Downloaded 1,303 times



























![Lucene: Querying • Parse a Lucene query define fields String[] fields = new String[3]; fields[0] = “title”; fields[1] = “body”; fields[2] = “tags”; Query q = new MultiFieldQueryParser(fields, new StandardAnalyzer()).parse(‘performance’); • Execute the query parse search query Searcher s = new IndexSearcher(indexName); Hits h = s.search(q); time: 80 milliseconds](https://image.slidesharecdn.com/fulltextsearchinpostgresql-091103175457-phpapp02/75/Full-Text-Search-In-PostgreSQL-29-2048.jpg)

















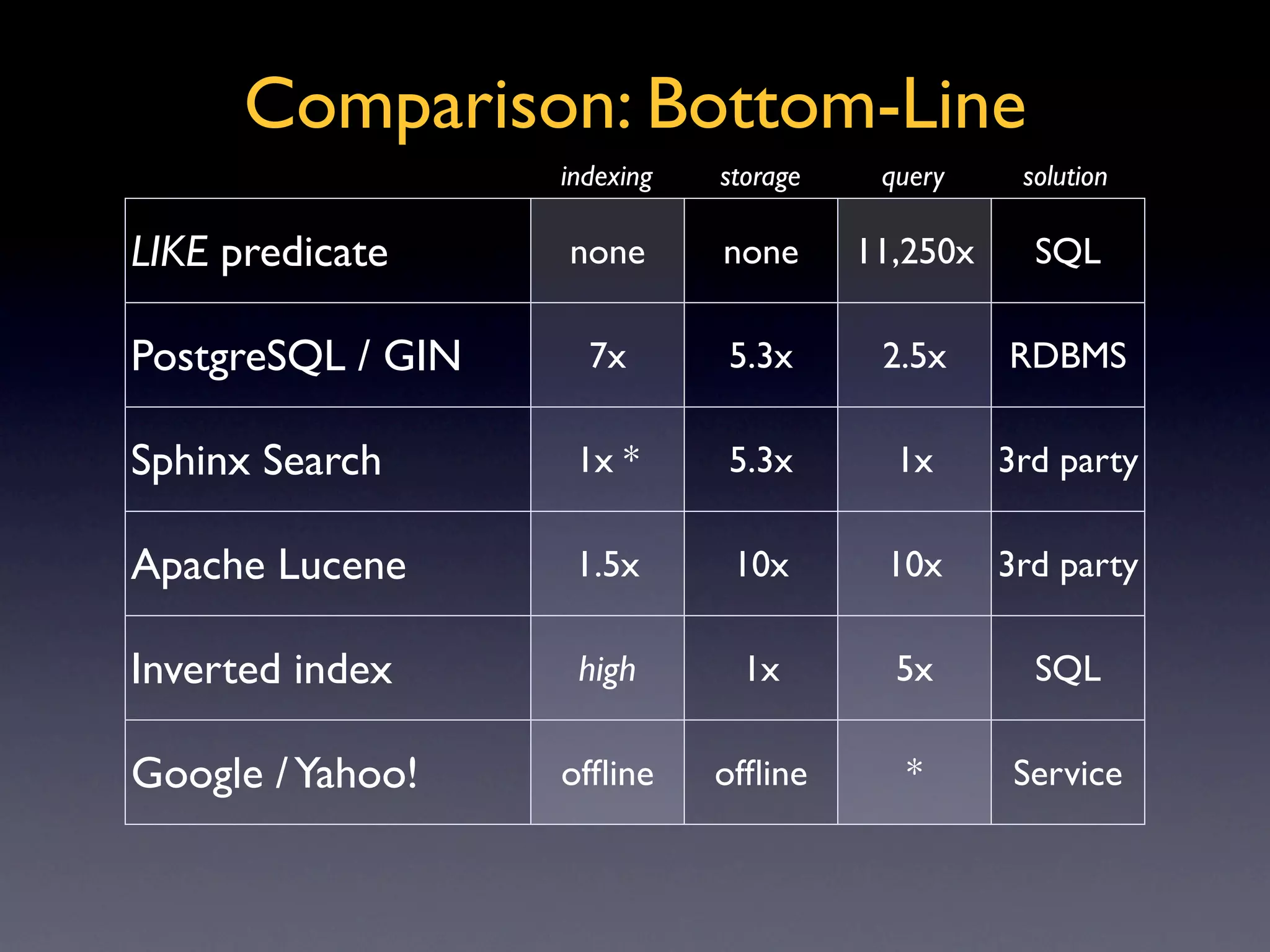


The document discusses practical full-text search solutions in PostgreSQL, highlighting various methods including with and without indexing using systems like Sphinx and Apache Lucene. It contrasts the performance of different search methods, emphasizing the importance of appropriate indexing for efficiency and accuracy in querying large datasets. The document concludes with a comparison of indexing speeds and storage requirements across different systems, providing insights into the best practices for full-text search implementation.
