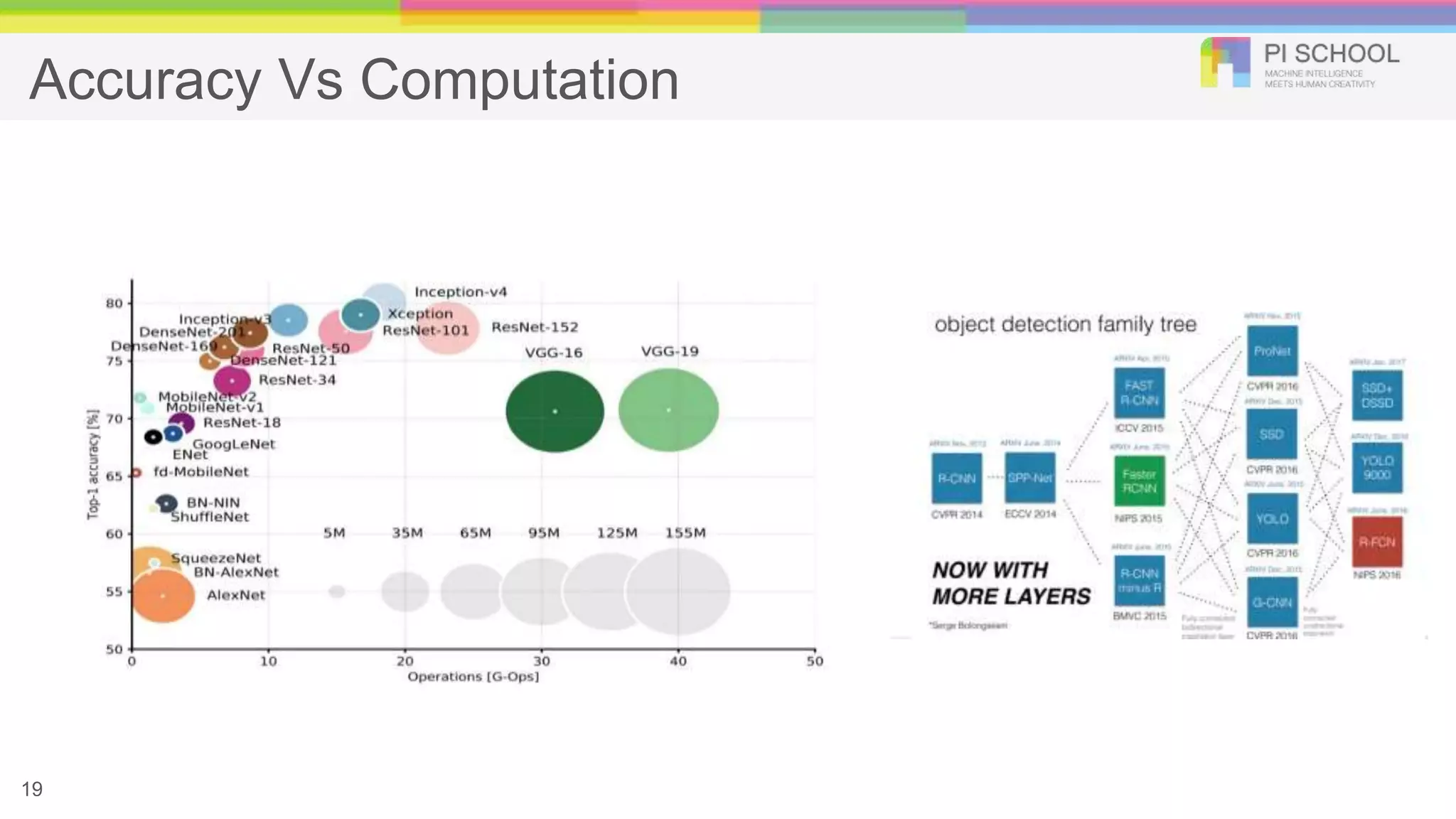
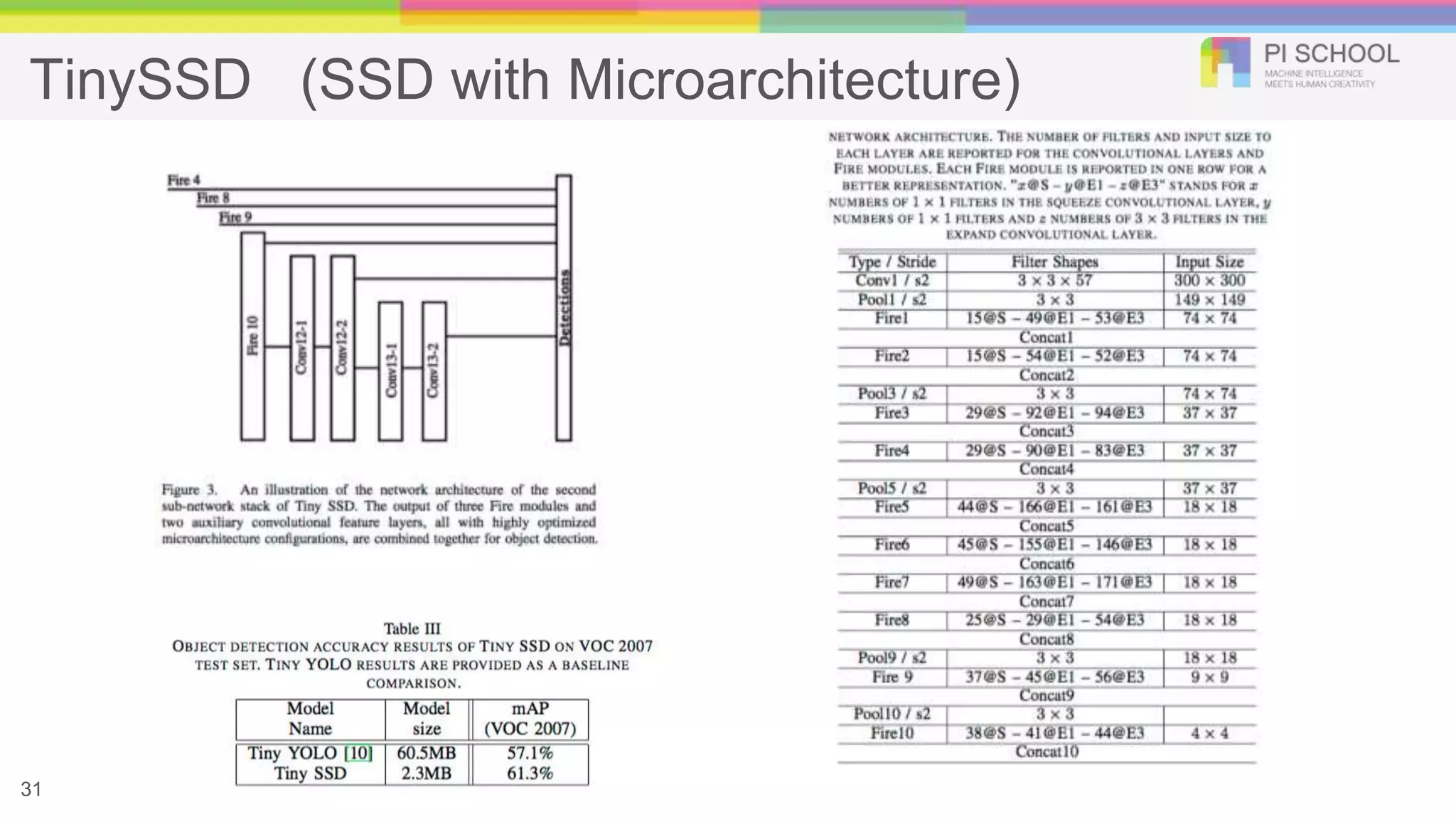
The document discusses advancements in object detection, highlighting key methodologies such as SqueezeNet, SSD, and Faster R-CNN, which improve performance in applications like autonomous vehicles and smart surveillance. It explains various strategies for enhancing CNN architectures, including pruning and quantization, to achieve efficient and accurate object detection. The presentation emphasizes the integration of AI in embedded systems to achieve low-latency and privacy-preserving solutions.
