Download as PDF, PPTX





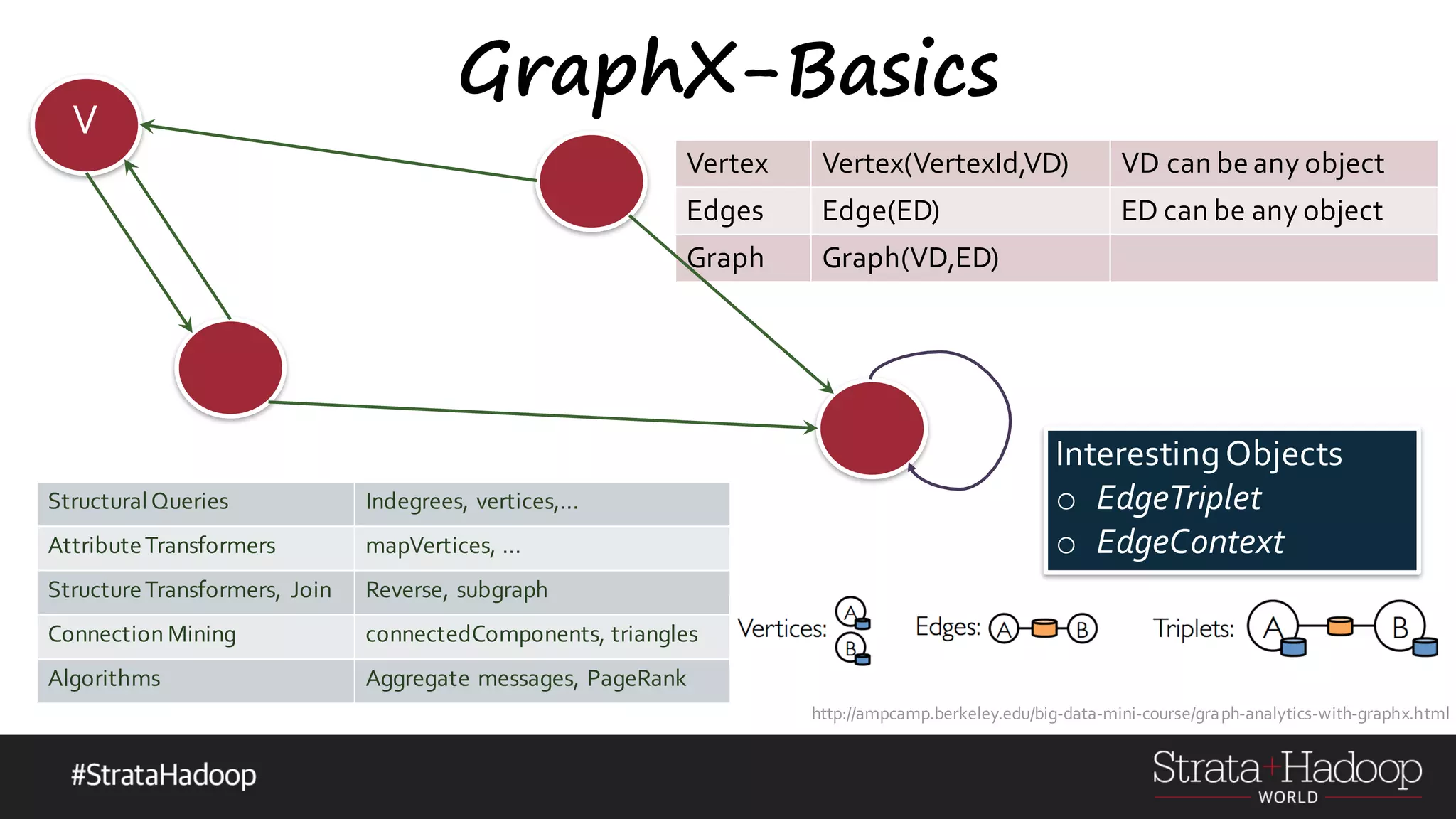
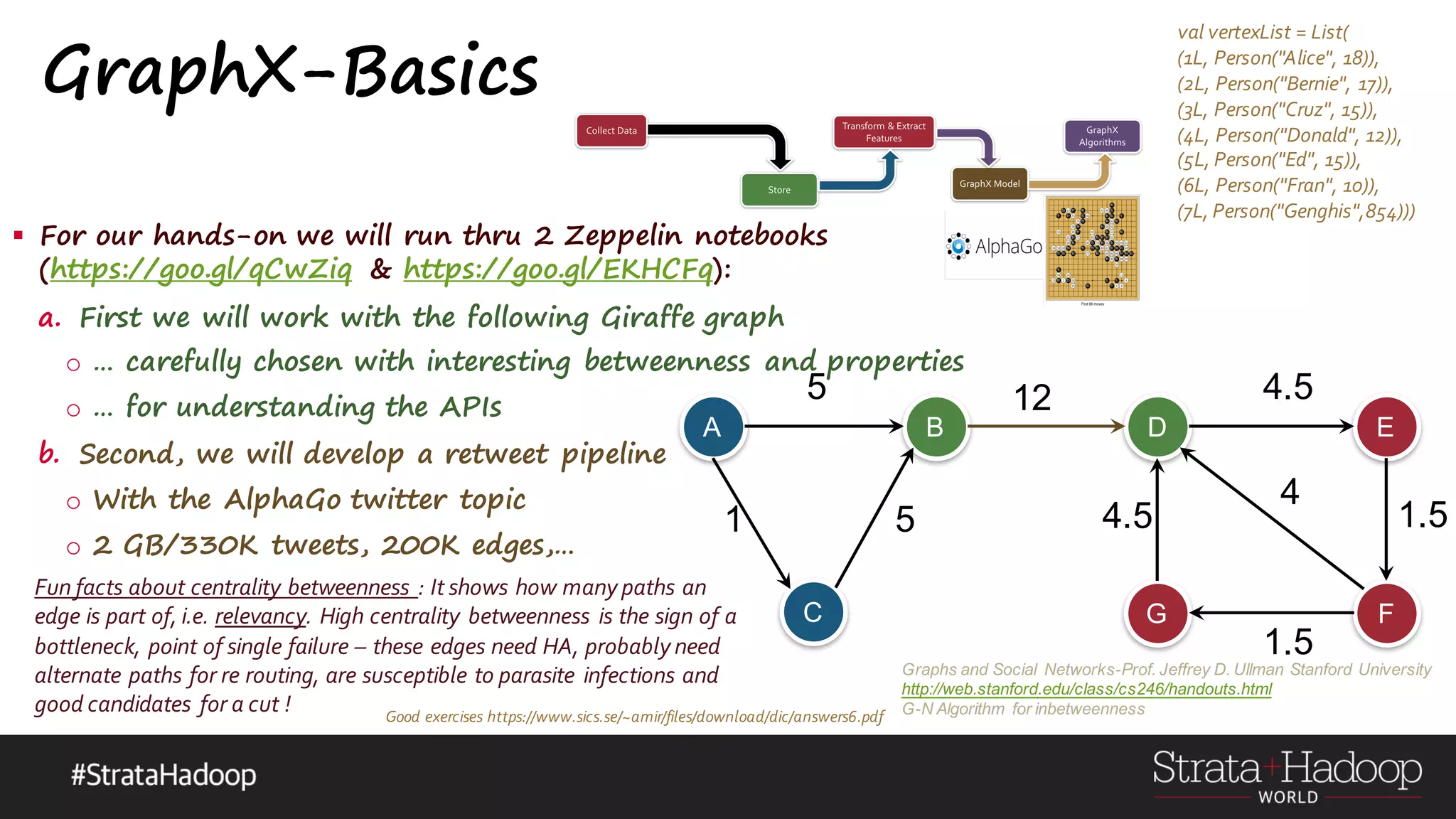
![GraphX-Basics o Computational Model o Directed MultiGraph o Directed - so in-degree & out-degree o MultiGraph – so multiple parallel edges between nodes including