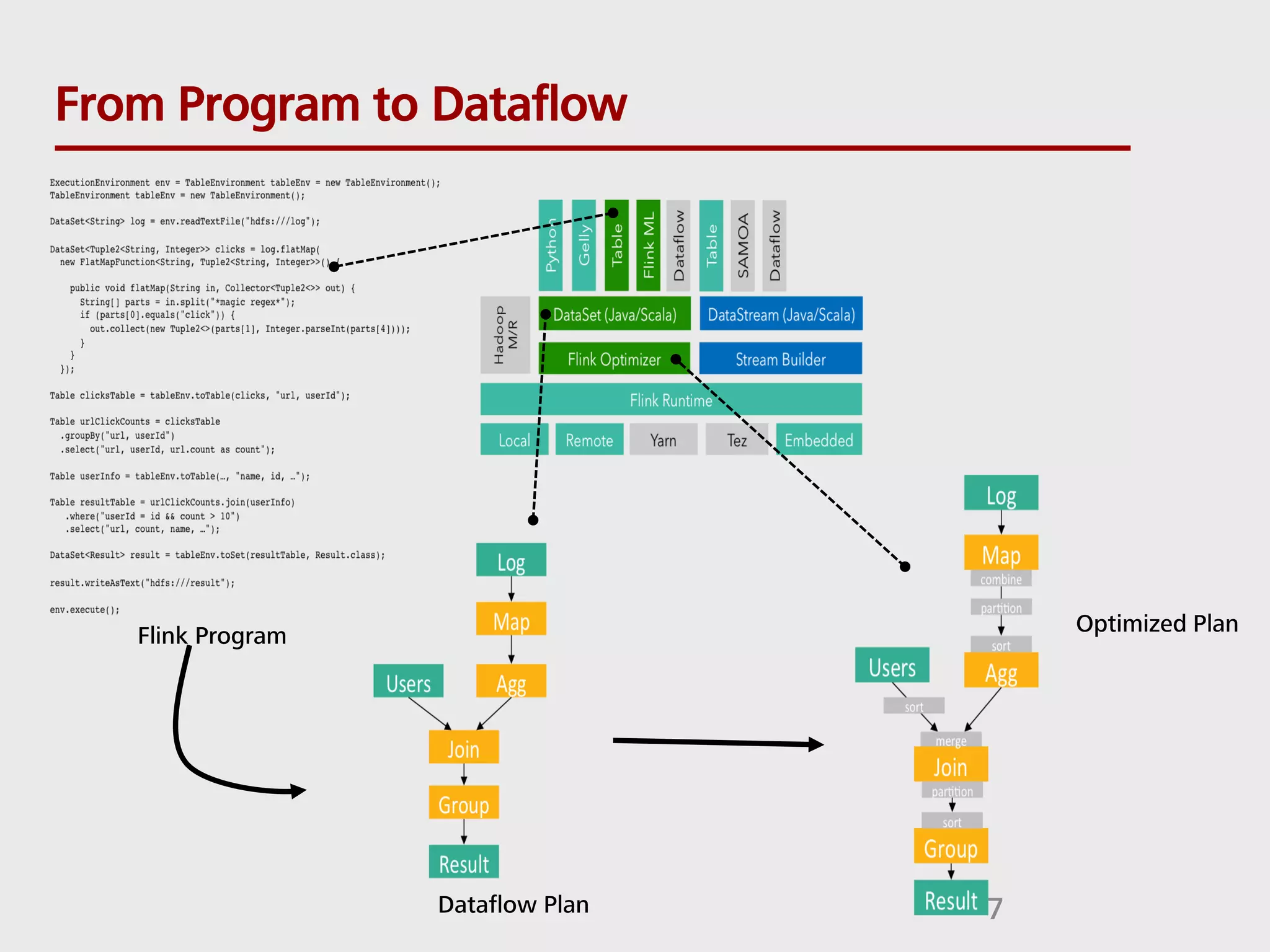
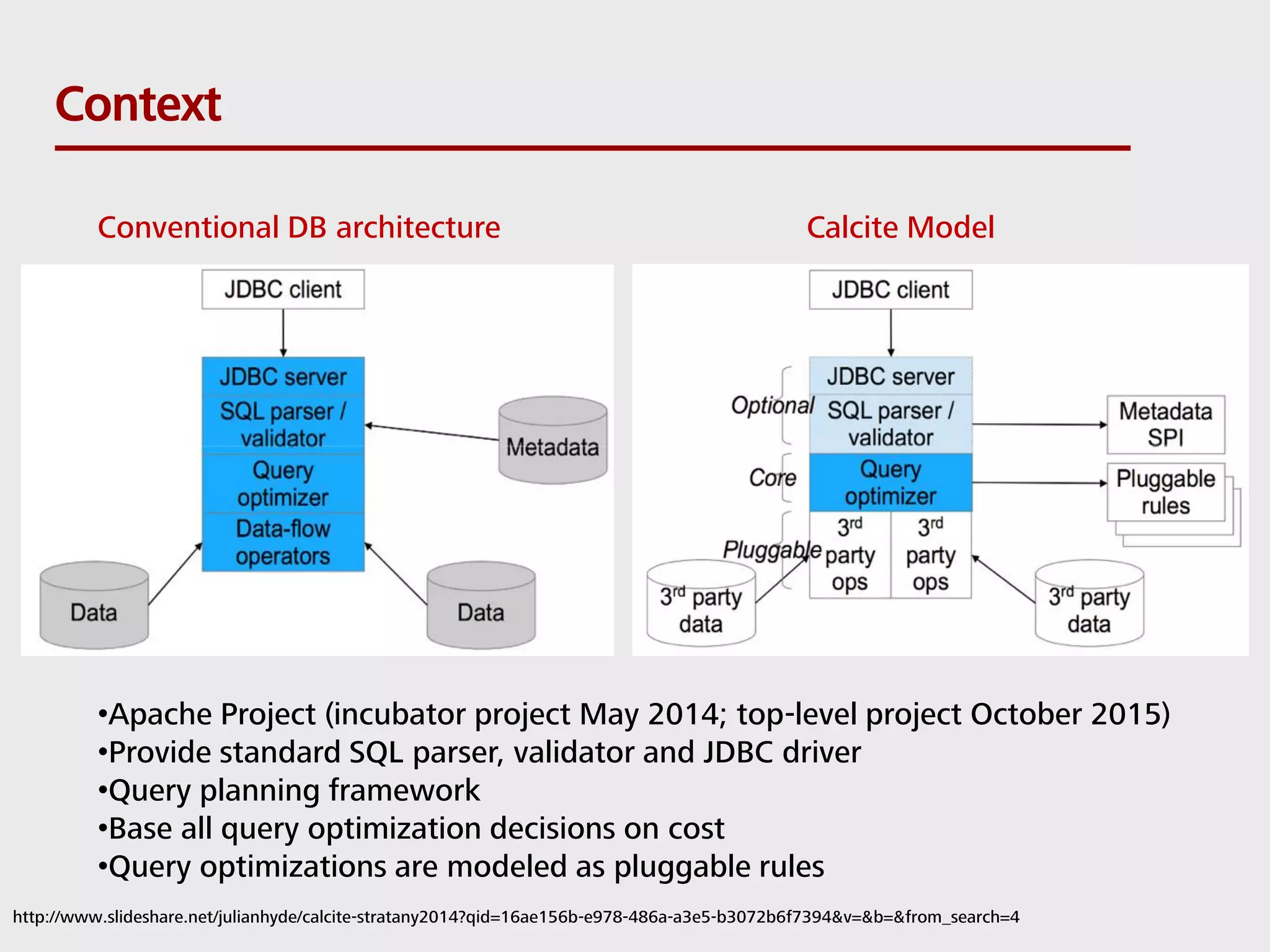
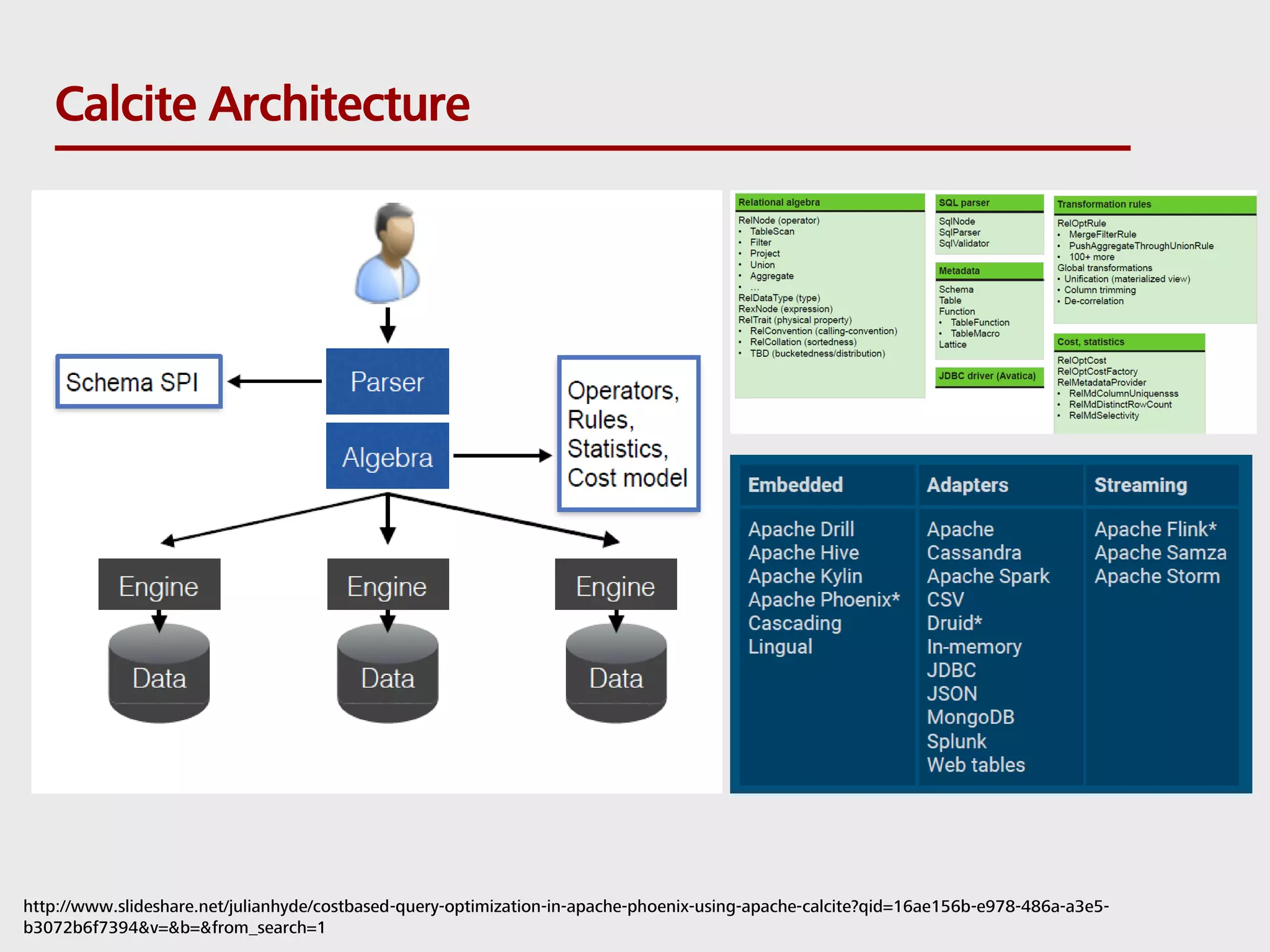
