Downloaded 20 times







![EPGM – Graph Representation 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 knows since : 2014 knows since : 2014 knows since : 2013 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-21-2048.jpg)
![[2] Community | interest : Graphs | vertexCount : 4 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 EPGM – Graph Representation [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 knows since : 2014 knows since : 2014 knows since : 2013 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-22-2048.jpg)

![Combination 1: personGraph = db.G[0].combine(db.G[1]).combine(db.G[2]) [2] Community | interest : Graphs| vertexCount : 4 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 knows since : 2014 knows since : 2014 knows since : 2013 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 DB](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-26-2048.jpg)
![[0] Community | interest : Databases | vertexCount : 3 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing 10 11 12 13 14 15 16 17 18 19 20 21 22 23 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag DB Combination [4] [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 knows since : 2014 knows since : 2014 knows since : 2013 knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 1: personGraph = db.G[0].combine(db.G[1]).combine(db.G[2])](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-27-2048.jpg)
![[0] Community | interest : Databases | vertexCount : 3 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing 10 11 12 13 14 15 16 17 18 19 20 21 22 23 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag DB Combination + Grouping [4] [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 knows since : 2014 knows since : 2014 knows since : 2013 knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 1: personGraph = db.G[0].combine(db.G[1]).combine(db.G[2]) 2: vertexGroupingKeys = [:label, “city”] 3: edgeGroupingKeys = [: label] 4: vertexAggFunc = (superVertex, vertices => superVertex[“count”] = |vertices|) 5: edgeAggFunc = (superEdge, edges => superEdge[“count”] = |edges|) 6: sumGraph = personGraph.groupBy(vertexGroupingKeys, vertexAggFunc, edgeGroupingKeys, edgeAggFunc)](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-29-2048.jpg)
![[0] Community | interest : Databases | vertexCount : 3 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing 10 11 12 13 14 15 16 17 18 19 20 21 22 23 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag DB Combination + Grouping [4] [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 knows since : 2014 knows since : 2014 knows since : 2013 knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 1: personGraph = db.G[0].combine(db.G[1]).combine(db.G[2]) 2: vertexGroupingKeys = [:label, “city”] 3: edgeGroupingKeys = [: label] 4: vertexAggFunc = (superVertex, vertices => superVertex[“count”] = |vertices|) 5: edgeAggFunc = (superEdge, edges => superEdge[“count”] = |edges|) 6: sumGraph = personGraph.groupBy(vertexGroupingKeys, vertexAggFunc, edgeGroupingKeys, edgeAggFunc) [5] [11] Person city : Leipzig count : 2 [12] Person city : Dresden count : 3 [13] Person city : Berlin count : 1 24 25 26 27 28 knows count : 3 knows count : 1 knows count : 2 knows count : 2 knows count : 2](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-30-2048.jpg)
![[0] Community | interest : Databases | vertexCount : 3 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing 10 11 12 13 14 15 16 17 18 19 20 21 22 23 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag DB Combination + Grouping + Aggregation [4] [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 knows since : 2014 knows since : 2014 knows since : 2013 knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 1: personGraph = db.G[0].combine(db.G[1]).combine(db.G[2]) 