Downloaded 45 times






![CNN Layers source: partially from cs231n_2017 A simple ConvNet for CIFAR-10 classification could have the architecture [INPUT - CONV - RELU - POOL - FC]. In more detail: • INPUT [e.g. 32x32x3] • Holds the raw pixel values of the image, width 32, height 32, and with three color channels R,G,B. • CONV layer [32x32x6] • Holds the output of neurons that are connected to local regions in the input, • each computing a dot product between their weights and a small region they are connected to in the input volume. This may result in volume such as [32x32x6] if we decided to use 6 filters. • RELU layer [32x32x6] • will apply an elementwise activation function, such as the max(0,x) thresholding at zero. This leaves the size of the volume unchanged ([32x32x6]). • POOL layer [16x16x6] • will perform a downsampling operation along the spatial dimensions (width, height), resulting in volume such as [16x16x6]. • FC (i.e. fully-connected) layer [400x1]> [120x1] > [84x1] • will compute the class scores, resulting in volume of size [1x1x10], where each of the 10 numbers correspond to a class score, such as among the 10 categories of CIFAR-10. As with ordinary Neural Networks and as the name implies, each neuron in this layer will be connected to all the numbers in the previous volume. Notes: switch 12 filters used in original note to 6 filters. 7/24/18 Creative Common BY-SA-NC 11](https://image.slidesharecdn.com/20180724ml-convolutionalneuralnetwork-180813195812/75/Machine-Learning-Convolutional-Neural-Network-11-2048.jpg)






![Alexnet - Trained Filters source: cs231n Example filters learned by Krizhevsky et al. Each of the 96 filters shown here is of size [11x11x3], and each one is shared by the 55*55 neurons in one depth slice. Notice that the parameter sharing assumption is relatively reasonable: If detecting a horizontal edge is important at some location in the image, it should intuitively be useful at some other location as well due to the translationally-invariant structure of images. There is therefore no need to relearn to detect a horizontal edge at every one of the 55*55 distinct locations in the Conv layer output volume. 7/24/18 Creative Common BY-SA-NC 22](https://image.slidesharecdn.com/20180724ml-convolutionalneuralnetwork-180813195812/75/Machine-Learning-Convolutional-Neural-Network-22-2048.jpg)
![Summary source: partially from cs231n_2017_lecture5.pdf slide-76 • Workflow 1. Initialize all filter weights and parameters with random numbers. 2. Use original images as input, 2.1 Apply Filters to Original Image > Conv layer 2.2 Apply Activation Function (e.g. ReLU) to Conv layer > Feature Map 2.3 Apply Pooling Filter to Feature Map > Smaller Feature Map (optional) 2.4 Flatten the Feature Map > Full Connected Network (FC) 2.5 Apply ANN training (forward and backward propagation) to FC 2.6 Optimize the Weights, Calculate error, adjust weights, loop with original images till the probability of correct class is high. 3. Test the result, if happy, then save filters (weight and parameters) for future use, else loop. • ConvNets stack CONV,POOL,FC layers [(CONV-RELU)*N-POOL?]*M-(FC-RELU)*K, SOFTMAX where - N is usually up to ~5, M is large, 0 <= K <= 2 - Trend towards smaller filters and deeper architectures - Trend towards getting rid of POOL/FC layers (just CONV) • But!! - recent advances such as ResNet/GoogLeNet challenge this paradigm. - Proposed new Capsule Neural Network can overcome some shortcoming of ConvNets. 7/24/18 Creative Common BY-SA-NC 23](https://image.slidesharecdn.com/20180724ml-convolutionalneuralnetwork-180813195812/75/Machine-Learning-Convolutional-Neural-Network-23-2048.jpg)
