Downloaded 15 times




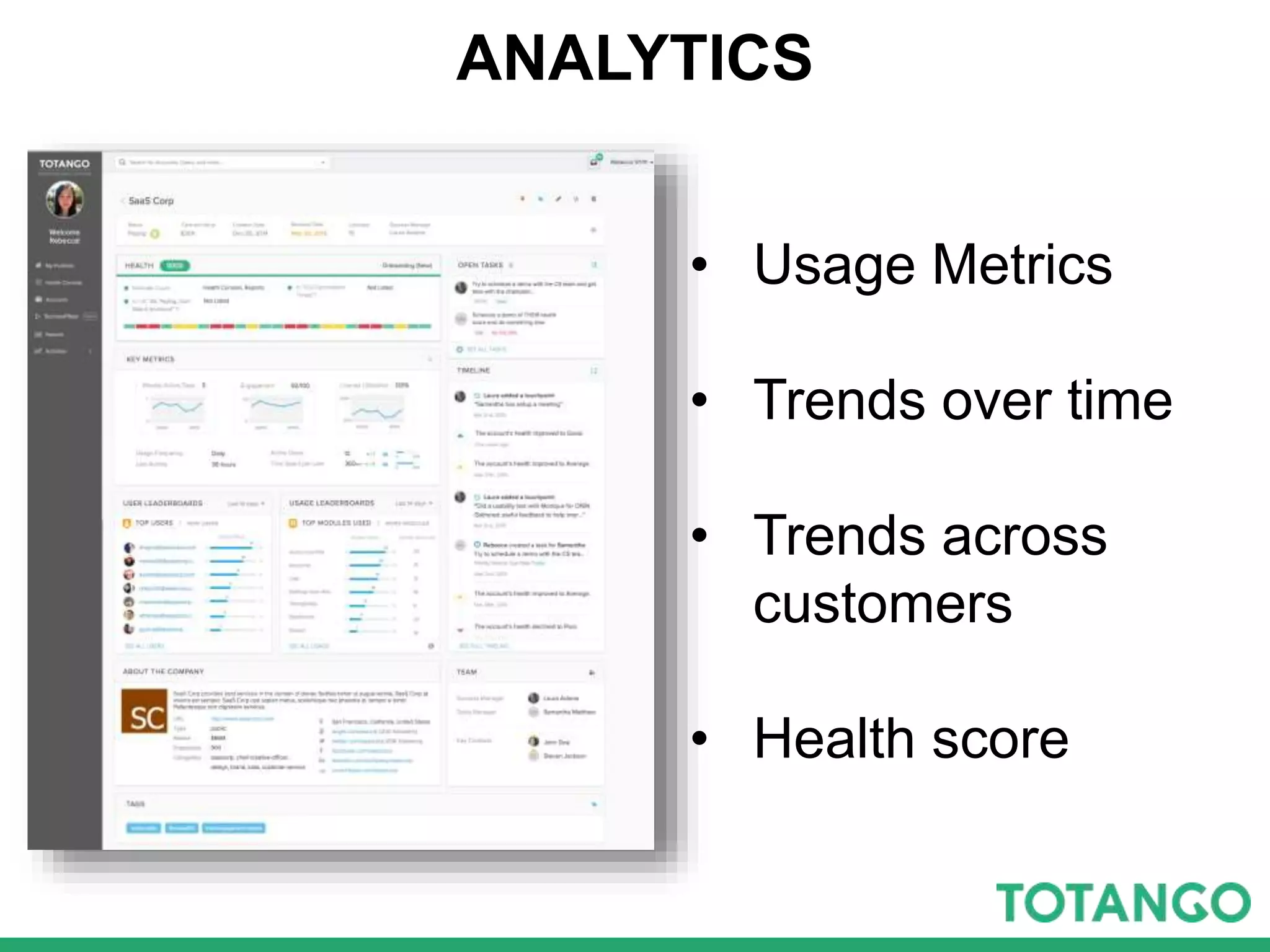

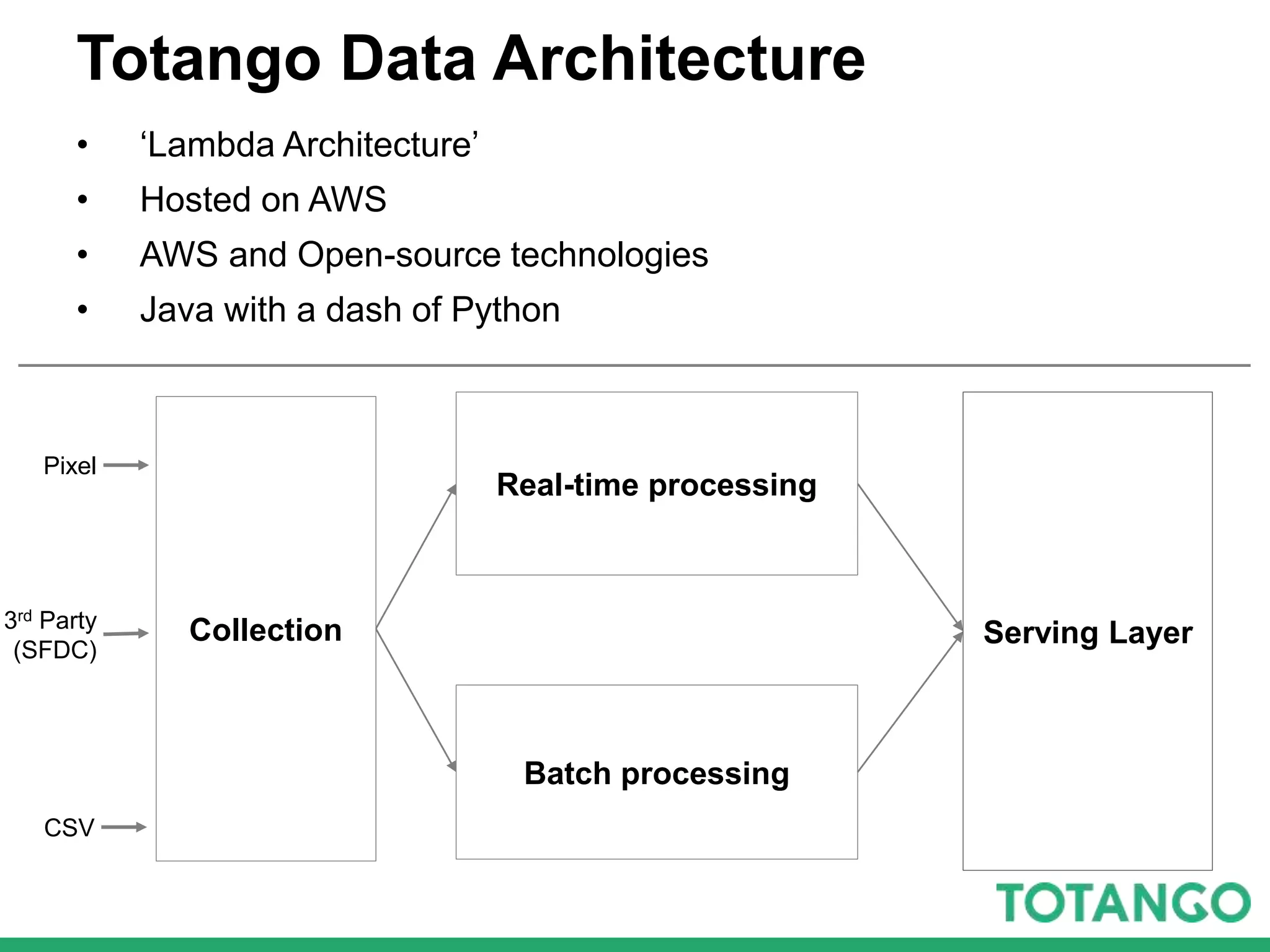