2: vertexGroupingKeys = [:label, “city”] 3: edgeGroupingKeys = [: label] 4: vertexAggFunc = (superVertex, vertices => superVertex[“count”] = |vertices|) 5: edgeAggFunc = (superEdge, edges => superEdge[“count”] = |edges|) 6: sumGraph = personGraph.groupBy(vertexGroupingKeys, vertexAggFunc, edgeGroupingKeys, edgeAggFunc) 7: aggFunc = (g => |g.E|) 8: aggGraph = sumGraph.aggregate(“edgeCount”, aggFunc) [5] [11] Person city : Leipzig count : 2 [12] Person city : Dresden count : 3 [13] Person city : Berlin count : 1 24 25 26 27 28 knows count : 3 knows count : 1 knows count : 2 knows count : 2 knows count : 2](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-31-2048.jpg)
![[0] Community | interest : Databases | vertexCount : 3 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing 10 11 12 13 14 15 16 17 18 19 20 21 22 23 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag DB Combination + Grouping + Aggregation [4] [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 knows since : 2014 knows since : 2014 knows since : 2013 knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 1: personGraph = db.G[0].combine(db.G[1]).combine(db.G[2]) 2: vertexGroupingKeys = [:label, “city”] 3: edgeGroupingKeys = [: label] 4: vertexAggFunc = (superVertex, vertices => superVertex[“count”] = |vertices|) 5: edgeAggFunc = (superEdge, edges => superEdge[“count”] = |edges|) 6: sumGraph = personGraph.groupBy(vertexGroupingKeys, vertexAggFunc, edgeGroupingKeys, edgeAggFunc) 7: aggFunc = (g => |g.E|) 8: aggGraph = sumGraph.aggregate(“edgeCount”, aggFunc) [5] edgeCount : 5 [11] Person city : Leipzig count : 2 [12] Person city : Dresden count : 3 [13] Person city : Berlin count : 1 24 25 26 27 28 knows count : 3 knows count : 1 knows count : 2 knows count : 2 knows count : 2](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-32-2048.jpg)