Overview of full-text search capabilities in PostgreSQL by Bill Karwin, highlighting experience and background.
Explains the importance of full-text search in web applications and sets the context for comparing five search solutions.
Introduction to sample data with 1.2 million tuples from StackOverflow posts to be used in search comparisons.
Discusses the inefficiencies of naive searching methods using regular expressions and LIKE queries.
Highlights the problems of irrelevant matches in traditional searches and the need for improved accuracy.
Introduces various full-text searching solutions including Full-Text Indexing and Inverted Indexes.
Details on PostgreSQL's text search features introduced since version 8.3, including TSVECTOR and TSQUERY.
Demonstrates how to perform basic text search queries in PostgreSQL with time taken for indexing.
Instructions on adding a TSVECTOR column to the Posts table for efficient text searching.
Overview of special index types available in PostgreSQL such as GIN and GiST.
How to create indexes for text search in PostgreSQL and compare query times with and without indexes.
Setup of a trigger to synchronize TSVECTOR data upon insertions and updates.
Introduction to the Lucene full-text search engine, its features, and its programming language compatibility.
Steps on how to use Lucene for indexing data with Java, including SQL integration details.
Details on how to parse and execute queries using Lucene with emphasis on query execution time.
Introduction to Sphinx Search, a full-text search engine with a focus on database integration.
Steps to configure, index, and query with Sphinx, including performance metrics for indexing time.
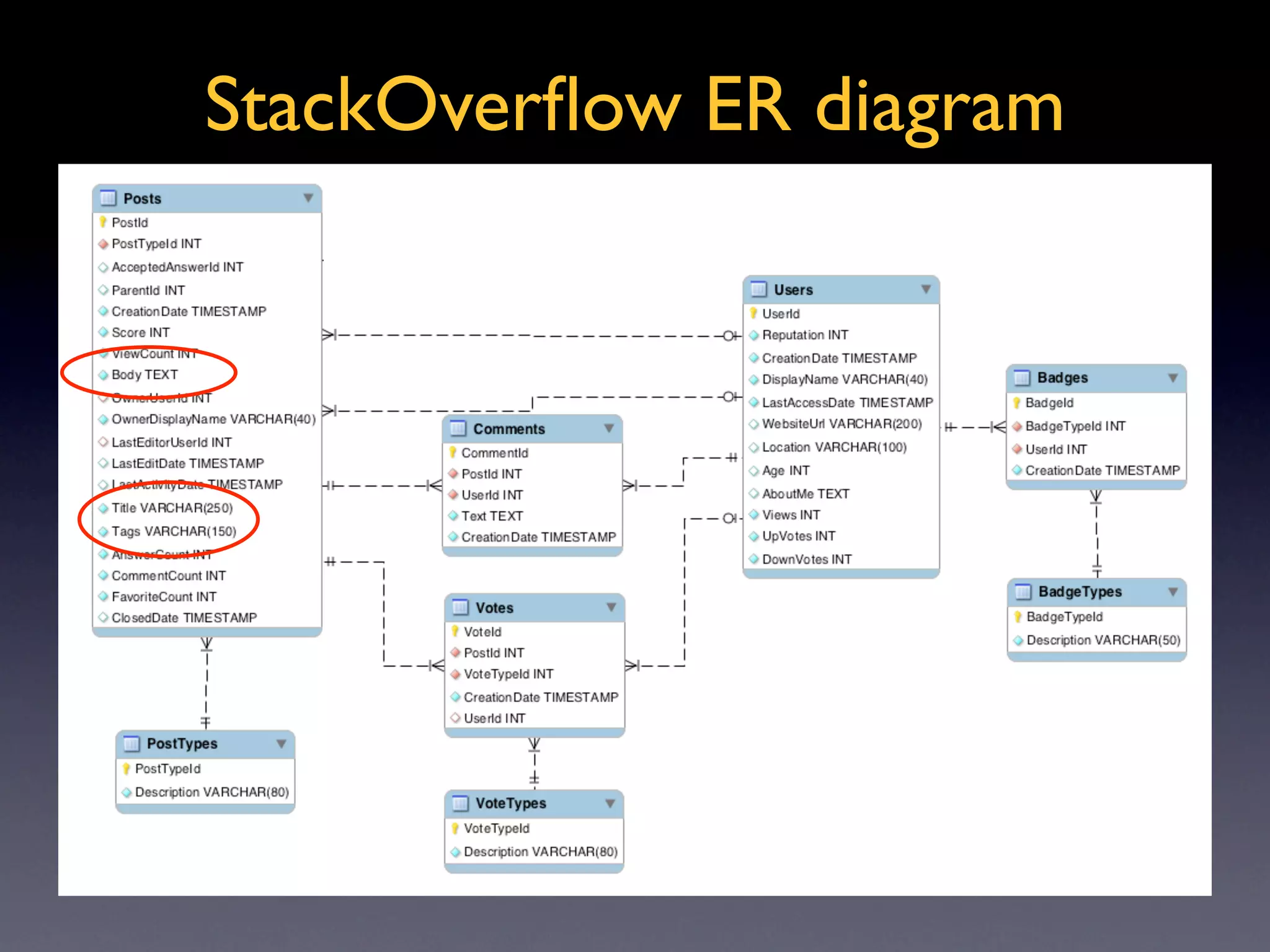
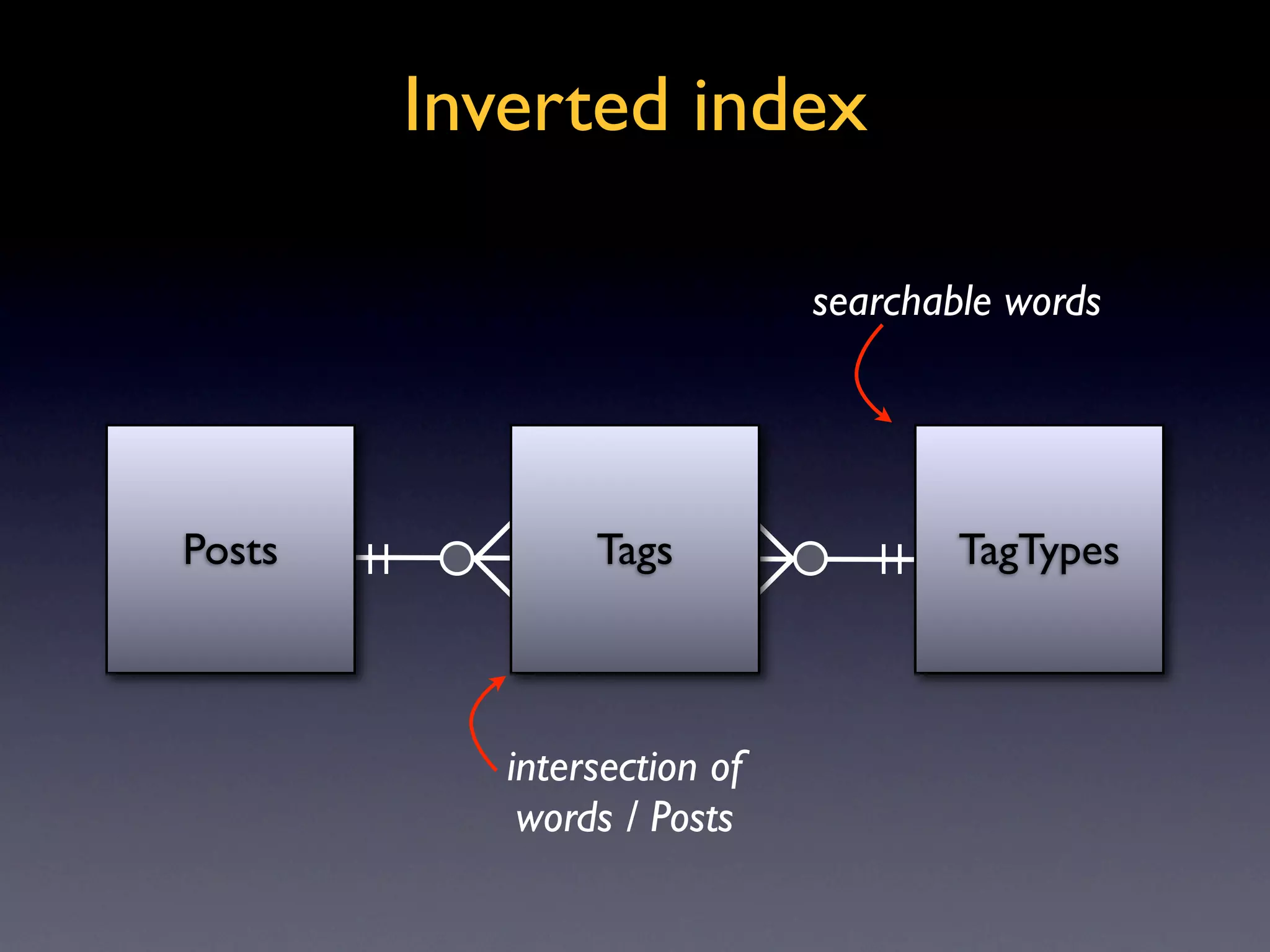
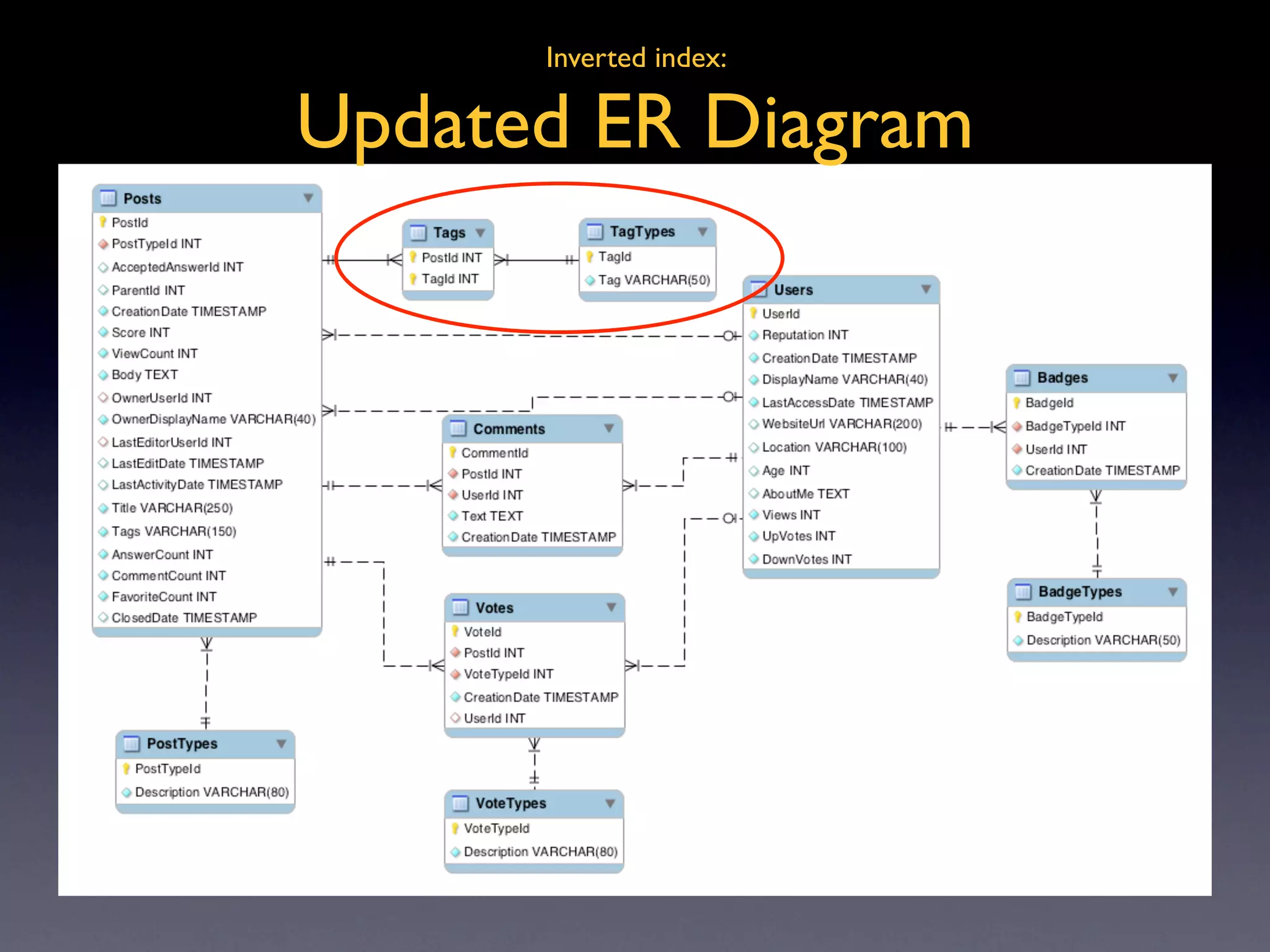
Basic explanation of inverted indexes and their role in search functionality, revised ER diagram included.
