Downloaded 81 times





![Scaling computation ● Different programming models, Different languages, Different levels ● Sequential ○ R, Matlab, Python, Scala ● Parallel ○ Theano, Torch, Caffe, Tensor Flow, Deeplearning4j Elapsed times for 20 PageRank iterations [3, 4]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-8-2048.jpg)
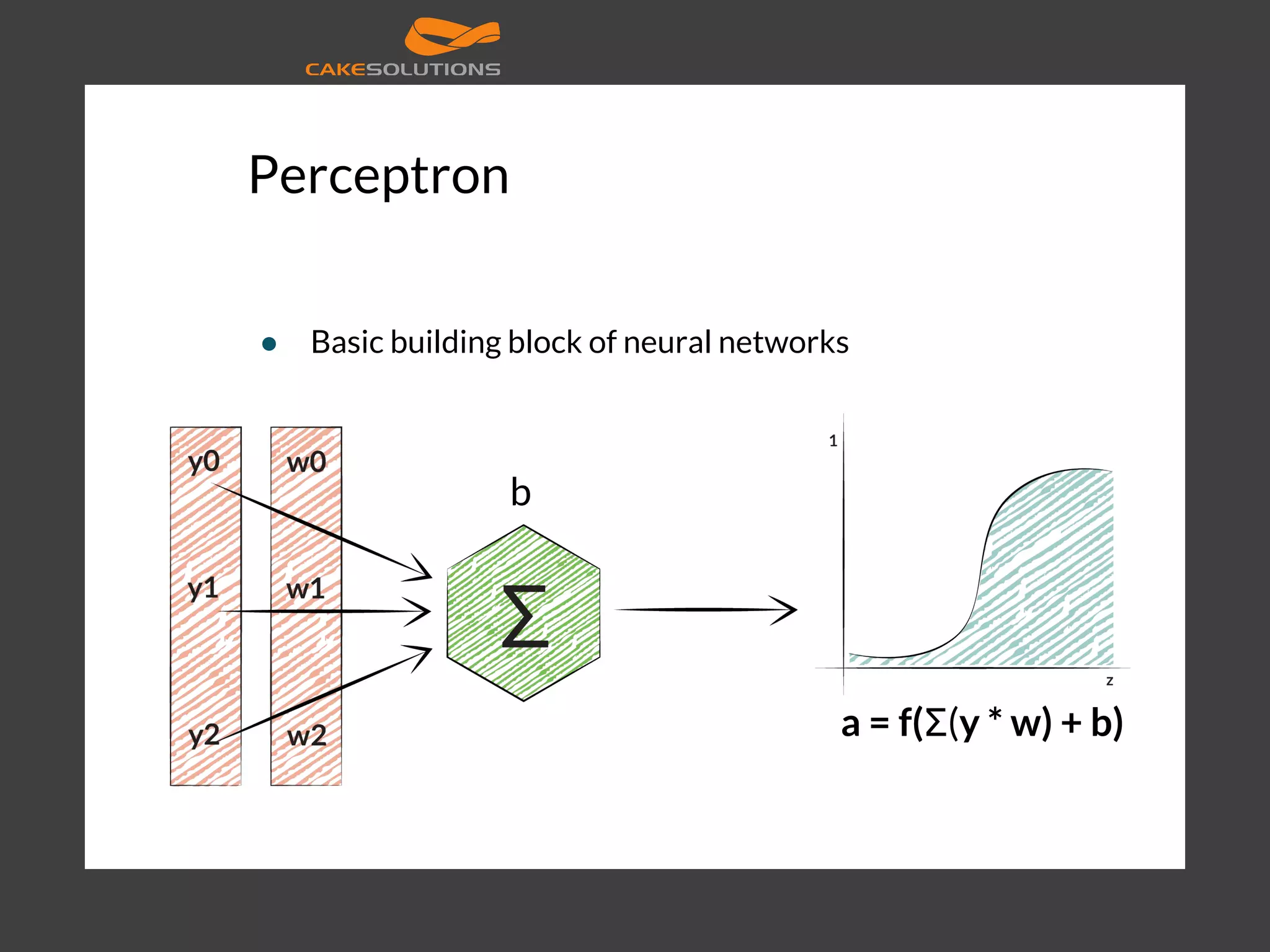
![Machine learning ● Linear algebra ● Vectors, matrices, vector spaces, matrix transformations, eigenvectors/values ● Many machine learning algorithms are optimization problems ● Goal is to solve them in reasonable (bounded) time ● Goal not always to find the best possible model (data size, feature engineering vs. algorithm/model complexity) ● Goal is to solve them reliably, at scale, support application needs and improve [5]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-9-2048.jpg)


![Failure in distributed system ● Node failures, network partitions, message loss, split brains, inconsistencies ● Microsoft's data centers average failure rate is 5.2 devices per day and 40.8 links per day, with a median time to repair of approximately five minutes (and a maximum of one week). ● Google new cluster over one year. Five times rack issues 40-80 machines seeing 50 percent packet loss. Eight network maintenance events (four of which might cause ~30-minute random connectivity losses). Three router failures (resulting in the need to pull traffic immediately for an hour). ● CENIC 500 isolating network partitions with median 2.7 and 32 minutes; 95th percentile of 19.9 minutes and 3.7 days, respectively for software and hardware problems [6]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-12-2048.jpg)