![Selection 1: resultColl = db.G[0,1,2].select((g => g[“vertexCount”] > 3)) [2] Community | interest : Graphs | vertexCount : 4 [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 knows since : 2014 knows since : 2014 knows since : 2013 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 DB](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-34-2048.jpg)
![Selection 1: resultColl = db.G[0,1,2].select((g => g[“vertexCount”] > 3)) [1] Community | interest : Hadoop| vertexCount : 3[0] Community | interest : Databases | vertexCount : 3 [0] Tag name : Databases [1] Tag name : Graphs [2] Tag name : Hadoop [3] Forum title : Graph Databases [4] Forum title : Graph Processing [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en [10] Person name : Frank gender : m city : Berlin age : 23 IP: 169.32.1.3 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 hasInterest hasInterest hasInterest hasInterest hasModeratorhasModerator hasMember hasMember hasMember hasMember hasTag hasTaghasTag hasTag knows since : 2015 knows since : 2015 knows since : 2015 knows since : 2013 DB [2] Community | interest : Graphs | vertexCount : 4 [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 0 1 2 3 4 5 knows since : 2014 knows since : 2014 knows since : 2013 knows since : 2013 knows since : 2014 knows since : 2014](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-35-2048.jpg)


![The „Hello World“ of Big Data – Word Count 1: ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); 2: 3: DataSet<String> text = env.fromElements( // or env.readTextFile(„hdfs://…“) 4: „He who controls the past controls the future.“, 5: „He who controls the present controls the past.“); 6: 7: DataSet<Tuple2<String, Integer>> wordCounts = text 8: .flatMap(new LineSplitter()) // splits the line and outputs (word, 1) tuples 9: .groupBy(0) 10: .sum(1); 11: 12: wordCounts.print(); // trigger execution flatMap „He who controls the past controls the future.“ „He who controls the present controls the past.