loops ! o Algorithms beware – can cyclic, loops o Property Graph o vertexID(64bit long) int o Need property, cannot ignore it o Vertex,Edge Parameterized over object types o Vertex[(VertexId,VD)], Edge[ED] o Attach user-defined objects to edges and vertices (ED/VD) Graphs and Social Networks-Prof. Jeffrey D. Ullman Stanford University http://web.stanford.edu/class/cs246/handouts.html G-N Algorithm for inbetweennessGood exercises https://www.sics.se/~amir/files/download/dic/answers6.pdf](https://image.slidesharecdn.com/graphx-15-160327192122/75/An-excursion-into-Graph-Analytics-with-Apache-Spark-GraphX-10-2048.jpg)
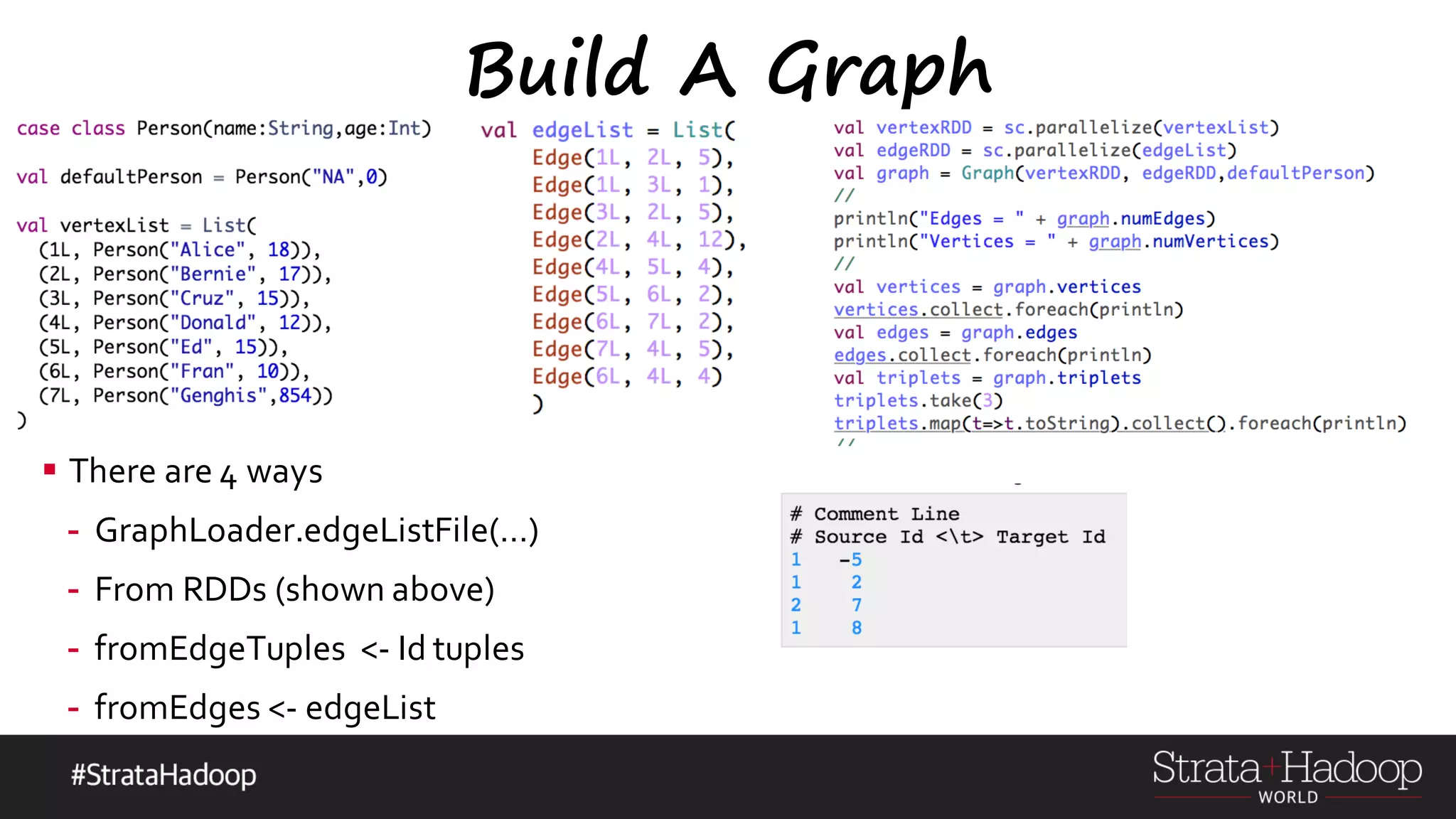


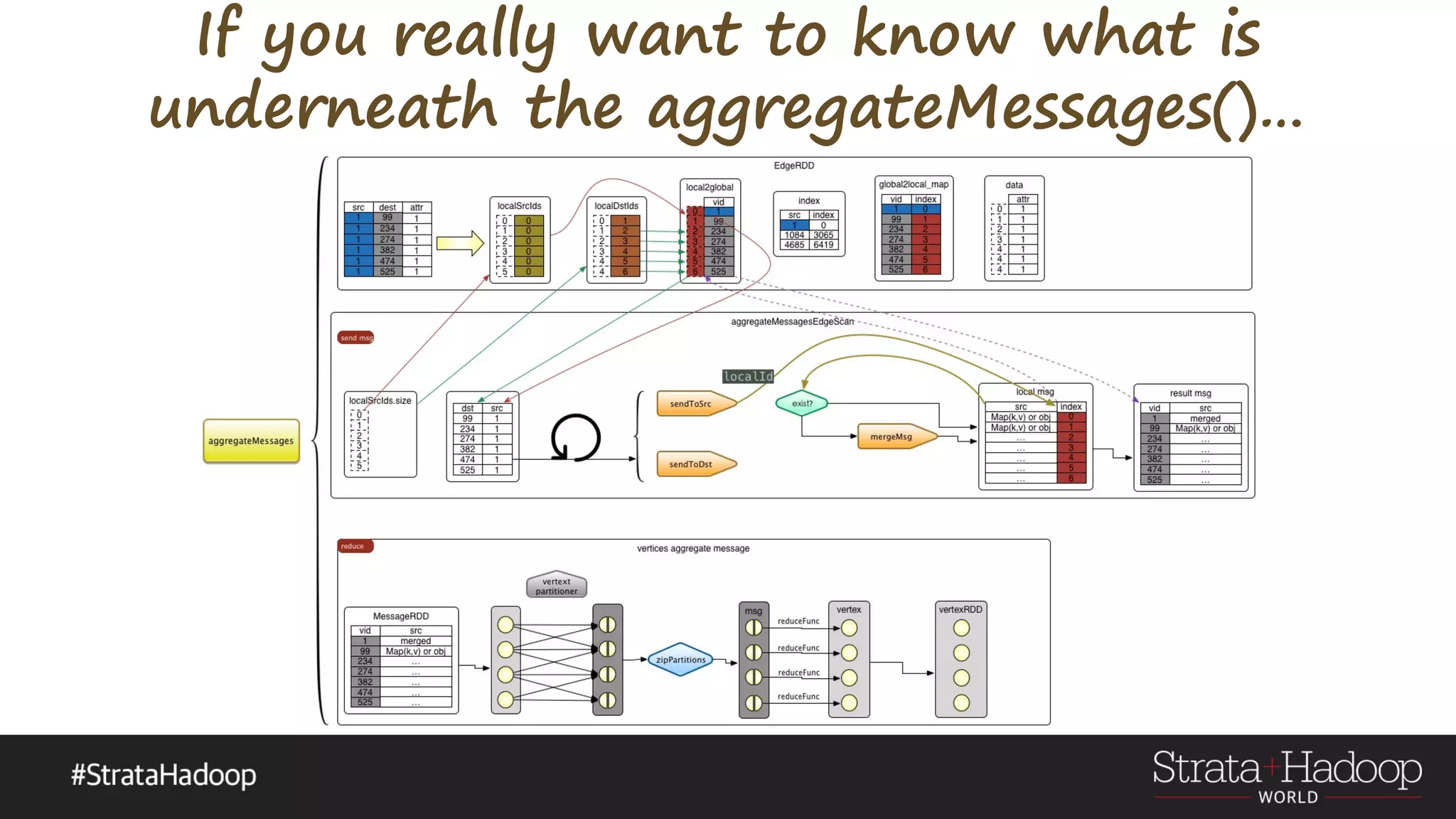
 => reduceFun)](https://image.slidesharecdn.com/graphx-15-160327192122/75/An-excursion-into-Graph-Analytics-with-Apache-Spark-GraphX-18-2048.jpg)





