






![Table API & SQL Example 9 val tEnv = TableEnvironment.getTableEnvironment(env) // configure your data source val customerSource = CsvTableSource.builder() .path("/path/to/customer_data.csv") .field("name", Types.STRING).field("prefs", Types.STRING) .build() // register as a table tEnv.registerTableSource(”cust", customerSource) // define your table program val table = tEnv.scan("cust").select('name.lowerCase(), myParser('prefs)) val table = tEnv.sql("SELECT LOWER(name), myParser(prefs) FROM cust") // convert val ds: DataStream[Customer] = table.toDataStream[Customer]](https://image.slidesharecdn.com/flinkforwardsf2017timowalthertableandsqlapi-170414102541/75/Flink-Forward-SF-2017-Timo-Walther-Table-SQL-API-unified-APIs-for-batch-and-stream-processing-9-2048.jpg)
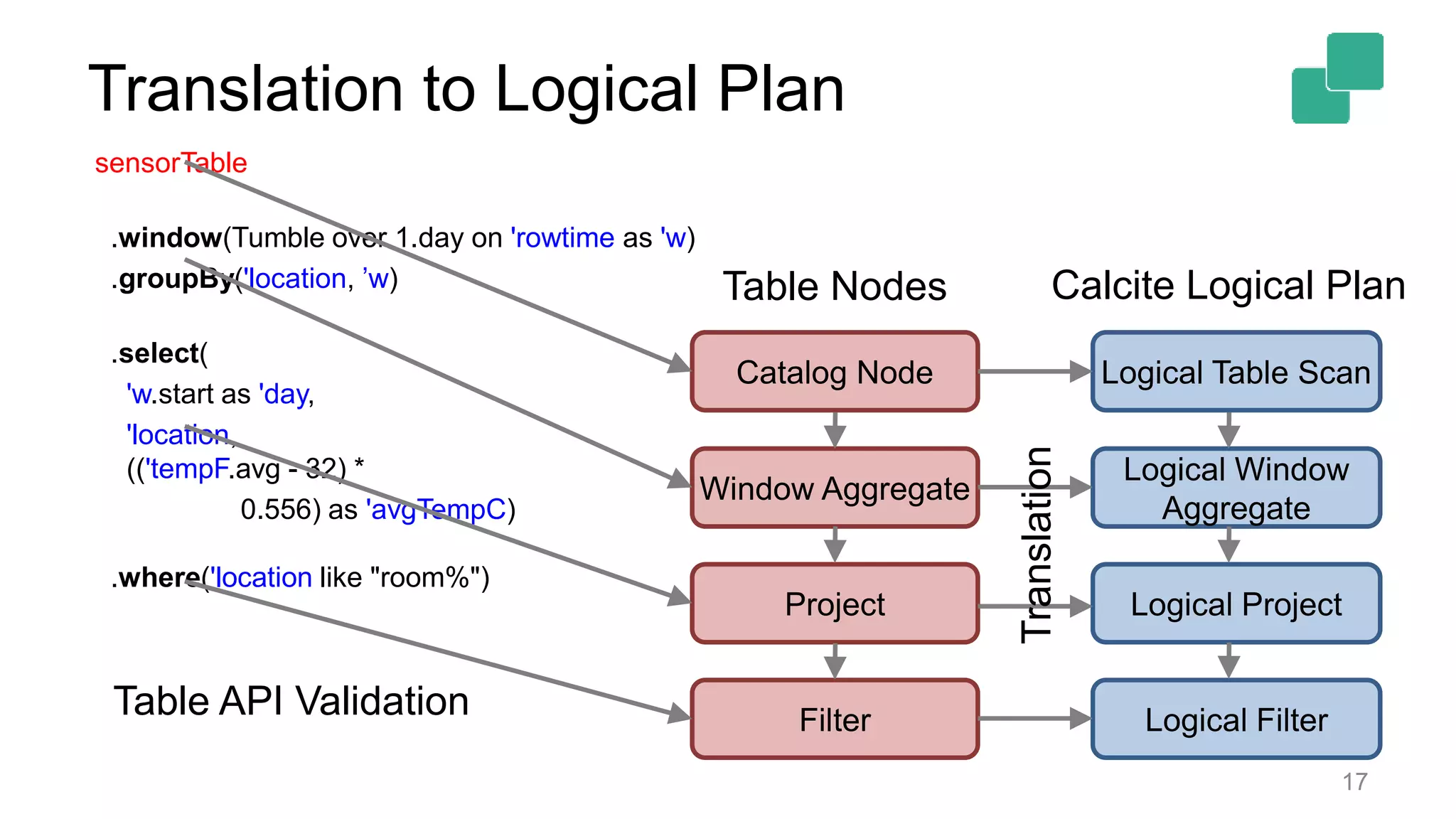
![Windowing in Table API 10 val sensorData: DataStream[(String, Long, Double)] = ??? // convert DataStream into Table val sensorTable: Table = sensorData .toTable(tableEnv, 'location, 'rowtime, 'tempF) // define query on Table val avgTempCTable: Table = sensorTable .window(Tumble over 1.day on 'rowtime as 'w) .groupBy('location, ’w) .select('w.start as 'day, 'location, (('tempF.avg - 32) * 0.556) as 'avgTempC) .where('location like "room%")](https://image.slidesharecdn.com/flinkforwardsf2017timowalthertableandsqlapi-170414102541/75/Flink-Forward-SF-2017-Timo-Walther-Table-SQL-API-unified-APIs-for-batch-and-stream-processing-10-2048.jpg)