“ (He,1) (who,1) (controls,1) (the,1) (past,1) // ... groupBy(0) [(He,1),(He,1)] [(who,1),(who,1)] [(future,1)] [(past,1),(past,1)] [(present,1)] // ... sum(1) (He,2) (who,2) (future,1) (past,2) (present,1) // ...](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-41-2048.jpg)

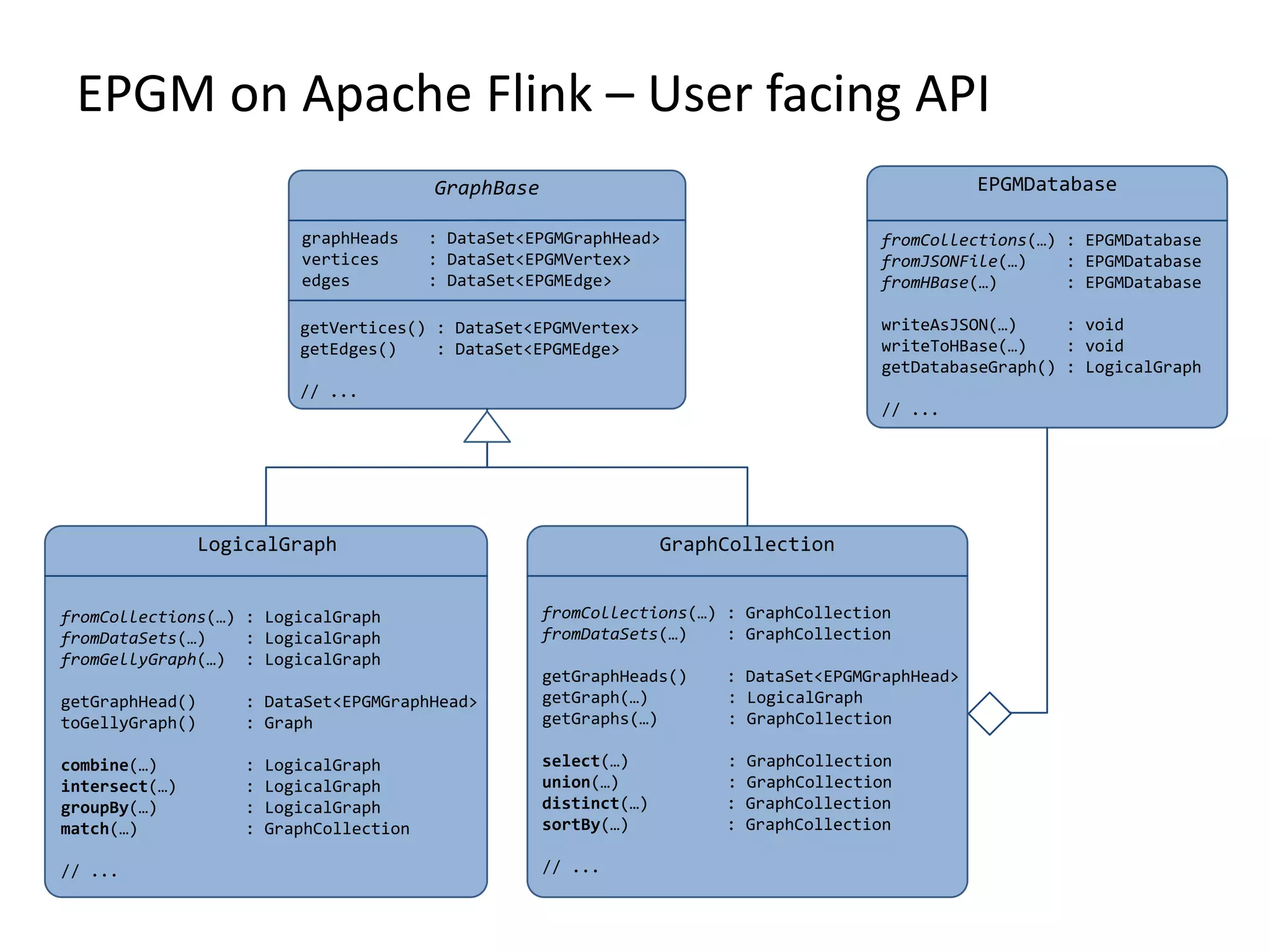
![EPGM on Apache Flink – DataSets Id Label Properties Graphs Id Label Properties SourceId TargetId Graphs EPGMGraphHead EPGMVertex EPGMEdge Id Label Properties POJO POJO POJO DataSet<EPGMGraphHead> DataSet<EPGMVertex> DataSet<EPGMEdge> Id Label Properties Graphs EPGMVertex GradoopId := UUID 128-bit String PropertyList := List<Property> Property := (String, PropertyValue) PropertyValue := byte[] GradoopIdSet := Set<GradoopId>](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-44-2048.jpg)
![EPGM on Apache Flink – Exclusion // input: firstGraph (G[0]), secondGraph (G[2]) 1: DataSet<GradoopId> graphId = secondGraph.getGraphHead() 2: .map(new Id<G>()); 3: 4: DataSet<V> newVertices = firstGraph.getVertices() 5: .filter(new NotInGraphBroadCast<V>()) 6: .withBroadcastSet(graphId, GRAPH_ID); 7: 8: DataSet<E> newEdges = firstGraph.getEdges() 9: .filter(new NotInGraphBroadCast<E>()) 10: .withBroadcastSet(graphId, GRAPH_ID) 11: .join(newVertices) 12: .where(new SourceId<E>().equalTo(new Id<V>()) 13: .with(new LeftSide<E, V>()) 14: .join(newVertices) 15: .where(new TargetId<E>().equalTo(new Id<V>()) 16: .with(new LeftSide<E, V>()); db.G[0].exclude(db.G[2]) [2] Community | interest : Graphs| vertexCount : 4 [0] Community | interest : Databases | vertexCount : 3 [5] Person name : Alice gender : f city : Leipzig age : 23 [6] Person name : Bob gender : m city : Leipzig age : 30 [7] Person name : Carol gender : f city : Dresden age : 30 [8] Person name : Dave gender : m city : Dresden age : 42 [9] Person name : Eve gender : f city : Dresden age : 35 speaks : en 0 1 2 3 4 5 6 7 knows since : 2014 knows since : 2014 knows since : 2013 knows since : 2013 knows since : 2014 knows since : 2014 knows since : 2015 knows since : 2013](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-45-2048.jpg)