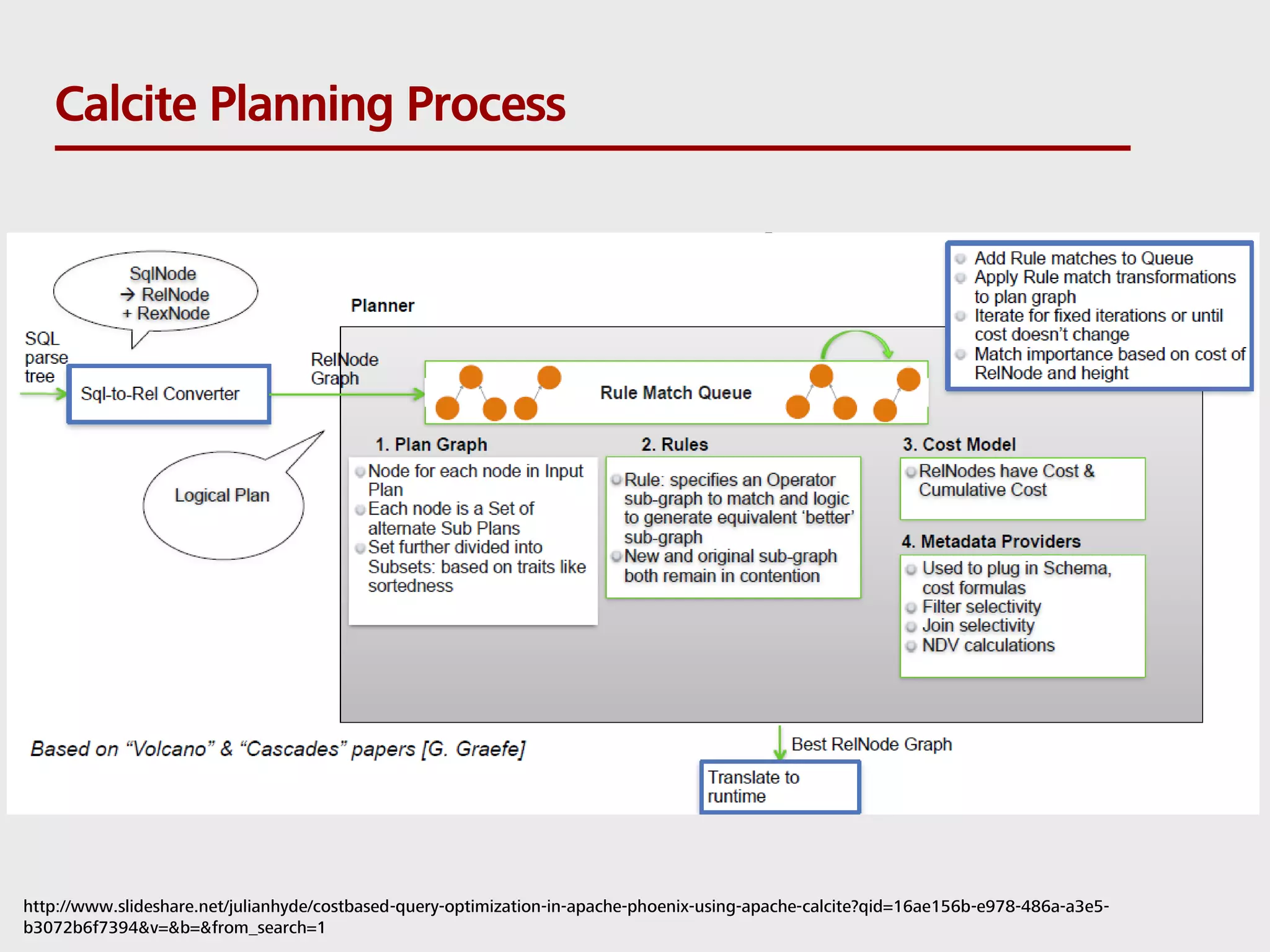
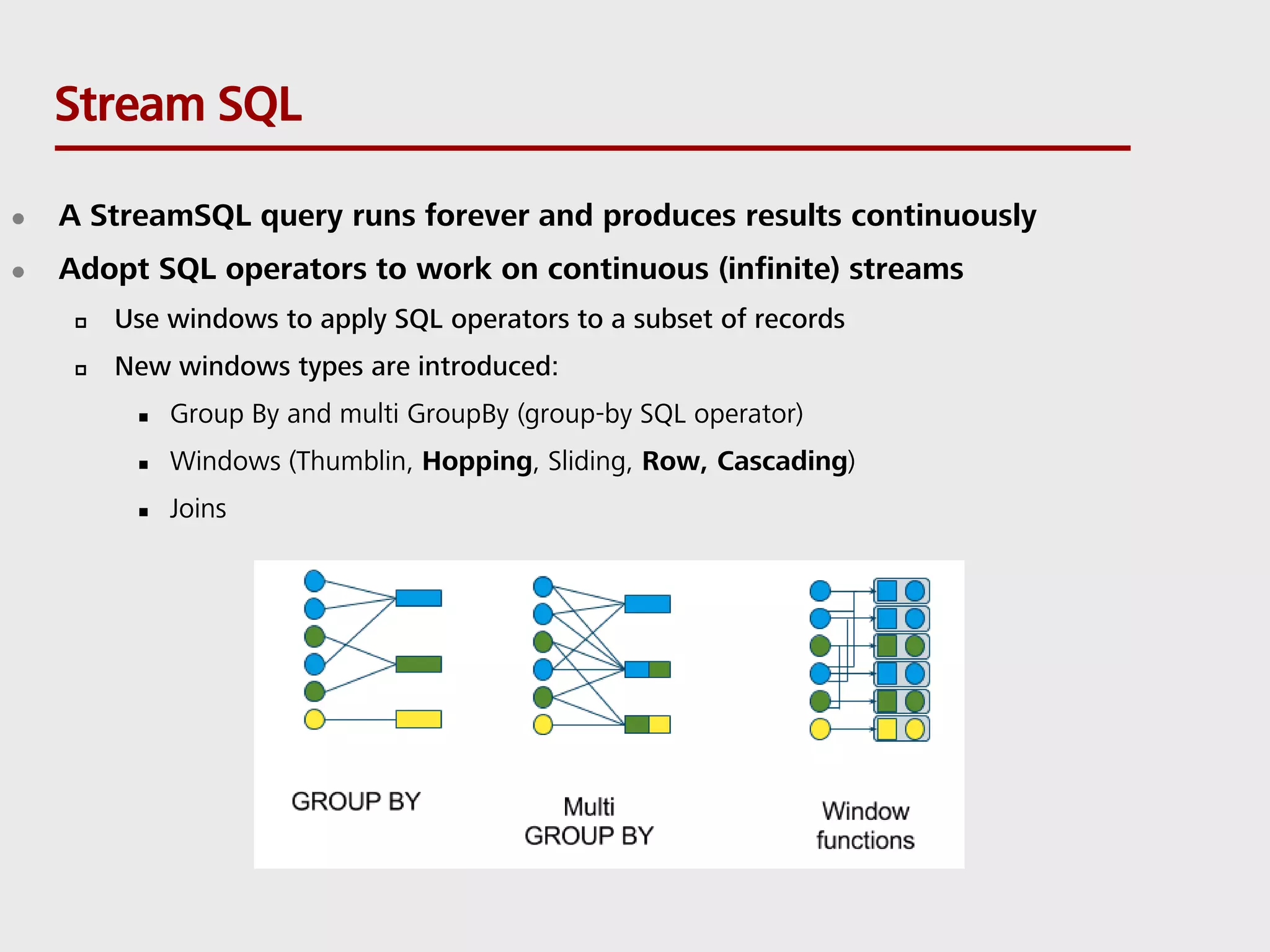
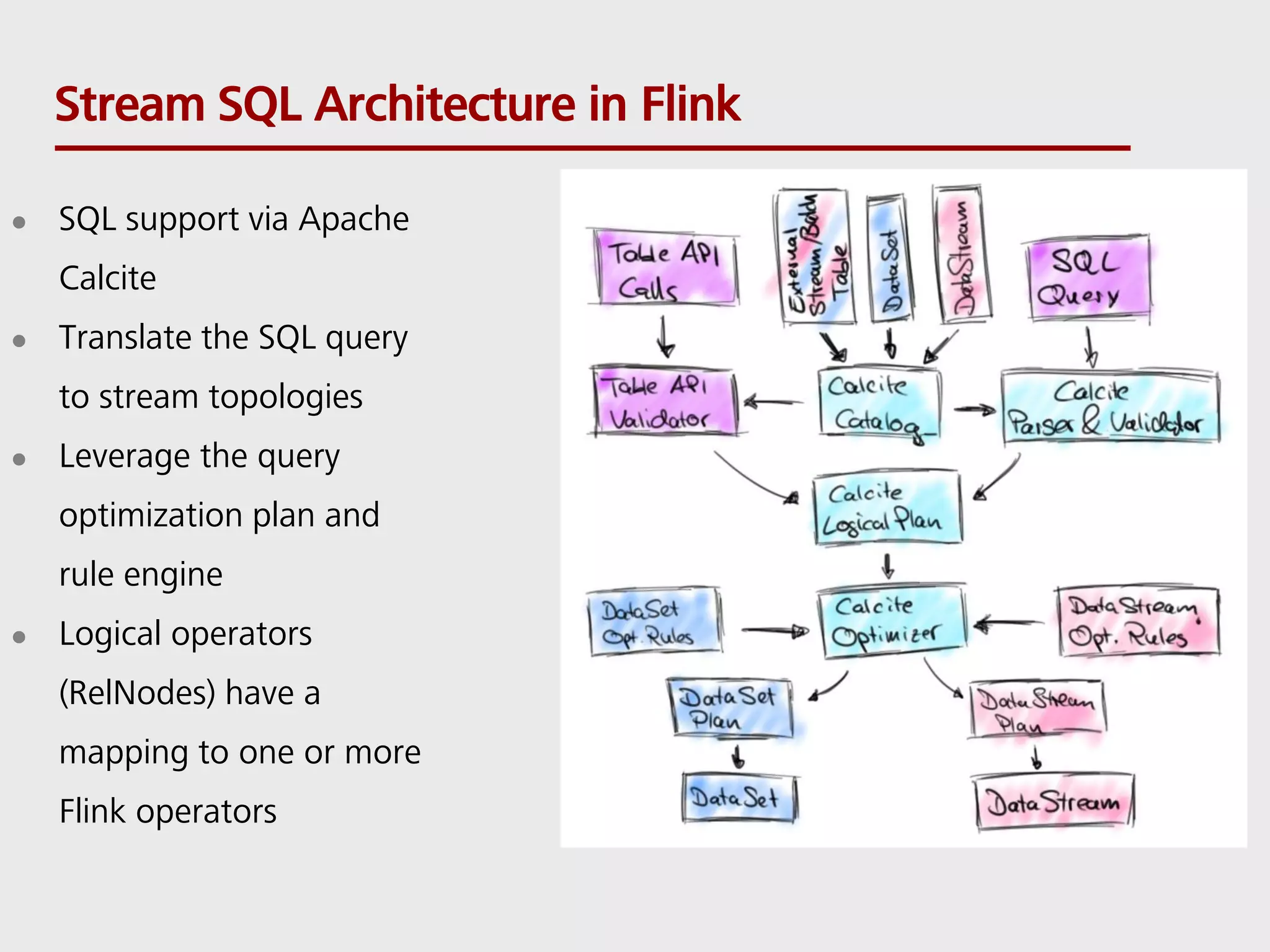
SQL can be used to query both streaming and batch data. Apache Flink and Apache Calcite enable SQL queries on streaming data. Flink uses its Table API and integrates with Calcite to translate SQL queries into dataflow programs. This allows standard SQL to be used for both traditional batch analytics on finite datasets and stream analytics producing continuous results from infinite data streams. Queries are executed continuously by applying operators within windows to subsets of streaming data.