![Windowing in SQL 11 val sensorData: DataStream[(String, Long, Double)] = ??? // register DataStream tableEnv.registerDataStream( "sensorData", sensorData, 'location, 'rowtime, 'tempF) // query registered Table val avgTempCTable: Table = tableEnv.sql(""" SELECT TUMBLE_START(TUMBLE(time, INTERVAL '1' DAY) AS day, location, AVG((tempF - 32) * 0.556) AS avgTempC FROM sensorData WHERE location LIKE 'room%’ GROUP BY location, TUMBLE(time, INTERVAL '1' DAY) """)](https://image.slidesharecdn.com/flinkforwardsf2017timowalthertableandsqlapi-170414102541/75/Flink-Forward-SF-2017-Timo-Walther-Table-SQL-API-unified-APIs-for-batch-and-stream-processing-11-2048.jpg)
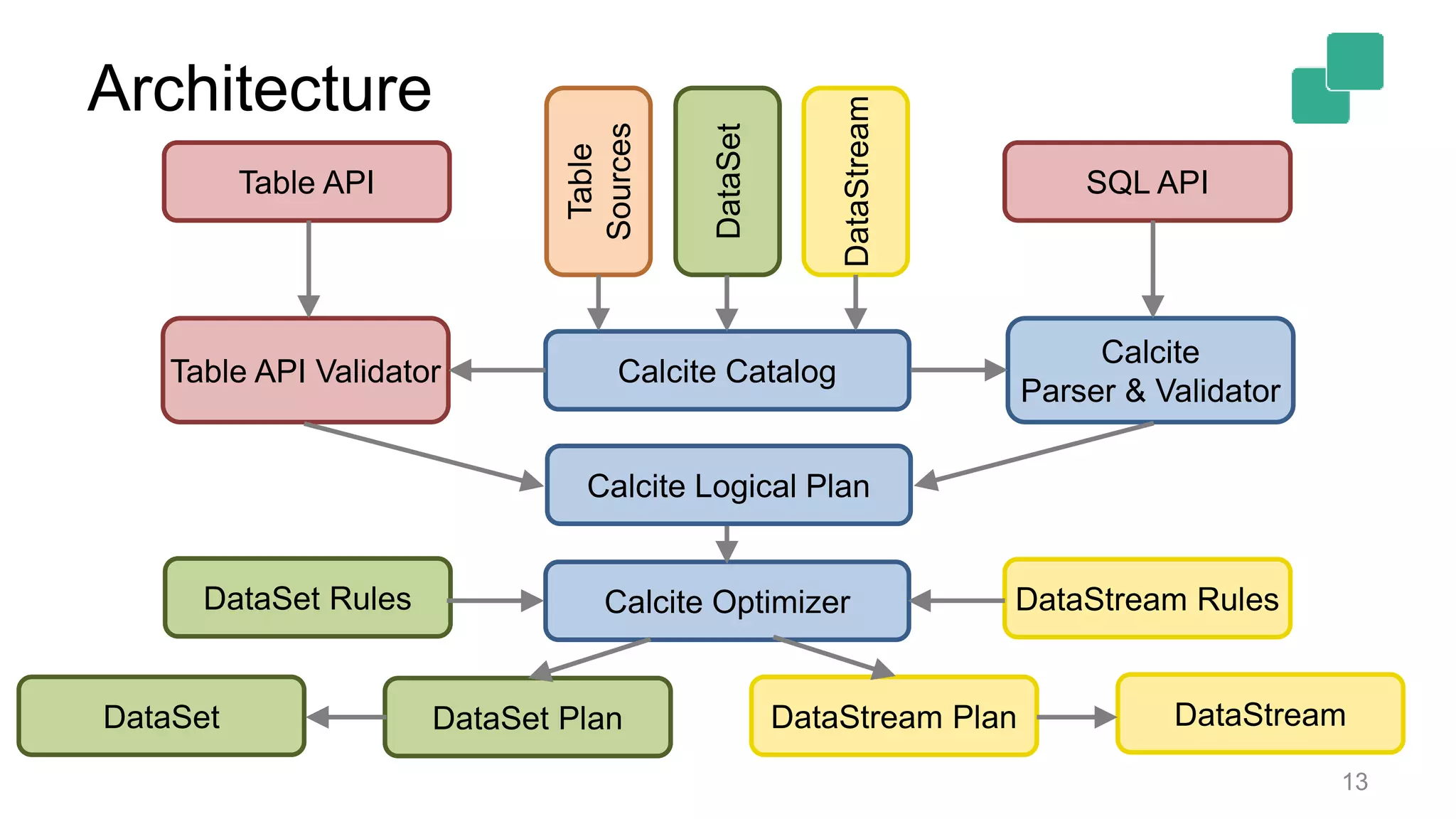
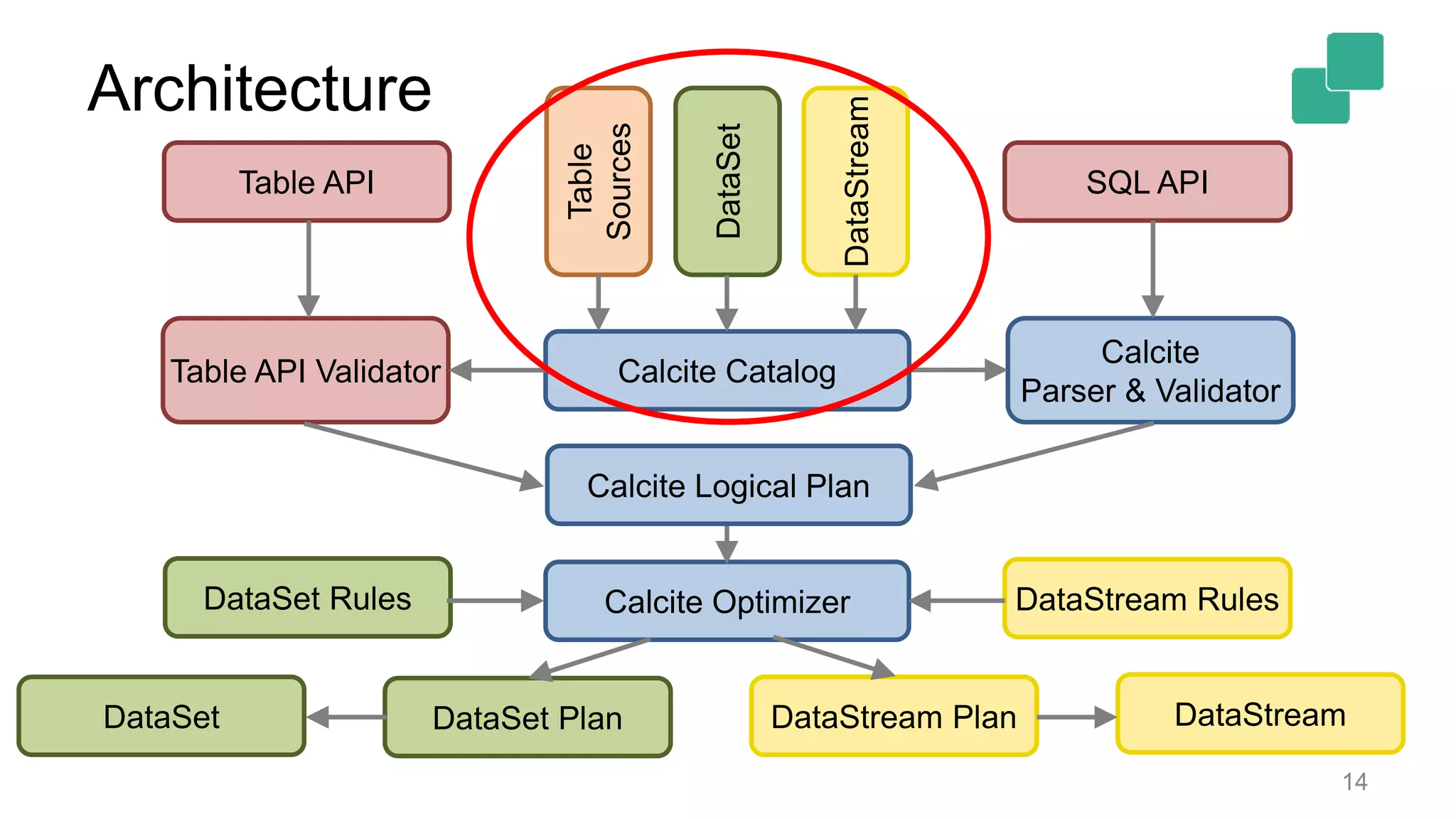
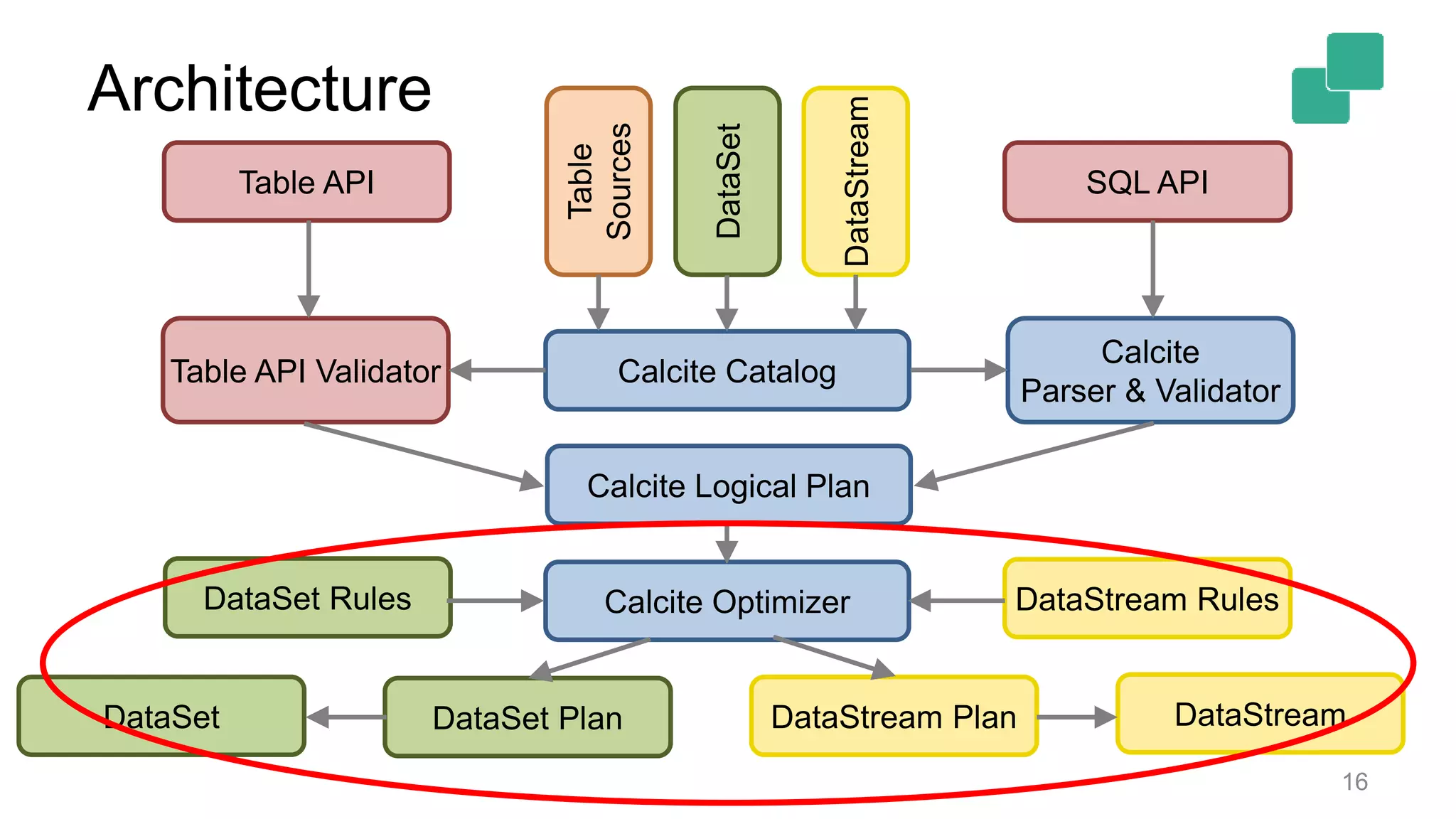
![Architecture 2 APIs [SQL, Table API] * 2 backends [DataStream, DataSet] = 4 different translation paths? 12](https://image.slidesharecdn.com/flinkforwardsf2017timowalthertableandsqlapi-170414102541/75/Flink-Forward-SF-2017-Timo-Walther-Table-SQL-API-unified-APIs-for-batch-and-stream-processing-12-2048.jpg)