![EPGM on Apache Flink – Exclusion Id Label Properties 2 Community interest: Graphs vertexCount: 4 graphId = secondGraph.getGraphHead() Id 2 newVertices = firstGraph.getVertices() Id Label Properties Graphs 5 Person name: Alice gender: f … [0, 2] 6 Person name: Bob gender: m … [0, 2] 9 Person name: Eve gender: f … [0] Id Label Properties Graphs 9 Person name: Eve gender: f … [0] .map(new Id<G>()); .filter(new NotInGraphBroadCast<V>()) .withBroadcastSet(graphId, GRAPH_ID);](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-46-2048.jpg)
![EPGM in Apache Flink – Exclusion newEdges = firstGraph.getEdges() Id Label SourceId TargetId Properties Graphs 0 knows 5 6 since: 2014 [0, 2] 1 knows 6 5 since: 2014 [0, 2] 6 knows 9 5 since: 2013 [0] 7 knows 9 6 since: 2015 [0] Id Label SourceId TargetId Properties Graphs 6 knows 9 5 since: 2013 [0] 7 knows 9 6 since: 2015 [0] Id Label SourceId TargetId … Id Label … 6 knows 9 5 … 9 Person … 7 knows 9 6 … 9 Person … Id Label SourceId TargetId … 6 knows 9 5 … 7 knows 9 6 … Id Label SourceId TargetId … Id Label … Id Label SourceId TargetId ….with(new LeftSide<E, V>()); .join(newVertices) .where(new TargetId<E>().equalTo(new Id<V>()) .with(new LeftSide<E, V>()) .join(newVertices) .where(new SourceId<E>().equalTo(new Id<V>()) .filter(new NotInGraphBroadCast<E>()) .withBroadcastSet(graphId, GRAPH_ID)](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-47-2048.jpg)

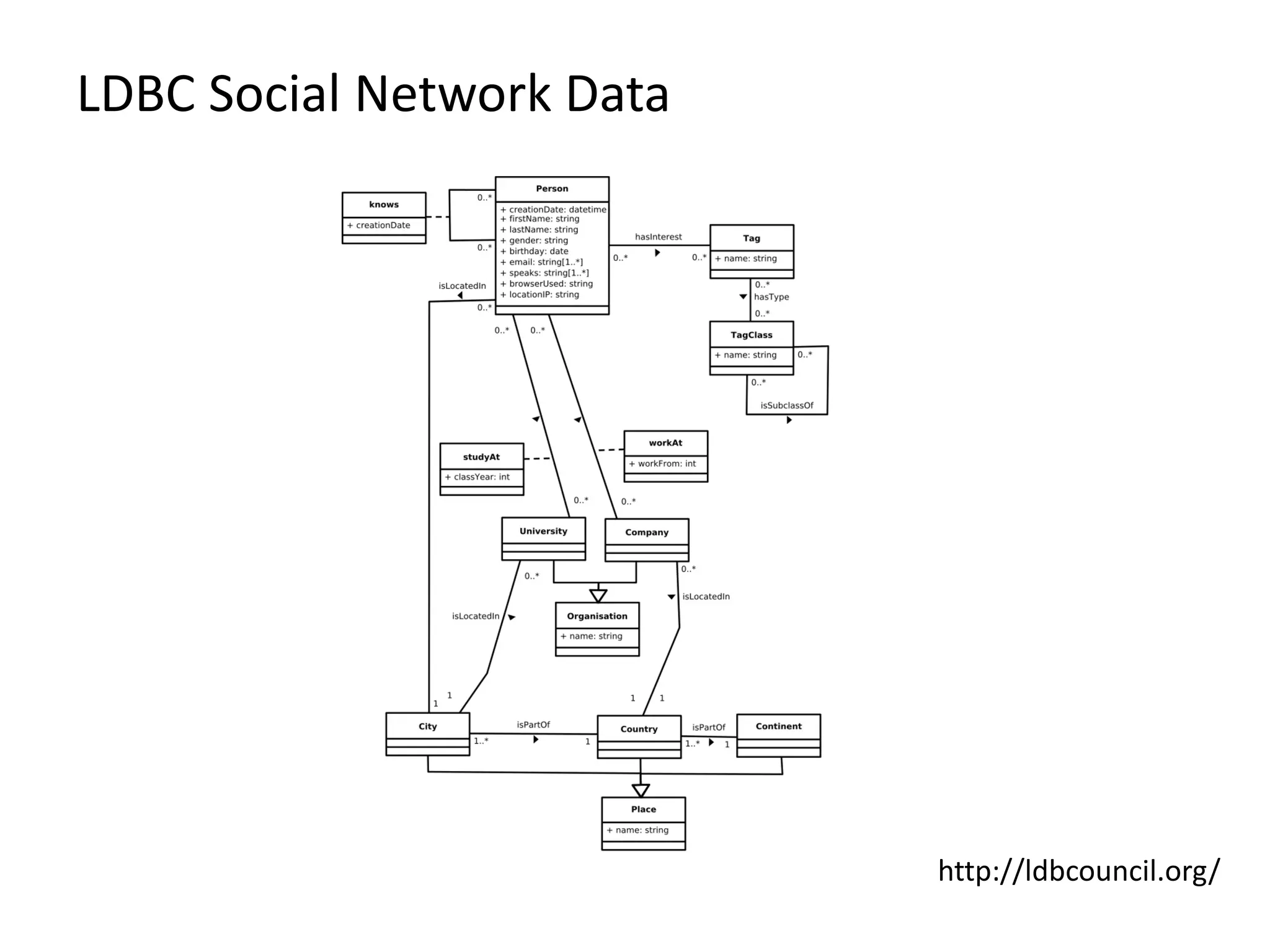