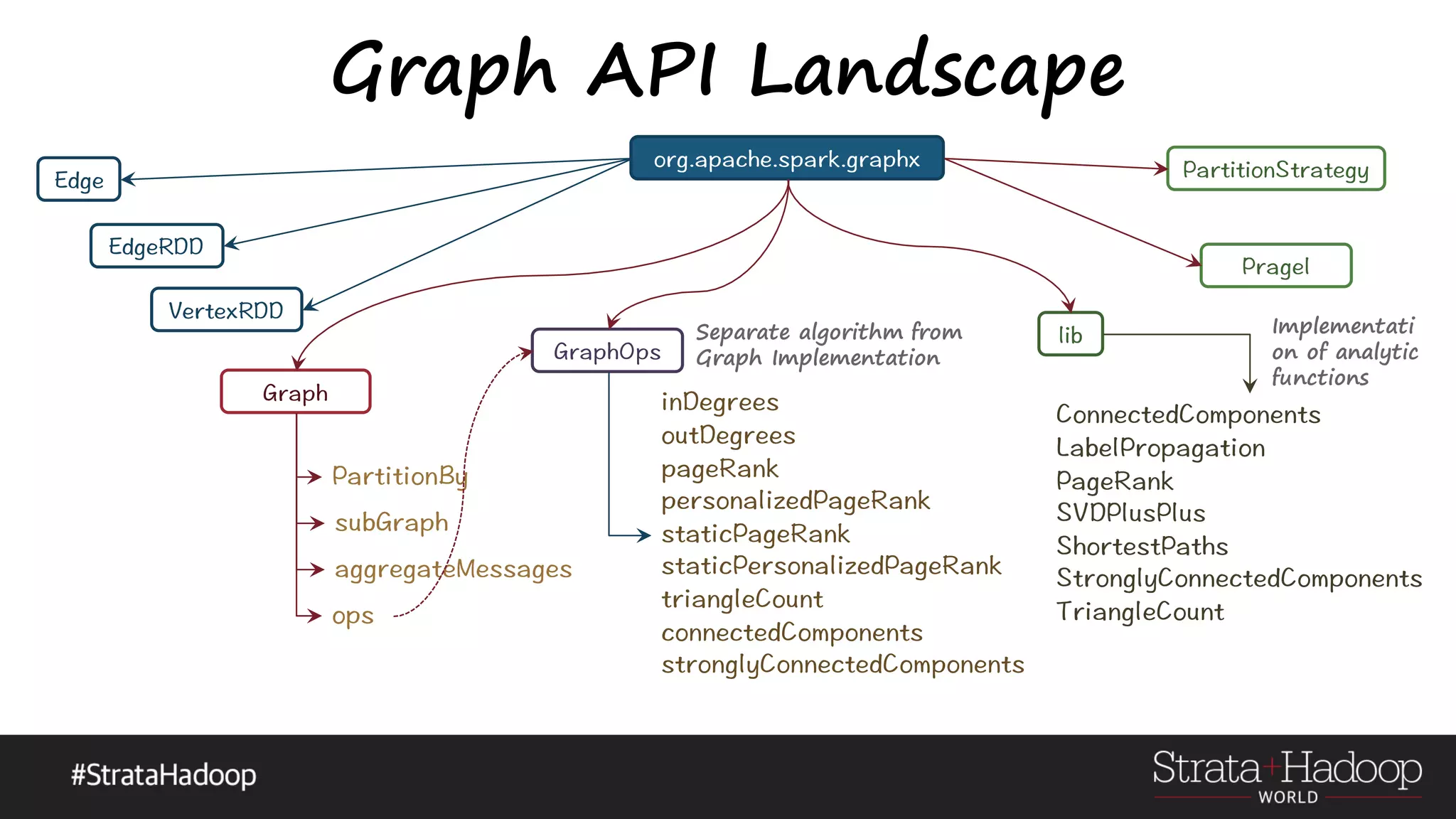
![The Art of an AlphaGo GraphX Vertex Vertex(VertexId,VD) VD can be any object Edges Edge(ED) ED can be any object Graph Graph(VD,ED) [(VertexId , VD)] [(VertexId, VertexId, [(VertexId, VD)]ED)] Vertex