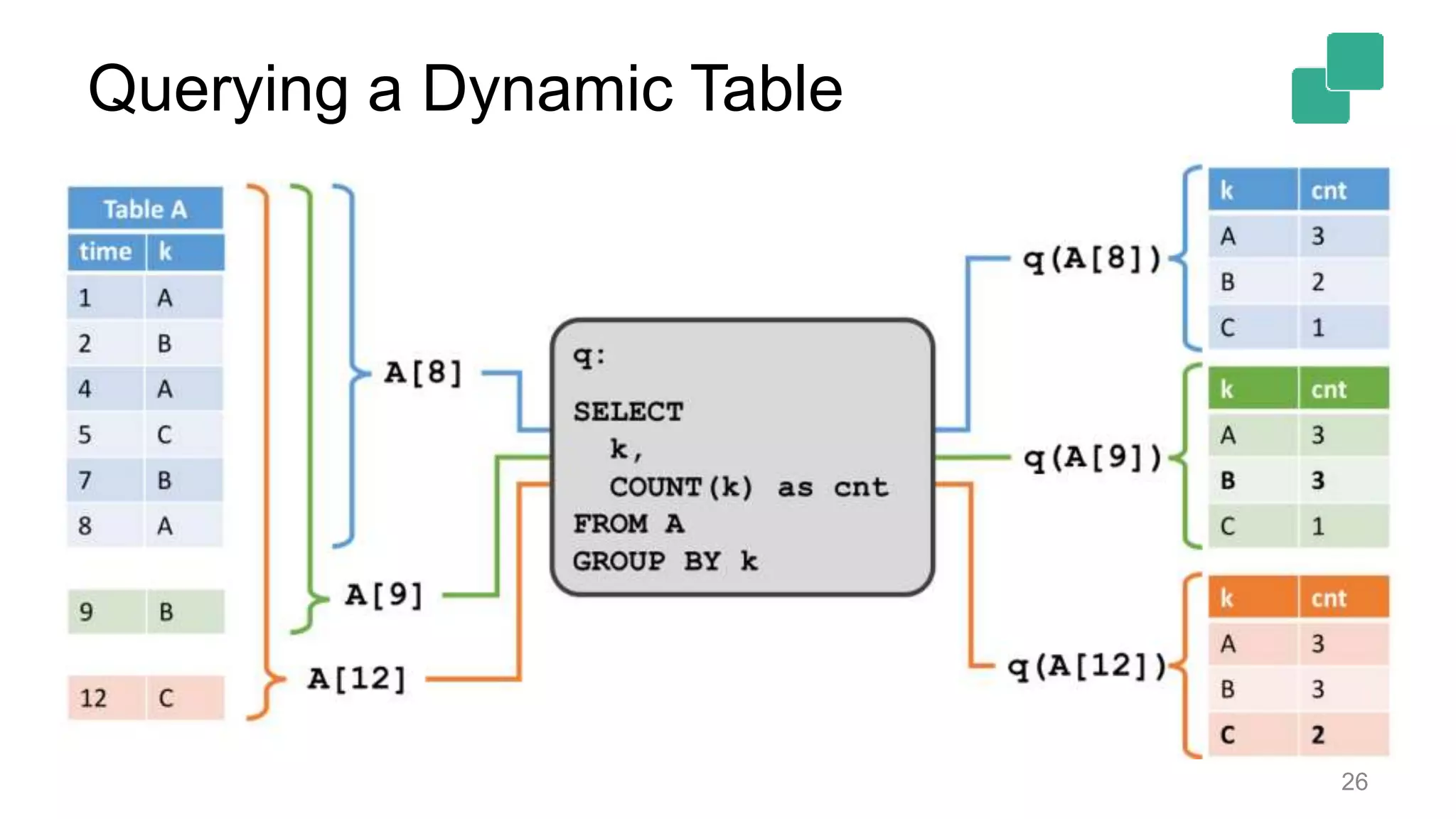
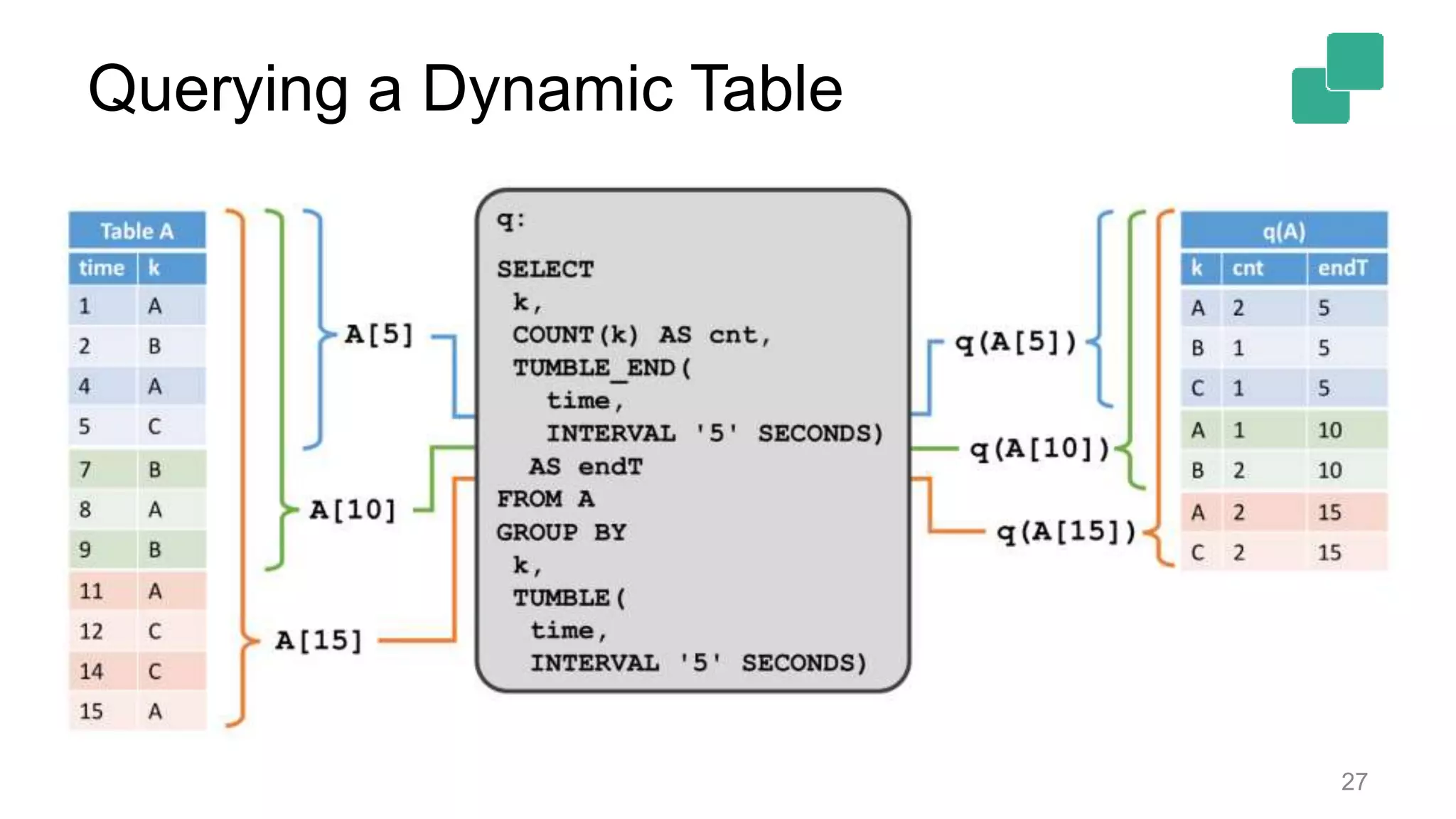
![Querying Dynamic Tables Dynamic tables change over time • A[t]: Table A at specific point in time t Dynamic tables are queried with relational semantics • Result of a query changes as input table changes • q(A[t]): Evaluate query q on table A at time t Query result is continuously updated as t progresses • Similar to maintaining a materialized view • t is current event time 25](https://image.slidesharecdn.com/flinkforwardsf2017timowalthertableandsqlapi-170414102541/75/Flink-Forward-SF-2017-Timo-Walther-Table-SQL-API-unified-APIs-for-batch-and-stream-processing-25-2048.jpg)





This document discusses Flink's Table and SQL APIs, which provide a unified way to write batch and streaming queries. It motivates the need for a relational API by explaining that while Flink's DataStream API is powerful, it requires more technical skills. The Table and SQL APIs allow users to focus on business logic by writing declarative queries. It describes how the APIs work, including translating queries to logical and execution plans and supporting batch, streaming and windowed queries. Finally, it outlines the current capabilities and opportunities for contributors to help expand Flink's relational features.