![Failure in distributed system ● MongoDB separated primary from its 2 secondaries. 2 hours later the old primary rejoined and rolled back everything on the new primary ● A network partition isolated the Redis primary from all secondaries. Every API call caused the billing system to recharge customer credit cards automatically, resulting in 1.1 percent of customers being overbilled over a period of 40 minutes. ● The partition caused inconsistency in the MySQL database. Because foreign key relationships were not consistent, Github showed private repositories to the wrong users' dashboards and incorrectly routed some newly created repositories. ● For several seconds, Elasticsearch is happy to believe two nodes in the same cluster are both primaries, will accept writes on both of those nodes, and later discard the writes to one side. ● RabbitMQ lost ~35% of acknowledged writes under those conditions. ● Redis threw away 56% of the writes it told us succeeded. ● In Riak, last-write-wins resulted in dropping 30-70% of writes, even with the strongest consistency settings ● MongoDB “strictly consistent” reads see stale versions of documents, but they can also return garbage data from writes that never should have occurred. [6]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-13-2048.jpg)
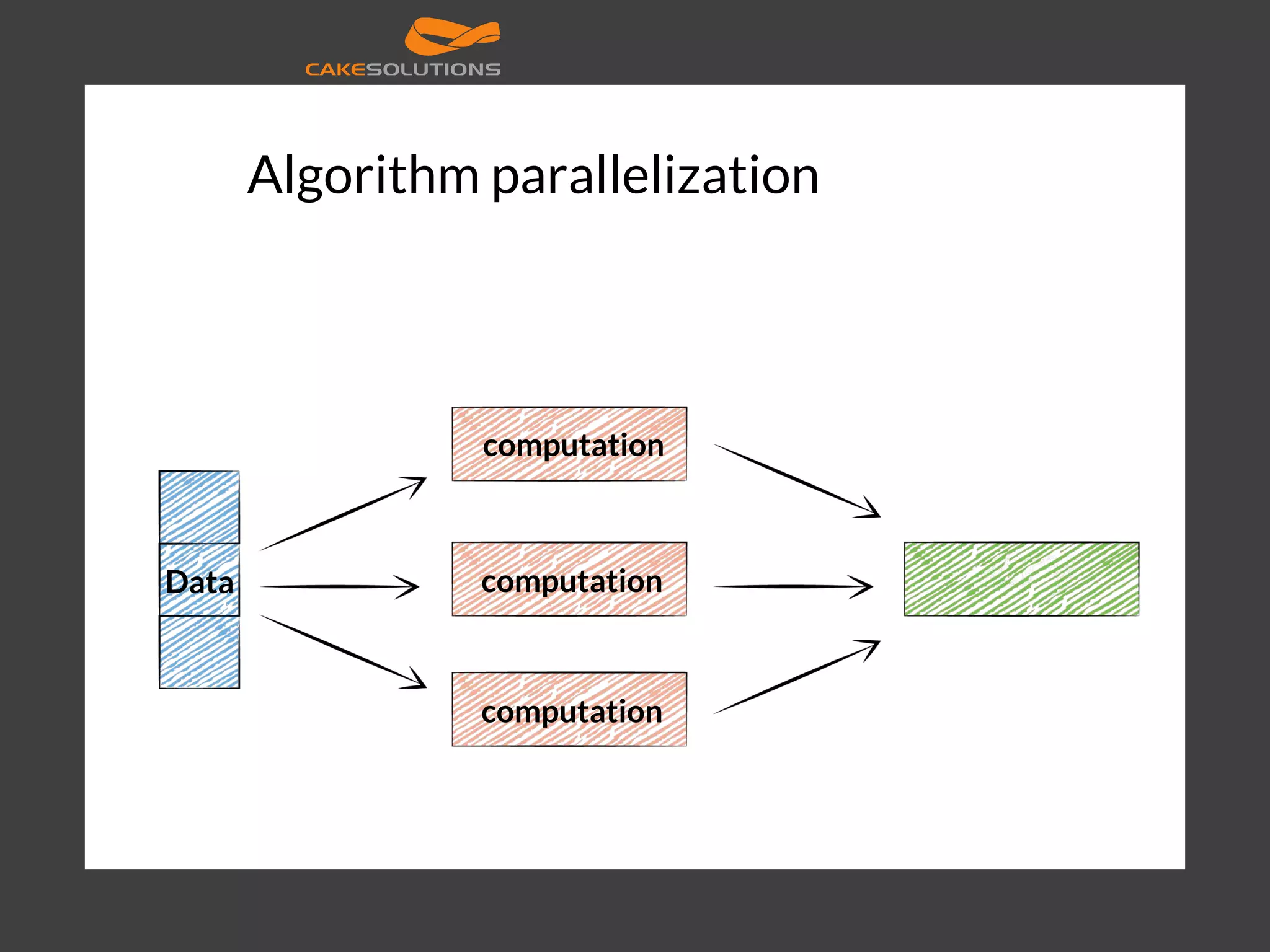
![Algorithm parallelization [7]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-15-2048.jpg)
![Neural network parallelism [8]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-16-2048.jpg)