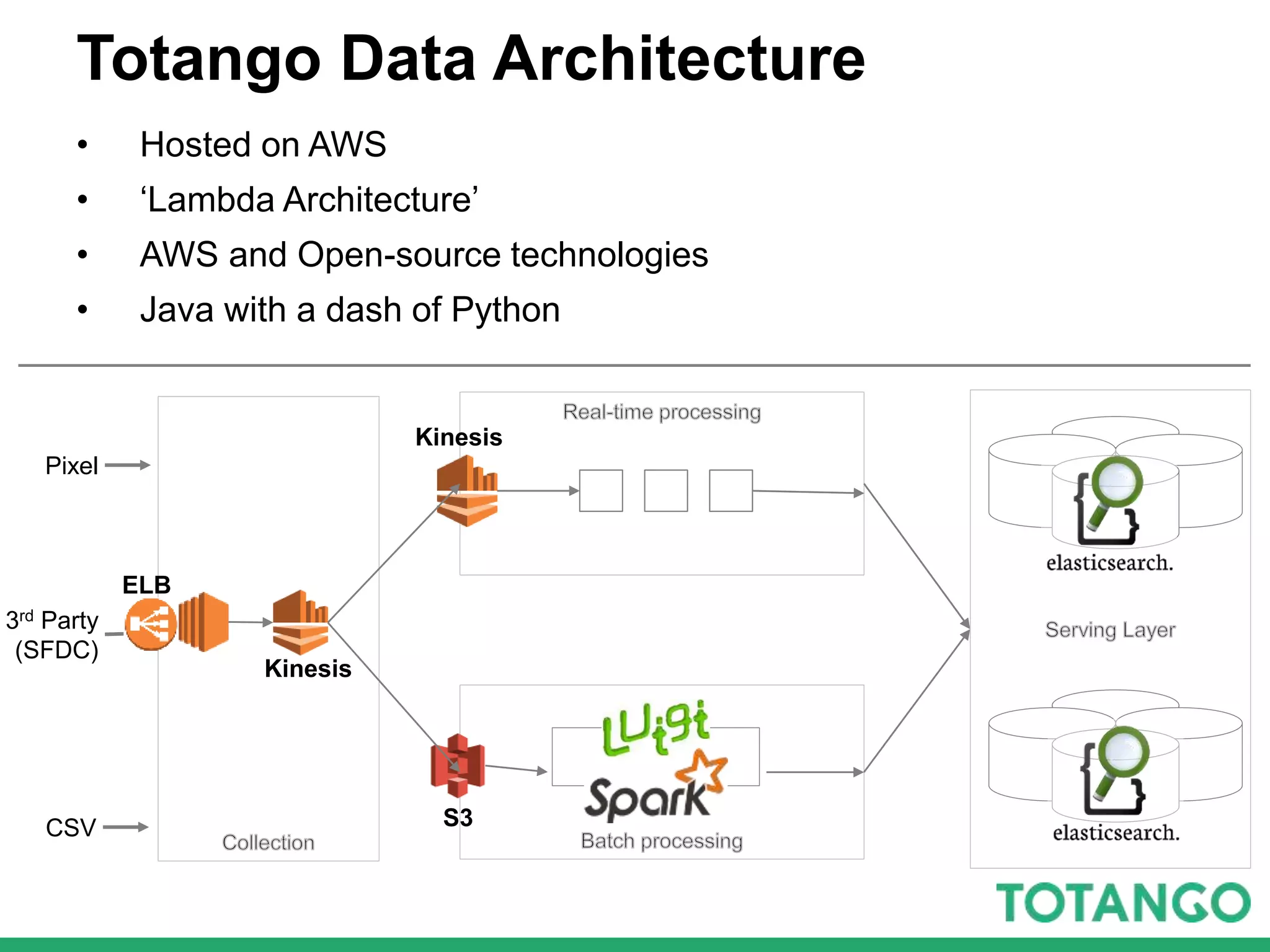
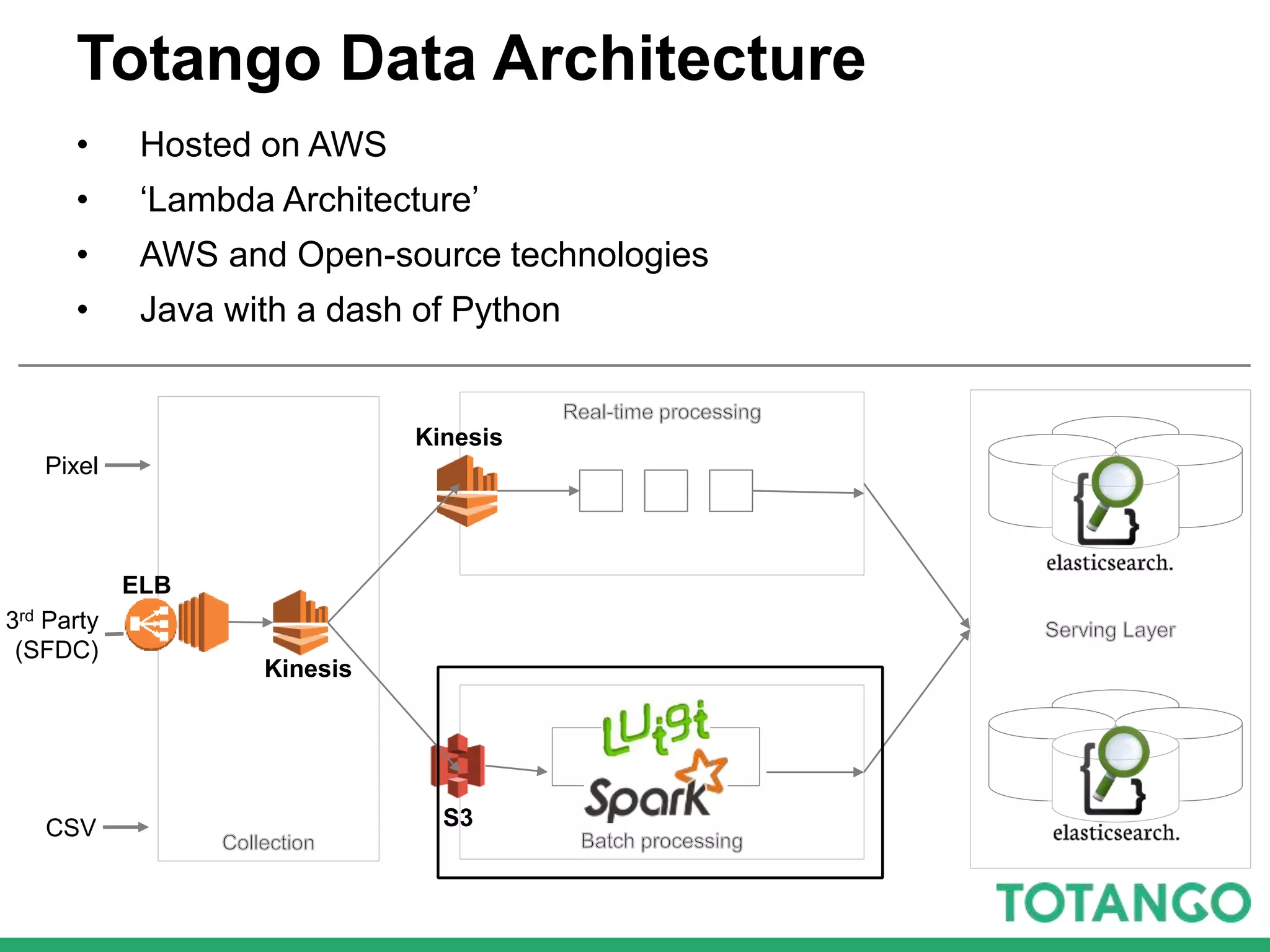
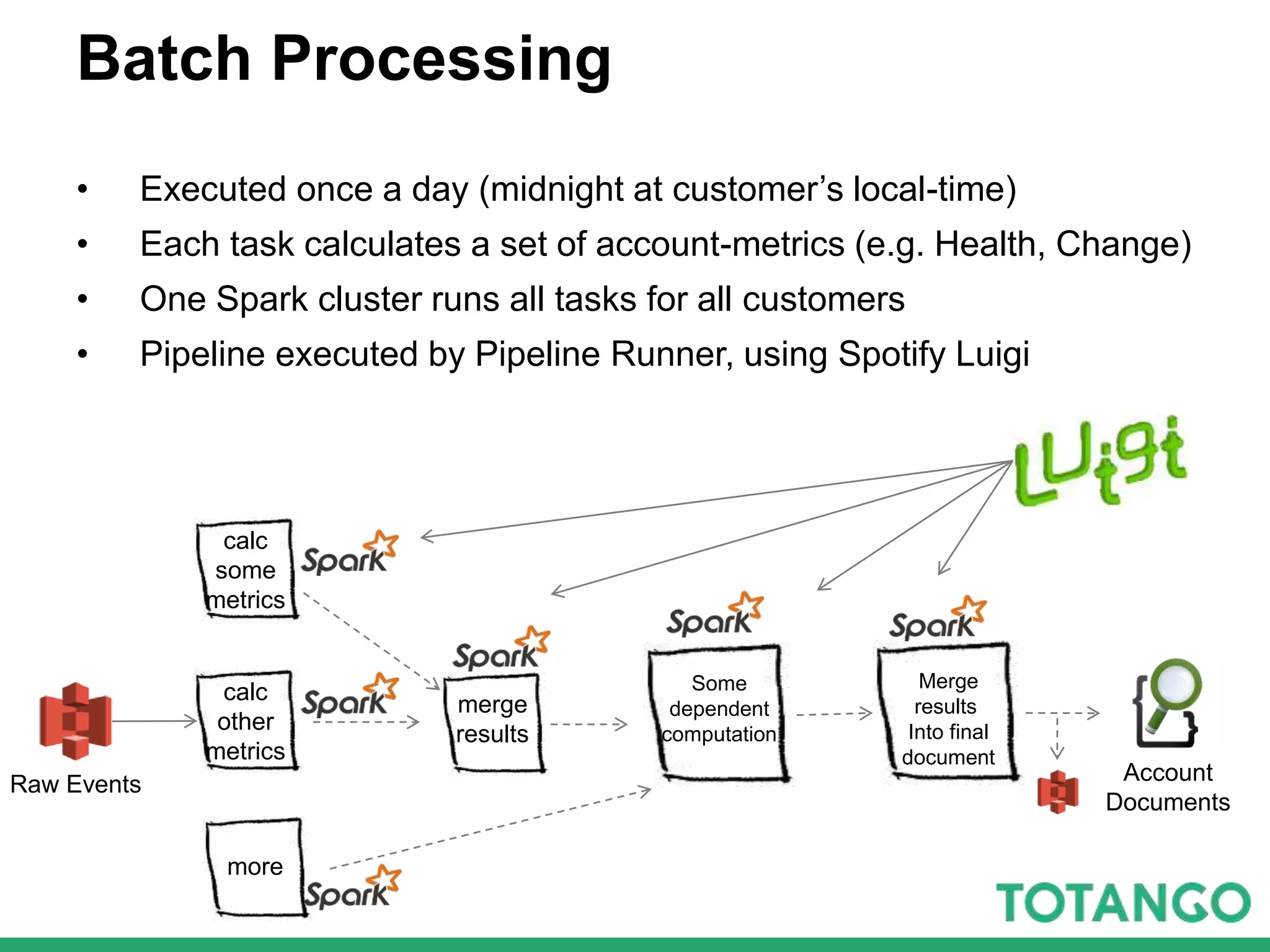