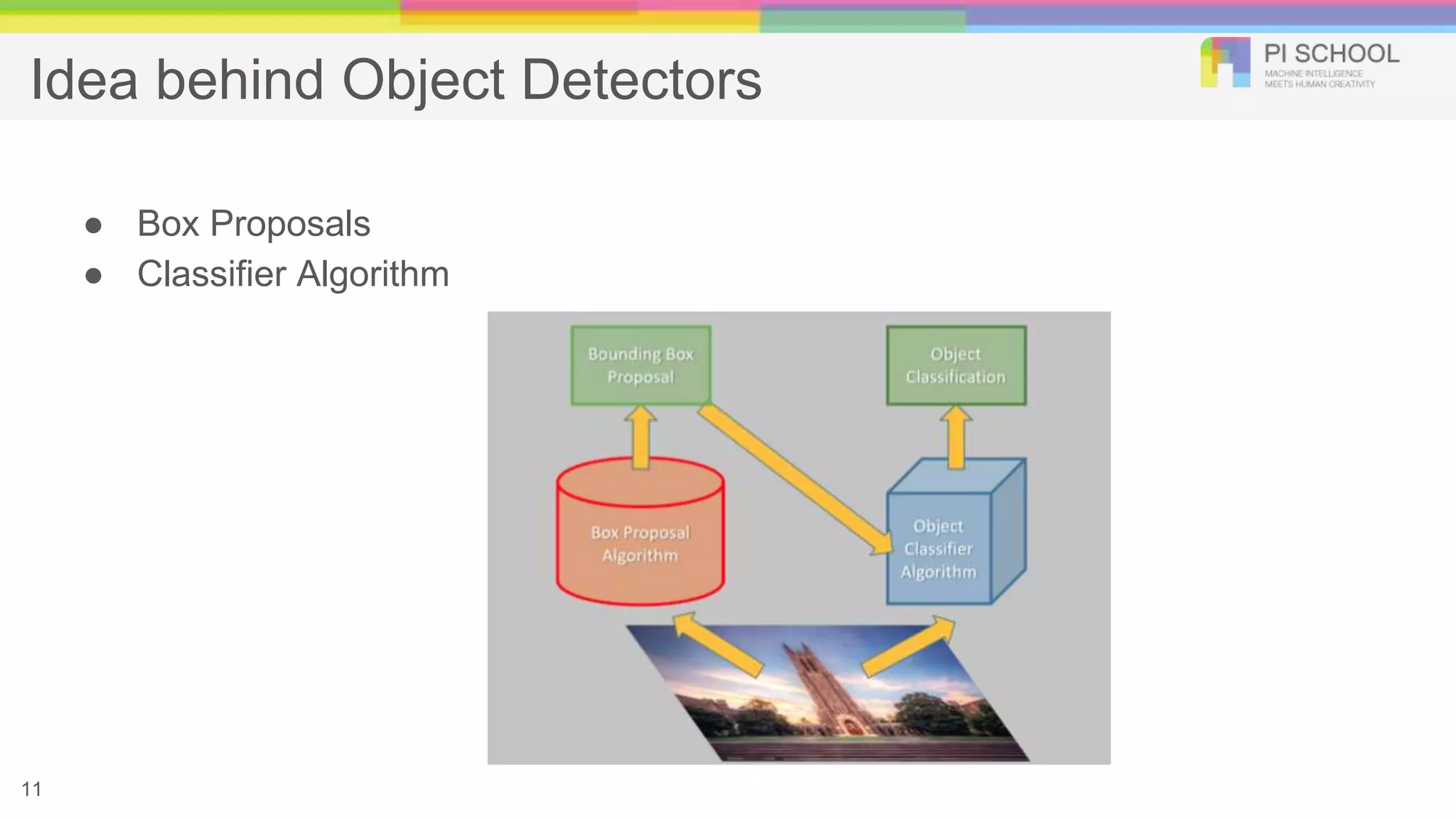
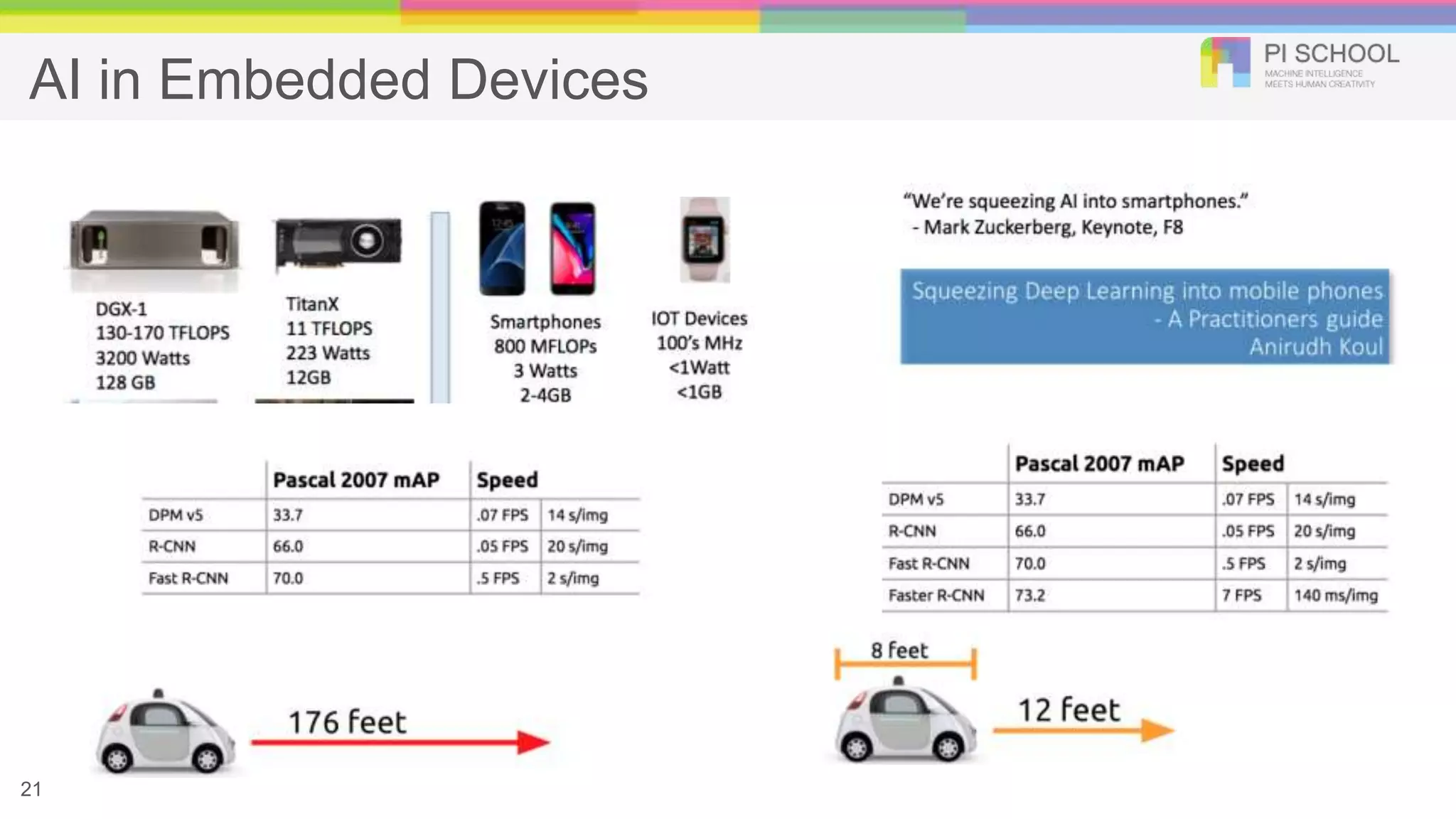
Image Classification/Object Detection ●Autonomous vehicles, smart video surveillance, facial detection and various applications, fast and robust object detection is need of an hour ● Nonly recognizing and classifying every object in an image, but localizing each one by drawing the appropriate bounding box around it. 3
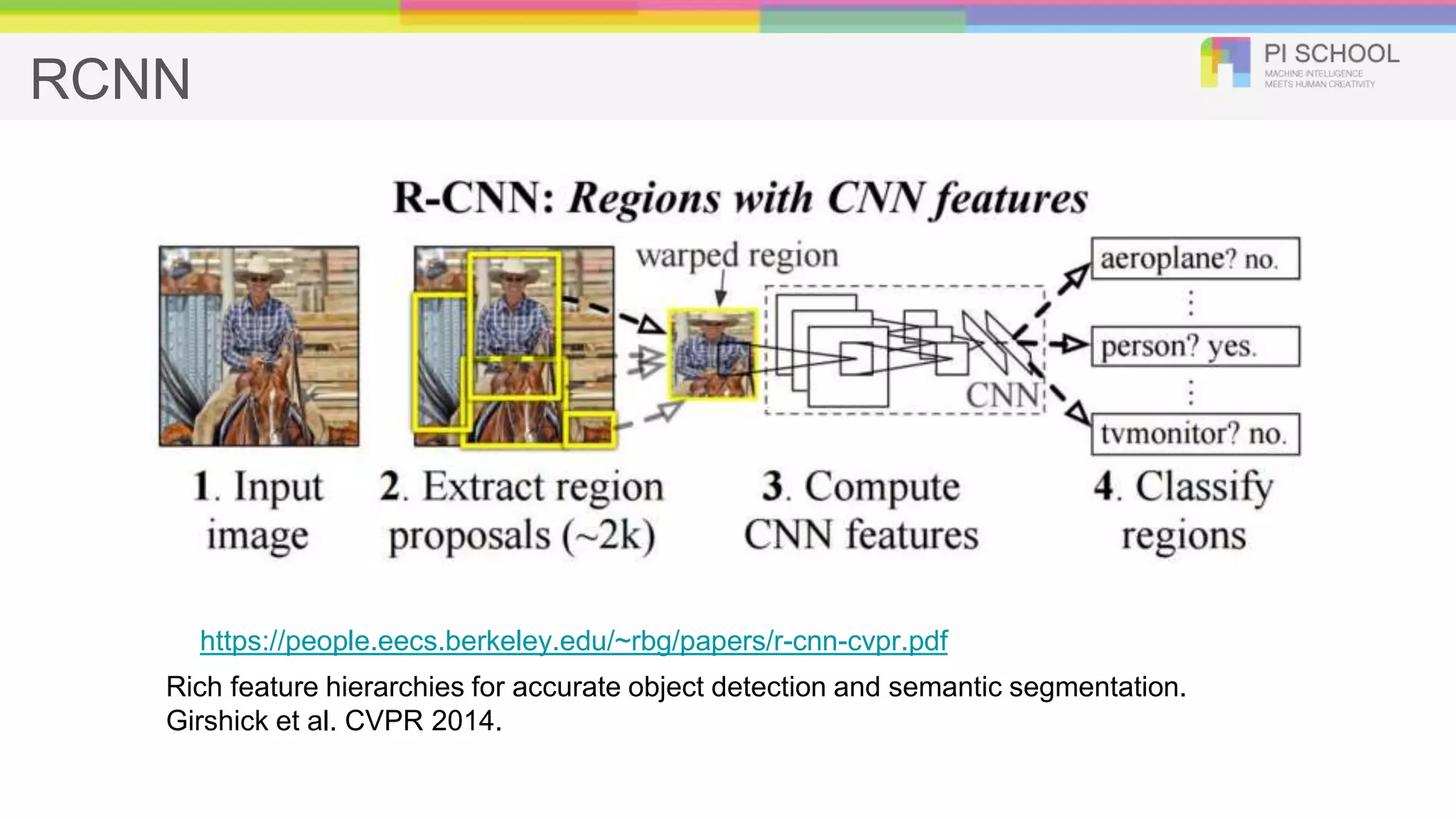
RCNN Rich feature hierarchiesfor accurate object detection and semantic segmentation. Girshick et al. CVPR 2014. https://people.eecs.berkeley.edu/~rbg/papers/r-cnn-cvpr.pdf
13.