![LDBC Social Network Data socialNetwork .subgraph( (v => v.label == ‘Person‘), (e => e.label == ‘knows‘)) .transform( (gIn, gOut => gOut = gIn), (vIn, vOut => { vOut.label = vIn.label, vOut[‘city‘] = vIn[‘city‘] vOut[‘gender‘] = vIn[‘gender‘] vOut[‘key‘] = vIn[‘birthday‘]}), (eIn, eOut) => eOut.label = eIn.label)) .callForCollection(:LabelPropagation, [‘key‘, 4]) .apply(g => g.aggregate(‘vertexCount‘, (h => |h.V|)) .select(g => g[‘vertexCount‘] > 50000) .reduce(g, h => g.combine(h)) .groupBy( [‘city‘,‘gender‘], (superVertex, vertices => superVertex[‘count‘] = |vertices|), [], (superEdge, edges => superEdge[‘count‘] = |edges|) .aggregate(‘vCount‘, (g => |g.V|)) .aggregate(‘eCount‘, (g => |g.E|))](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-50-2048.jpg)
![LDBC Social Network Data socialNetwork .subgraph( (v => v.label == ‘Person‘), (e => e.label == ‘knows‘)) .transform( (gIn, gOut => gOut = gIn), (vIn, vOut => { vOut.label = vIn.label, vOut[‘city‘] = vIn[‘city‘] vOut[‘gender‘] = vIn[‘gender‘] vOut[‘key‘] = vIn[‘birthday‘]}), (eIn, eOut) => eOut.label = eIn.label)) .callForCollection(:LabelPropagation, [‘key‘, 4]) .apply(g => g.aggregate(‘vertexCount‘, (h => |h.V|)) .select(g => g[‘vertexCount‘] > 50000) .reduce(g, h => g.combine(h)) .groupBy( [‘city‘,‘gender‘], (superVertex, vertices => superVertex[‘count‘] = |vertices|), [], (superEdge, edges => superEdge[‘count‘] = |edges|) .aggregate(‘vCount‘, (g => |g.V|)) .aggregate(‘eCount‘, (g => |g.E|))](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-51-2048.jpg)
![Benchmark Results Dataset # Vertices # Edges Graphalytics.1 61,613 2,026,082 Graphalytics.10 260,613 16,600,778 Graphalytics.100 1,695,613 147,437,275 Graphalytics.1000 12,775,613 1,363,747,260 Graphalytics.10000 90,025,613 10,872,109,028 16x Intel(R) Xeon(R) 2.50GHz (6 Cores) 16x 48 GB RAM 1 Gigabit Ethernet Hadoop 2.6.0 Flink 1.0-SNAPSHOT slots (per worker) 12 jobmanager.heap.mb 2048 taskmanager.heap.mb 40960 0 200 400 600 800 1000 1200 1 2 4 8 16 Runtime[s] Number of workers Runtime Graphalytics.100](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-52-2048.jpg)
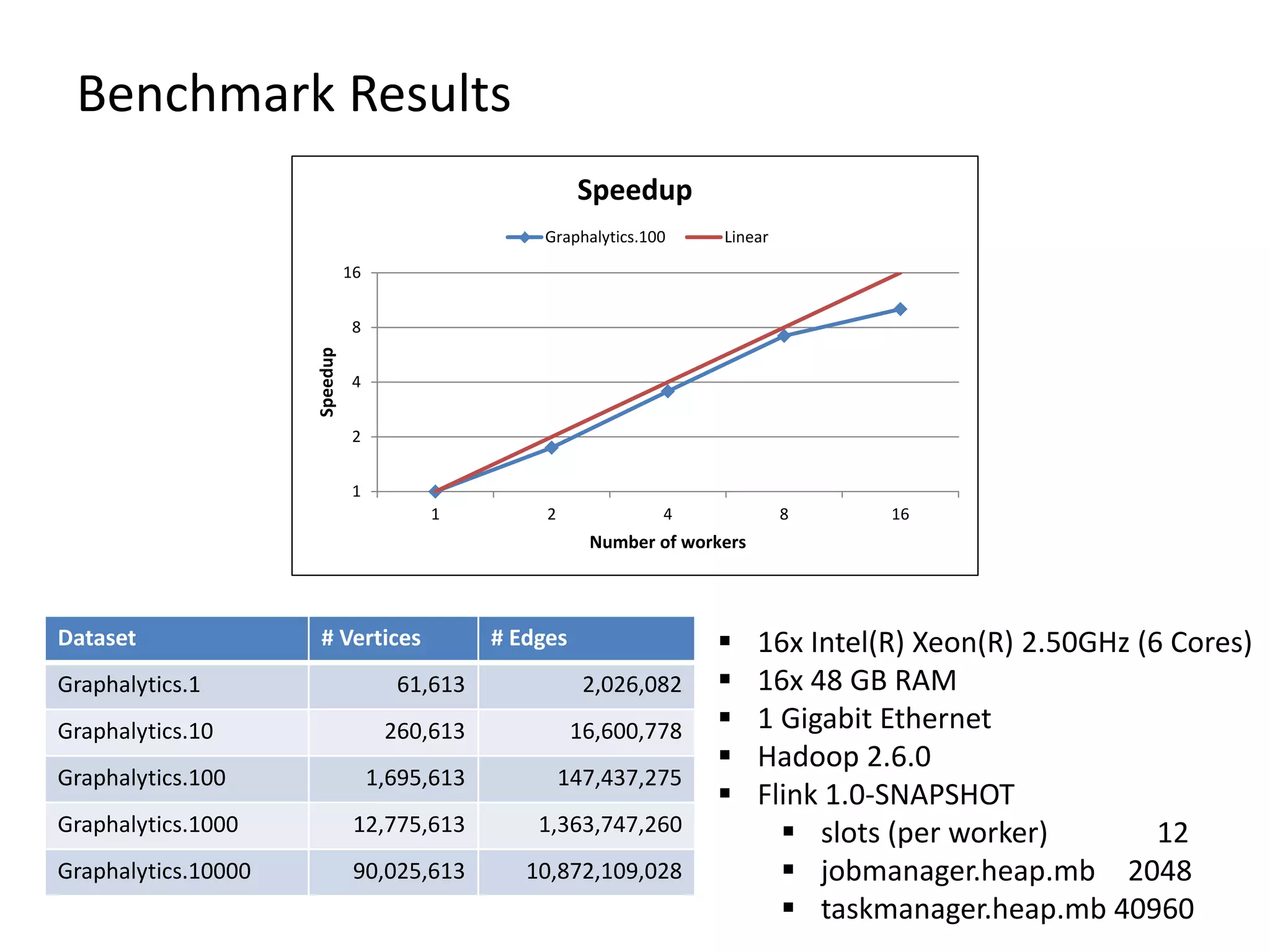
