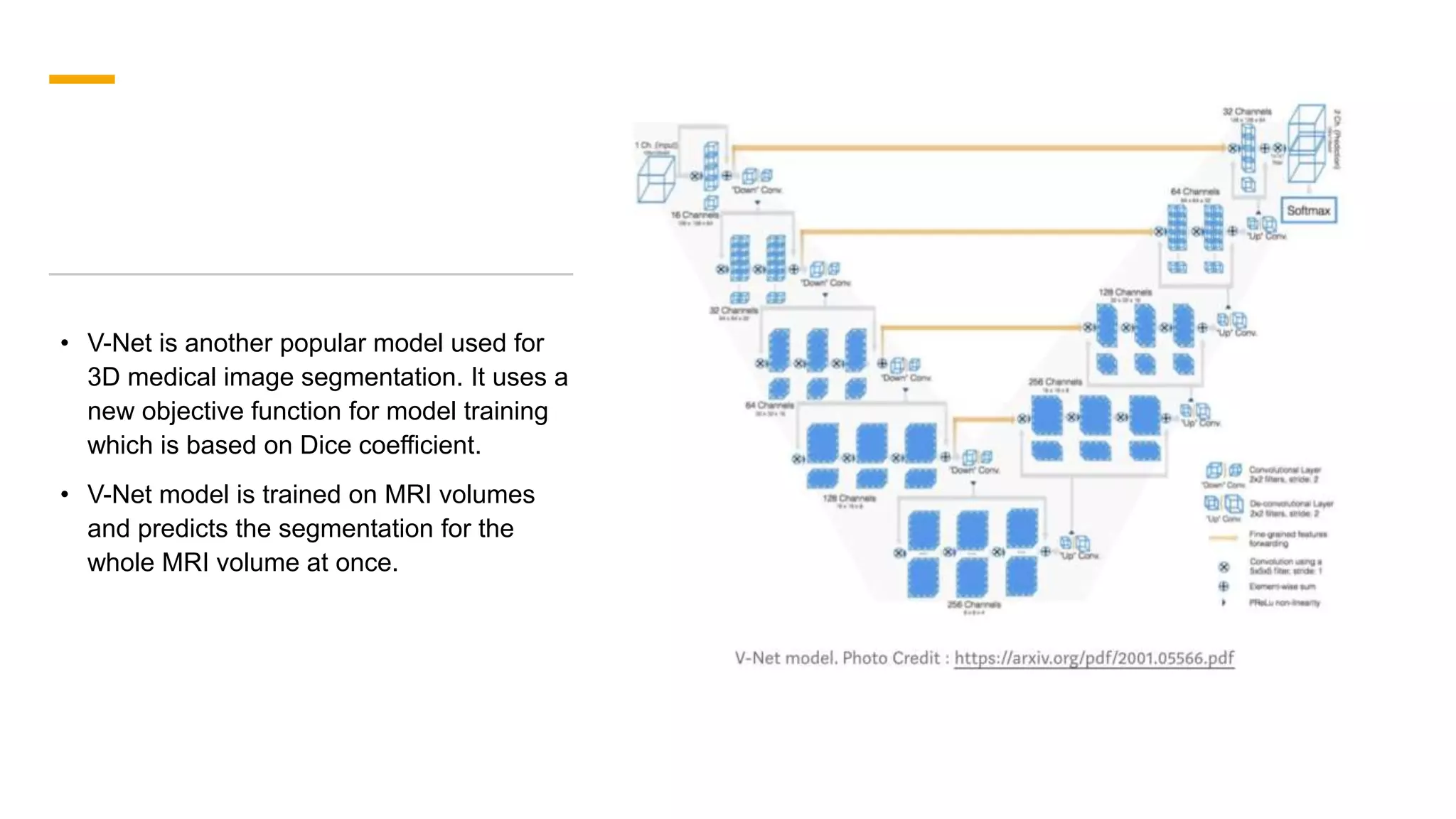
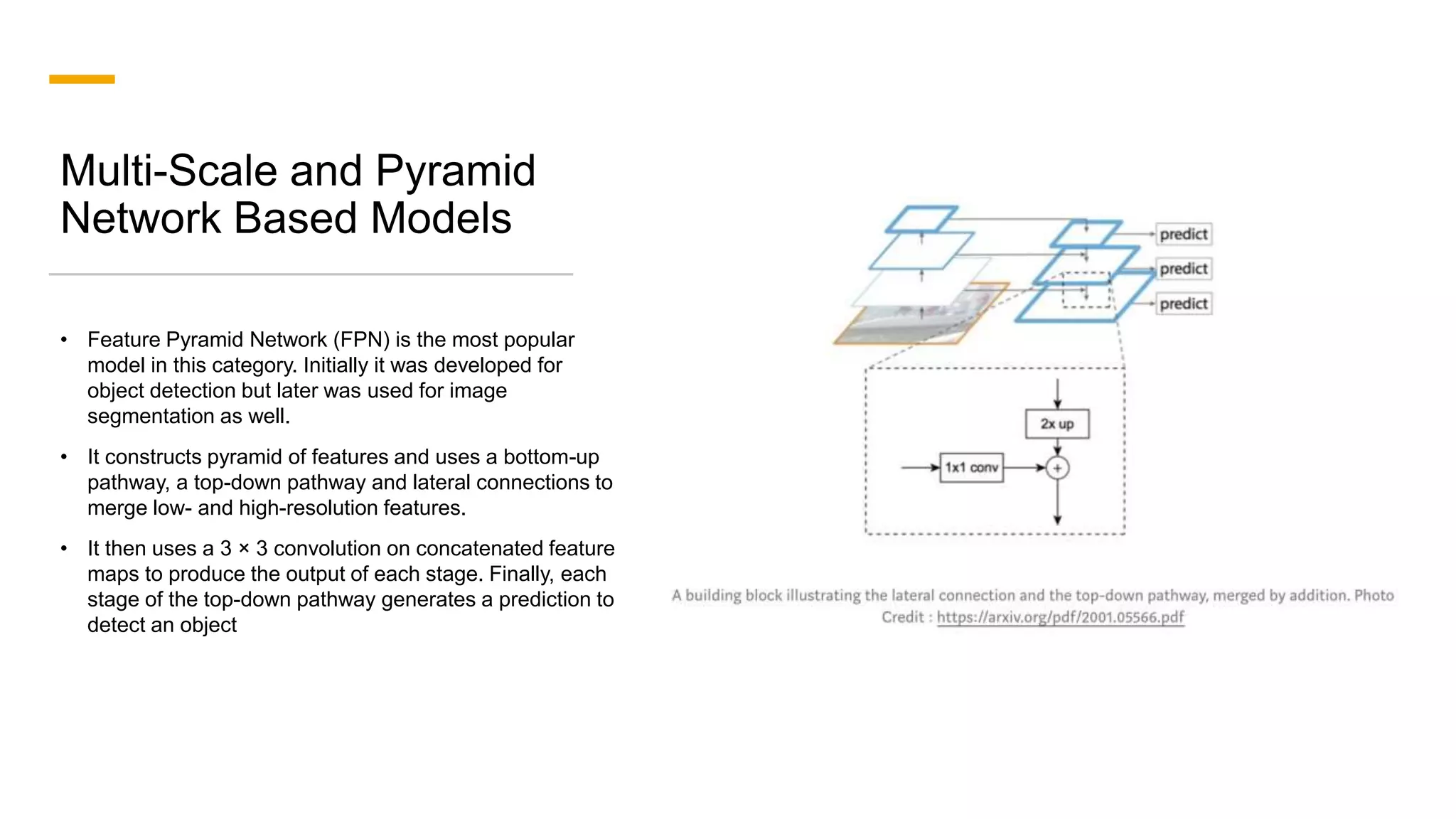
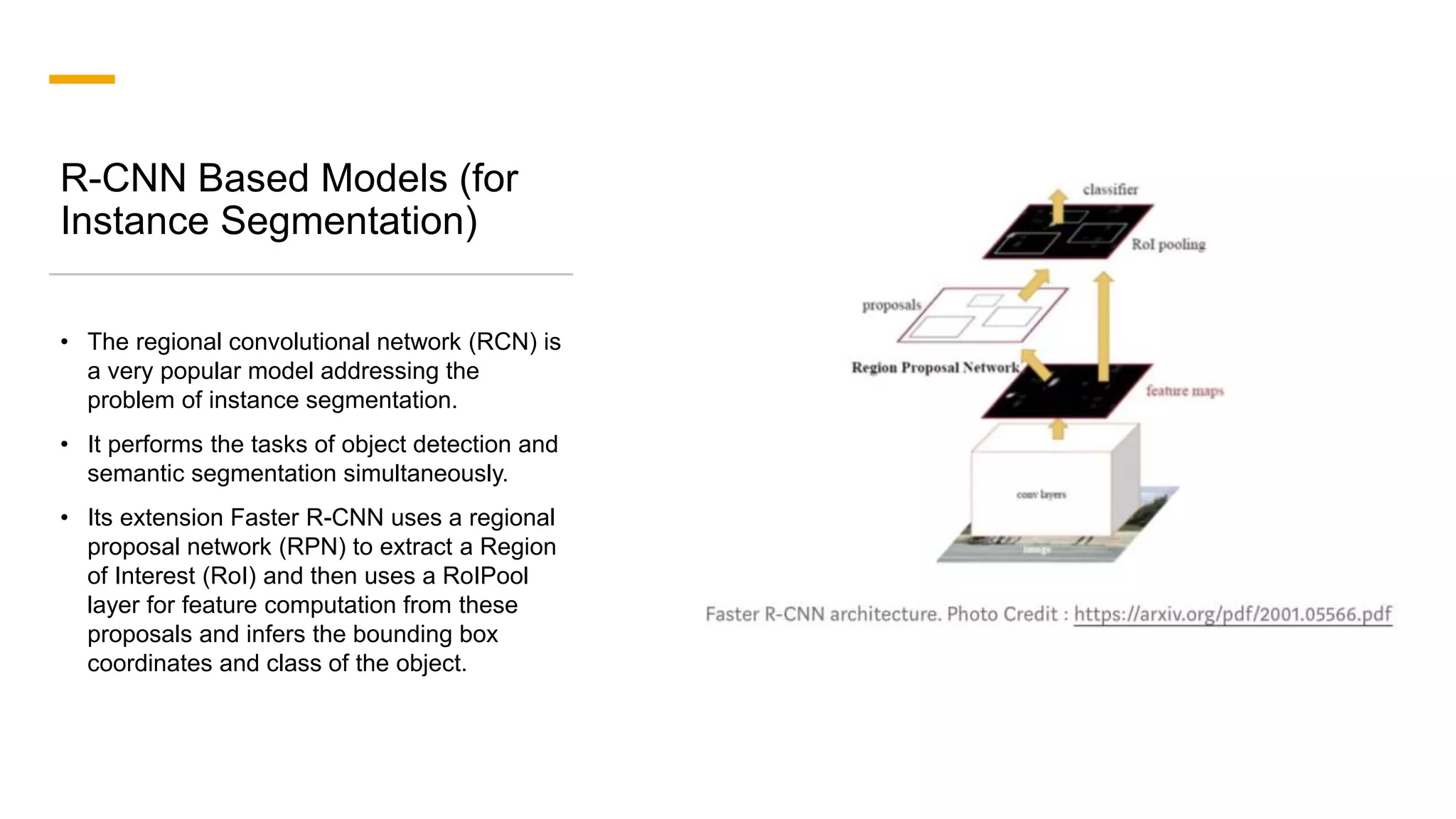


