Downloaded 163 times





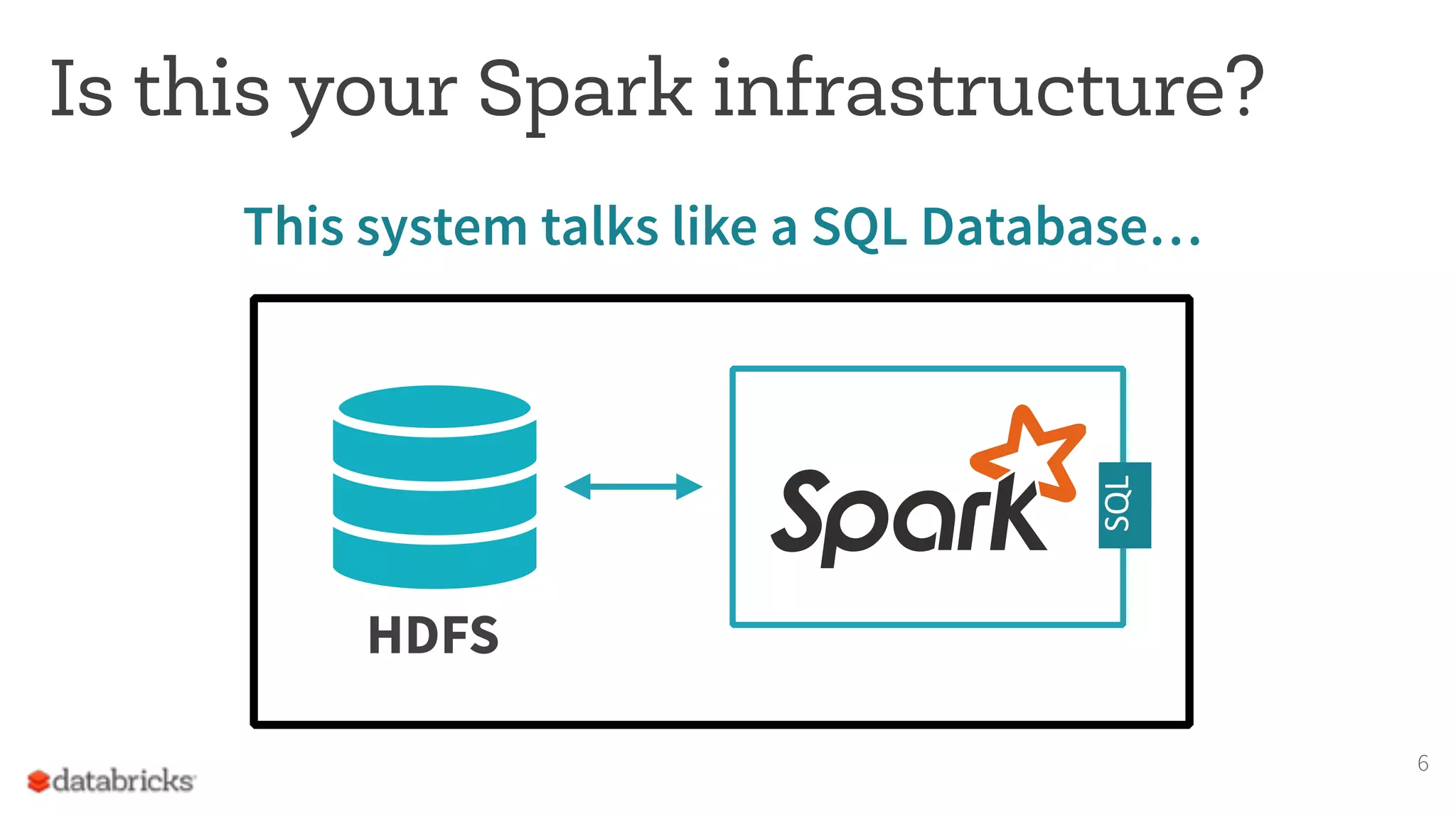
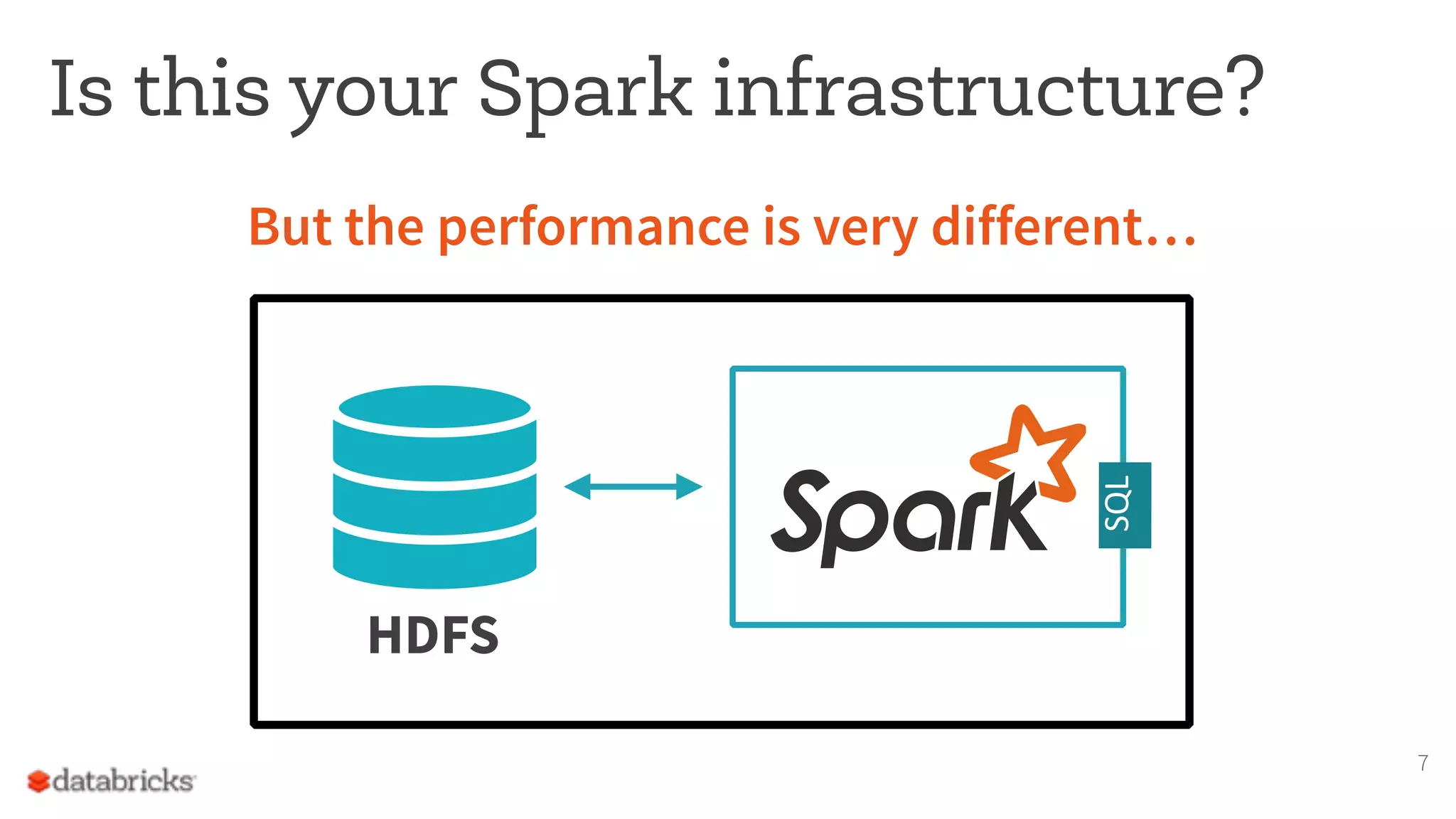