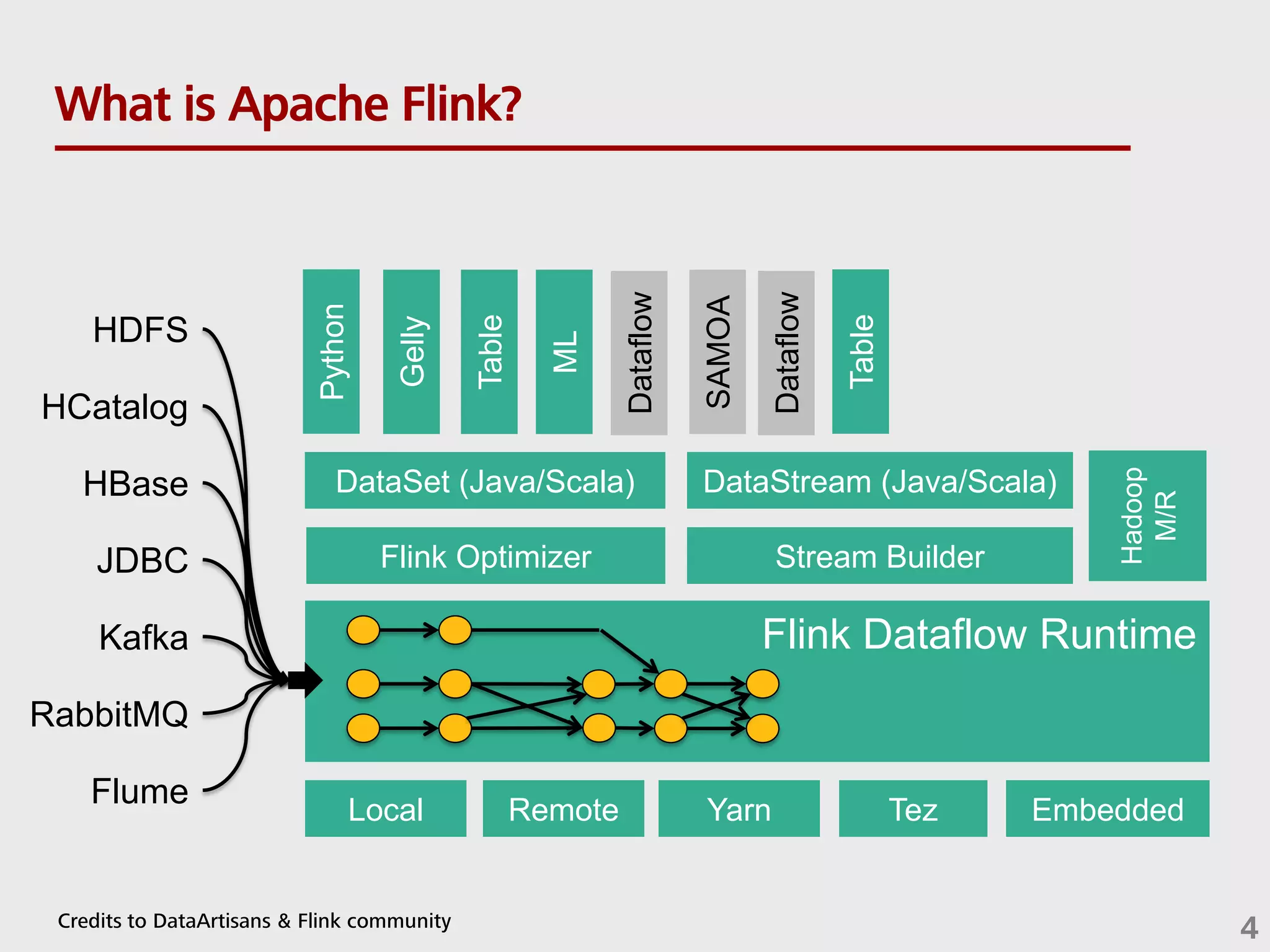
![Technology inside Flink case class Path (from: Long, to: Long) val tc = edges.iterate(10) { paths: DataSet[Path] => val next = paths .join(edges) .where("to") .equalTo("from") { (path, edge) => Path(path.from, edge.to) } .union(paths) .distinct() next } Cost-based optimizer Type extraction stack Task scheduling Recovery metadata Pre-flight (Client) Master Workers DataSourc e orders.tbl Filter Map DataSourc e lineitem.tbl Join Hybrid Hash build HT probe hash-part [0] hash-part [0] GroupRed sort forward Program Dataflow Graph Memory manager Out-of-core algos Batch & Streaming State & Checkpoints deploy operators track intermediate results Credits to DataArtisans & Flink community 5](https://image.slidesharecdn.com/sqlonstreams2share-160810063345/75/Towards-sql-for-streams-5-2048.jpg)