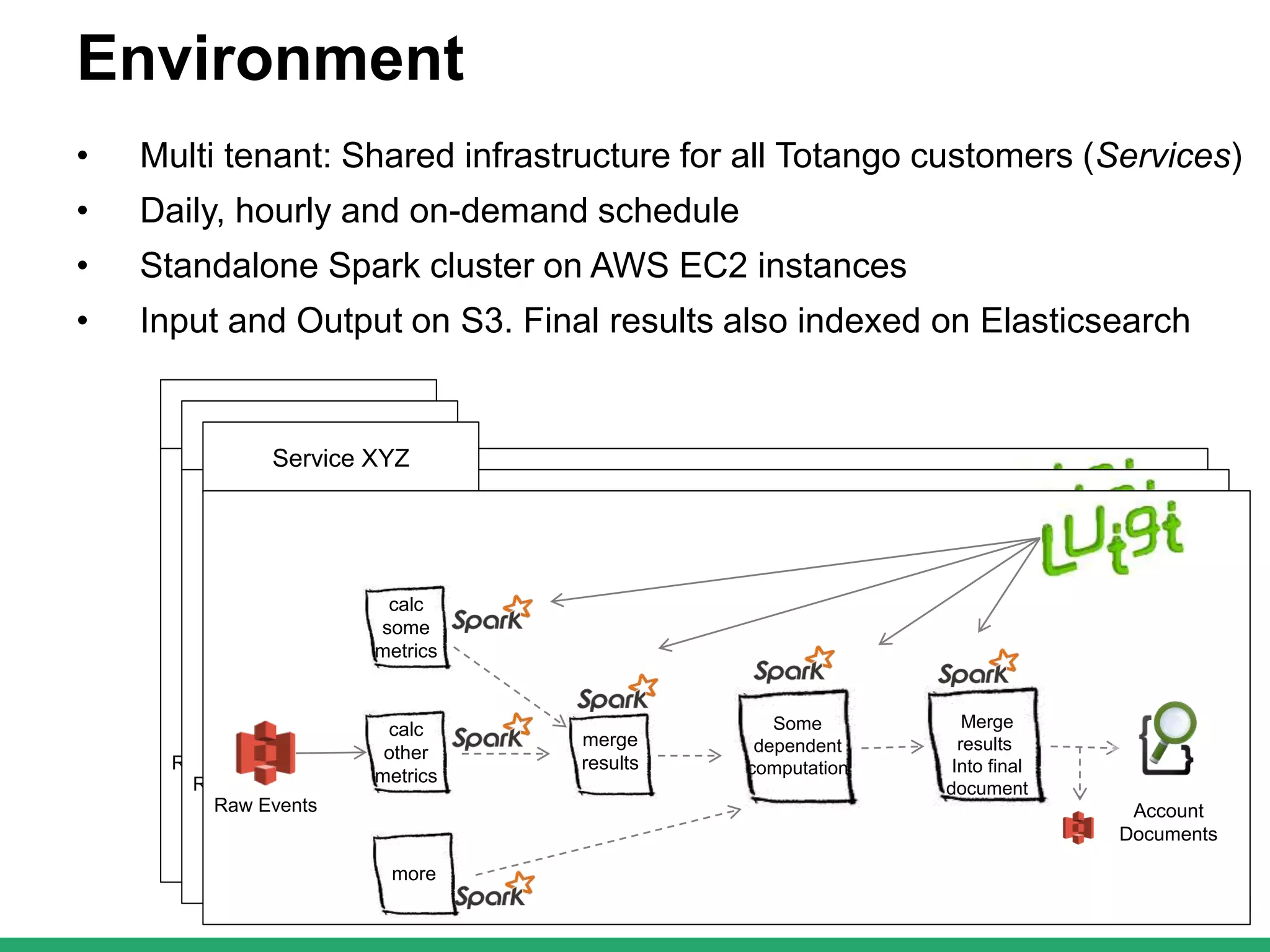

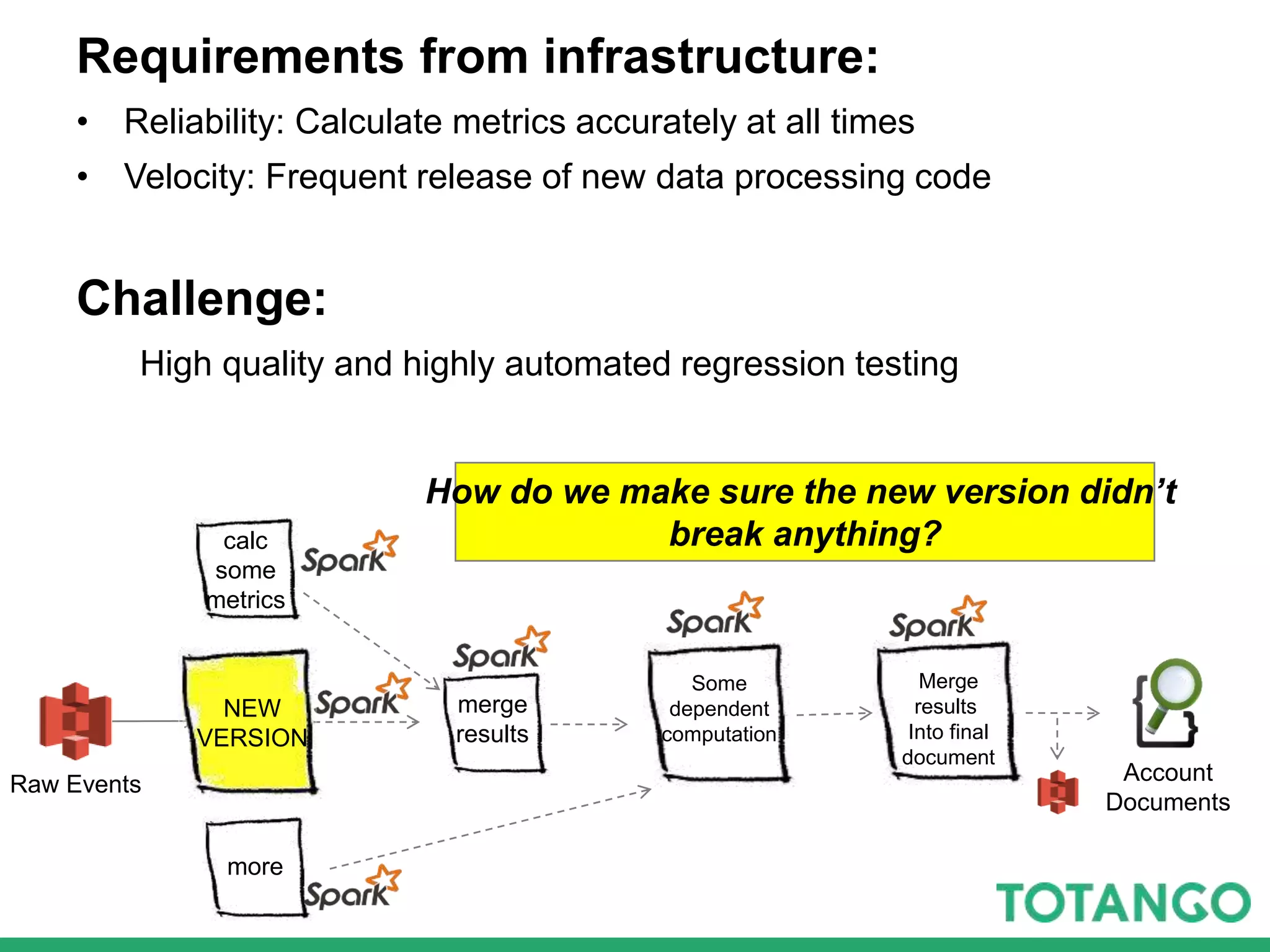
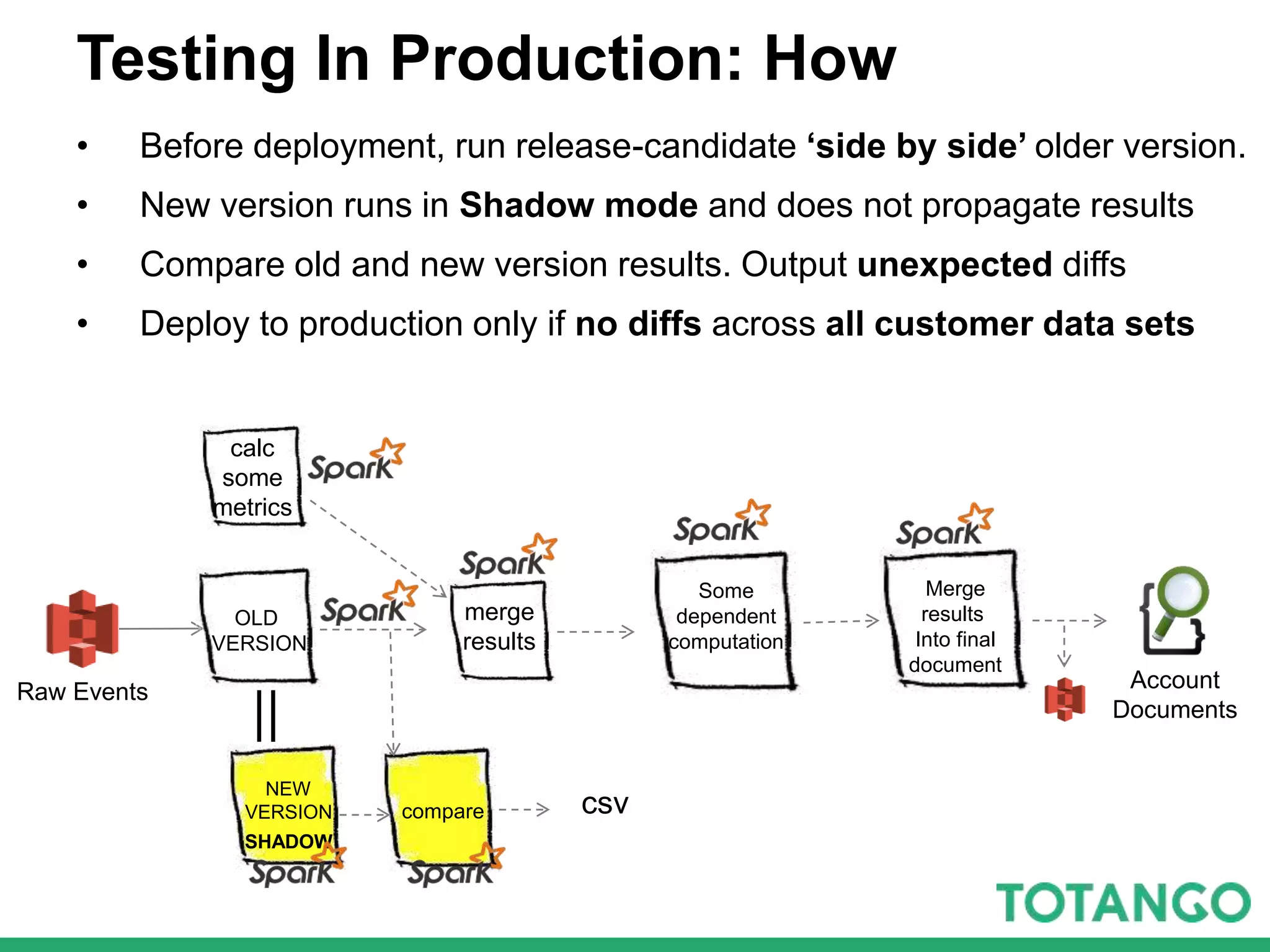