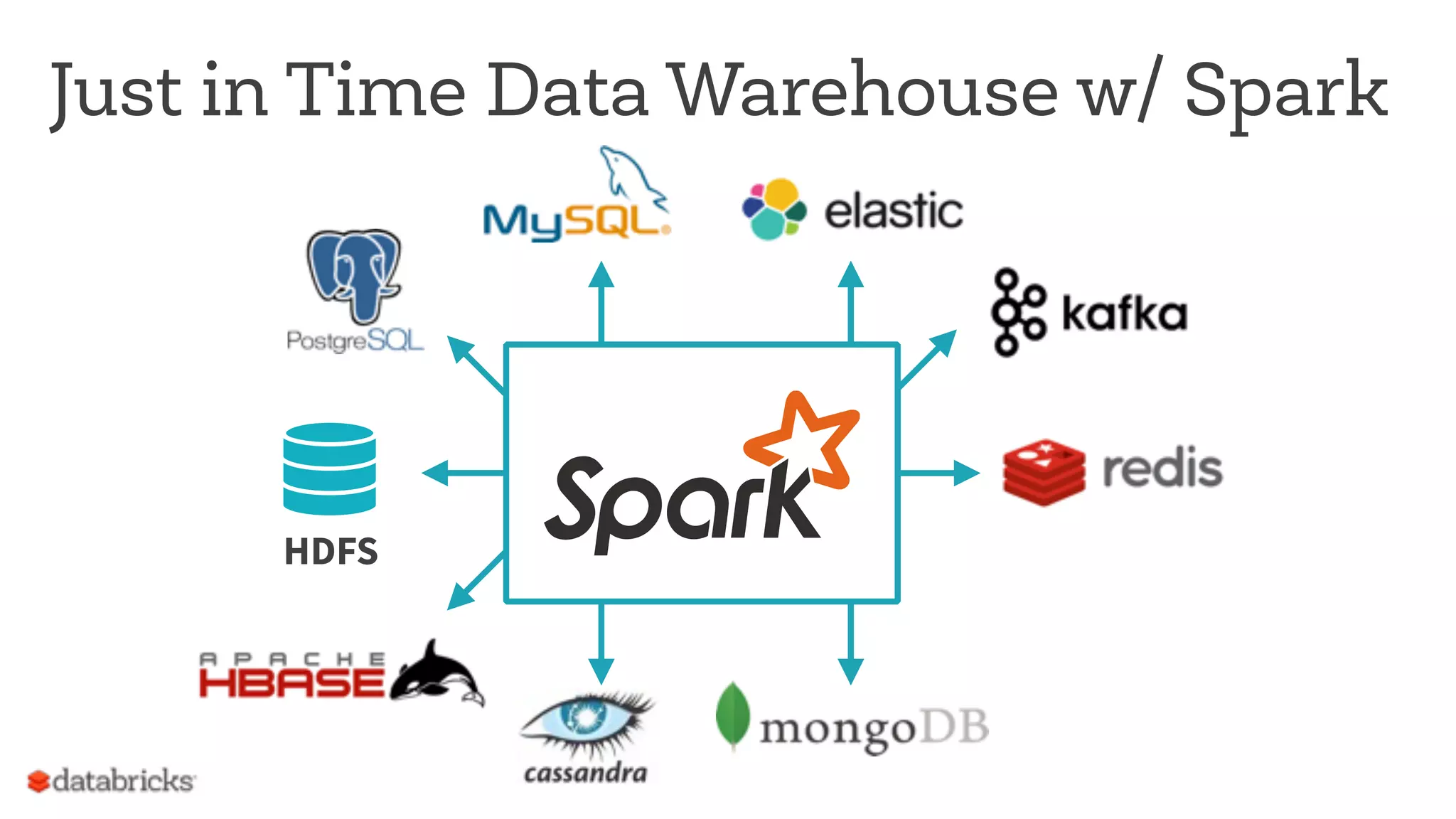
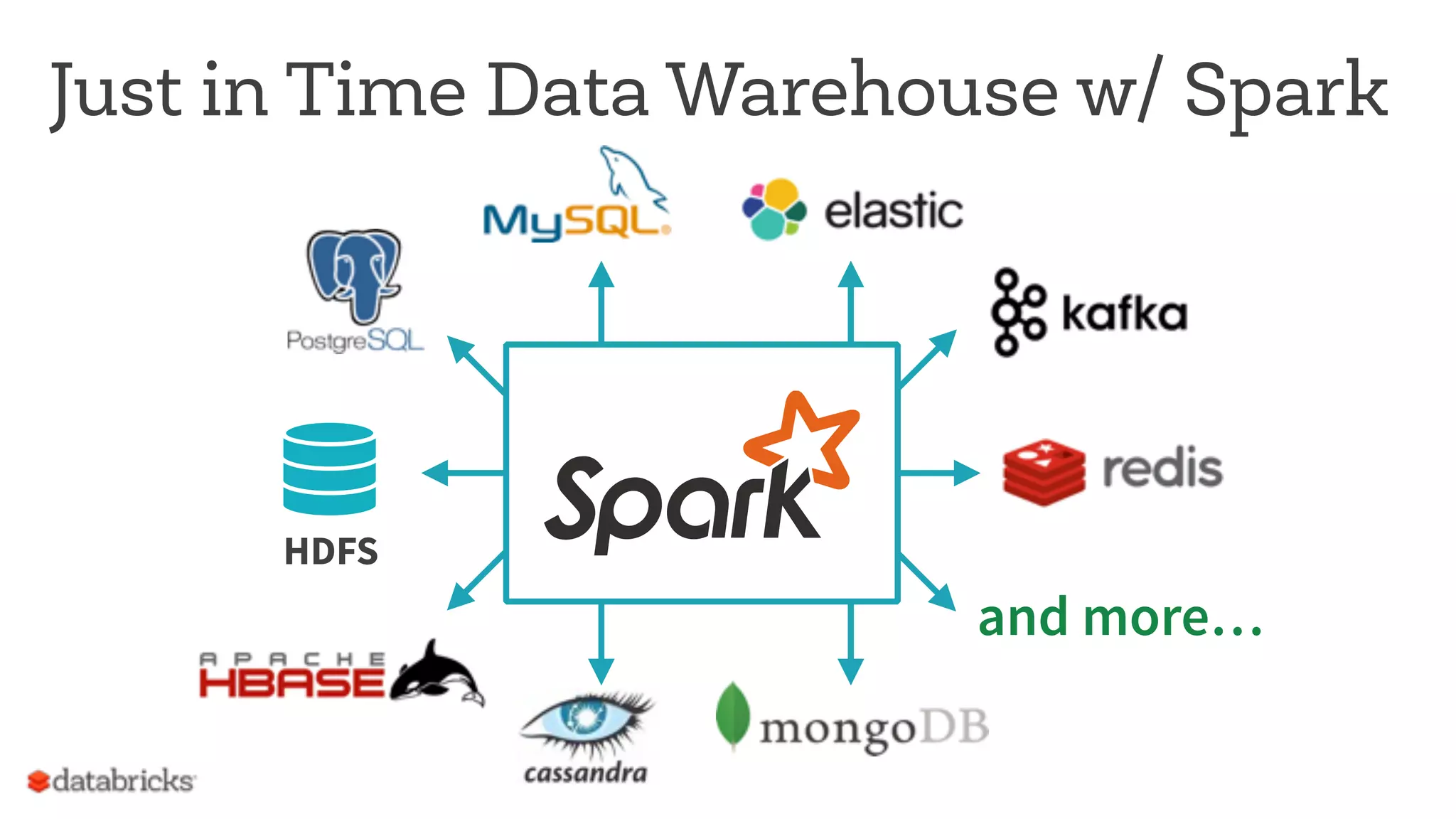








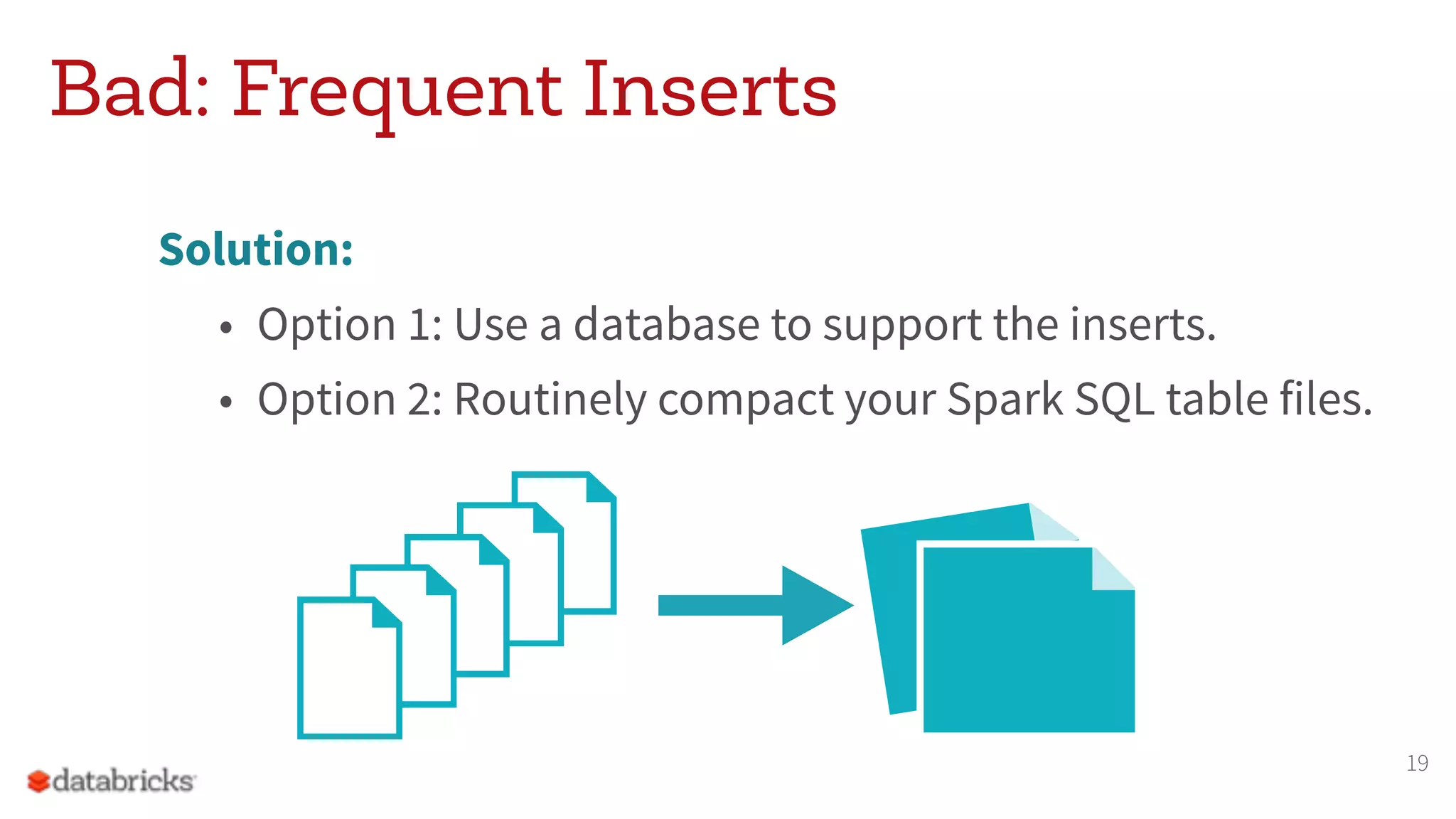