Timo Walther introduces Apache Flink focusing on its Table and SQL API for batch and stream processing.
The DataStream API allows expressive stream processing but is complex, requiring skilled programming.
A relational API is easier, declarative, and can optimize queries, providing a familiar SQL interface.
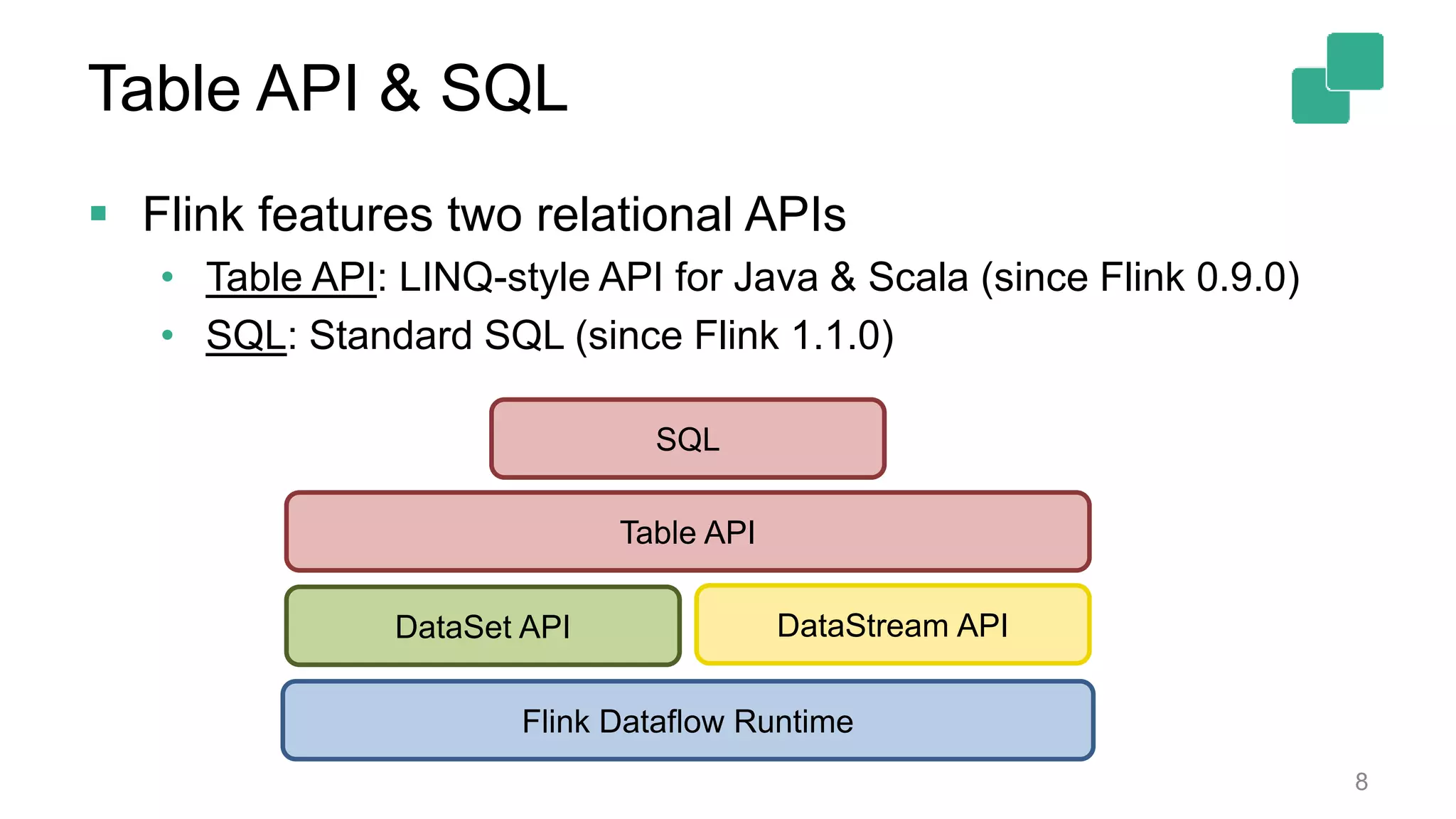
Flink offers two relational APIs: Table API for Java/Scala and standard SQL, enabling versatile data operations.
Examples of implementing windowing mechanisms in Table API and SQL for stream processing applications.
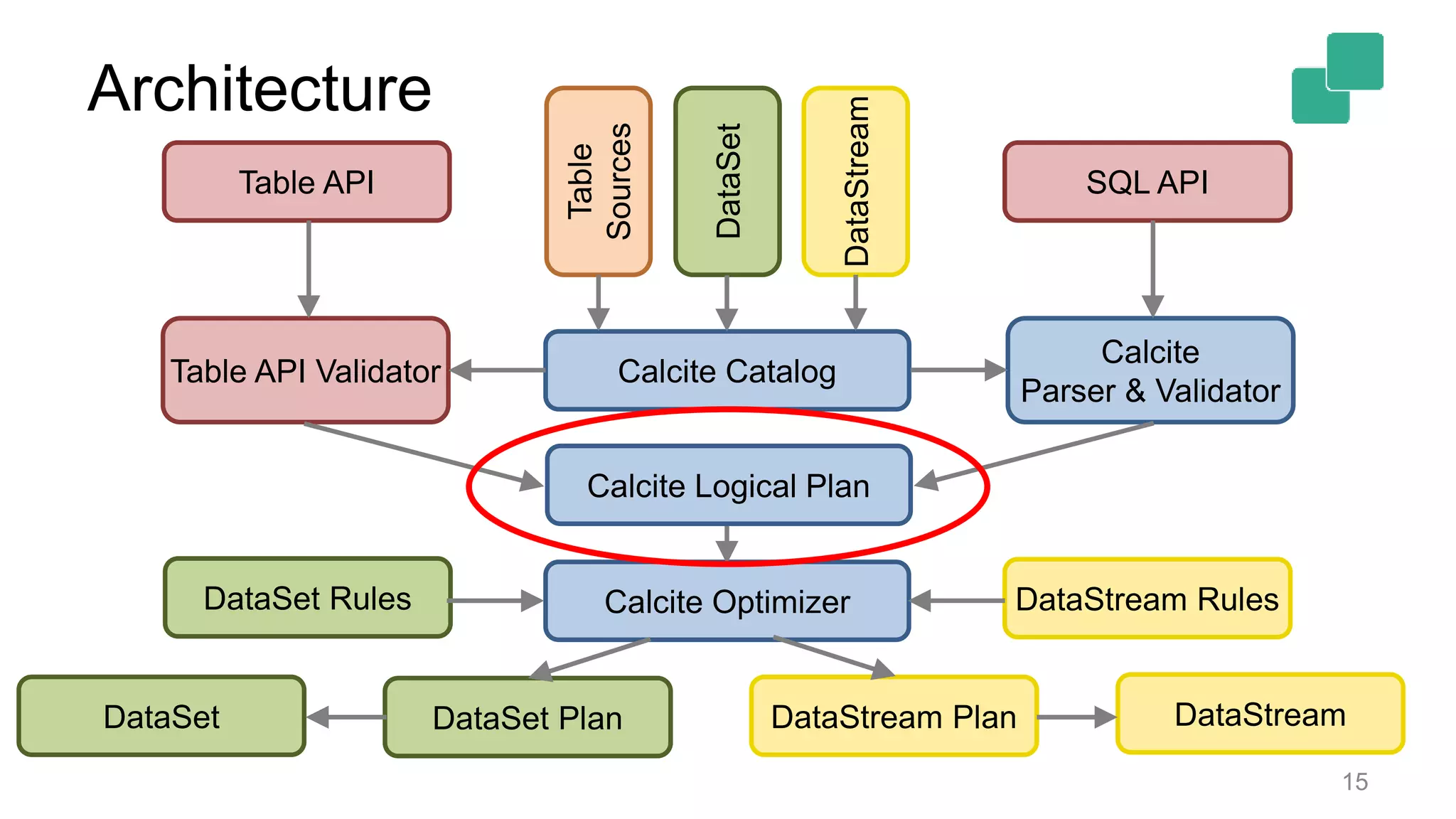
Architecture details show translation paths between SQL/Table APIs and backends, highlighting four paths.