 • [AlexNet](https://www.jeremyjordan.me/convnet-architectures/#alexnet) • [VGG 16](https://www.jeremyjordan.me/convnet-architectures/#vgg16 ) Modern network architectures • [Inception](https://www.jeremyjordan.me/convnet-architectures/#inception) • [ResNet](https://www.jeremyjordan.me/convnet-architectures/#resnet) • [DenseNet](https://www.jeremyjordan.me/convnet-architectures/#densenet )](https://image.slidesharecdn.com/20180724ml-convolutionalneuralnetwork-180813195812/75/Machine-Learning-Convolutional-Neural-Network-24-2048.jpg)
 • [Using Convolutional Neural Networks for Image Recognition](https://ip.cadence.com/uploads/901/cnn_wp-pdf) • [Activation Functions: Neural Networks](https://towardsdatascience.com/activation-functions-neural-networks- 1cbd9f8d91d6) • [Convolutional Neural Networks Tutorial in TensorFlow](http://adventuresinmachinelearning.com/convolutional-neural- networks-tutorial-tensorflow/) • [Rethinking the Inception Architecture for Computer Vision](https://arxiv.org/pdf/1512.00567.pdf) 7/24/18 Creative Common BY-SA-NC 26](https://image.slidesharecdn.com/20180724ml-convolutionalneuralnetwork-180813195812/75/Machine-Learning-Convolutional-Neural-Network-26-2048.jpg)
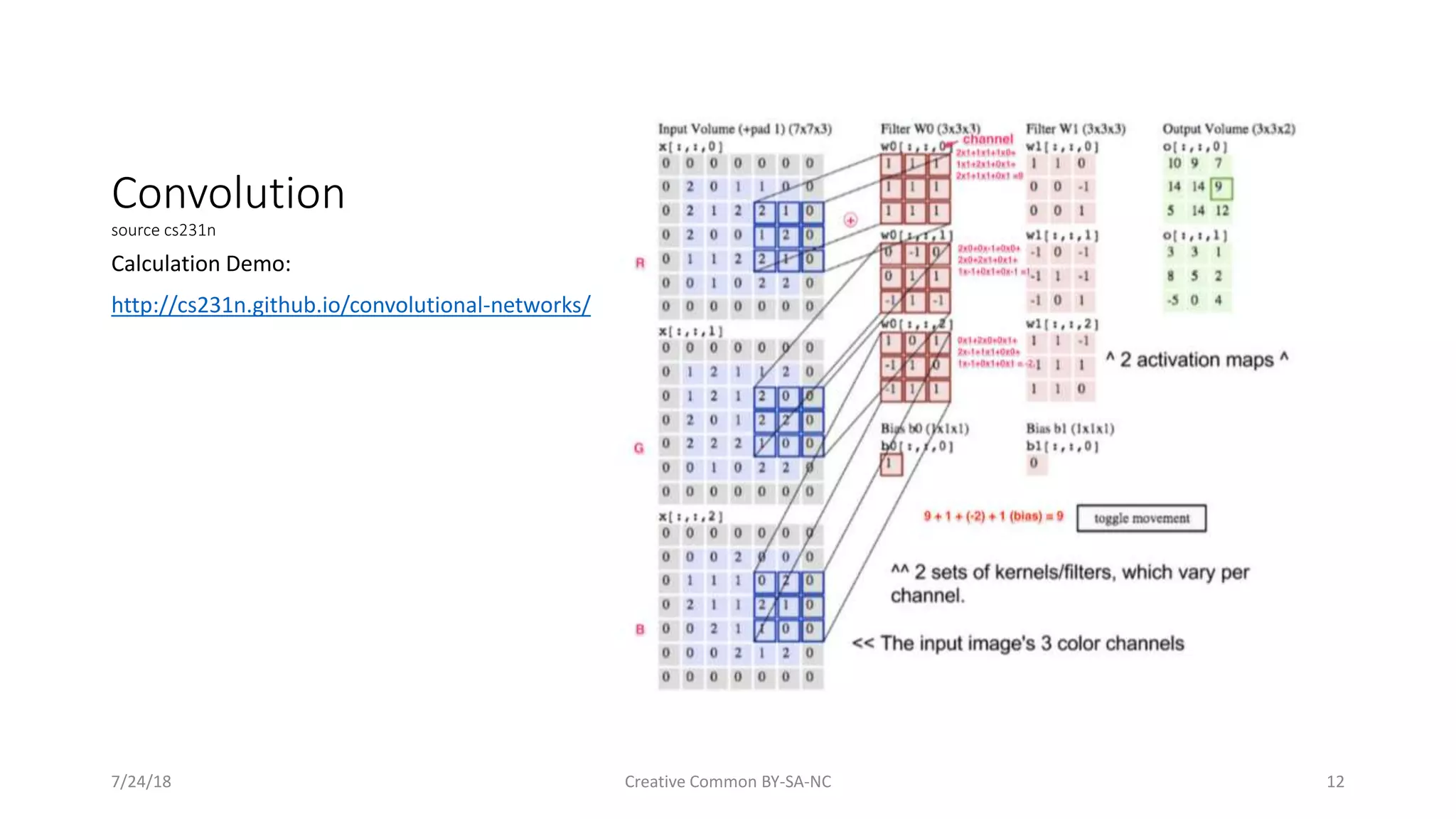
 building image [Demo – cs231n](http://cs231n.stanford.edu/) end to end architecture in real-time [Demo – convolution calculation](http://cs231n.github.io/convolutional-networks/ ) dot product [Demo – cifar10 ](https://cs.stanford.edu/people/karpathy/convnetjs/demo/cifar10.html) in details filter/ReLU 7/24/18 Creative Common BY-SA-NC 27](https://image.slidesharecdn.com/20180724ml-convolutionalneuralnetwork-180813195812/75/Machine-Learning-Convolutional-Neural-Network-27-2048.jpg)
 use tensorflow local [image classification with Keras](https://github.com/rkuo/ml-tensorflow/blob/master/cnn-cifar10/cnn-cifar10-keras-v0.2.0.ipynb ) use keras local [catsdogs](https://github.com/rkuo/fastai/blob/master/lesson1-catsdogs/Fastai_2_Lesson1.ipynb) use fastai with pre-trained model = resnet34 [tableschairs](https://github.com/rkuo/fastai/blob/master/lesson1-tableschairs/Fastai_2_Lesson1a-tableschairs.ipynb ) switch data 7/24/18 Creative Common BY-SA-NC 28](https://image.slidesharecdn.com/20180724ml-convolutionalneuralnetwork-180813195812/75/Machine-Learning-Convolutional-Neural-Network-28-2048.jpg)







The document provides an overview of convolutional neural networks (CNNs) for visual recognition. It discusses the basic concepts of CNNs such as convolutional layers, activation functions, pooling layers, and network architectures. Examples of classic CNN architectures like LeNet-5 and AlexNet are presented. Modern architectures such as Inception and ResNet are also discussed. Code examples for image classification using TensorFlow, Keras, and Fastai are provided.
Overview of Convolutional Neural Networks (CNNs) focusing on visual recognition.