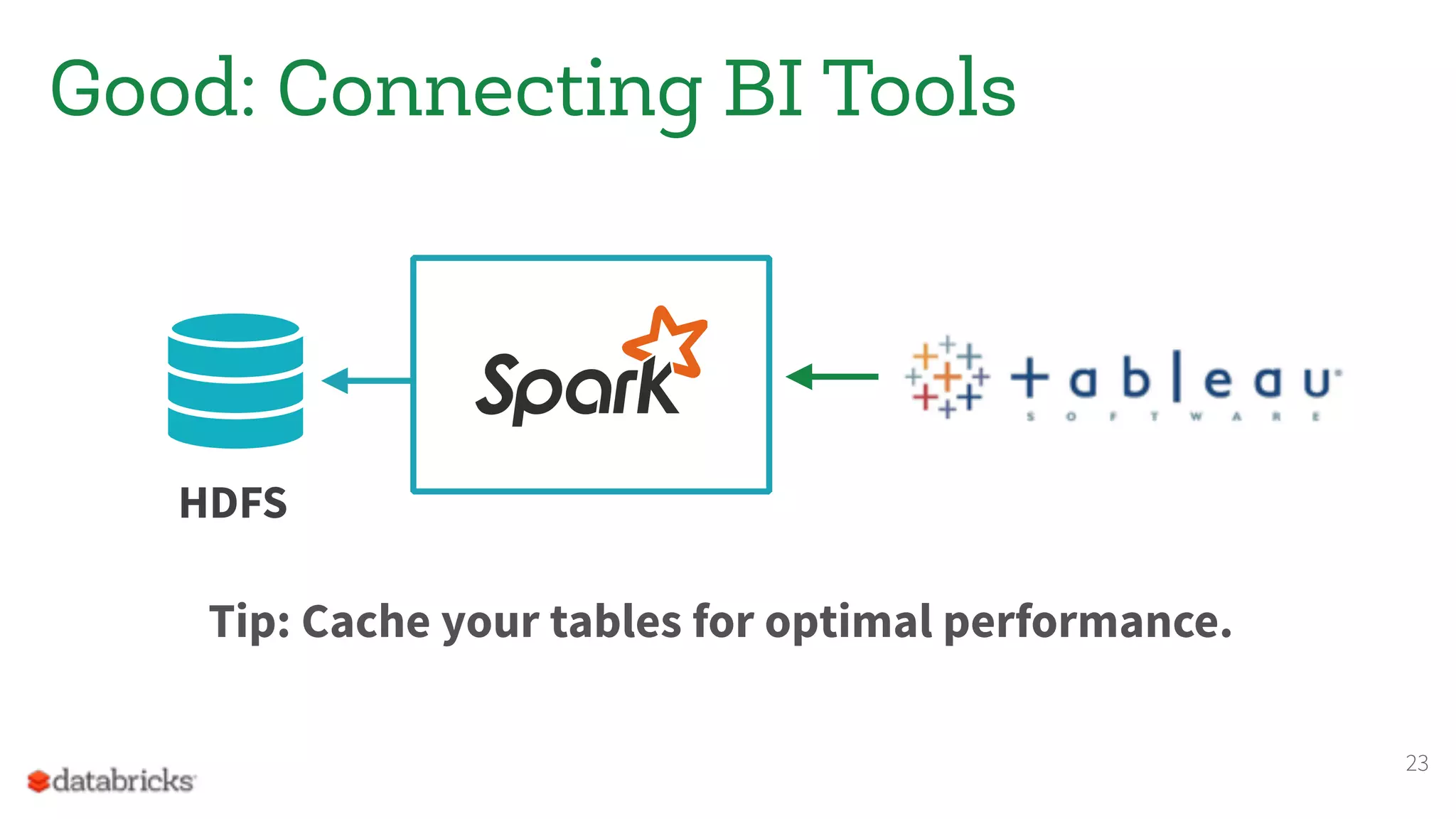
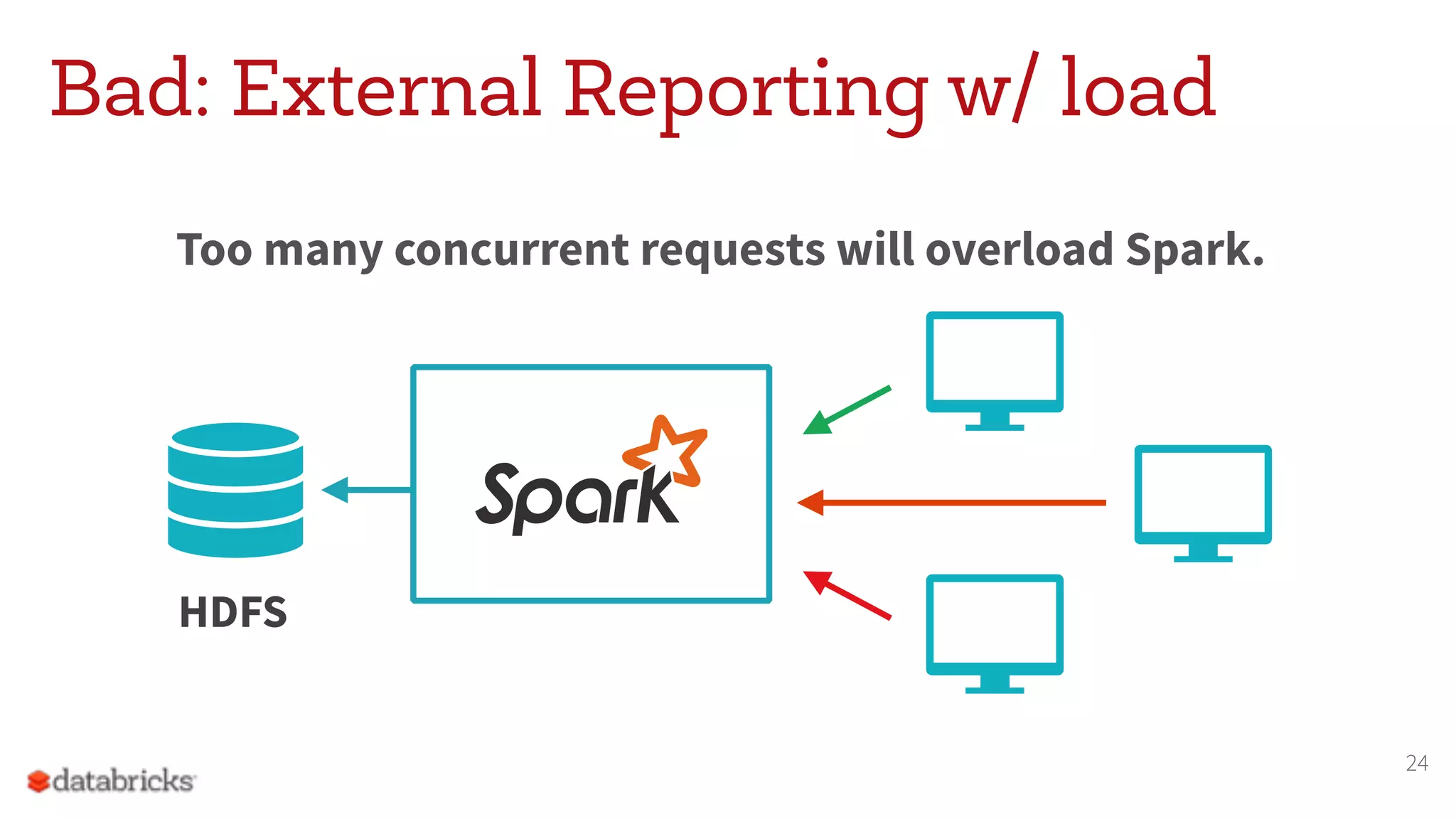