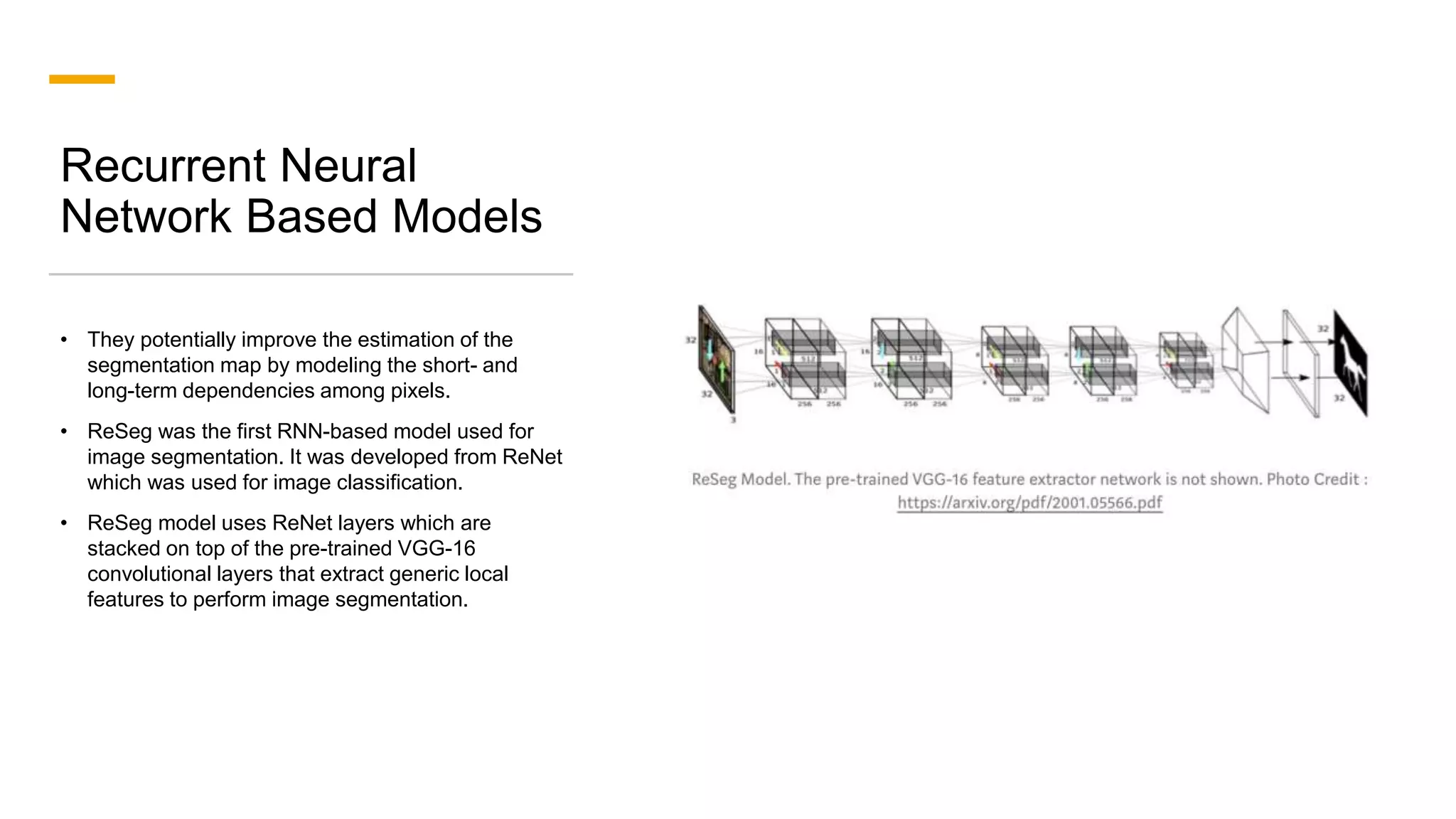
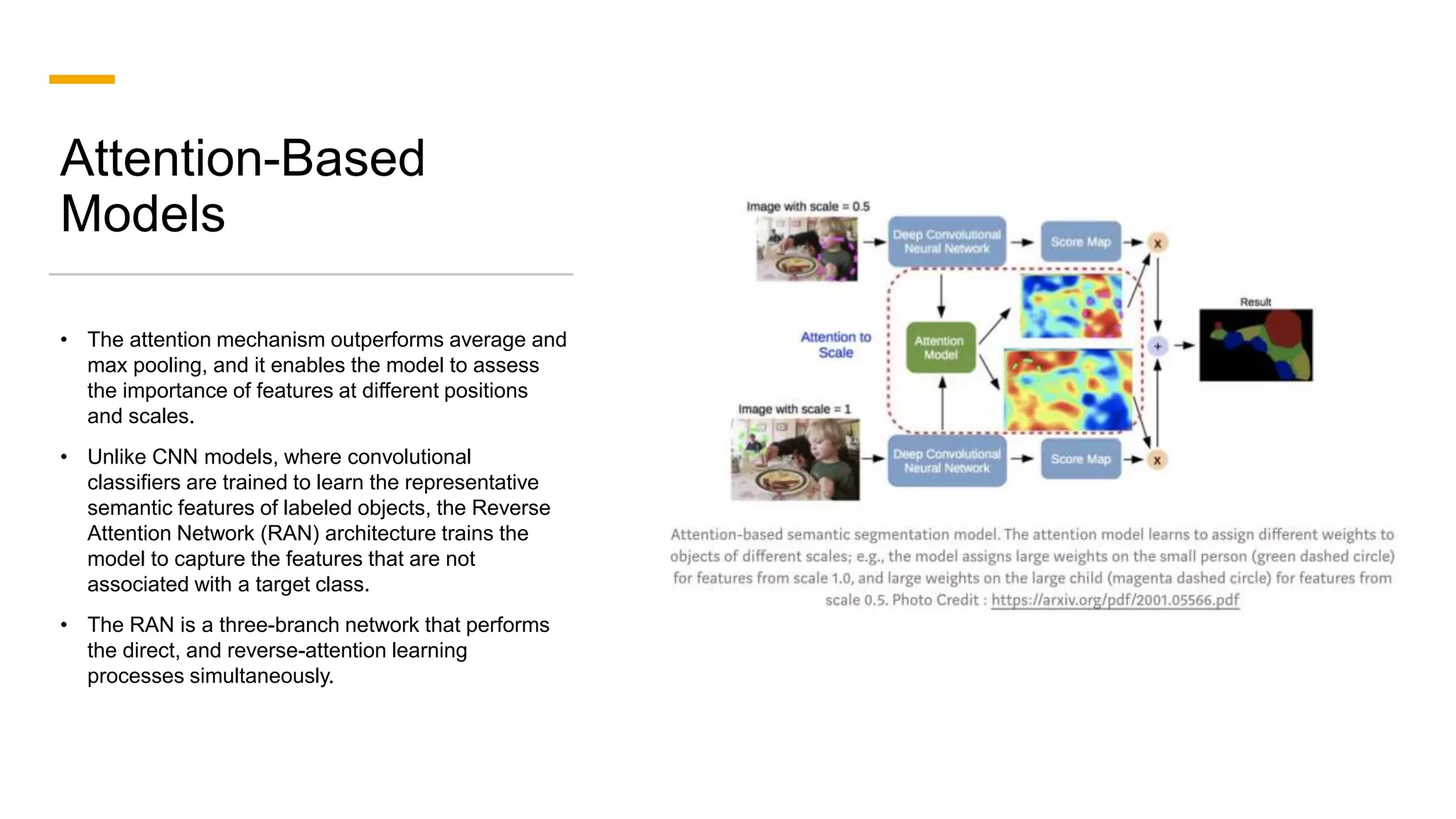