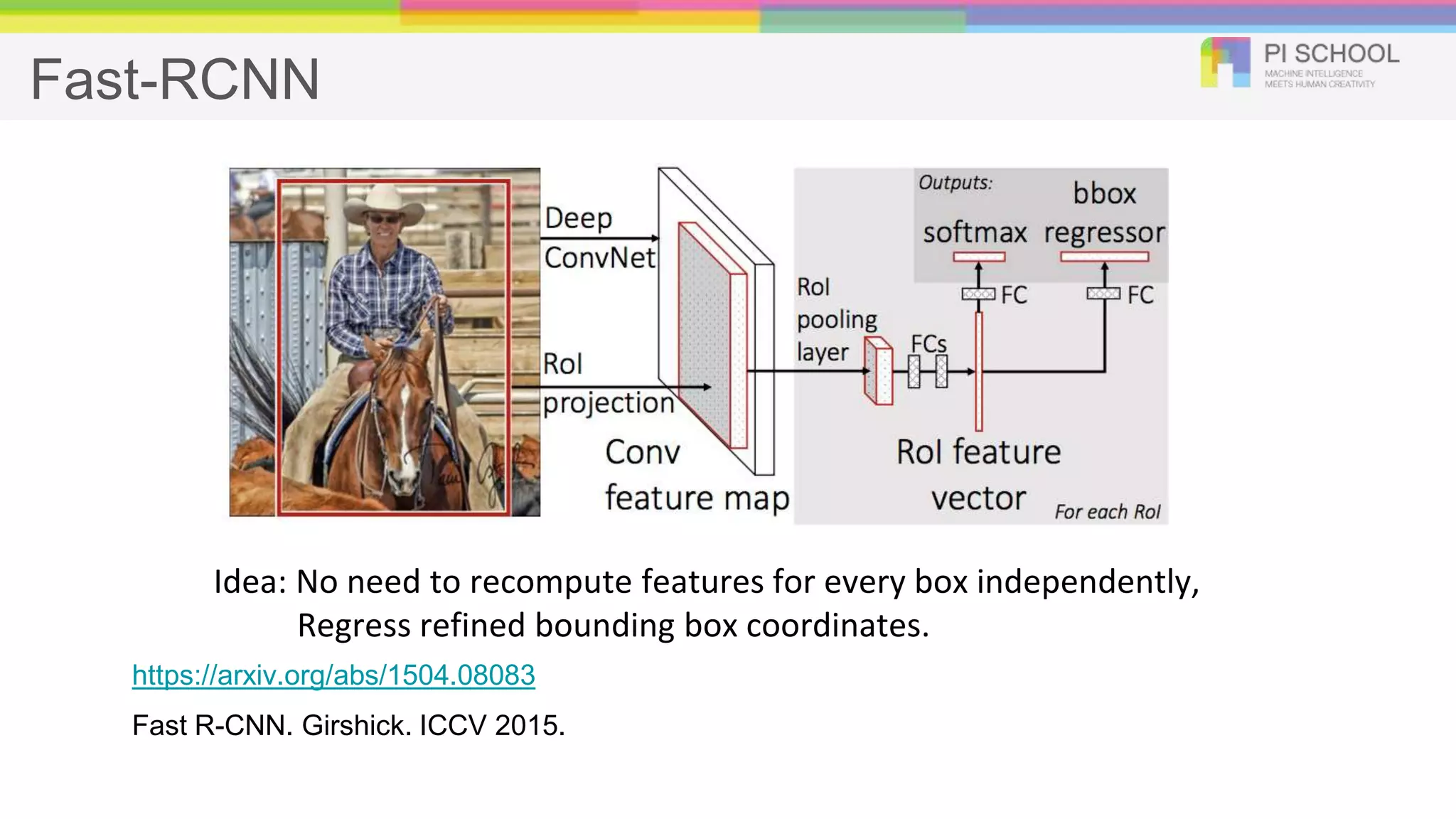
Fast-RCNN Fast R-CNN. Girshick.ICCV 2015. https://arxiv.org/abs/1504.08083 Idea: No need to recompute features for every box independently, Regress refined bounding box coordinates.
14.
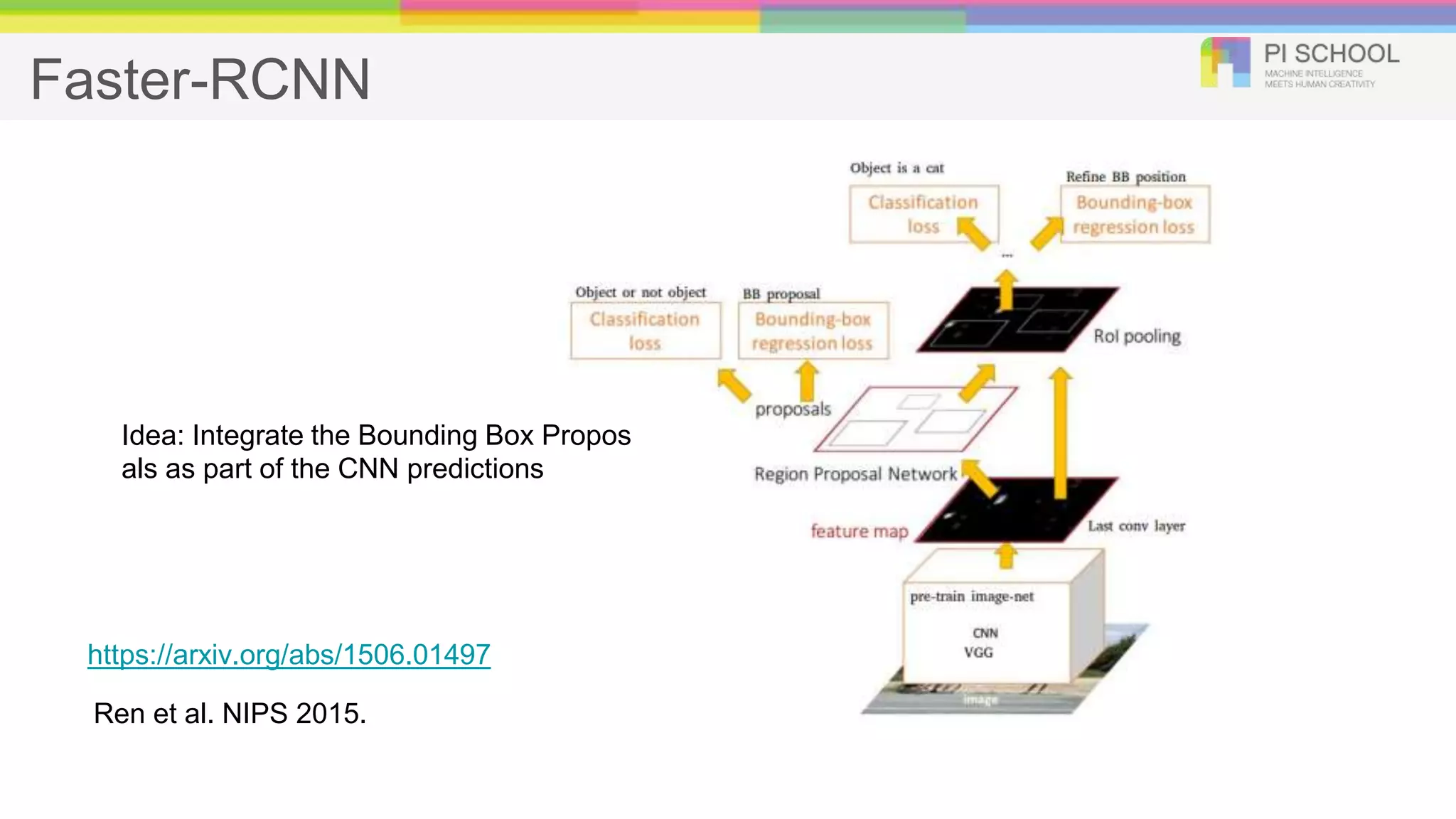
Faster-RCNN Ren et al.NIPS 2015. https://arxiv.org/abs/1506.01497 Idea: Integrate the Bounding Box Propos als as part of the CNN predictions
15.