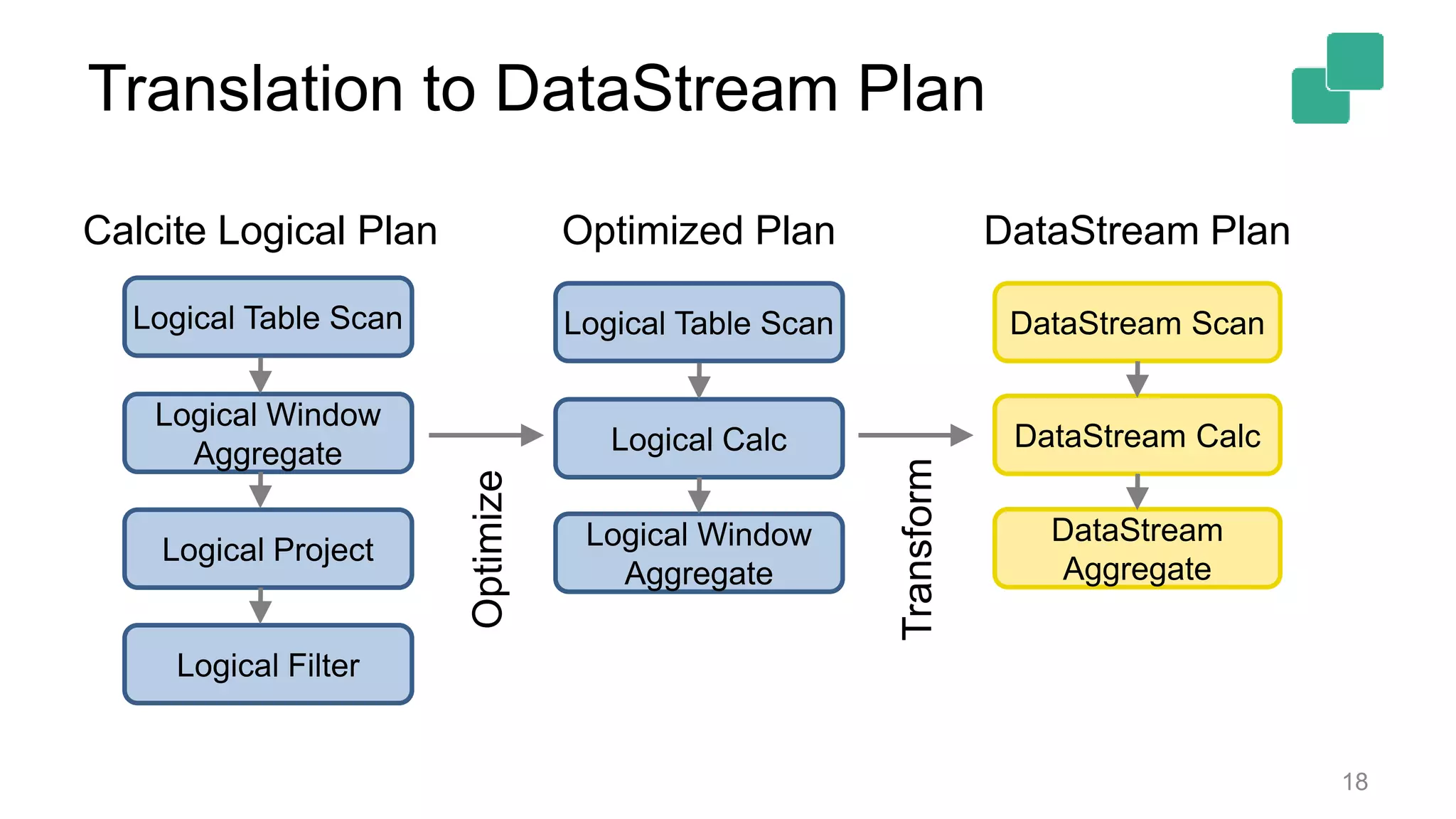
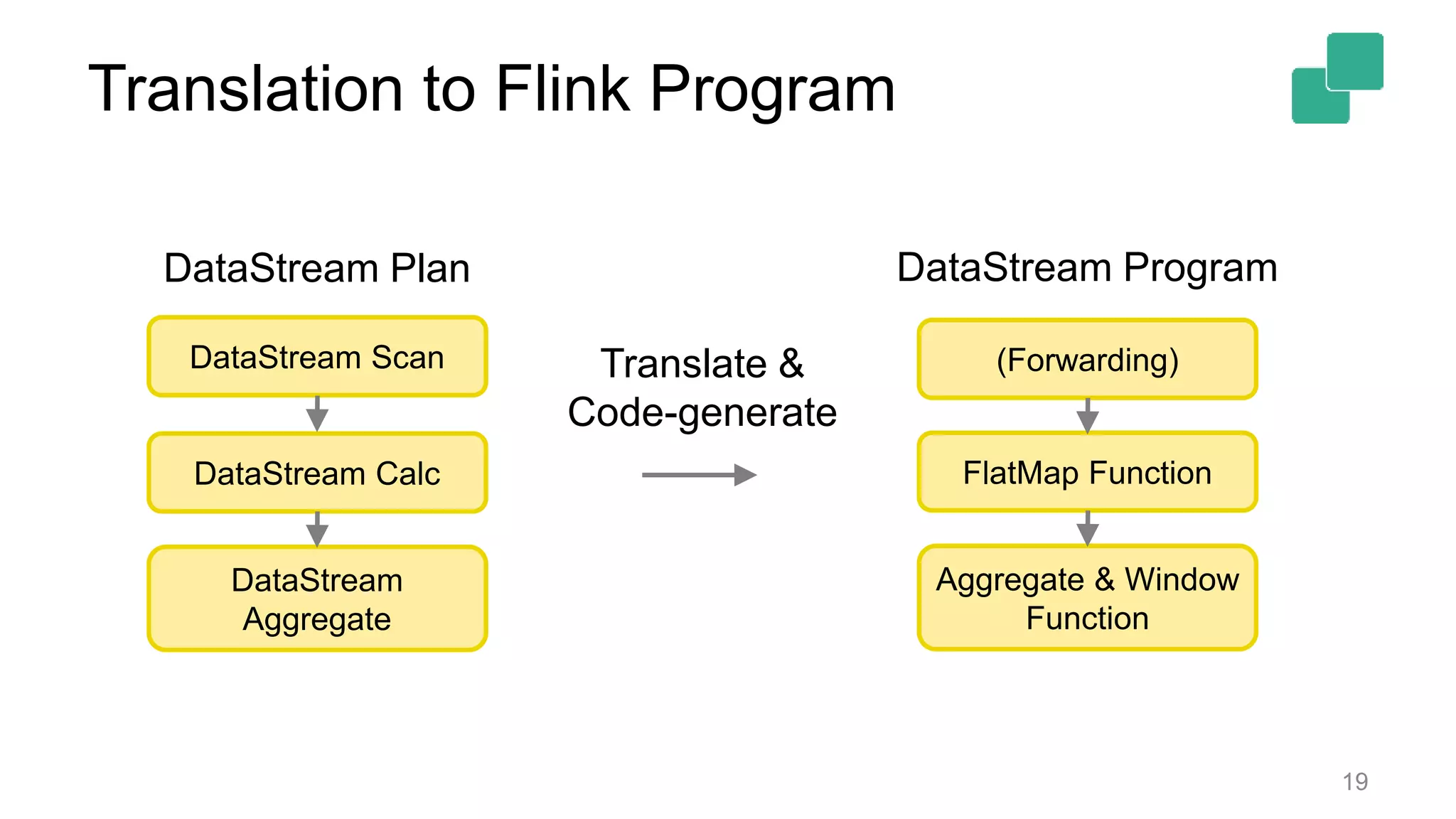
Describes the logical plan translation of Table API queries into DataStream operations for execution.
