Downloaded 165 times




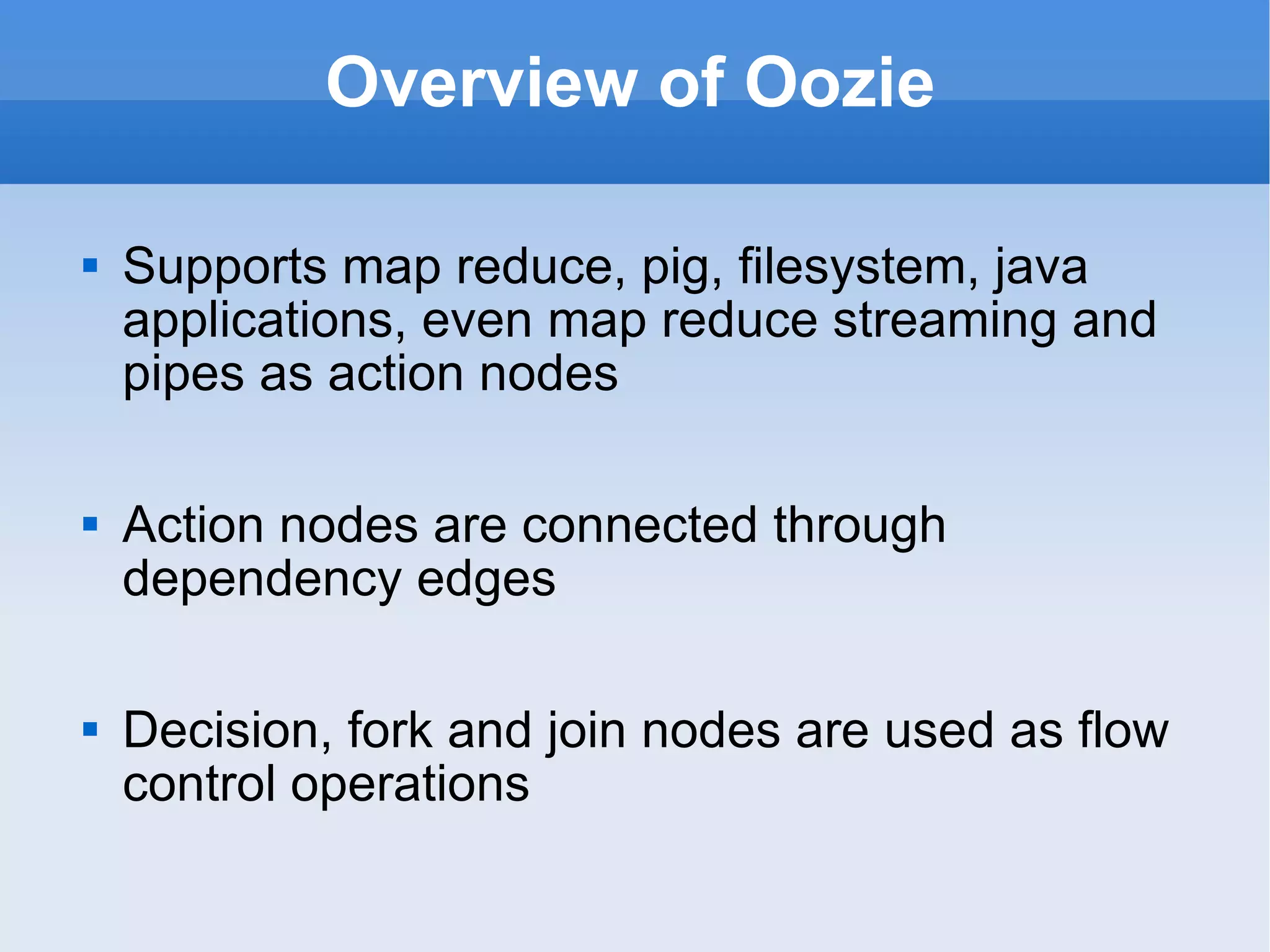


![Chain MR Chains the multiple mapper classes in single map task which saves lots of I/O The output of immediate previous mapper