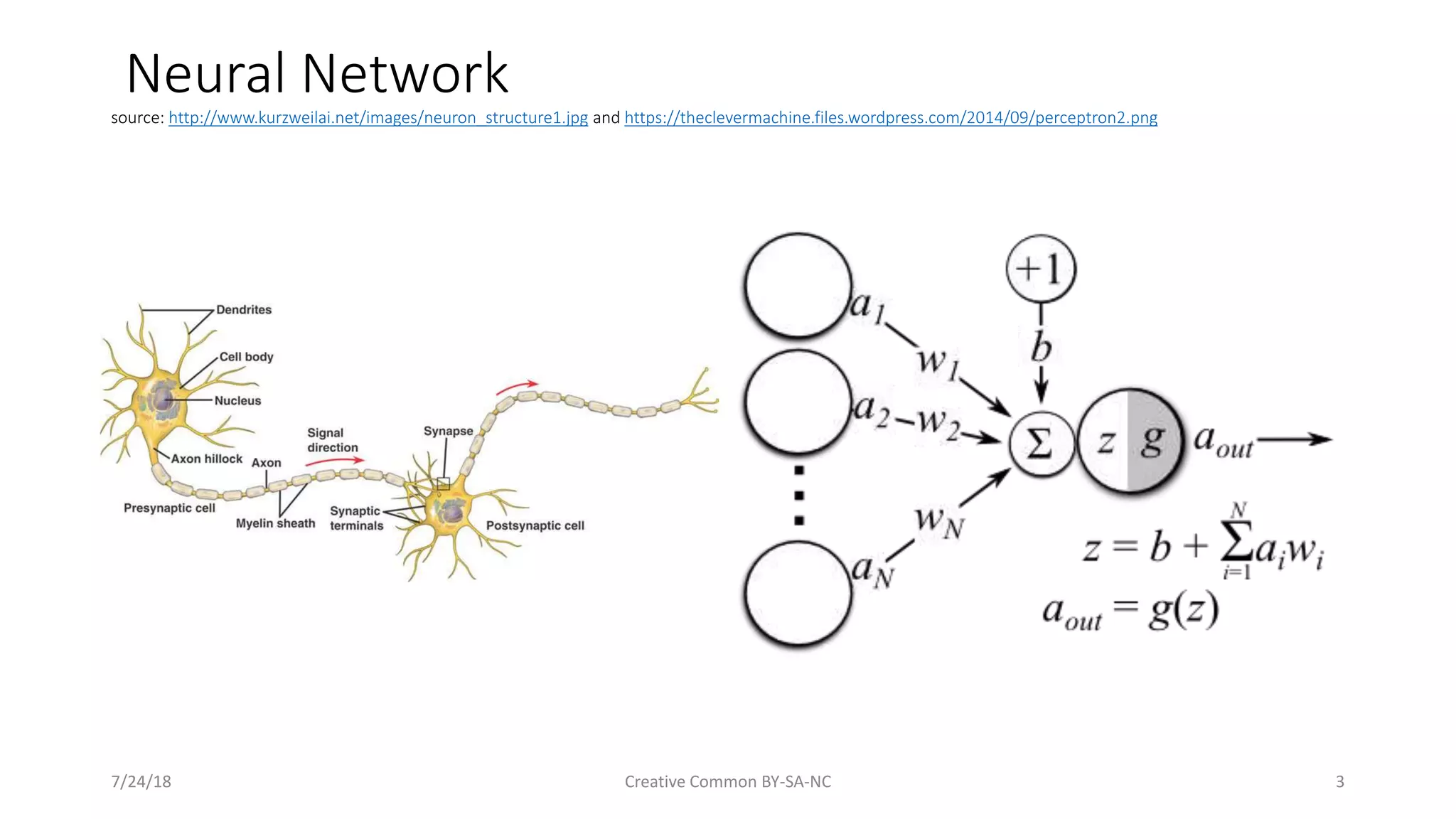
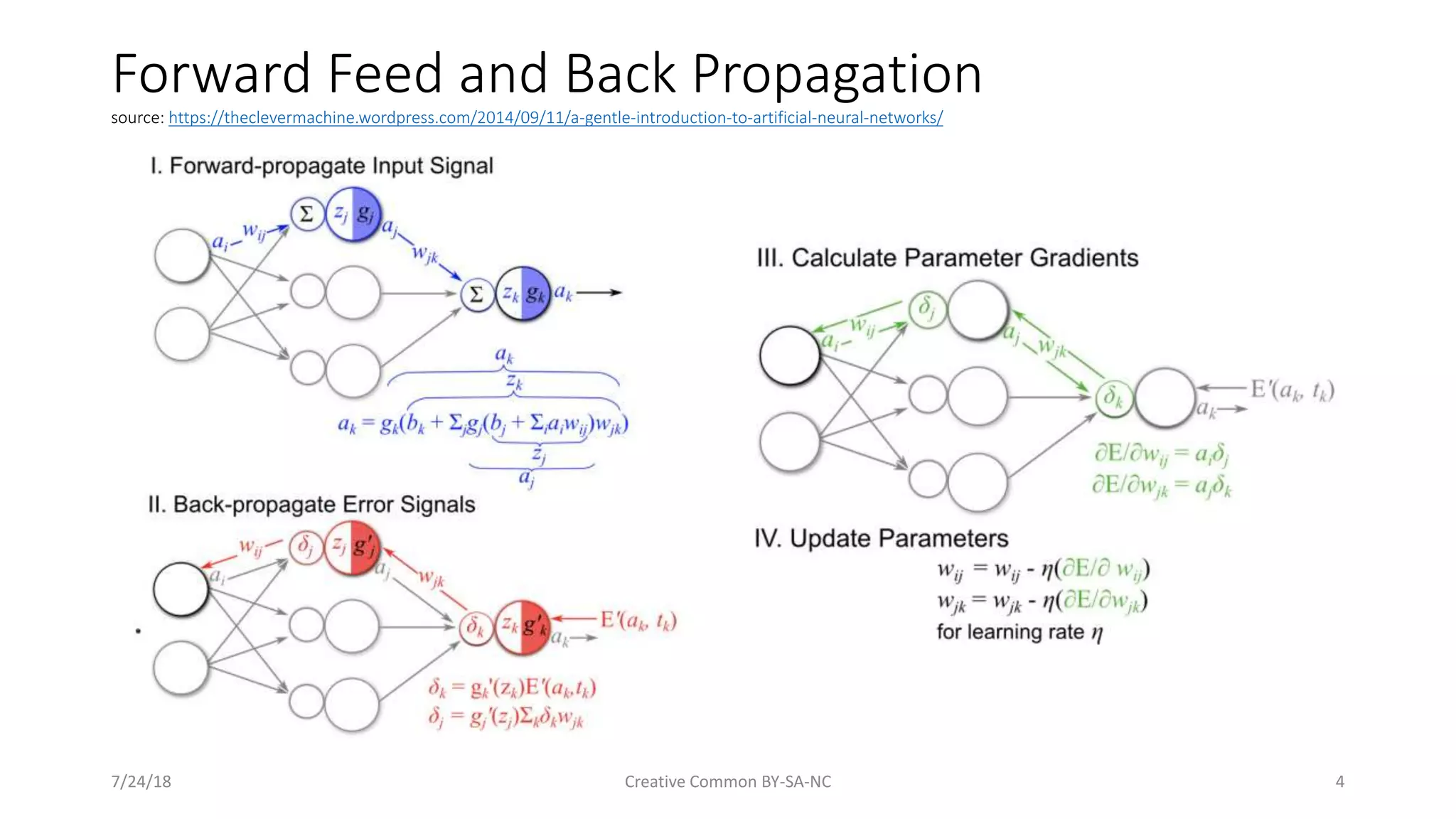
Definition and basic structure of neural networks along with details on the forward feed and backpropagation.