VertexEdge](https://image.slidesharecdn.com/graphx-15-160327192122/75/An-excursion-into-Graph-Analytics-with-Apache-Spark-GraphX-29-2048.jpg)
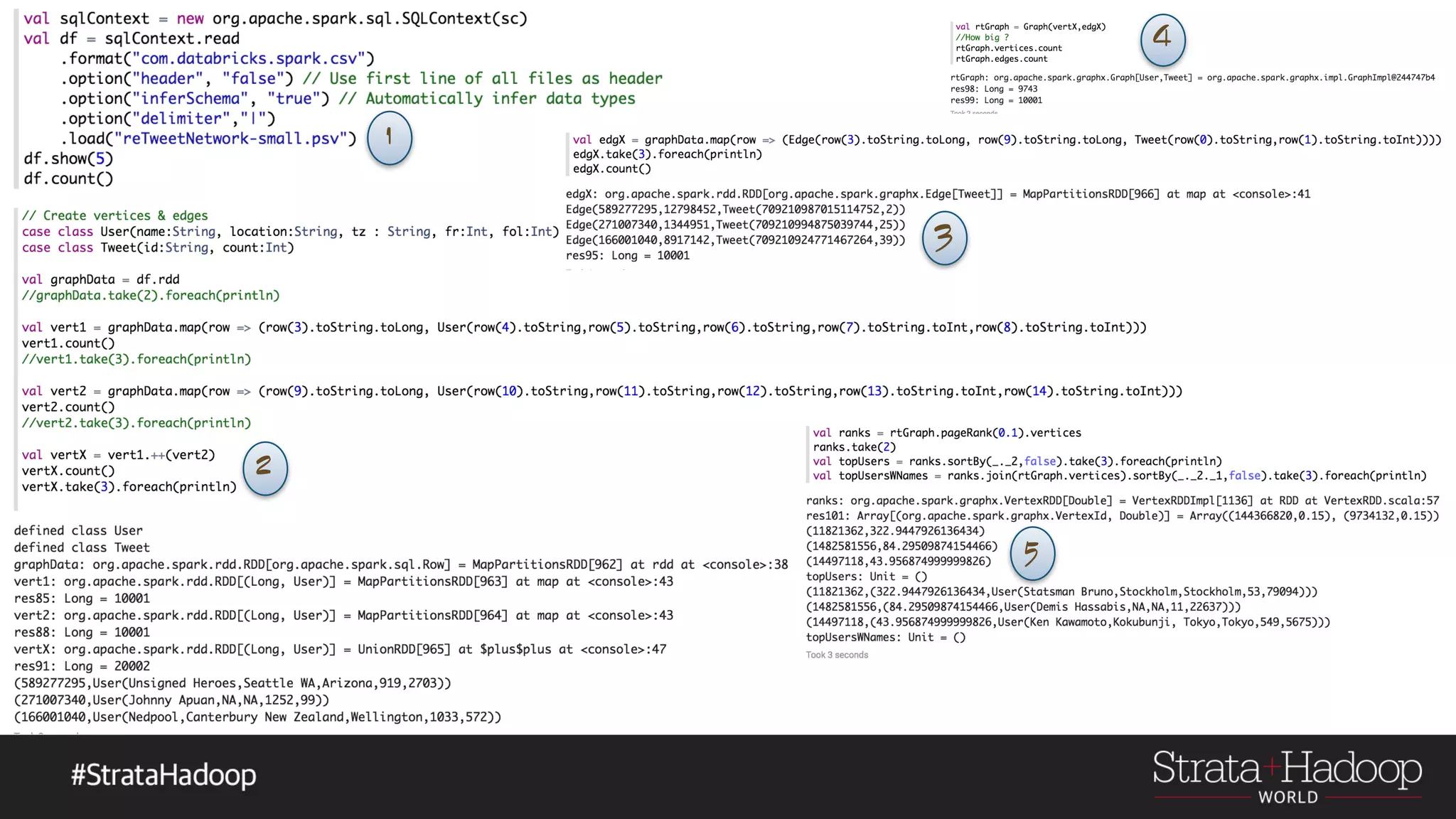


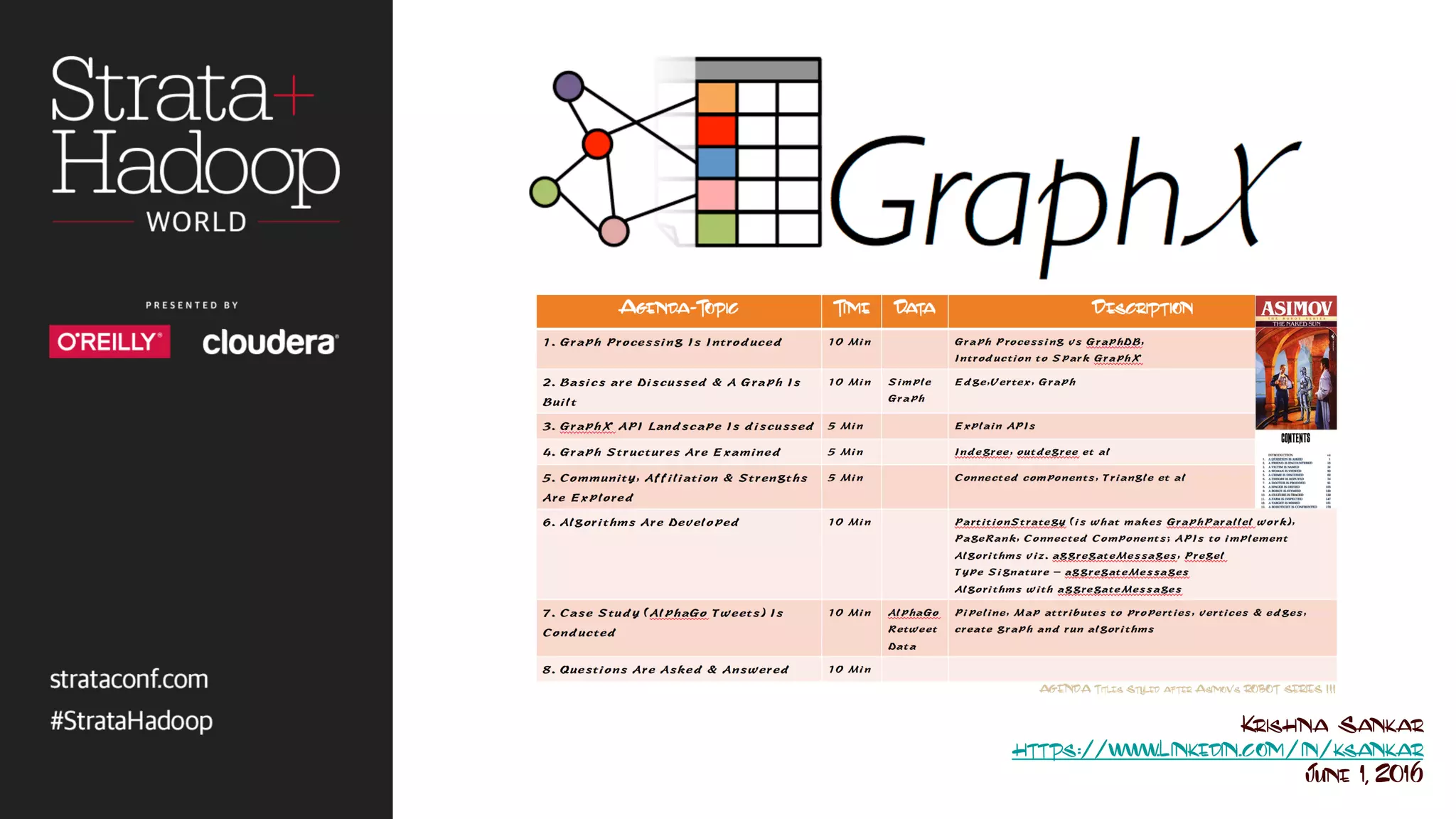
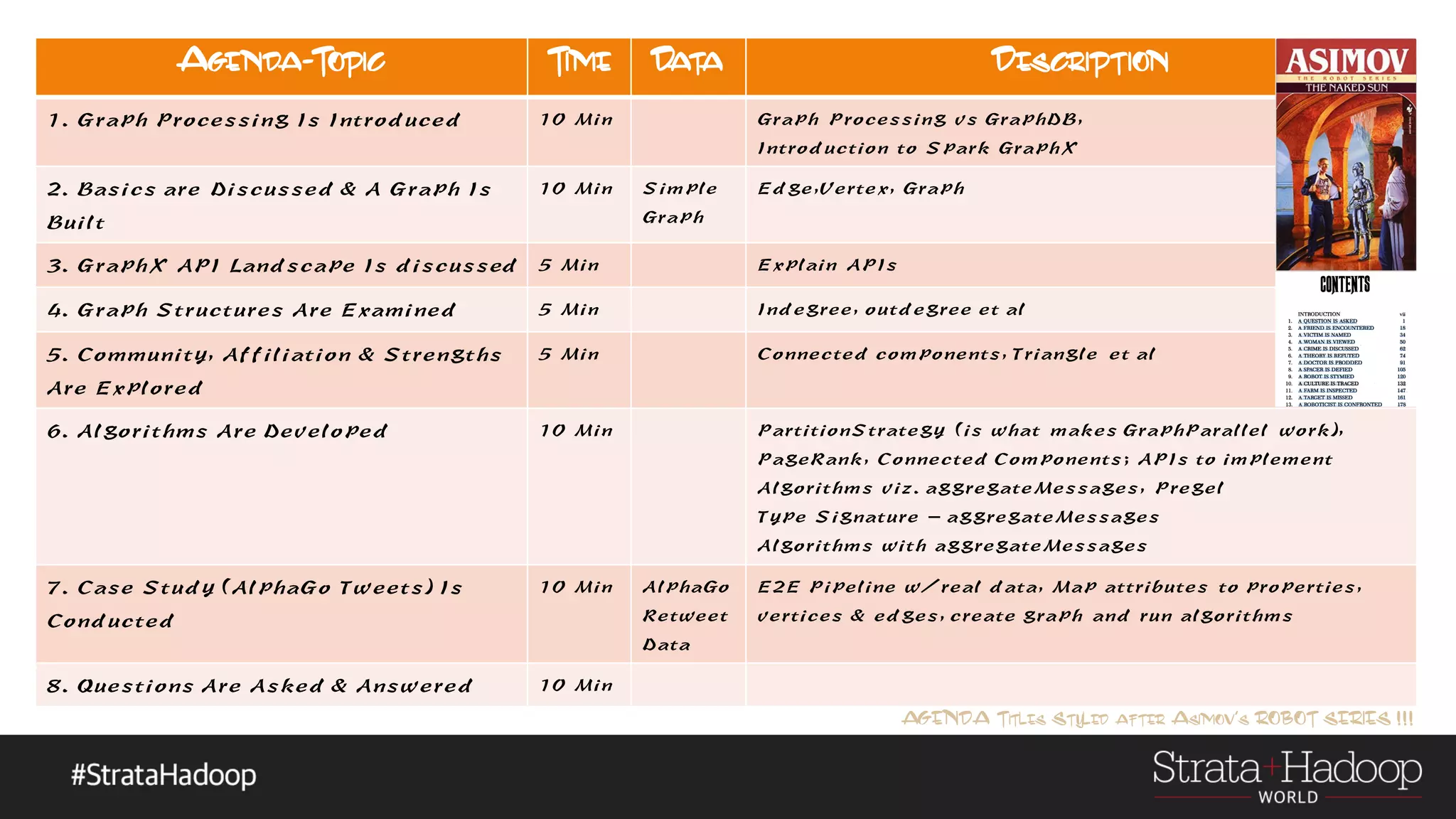