Current batch and streaming features of Flink include extensive SQL capabilities and windowing logic.
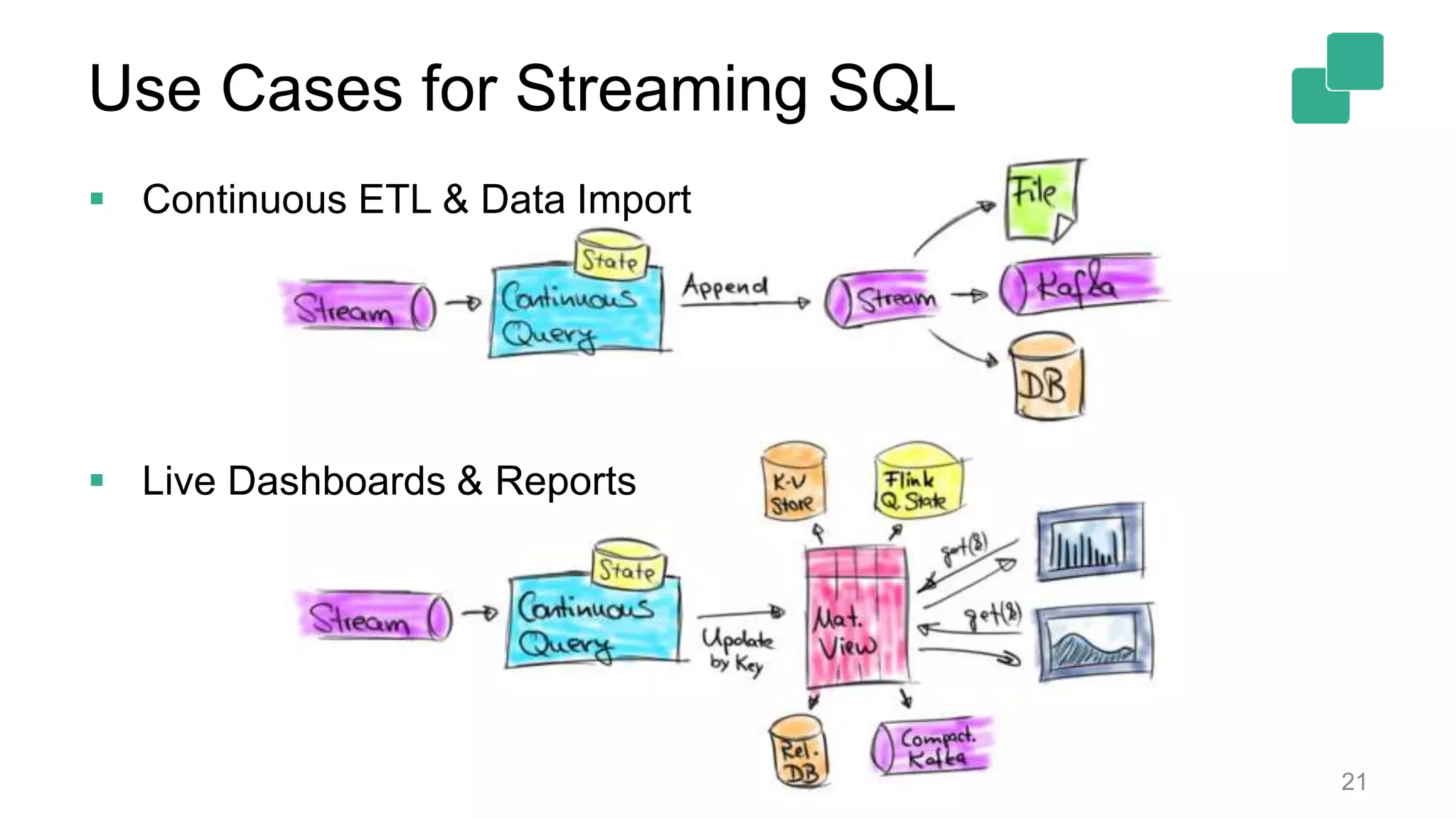
Use cases for Streaming SQL include continuous data import and real-time dashboards.
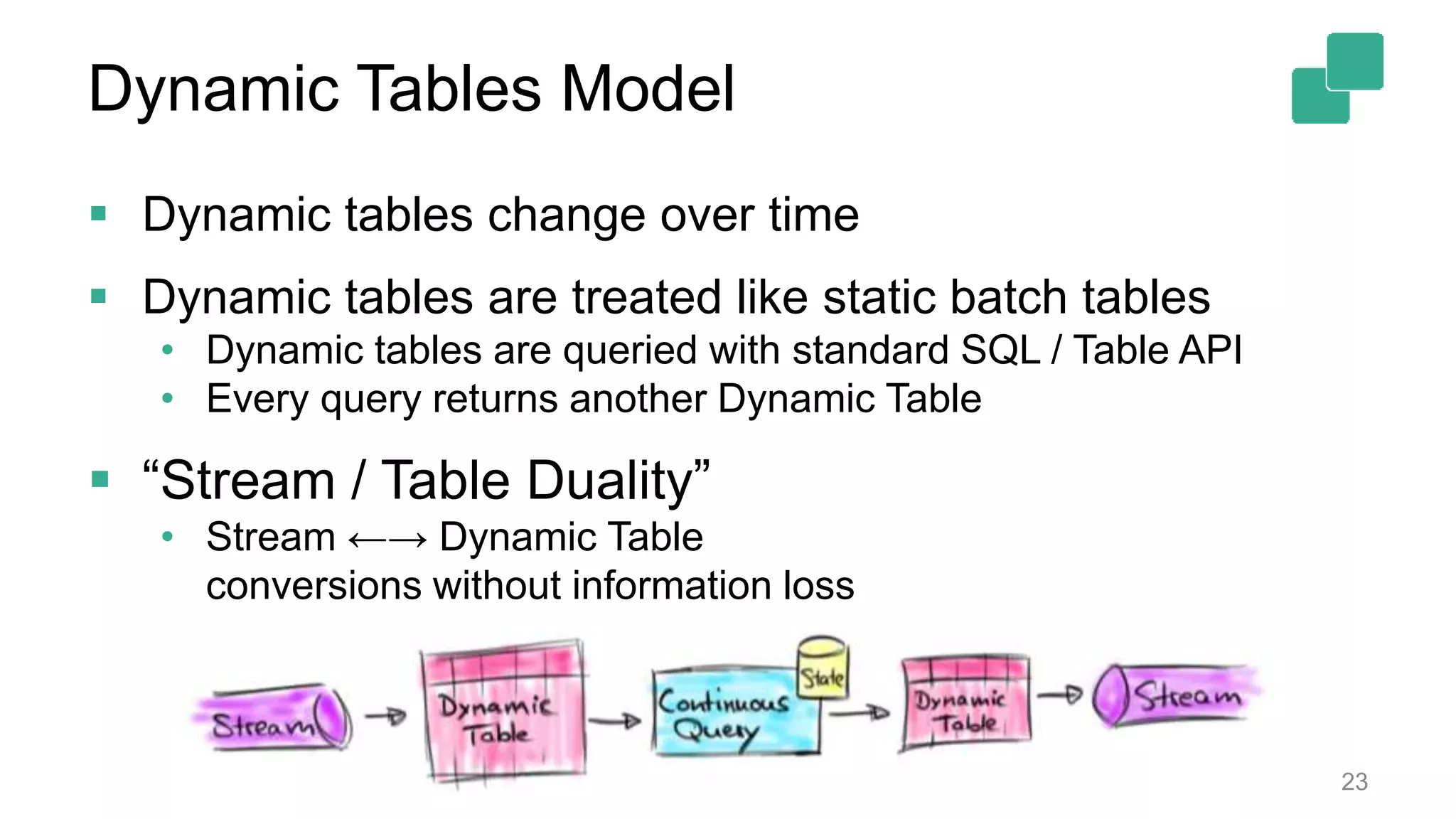
Dynamic tables represent time-variant data that can be queried with standard SQL semantics.
