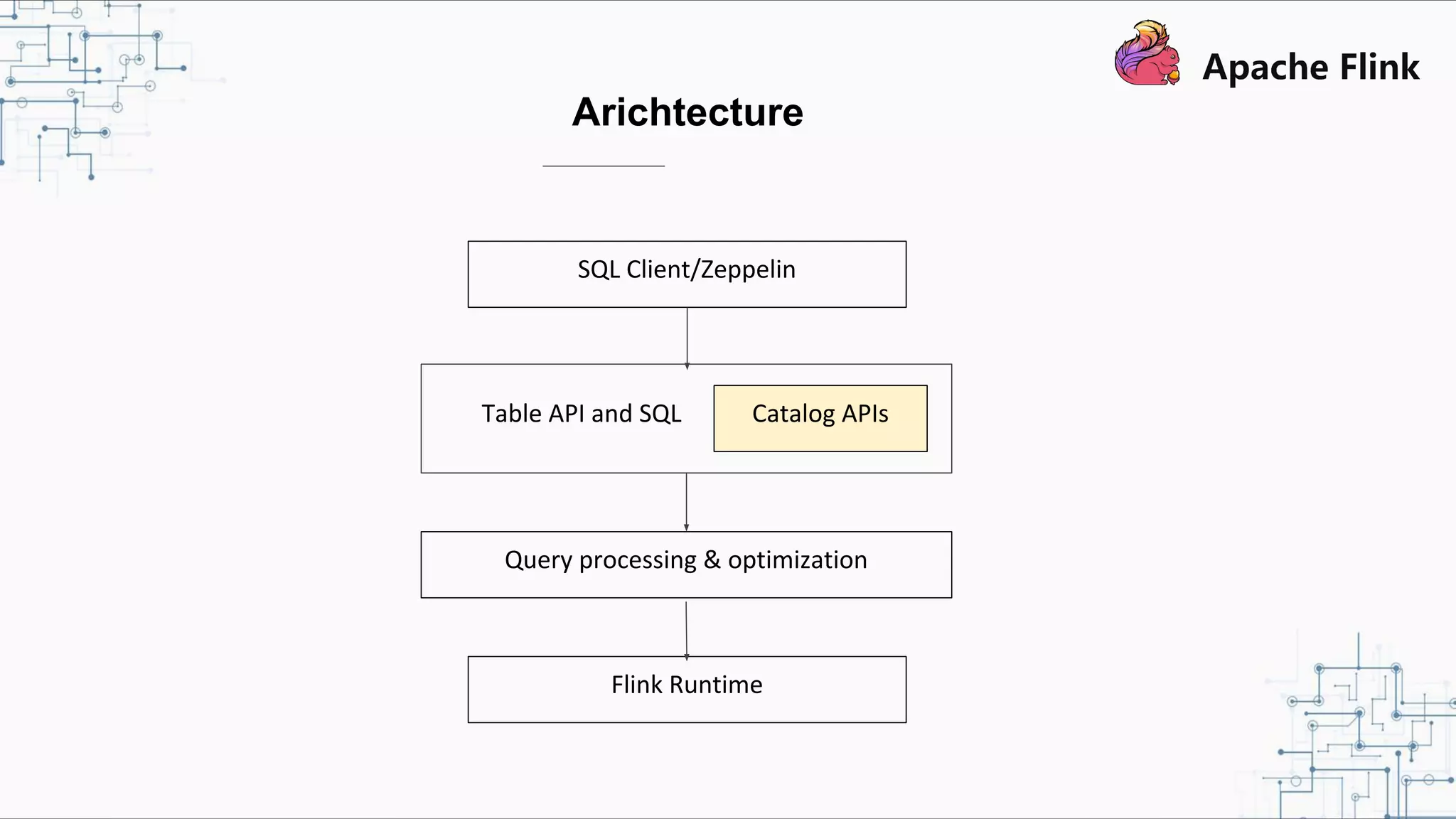
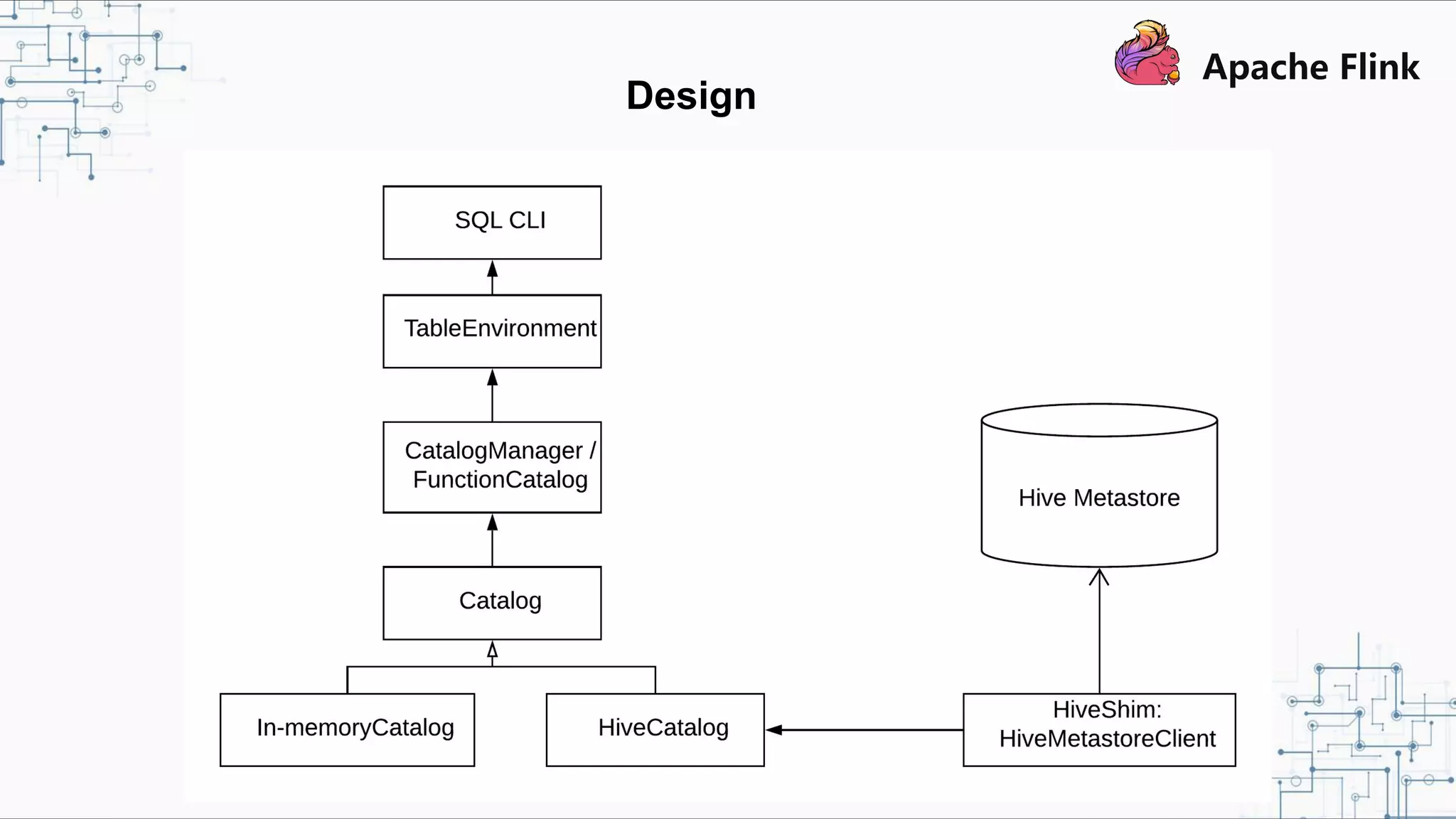
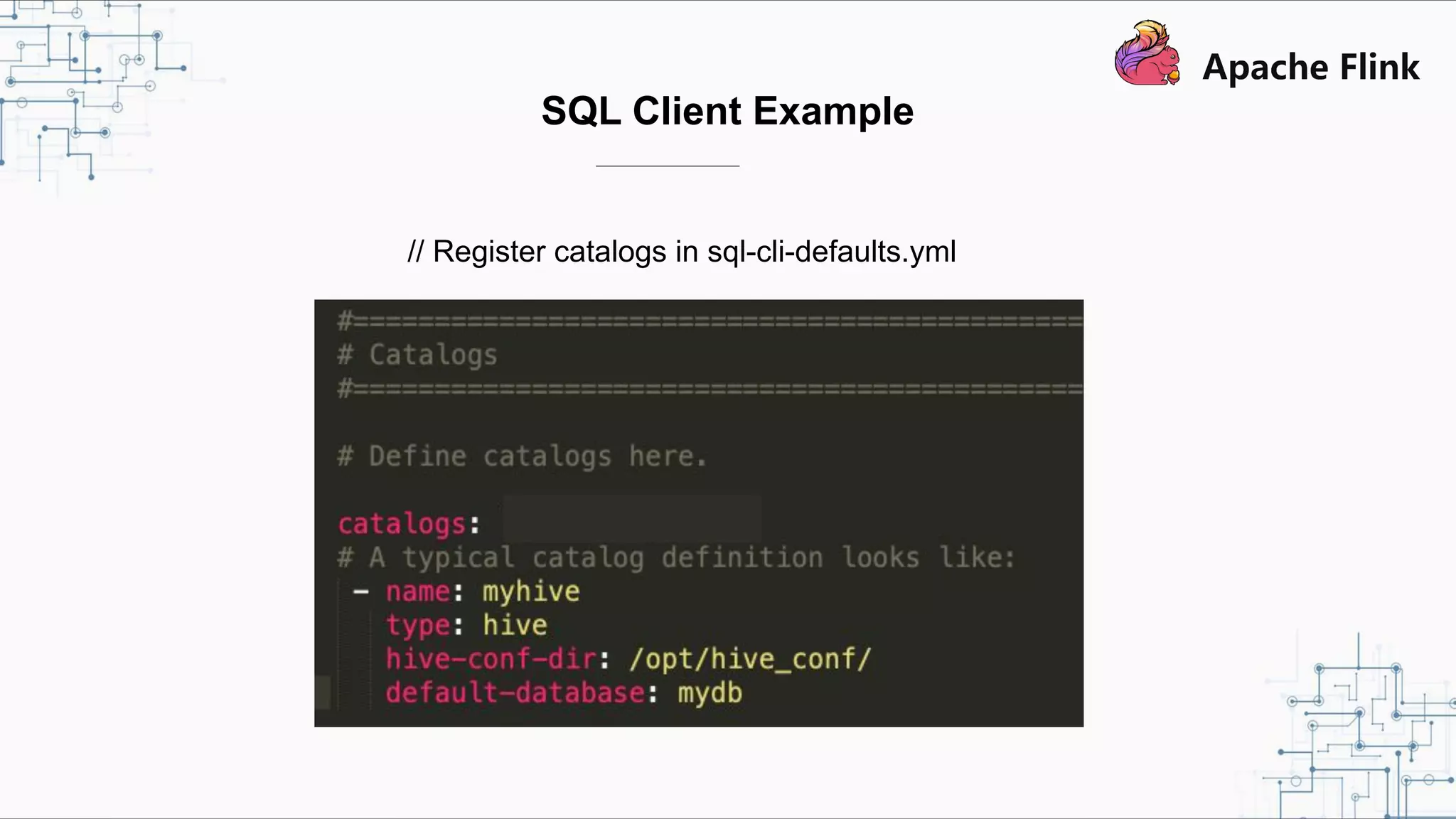
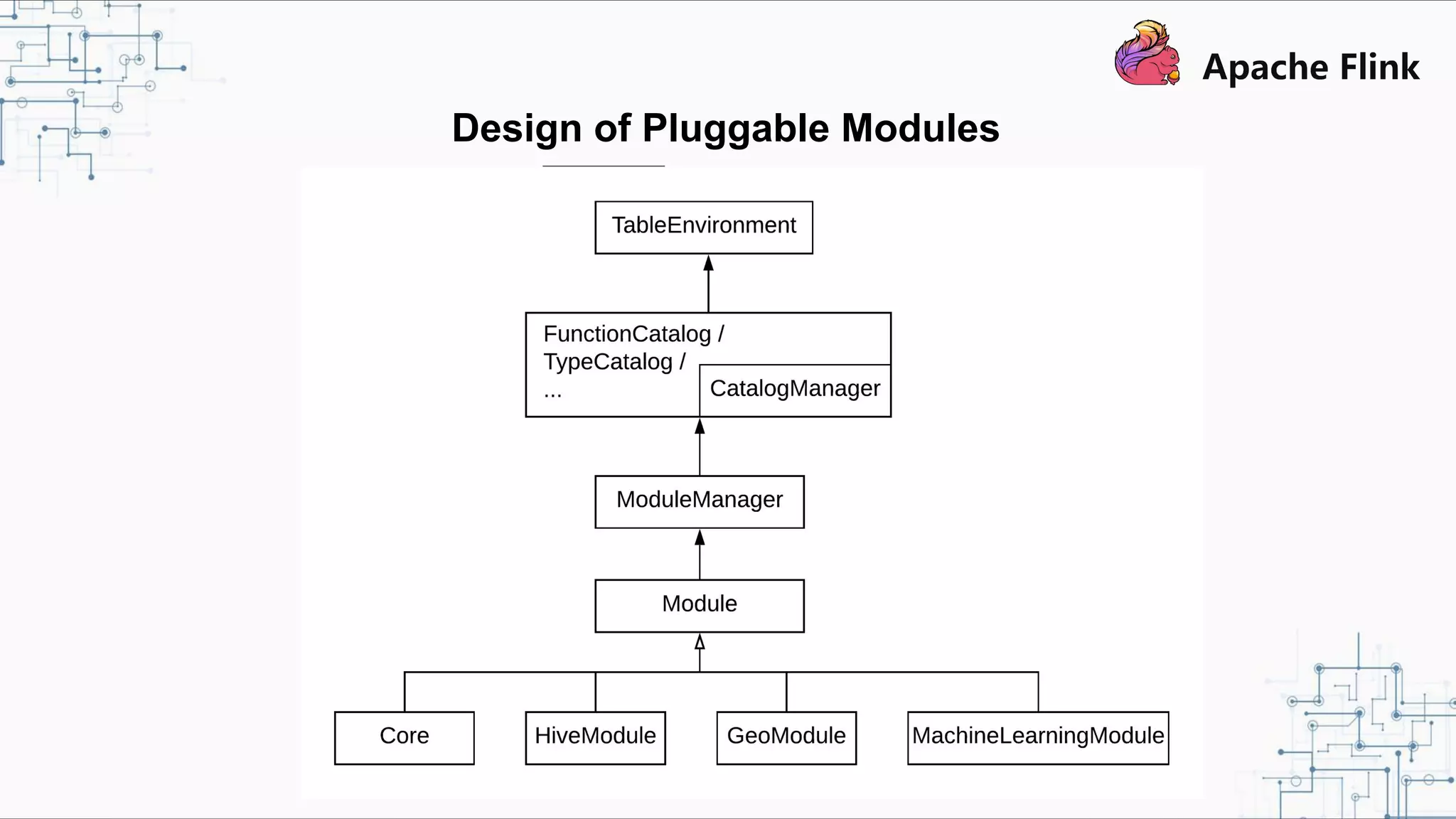
Flink and Hive Integration aims to unify Flink's streaming and batch processing capabilities by integrating with Hive. Flink 1.9 introduced initial integration with Hive by developing new Catalog APIs to integrate Flink with Hive's metadata and metastore. Flink 1.10 will enhance this integration by supporting more Hive versions, improving Hive source and sink, and introducing pluggable function and table modules. The integration strengthens Flink's metadata management and SQL capabilities while promoting its adoption for both streaming and batch processing.