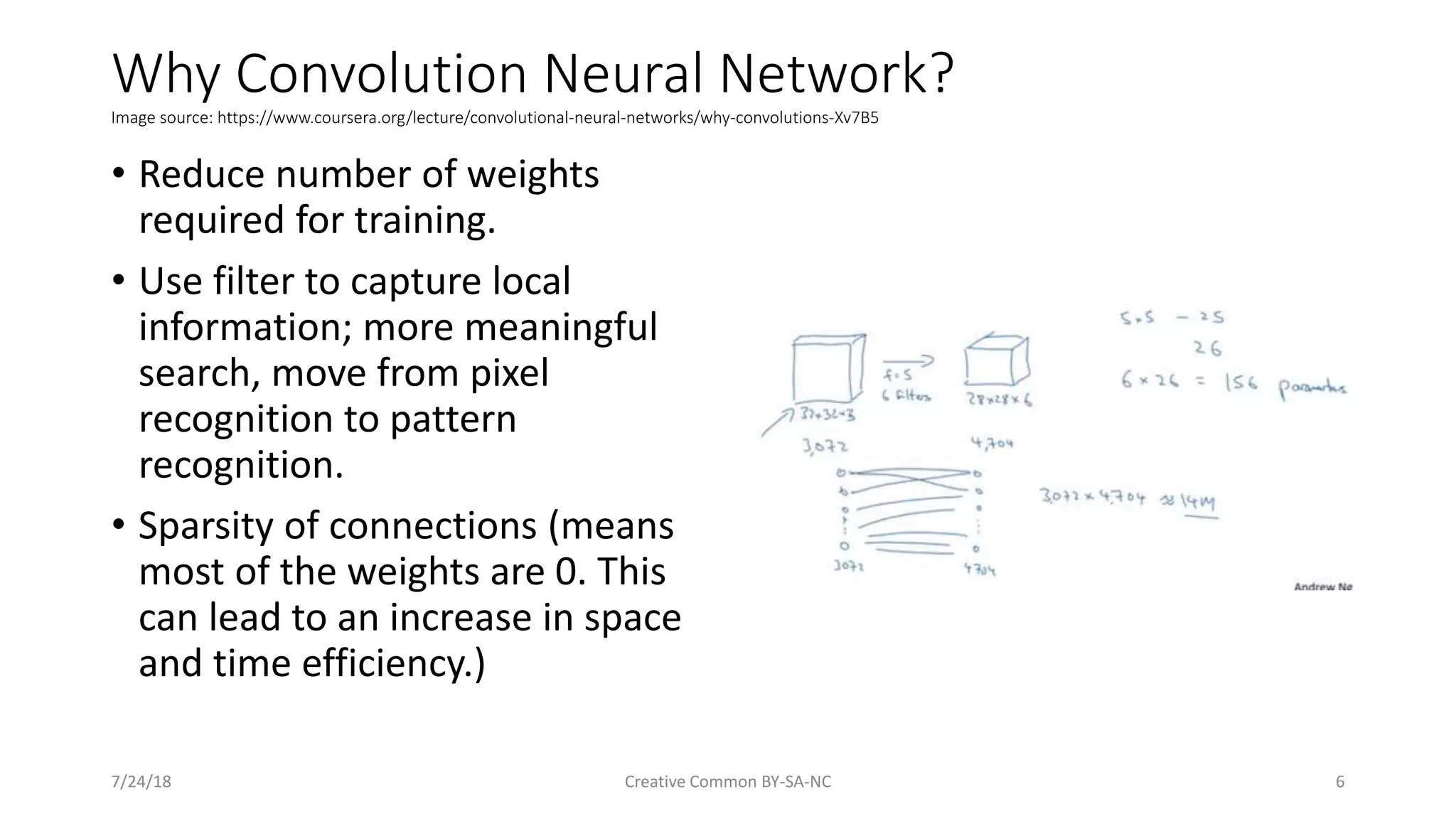
Highlights the necessity of convolution in CNNs, including efficiency in weight reduction and pattern recognition.
Discusses the convolution processes and basic operations important in CNN architecture.
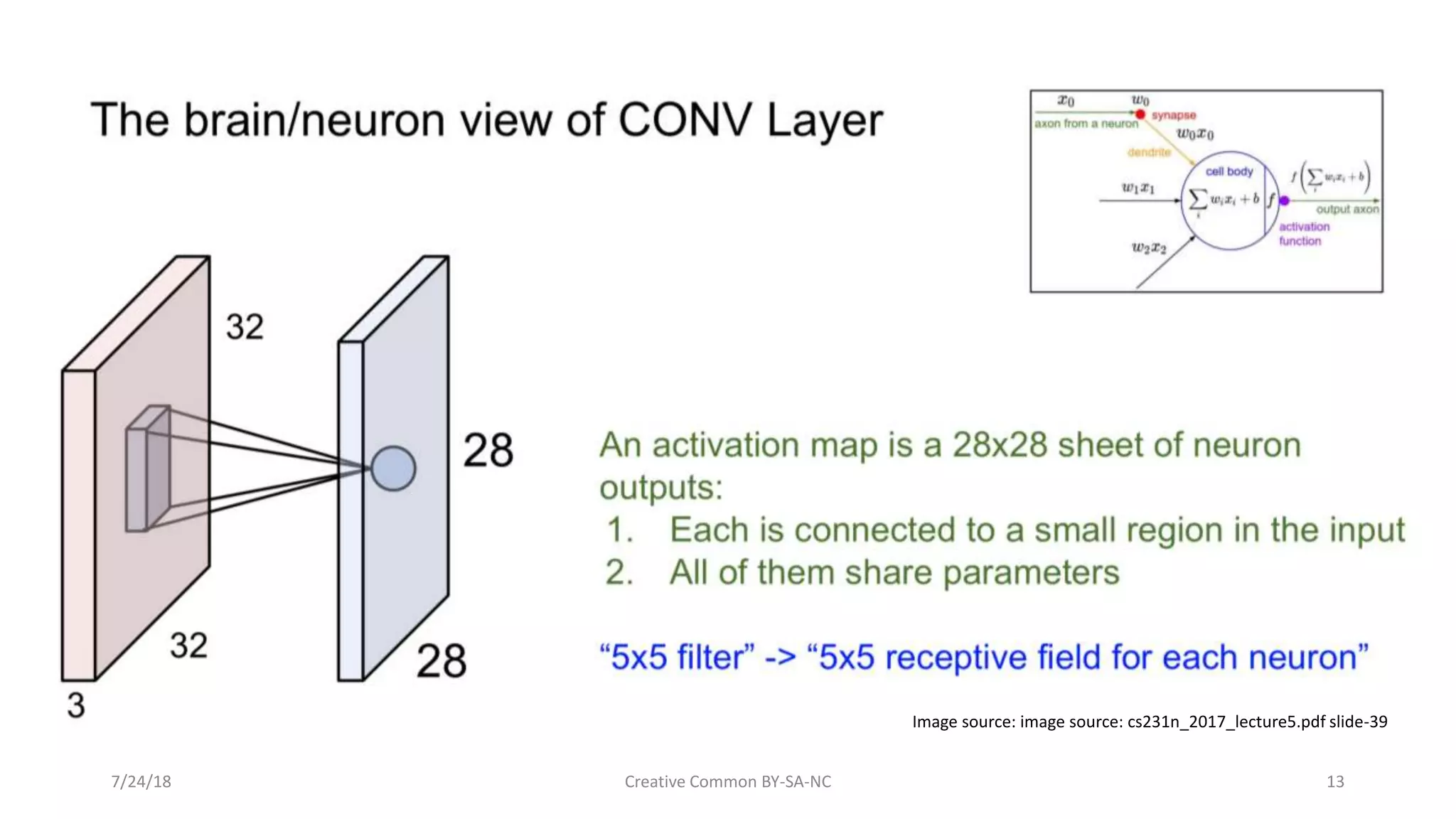
Details on CNN architecture, layers including convolution, ReLU function, pooling, and their dimensions.