is fed as input to current mapper The output of last mapper is written as task output Supports passing key/value pairs to next maps by reference to save [de]serialization time ChainReducer supports to chain multiple mapper classes after reducer within reducer task](https://image.slidesharecdn.com/hadoopecosystemframeworknhadoopinliveenvironment-110911235314-phpapp01/75/Hadoop-ecosystem-framework-n-hadoop-in-live-environment-12-2048.jpg)
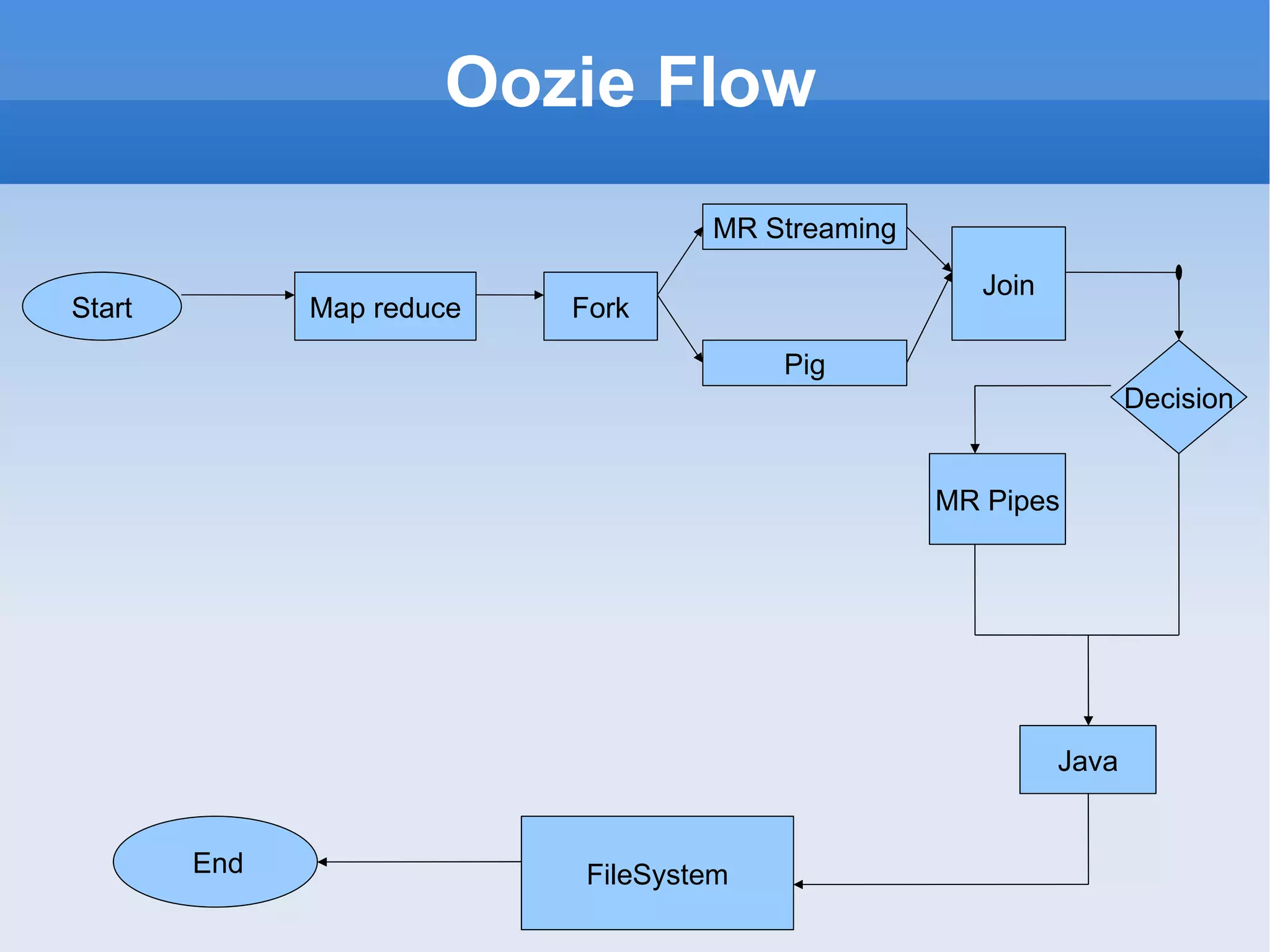















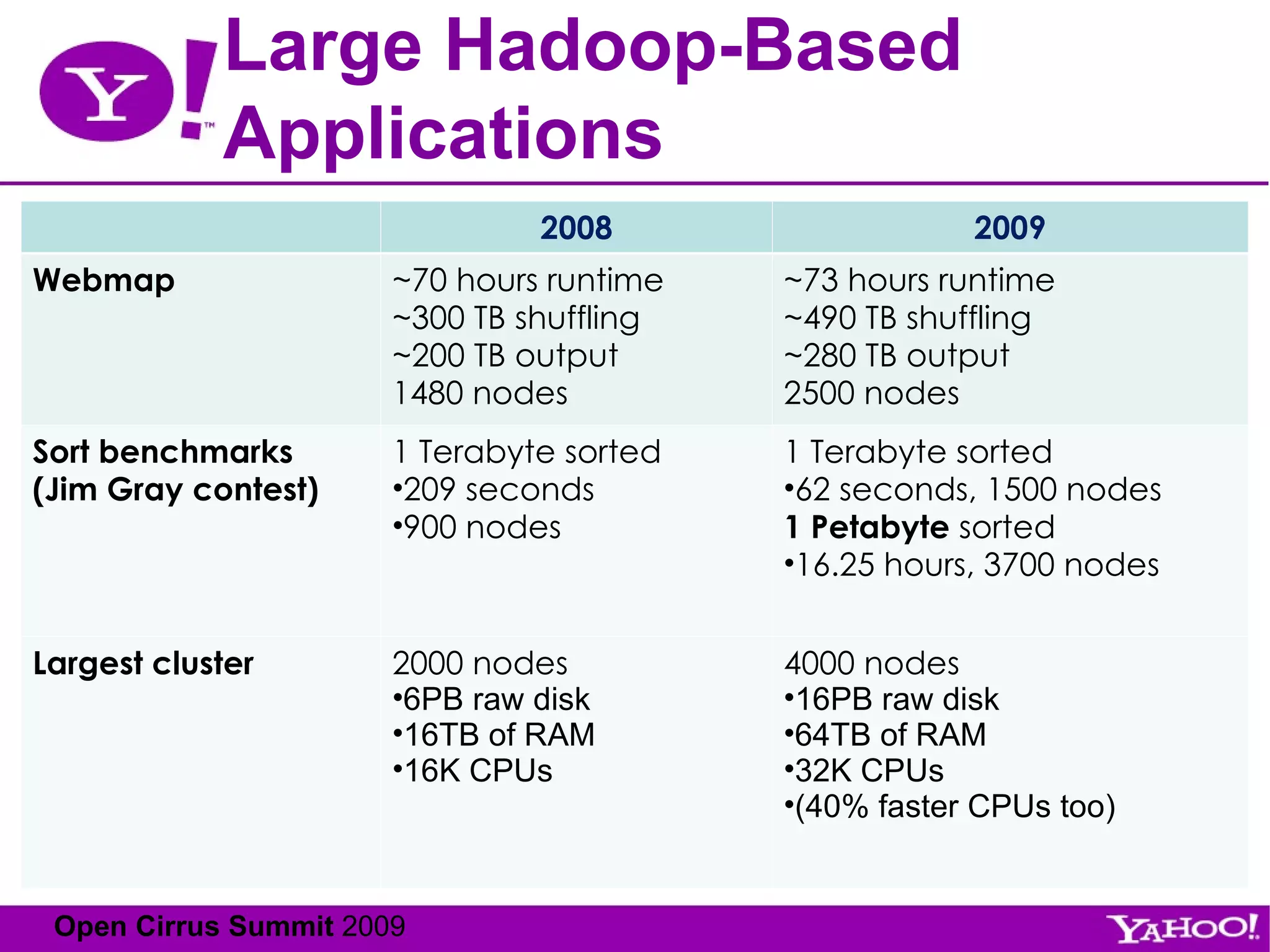








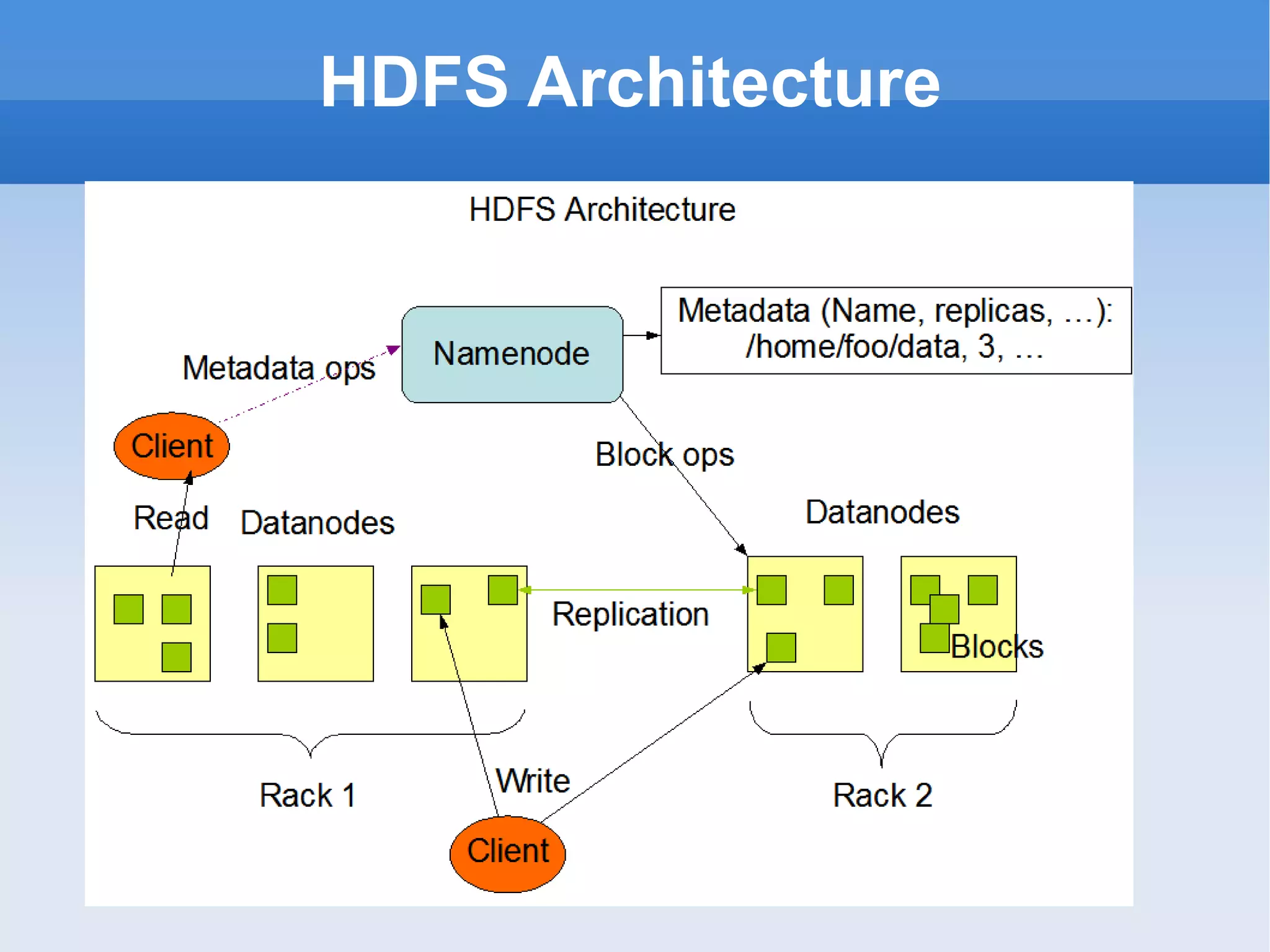