![import tensorflow as tf def init_weights(shape): return tf.Variable(tf.random_normal(shape, stddev=0.01)) def model(X, w_h, w_o): h = tf.nn.sigmoid(tf.matmul(X, w_h)) return tf.matmul(h, w_o) X = tf.placeholder("float", [None, 784]) Y = tf.placeholder("float", [None, 10]) w_h = init_weights([784, 625]) w_o = init_weights([625, 10]) py_x = model(X, w_h, w_o) cost = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(py_x, Y)) train_op = tf.train.GradientDescentOptimizer(0.05).minimize(cost) predict_op = tf.argmax(py_x, 1) sess = tf.Session() init = tf.initialize_all_variables() sess.run(init) sess.run(train_op, …) sess.run(predict_op, …) [9, 10]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-17-2048.jpg)
![Model parallelism [11] Machine1 Machine2 Machine3 Machine4 Machine1 Machine2 Machine3 Machine4](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-18-2048.jpg)
![Data parallelism [11] Data Data](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-19-2048.jpg)
![Parameter server ● Model and data parallelism ● Failures and slow machines ● Additional stochasticity due to asynchrony (relaxed consistency, not up to data parameters, ordering not guaranteed, …) [11]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-20-2048.jpg)
![Examples “Their network for face detection from youtube comprised millions of neurons and 1 billion connection weights. They trained it on a dataset of 10 million 200x200 pixel RGB images to learn 20,000 object categories. The training simulation ran for three days on a cluster of 1,000 servers totaling 16,000 CPU cores. Each instantiation of the network spanned 170 servers” Google. “We demonstrate near-perfect weak scaling on a 16 rack IBM Blue Gene/Q (262144 CPUs, 256 TB memory), achieving an unprecedented scale of 256 million neurosynaptic cores containing 65 billion neurons and 16 trillion synapses“ TrueNorth, part of project IBM SyNAPSE. [11, 12]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-21-2048.jpg)