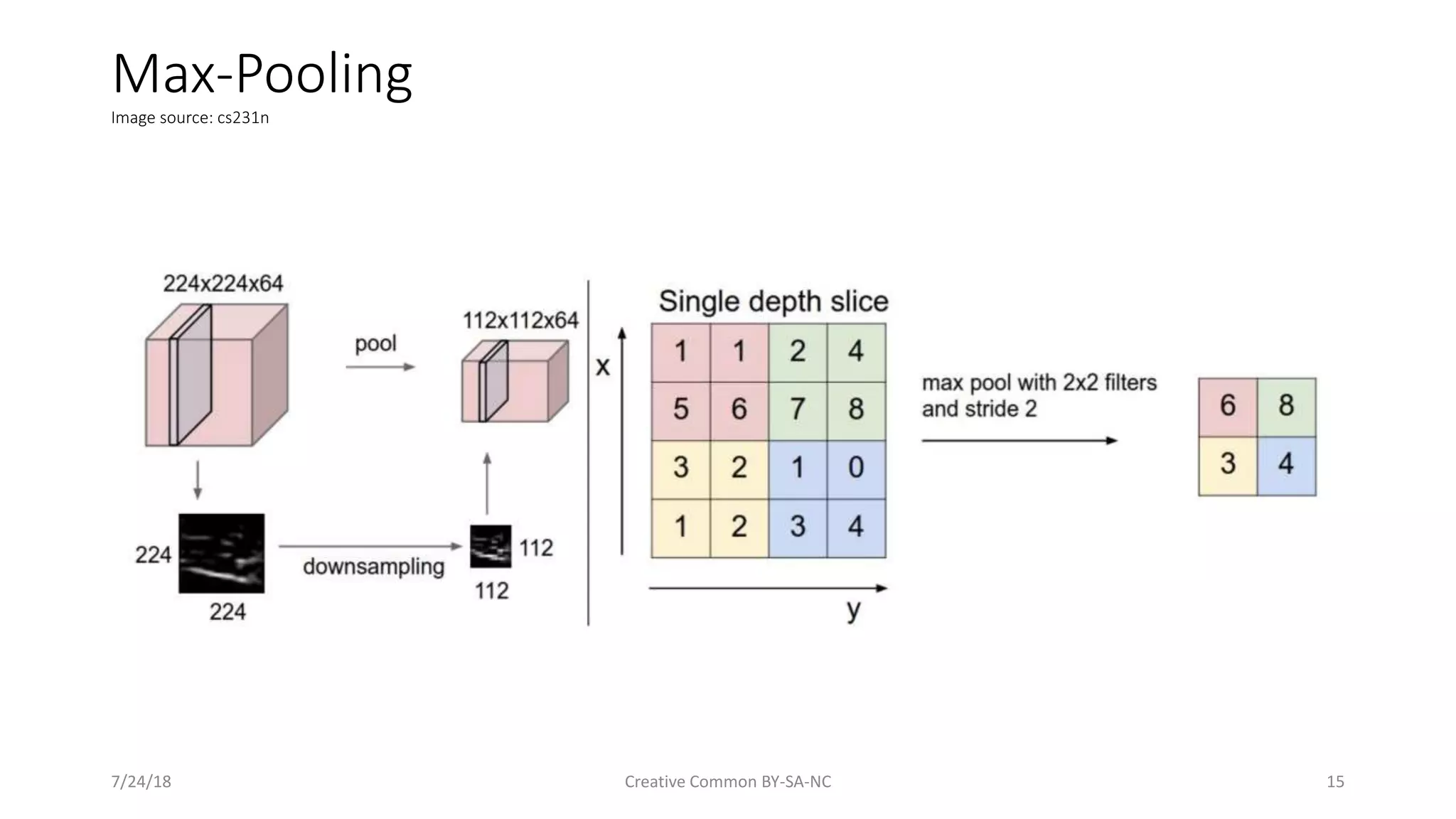
Discusses activation functions, particularly ReLU, and the concept of max pooling.
