Download as PDF, PPTX









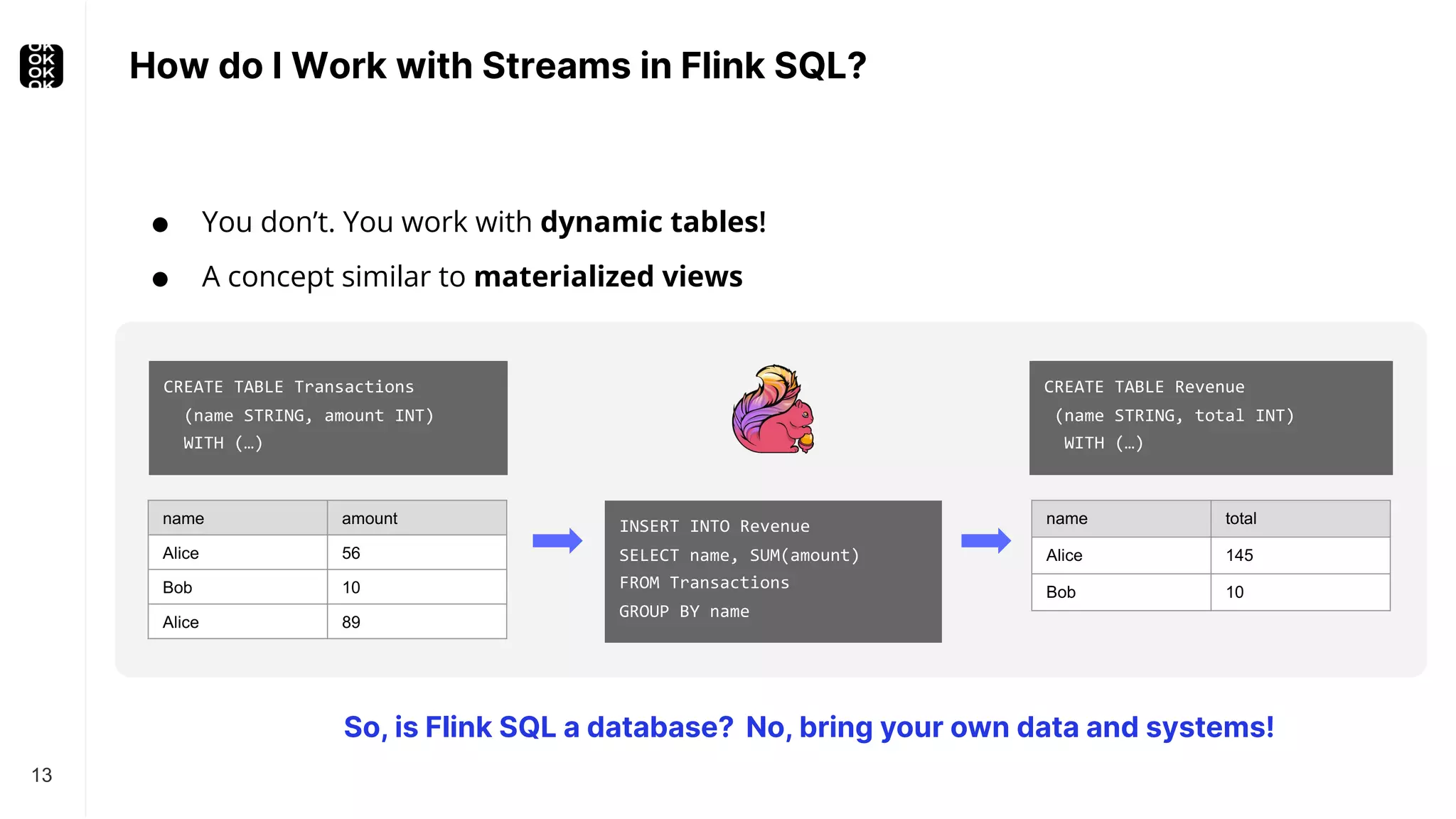
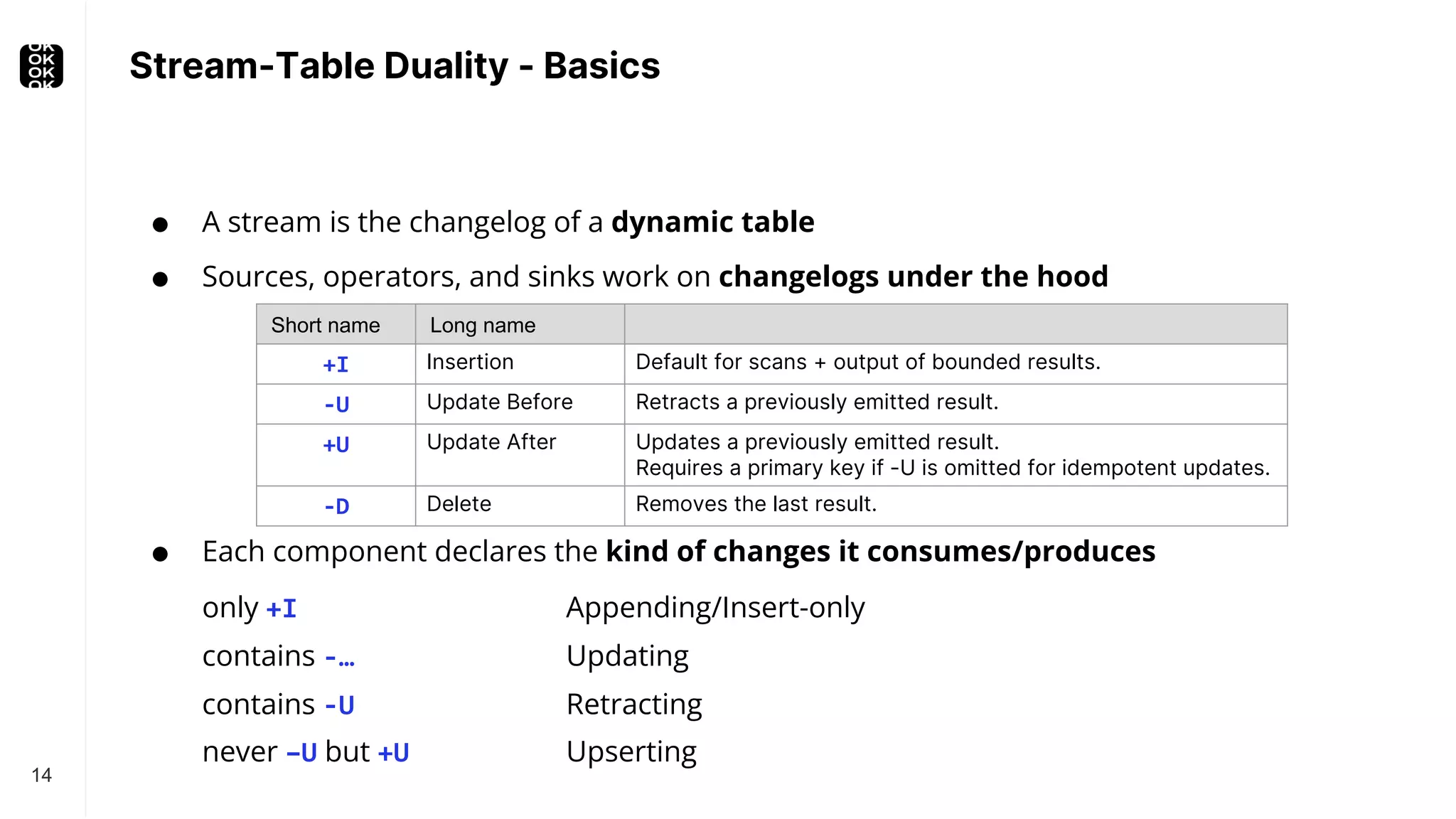
![Stream-Table Duality - Example 15 An applied changelog becomes a real (materialized) table. name amount Alice 56 Bob 10 Alice 89 name total Alice 56 Bob 10 changelog +I[Alice, 89] +I[Bob, 10] +I[Alice, 56] +U[Alice, 145] -U[Alice, 56] +I[Bob, 10] +I[Alice, 56] 145 materialization CREATE TABLE Revenue (name STRING, total INT) WITH (…) INSERT INTO Revenue SELECT name, SUM(amount) FROM Transactions GROUP BY name CREATE TABLE Transactions (name STRING, amount INT) WITH (…)](https://image.slidesharecdn.com/timowaltherbr0762022-9-221023172317-803bf70e/75/CDC-Stream-Processing-With-Apache-Flink-With-Timo-Walther-Current-2022-15-2048.jpg)