![Examples [13]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-22-2048.jpg)

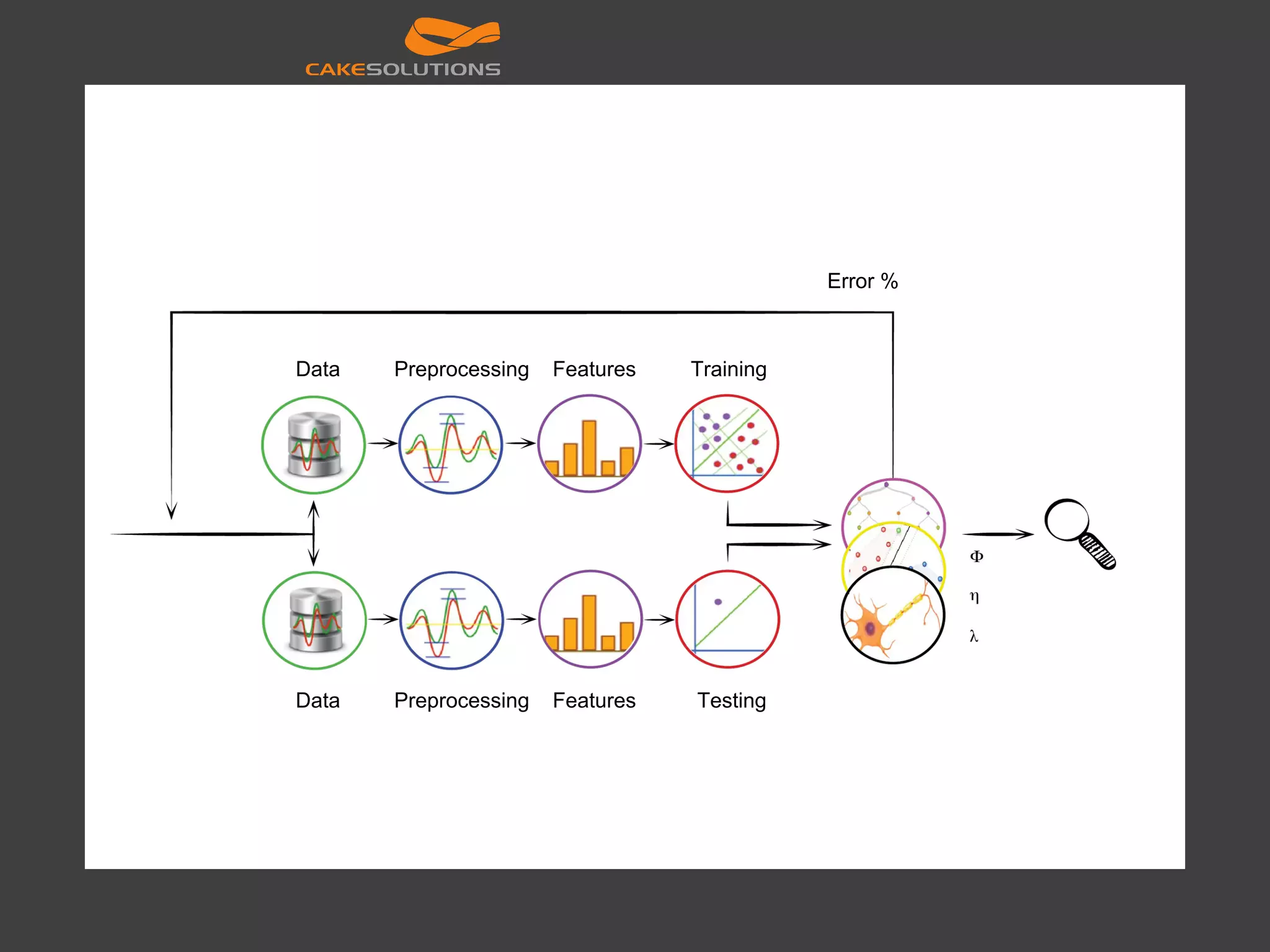

![[14] CQRS Client QueryCommand DBDB Denormalise /Precompute Kappa architecture Batch-Pipeline Kafka Allyour data NoSQL SQL Spark Client Client Client Views Stream processor Flume Scoop Hive Impala Oozie HDFS Lambda Architecture Batch Layer Servin g Layer Stream layer (fast) Query Query Allyour data Serving DB](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-26-2048.jpg)
![[15, 16]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-27-2048.jpg)



![Distributed computation ● Spark streaming ● Computing, processing, transforming, analytics [17]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-31-2048.jpg)
![textFile mapmap reduceByKey collect sc.textFile("counts") .map(line => line.split("t")) .map(word => (word(0), word(1).toInt)) .reduceByKey(_ + _) .collect() [18] RDD](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-32-2048.jpg)
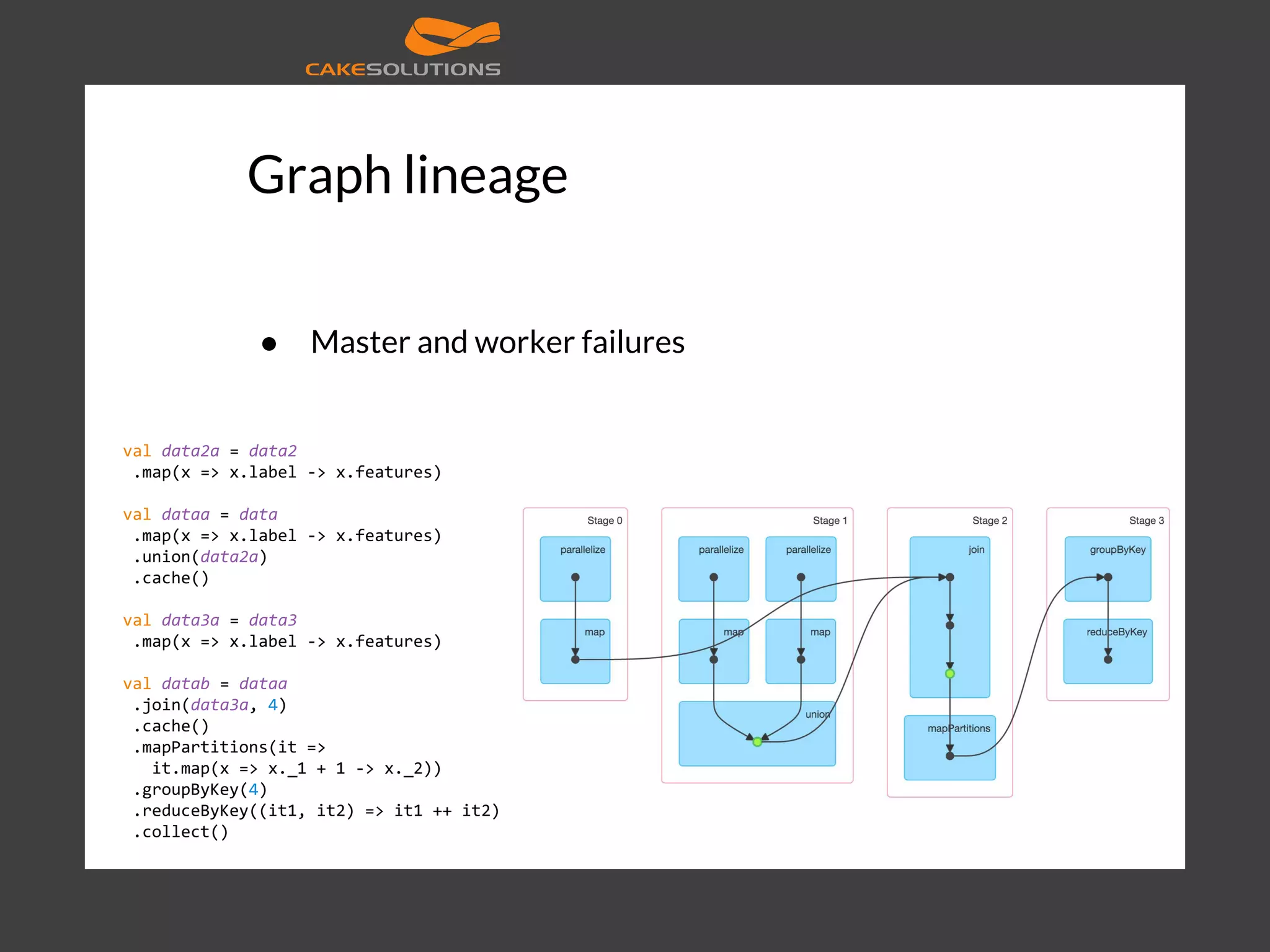
![Optimizations ● Multiple phases ● Catalyst [19]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-34-2048.jpg)
![Optimizations [20] Spark master Spark worker Cassandra](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-35-2048.jpg)
![Optimizations ● CPU and memory bottlenecks, not IO ● Project Tungsten ○ Explicit memory management and binary processing ○ Cache-aware computation ○ Code generation ● Daytona Gray Sort 100TB Benchmark won by Apache Spark ○ Optimized memory layout, shuffle algorithm, ... [20]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-36-2048.jpg)