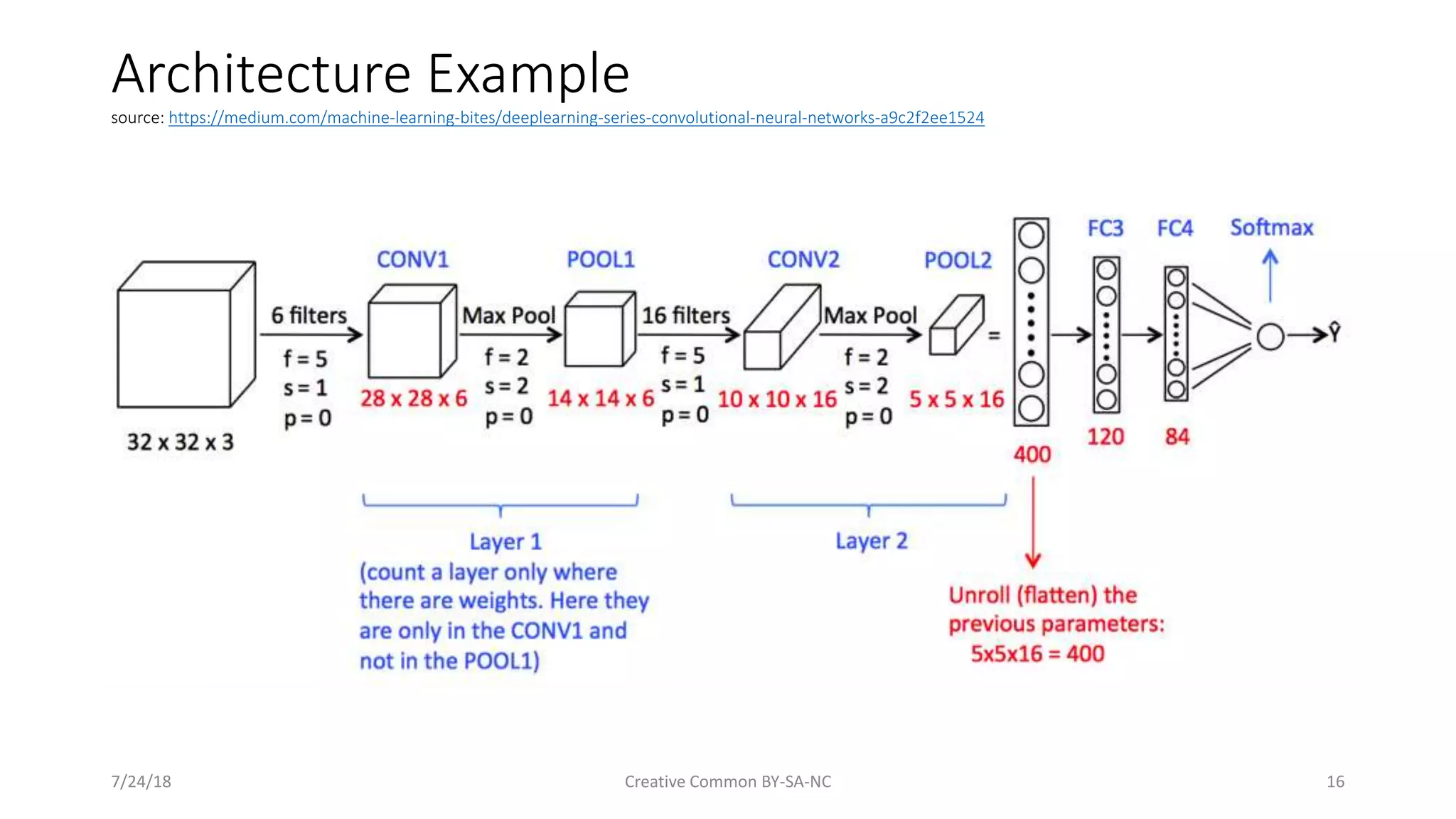
Provides examples of CNN architectures including specifics on structure and filter training.
Summarizes the workflow for developing CNNs, from initializing weights to testing and saving models.
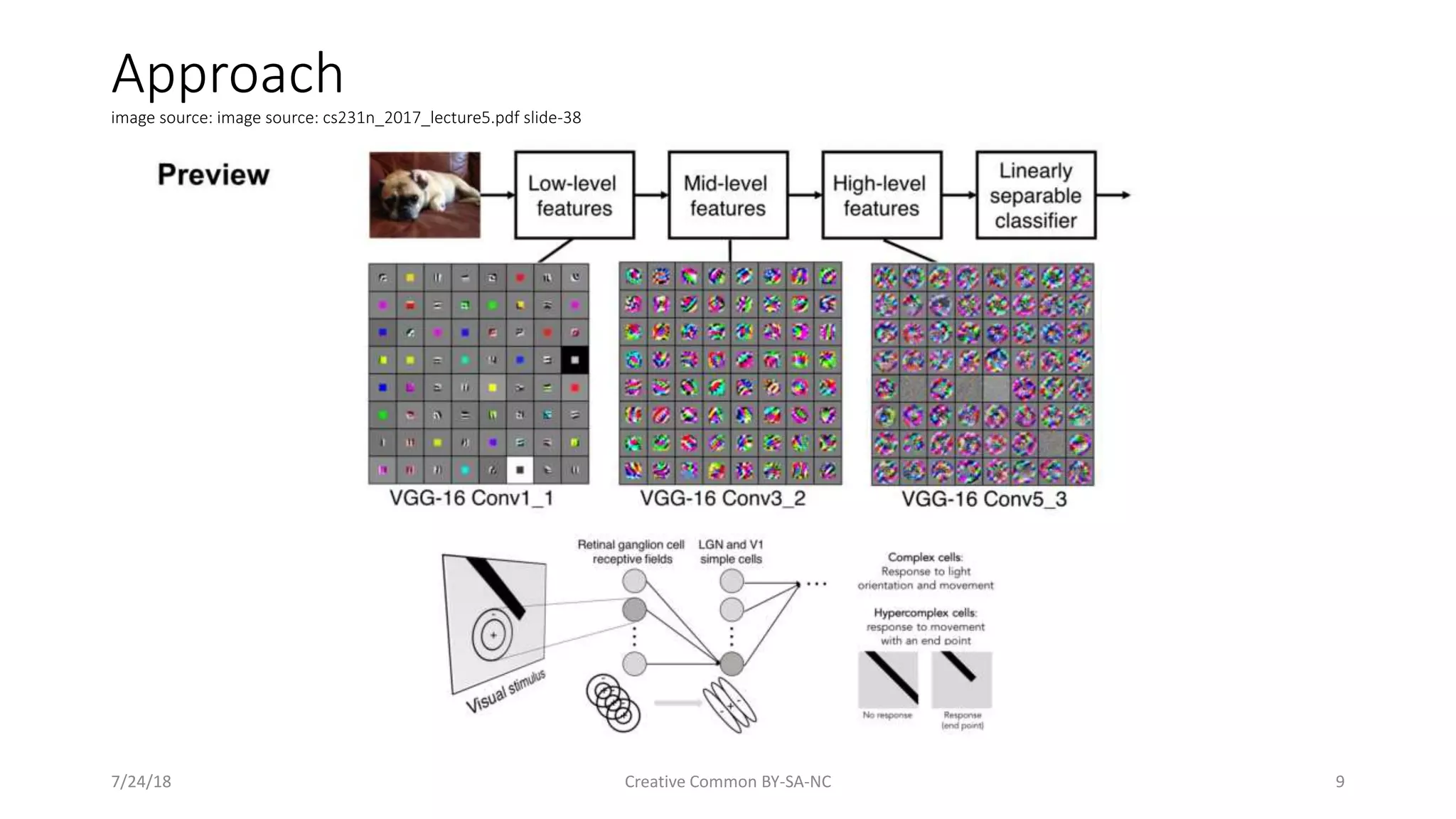
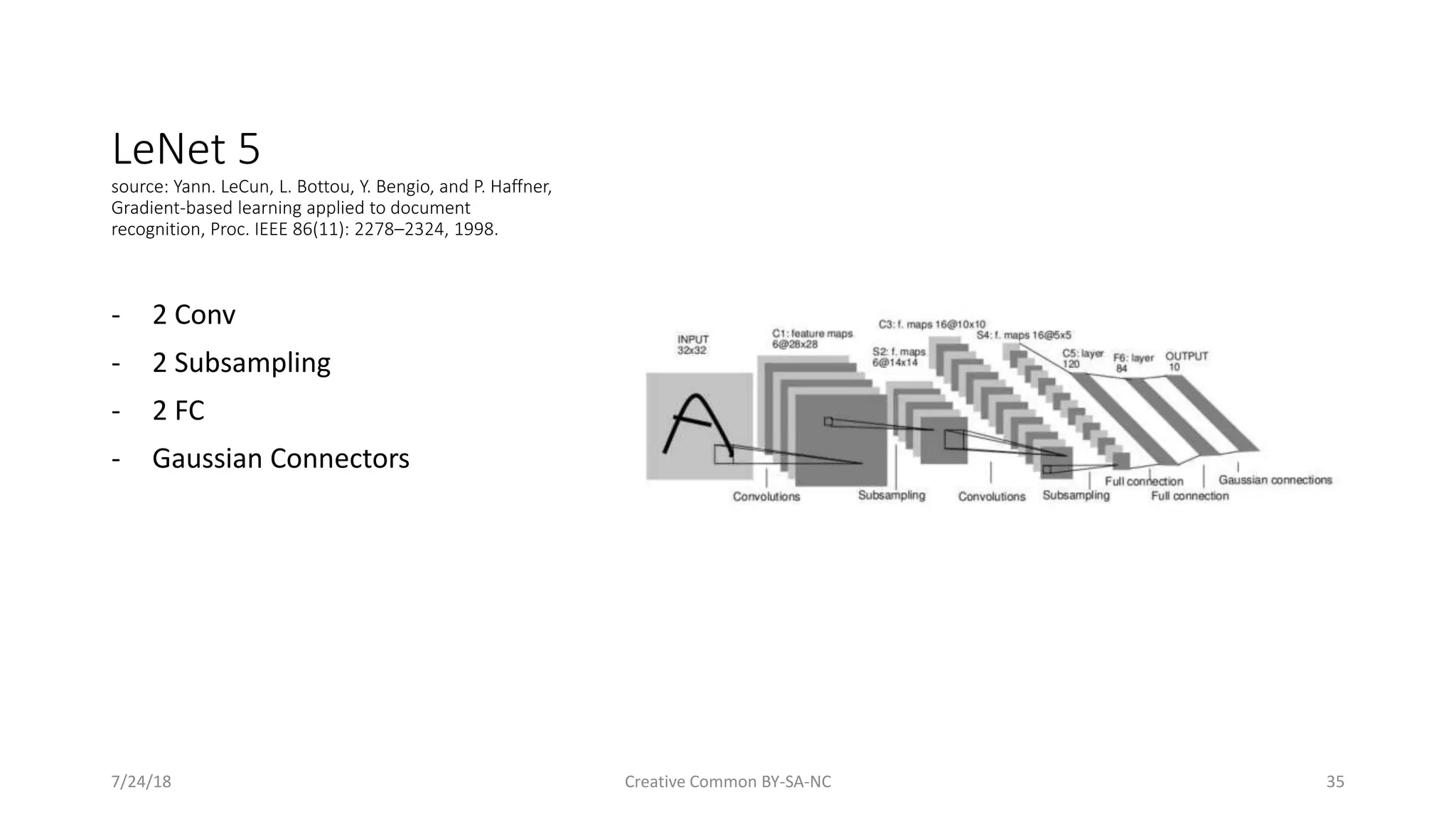
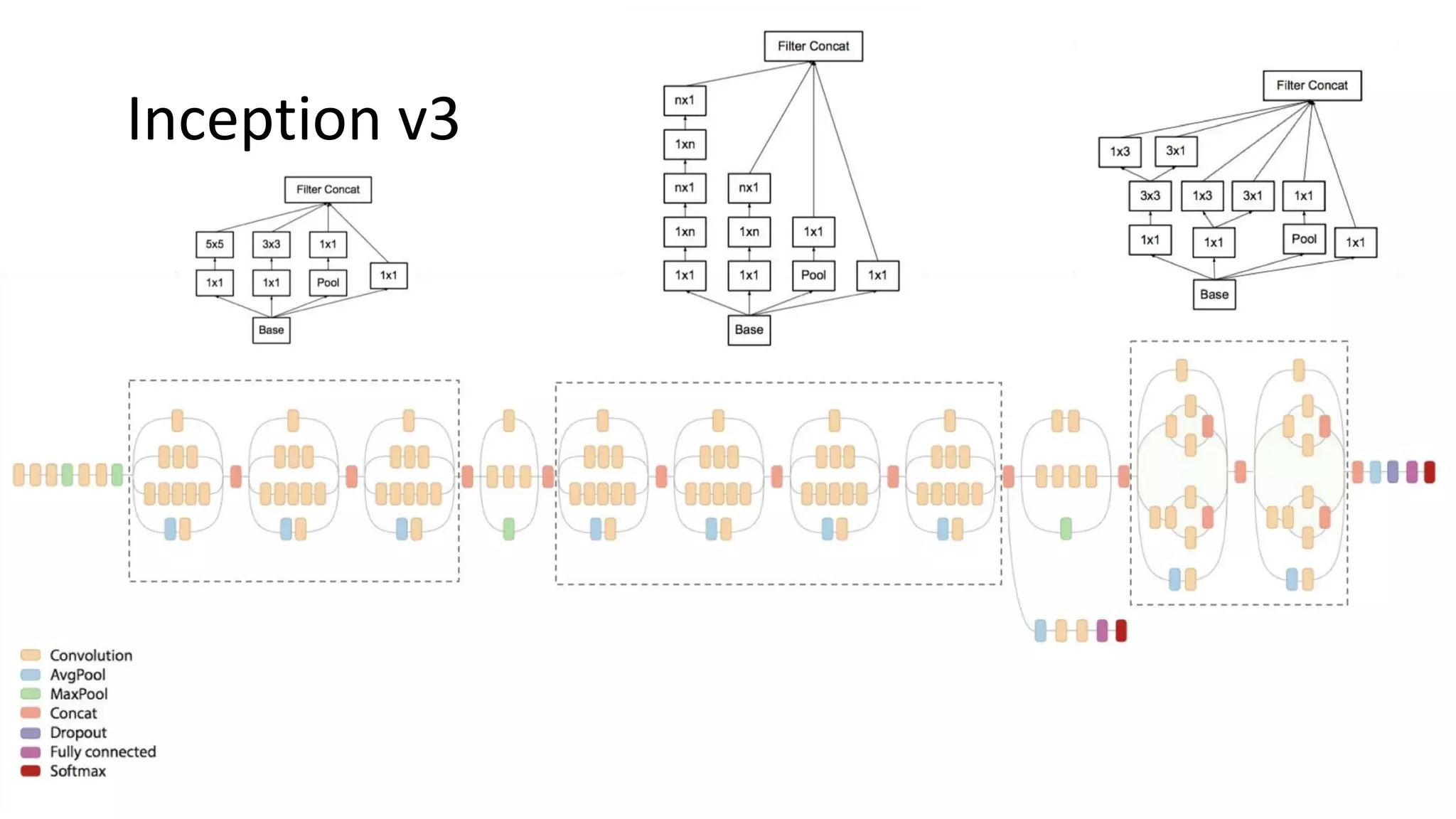