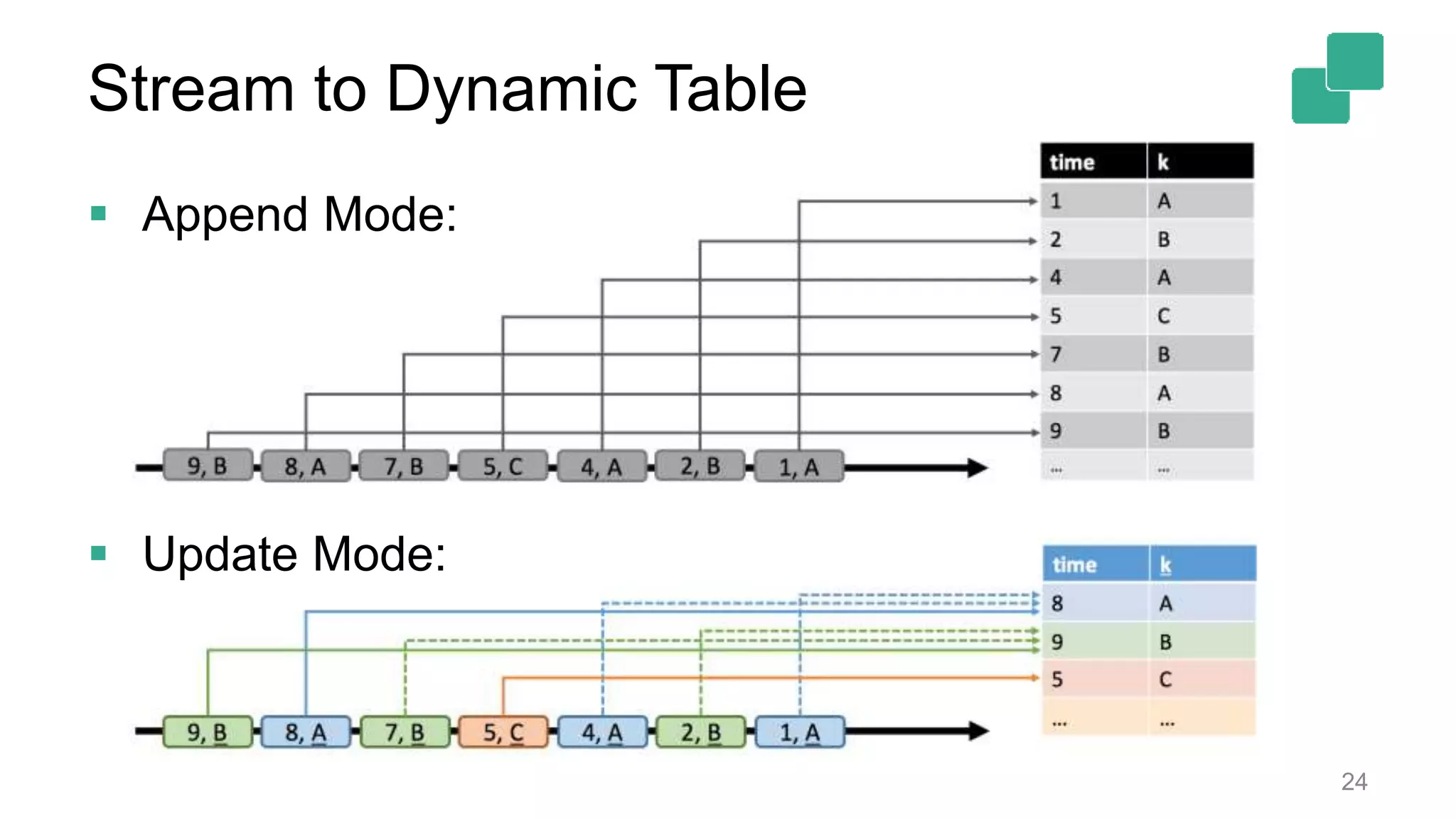
Dynamic tables can be queried as they change over time, with specific limitations on state growth.
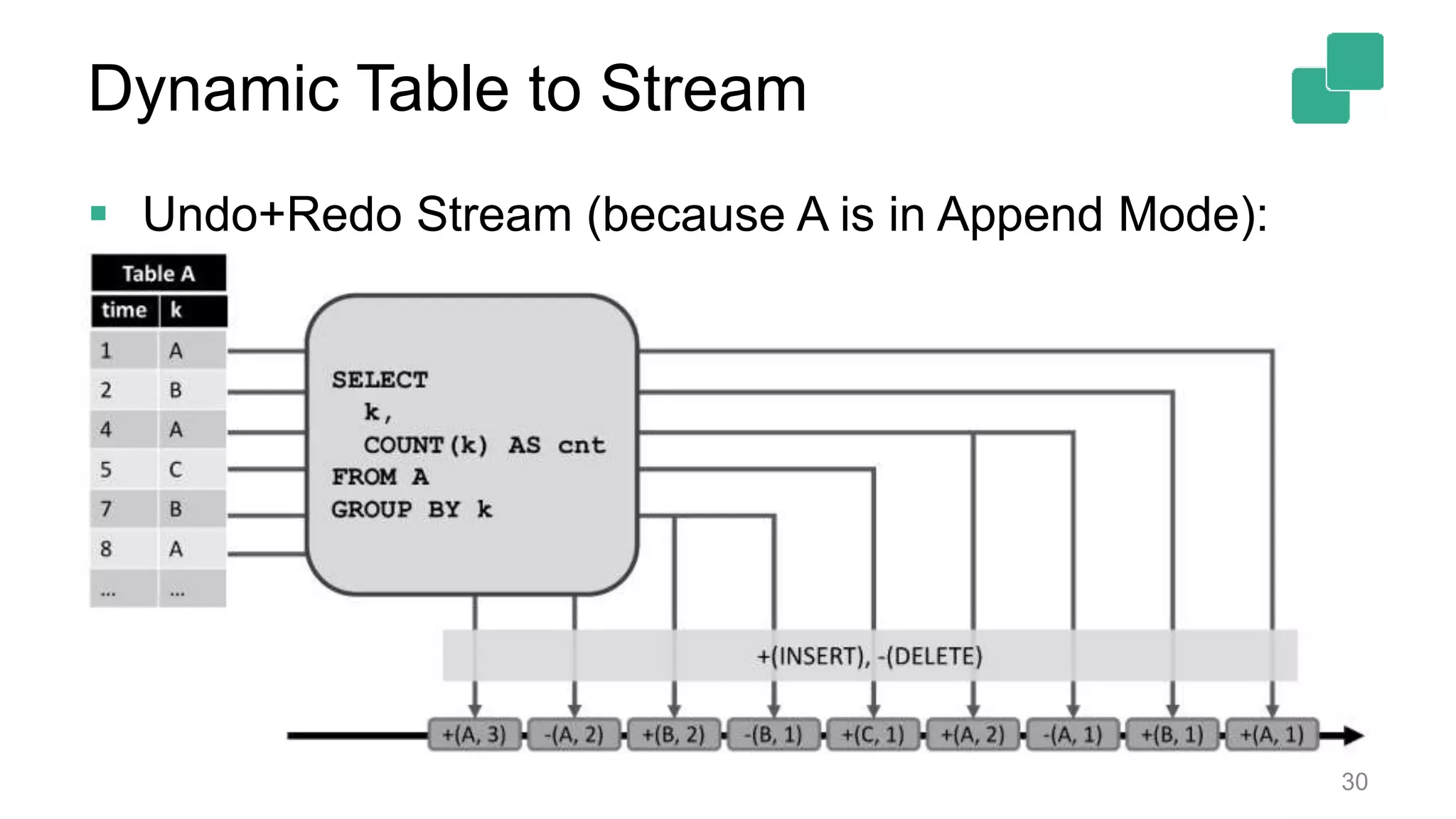
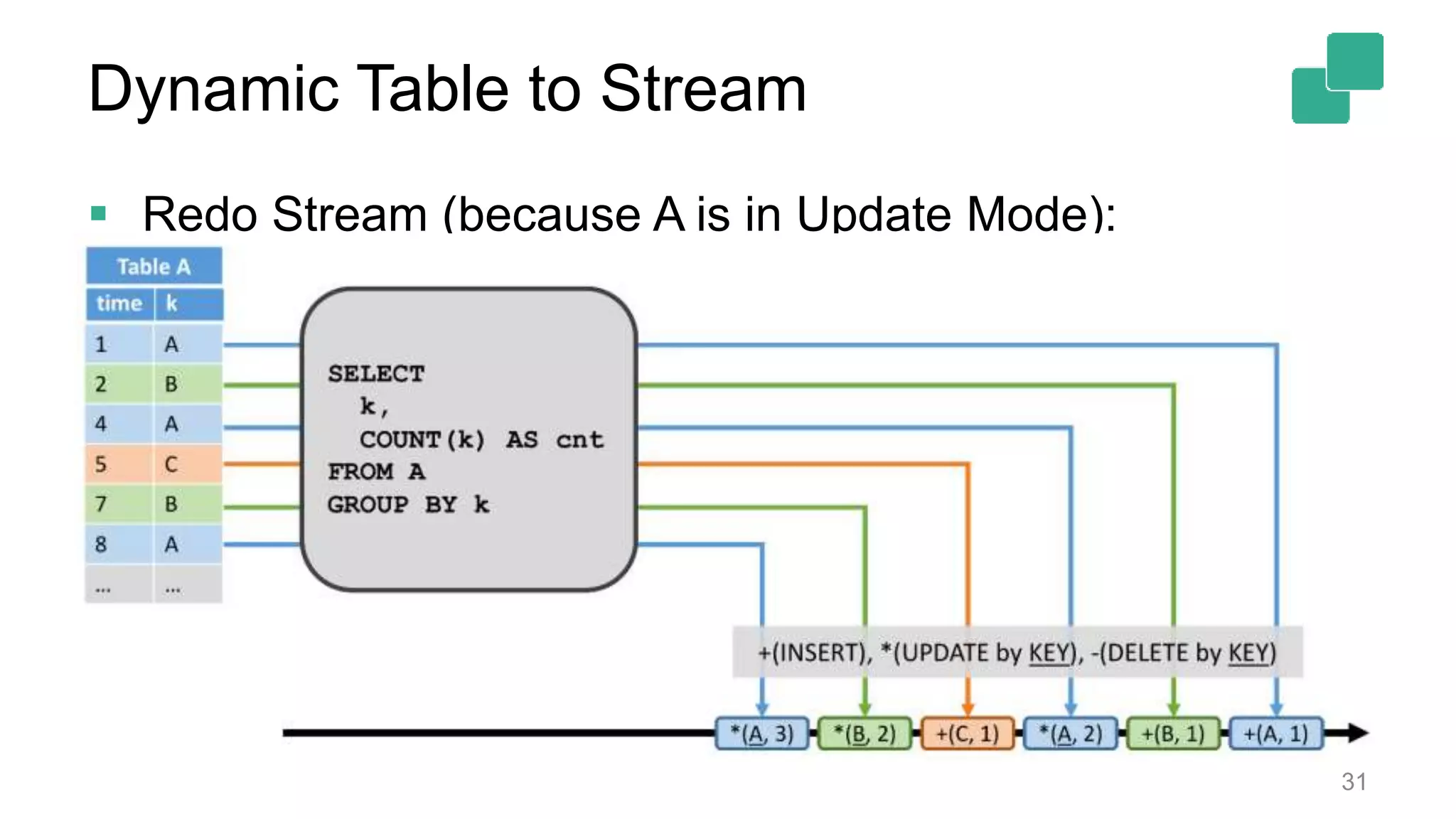
Dynamic table modifications can be converted to streams, enhancing real-time data tracking.