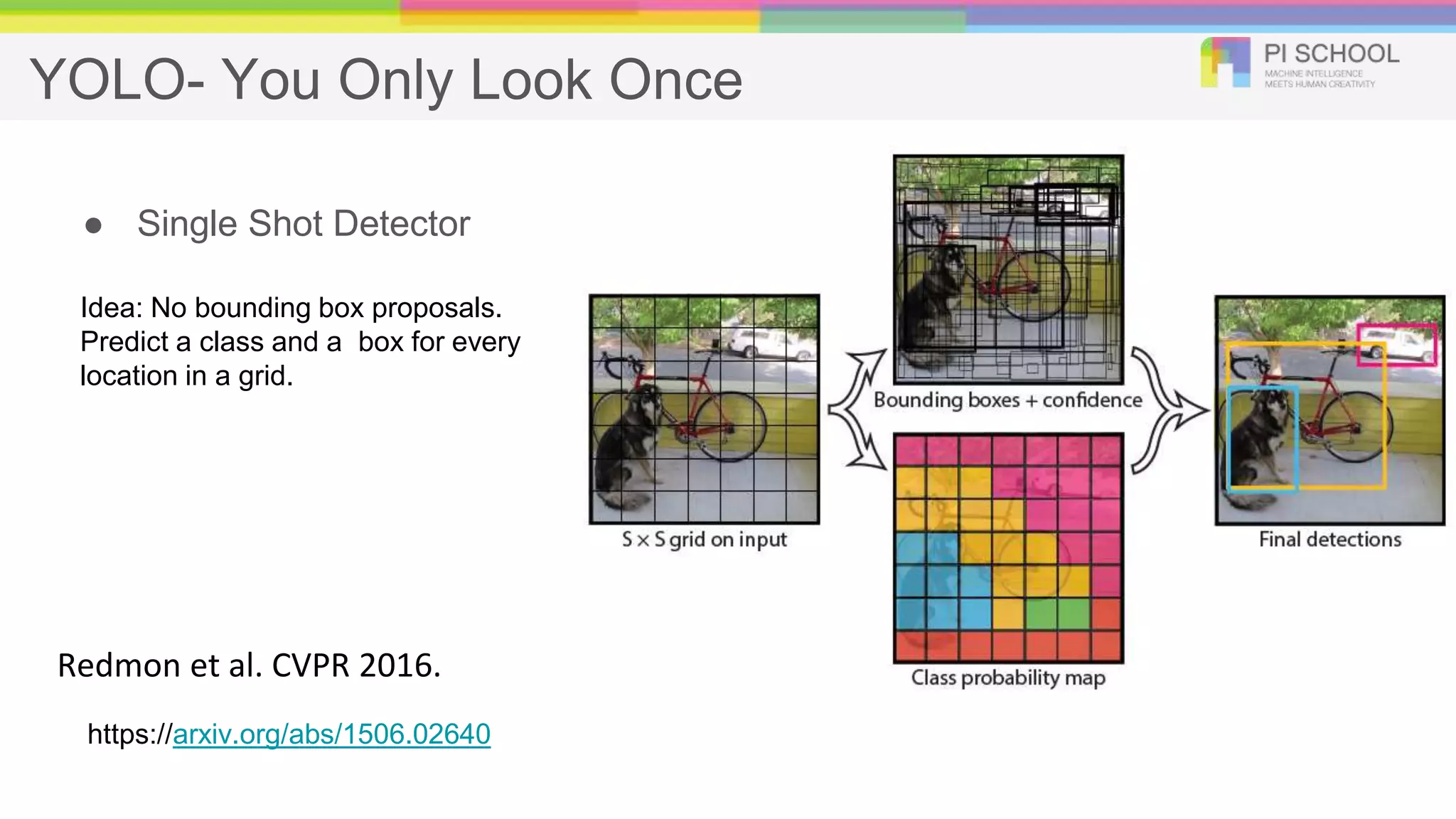
YOLO- You OnlyLook Once ● Single Shot Detector Redmon et al. CVPR 2016. https://arxiv.org/abs/1506.02640 Idea: No bounding box proposals. Predict a class and a box for every location in a grid.
16.
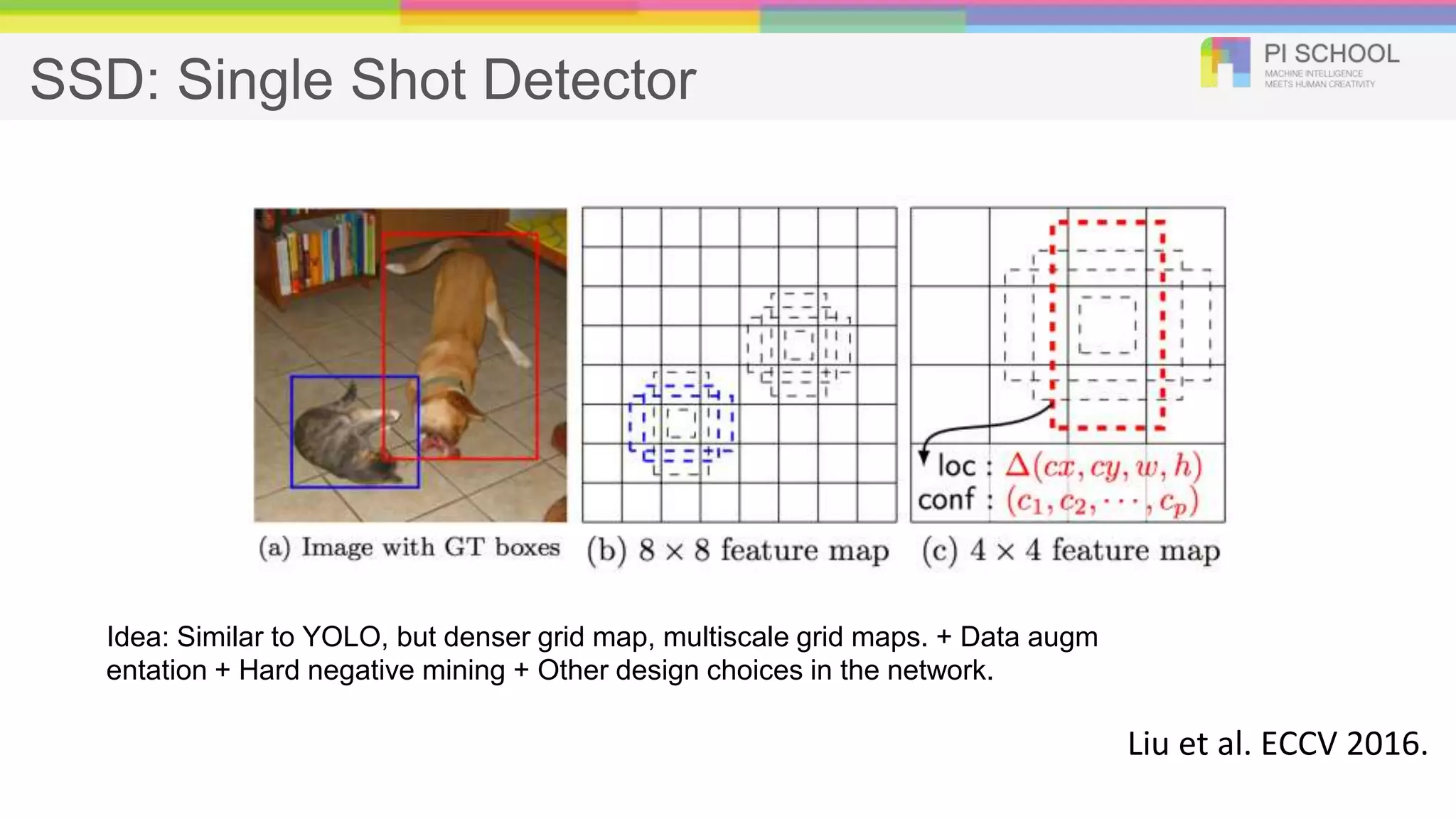
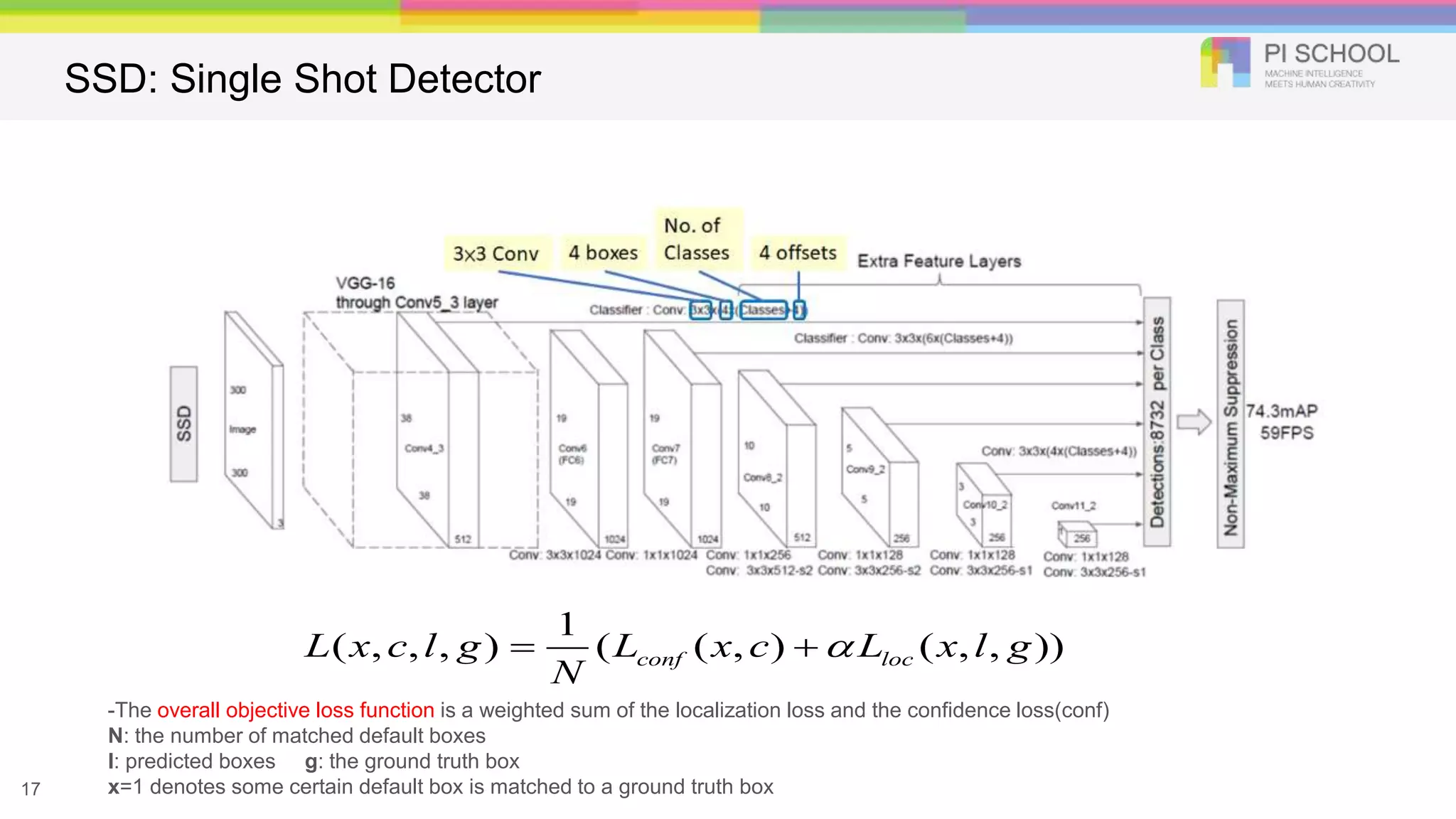
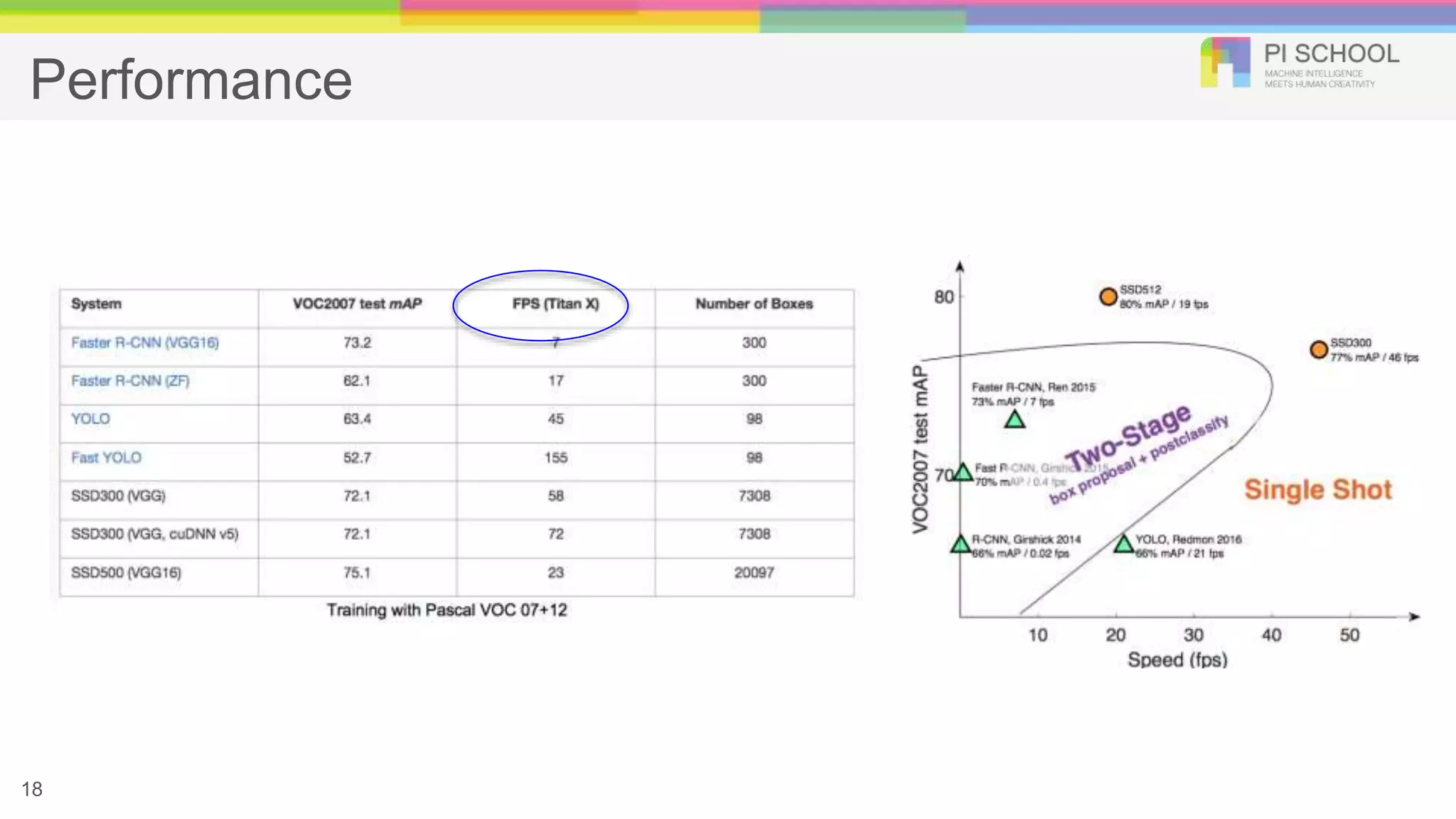
SSD: Single ShotDetector Liu et al. ECCV 2016. Idea: Similar to YOLO, but denser grid map, multiscale grid maps. + Data augm entation + Hard negative mining + Other design choices in the network.
17.