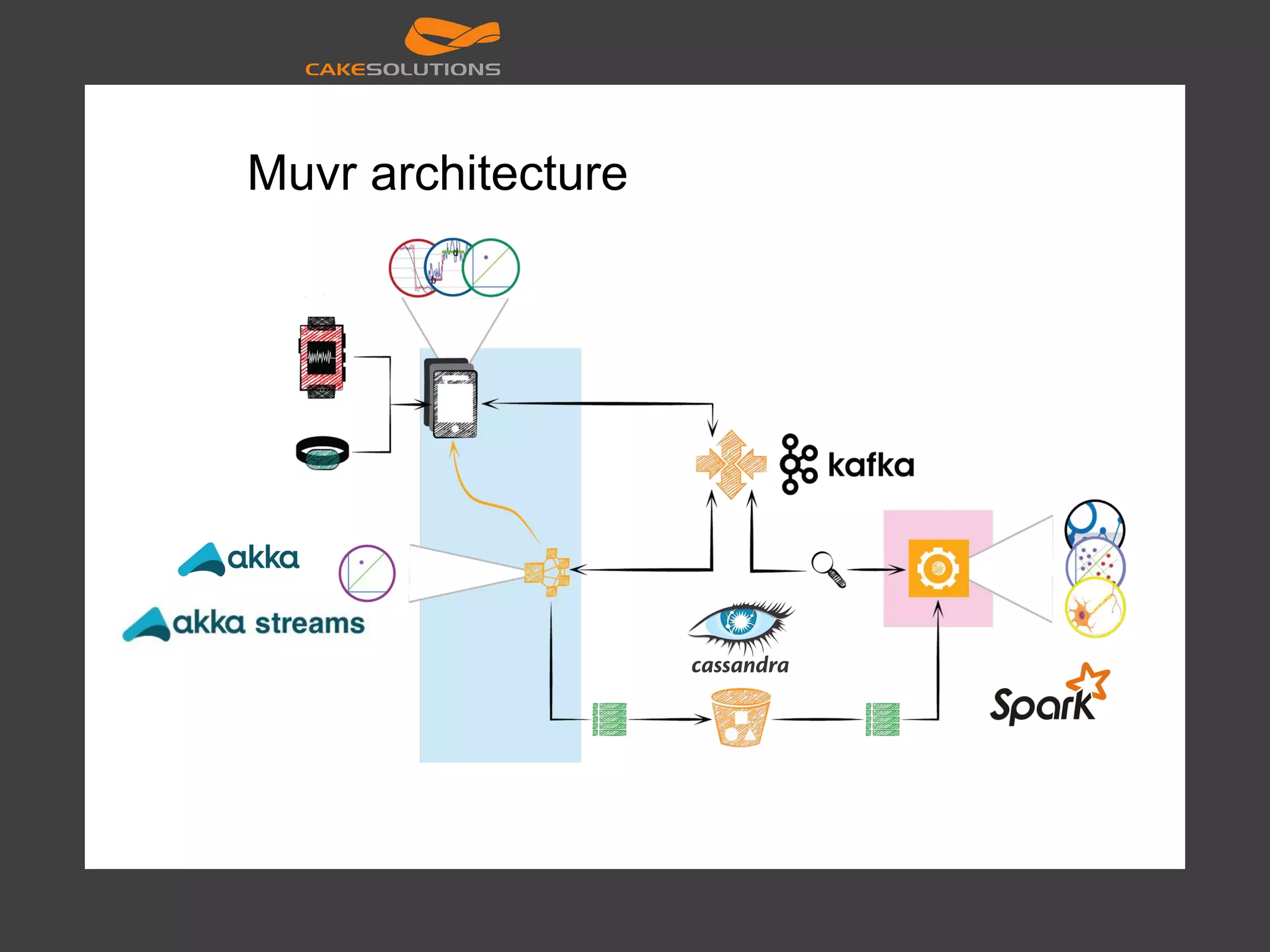
![Muvr [21]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-39-2048.jpg)
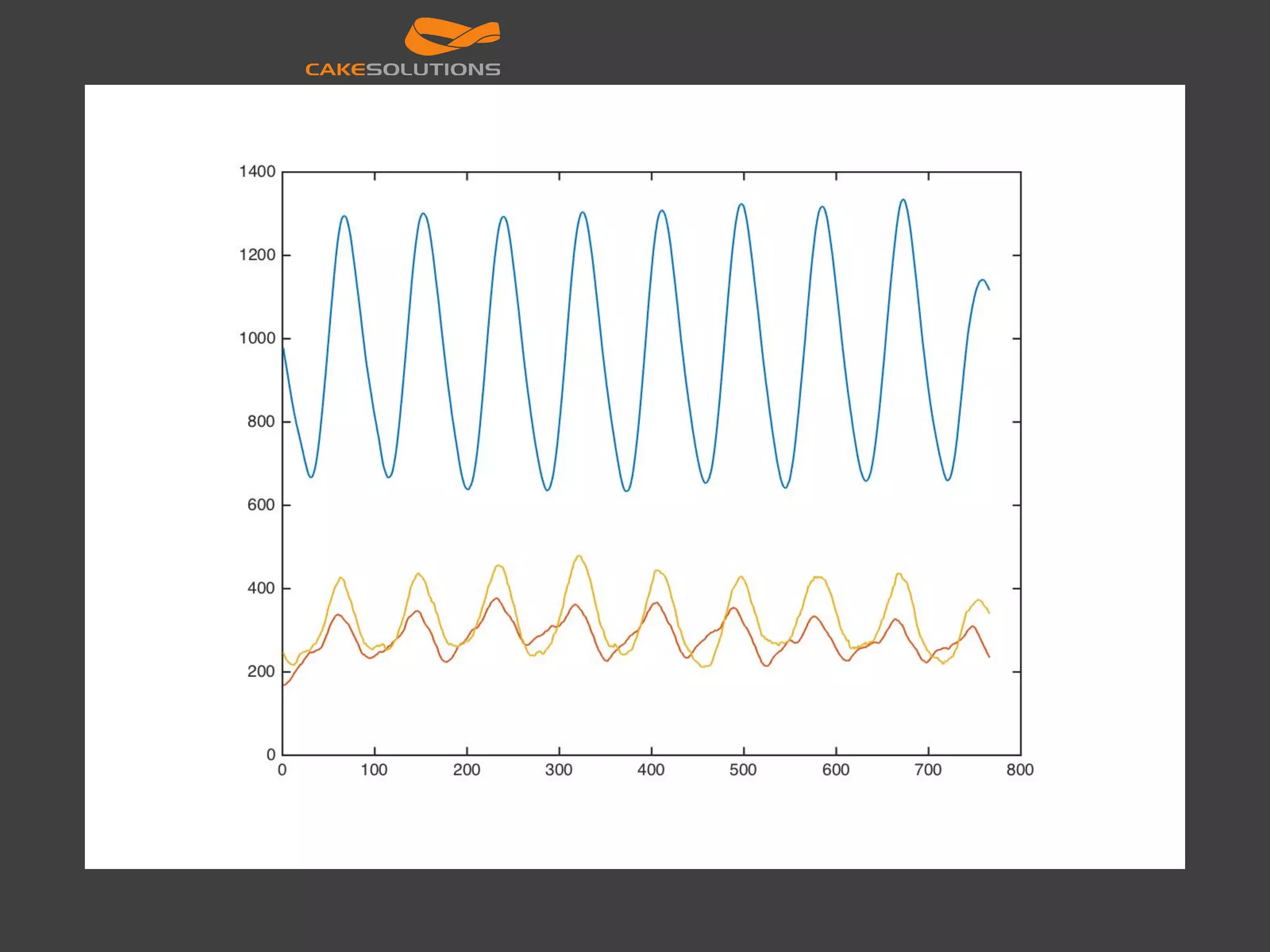
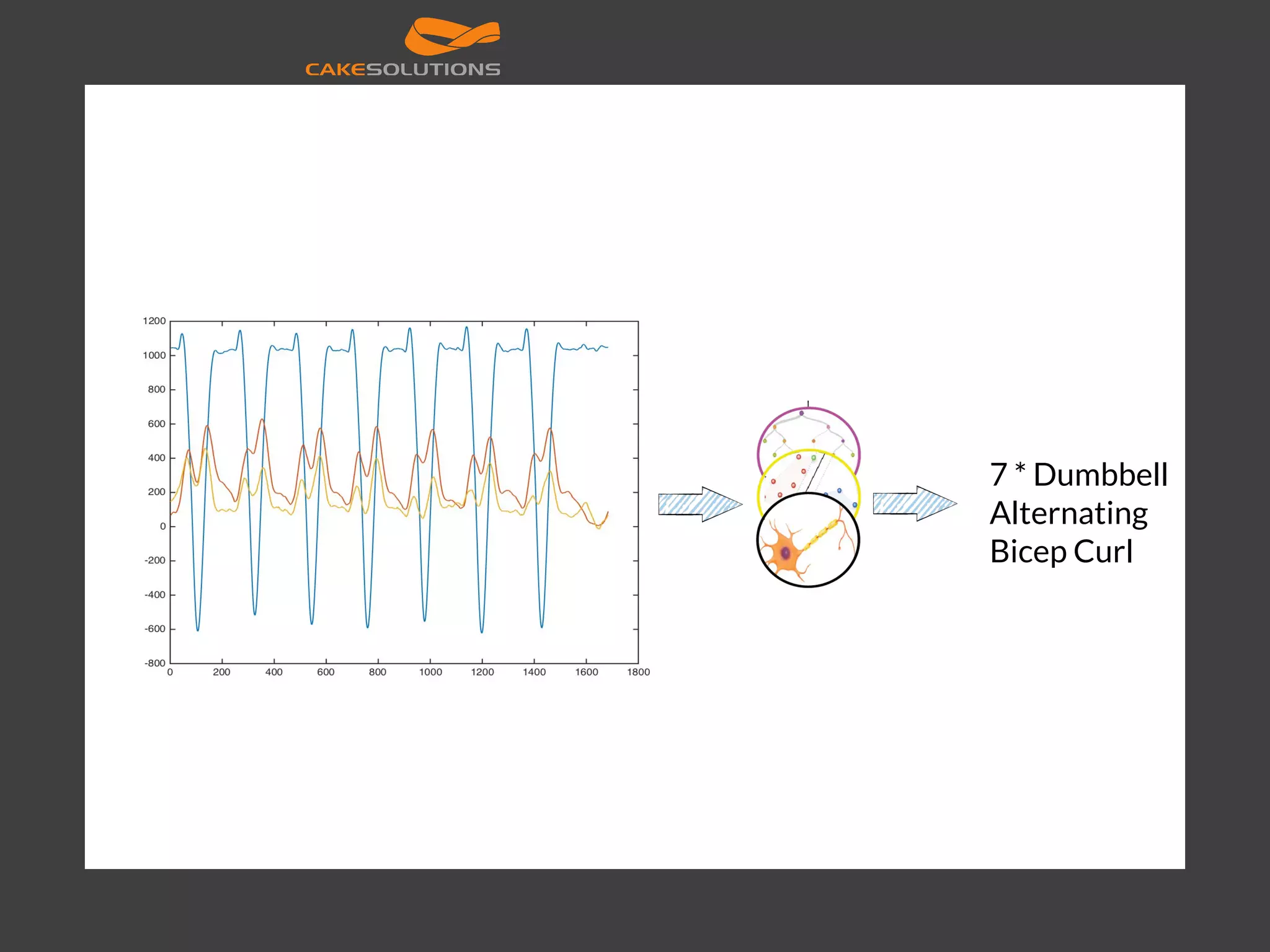


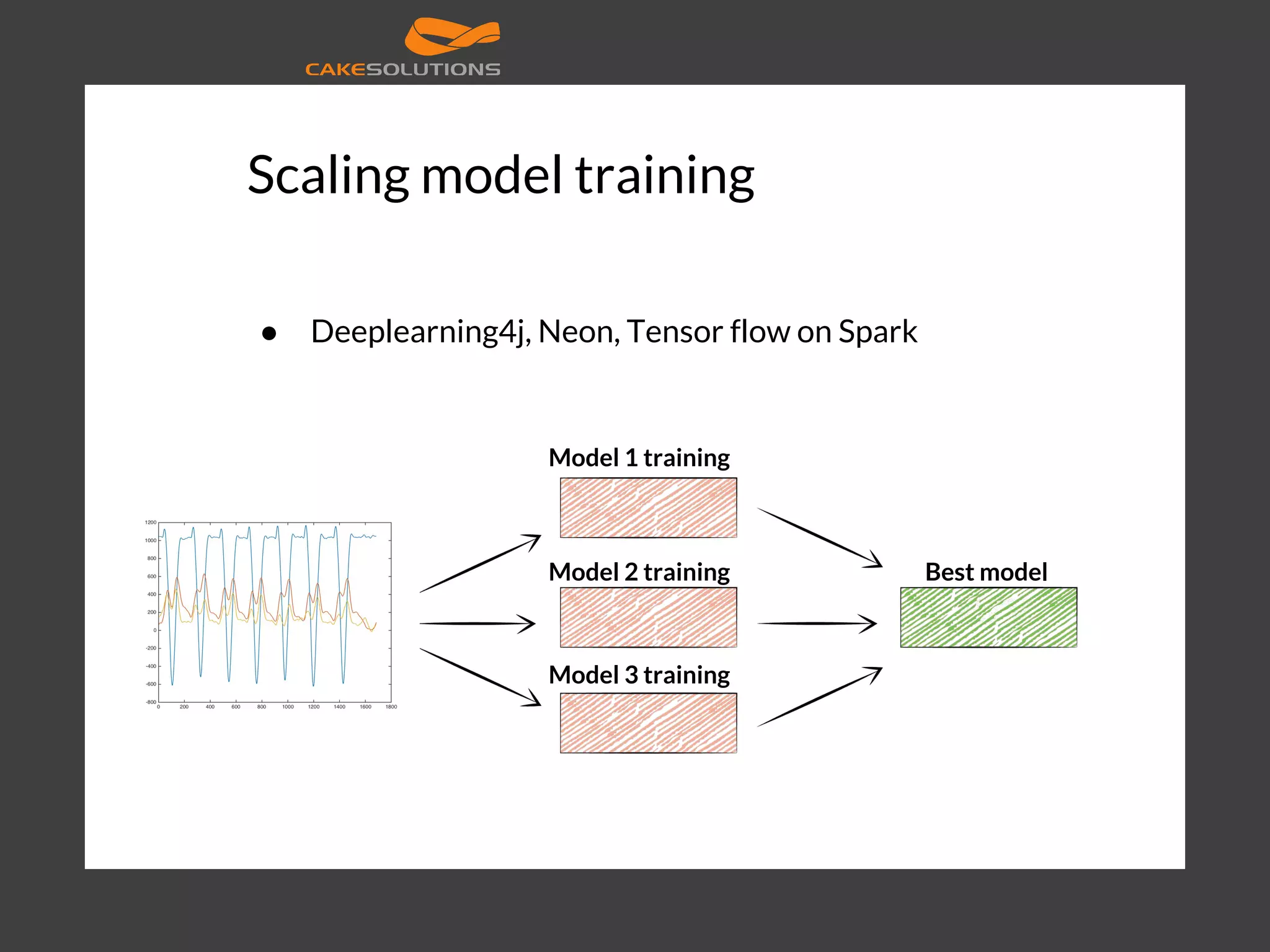
![Scaling model training val sc = new SparkContext("local[4]", "NN") val data = ... val layers = Array[Int](inputSize, 250, 50, outputSize) val trainer = new MultilayerPerceptronClassifier() .setLayers(layers) .setBlockSize(128) .setSeed(1234L) .setMaxIter(100) val model = trainer.fit(data) val result = model.transform(data) println(result.select(result("prediction")).foreach(println)) val predictionAndLabels = result.select("prediction", "label") val evaluator = new MulticlassClassificationEvaluator() .setMetricName("precision") println("Precision:" + evaluator.evaluate(predictionAndLabels))](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-48-2048.jpg)
![init_norm = Uniform(low=-0.1,high=0.1) bias_init = Constant(val = 1.0) layers = [] layers.append(Conv( fshape = (1, 3, 16), init=init_norm, bias=bias_init, activation=Rectlin())) layers.append(Pooling( op="max", fshape=(2,1), strides=2)) layers.append(Conv( fshape = (1, 3, 32), init=init_norm, bias=bias_init, activation=Rectlin())) layers.append(Pooling( op="max", fshape=(2,1), strides=2)) layers.append(Affine( nout=100, init=init_norm, bias=bias_init, activation=Rectlin())) layers.append(Dropout( name="do_2", keep = 0.9)) layers.append(Affine( nout=dataset.num_labels, init=init_norm, bias=bias_init, activation = Logistic())) return Model(layers=layers)](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-50-2048.jpg)