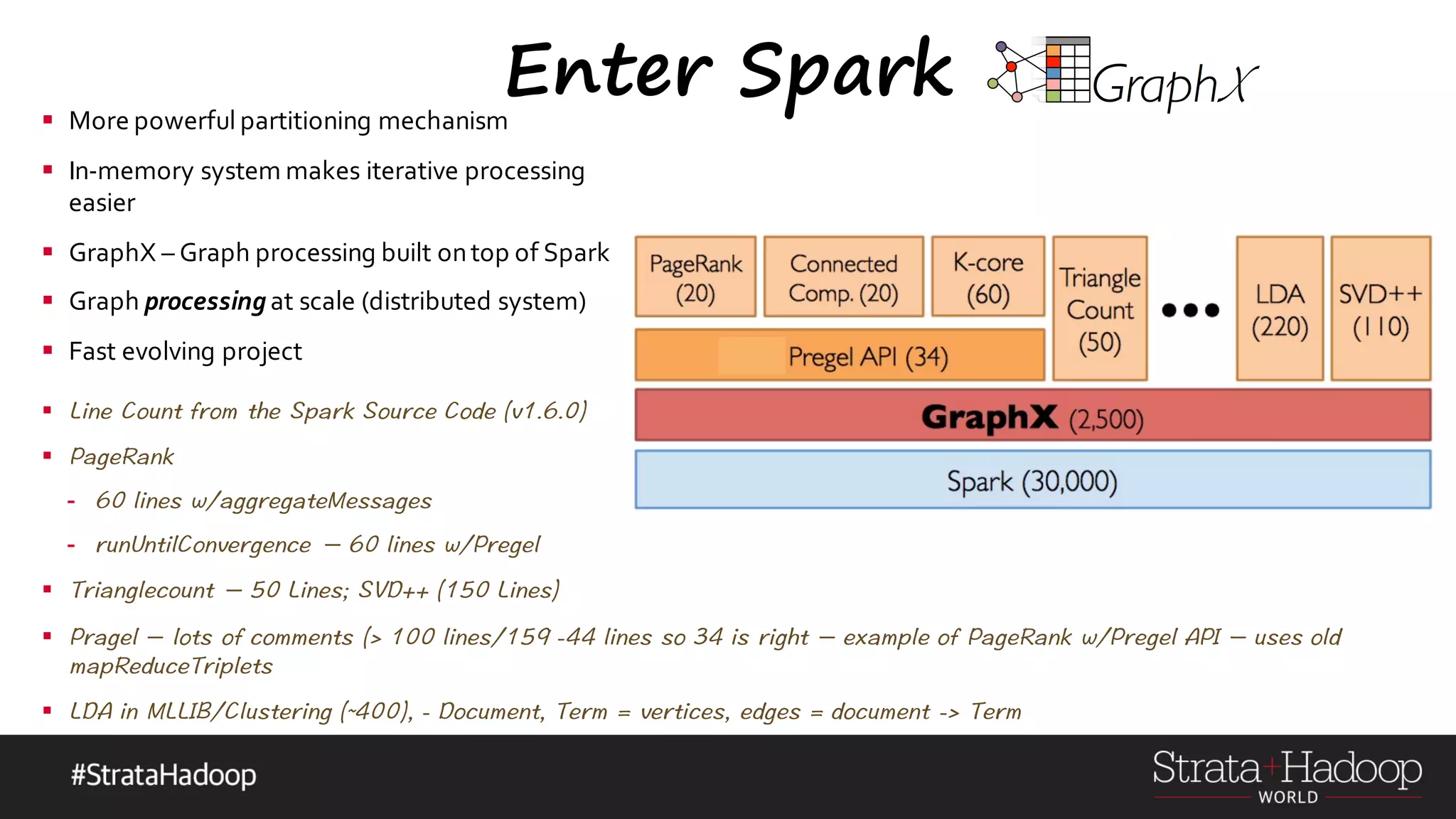
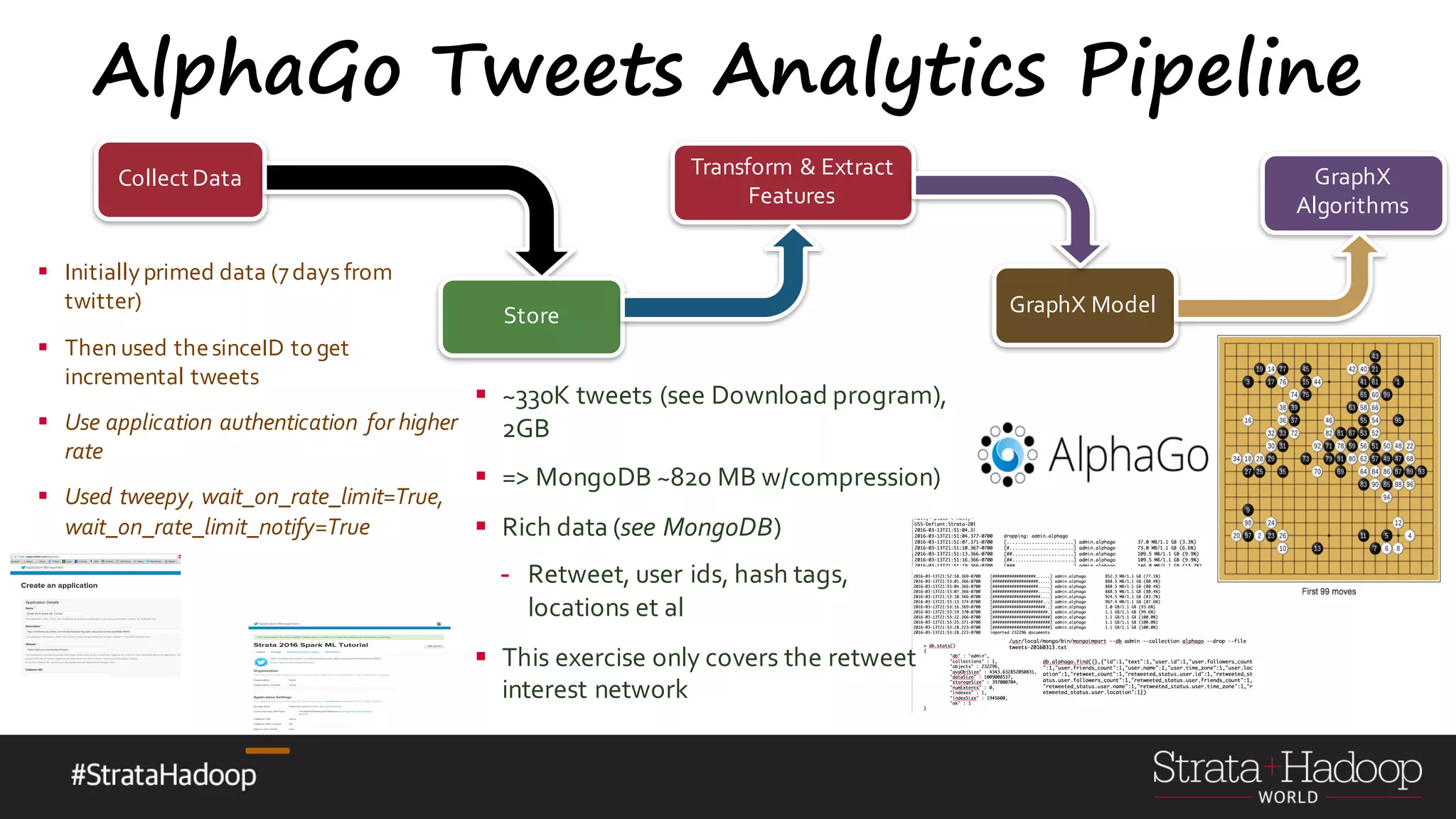
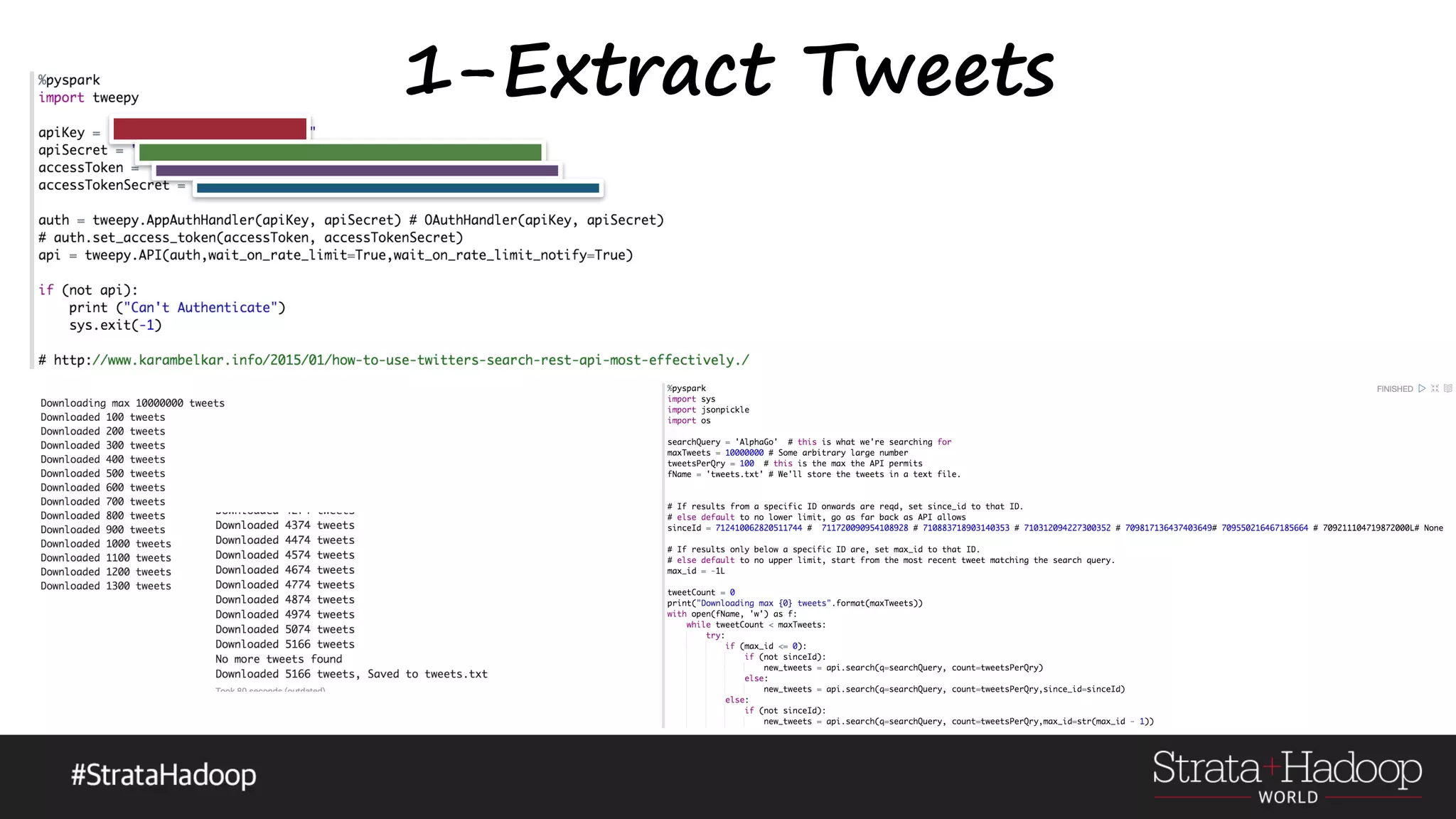
The document discusses the use of Apache Spark's GraphX for graph processing, outlining its API landscape, algorithms, and real-world applications. It includes a tutorial agenda covering topics such as graph structures, community analysis, and case studies like the AlphaGo tweet analysis. Additionally, it highlights various graph processing frameworks and partitioning strategies to efficiently manage large datasets.