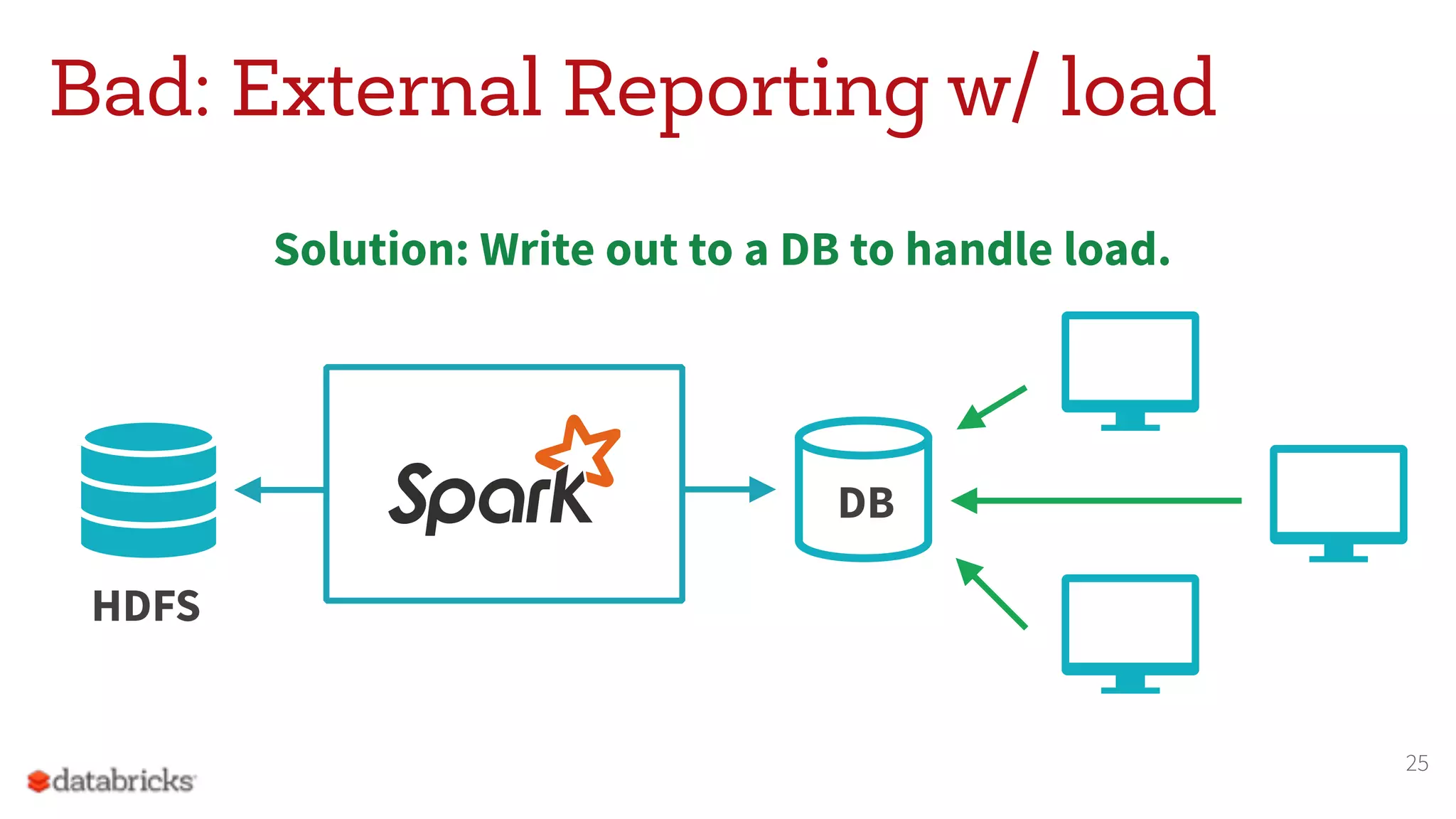




The document discusses the appropriate use of Apache Spark within big data architecture, emphasizing the differences between traditional SQL databases and Spark's performance capabilities. It addresses various workload types, such as batch processing and ad hoc analysis, and highlights best practices for data storage and management while cautioning against Spark's limitations with random access and frequent updates. It also provides solutions for handling specific use cases, such as machine learning and external reporting.