![sc .cassandraTable(conf["cassandra"]["data_keyspace"], conf["cassandra"]["data_table"]) .select("user_id", "model_id", "file_name", "time", "x", "y", "z", "exercise") .spanBy("user_id", "model_id") .map(train_model_for_user) .saveToCassandra(conf["cassandra"]["model_keyspace"], conf["cassandra"]["model_table"])](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-52-2048.jpg)
![[22]](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-53-2048.jpg)
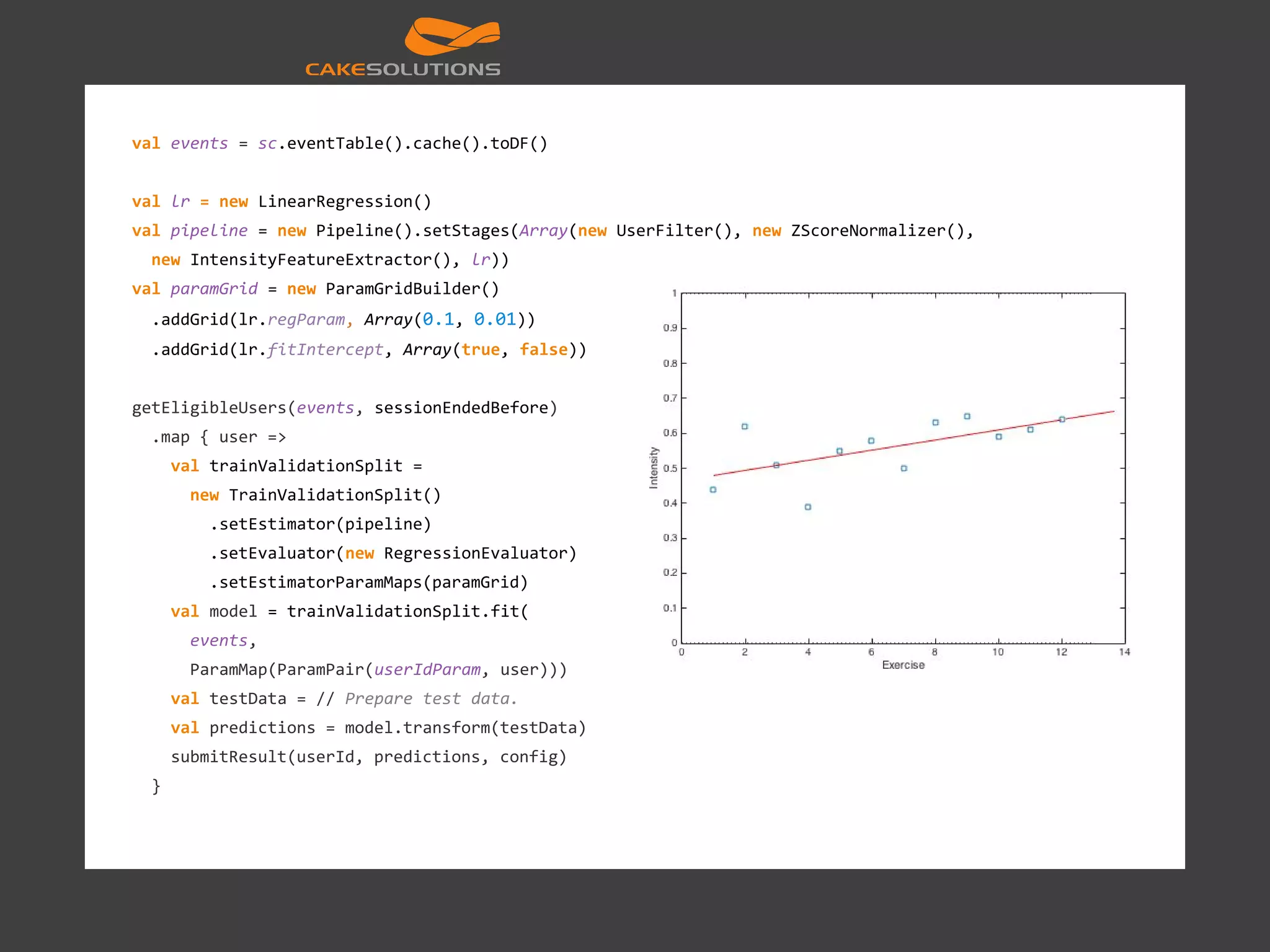
![Queries and analytics val events: RDD[(JournalKey, Any)] = sc.eventTable().cache().filterClass [EntireResistanceExerciseSession].flatMap(_.deviations) val deviationsFrequency = sqlContext.sql( """SELECT planned.exercise, hour(time), COUNT(1) FROM exerciseDeviations WHERE planned.exercise = 'bench press' GROUP BY planned.exercise, hour(time)""") val deviationsFrequency2 = exerciseDeviationsDF .where(exerciseDeviationsDF("planned.exercise") === "bench press") .groupBy( exerciseDeviationsDF("planned.exercise"), exerciseDeviationsDF("time”)) .count() val deviationsFrequency3 = exerciseDeviations .filter(_.planned.exercise == "bench press") .groupBy(d => (d.planned.exercise, d.time.getHours)) .map(d => (d._1, d._2.size))](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-55-2048.jpg)
![Clustering def toVector(user: User): mllib.linalg.Vector = Vectors.dense( user.frequency, user.performanceIndex, user.improvementIndex) val events: RDD[(JournalKey, Any)] = sc.eventTable().cache() val users: RDD[User] = events.filterClass[User] val kmeans = new KMeans() .setK(5) .set... val clusters = kmeans.run(users.map(_.toVector))](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-56-2048.jpg)