![Stream-Table Duality - Example 16 An applied changelog becomes a real (materialized) table. name amount Alice 56 Bob 10 Alice 89 name total Alice 56 Bob 10 +I[Alice, 89] +I[Bob, 10] +I[Alice, 56] +U[Alice, 145] -U[Alice, 56] +I[Bob, 10] +I[Alice, 56] 145 materialization CREATE TABLE Revenue (PRIMARY KEY(name) …) WITH (…) INSERT INTO Revenue SELECT name, SUM(amount) FROM Transactions GROUP BY name CREATE TABLE Transactions (name STRING, amount INT) WITH (…) Save ~50% of traffic if downstream system supports upserting!](https://image.slidesharecdn.com/timowaltherbr0762022-9-221023172317-803bf70e/75/CDC-Stream-Processing-With-Apache-Flink-With-Timo-Walther-Current-2022-16-2048.jpg)

![Retract vs. Upsert 18 Retract ● No primary key requirements ● Works for almost every external system ● Supports duplicate rows ● In distributed system often unavoidable à most flexible changelog mode à default mode Upsert ● Traffic + computation optimization ● In-place updates (idempotency) SELECT c, COUNT(*) FROM ( SELECT COUNT(*) AS c FROM T GROUP BY user ) GROUP BY c Count 1 Subtask 1 Count 2 Subtask 1 Subtask 2 +U[1] +U[2] +I[…] 1=>1 2=>1 Subtask 2 +I[…]](https://image.slidesharecdn.com/timowaltherbr0762022-9-221023172317-803bf70e/75/CDC-Stream-Processing-With-Apache-Flink-With-Timo-Walther-Current-2022-18-2048.jpg)
![Changelog Insights – Append-only 19 CREATE TABLE Transaction (tid BIGINT, amount INT); CREATE TABLE Payment (tid BIGINT, method STRING); CREATE TABLE Result (tid BIGINT, …); // accepts