![Benchmark Results Dataset # Vertices # Edges Graphalytics.1 61,613 2,026,082 Graphalytics.10 260,613 16,600,778 Graphalytics.100 1,695,613 147,437,275 Graphalytics.1000 12,775,613 1,363,747,260 Graphalytics.10000 90,025,613 10,872,109,028 1 10 100 1000 10000 Runtime[s] Datasets 16x Intel(R) Xeon(R) 2.50GHz (6 Cores) 16x 48 GB RAM 1 Gigabit Ethernet Hadoop 2.6.0 Flink 1.0-SNAPSHOT slots (per worker) 12 jobmanager.heap.mb 2048 taskmanager.heap.mb 40960](https://image.slidesharecdn.com/2016fosdemweb-160202080009/75/Gradoop-Scalable-Graph-Analytics-with-Apache-Flink-FOSDEM-2016-54-2048.jpg)

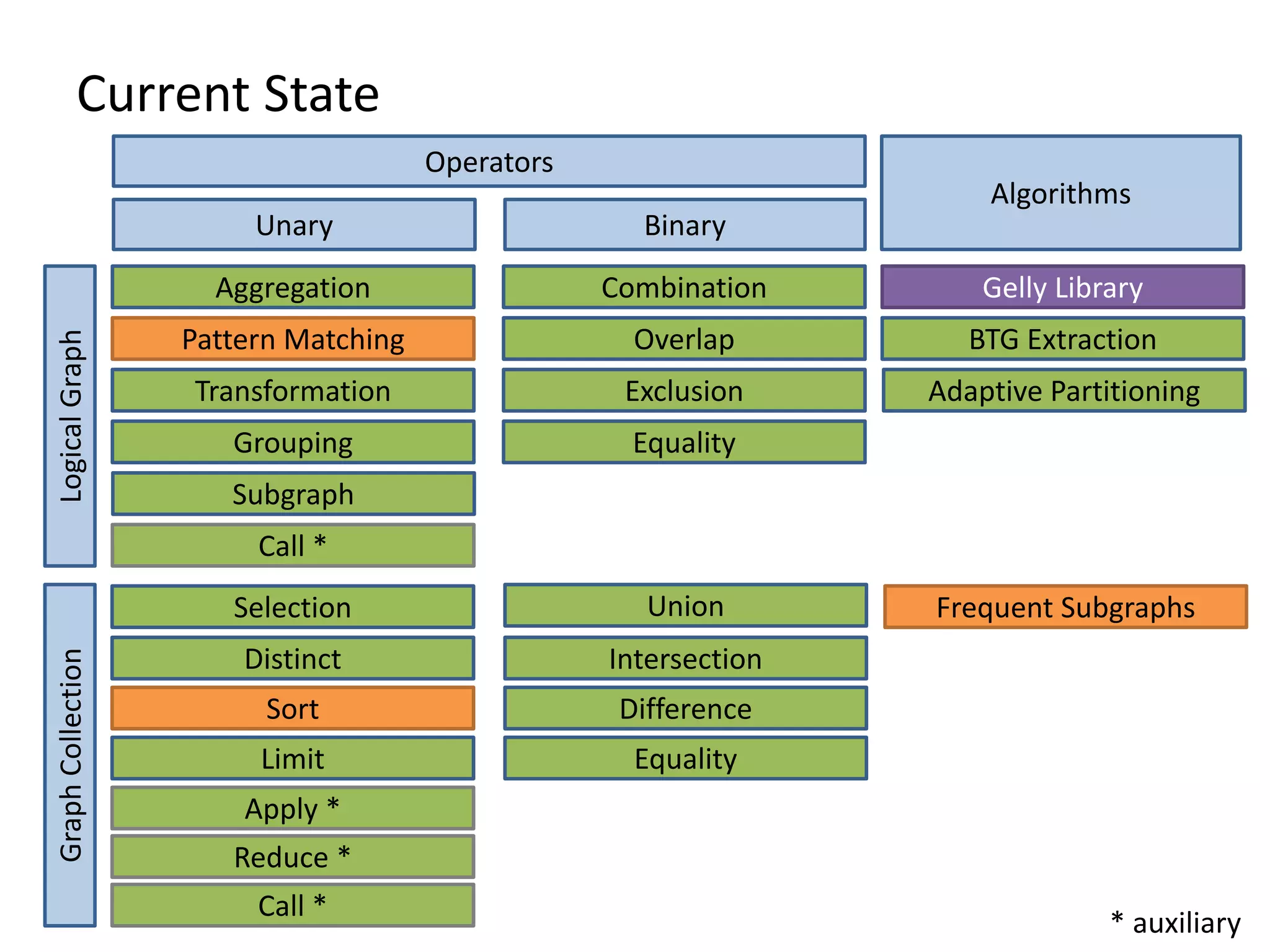





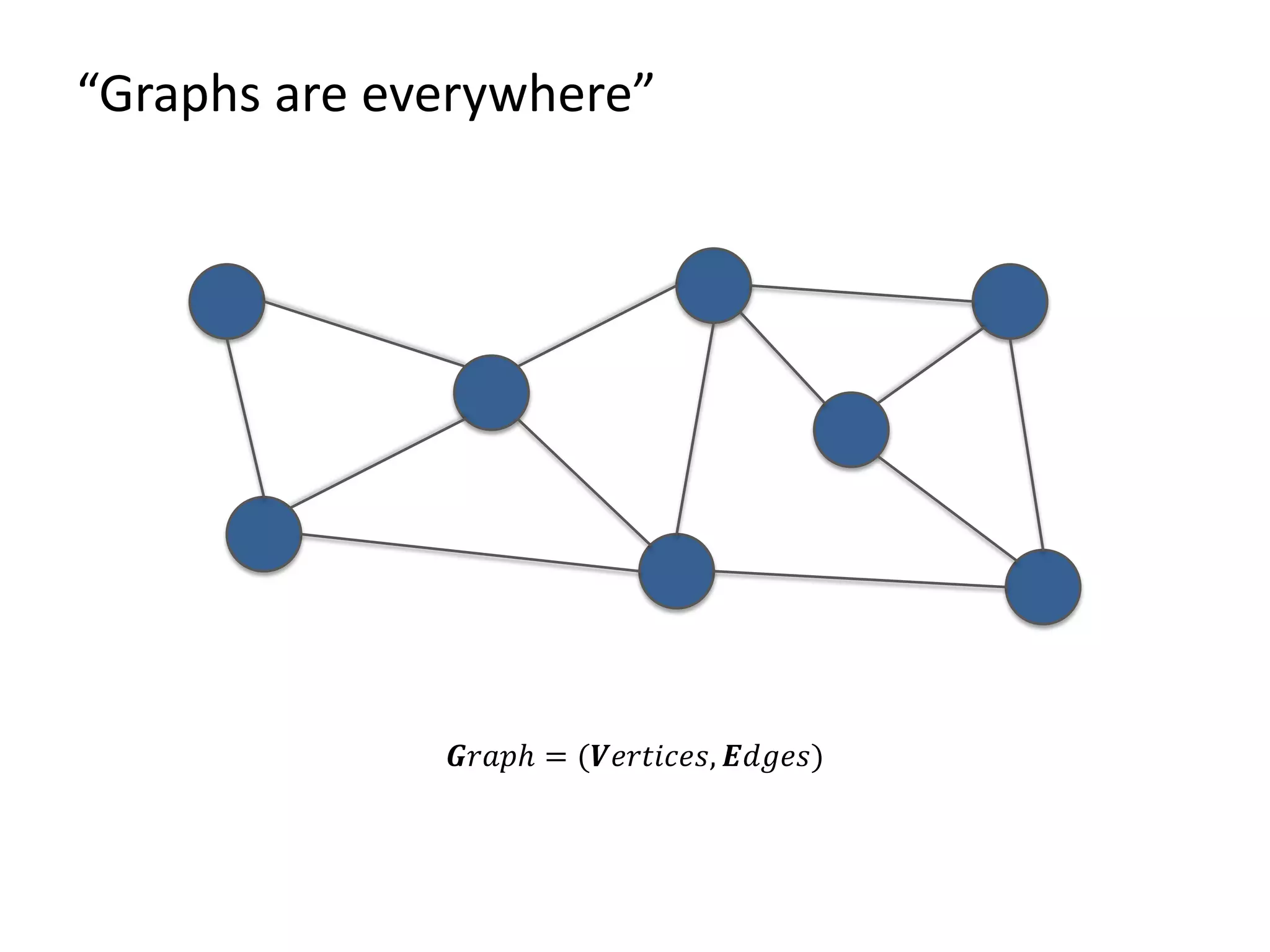
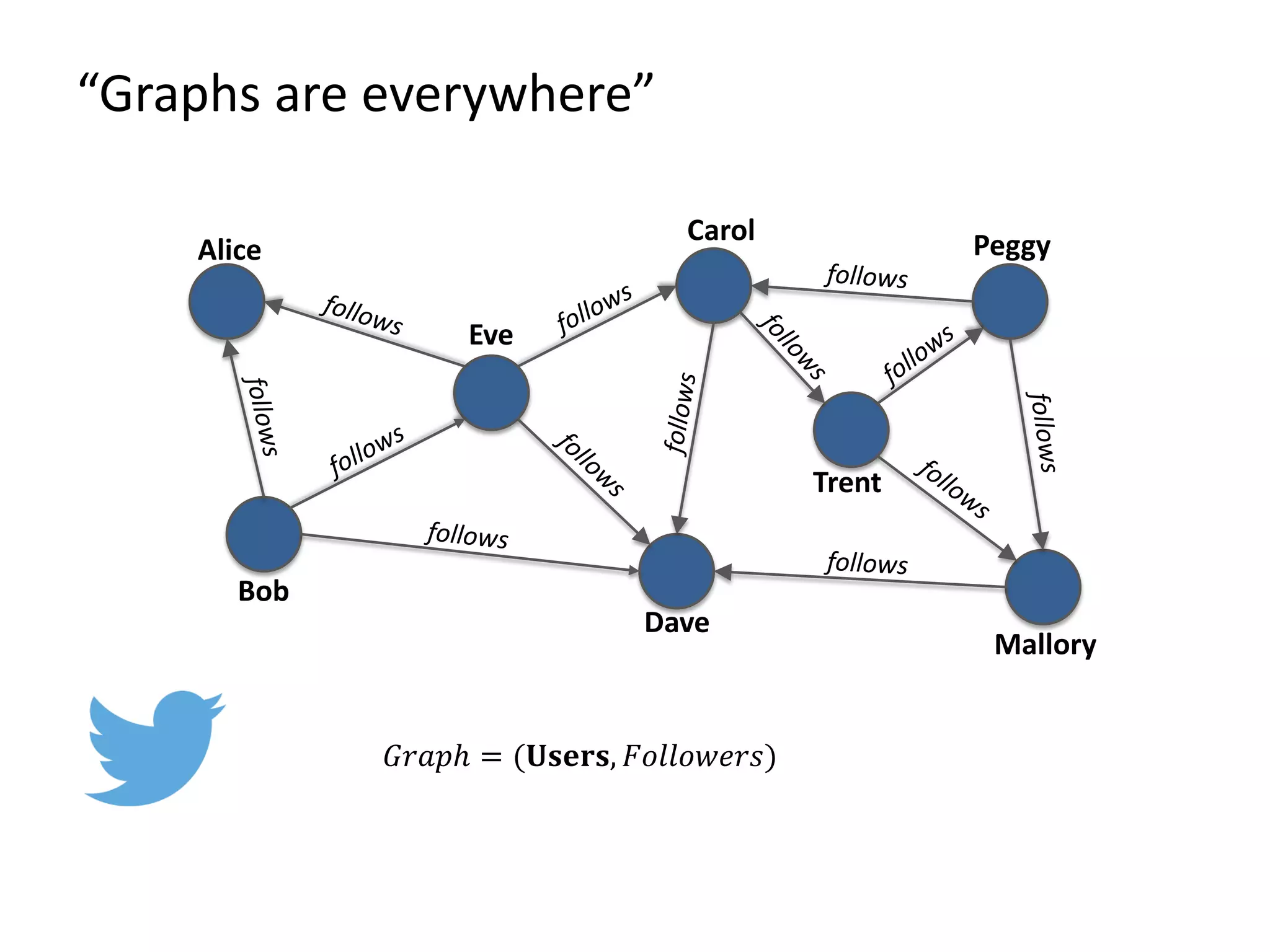
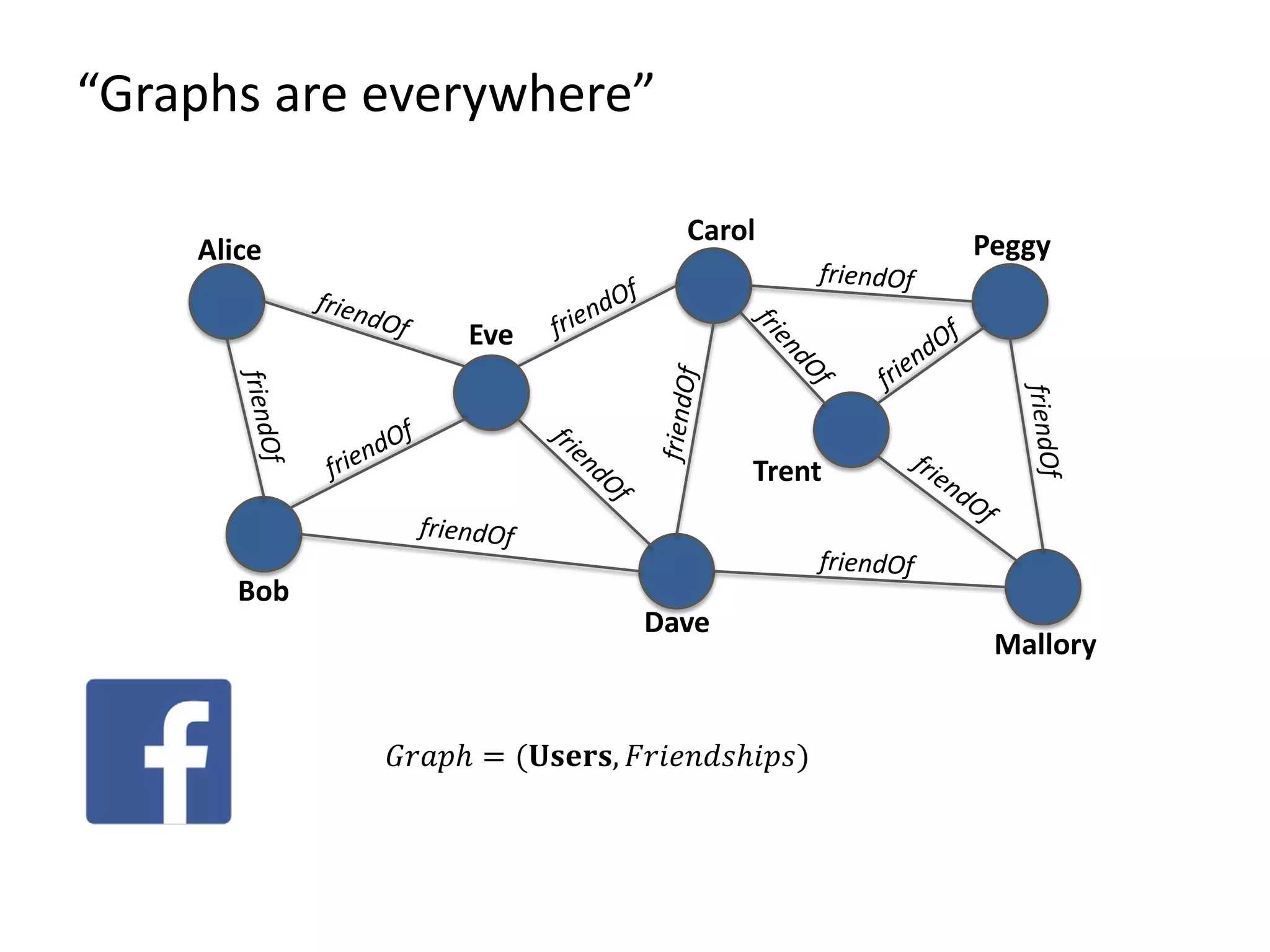
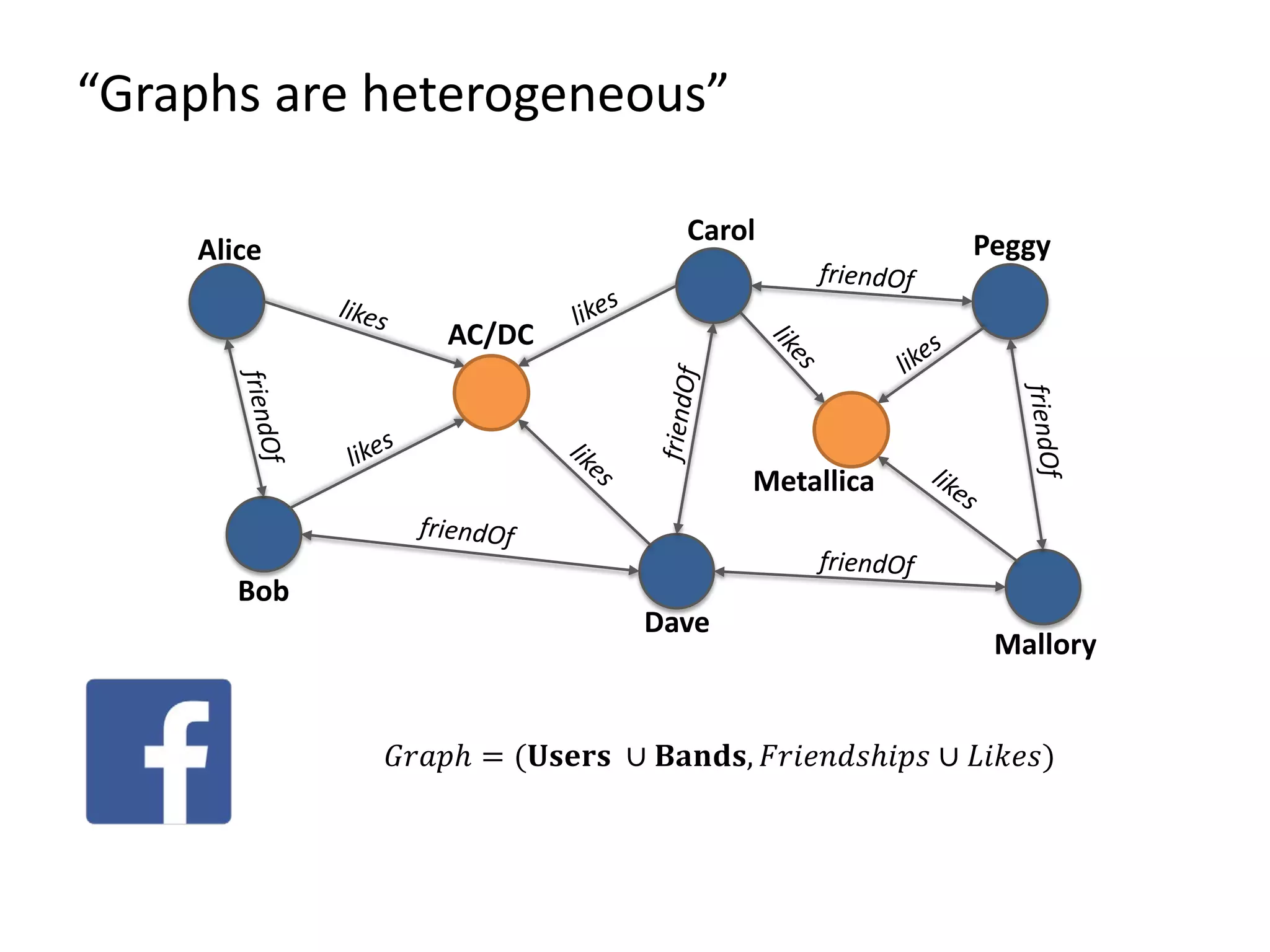
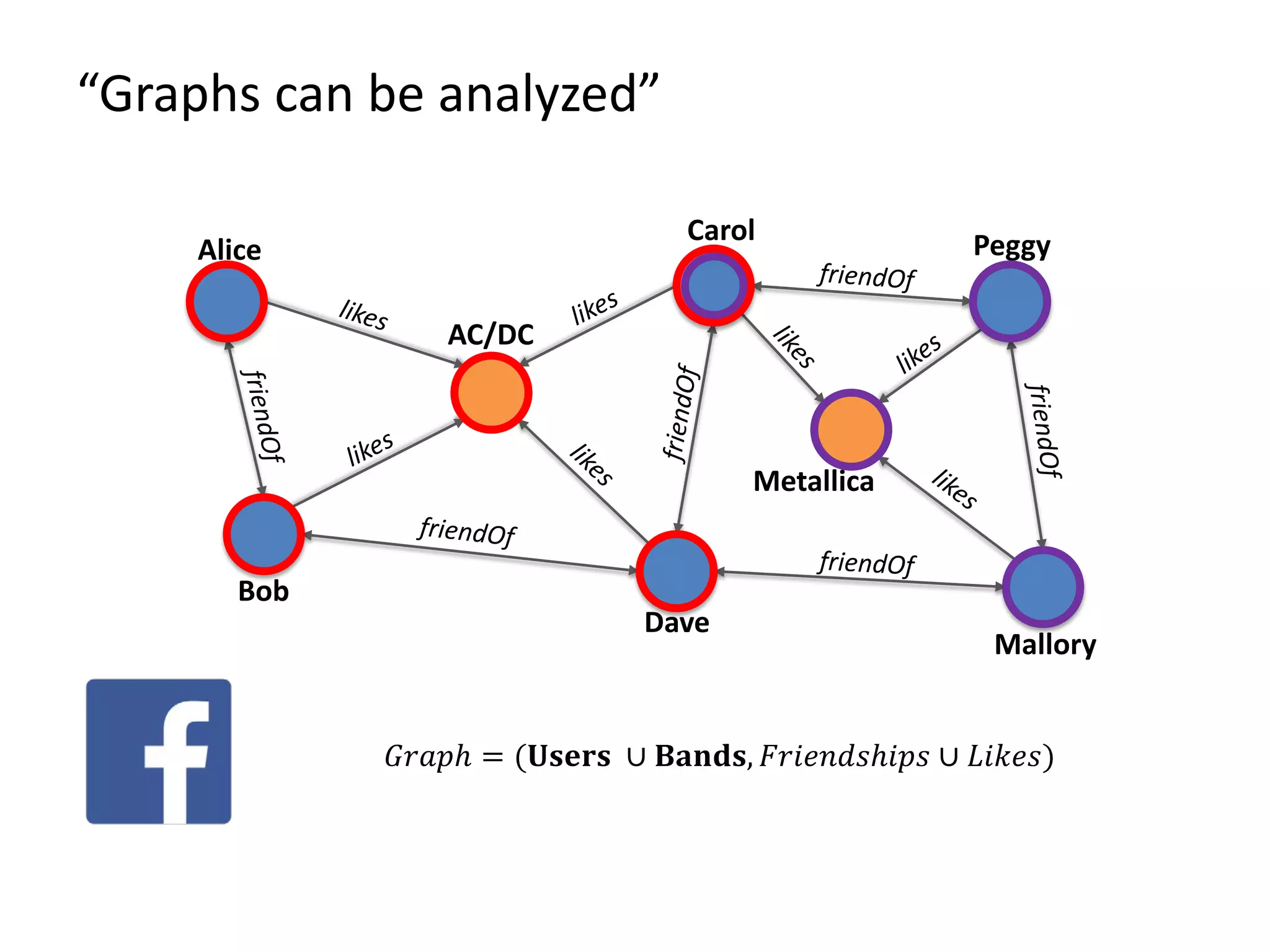
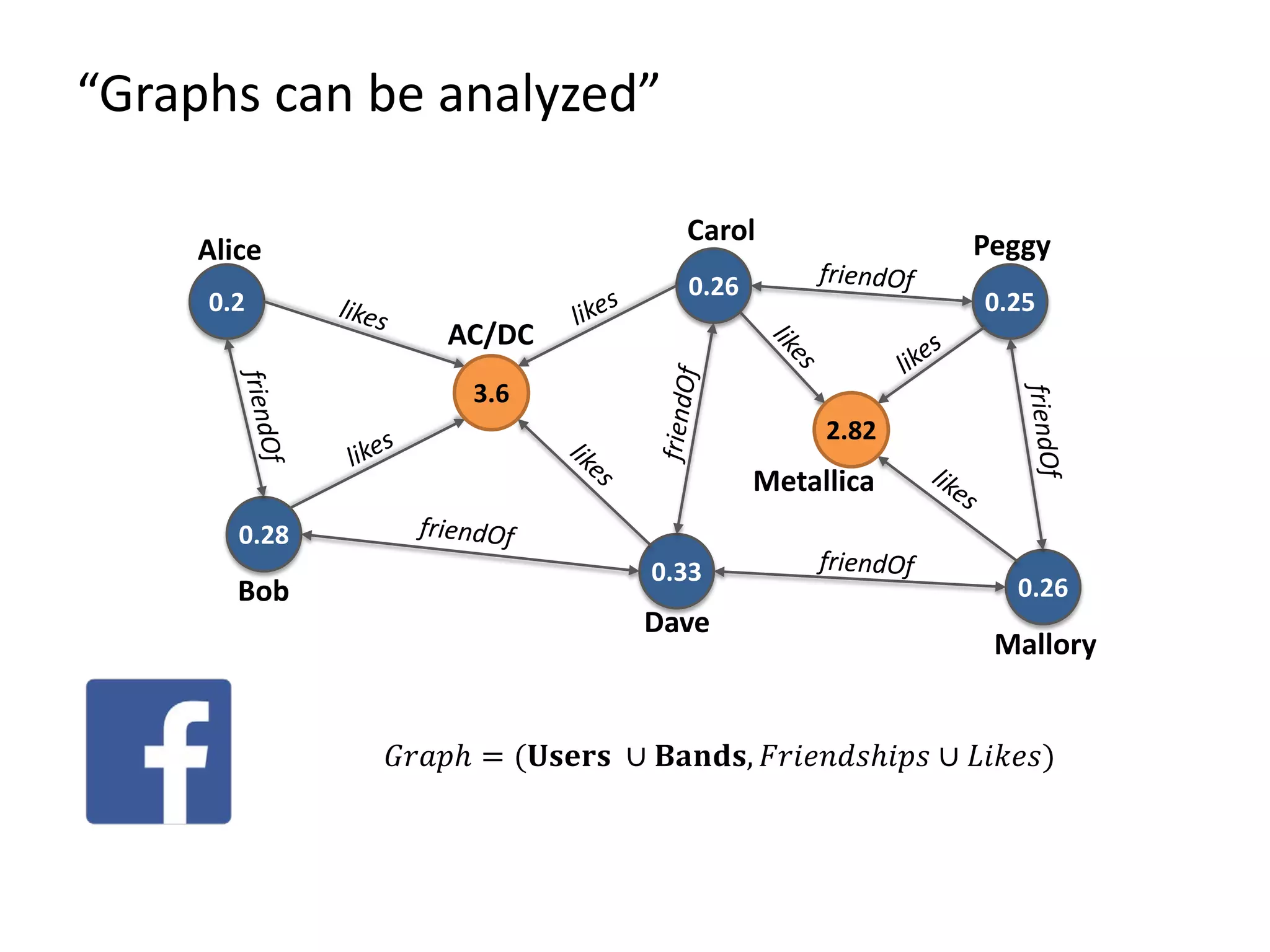
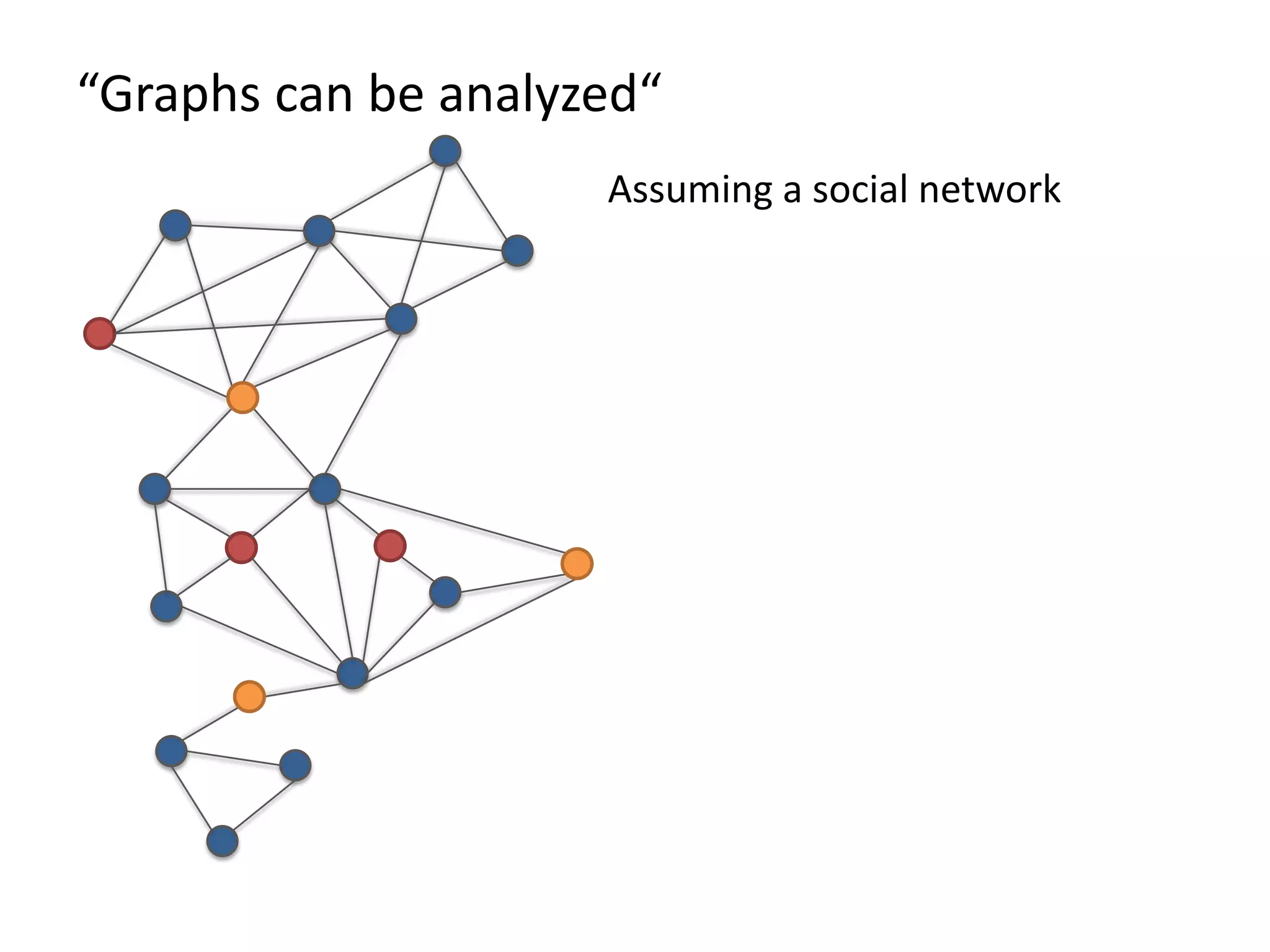
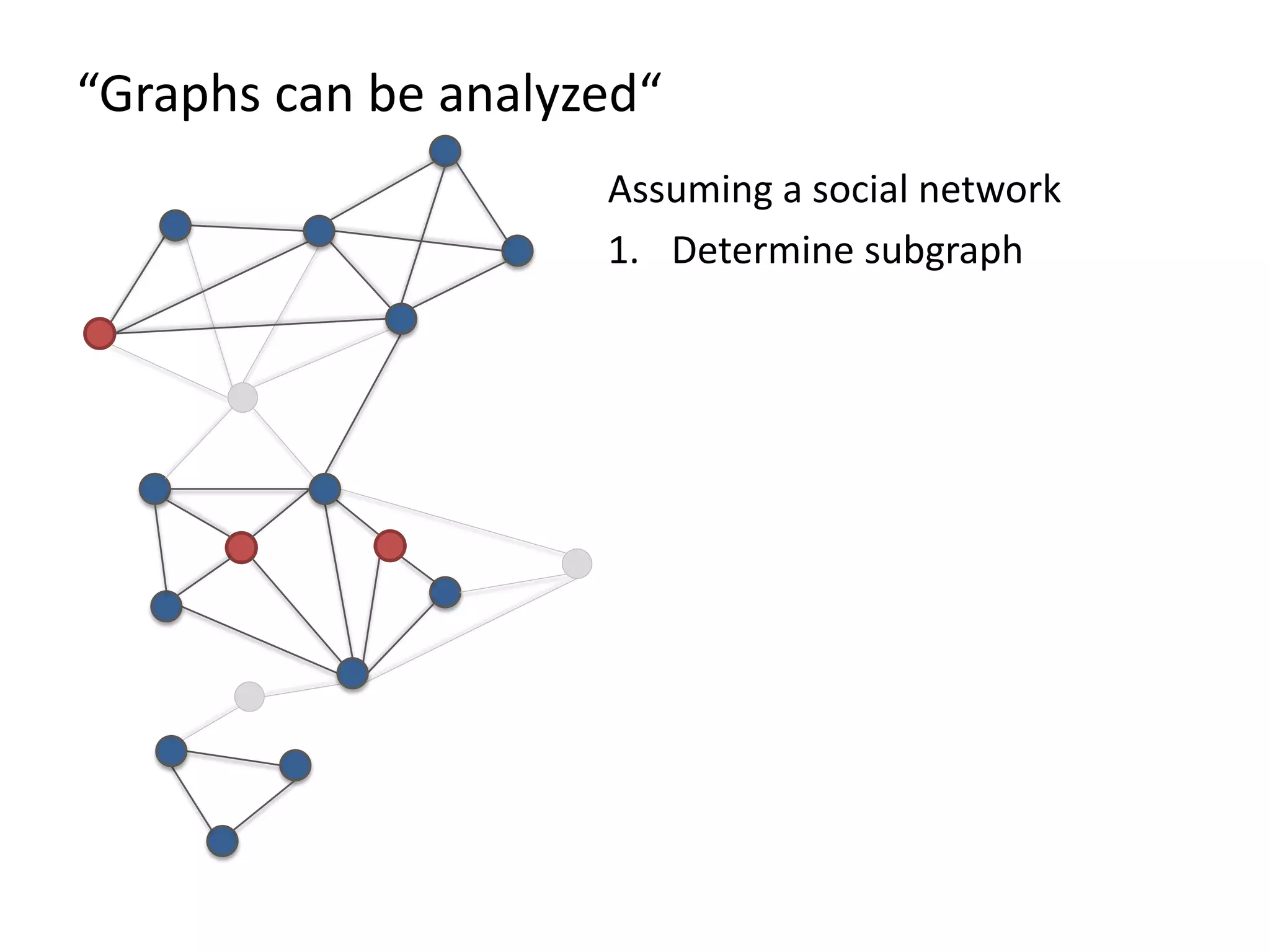
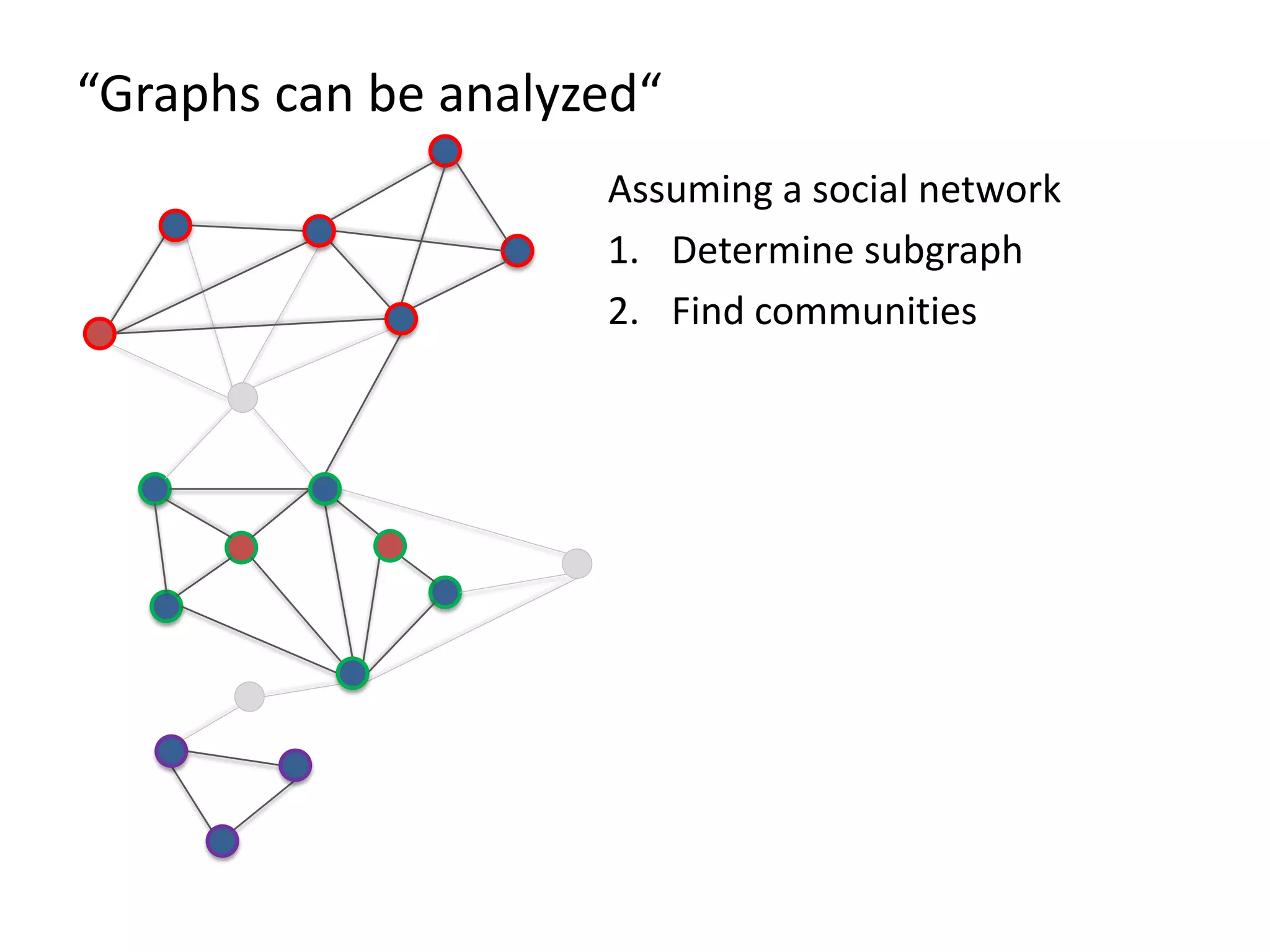
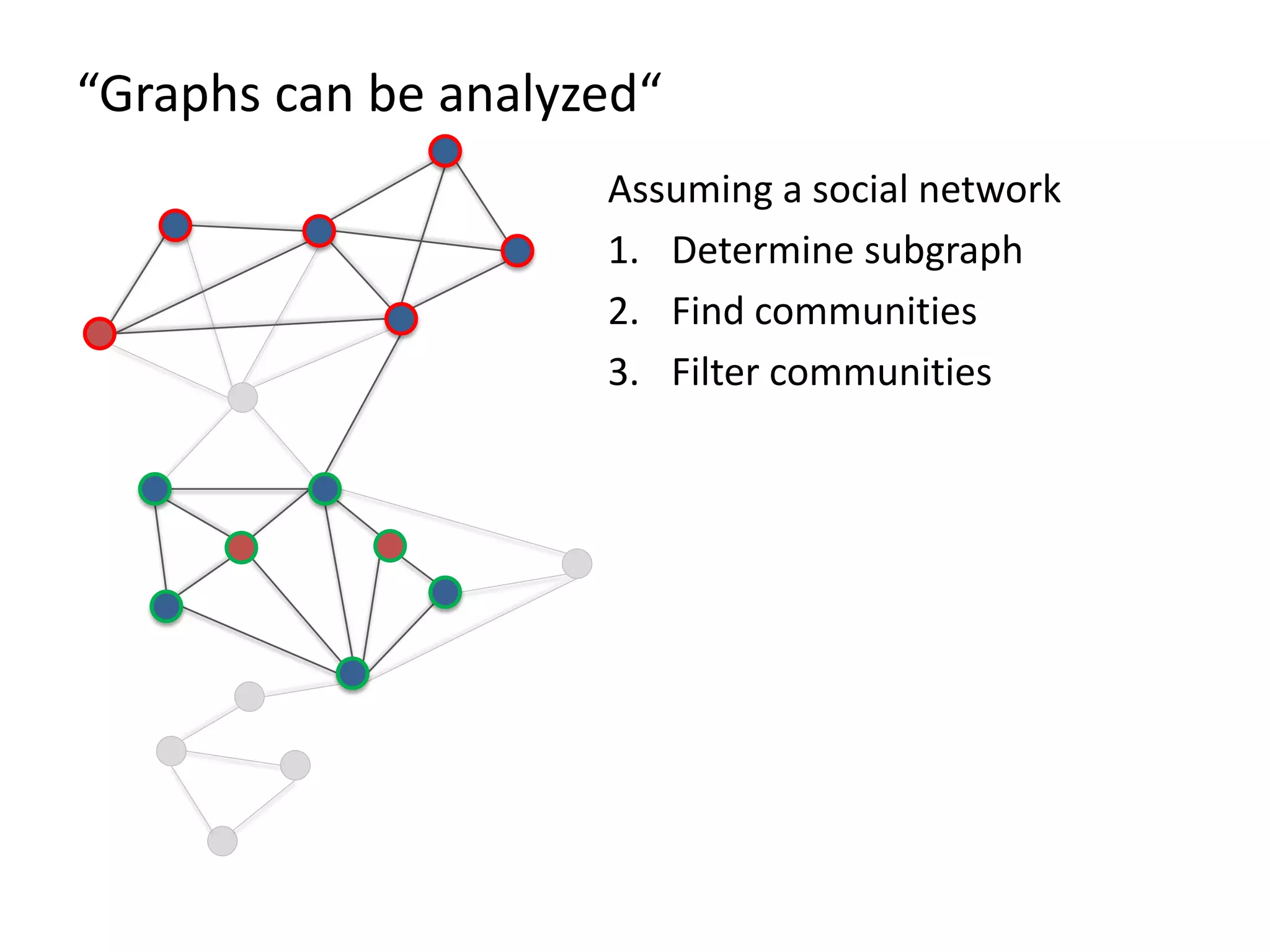
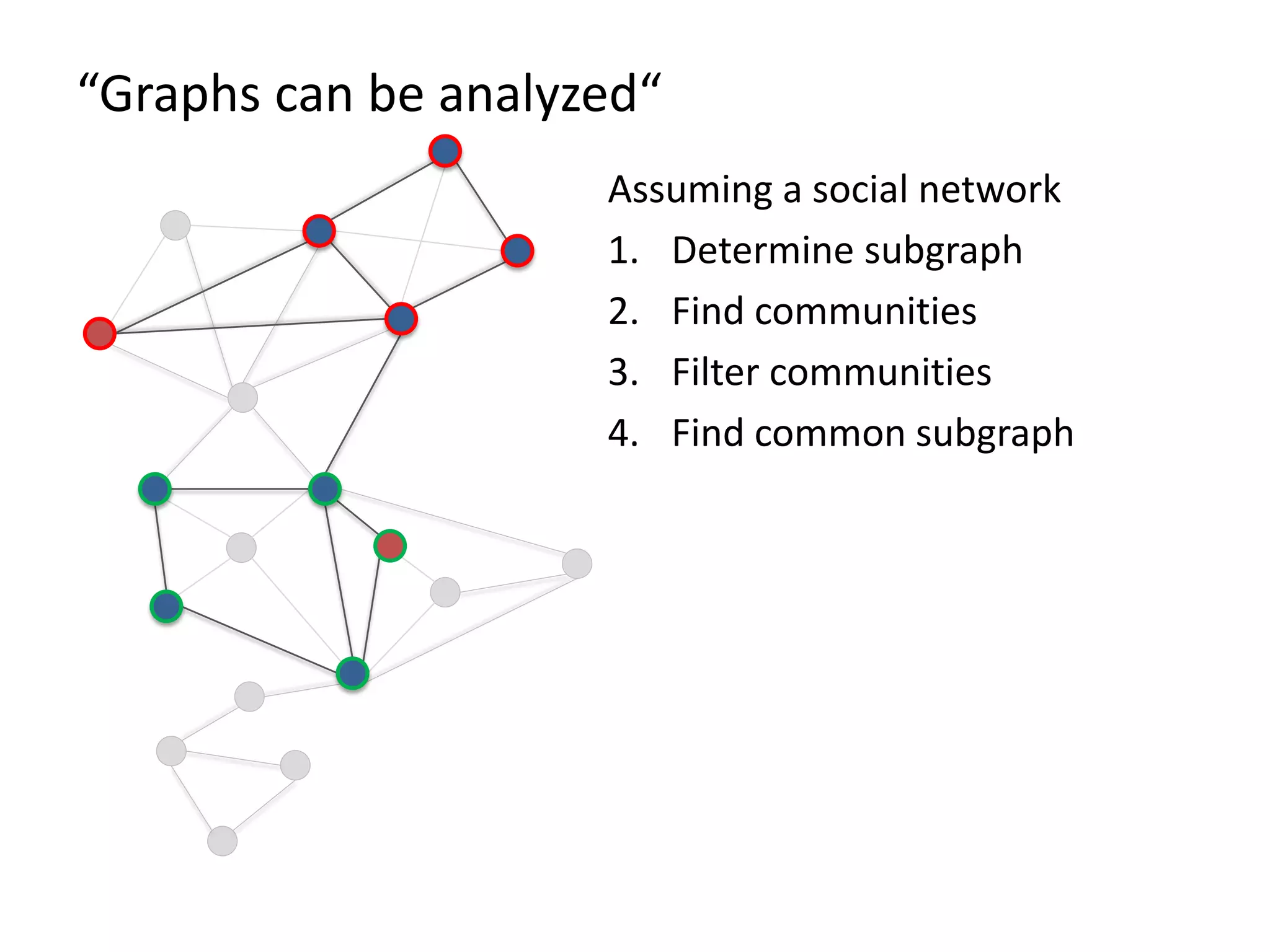
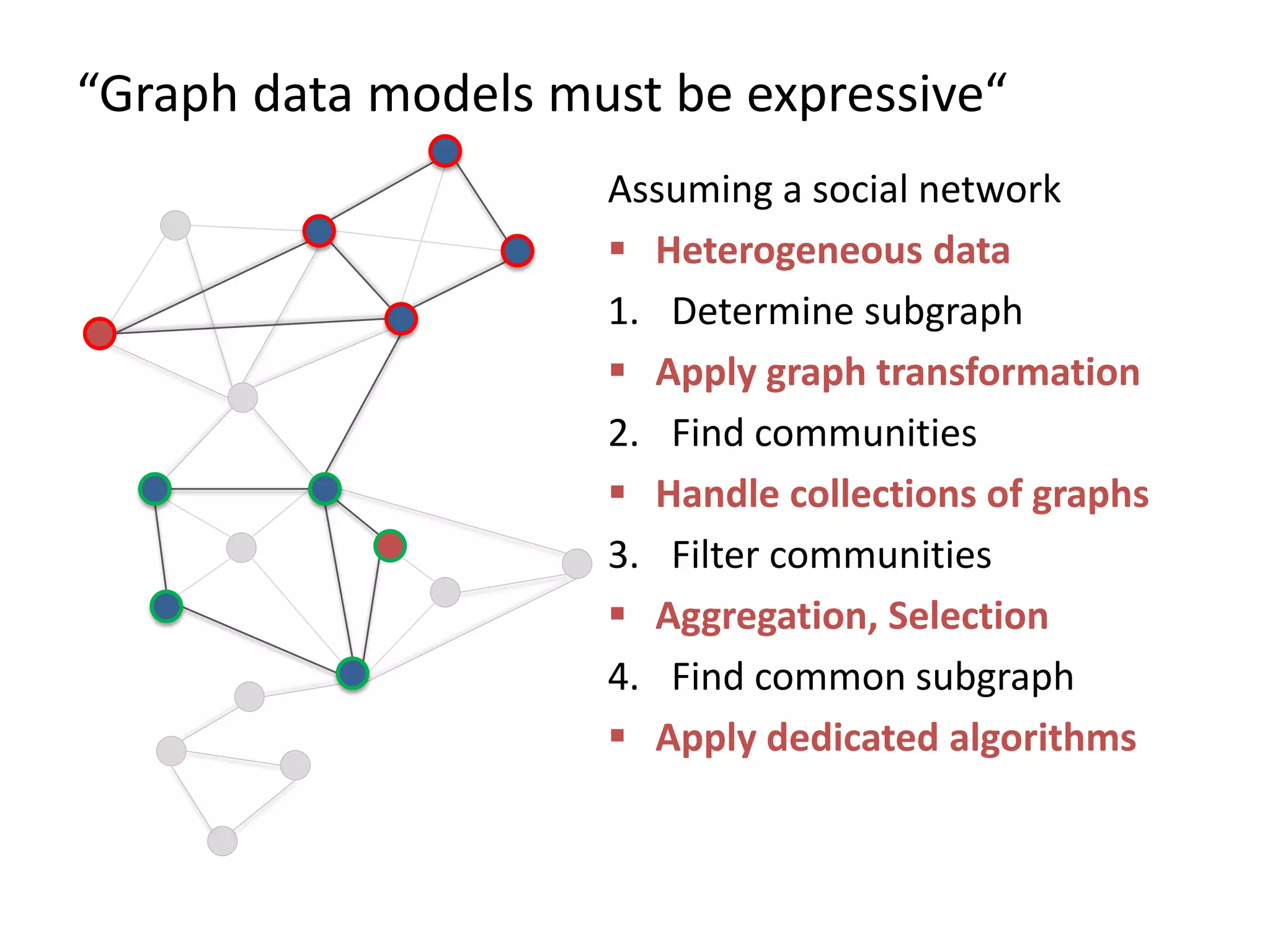
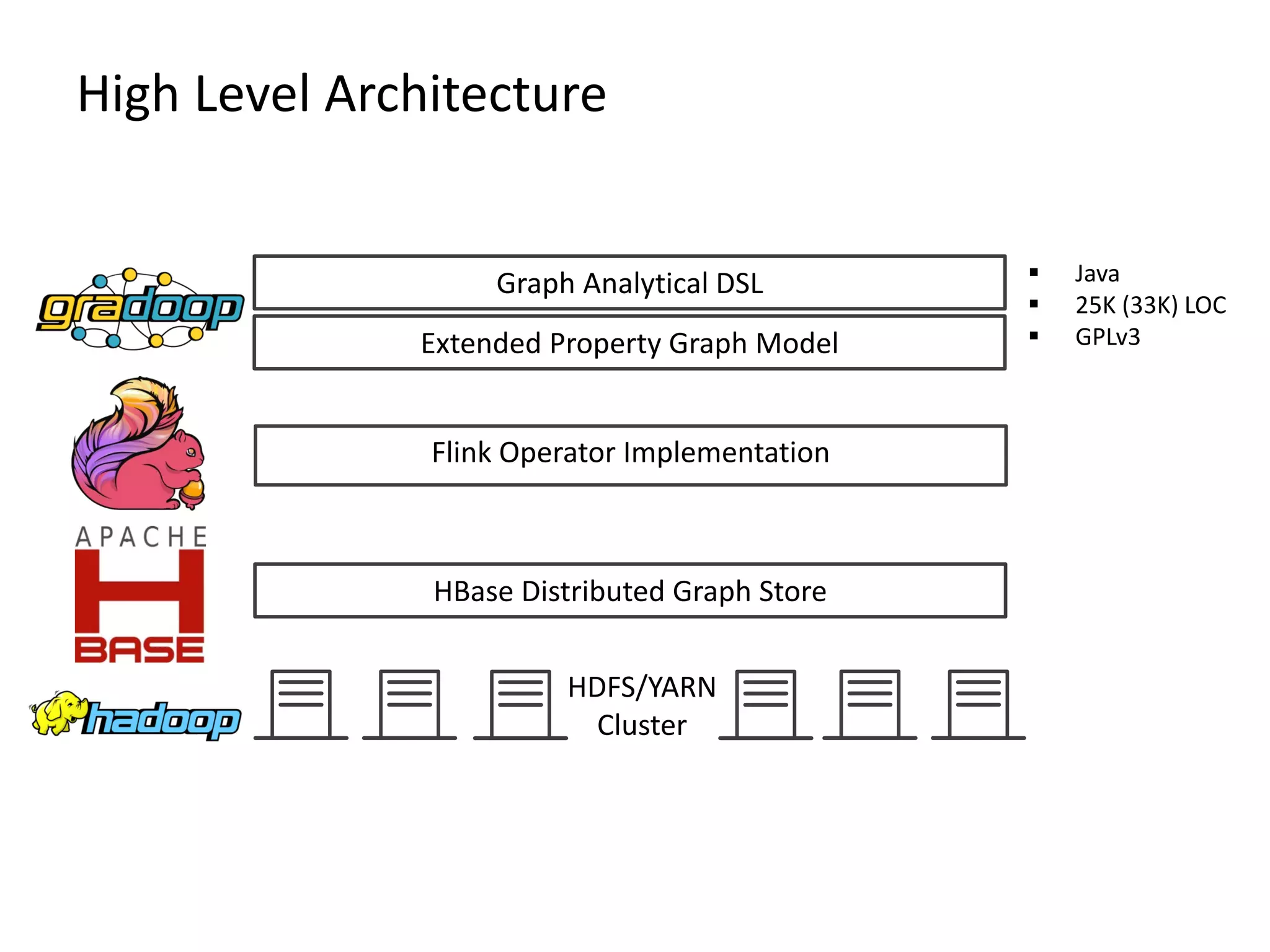
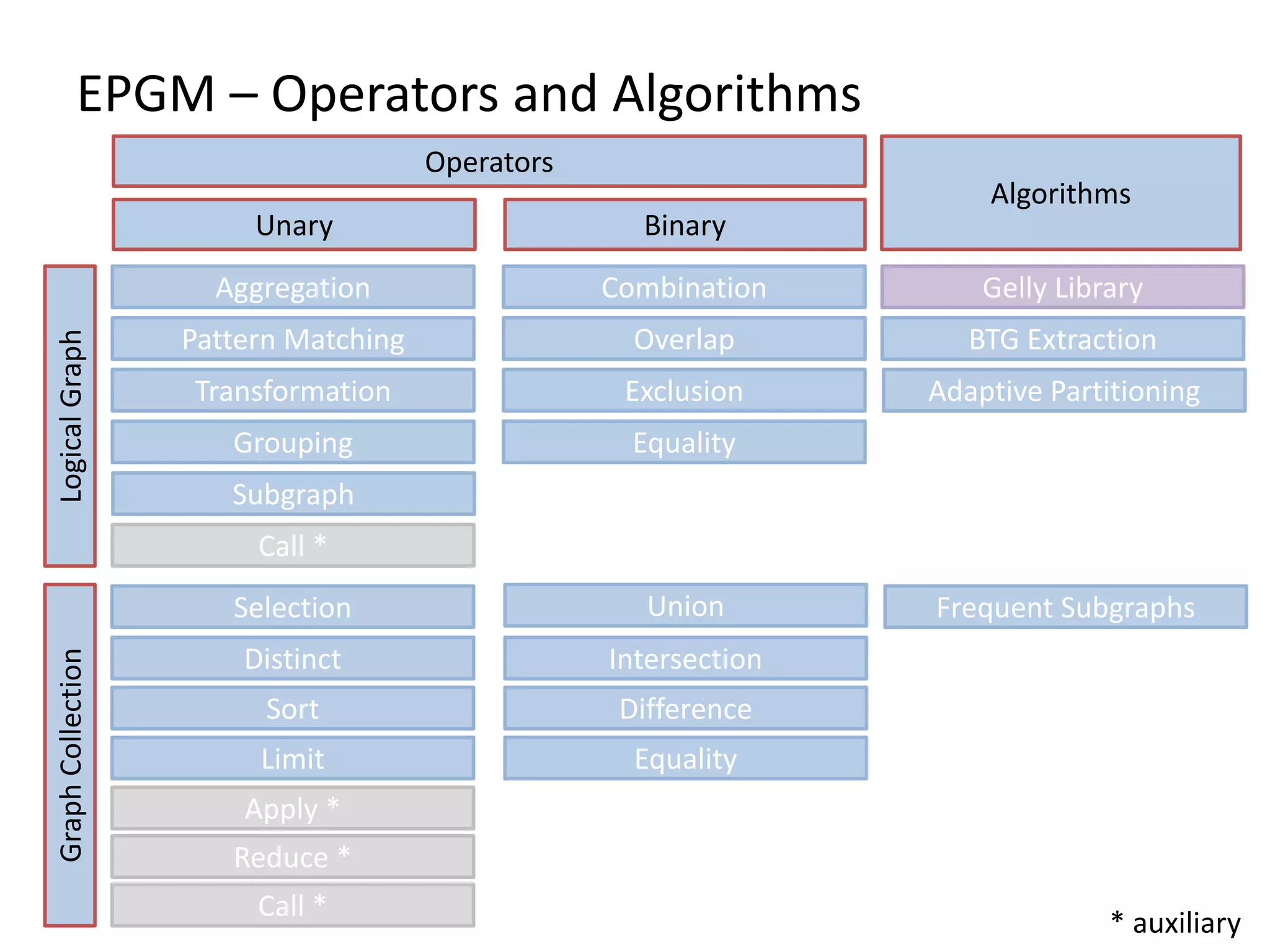
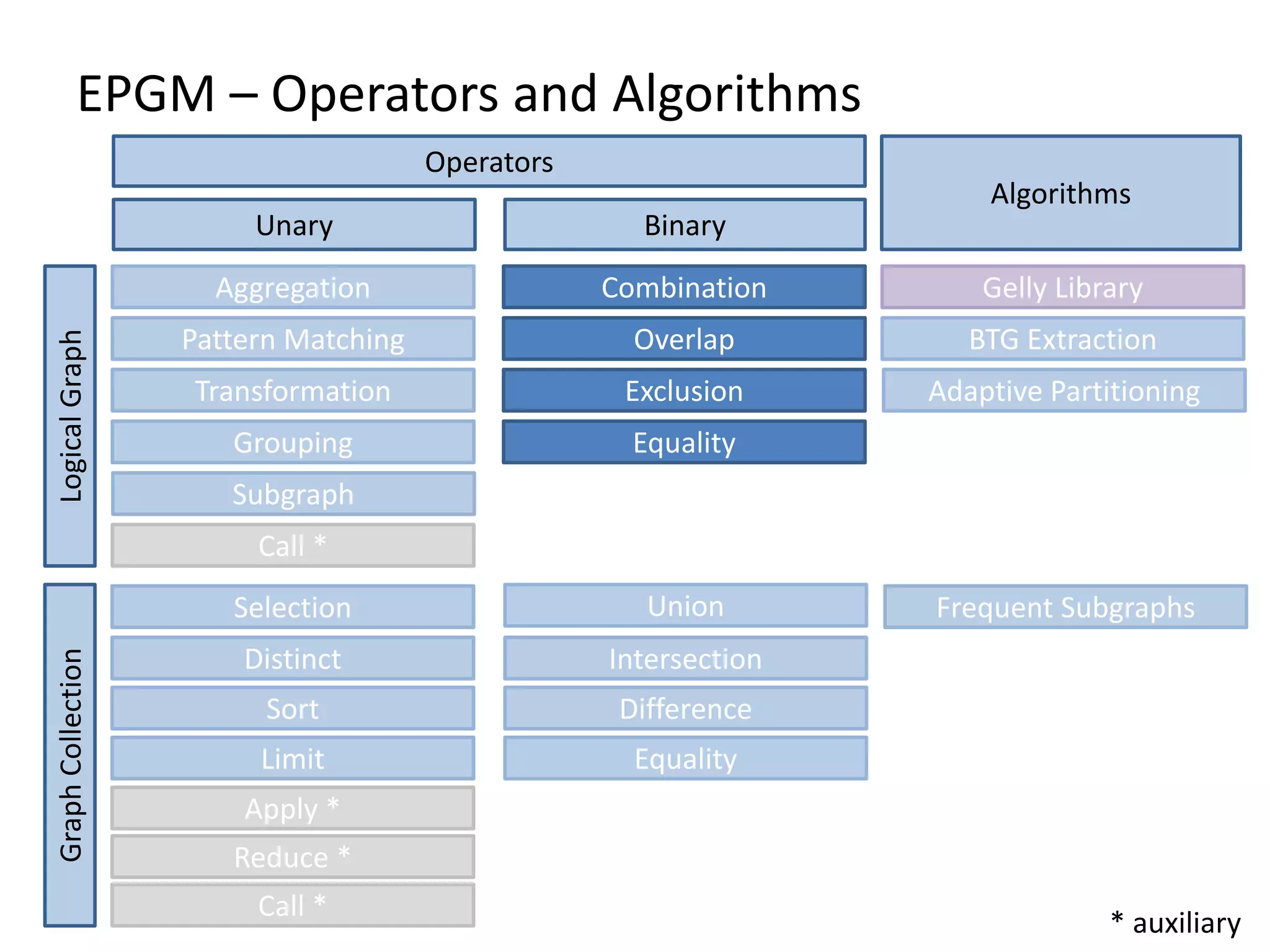
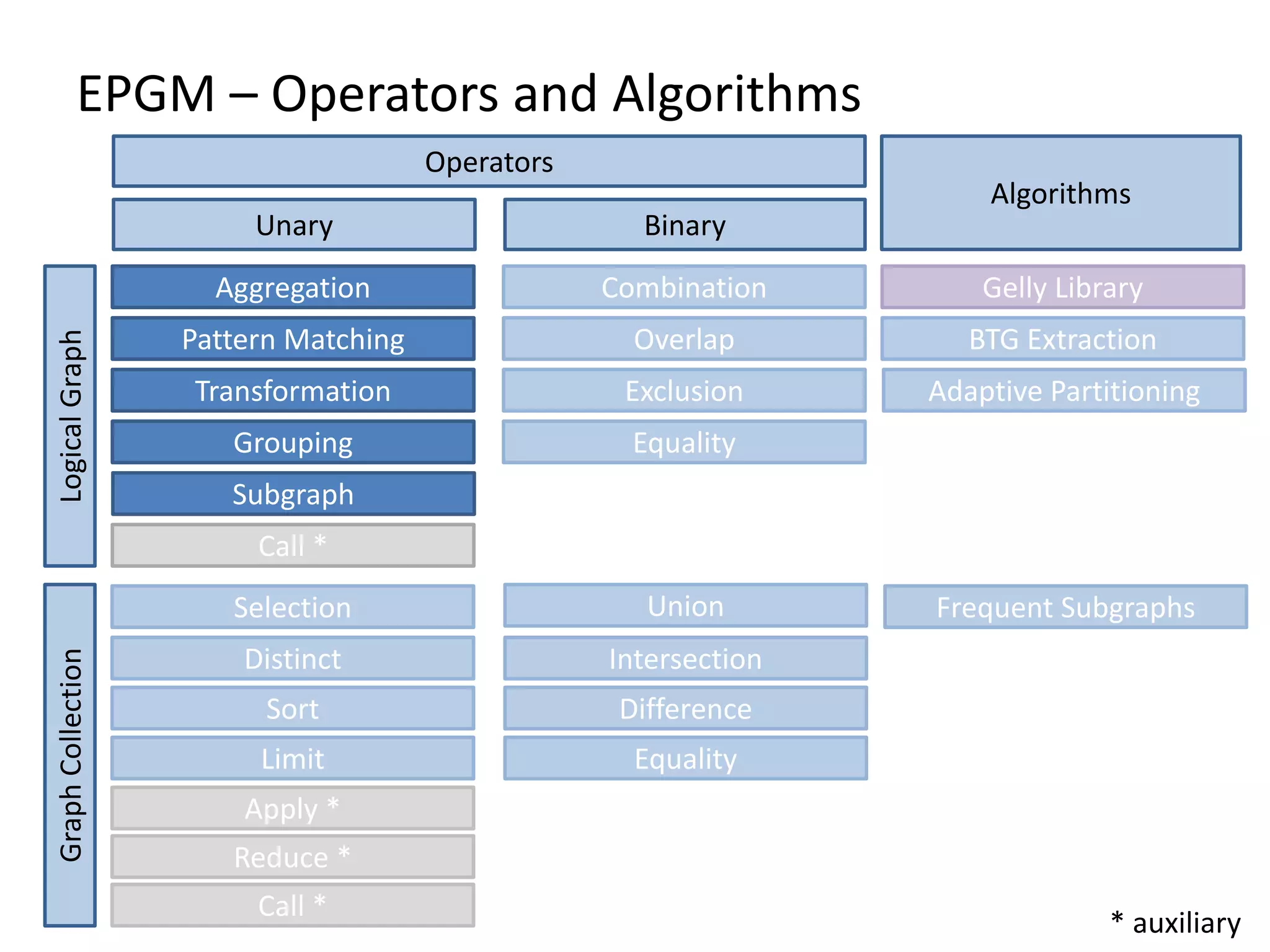
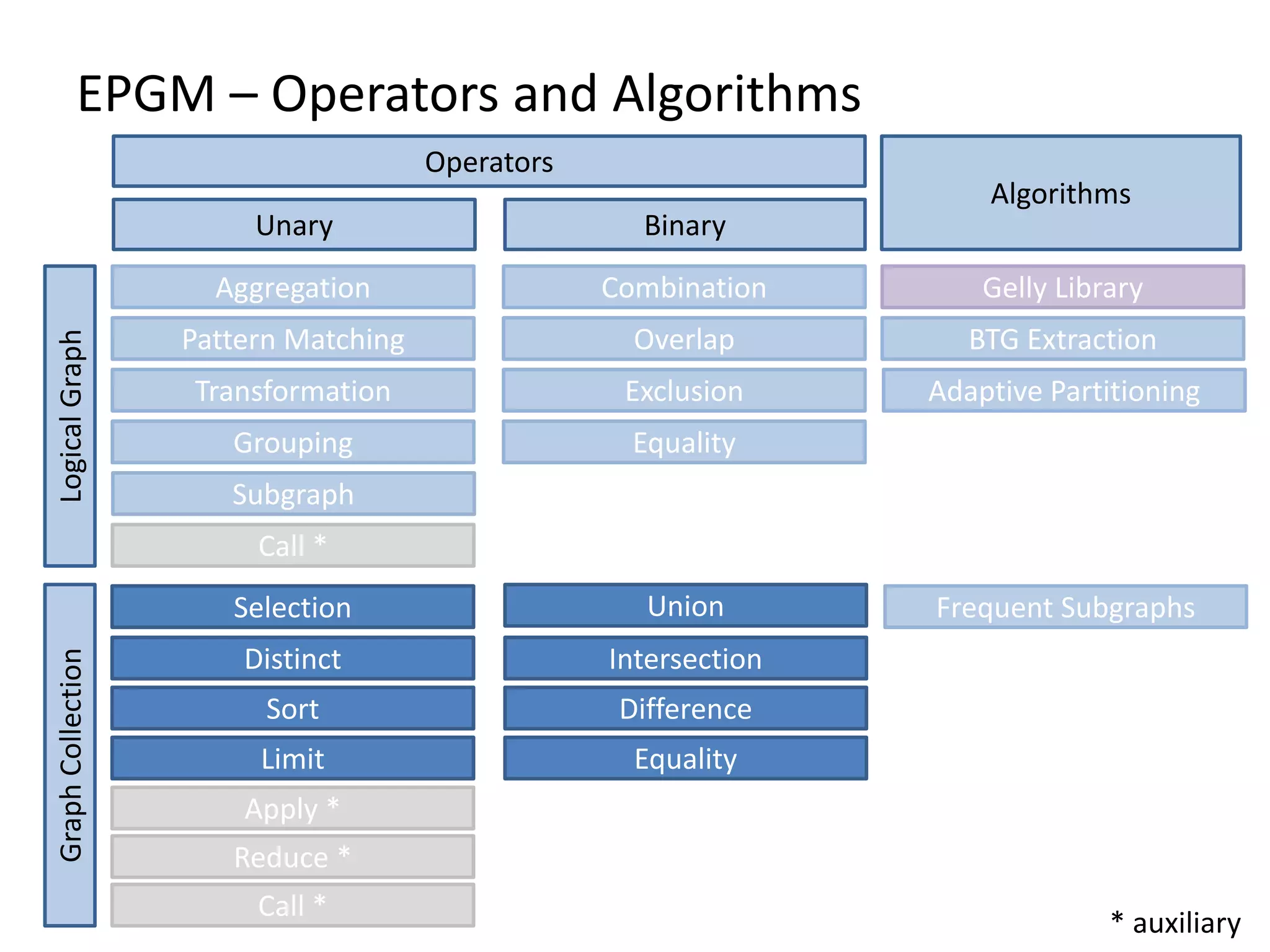
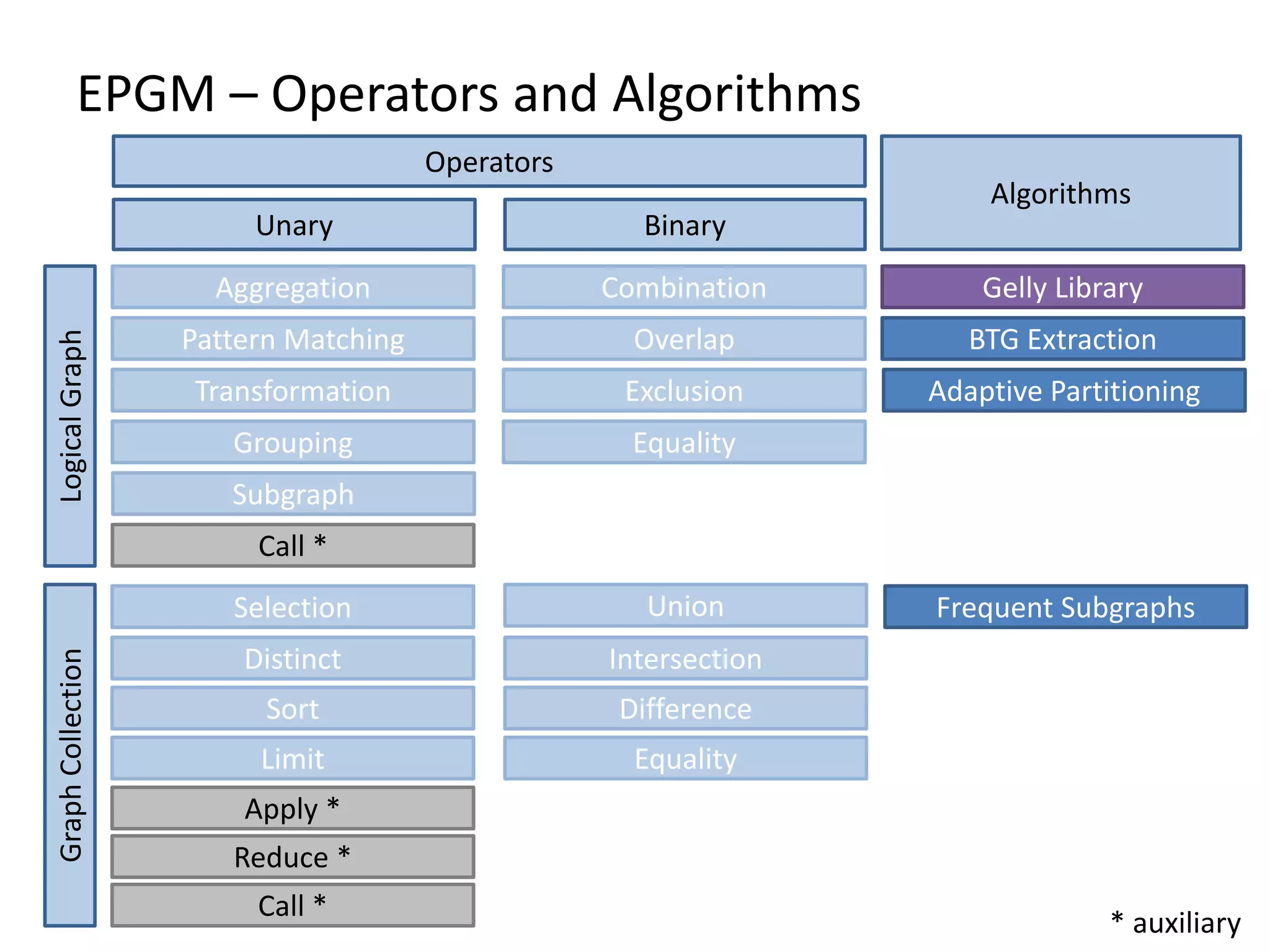
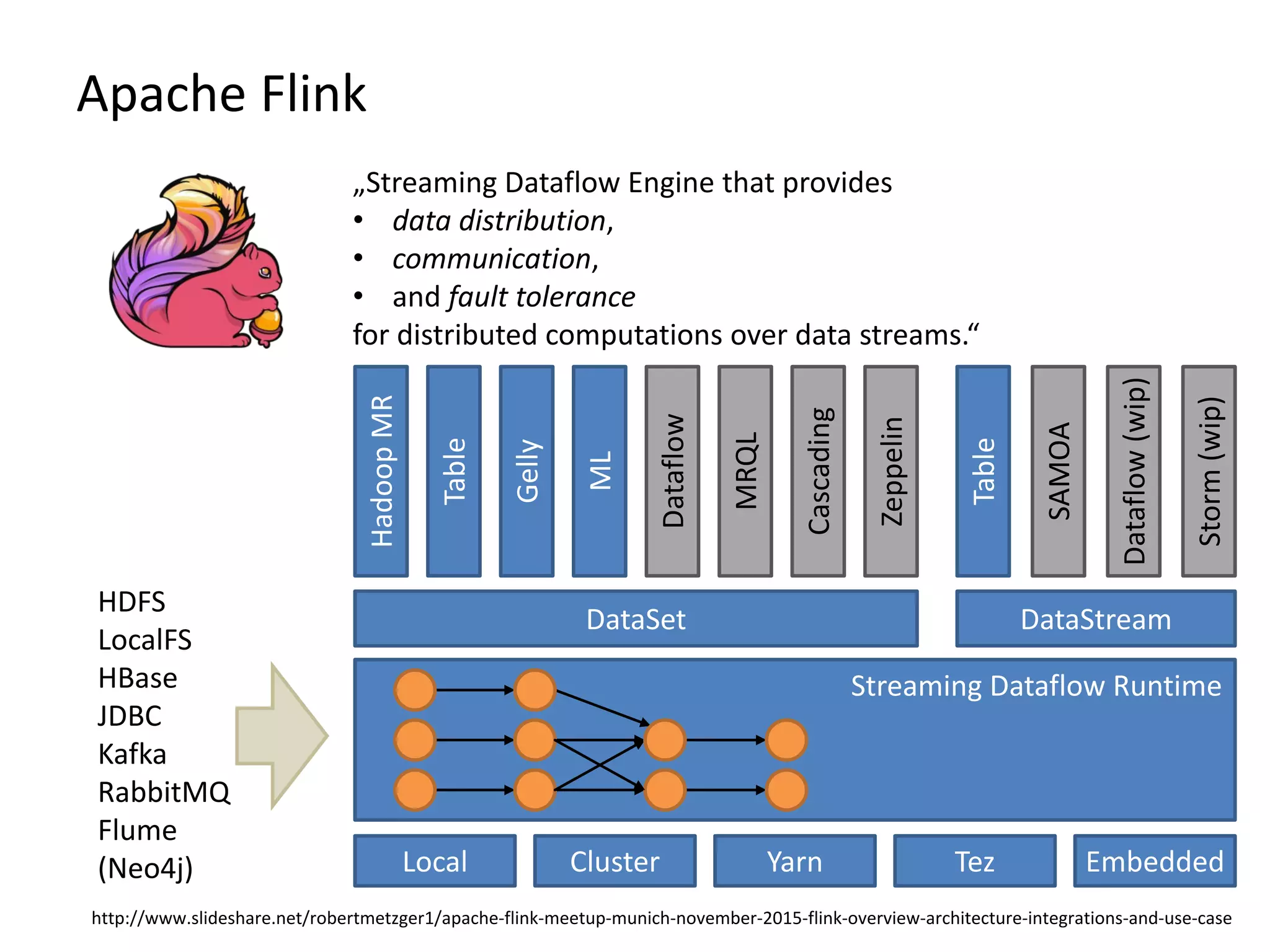
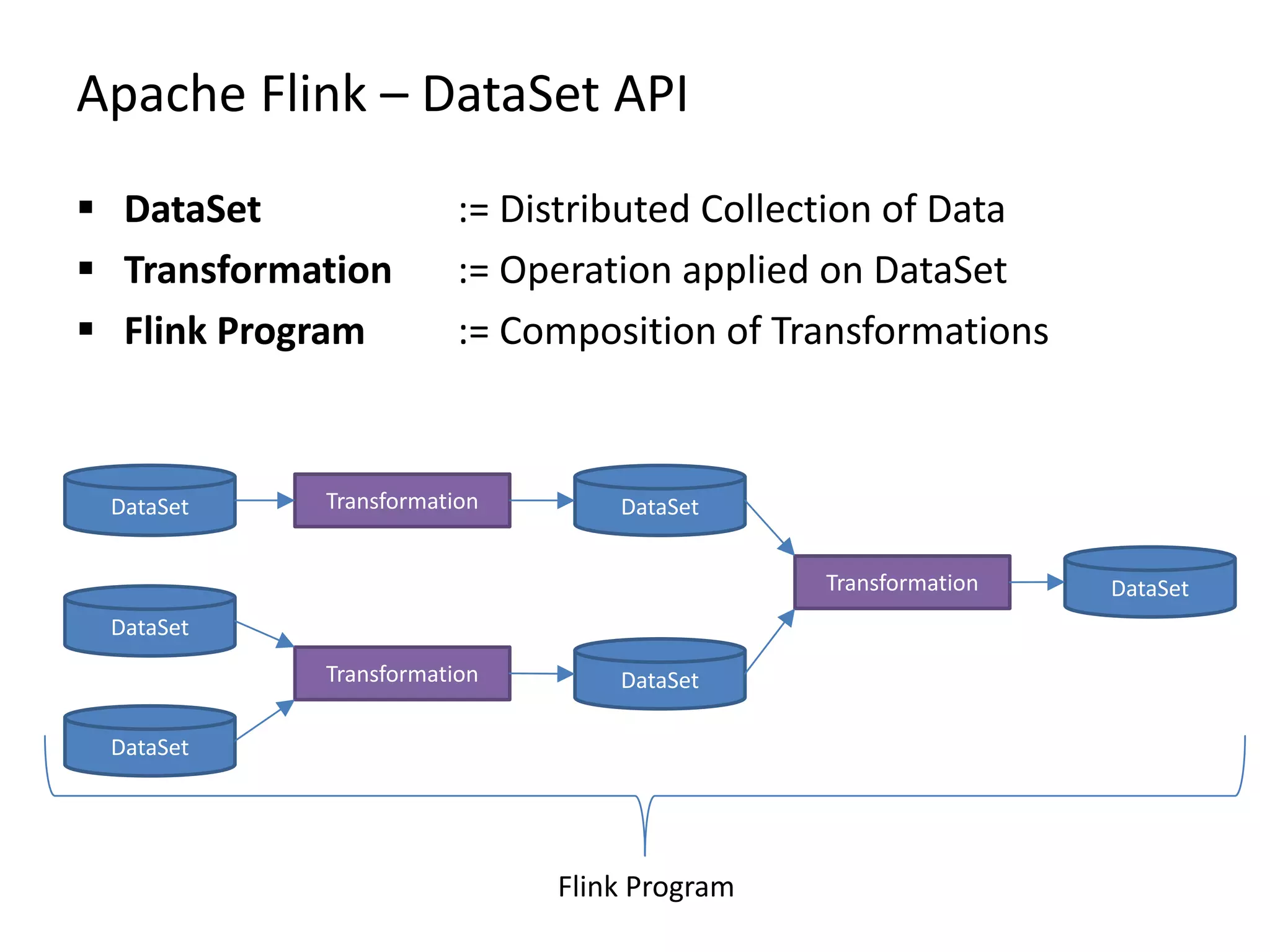
The document discusses Gradoop, a framework for scalable graph analytics using Apache Flink, developed by a team from Leipzig University. It highlights the framework's capabilities for distributed graph data management and its support for expressive graph data models. The document also elaborates on various operators and algorithms designed for graph analytics, including subgraph determination, community detection, and graph transformations.