![Recommendations val weight: RDD[(JournalKey, Any)] = sc.eventTable().cache() val exerciseDeviations = events .filterClass[EntireResistanceExerciseSession] .flatMap(session => session.sets.flatMap(set => set.sets.map( exercise => (session.id.id, exercise.exercise)))) .groupBy(e => e) .map(g => Rating(normalize(g._1._1), normalize(g._1._2), normalize(g._2.size))) val model = new ALS().run(ratings) val predictions = model.predict(recommend) bench press bicep curl dead lift user 1 5 2 user 2 4 3 user 3 5 2 user 4 3 1](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-57-2048.jpg)
![Graph analysis val events: RDD[(JournalKey, Any)] = sc.eventTable().cache() val connections = events.filterClass[Connections] val vertices: RDD[(VertexId, Long)] = connections.map(c => (c.id, 1l)) val edges: RDD[Edge[Long]] = connections .flatMap(c => c.connections .map(Edge(c.id, _, 1l))) val graph = Graph(vertices, edges) val ranks = graph.pageRank(0.0001).vertices](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-58-2048.jpg)


![References [1] http://arxiv.org/abs/1112.6209 [2] SuperComputing 2012 two weeks ago and part of the IBM SyNAPSE project [3] http://www.csie.ntu.edu.tw/~cjlin/talks/twdatasci_cjlin.pdf [4] http://blog.acolyer.org/2015/06/05/scalability-but-at-what-cost/ [5] https://www.tensorflow.org/versions/master/tutorials/mnist/beginners/index.html [6] https://queue.acm.org/detail.cfm?id=2655736 [7] http://fa.bianp.net/blog/2013/isotonic-regression/ [8] http://briandolhansky.com/blog/2014/10/30/artificial-neural-networks-matrix-form-part-5 [9] https://github.com/nlintz/TensorFlow-Tutorials/blob/master/3_net.py [10] https://www.tensorflow.org/ [11] http://static.googleusercontent.com/media/research.google.com/en/us/archive/large_deep_networks_nips2012.pdf [12] https://www.quora.com/How-big-is-the-largest-feedforward-neural-network-ever-trained-and-what-for [13] http://static.googleusercontent.com/media/research.google.com/en//archive/unsupervised_icml2012.pdf [14] http://www.benstopford.com/2015/04/28/elements-of-scale-composing-and-scaling-data-platforms/ [15] http://malteschwarzkopf.de/research/assets/google-stack.pdf [16] http://malteschwarzkopf.de/research/assets/facebook-stack.pdf [17] https://twitter.com/tsantero/status/695013012525060097 [18] http://www.slideshare.net/LisaHua/spark-overview-37479609 [19] https://ogirardot.wordpress.com/2015/05/29/rdds-are-the-new-bytecode-of-apache-spark/ [20] https://kayousterhout.github.io/trace-analysis/ [21] https://github.com/muvr [22] https://databricks.com/blog/2016/01/25/deep-learning-with-spark-and-tensorflow.html](https://image.slidesharecdn.com/machinelearningatscalewithapachesparkfinal-160211225906/75/Machine-learning-at-Scale-with-Apache-Spark-62-2048.jpg)


This document discusses scaling machine learning using Apache Spark. It covers several key topics: 1) Parallelizing machine learning algorithms and neural networks to distribute computation across clusters. This includes data, model, and parameter server parallelism. 2) Apache Spark's Resilient Distributed Datasets (RDDs) programming model which allows distributing data and computation across a cluster in a fault-tolerant manner. 3) Examples of very large neural networks trained on clusters, such as a Google face detection model using 1,000 servers and a IBM brain-inspired chip model using 262,144 CPUs.