all changes INSERT INTO Result SELECT * FROM Transactions T JOIN Payments P ON T.tid = P.tid; Sink(table=[Result], changelogMode=[NONE]) +- Join(leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey], changelogMode=[I]) :- Exchange(changelogMode=[I]) : +- TableSourceScan(table=[[Transaction]], changelogMode=[I]) +- Exchange(changelogMode=[I]) +- TableSourceScan(table=[[Payment]], changelogMode=[I])](https://image.slidesharecdn.com/timowaltherbr0762022-9-221023172317-803bf70e/75/CDC-Stream-Processing-With-Apache-Flink-With-Timo-Walther-Current-2022-19-2048.jpg)
![Changelog Insights – Updating 20 CREATE TABLE Transaction (tid BIGINT, amount INT); CREATE TABLE Payment (tid BIGINT, method STRING); CREATE TABLE Result (tid BIGINT, …); INSERT INTO Result SELECT * FROM Transactions T LEFT JOIN Payments P ON T.tid = P.tid; Sink(table=[Result], changelogMode=[NONE]) +- Join(leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey], changelogMode=[I,UB,UA,D]) :- Exchange(changelogMode=[I]) : +- TableSourceScan(table=[[Transaction]], changelogMode=[I]) +- Exchange(changelogMode=[I]) +- TableSourceScan(table=[[Payment]], changelogMode=[I])](https://image.slidesharecdn.com/timowaltherbr0762022-9-221023172317-803bf70e/75/CDC-Stream-Processing-With-Apache-Flink-With-Timo-Walther-Current-2022-20-2048.jpg)
![Changelog Insights – Updating with PK 21 CREATE TABLE Transaction (tid BIGINT, amount INT); CREATE TABLE Payment (tid BIGINT, method STRING); CREATE TABLE Result (tid BIGINT, …, PRIMARY