A look at both classic and modern CNN architectures such as LeNet-5, AlexNet, and ResNet.
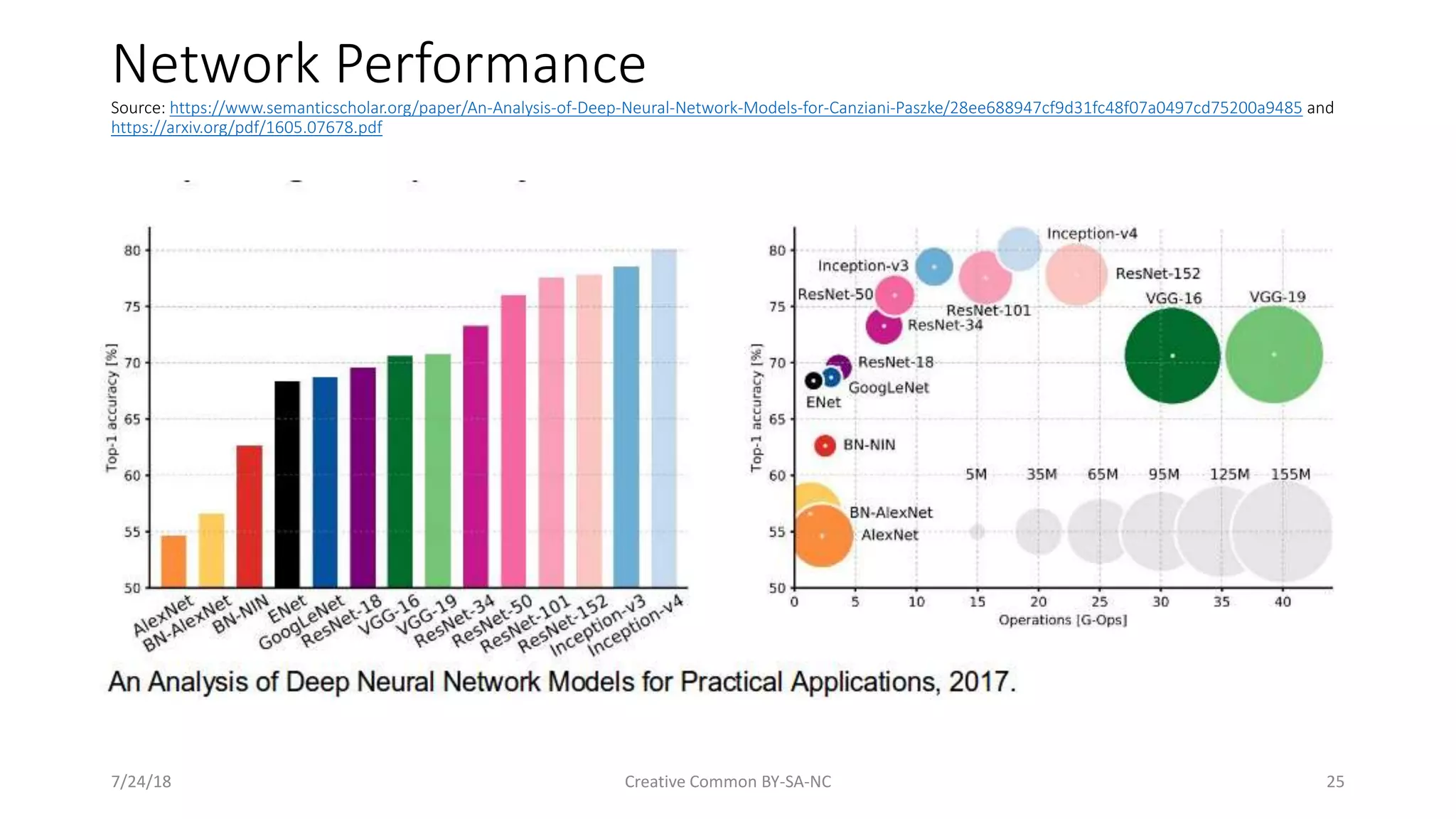
Discusses the performance evaluation of different deep neural networks for various tasks.
List of references and resources for more information on CNNs and their applications.
Links to various demos showcasing real-time CNN architectures and calculations.
Practical code examples for image classification using different frameworks like TensorFlow and Keras.
Reiterates the benefits of using CNNs, including reduced weights and improved efficiency.
Specific architectures like LeNet-5 and Inception v3 with historical context.