Download as PDF, PPTX










![Extract features Feature extracIon Original dataset 17 PredicIve model EvaluaIon Text Label Words Features I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...] Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...] I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...]](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160815145004/75/Foundations-for-Scaling-ML-in-Apache-Spark-17-2048.jpg)
![Fit a model Feature extracIon Original dataset 18 PredicIve model EvaluaIon Text Label Words Features Prediction Probability I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...] 4 0.8 Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6 this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9 never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7 I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...] 4 0.7](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160815145004/75/Foundations-for-Scaling-ML-in-Apache-Spark-18-2048.jpg)
![Evaluate Feature extracIon Original dataset 19 PredicIve model EvaluaIon Text Label Words Features Prediction Probability I bought the game... 4 “i", “bought”,... [1, 0, 3, 9, ...] 4 0.8 Do NOT bother try... 1 “do”, “not”,... [0, 0, 11, 0, ...] 2 0.6 this shirt is aweso... 5 “this”, “shirt” [0, 2, 3, 1, ...] 5 0.9 never got it. Seller... 1 “never”, “got” [1, 2, 0, 0, ...] 1 0.7 I ordered this to... 3 “i”, “ordered” [1, 0, 0, 3, ...] 4 0.7](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160815145004/75/Foundations-for-Scaling-ML-in-Apache-Spark-19-2048.jpg)





![Tungsten in ML Tungsten: off-heap memory management • Avoids JVM GC • Uses efficient storage formats • Code generation 26 Issue in ML: object creation during each iteration Issue in ML: Array[(Int,Double,Double)] Issue in ML: Volcano iterator model in MR/RDDs](https://image.slidesharecdn.com/16-08-14kddbigmine16talk-160815145004/75/Foundations-for-Scaling-ML-in-Apache-Spark-26-2048.jpg)






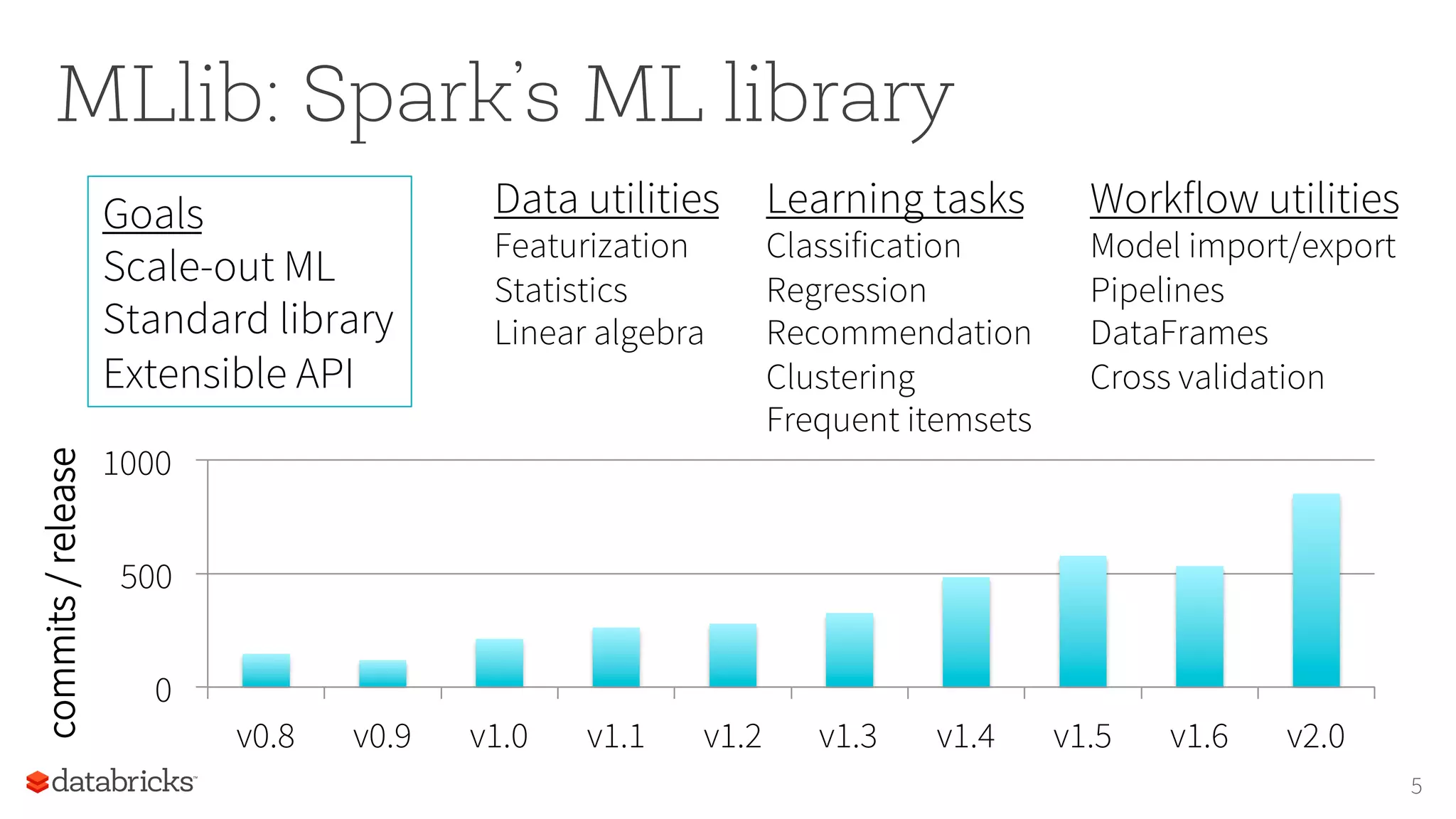