KEY(tid) NOT ENFORCED); INSERT INTO Result SELECT * FROM Transactions T LEFT JOIN Payments P ON T.tid = P.tid; Sink(table=[Result], changelogMode=[NONE], upsertMaterialize=[true]) +- Join(leftInputSpec=[NoUniqueKey], rightInputSpec=[NoUniqueKey], changelogMode=[I,UB,UA,D]) :- Exchange(changelogMode=[I]) : +- TableSourceScan(table=[[Transaction]], changelogMode=[I]) +- Exchange(changelogMode=[I]) +- TableSourceScan(table=[[Payment]], changelogMode=[I])](https://image.slidesharecdn.com/timowaltherbr0762022-9-221023172317-803bf70e/75/CDC-Stream-Processing-With-Apache-Flink-With-Timo-Walther-Current-2022-21-2048.jpg)
![Changelog Insights – Updating with PK 22 CREATE TABLE Transaction (tid BIGINT, …, PRIMARY KEY(tid) NOT ENFORCED); CREATE TABLE Payment (tid BIGINT, …, PRIMARY KEY(tid) NOT ENFORCED); CREATE TABLE Result (tid BIGINT, …, PRIMARY KEY(tid) NOT ENFORCED); INSERT INTO Result SELECT * FROM Transactions T LEFT JOIN Payments P ON T.tid = P.tid; Sink(table=[Result], changelogMode=[NONE]) +- Join(leftInputSpec=[UniqueKey], rightInputSpec=[UniqueKey], changelogMode=[I,UA,D]) :- Exchange(changelogMode=[I]) : +- TableSourceScan(table=[[Transaction]], changelogMode=[I]) +- Exchange(changelogMode=[I]) +- TableSourceScan(table=[[Payment]], changelogMode=[I])](https://image.slidesharecdn.com/timowaltherbr0762022-9-221023172317-803bf70e/75/CDC-Stream-Processing-With-Apache-Flink-With-Timo-Walther-Current-2022-22-2048.jpg)
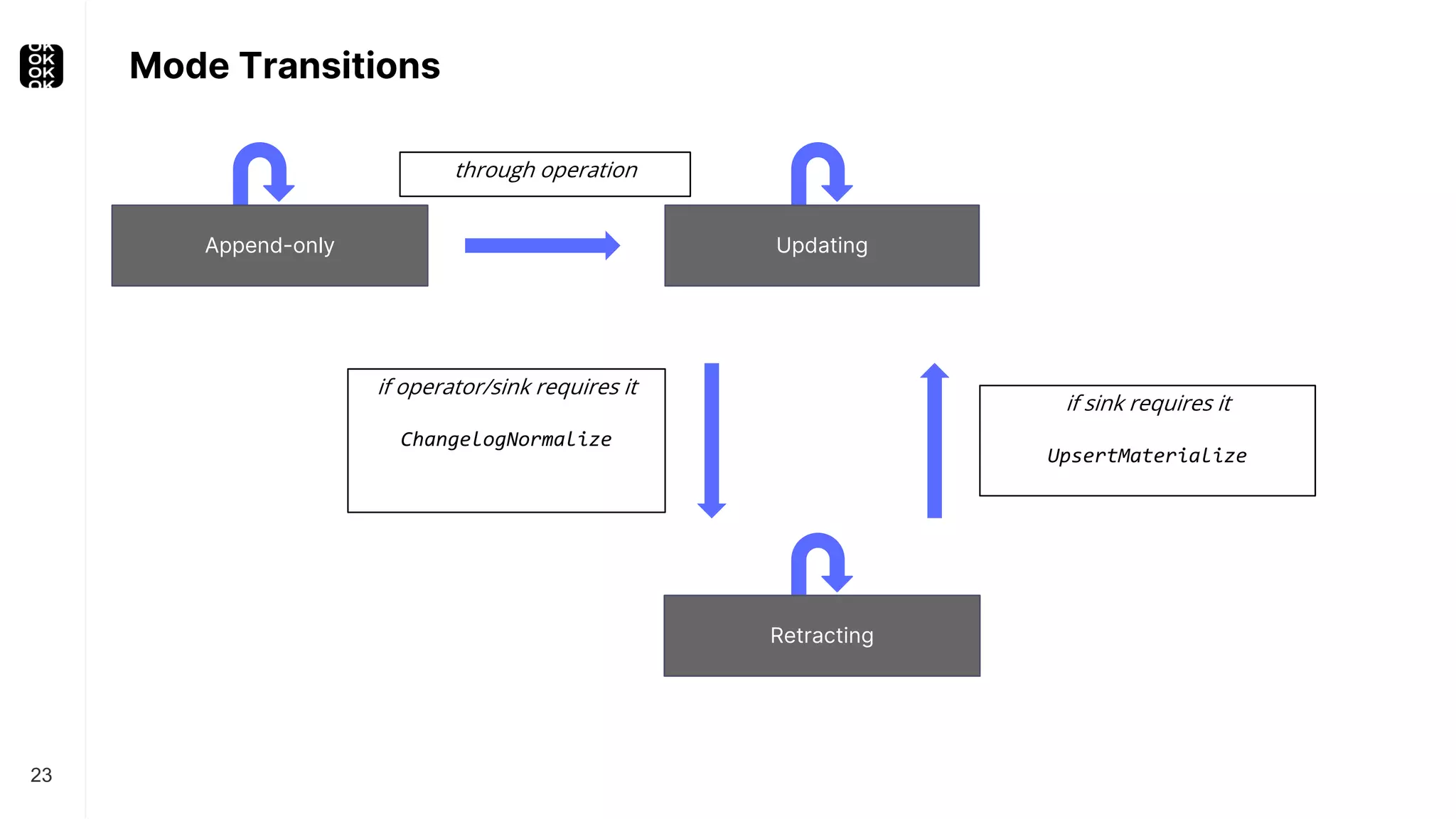
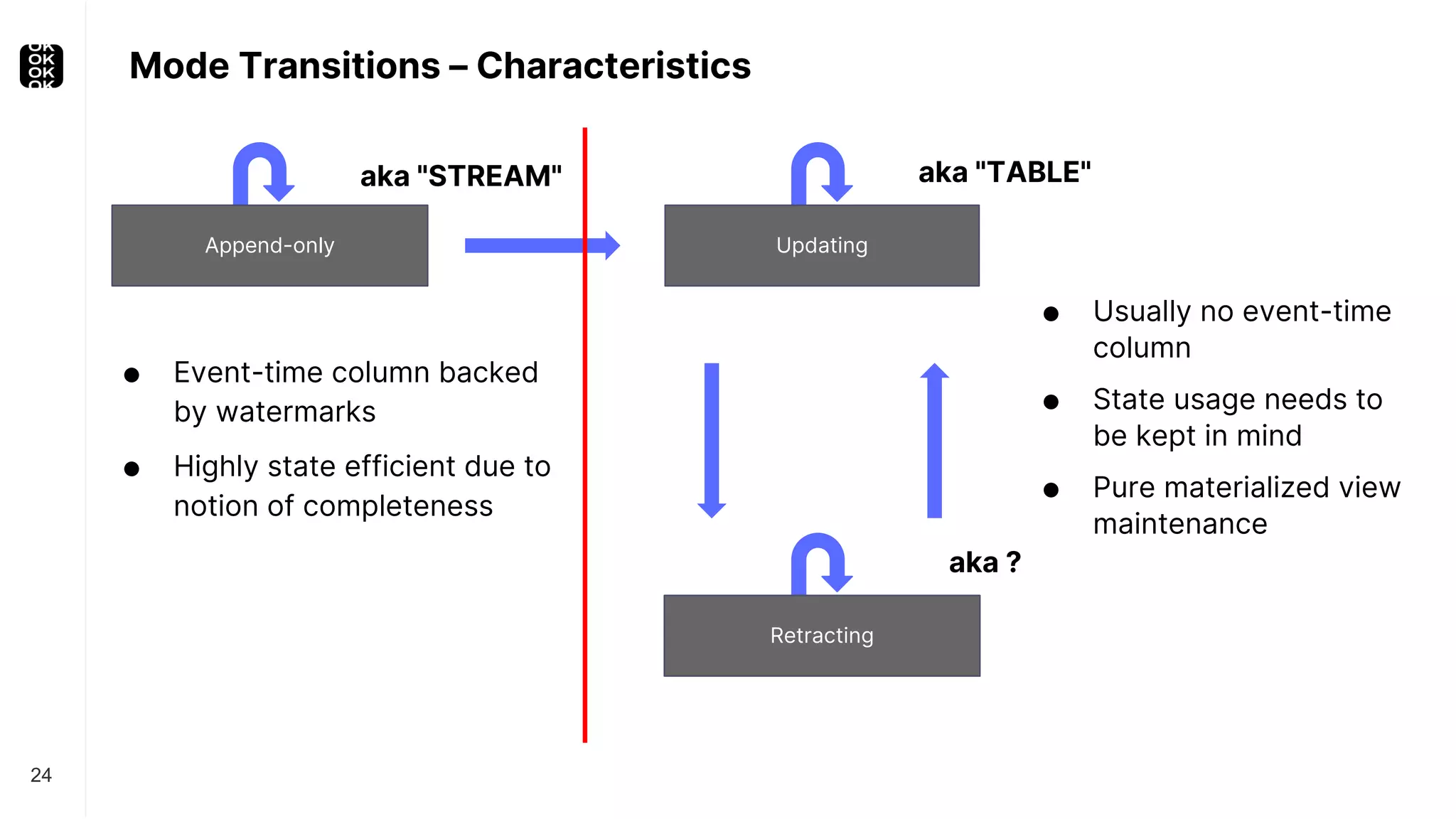