-The overall objectiveloss function is a weighted sum of the localization loss and the confidence loss(conf) N: the number of matched default boxes l: predicted boxes g: the ground truth box x=1 denotes some certain default box is matched to a ground truth box17 1 ( , , , ) ( ( , ) ( , , ))conf locL x c l g L x c L x l g N SSD: Single Shot Detector
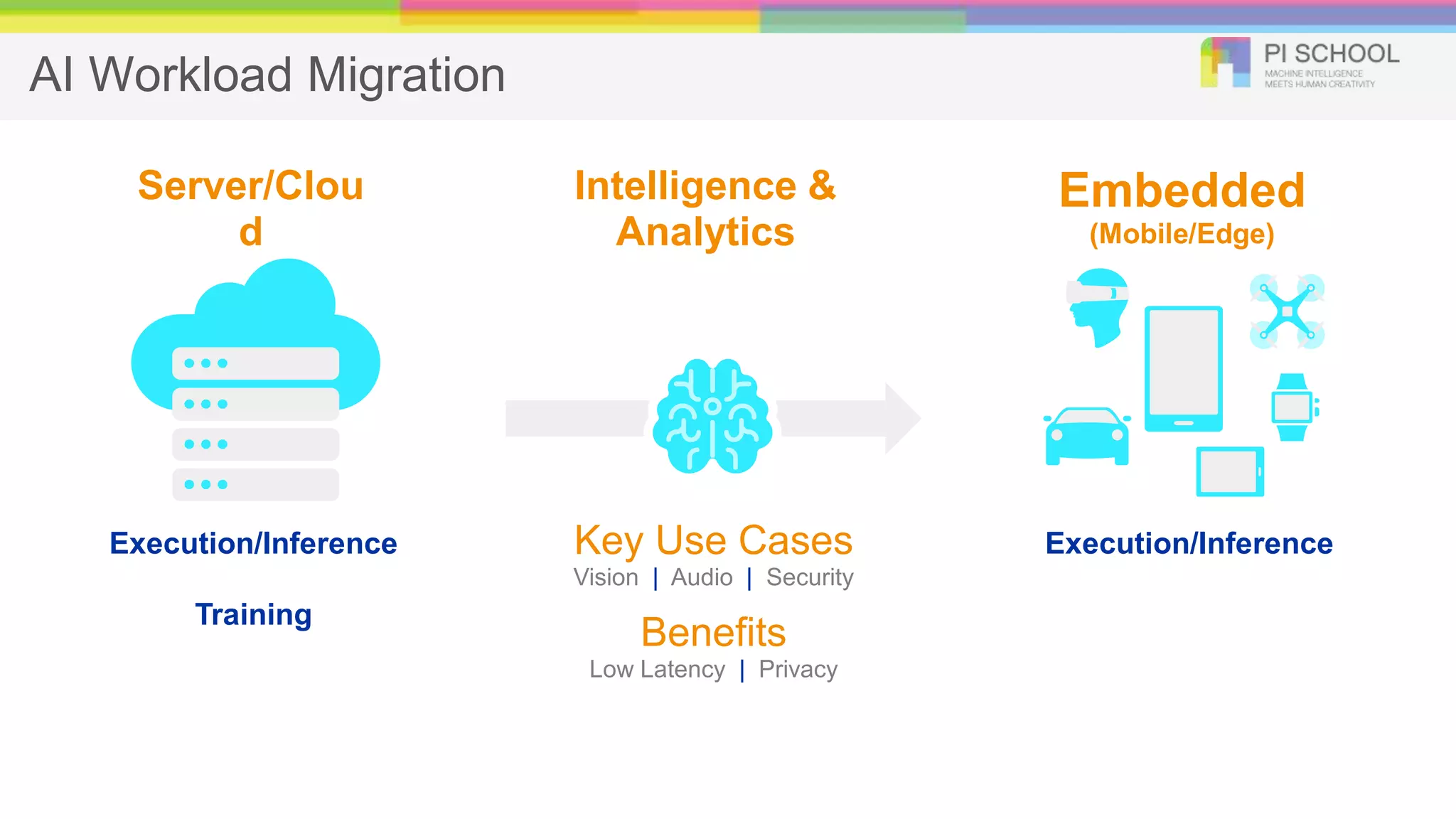
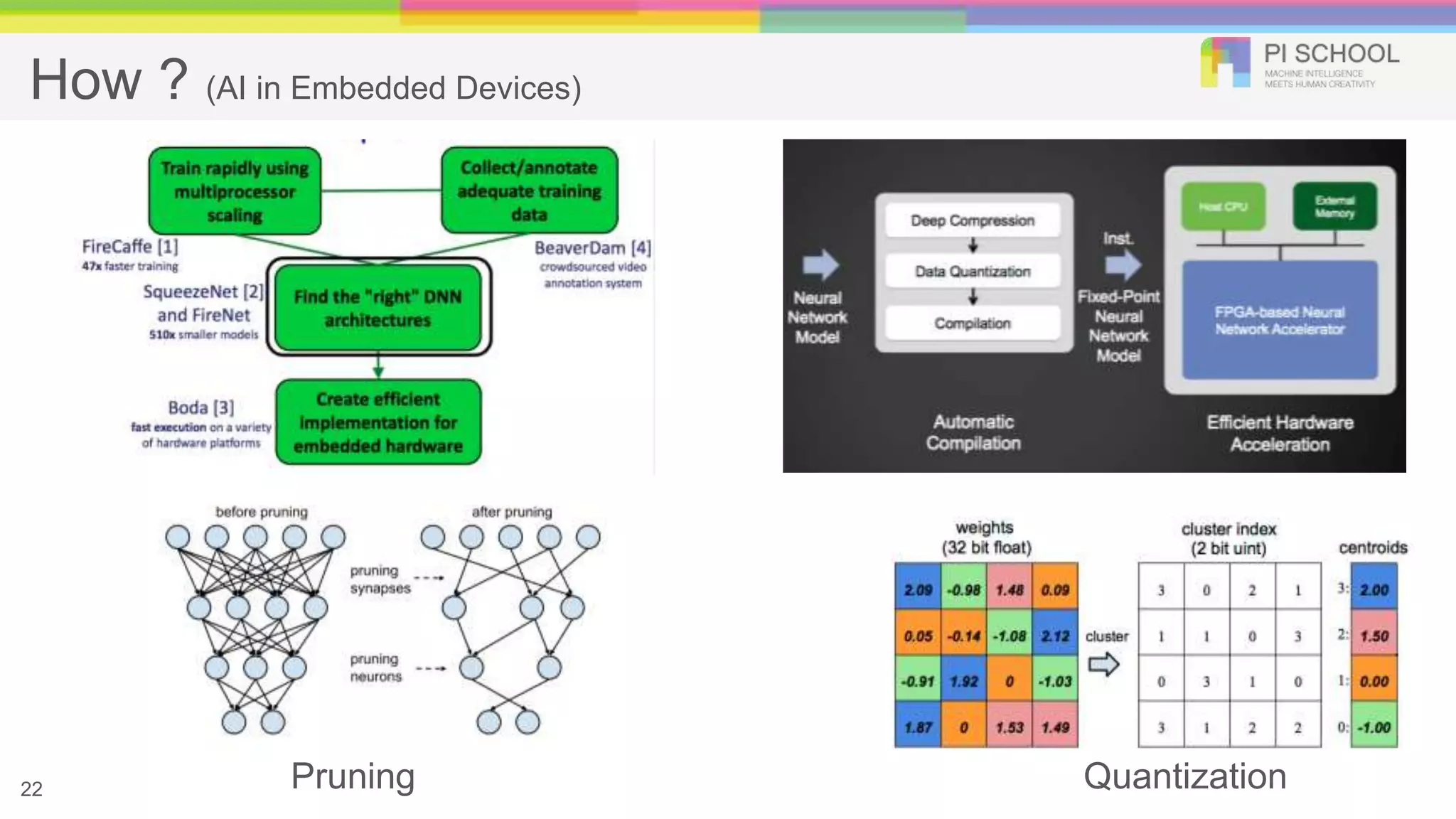
How ? (AIin Embedded Devices) Pruning Quantization22
23.
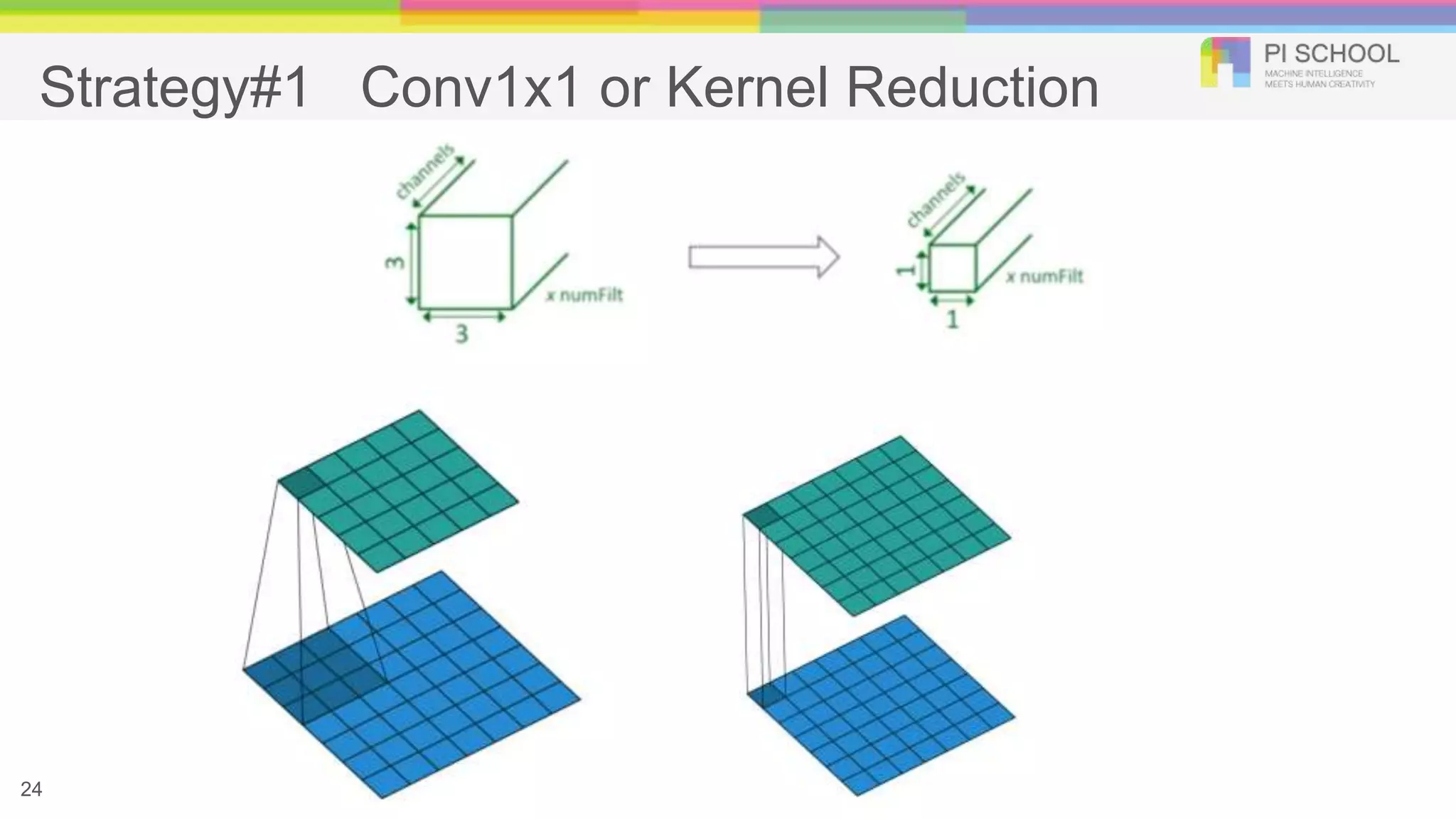
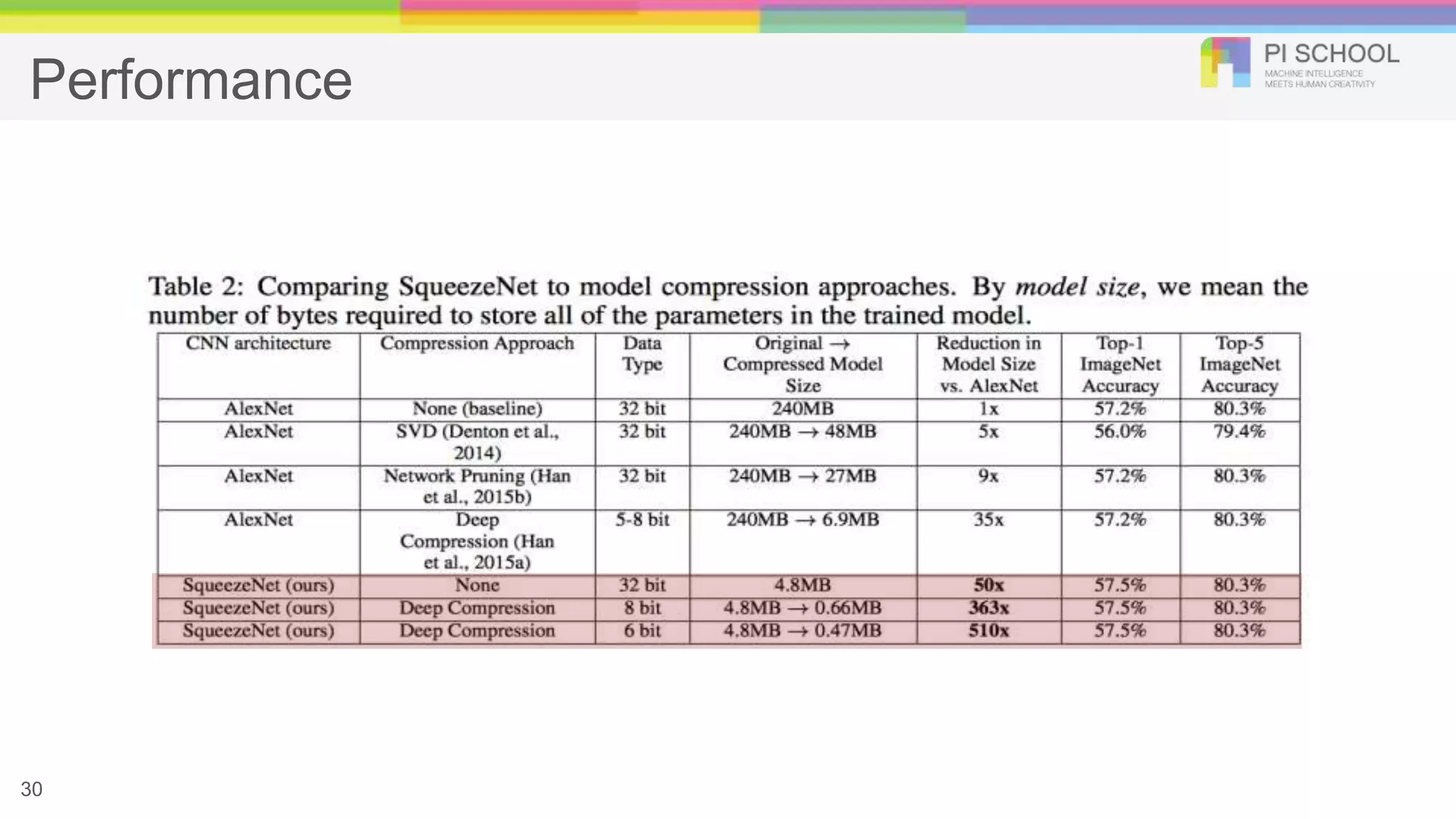
SqueezeNet (Parameter Reduction) ●Strategy 1. Replace 3x3 filters with 1x1 filters ○ Parameters per filter: (3x3 filter) = 9 * (1x1 filter) ● Strategy 2. Decrease the number of input channels to 3x3 filters ○ Total # of parameters: (# of input channels) * (# of filters) * ( # of parameters per filter) ● Strategy 3. Downsample late in the network so that convolution layers have large activation maps ○ Size of activation maps: the size of input data, the choice of layers in which to downsample in the CNN architecture 23 Iandola, Forrest N., et al. "SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size."