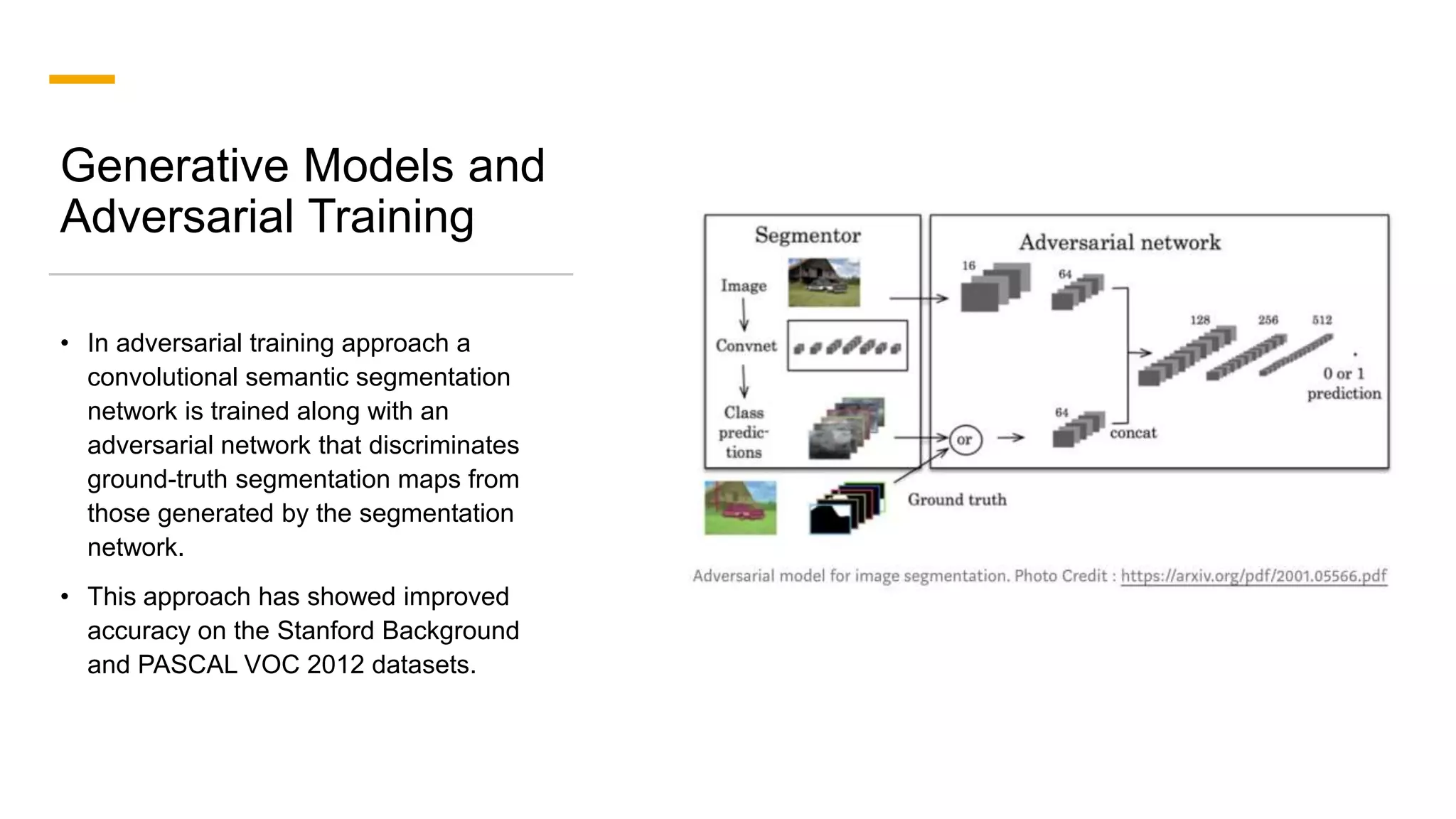

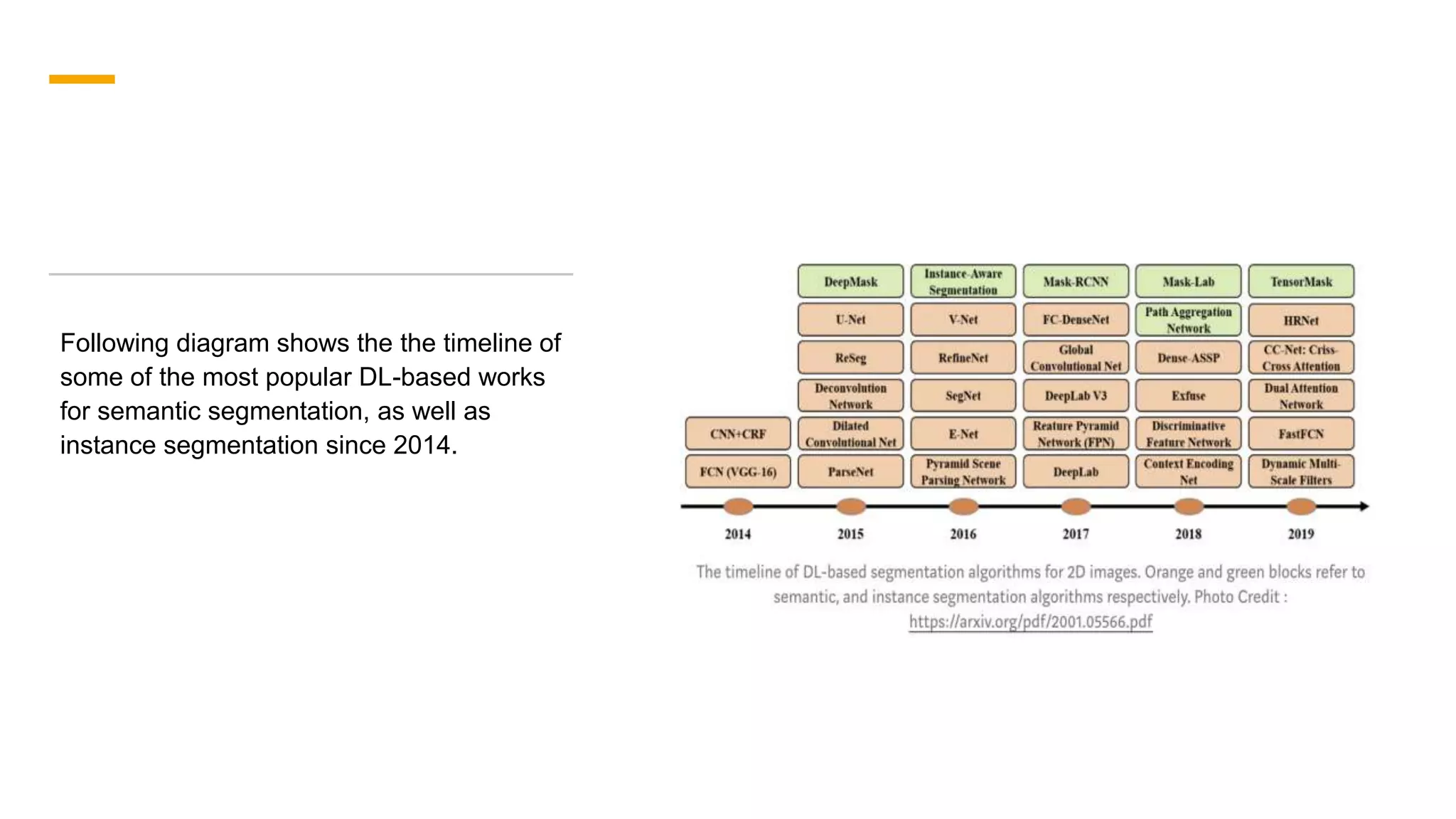




1. The document discusses various deep learning models for image segmentation, including fully convolutional networks, encoder-decoder models, multi-scale pyramid networks, and dilated convolutional models. 2. It provides details on popular architectures like U-Net, SegNet, and models from the DeepLab family. 3. The document also reviews datasets commonly used to evaluate image segmentation methods and reports accuracies of different models on the Cityscapes dataset.