Data definitions and SQL implementations for creating and querying inverted indexes efficiently.
Overview of search engine services, particularly Google Custom Search Engine and its suitability.
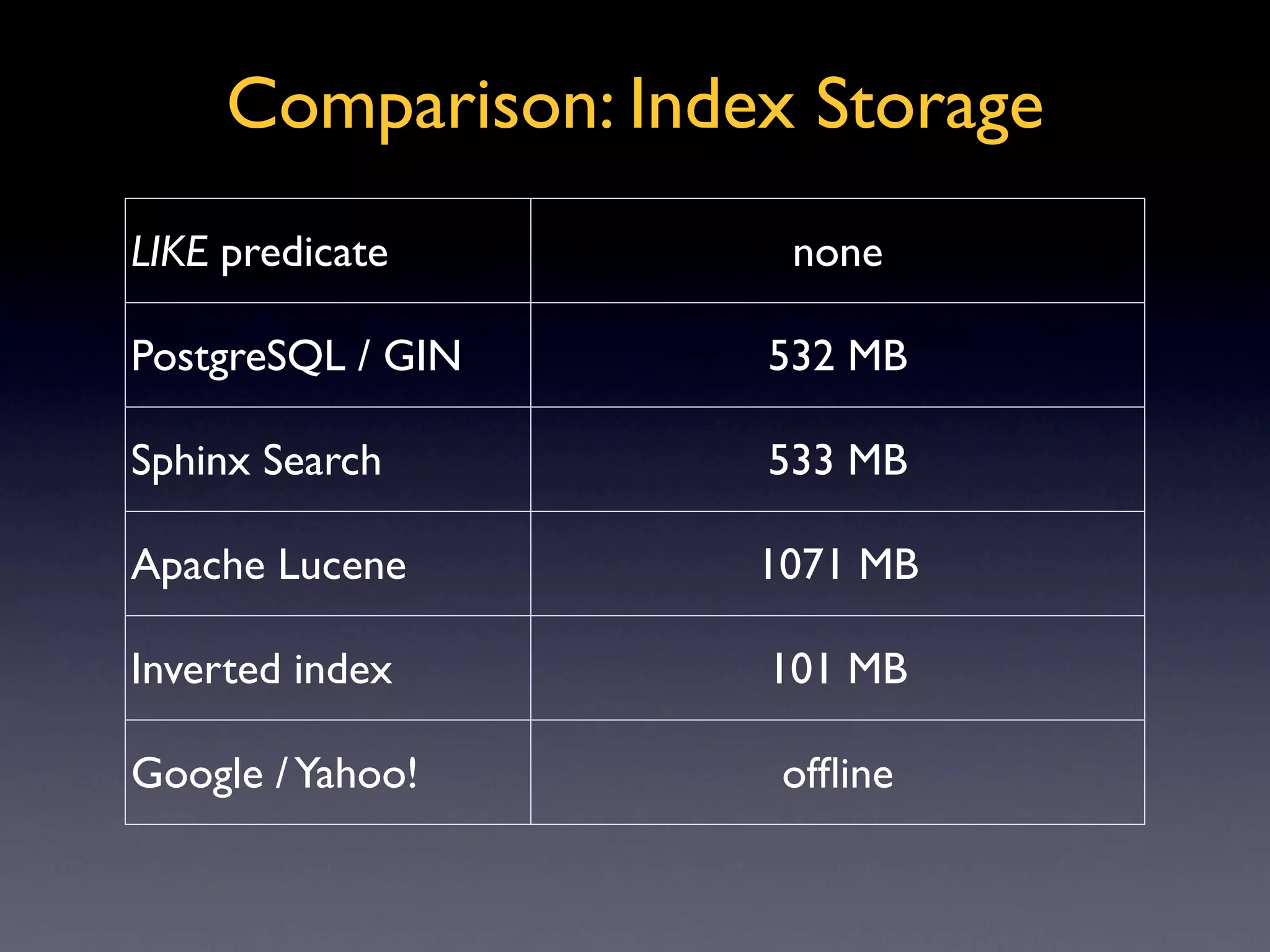
Comparative analysis of different search solutions based on indexing time, storage space, and query speed.
Copyright notice regarding the presentation and guidelines for sharing this work.