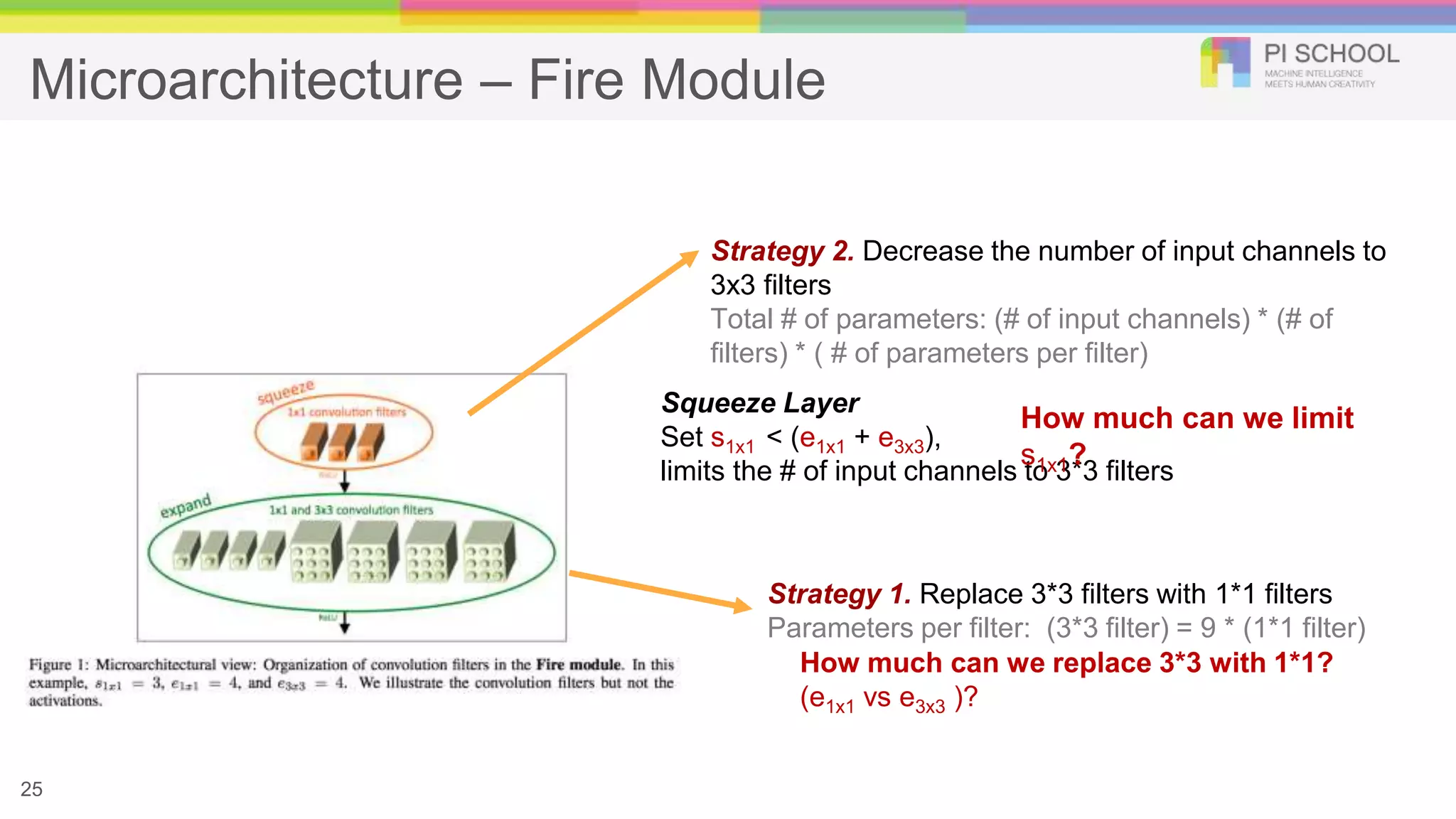
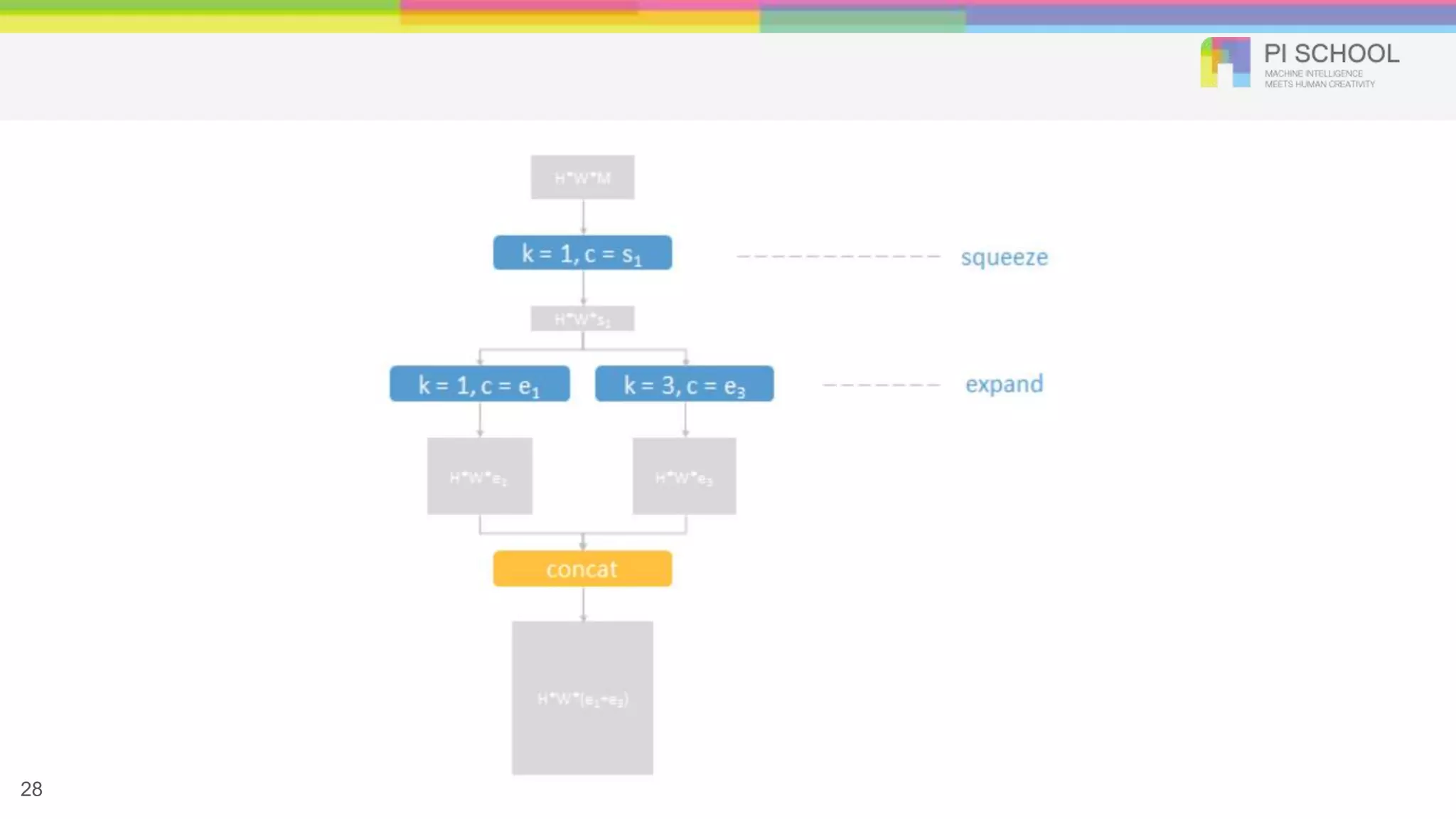
Microarchitecture – FireModule 25 Squeeze Layer Set s1x1 < (e1x1 + e3x3), limits the # of input channels to 3*3 filters Strategy 2. Decrease the number of input channels to 3x3 filters Total # of parameters: (# of input channels) * (# of filters) * ( # of parameters per filter) How much can we limit s1x1? Strategy 1. Replace 3*3 filters with 1*1 filters Parameters per filter: (3*3 filter) = 9 * (1*1 filter) How much can we replace 3*3 with 1*1? (e1x1 vs e3x3 )?