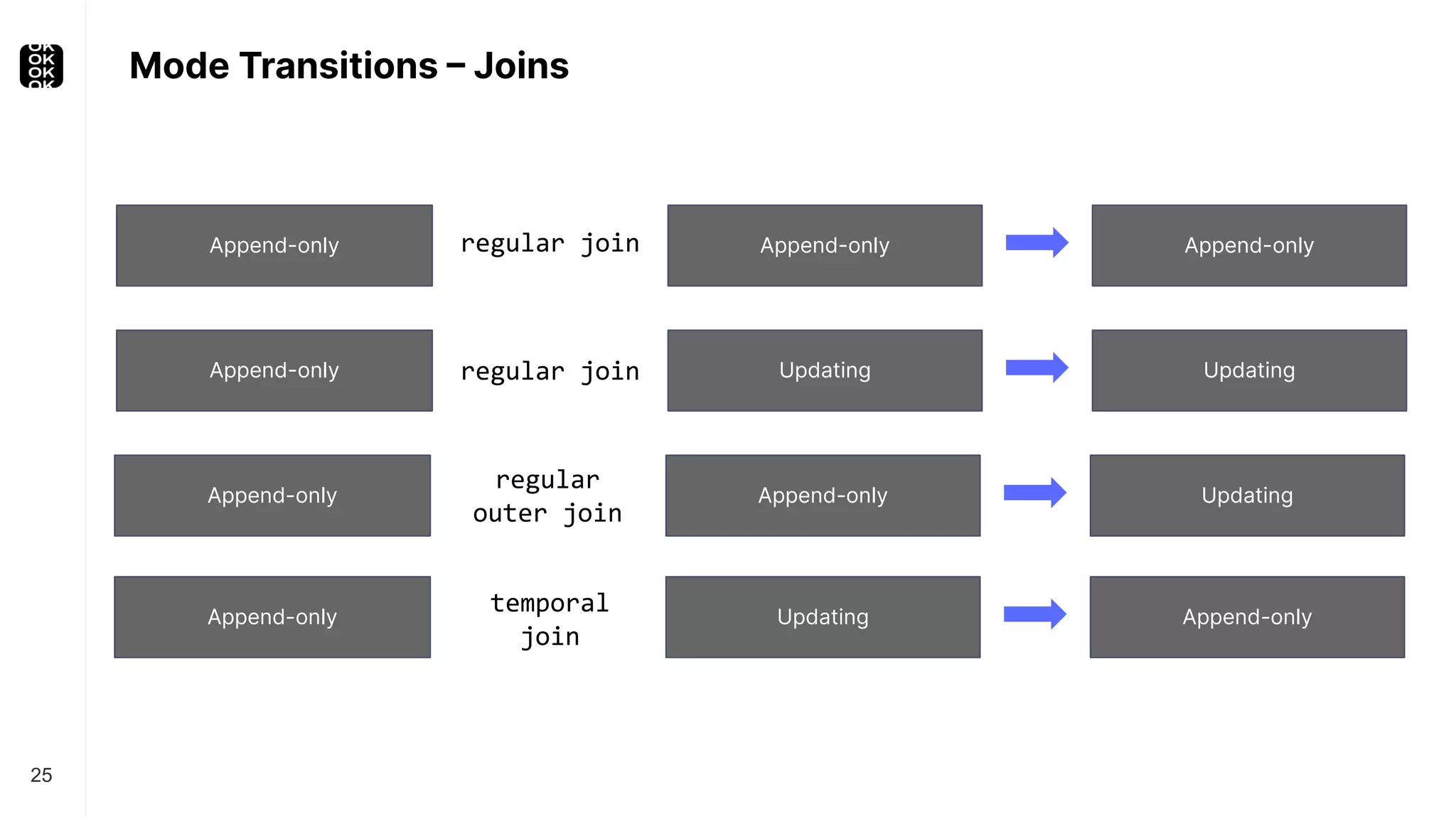
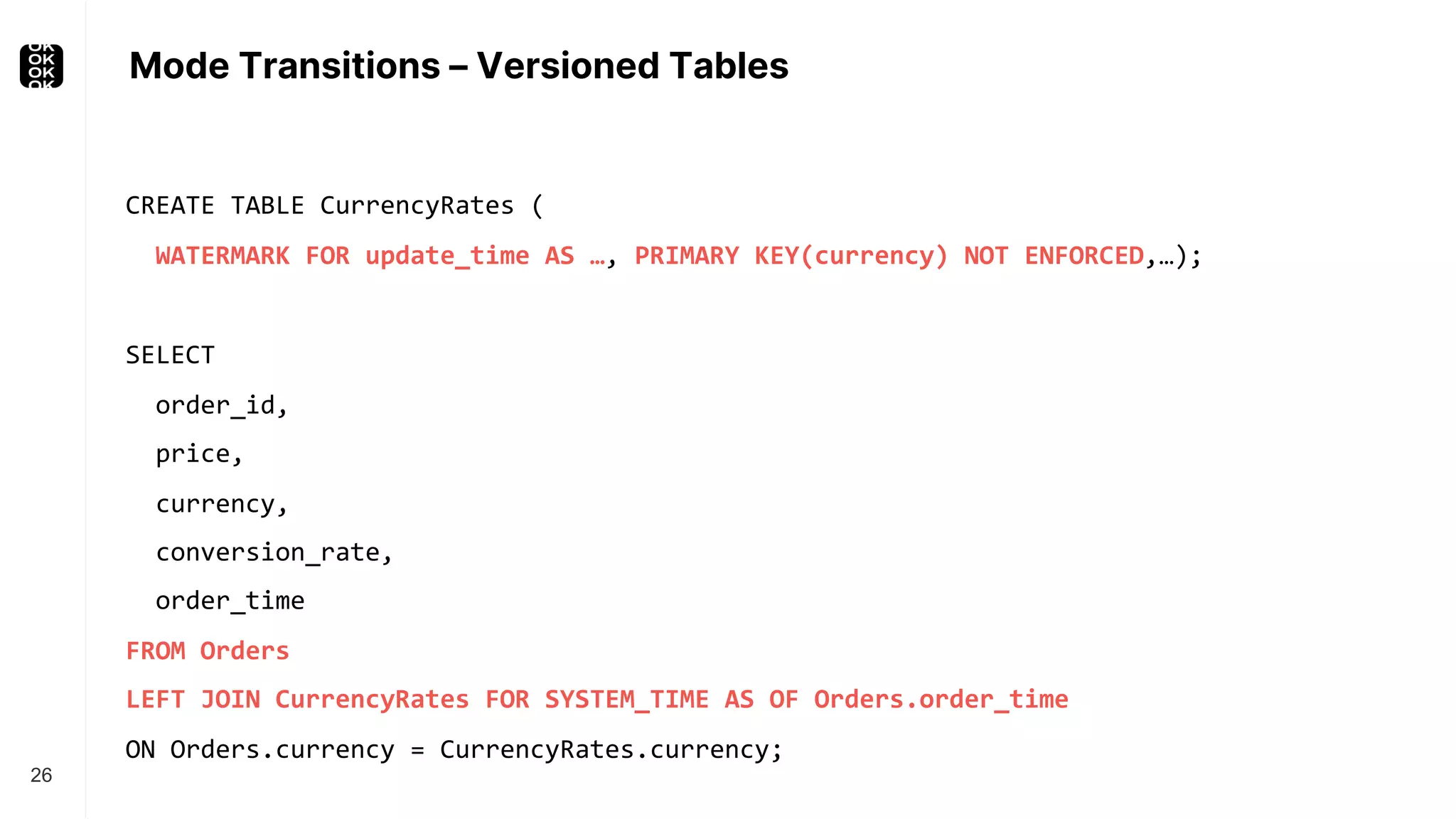
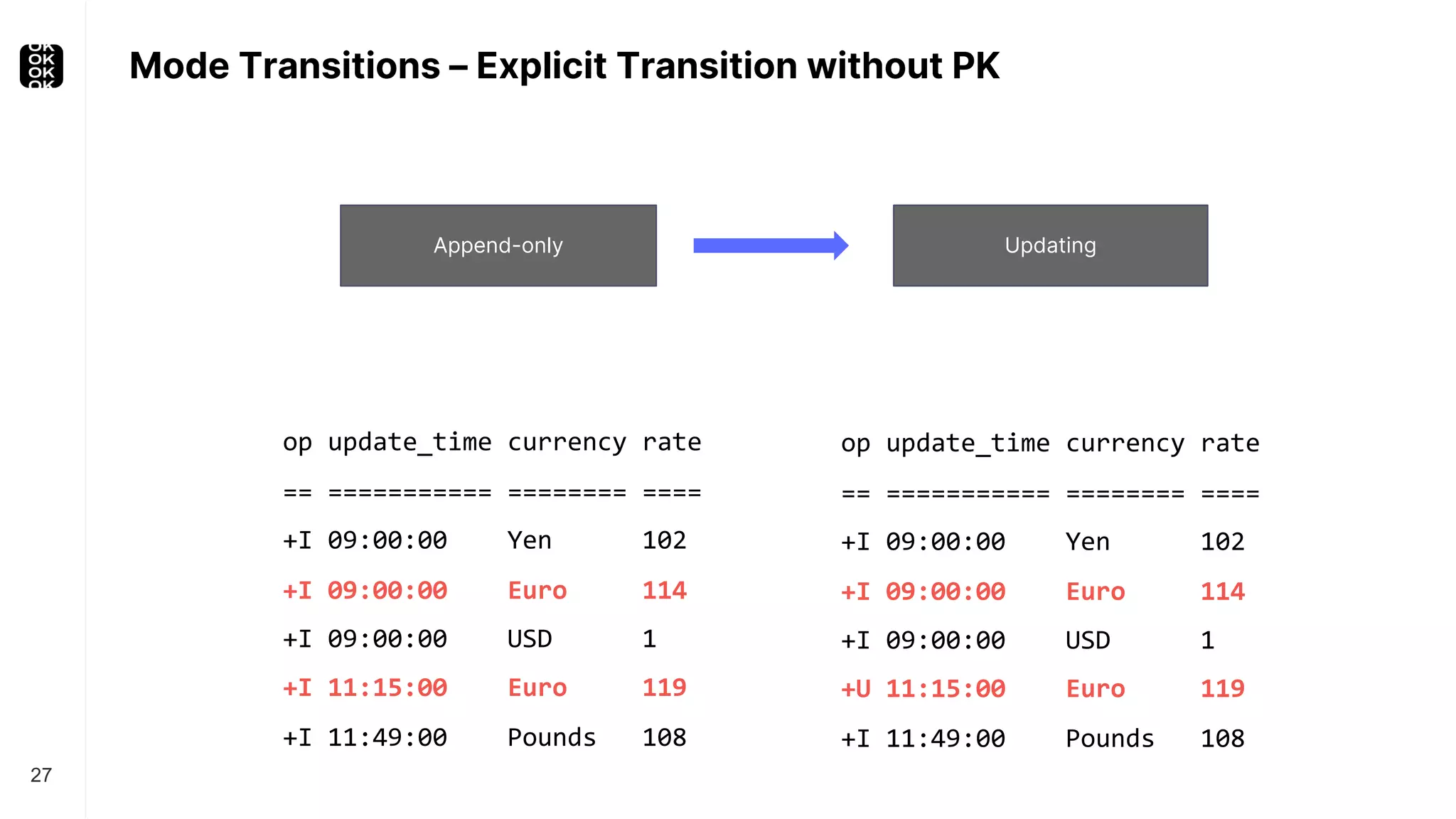





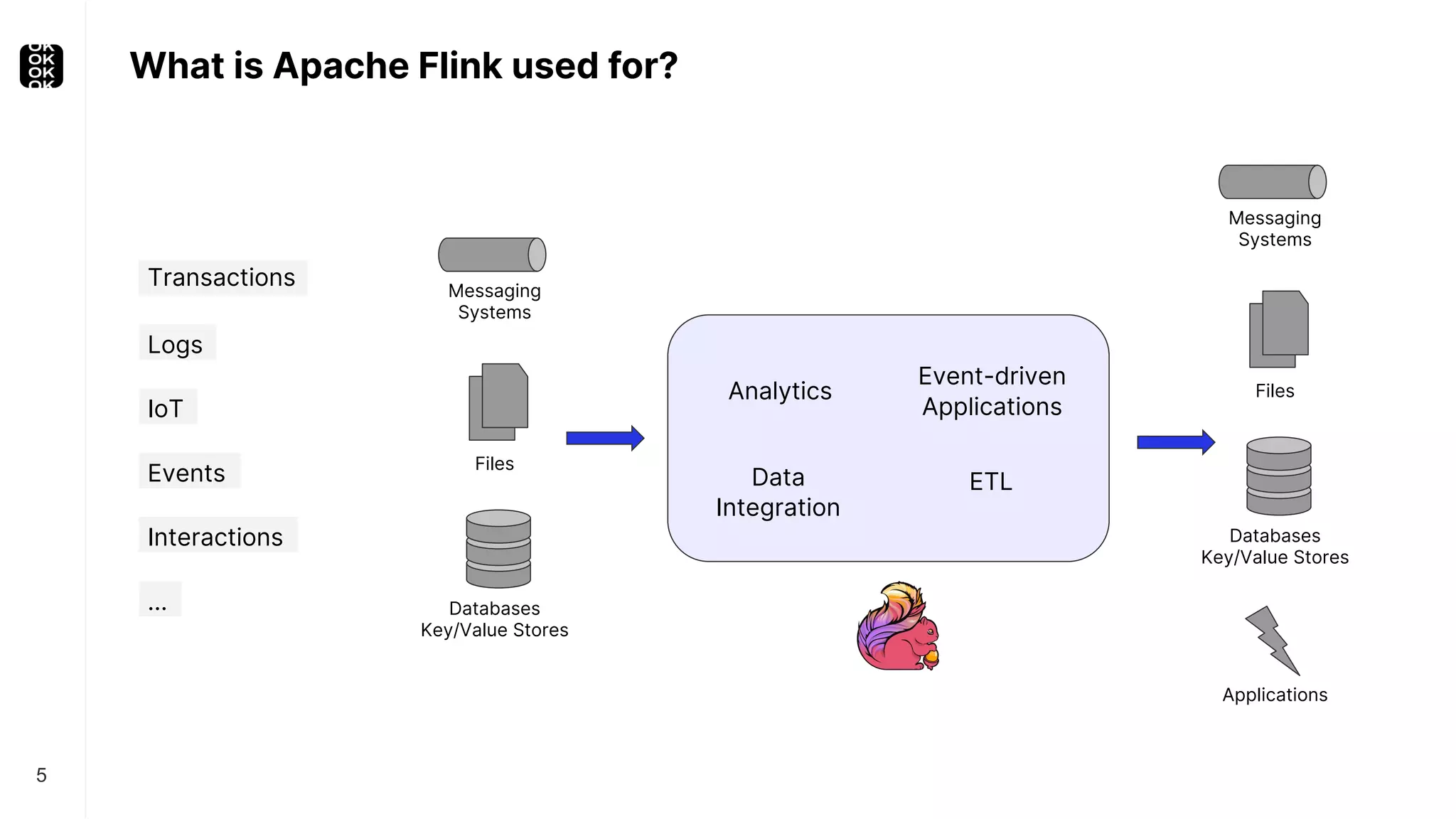
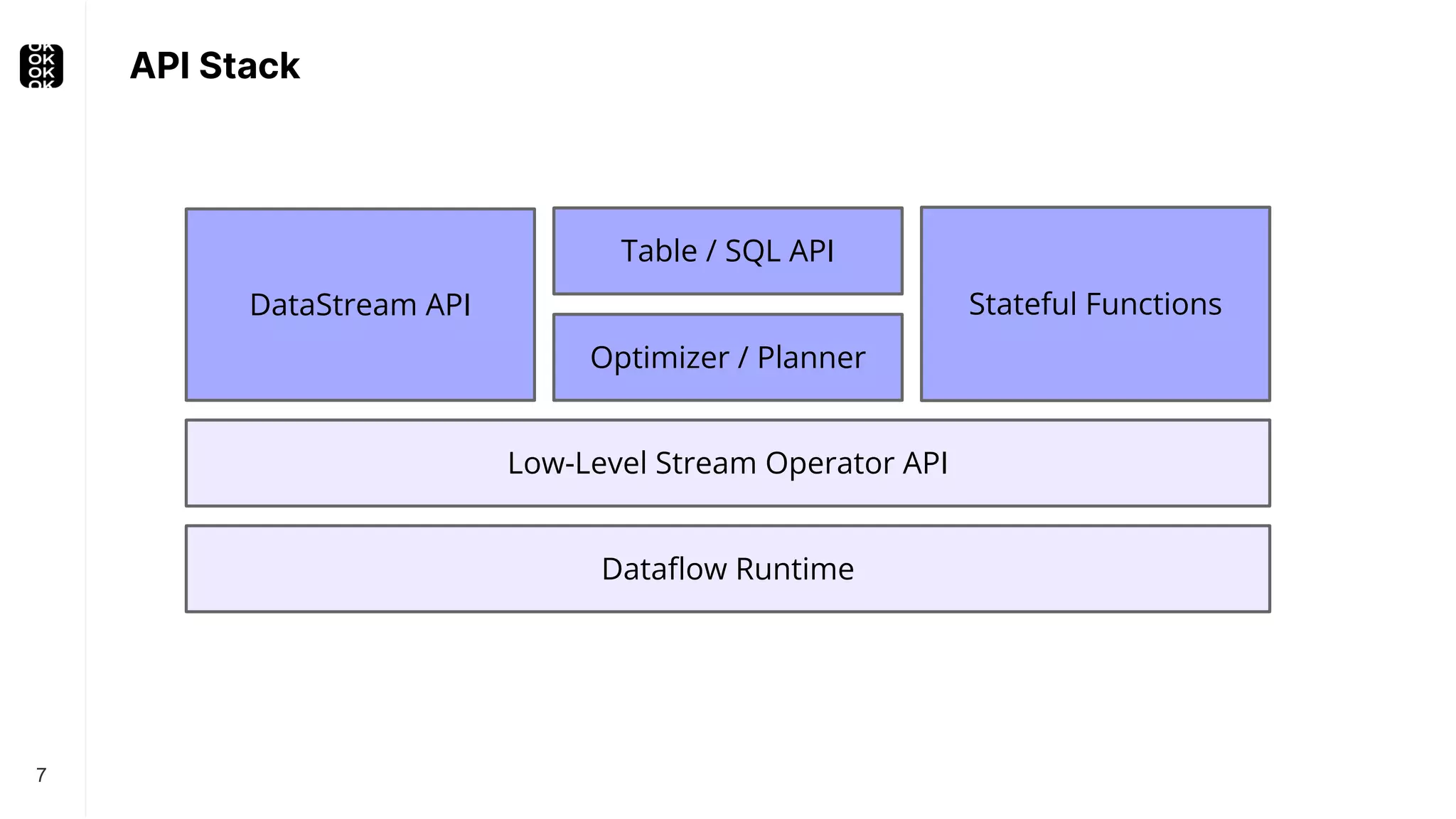
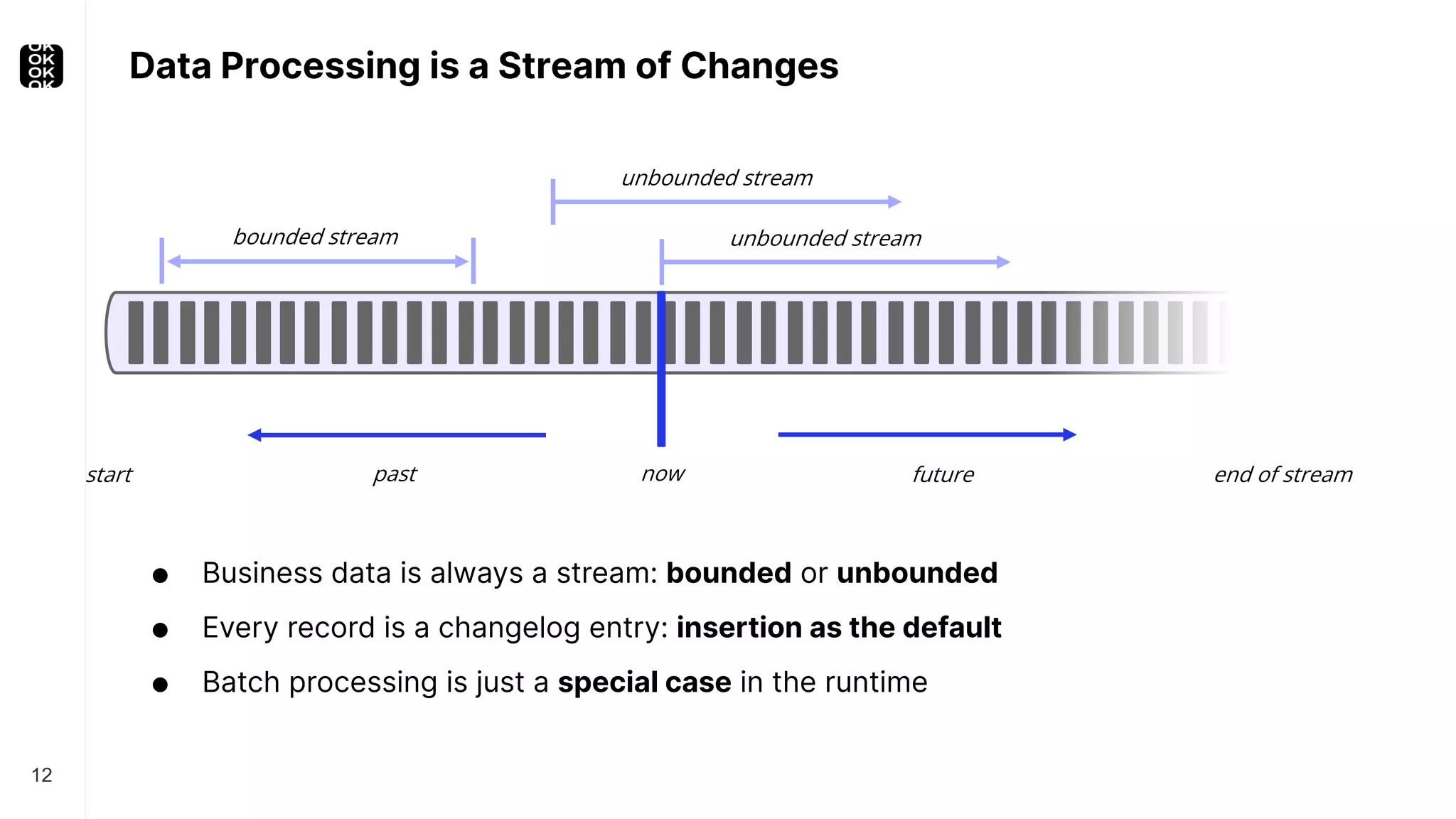
The document is a presentation by Timo Walther on Apache Flink, focusing on its capabilities for stream processing and the use of Flink SQL to manage data as dynamic tables. It describes the structure of Flink, including its APIs, data processing models, and concepts like changelog entry updates, stream-table duality, and operational modes. The presentation highlights Flink's usefulness for integrating various data systems and has links to additional resources and projects related to Flink.