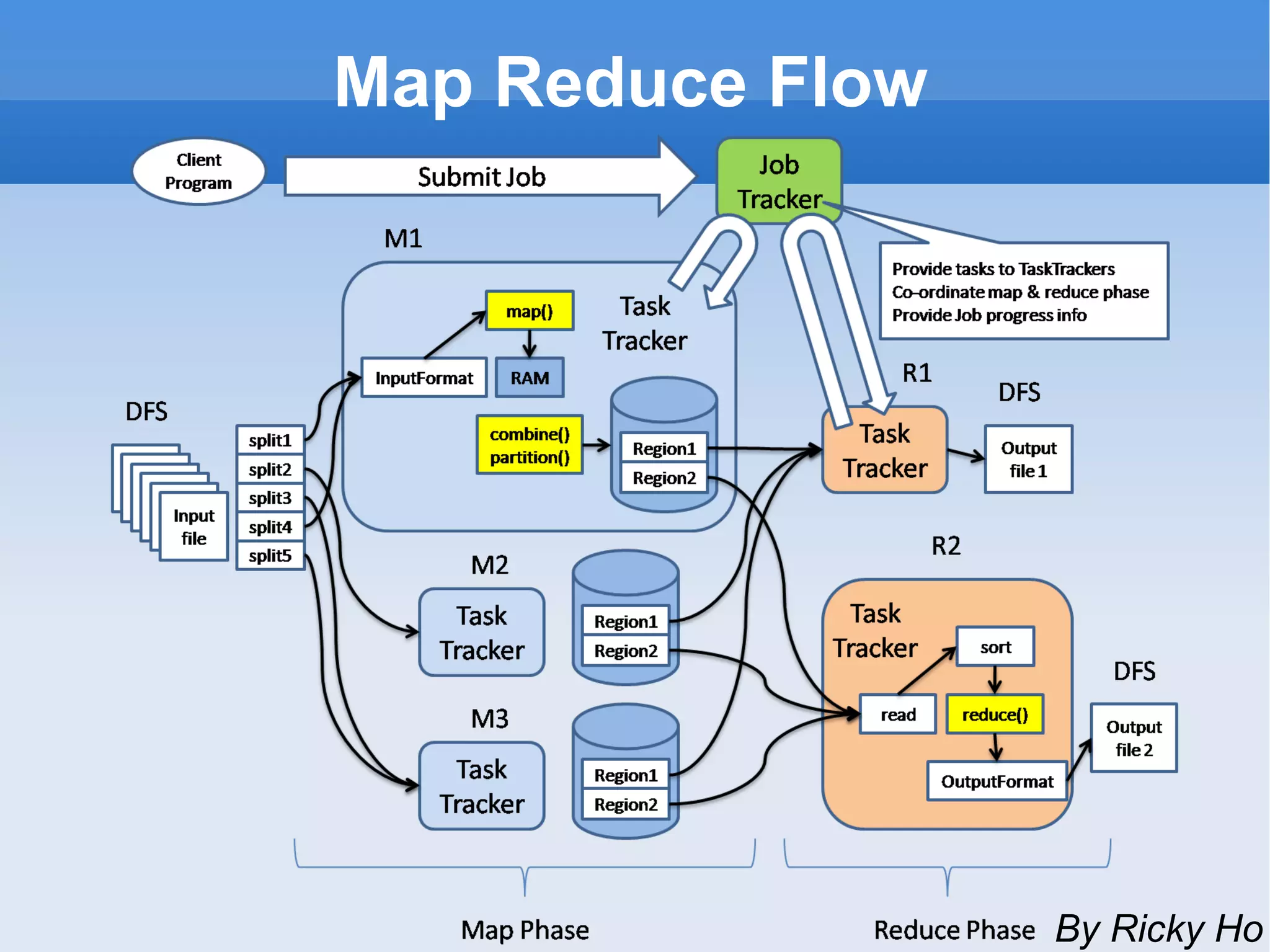
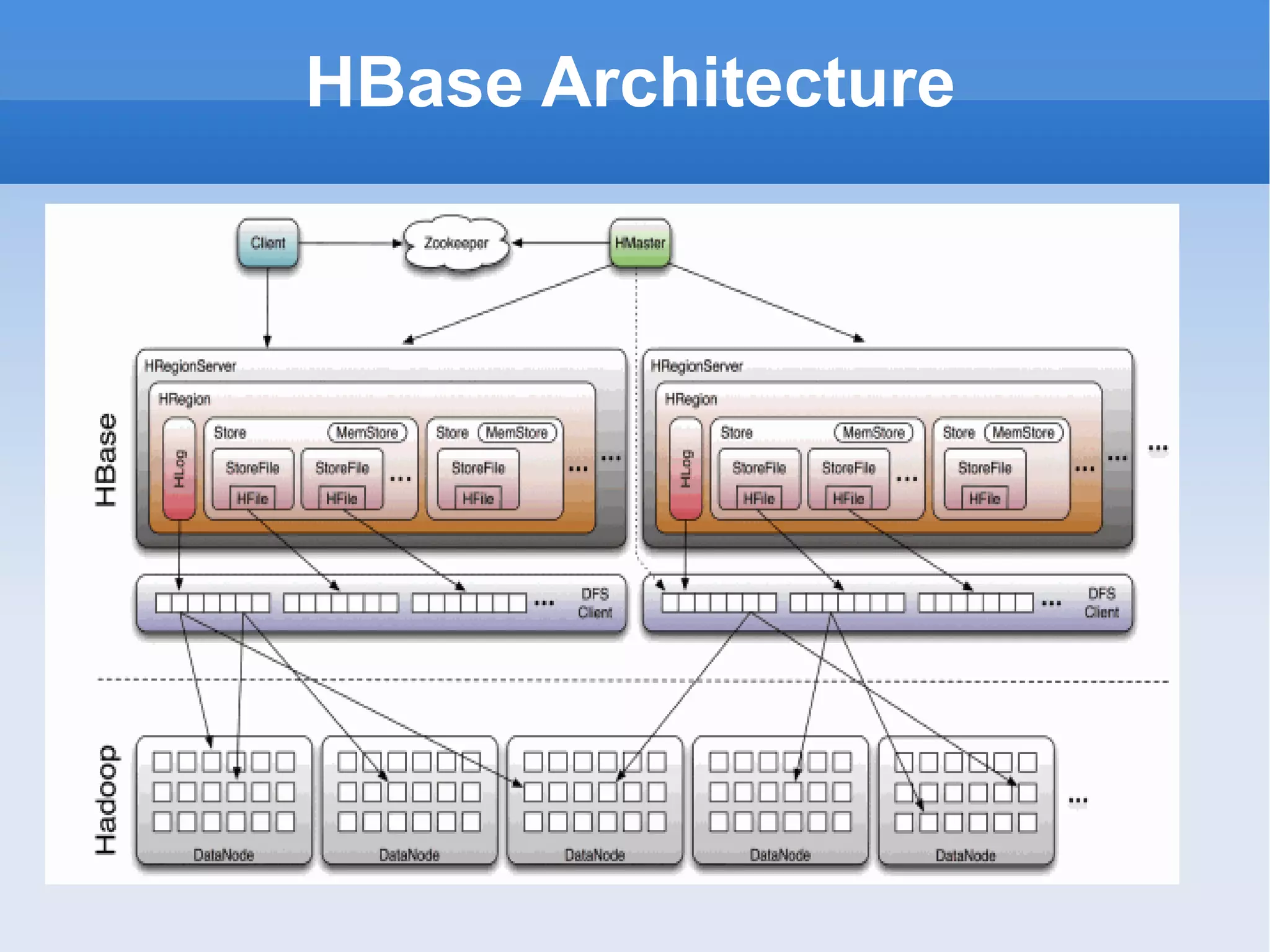
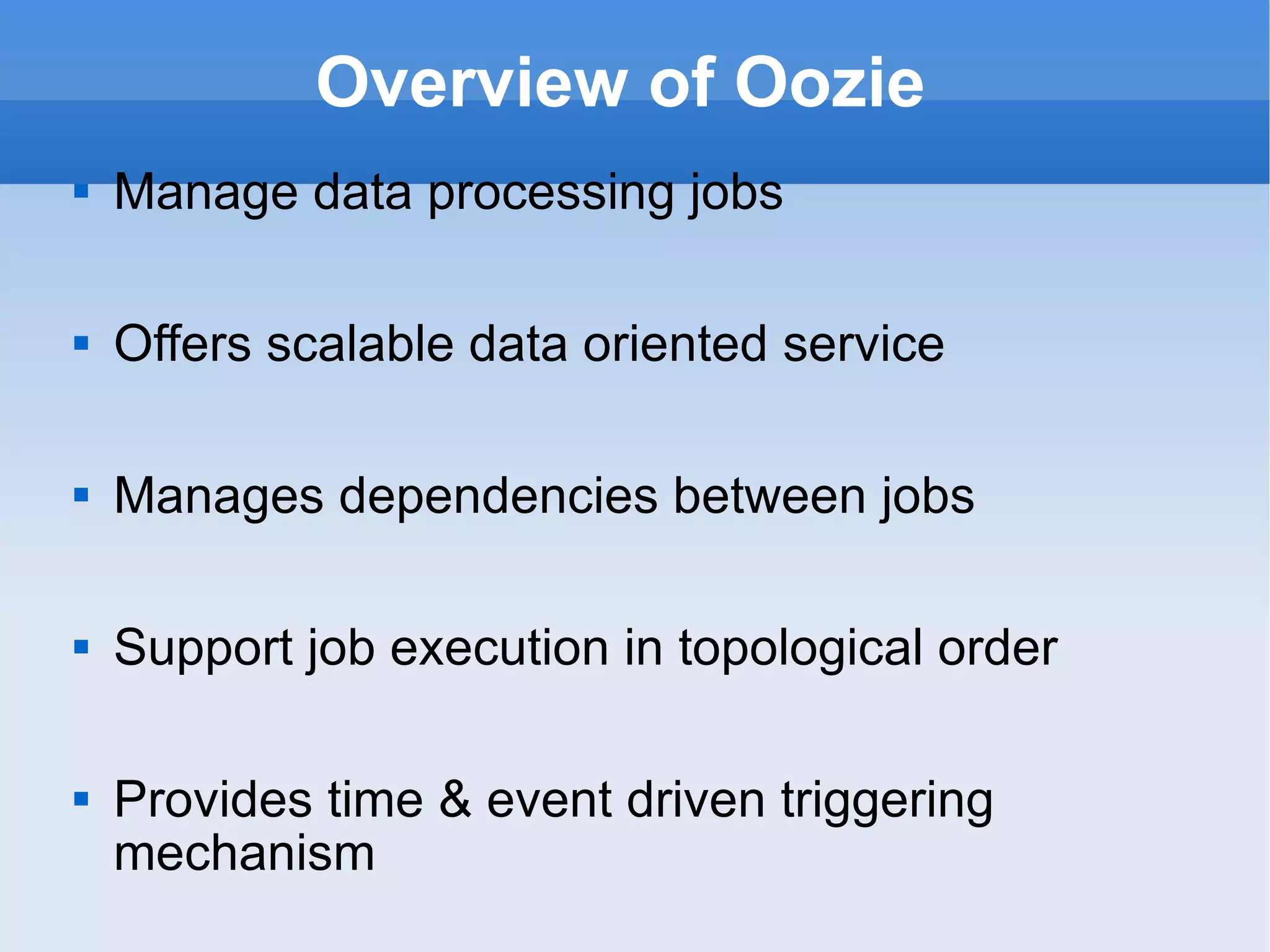
The document provides an overview of the Hadoop ecosystem and how several large companies such as Google, Yahoo, Facebook, and others use Hadoop in production. It discusses the key components of Hadoop including HDFS, MapReduce, HBase, Pig, Hive, Zookeeper and others. It also summarizes some of the large-scale usage of Hadoop at these companies for applications such as web indexing, analytics, search, recommendations, and processing massive amounts of data.