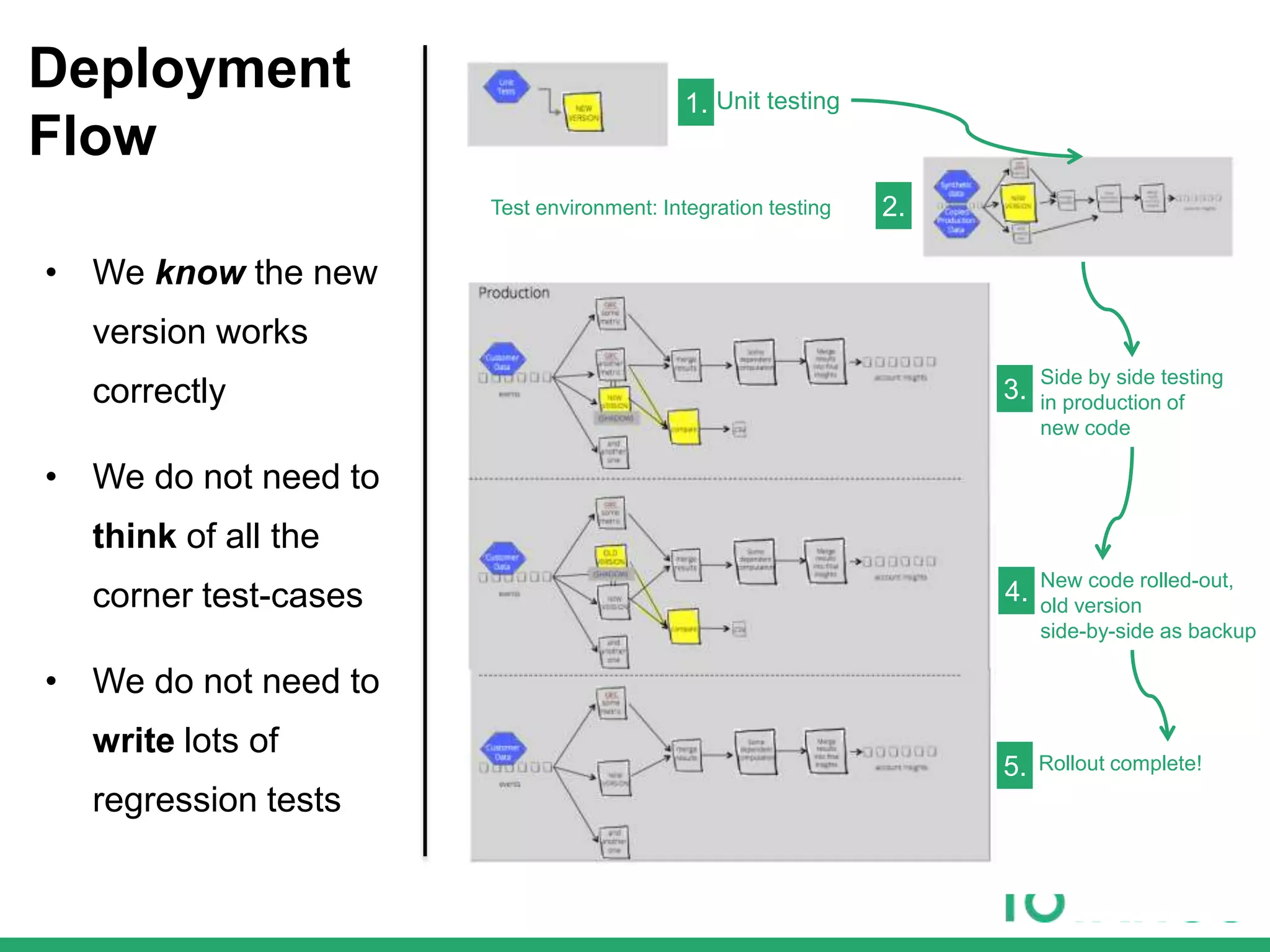


The document outlines Totango's enterprise-grade architecture and data processing capabilities using Spark, hosted on AWS with a focus on reliability and accuracy. It emphasizes a multi-tenant environment, daily batch processing, and quality assurance strategies such as shadow testing and side-by-side comparisons for regression testing. Additionally, it highlights the company's mission to help online businesses leverage data for customer success, alongside a brief overview of its history and team structure.