26.
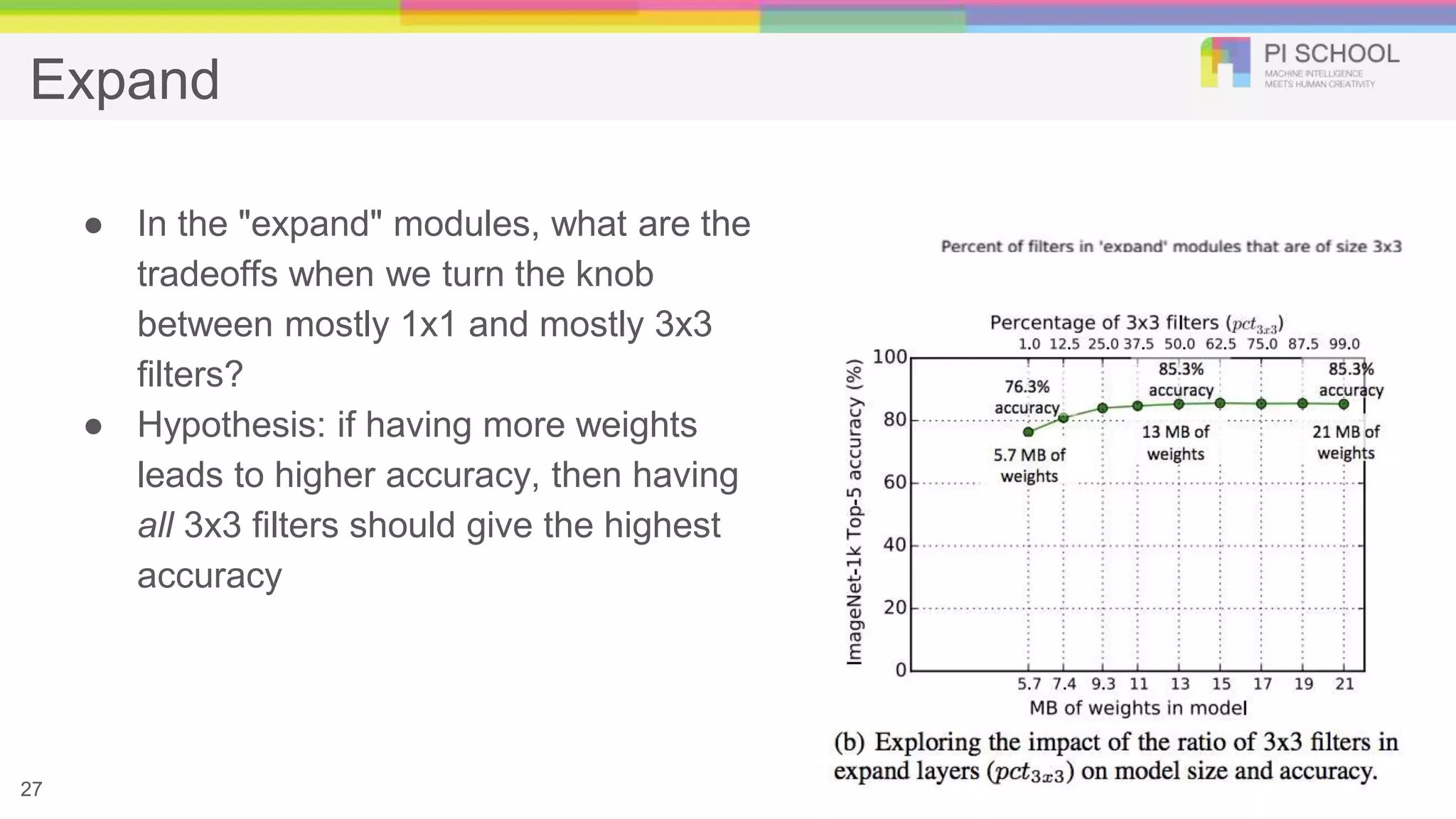
Expand ● In the"expand" modules, what are the tradeoffs when we turn the knob between mostly 1x1 and mostly 3x3 filters? ● Hypothesis: if having more weights leads to higher accuracy, then having all 3x3 filters should give the highest accuracy 27
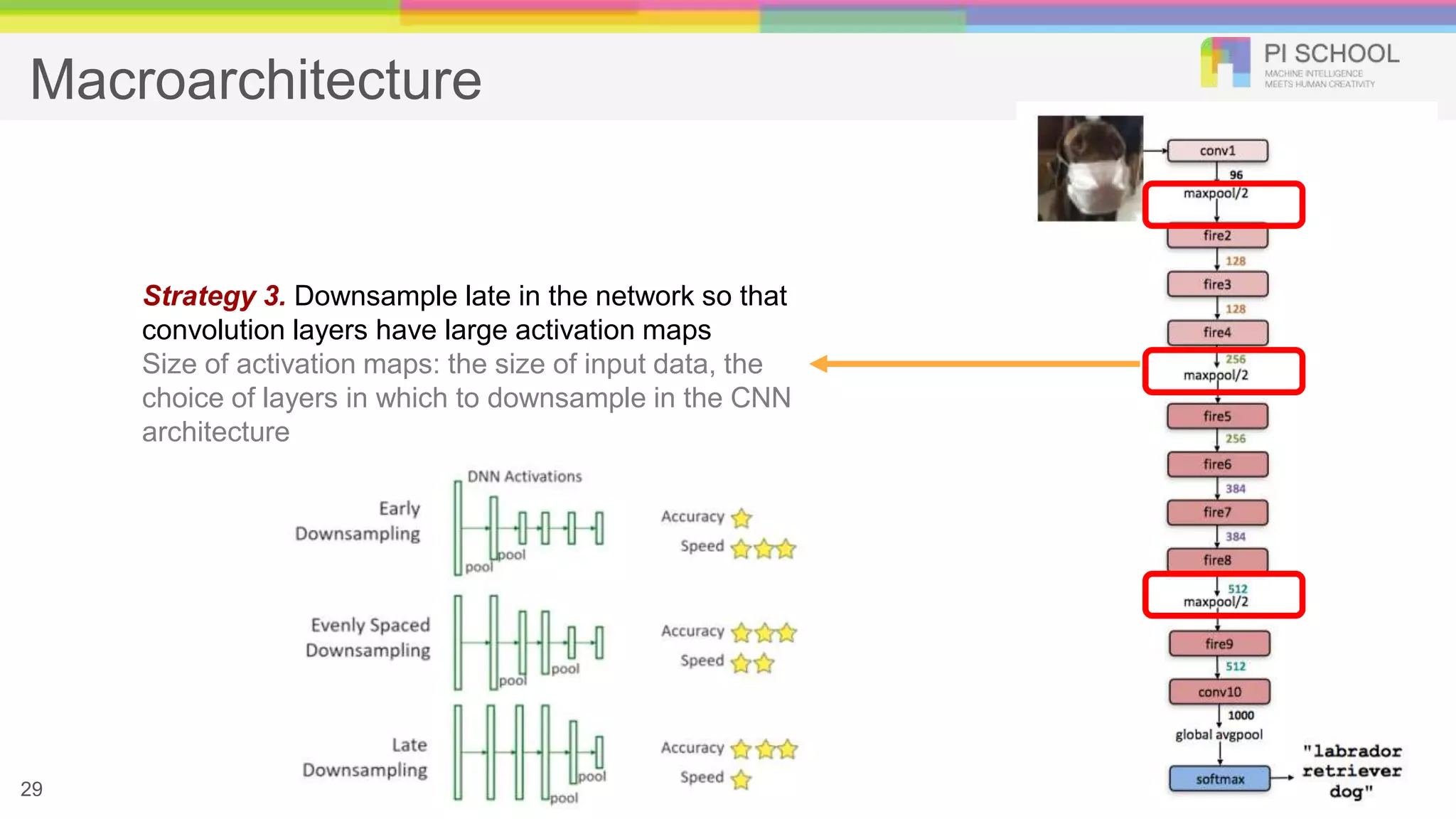
Macroarchitecture 29 Strategy 3. Downsamplelate in the network so that convolution layers have large activation maps Size of activation maps: the size of input data, the choice of layers in which to downsample in the CNN architecture