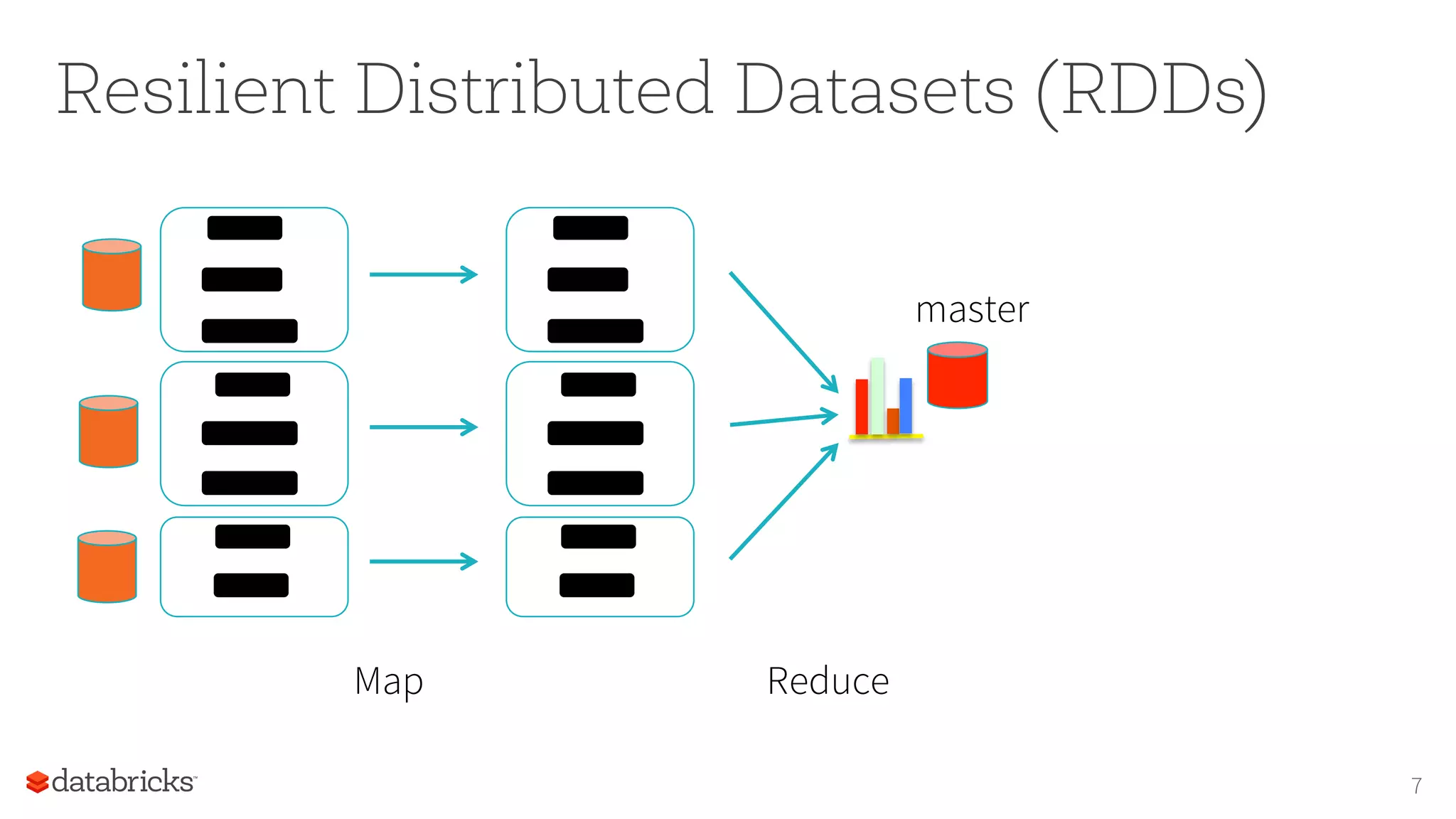
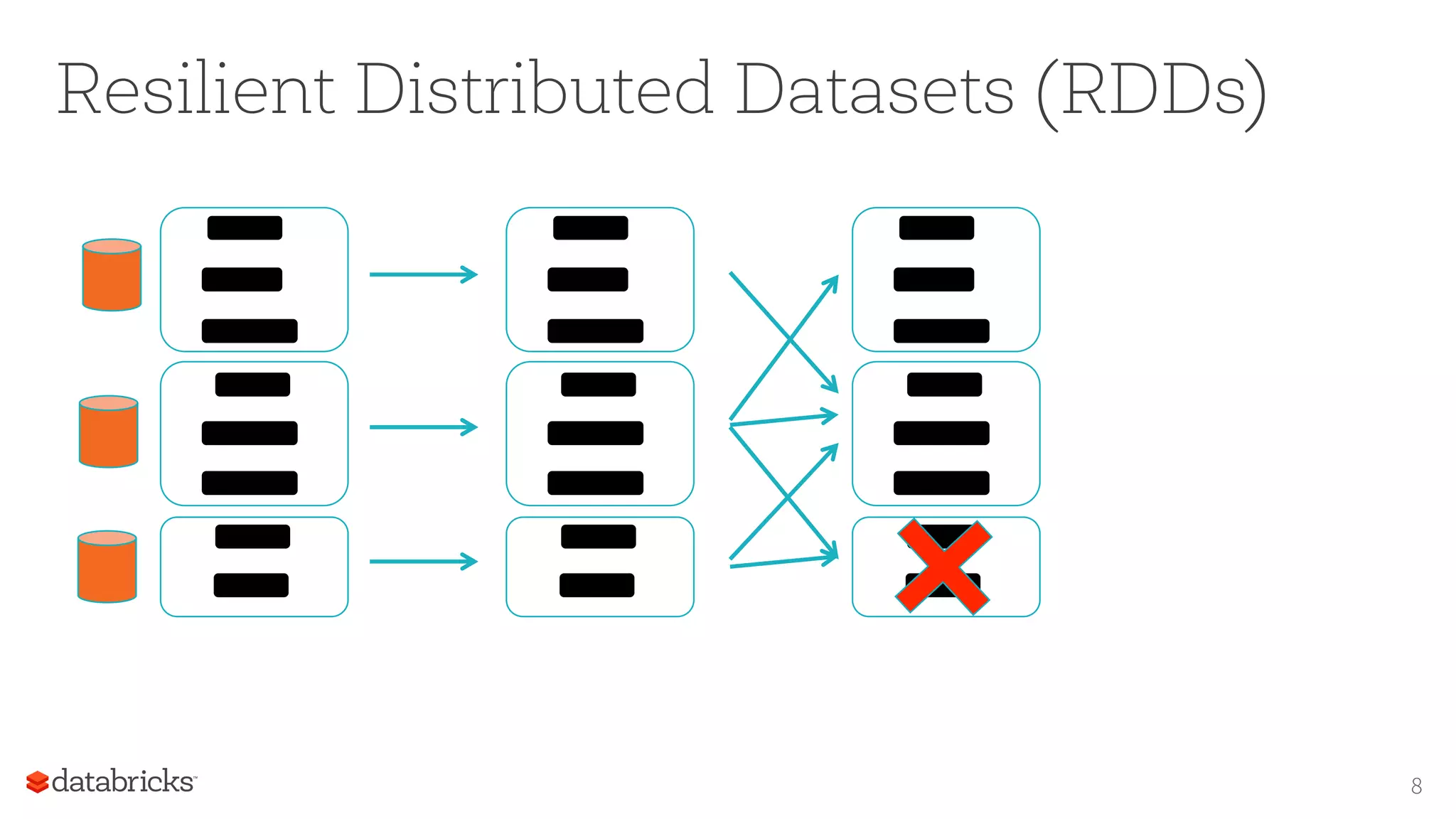
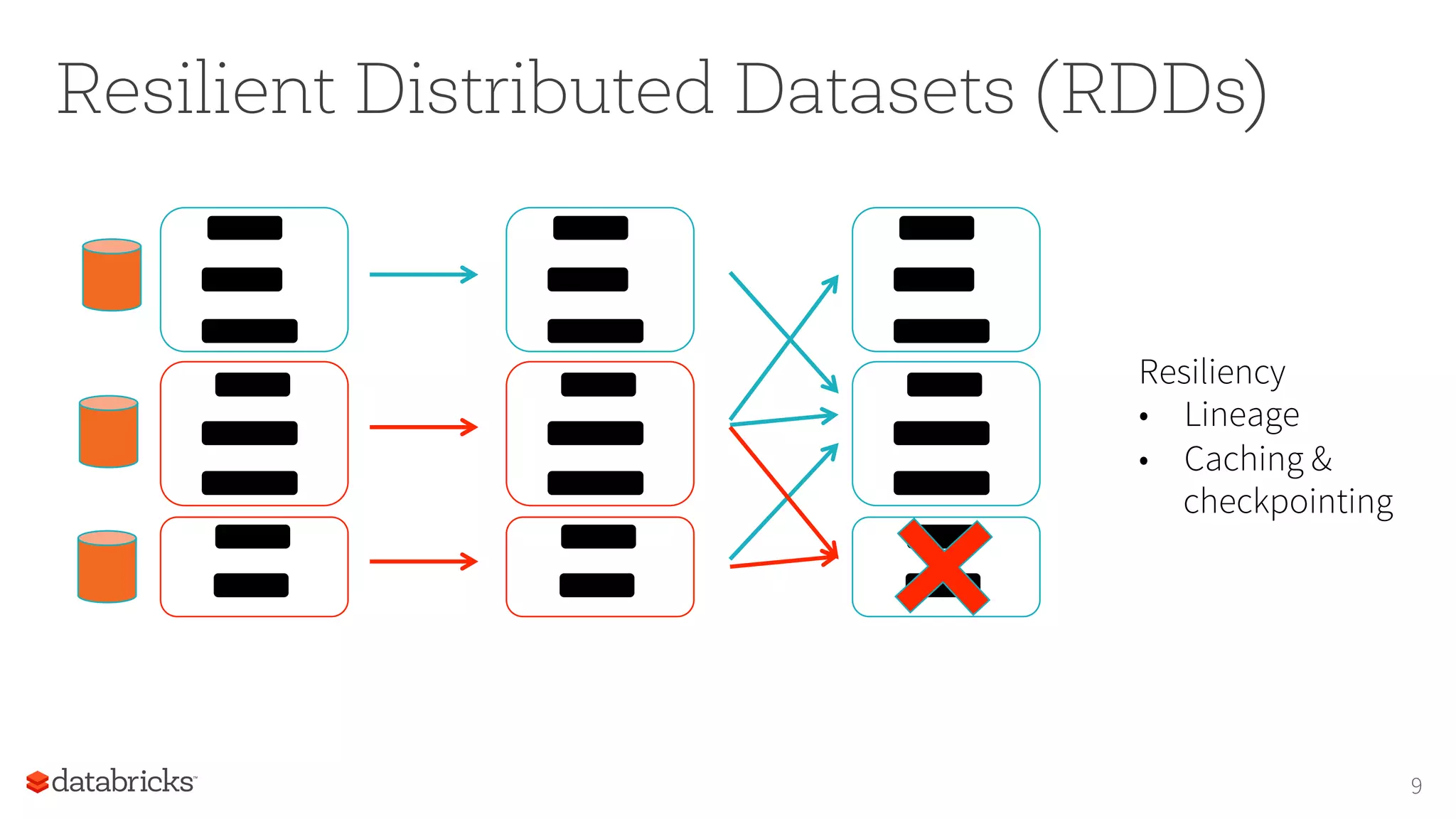
The document discusses the foundations for scaling machine learning (ML) in Apache Spark, highlighting its capabilities, such as scalability using resilient distributed datasets (RDDs) and integration with DataFrames. Key focuses include the performance challenges of RDDs, the advantages of using DataFrames for ML pipelines, and future improvements with Catalyst query optimization and Tungsten memory management. The author emphasizes the importance of transitioning ML algorithms to DataFrames for better scalability and usability.