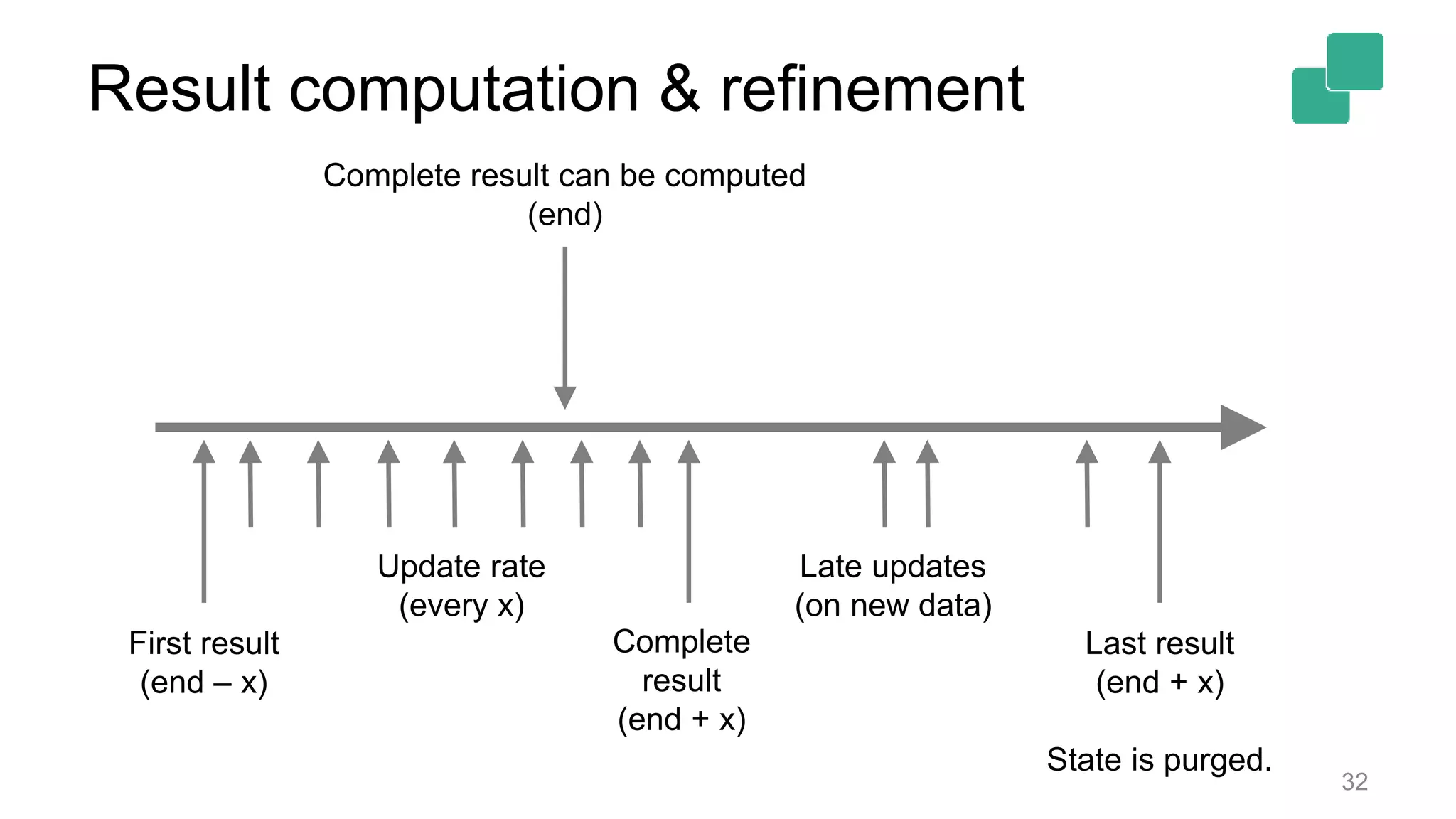
Discusses handling results and state management in dynamic contexts, focusing on late updates and completions.
Encouragement for community contributions to improve the project along with a thanks note.